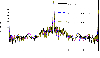Novel Parallelization of Discontinuous Galerkin Method for Transient Electromagnetics Simulation Based on Sunway Supercomputers
Minxuan Li, Qingkai Wu, Zhongchao Lin, Yu Zhang, and Xunwang Zhao
School of Electronic Engineering, Xidian University, Xi’an, 710071, China
lwdldj@163.com, zclin@xidian.edu.cn
Submitted On: June 23, 2022; Accepted On: September 24, 2022
Abstract
A novel parallelization of discontinuous Galerkin time-domain (DGTD) method hybrid with the local time step (LTS) method on Sunway supercomputers for electromagnetic simulation is proposed. The proposed method includes a minimum number of roundtrip (MNR) strategy for processor-level parallelism and a double buffer strategy based on the remote memory access (RMA) of the Sunway processor. The MNR strategy optimizes the communication topology between nodes by recursively establishing the minimum spanning tree and the double buffer strategy is designed to make communication overlapped computation when RMA transmission. Combining the two methods, the proposed method achieves an unprecedented massively parallelism of the DGTD method. Several examples of radiation and scattering are used as cases to study the accuracy and validity of the proposed method. The numerical results show that the proposed method can effectively support 16,000 nodes (1,040,000 cores) parallelism on the Sunway supercomputer, which enables the DGTD method to solve the transient electromagnetic field in a very short time.
Index Terms: discontinuous Galerkin method, electromagnetic analysis, memory access optimization, sunway TaihuLight.
1 INTRODUCTION
As one of the most accurate time-domain electromagnetic field calculation methods, the discontinuous Galerkin time-domain (DGTD) method has higher numerical accuracy and modeling flexibility than traditional time-domain methods, such as the finite difference time-domain (FDTD) method and the finite volume time-domain (FVTD) method [1, 2, 3]. Thus, it is widely used in the simulation of broadband characteristics in ultra-wideband (UWB) communication, pulse radar, time-domain measurement, and electromagnetic compatibility, etc [4, 5]. In the industrial application of the DGTD method [1, 2, 3, 8, 9], the important key technologies are multi-scale techniques and the massively parallelism techniques [10, 11, 12]. The common multis-cale technique of the DGTD method is local time stepping (LTS). At present, some research on the thread-level parallelism of LTS-DGTD [13, 20, 21], which makes the implementation of the distributed parallelism of LTS-DGTD is feasible, has been performed. However, LTS-DGTD does not scale well on the multi-node parallelism between nodes [13, 14]. The multi-node parallelism is very common in distributed platforms, such as supercomputers. With the advancement of computer technology, supercomputers have reached tens of thousands of nodes so far [13, 15, 16, 17], and the maximum parallel size of the DGTD method has stopped at hundreds of nodes [14, 18, 19, 20], which makes the DGTD method unsuitable for electrically large problems on modern supercomputers with ever increasing nodes.. Therefore, the massively node-level parallelism for the LTS-DGTD method urgentiv.In addition, at the current situation of chip supply shortage and prohibition, it is necessary to study the parallelism of China’s domestic processors, such as SW26010, which composes the Sunway TaihuLight, the most powerful supercomputer in China [21–26]. Based on SW26010, a new Sunway CPU has been developed [27]. The new Sunway CPU expands the computing processing element (CPE)’s local data memory (LDM) from 64KB to 256 KB and improves the bandwidth of the LDM controller. At the same time, the remote memory access (RMA) technology, which is one of the most attractive technological advances of the new Sunway CPU is introduced for the communication between CPEs. The new Sunway supercomputer composed of the new Sunway CPU, will be possible achieves 1000 PFlops [28]. However, there is no research on the DGTD method with the new Sunway CPU.
To solve these problems, this paper proposes a novel parallelism of the LTS-DGTD method for Sunway supercomputers. The proposed method has a minimum roundtrip strategy to improve the scalability of node-level parallelism of the LTS-DGTD method, and a double-buffer parallelism with RMA of LTS-DGTD method for the new Sunway supercomputer. The double-buffer strategy is efficient for reducing the computing time in-cores and improves the communication efficiency of the LTS-DGTD in CPEs. These two proposed strategies enable the LTS-DGTD method to be implemented on the new Sunway supercomputer successfully and efficiently.
2 THE FORMULATION OF DISCONTINUOUS GALERKIN TIME-DOMAIN
The Maxwell’s equation in 3D space [4] is:
| (1) |
in which E, H, D and B are the electric field intensity, magnetic field intensity, electric flux density, and magnetic flux density, respectively; is permittivity and is permeability, and J is the electric current density; is the electric charge density. E and H are approximated as:
| (2) |
where denotes the basis function, and are the time depent coefficients of basis function , is the number of basis functions. In this study, the 0.5, 1 and 2 order hierarchical basis functions of [6] are used.
Following the Galerkin finite elements approach [1] to the curl operators of equation (1) without J, it can be written as:
| (3) |
where is the calculation domain divided into tetrahedrons. According to [1], with integration by parts, the weak forms of equation (3) are:
| (4) |
where is the boundary of , and is the normal vector located on . The DGTD method introduces numerical fluxes to substitute for the right-terms, i.e., integration over the tetrahedron interfaces.We fthe procedure set out in [7] to deal with the right-terms of equation (4): solving the Riemann problem under the Rankine-Hugoniot condition yields an expression for the upwind flux:
| (5) |
where is the adjacent tetrahedron of tetrahedron , the wave impedances of and are and , respectively. For anisotropic Maxwell equations, it is necessary to deal with the tensor matrices of permitivity and permeability, which has been well solved in [4] and [5]. The isotropy semi-discrete form with upwind flux is shown as:
| (6) |
which can be written as matrix forms as:
| (7) |
where and denote vectors composed by and in the integral domain, respectively, the flux coefficients are , , and , is the mass matrix, is the stiffness matrix, and are the flux matrices. Those matrices can be summarized:
| (8) | ||
Those linear equations defined in one tetrahedron or a subdomain of avoid composing a large sparse matrix.
Applying the explicit leapfrog (LF) scheme [10] to deal with the time derivative of equation (7), we have:
| (9) |
where is the size of time step, and differ by half a time step. Following the CFL condition, the maximum time step size is limited by the smallest element.
The size of the smallest and biggest element is always large in practice, so that the time step size is too short for most elements which leads to a huge number of time steps. The LTS-DGTD method in [2] is:
| (10) |
in which , M is the number of levels and is the level of . The minimum element size between levels varies by three times and the time step size is three times either. This greatly reduces the total amount of calculation. However, this scheme has a higher error in 3D space than in 2D space, so that the interpolation method is used on the different time step fields between adjacent elements of different levels to obtain pseudo time steps. This paper uses an interpolation method as follows:
| (11) |
where is field and is the time step size of element j, is the time step size of element . The computation work is shown in Fig. 1. The ratio of time step sizes of level1, level2 and level3 is 1:3:9. Pseudo time steps of higher level are obtained by equation (11) and provided to lower level, the stability of this scheme is proven in [1]. Obviously, the acceleration of LTS is determined by and the number of elements in different levels.
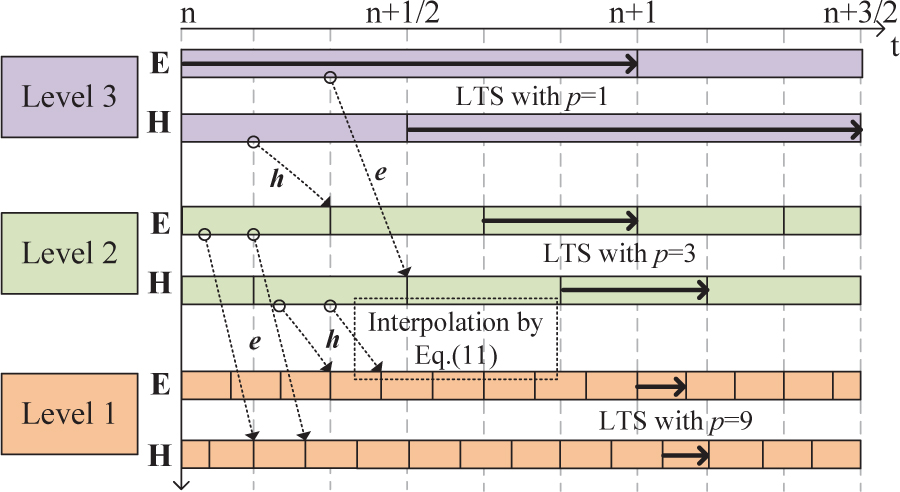
Figure 1: Computation work of LTS-DGTD with interpolation, E and H are pseudo electric and magnetic field obtained by equation (11), respectively.
3 THE MINIMUM ROUNDTRIP STRATEGY FOR LTS-DGTD
Thread-level LTS-DGTD parallelism is very easy to implement due to the independence of the element in equation (10). When updating the electric and magnetic fields, it only depends on the fields of and in the previous time step. As for processor-level parallelism, equation (10) can be written as:
| (12) |
where is the number of elements belong to the local processor and y is the number of elements belong to adjacent processors. is the boundary adjacent with another processor.
When the LTS-DGTD method executing on a distributed platform, the communication is performed between the adjacent processors which always are defined on a host core of nodes. In this paper, the message passing interface (MPI) is used to support the communication between nodes. The logP [24] model is the most popular topology of distributed platforms, and its structure is shown in Fig. 2.
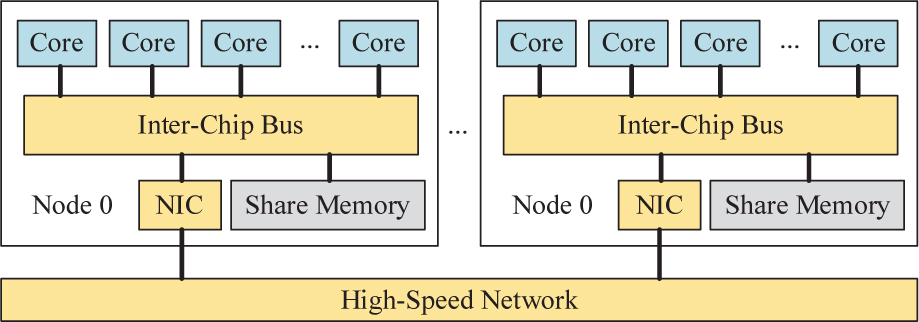
Figure 2: The structure of massively distributed platform. Processor is defined on cores, and NIC is the network interface controller.
The running time of the logP model is:
| (13) |
where is the time of calculation, is the time of communication. The computational time complexity of LTS-DGTD in each iteration step is determined by the number of elements of LTS levels. Communication time complexity can be expressed as
| (14) |
where is the network bandwidth, is the number of roundtrips between nodes and is the amount of data transmission per roundtrip. can be considered a constant when data transmitting continuously between nodes. The memory of each node is accessed locally for the storage structure of the logP model, non-dependent processors do not influence each other while communicating, thus they can communicate at the same time. We should select nodes that communicating at the same time to reduce the number of roundtrips, so a minimum number of roundtrip (MNR) strategy is proposed to solve this problem.
As the global graph shown in Fig. 3, the number in a node represents the rank of a processor, the edge indicates the communication between two processes. Obviously, simple graph sorting cannot obtain the MNR. Referring to the Kruskal algorithm [29], only each independent subtree is saved in the process while finding the minimum spanning tree (MST), the number of independent subtrees is the MNR. This algorithm for finding MNR of the LTS method is MNR-LTS algorithm which has four steps as follows.
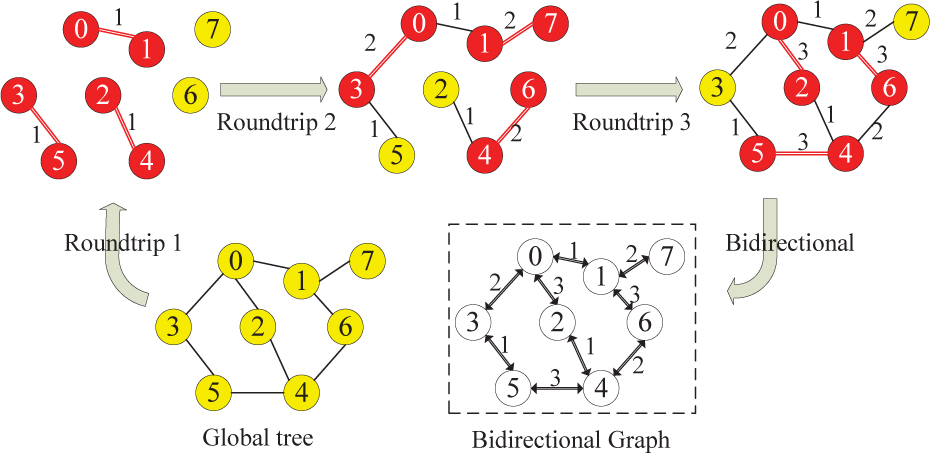
Figure 3: The minimum number of roundtrips strategy and the graph of communication. The weight of edge is its roundtrip among the communication, the red circles indicate that the processor communicates in this roundtrip and the yellow circles indicate that the processor does not communicate.
Step 1 Mark the weights of edges in the graph as 0, set the current roundtrip as 1.
Step 2 Pick all unconnected edges in the graph, remark the weight of those edges as current roundtrip.
Step 3 Remove the picked edges of the previous step and create a new graph, add one to current roundtrip.
Step 4 Repeat steps 2 and 3 until all edges are remarked. These four steps are performed in every LTS levels, sum of all LTS levels roundtrip is the final number of roundtrips. The weight of an edge is the roundtrip of the communication between the processors connected by this edge. Since this graph is a bipartite graph above send and receive, the MNR should be twice the current roundtrip. Because the graph topology of nodes exists naturally, this method can be used on most distributed computers, such as distributed computing systems and supercomputers.
4 PARALLELISM ON SUNWAY SUPERCOMPUTERS
The most classic Sunway many-core CPU is SW26010, which is based on the Alpha framework and composed of four core groups (CG). Each CG contains a management processing (MPE) and an 8 × 8 CPE cluster. Each CG has 8G of share memory space and can be accessed by the primary and secondary cores, while each CPE core has a separate LDM sized 64KB. The CPE core reads the LDM quickly, but because the local memory space is too small, it needs to communicate with the host memory using the direct memory access (DMA).
The task division of inner-chip is important for Sunway manycore CPU. The structure of Sunway CPU is shown in Fig. 4, MPE broadcast the tetrahedrons and matrices to CPEs, and LDM receives them. However, the bandwidth of the interface is not optimal thus the communication between MPE and CPEs is slow. The conventional method to solve this problem is using DMA to transmit data. On the new general Sunway supercomputer, there is a better method to improve the communication efficiency of MPE to CPEs.
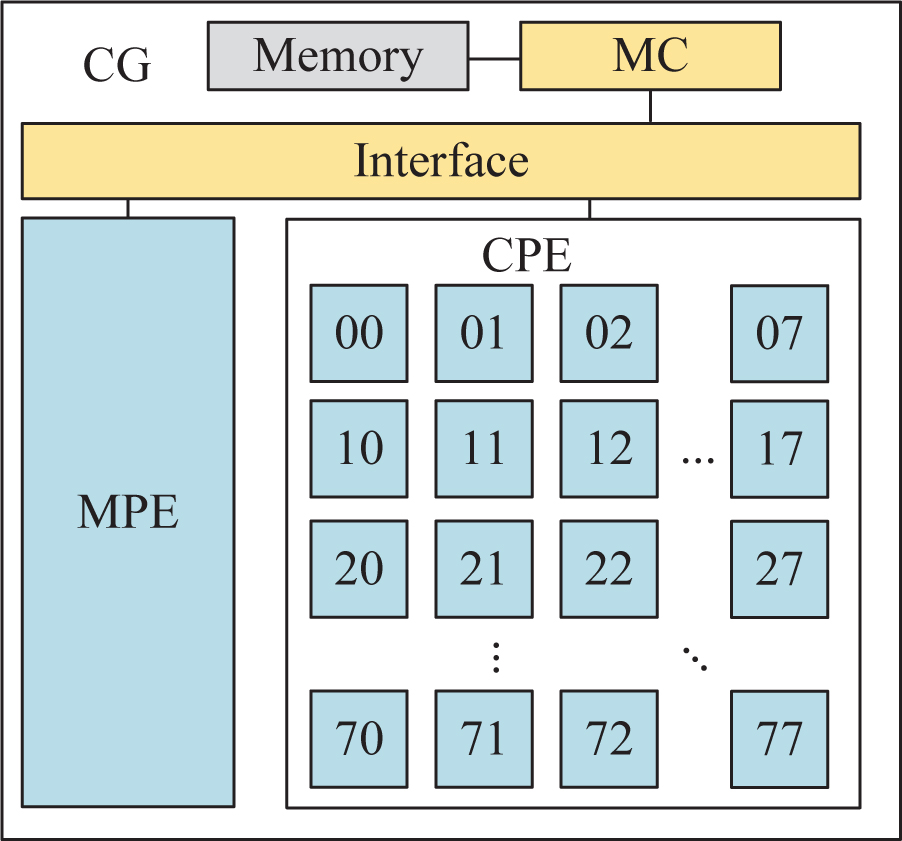
Figure 4: Structure of SW26010 and new general Sunway CPU.
When LDM transmits data, MPE uses DMA channel to transfer data from main memory to local memory, which is suspended from the core processor and allows access to parts of local memory that are not data transferred for operation. At the RMA double-buffer (RMA-DB) strategy, the received CPE memory buffers are divided into two parts when transferring data from one core to another through CPE inter-communication on CPEs. The two buffers are used to transfer and calculate data alternately to achieve the effect of communication masking, which hides the transmit time behind the computation time as Fig. 5 shows. At the same time, the application of MNR strategy to control process-level data exchange between the core groups improves the parallel efficiency and is suitable for large-scale parallel computing.
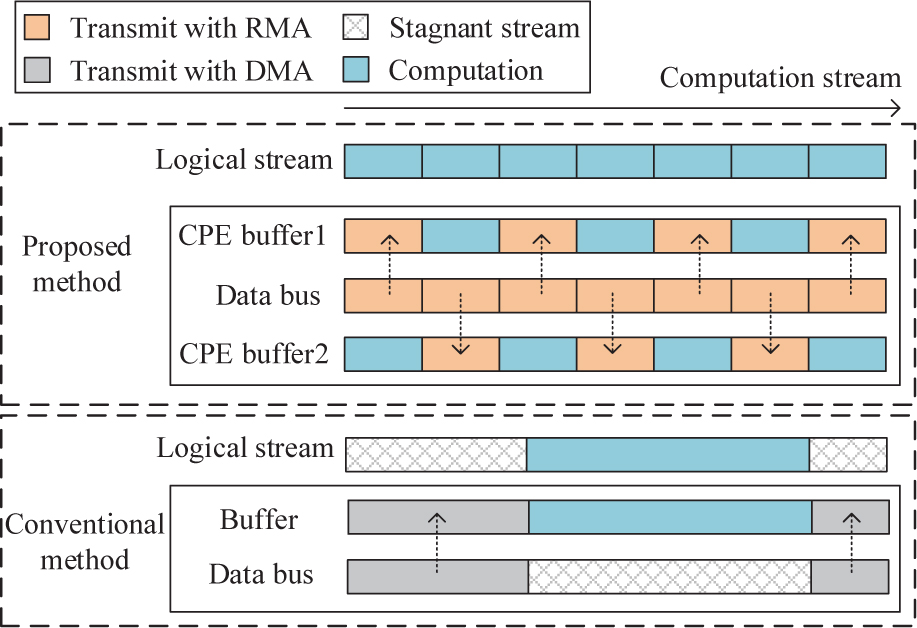
Figure 5: Transmit data by RMA and DMA. In proposed method, buffer 1 and buffer 2 transfer data using RMA alternately. The stagnant stream denotes there is nothing to do at that moment.
It should be noted that although the RMA-DB strategy can hide the communication time behind the calculation time, the MPE to LDM still consumes a lot of time, which is caused by the Sunway CPU architecture.
5 NUMERICAL RESULTS AND ANALYSIS
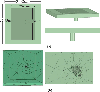
Firstly, a radiation problem is considered to test the LTS-DGTD method with RMA-DB strategy. Patch antennas are widely used in mobile communication and miniaturized radars, so in this paper a rectangular patch antenna is used to demonstrate the accuracy and efficiency of the proposed method. The rectangular patch is 22.7091 mm 30.1615 mm, treated as perfect electric conductor (PEC), the size of the dielectric substrate is 34.92 mm 38.65 mm 3 mm and its relative permittivity is 4.5. A modulated Gaussian pulse in 2GHz to 6 GHz excites the coaxial wave port at the bottom of the antenna, inner and outer radius of the coaxial line are 0.44 mm and 1.5 mm, respectively. The coaxial line makes the antenna mesh has multi-scale size, there is no sparse matrix solver that can use RMA-DB strategy on the new sunway supercomputer for the time being, thus, the LTS-DGTD method is suitable for this problem. According to the wavelength of 4 GHz, 52,755 tetrahedrons were obtained through meshes discretisation, which is partitioned into 3 LTS levels in LTS-DGTD, the time step sizes are from 0.0602 ps to 0.5418 ps. The geometry and mesh of the patch antenna are shown in Fig. 6.
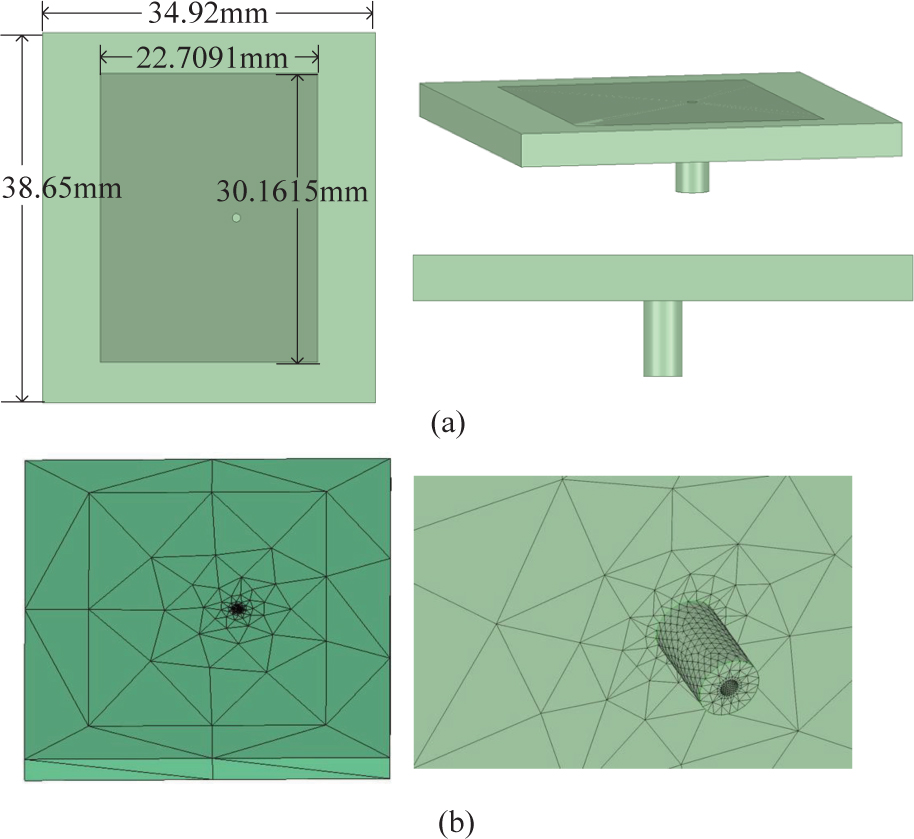
Figure 6: The model and mesh of patch antenna. (a) Front, top, and side views of the model; (b) Top and bottom meshes.
Table 1: Running time of the proposed method
| Kernel | LTS | MPE | CPEs Cluster | RMA-DB |
| level | time(s) | time(s) | time(s) | |
| Update | Level1 | 263.1 | 148.2 | 81.4 |
| E | Level2 | 295.5 | 156.3 | 85.2 |
| Level3 | 1845.6 | 945.8 | 443.7 | |
| Update | Level1 | 262.5 | 147.8 | 80.9 |
| H | Level2 | 296.0 | 155.2 | 86.8 |
| Level3 | 1845.2 | 946.1 | 443.3 |
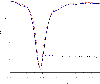
The S-parameter of the LTS-DGTD method on CPU and Sunway processor are exhibited in Fig. 7, the result of commercial software Ansys-HFSS is also proposed in Fig. 7. Its obviously that the accuracy of the proposed method on CPU is similar to that on Sunway. To show the efficiency of the RMA-DB strategy, the running time of different parts of the proposed method is summarized in Table 1, the update E is the first stage of Eq. (12) and the update H is the second stage of Eq. (12). With the RMA-DB strategy, CPEs has 4.15 acceleration than MPE, that demonstrates the efficiency of the RMA-DB strategy.
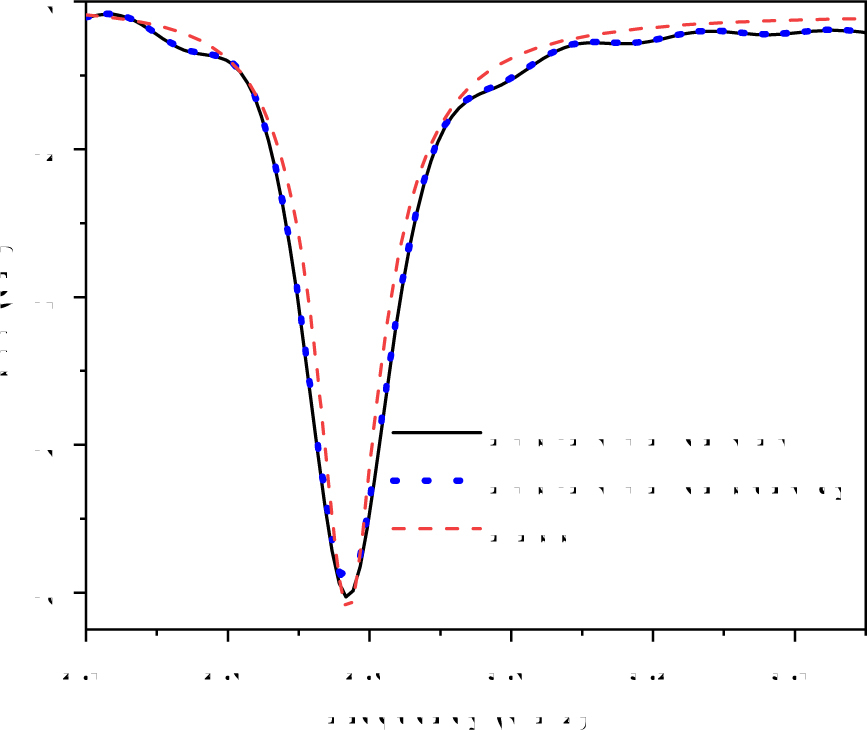
Figure 7: Transmit data by RMA and DMA. In proposed method, buffer 1 and buffer 2 transfer data using RMA alternately. The stagnant stream denotes there is nothing to do at that moment.
Secondly, a slot antenna is used to demonstrate the performance of MNR strategy on homogeneous distributed computers. The geometry of the antenna is shown in Fig. 8. This antenna is excited by a coaxial wave port with the modulated Gaussian pulse in 15 GHz to 17 GHz. The antenna model is discretized into 1101096 tetrahedrons and is simulated by the DGTD-LTS method with MNR strategy on a homogeneous distributed computer. The homogeneous computer has 16 nodes, each node has 72 cores (Intel Xeon Gold 6140 @ 2.30GHz). The 120, 360, 720 and 936 cores cases employ 2, 6, 12 and 13 nodes, respectively. Cores are executed as threads by OpenMP. The Fig. 9 shows the gain obtained by the MNR strategy and the FDTD method. The calculation details of the original method and MNR strategy are given in Table 2. Compared with the original method, the MNR strategy significantly improves computational efficiency, and as the number of nodes increases, the acceleration becomes more obvious.
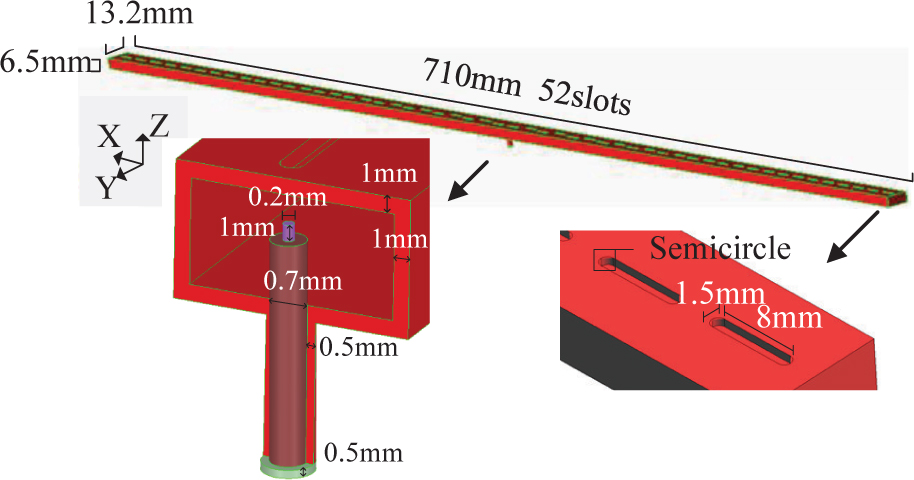
Figure 8: Geometry of the slot antenna.
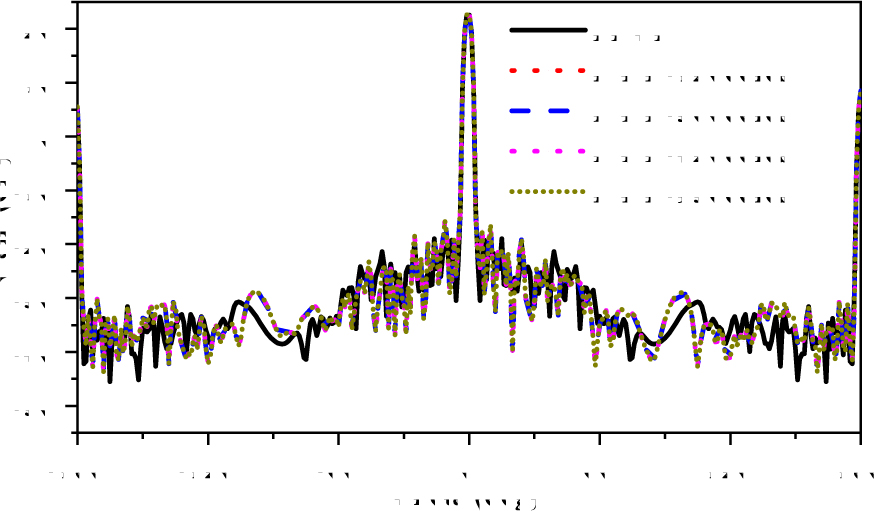
Figure 9: Gain of the slot antenna obtained by the MNR strategy and FDTD method.
Table 2: Computational Performance of the slot antenna
| Number of cores | Time of original (min) | Time of MNR (min) | Speedup |
|---|---|---|---|
| 120 | 143.07 | 136.55 | 1.05 |
| 360 | 56.95 | 47.44 | 1.20 |
| 720 | 34.10 | 24.75 | 1.38 |
| 936 | 29.07 | 19.67 | 1.48 |
To show the performance of MNR strategy on supercomputers, a scatter analysis of an automobile is considered. The analysis of radar scattering can be regarded as a typical case of the electrically large-scale target simulation, similar analysis can be aimed at aircrafts, ships and other targets. The size of the automobile is 5.20 m 1.82 m 1.55 m, for the convenience of calculation, the shell of the car is regarded as PEC, the interior of the car is vacuum, and the tire is non-conductive rubber, which is regarded as microwave absorbing material. The plane wave with frequency of 800 MHz to 1200 MHz illuminates the car from front to back. Waves with this frequency band can attenuate slowly and propagate to distant place. To prove the efficiency of MNR strategy in the case of multiple nodes, this example is simulated by the Sunway TaihuLight supercomputer. The Sunway TaihuLight supercomputer has 4 SW26010 CPU per node and the SW26010 CPU has 65 cores [26].
The model is divided into 3,188,485 tetrahedrons and the LTS-DGTD method simulates this model with 1600 nodes (6400 processors) on the Sunway Taihulight supercomputer. To confirm the accuracy of the proposed method, the results of using and not using MNR strategy are compared and shown in Fig. 10. The normalized electric fields of the automobile from 3 ns to 14 ns obtained by the proposed method are shown in Fig. 11. In order to analyze the performance of MNR strategy, the calculation details are given in Table 3. Its obviously that the MNR strategy reduces the number of roundtrips by 22.3 times and improves the speed of data transmission by 25.1 times, and this result verifies the effectiveness of MNR strategy.
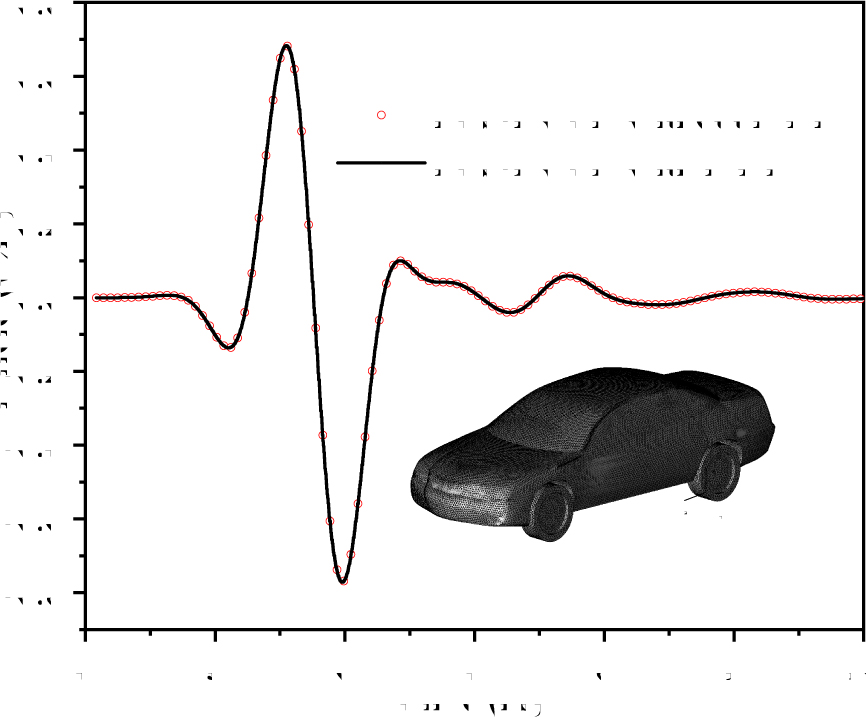
Figure 10: Comparisons of electric field between the LTS-DGTD method with and without the MNR strategy.
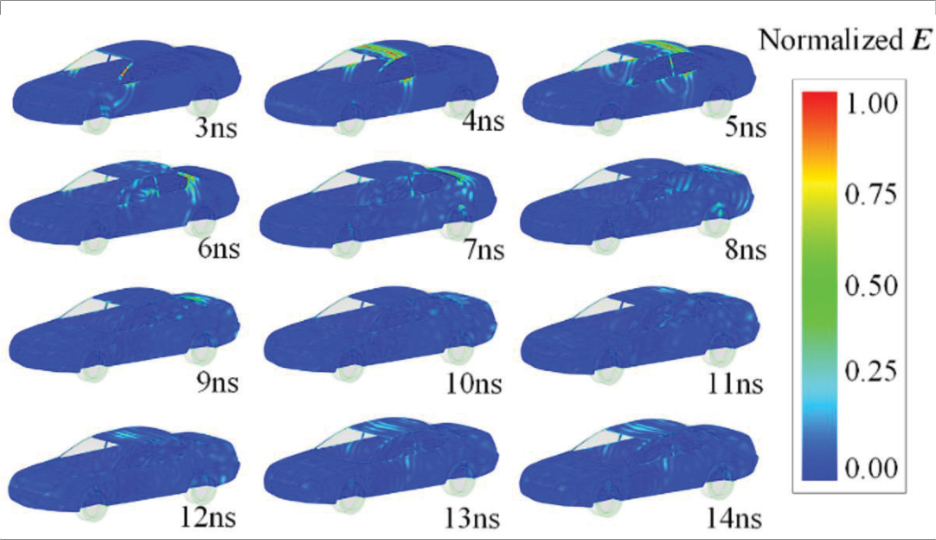
Figure 11: Normalized electric field of the automobile from 3 ns to 14 ns proposed by the LTS-DGTD method with MNR strategy.
Table 3: Computational Performance of automobile
| Method | Number of Roundtrips | Time (s) | Speedup |
|---|---|---|---|
| Original | 7590 | 8895.6 | 1 |
| MNR | 341 | 354.1 | 25.1 |
Slot antenna array always have high working frequency and strongly resonance, its transient characteristic is hard to be simulated by classical numerical method. There a slot antenna array to highlight the validity of the two proposed methods is shown. The array size is 0.34115 m 0.018477 m 0.35456 m and its working frequency band is 15.9 GHz–17.9 GHz, the curved slots make the model have multi-scale characteristics. Absorb boundary condition (ABC) is used to terminate the air box. A modulated Gaussian pulse from 14 GHz to 19 GHz is applied into a coaxial port which loaded at the bottom of the array. The model is divided into 19,320,201 tetrahedrons, whose number of unknowns is 386,404,020. The proposed method partitions the mesh into 5 LTS levels and the time steps are from 0.0243 ps to 1.9683 ps.
Table 4: Computational Performance of automobile
| Number of procs | Number of cores | Time of update (s) | Efficiency |
|---|---|---|---|
| 1600 | 104,000 | 809.5 | 100.0 |
| 3200 | 208,000 | 409.8 | 98.7 |
| 6400 | 416,000 | 225.1 | 89.9 |
| 16000 | 1,040,000 | 109.6 | 73.8 |
The proposed method is excuted with 4000 nodes (4 processors per node) on the new Sunway supercomputer, Fig. 12 shows the normalized directivity of 16GHz provided by measurement and the proposed method in plane yoz, and Fig. 13 shows the 3D directivity of the array and its transient electric fields at 1.5ns, 2ns and 3ns, which is helpful for us to analyze the excitation mode and design of slot antennas. The iteration time and strong scalability efficiency are presented in Table 4. The results show that the proposed method can achieve 73.8% parallel efficiency [24] when extended to 1040000 cores of 16000 processes, which expands the scale of the LTS-DGTD method from hundreds of nodes to tens of thousands of nodes, and can effectively support its operation on modern supercomputers.
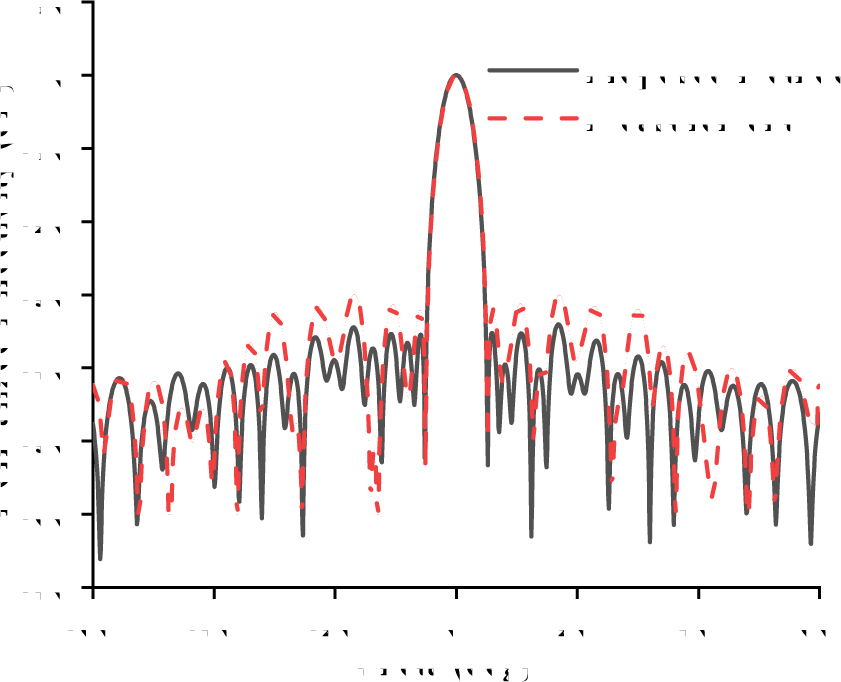
Figure 12: Normalized directivity of slot antenna array in plane yoz.
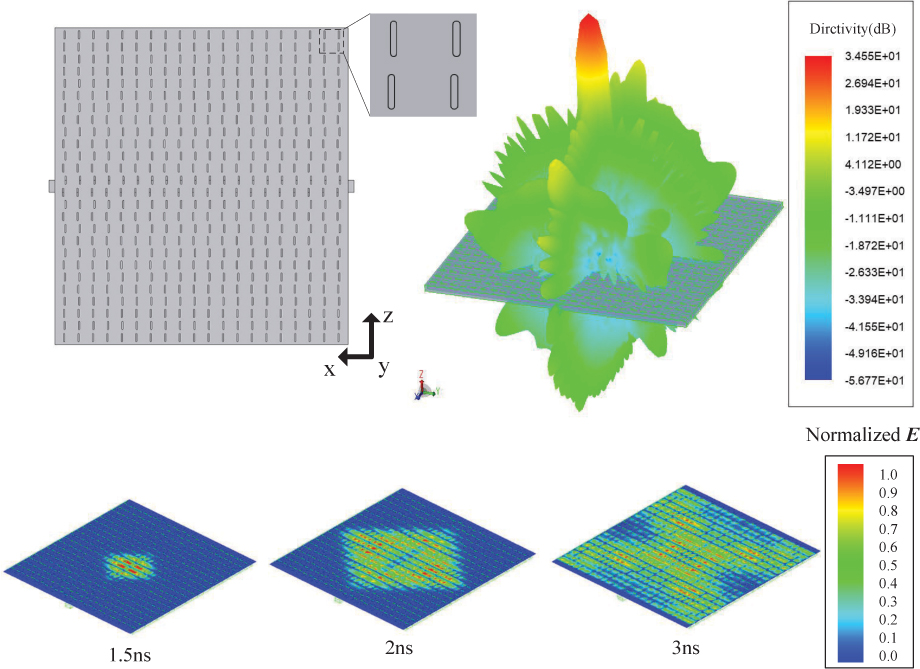
Figure 13: Normalized directivity of slot antenna array in plane yoz.
6 CONCLUSION
In this paper, a high-performance parallelism of the LTS-DGTD method on China’s homegrown Sunway supercomputers is proposed for the transient electromagnetic analysis. The MNR strategy is applied to reduce the communication roundtrip between multi-nodes system for the LTS-DGTD method, and a newly double-buffer strategy is employed to make the communication overlapped computation in CPEs with RMA transmission. Several numerical examples are used to demonstrate the performance and efficiency of the proposed method, which include the transient simulation of automobile, antenna and antenna array with analyzed on the Sunway TaihuLight and the new Sunway supercomputer. Numerical results show the parallel efficiency of the proposed method is 73.8% from 1600 nodes to 16000 nodes, which can be quite important for the application of the LTS-DGTD method in industrial simulation. At the same time, the MNR strategy in the proposed method can also be used on multi-node supercomputers other than Sunway supercomputer.
ACKNOWLEDGMENT
The authors would like to thank Dr. Shugang Jiang from Xidian University for his valuable suggestions for this article. They would also like to appreciate constructive and professional comments from Editors and anonymous reviewers. This work was supported by the National Science Foundation of China (Grant No. 61901323), the Key Research and Development Program of Shaanxi (2021GXLH-02, 2022ZDLGY02-02) and the Fundamental Research Funds for the Central Universities (QTZX22155).
REFERENCES
[1] J. S. Hesthaven and T. Warburton, Nodal Discontinuous Galerkin Methods: Algorithms, Analysis, and Applications, Springer, New York, NY, USA,2022.
[2] E. Montseny, S. Pernet, X. Ferrières, and G. Cohen, “Dissipative terms and local time-stepping improvements in a spatial high order Discontinuous Galerkin scheme for the time-domain Maxwell’s equations,” J Comput. Phys, vol. 227, no. 14, pp. 6795-6820, 2008.
[3] D. Sármány, M. A. Botchev, and J. J. M. Vegt, “Time-integration methods for finite element discretisations of the second-order Maxwell equation,” Computers and Mathematics with Applications, vol. 65 no. 3, pp. 528-543, 2013. https://doi.org/10.1016/j.camwa.2012.05.023
[4] Q. Zhan, Y. Fang, M. Zhuang, M. Yuan, and Q. H. Liu, “Stabilized DG-PSTD method With nonconformal meshes for electromagnetic waves,” IEEE Transactions on Antennas and Propagation, vol. 68, no. 6, pp. 4714-4726, Jun. 2020. https://doi.org/10.1109/TAP.2020.2970036.
[5] Q. Zhan, Y. Wang, Y. Fang, Q. Ren, S. Yang, and W.-Y. Yin, “An adaptive high-order transient algorithm to solve large-scale anisotropic Maxwell’s equations,” IEEE Transactions on Antennas and Propagation, vol. 70, no. 3, pp. 2082-2092, Mar. 2022. https://doi.org/10.1109/TAP.2021.3111639.
[6] J. P. Webb and B. Forgahani, “Hierarchal scalar and vector tetrahedra,” IEEE Transactions on Magnetics, vol. 29, no. 2, pp. 1495-1498, Mar. 1993. https://doi.org/10.1109/20.250686.
[7] P. Li, Y. Shi, L. J. Jiang, and H. Bağcı, “A hybrid time-domain discontinuous Galerkin-boundary integral method for electromagnetic scattering analysis,” IEEE Transactions on Antennas and Propagation, vol. 62, no. 5, pp. 2841-2846, May 2014. https://doi.org/10.1109/TAP.2014.2307294.
[8] H. X. Qi, Y. H. Wang, J. Zhang, X. H. Wang, and J. G. Wang, “Explicit high-order exponential time integrator for discontinuous Galerkin solution of Maxwell’s equations,” Computer Physics Communications, vol. 267, 2021. https://doi.org/10.1016/j.cpc.2021.108080.
[9] X. Li, L. Xu, H. Wang, Z. H. Yang, and B. Li, “A new implicit hybridizable discontinuous Galerkin time-domain method for solving the 3-D electromagnetic problems,” Applied Mathematics Letters, vol. 93, 2019. https://doi.org/10.1016/j.aml.2019.02.004
[10] J. F. Chen and Q. H. Liu, “Discontinuous Galerkin time-domain methods for multiscale electromagnetic simulations: A review,” Proc. IEEE, vol. 101, no. 2, pp. 242-254, Feb. 2013.
[11] J. M. Jin, Theory and Computation of Electromagnetic Fields, Wiley-IEEE Press, USA, 2010.
[12] L. Raphaël, V. Jonathan, D. Clément, S. Claire, and L. Stéphane, “A parallel non-conforming multielement DGTD method for the simulation of electromagnetic wave interaction with metallic nanoparticles,” Journal of Computational and Applied Mathematics, vol. 270, pp. 330-342, 2014. https://doi.org/10.1016/j.cam.2013.12.042
[13] S. Dosopoulos, J. D. Gardiner, and J. F. Lee, “An MPI/GPU parallelization of an interior penalty discontinuous Galerkin time domain method for Maxwell’s equations,” Radio Science,2011.
[14] H. H. Zhang, P. P. Wang, L. J. Jiang, W. Sha, M. S. Tong, Y. Liu, W. Wu, and G. Shi, “Parallel higher order DGTD and FETD for transient electromagnetic-circuital-thermal co-simulation,” IEEE Transactions on Microwave Theory and Techniques, vol. 70, no. 6, pp. 1, 2022. https://doi.org/10.1109/TMTT.2022.3164703
[15] P. Li, D. R. Chakrabarti, C. Ding, and L. Yuan, “Adaptive software caching for efcient NVRAM data persistence,” 2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pp. 112-122, 2017.
[16] K. Zhang, “The research and application of memory access optimization on heterogeneous multi-core platforms (in Chinese),” Dissertation, University of Science and Technology, Beijing,2018.
[17] H. Bai, C. Hu, X. He, B. Zhang, and J. Wang, “Crystal MD: Molecular dynamic simulation software for metal with BCC structure,” Big Data Technology and Applications, Springer, Singapore, pp. 247-258, 2017.
[18] D. Feng, S. Liu, X. Wang, X. Y. Wang, and G. Li, “High-order GPU-DGTD method based on unstructured grids for GPR simulation,” Journal of Applied Geophysics, vol. 202, 2022. https://doi.org/10.1016/j.jappgeo.2022.104666
[19] Z. G. Ban, Y. Shi, and P. Wang, “Advanced parallelism of DGTD method with local time stepping based on novel MPI + MPI unified parallel algorithm,” IEEE Transactions on Antennas and Propagation, vol. 70, no. 5, pp. 3916-3921, 2022. https://doi.org/10.1109/TAP.2021.3137455
[20] H. T. Mengand and J. M. Jin, “Acceleration of the dual-field domain decomposition algorithm using MPI–CUDA on large-scale computing systems,” IEEE Transactions on Antennas and Propagation, vol. 62, no. 9, pp. 4706-4715, 2014. https://doi.org/10.1109/TAP.2014.2330608
[21] G. Chen G, L. Zhao, and W. H. Yu, “A novel acceleration method for DGTD algorithm on sunway TaihuLight,” 2018 IEEE Asia-Pacific Conference on Antennas and Propagation (APCAP), Auckland, New Zealand, 2018. https://doi.org/0.1109/APCAP.2018.8538209
[22] J. Dongarra, “Sunway TaihuLight supercomputer makes its appearance,” Natl Sci Rev., vol. 3, no. 3, pp. 265-266, 2019.
[23] Z. Xu, J. Lin, and S. Matsuoka, “Benchmarking SW26010 many-core processor,” IEEE International Parallel and Distributed Processing Symposium Workshops, 2017.
[24] Z. Xu, J. Lin, and S. Matsuoka, “The compiling system user guide of Sunway TighthuLight,” National Super-computing Wuxi Center, Wuxi, 2016.
[25] Y. Yu, H. An, J. Chen, W. Liang, Q. Xu, and Y. Chen, “Pipelining computation and optimization strategies for scaling gromacs on the Sunway many-core processor,” Algorithms and Architectures for Parallel Processing, vol. 10393, pp. 18-32, 2017.
[26] D. X. Chen and X. Liu, “Parallel programming andoptimization of Sunway Taihulight supercomputer (in Chinese),” National Super-computing Wuxi Center, Wuxi, 2017.
[27] J. Gu, J. W. Feng, X. Y. Hao, T. Fang, C. Zhao, H. An, J. Chen, M. Xu, J. Li, W. Han, C. Yang, F. Li, and D. Chen, “Establishing a non-hydrostatic global atmospheric modeling system at 3-km horizontal resolution with aerosol feedbacks on the Sunway supercomputer of China,” Science Bulletin, vol. 67, no. 11, pp. 1170-1181, 2022. https://doi.org/10.1016/j.scib.2022.03.009
[28] M. Dun, Y. C. Li, Q. X. Sun, H. L. Yang, W. Li, Z. Luan, L. Gan, G. Yang, and D. Qian, “Towards efficient canonical polyadic decomposition on sunway many-core processor,” Information Sciences, vol. 549, pp. 221-248, 2021. https://doi.org/10.1016/j.ins.2020.11.013
[29] R. Berger, S. Dubuisson, and C. Gonzales, “Fast multiple histogram computation using Kruskal’s algorithm,” 2012 19th IEEE International Conference on Image Processing, 2012. https://doi.org/10.1109/ICIP.2012.6467374
BIOGRAPHIES

Minxuan Li was born in Changzhi, Shanxi, China, in 1994. He received the B.S. degree in electronic information engineering from Harbin Institute of Technology, Weihai, China in 2016. He is currently pursuing the Ph.D. degree with Xidian University, Xi’an, China. His current research interests include parallel computation and transient electromagneticanalysis.

Qingkai Wu was born in Yangzhou, Zhejiang, China, in 1997. He received the B.S. degree in electronic science and technology from Xidian University, Xi’an, China in 2020. He is currently pursuing the Ph.D. degree with Xidian University, Xi’an, China. His current research interests include transient electromagneticanalysis.

Zhongchao Lin was born in Hubei, China, in 1988. He received the B.S. and Ph.D. degrees from Xidian University, Xi’an, China, in 2011 and 2016, respectively. He joined Xidian University, in 2016, as a Post Doctoral Fellow, where he was lately promoted as an Associate Professor. His research interests include large-scale computational electromagnetic, scattering, and radiation electromagnetic analysis.

Yu Zhang received the B.S., M.S., and Ph.D. degrees from Xidian University, Xi’an, China, in 1999, 2002, and 2004, respectively. In 2004, he joined Xidian University as a Faculty Member. He was a Visiting Scholar and an Adjunct Professor with Syracuse University, from 2006 to 2009. As a Principal Investigator, he works on projects, including the Project of NSFC. He has authored four books Parallel Computation in Electromagnetics (Xidian University Press, 2006), Parallel Solution of Integral Equation-Based EM Problems in the Frequency Domain (Wiley IEEE, 2009), Time and Frequency Domain Solutions of EM Problems Using Integral Equations and a Hybrid Methodology (Wiley, 2010), and Higher Order Basis Based Integral Equation Solver (Wiley, 2012), as well as more than 100 journal articles and 40 conference papers.

Xunwang Zhao was born in Shanxi, China, in 1983. He received the B.S. and Ph.D. degrees from Xidian University, Xi’an, China, in 2004 and 2008, respectively. He joined Xidian University, in 2008, as a Faculty Member, where he was lately promoted as a Full Professor. He was a Visiting Scholar with Syracuse University, Syracuse, NY, USA, from December 2008 to April 2009. As a Principal Inves tigator, he works on several projects, including the project of NSFC. His research interests include computational electromagnetic and electromagnetic scattering analysis.
ACES JOURNAL, Vol. 37, No. 7, 795–804.
doi: 10.13052/2022.ACES.J.370706
© 2022 River Publishers