A Pre-splitting Green’s Function based Hybrid Fast Algorithmfor Multiscale Problems
Guang-Yu Zhu, Wei-Dong Li, Wei E. I. Sha, Hou-Xing Zhou, and Wei Hong
1College of Information Science and Electronic Engineering
Zhejiang University, Hangzhou, 310027, China
gyzhu_china@163.com
2State Key Laboratory of Millimeter Waves
Frontiers Science Center for Mobile Information Communication and Security
Southeast University, Nanjing, 210096, China
Submitted On: February 19, 2023; Accepted On: July 26, 2023
ABSTRACT
Based on the splitting form of the Green’s function, a hybrid fast algorithm is proposed for efficient analysis of multiscale problems. In this algorithm, the Green’s function is a priori split into two parts: a spectrally band-limited part and a spatially localized part. Then, the fast Fourier transforms (FFT) utilizing the global Cartesian grid and the matrix compression method aided by an adaptive octree grouping are implemented for these two parts, respectively. Compared with the traditional methods which only employ the FFT for acceleration, the proposed hybrid fast algorithm is capable of maintaining low memory consumption in multiscale problems without compromising time cost. Moreover, the proposed algorithm does not need cumbersome geometric treatment to implement the hybridization, and can be established in a concise and straightforward manner. Several numerical examples discretized with multiscale meshes are provided to demonstrate the computational performance of proposed hybrid fast algorithm.
Index Terms: Fast algorithm, fast Fourier transform, Green’s function, matrix compression, multiscale problems.
I. INTRODUCTION
Many real-world electromagnetic (EM) problems require multiscale discretization [1, 2, 3, 4]. When the method of moments (MoM) [5], along with classical fast algorithms, is used to model the multi-scale problems, a single fast algorithm [6, 7, 8, 9, 10, 11, 12] is often insufficient to achieve satisfactory computational performance. Instead, due to capturing both the circuit physics and wave physics [1], hybrid fast algorithms [19, 20, 21, 22] generally provide a more practical path to efficiently solve EM multiscale problems.
As we know, the multilevel fast multipole algorithm (MLFMA) is widely used for efficient simulation of electrically large problems [6, 7, 8]. However, the MLFMA encounters the sub-wavelength breakdown [8] when dense mesh occurs. As a remedy, low-frequency fast algorithms [23, 24] were studied. Correspondingly, a series of hybrid algorithms were developed [25, 26, 27, 28, 29, 30], such as mixed-form FMA [19], interpolative decomposition (ID)-MLFMA [20], and adaptive cross approximation (ACA)-MLFMA [21].
Different from the MLFMA, the pre-correction-fast Fourier transforms (FFT)-based methods [9, 10, 11, 12, 13, 14, 15, 16, 17, 18] (e.g., adaptive integral method (AIM) [9], pre-corrected FFT (P-FFT) [10], and integral equation FFT (IE-FFT) [11]) are free from the sub-wavelength breakdown. Nevertheless, due to the intrinsic uniformity of the global Cartesian grids, the pre-correction-FFT-based methods do not allow for sufficient and varying spatial resolutions to handle multiscale discretizations. That is, by simply tuning the grid spacing, it is hard to achieve high computational efficiency for far interactions and maintain low storage efficiency for the near matrix at the same time [31].
Recently, in order to overcome this shortcoming of the pre-correction-FFT-based methods, a hybrid fast algorithm was developed in [31]. In this algorithm, the pre-correction-FFT-based methods is augmented with the matrix compression method (ACA) [36, 37, 38]. However, to implement such a hybridization, the procedures are not as straightforward as they seem [31]. In particular, a complicated spatial grouping strategy is inherently needed, and the relations between the required auxiliary geometric data structures (such as the Cartesian grid, the expansion box, and the tree-cube) are complex and require cautious treatments [31]. Such a situation motivates us to reconsider the overall framework of the pre-correction-FFT-based methods and wonder if there exists a more elegant way to develop a hybrid algorithm that consists of both the FFT and the matrix compression methods(e.g., ACA).
As an interesting alternative of the well-studied pre-correction-FFT-based methods, some pre-splitting-FFT-based method was developed in [32, 33]. Basically, the pre-splitting-FFT-based method bears similarities with the well-known pre-correction-FFT-based methods, since it also uses the Cartesian grid and the FFT as the essentials for the acceleration of the spatial convolutions. However, different from the widely-used pre-correction-FFT-based methods which typically utilize the Cartesian grid-based near-field corrections (based on some local expansion boxes) to compensate for the near-field contributions, the pre-splitting-FFT-based method [32, 33] instead resorts to some splitting form of the Green’s function so as to realize accurate and efficient computations. Despite of its unique feature, this pre-splitting-based framework has not attracted enough attentions in the computational electromagnetics (CEM) community, and a hybrid fast algorithm based on such framework has never been explored yet.
In this work, based on the splitting form of the Green’s function, a hybrid fast algorithm is proposed for efficiently analyzing multiscale problems. Specifically, the pre-splitting-FFT-based method originally devised for the problems with quasi-uniform discretizations is here further enhanced with the matrix compression method (ACA). Thus, a hybrid fast algorithm using both the FFT and the matrix compression method is established. In particular, the proposed hybrid fast algorithm is capable of maintaining low memory consumption in multiscale problems without compromising time cost, thus manifesting itself as a favorable multiscale extension of the pure FFT-based method. Furthermore, the required auxiliary geometric data structures herein (including the Cartesian grid and the spatial grouping octree) can be constructed independent of each other, and are not intertwined as in [31]. Consequently, the proposed hybrid algorithm can be implemented in a straightforward manner without any cumbersome geometric treatment.
In the following, after introducing the basic formulations and implementation key points in Section 2, several numerical examples discretized with multiscale meshes are then provided in Section 3 to demonstrate the computational performances of the proposed hybrid fast algorithm for multiscale problems.
II. FORMULATION
A perfectly electric conductor (PEC) object illuminated by an incident plane wave is considered. The combined field integral equation (CFIE) is employed to model this typical electromagnetic scattering problem. Throughout the paper, we use to denote the wavelength in free space. Moreover, we use and to denote the wave number and the wave impedance in free space, respectively.
A. Combined field integral equation
The CFIE is the linear combination of the electric field integral equation (EFIE) and the magnetic field integral equation (MFIE), which is conventionally expressed as
| (1) |
where denotes the combination factor and , the EFIE is formulated as
| (2) |
and the MFIE is formulated as
| (3) |
In the above, and are the incident electric field and the incident magnetic field, respectively. Moreover, denotes the Green’s function with the field point r and the source point . Furthermore, denotes the surface current.
By using the method of moments (MoM) [5] with the RWG function [39], the CFIE can be discretized into a matrix equation
| (4) |
where Z is the impedance matrix, I is the unknown surface current coefficients vector, V is the righthand side vector of the incident field, and is the number of unknowns. More specifically, the impedance matrix Z corresponding to the CFIE is described by
| (5) |
where
| (6) |
and
| (7) |
In the above, and . Moreover, and denote the th and th RWG functions, respectively. Furthermore, and are the supports of the corresponding RWG functions, respectively.
B. Pre-splitting the Green’s function
In the following, the splitting forms of the Green’s function and its gradient are introduced. First, consider the Green’s function in the EFIE, namely
| (8) |
where
| (9) |
denotes the distance between the field point and the source point . Clearly, the above can also be equivalently represented as
| (10) |
where
| (11) |
| (12) |
A basic property of is that, this function is singular for , and its magnitude is globally nonzero for . Also, note that the singular behavior of comes from .
Using the pre-splitting strategy [32, 33], the Green’s function (8) can be written as two parts, namely
| (13) |
where
| (14) |
| (15) |
with being a splitting threshold, and being some auxiliary function. Particularly, the above two parts manifest the following properties.
• Function is a singular and spatially localized function.
It has nonzero function value only when , and for .
• Function is a globally oscillatory and spectrally band-limited function.
It is smooth and bounded for and .
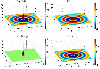
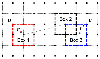
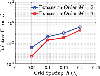
To have more intuitive understanding on the properties of function and , the corresponding function images are shown in Fig. 1.
Moreover, from a physical and spectral perspective, mainly captures the evanescent waves, and mainly captures the propagating waves.
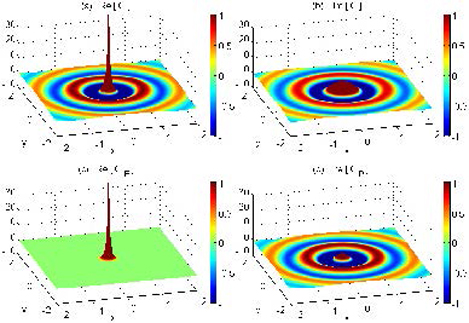
Figure 1: The Green’s function is a priori split into a singular but spatially localized part and a globally oscillatory but spectrally band-limited part . The relevant magnitudes of the original Green’s function and of these two parts are visualized in the figure.
To achieve the above splitting and corresponding properties, the auxiliary function is specially designed and one simple way is to choose to be a polynomial of the following form [32, 33]
| (16) |
where , , and are unknown coefficients. Clearly, the above is a three order polynomial without the linear term, and it implies
| (17) |
meaning that the first order derivative function of is zero at (where ).
Given the splitting threshold , the coefficients in (16) can be determined by some continuity conditions at as follows
| (18) |
or, by solving the following matrix equation
| (19) |
The derivative functions of used in the above are given in the appendix. Thus, after is obtained, the splitting representation (13) is completely determined.
The polynomial choice (16), the implicit continuity condition (17), and the explicit continuity condition (18) are based on the consideration that, after the splitting, the resultant (or, more precisely, ) should be smooth everywhere for and , so that it can be interpolated accurately without much difficulty (the interpolation procedures will be discussed in the next subsection).
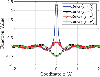
To make it more clear, without loss of generality, consider the following representative situation. The source point is fixed to the coordinate origin, and the field point r is moving along the axis. Then, the corresponding function values of and are evaluated, as shown in Fig. 3. We can clearly see that is singular when r approaches , while is continuous and smooth everywhere. Here, is smooth at (where ) as a result of (17), and smooth at the splitting point as a result of (18).
Next, consider the gradient of the Green’s function in the MFIE, namely
| (20) |
with
| (21) |
where
| (22) |
| (23) |
and
| (24) |
Similar to (8), function is singular for , and its magnitude is globally nonzero for . Also, note that the singular behavior of comes from .
Again, using the pre-splitting strategy [32, 33], the gradient Green’s function (20) can be written as two parts, namely
| (25) |
where
| (26) |
| (27) |
with being the splitting threshold, and being some auxiliary function.
Here, the following auxiliary function is used to achieve the desired splitting, namely
| (28) |
Note that, different from (16), the above is a three order polynomial without the constant term, and it implies
| (29) |
which clearly means that the function value of is zero at (where ).
Given the splitting threshold , the coefficients in (28) can be determined by some continuity conditions at as follows
| (30) |
or, by solving the following matrix equation
| (31) |
The derivative functions of used in the above are given in the appendix. Thus, after is obtained, the splitting representation (25) is completely determined.
Similar as before, (28), (29), and (30) are based on the consideration that, after the splitting, the resultant (or, more precisely, each Cartesian component , ) should be smooth everywhere for and , so that it can be interpolated accurately without much difficulty.
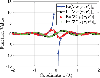
To make it more clear, consider the representative situation of and r as before. Then, the corresponding function values of and are evaluated, as shown in Fig. 4. Here, is smooth at (where ) as a result of (29), and smooth at the splitting point as a result of (30).
Note that the auxiliary function (28) chosen for the splitting of () is different from the auxiliary function (16) chosen for the splitting of . Such difference is due to the fact that, unlike , () manifest different (i.e., positive or negative) singular behaviors when r approaches along different directions (e.g., along or direction), which can be deduced from the definition of (24), or, more intuitively, observed from Fig. 3 and Fig. 4.
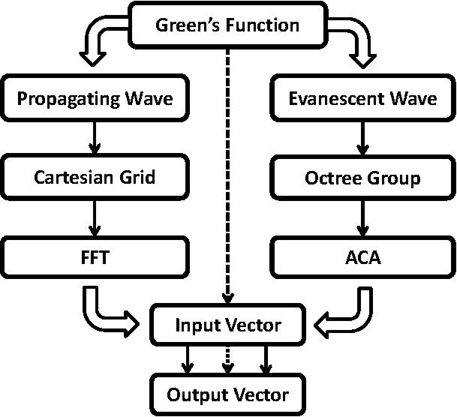
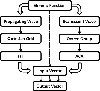
Figure 2: Systematic diagram of the flow chart and relevant key elements of the presented hybrid fast algorithm. Particularly, the two auxiliary geometric data structures, including the Cartesian grid and the octree grouping, can be constructed independently.
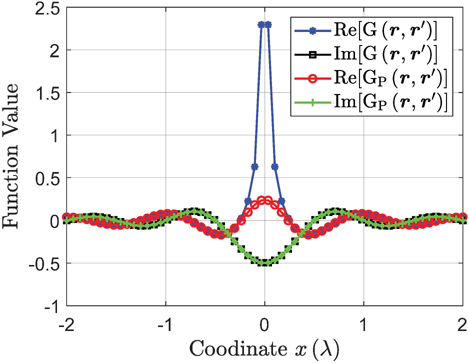
Figure 3: The function values of and . The source point is fixed to the coordinate origin, and the field point r is moving along the axis.
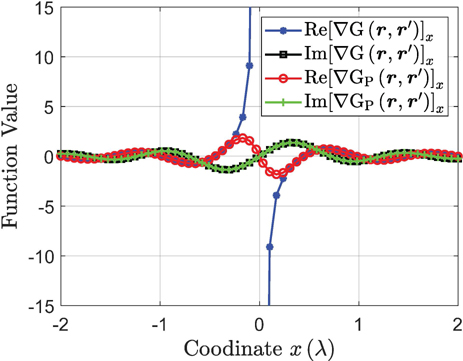
Figure 4: The function values of and . The source point is fixed to the coordinate origin, and the field point r is moving along the axis.
With the splitting form of the Green’s function (13) and its gradient (25), the impedance matrix can be correspondingly split into two parts, yielding
| (32) |
where is related to and , while is related to and . For convenience, and are termed here as the evanescent matrix and the propagating matrix, respectively. When the commonly-used Krylov subspace iterative method [35] is employed to solve the matrix equation (4), the matrix-vector product is computed. Using the splitting representation (32), this product can be equivalently implemented as
| (33) |
As will be shown in the following subsections, by fully exploiting the properties of the splitting form of the Green’s function and its gradient, both and can be evaluated in an efficient manner. For clarity, before going into further discussion, basic concepts and key elements of the presented hybrid fast algorithm are illustrated in Fig. 2.
C. Propagating matrix calculation
Due to the unique properties (smoothness and translation invariance) of and , the matrix-vector product can be calculated accurately and efficiently, with the aid of proper interpolation and theFFT.
To this end, some auxiliary geometric data structures need to be defined first. Specifically, the object considered is enclosed by a three dimensional (3D) rectangular bounding box. Then, this bounding box is subdivided regularly along each Cartesian dimension, yielding a cluster of global Cartesian grids [9, 10, 11, 12, 13, 14]. The grid spacings along these Cartesian dimensions are here denoted by , , , respectively. The number of grids along these Cartesian dimensions are denoted by , , , respectively. Thus, a total of Cartesian grids are defined.
Recall that and obtained from the splitting process are smooth everywhere for and . Thus, they can be well approximated using the following Cartesian grid-based sampling expansions
| (34) |
| (35) |
for and , where and denote the corresponding local expansion boxes that enclose r and , respectively. Note that, depending on the relative position between r and , and can be either well-separated or overlapping, as illustrated in Fig. 5. Moreover, u and v denote the coordinates of the Cartesian grids related to and , respectively. Furthermore, (or ) denotes the 3D Lagrange interpolation basis function based on the Cartesian grids of (or ), which is defined concretely by
| (36) |
where
| (37) |
with being the expansion order and being the coordinates of the Cartesian grids involved. Clearly, when , a total of Cartesian grids are involved in (36).
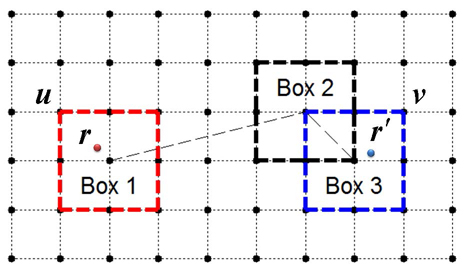
Figure 5: Computation corresponding to the propagating matrix can be accelerated by the FFT using the Global Cartesian grid and the local expansion boxes. Typical examples of the expansion boxes are illustrated using different colors. Here, Box 1 and Box 2 are well-separated, while Box 2 and Box 3 are overlapping.
With the expansions (34) and (35), can be correspondingly rewritten as
| (38) |
where and are triple block Toeplitz matrices of dimension . Moreover, , , and are sparse matrices of dimension , defined concretely by
| (39) |
| (40) |
| (41) |
Exploiting the block Toeplitz structure of and , the matrix-vector product can then be evaluated efficiently by the FFT as follows
| (42) |
where and denote the forward and inverse FFT.
Notably, in the conventional pre-correction-based framework [9, 10, 11, 12, 13], the original Green’s function is approximated with the grid-based sampling expansion. Differently, for the pre-splitting-based framework [32, 33] adopted herein, the function is instead approximated with the grid-based sampling expansion, as in (34). Since is smooth everywhere without singularity, it is possible to approximate with sufficiently good accuracy for arbitrary r and by proper interpolation. Consequently, unlike [9, 10, 11, 12, 13, 31], the Cartesian grid-based near-field corrections are not necessary here.
D. Evanescent matrix calculation
Referring to (14) and (26), we know that , dominated by and , has nonzero elements only when . Therefore, with quasi-uniform meshes, is a typical sparse matrix with few nonzero elements, and thus it can be stored without much effort. However, in multiscale problems, dense mesh always occurs. Thus, near-field interactions within increase substantially. In this case, the nonzero elements of will increase dramatically.
Fortunately, in the pre-splitting-based framework adopted, this difficulty can be trivially addressed. In a nut shell, we first construct a spatial grouping only based on the geometric position of the basis functions, and then apply the matrix compression methods based on such a grouping to achieve memory reductions of .
Here, a standard adaptive octree is utilized for accomplishing the spatial grouping, and the basic procedures for its construction are outlined as follows.
1. A root cube enclosing the whole object is constructed.
2. The nonempty cubes are subdivided into eight sub-cubes recursively until the number of basis functions within each cube is smaller than a prescribed constant.
3. An octree is built when the process finishes.
Accordingly, several concepts related to the octree are then defined as follows.
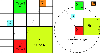
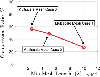
•Those cubes that do not need to be further subdivided are called leaf cubes. Here, the leaf cubes are denoted by , with being the index of some leaf cube. It should be noted that not all of the leaf cubes are located at the same octree level. Typical examples of the leaf cubes are shown in Fig. 6 and are highlighted with colors.
• Two leaf cubes (e.g., and ) are called neighbor cubes if they share at least one vertex, such as Cube 1 and Cube 5; otherwise, they are called well-separated cubes, such as Cube 1 and Cube 3. For convenience, we use to denote that two cubes are neighbor cubes, and use to denote that two cubes are well-separated cubes.
Note that, in [31], the conventional octree grouping cannot be directly applied, and a more involved grouping scheme is developed, in which the cubes for grouping the basis functions are induced from the Cartesian grids. In contrast, here the basis function grouping does not have to be dependent on the Cartesian grids, and can be implemented independently and conventionally. In other words, the commonly-used adaptive octree can be directly employed to achieve the required groupings, and the treatments of the required auxiliary geometric data structures herein are thus simple and straightforward.
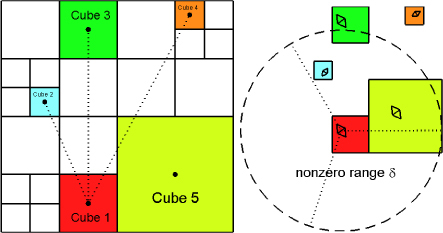
Figure 6: The storage of is effectively compressed by using the spatial grouping octree and the matrix compression method. Illustration of the octree grouping is shown in the left subfigure, where some leaf cubes are highlighted using colors. Here, Cube 5 is neighbor cube of Cube 1, while Cube 2, Cube 3, Cube 4 are all well-separated cubes of Cube 1. Besides, the nonzero range of , characterized by , is illustrated in the right subfigure. Note that the establishment of the grouping and the application of the compression can be realized independent of the Cartesian grids and the FFT.
On the basis of the spatial groupings above, can then be rewritten as
| (43) |
where
• denote those matrix subblocks corresponding to the interactions between neighbor cubes. They are directly computed and stored.
• denote those matrix subblocks corresponding to the interactions between well-separated cubes. These matrix subblocks can be low-rank. They can be compressed and stored in a compact form.
Here, the ACA [36, 37, 38] is employed for accomplishing the matrix compression. Detailed procedures of the ACA can be found in, for example, [37, 38]. Correspondingly, can be then factorized as
| (44) |
Thus, the matrix-vector product can be calculated as
| (45) |
Some implementation details for the compression of are further clarified as follows. In particular, as shown in Fig. 6, due to the localized nature of decided by , for a basis function in Cube 1, all the basis functions in Cube 2 have full interactions with , while all the basis functions in Cube 4 have zero interactions with . Meanwhile, only parts of the basis functions in Cube 3 and Cube 5 have nonzero interactions with . Hence, for two well separated groups with index sets s and t, only the submatrices representing nonzero interactions is to be compressed. Thus, the matrix which represents the interactions between the two groups is in fact described more precisely by
| (46) |
with subsets and . Here, and are permutation matrices, denotes the matrix subblock corresponding to nonzero interactions. Note that, depending on the relative position between the two cubes considered, there can be many zero interactions in , due to the sparsity pattern of . Therefore, the matrix compression is in fact applied to rather than , and we have
| (47) |
where and denote the sizes of index sets and , respectively. Meanwhile, the dimension of the matrix is , and the dimension of the matrix is . Here, denotes the compression rank of for a given tolerance. Ultimately, the compressed matrices and in (47) are stored, and are applied to the surface current vector I in an efficient manner. For many practical problems that involve multiscale discretization, the matrix block can be effectively compressed, and the memory consumption for and are greatly reduced compared to that for .
III. NUMERICAL RESULTS
In this section, the computational performance of the proposed hybrid algorithm is demonstrated through several numerical examples. The conjugate gradient method (CG) [35] is used as the iterative solver, and the tolerance is set to 1.0E-3. The diagonal preconditioner is used to improve the convergence. Unless otherwise stated, the grid spacings (i.e., , , ) for the FFT acceleration are by default set to the common value 0.1 , and the expansion orders (i.e., , , ) are by default set to the common value . Furthermore, the well-known FFTW [34] is used to perform the FFT. For clarity, in the following, the traditional pre-splitting-FFT-based algorithm which employs the uncompressed will be termed as the PSG-FFT algorithm, and the proposed hybrid fast algorithm (enhanced with the ACA) will be referred to as the PSG-FFT-ACA algorithm.
A. Sphere
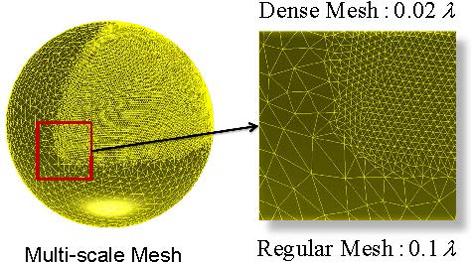
Figure 7: Mesh configurations of the PEC sphere. The radius of the sphere is 1.0 . Here, about a quarter of the spherical surface is discretized with a relatively dense mesh of 0.02 , and the rest of the surface is discretized with a regular mesh of 0.1 . For clarity, the enlarged view of the multiscale mesh is also visualized in the above.
A PEC sphere of radius 1.0 is first considered. The surface of the sphere is discretized with multiscale triangular meshes, resulting in 34,764 RWG functions. In particular, as shown in Fig. 7, about a quarter of the surface is discretized with dense meshes of edge lengths about 0.02 , and the rest is discretized with regular meshes of edge lengths about 0.1 .
For this example, the standard MoM (without using any acceleration technique), the traditional PSG-FFT algorithm, and the proposed PSG-FFT-ACA algorithm are adopted as the the solution methods. After solving the corresponding matrix equations as formulated in (4), the surface current coefficients (i.e, the solutions of equation (4)) , , and are then obtained, respectively. Here, it should be noticed that both and depend on the choice of the pre-splitting threshold . However, when the standard MoM is used, is not involved, and is therefore independent of . Thus, the solution can be used as a proper reference, to evaluate the accuracy of and for varying . The relative errors of the surface current coefficients are defined as follows
| (48) |
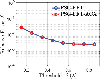
where denotes the surface current coefficients to be tested, denotes some specified surface current coefficients to be used as the reference, and denotes the 2-norm of vector. Based on (48), the relative errors of both the traditional PSG-FFT algorithm and the proposed PSG-FFT-ACA algorithm for several different are calculated and shown in Fig. 8. We can see that both algorithms can achieve accurate results and show similar accuracy level. In particular, within the range of the between 0.15 and 0.65 , the errors of both algorithms decrease with increasing . Furthermore, the accuracies of both algorithms are not strongly sensitive with respect to the considered.
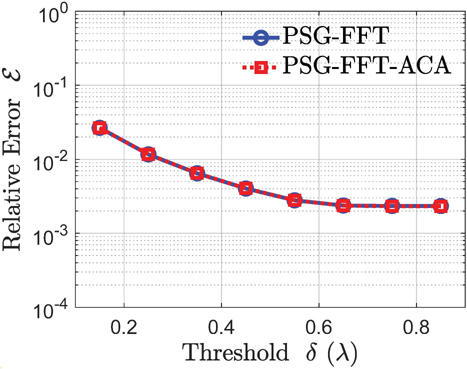
Figure 8: Relative errors of the surface currents coefficients I with respect to different splitting threshold . The relative errors of both the traditional PSG-FFT algorithm and the proposed PSG-FFT-ACA algorithm are illustrated. The surface currents coefficients obtained using the standard MoM are used as the reference.
In the following, the choice of is discussed. In principle, can be of any value. However, in practice, a moderate value of is suggested, due to the following considerations.
• If is chosen be relatively large, the number of nonzero elements of the evanescent matrix will then become relatively large. Clearly, in this case, the corresponding computational cost will increase. In Table 1, the computational costs with respect to are recorded. It can be observed that the time and memory consumptions of both the traditional PSG-FFT algorithm and the proposed PSG-FFT-ACA algorithm increase as increase. Hence, due to efficiency considerations, is not suggested to be too large.
• If is chosen to be relatively small, the number of nonzero elements of the evanescent matrix will become relatively small, and the computational cost is correspondingly reduced. However, from Fig. 8, it is observed that the accuracy of the solution is slightly reduced when becomes smaller. Hence, due to accuracy considerations, is not suggested to be too small as well.
Based on the above considerations, the between 0.15 and 0.65 can be proper choice. In practice, by tuning the splitting threshold within this range, we can trade off between accuracy and computational cost.
Table 1: Time and memory for the sphere model with different splitting threshold
| PSG-FFT | PSG-FFT-ACA | |||
|---|---|---|---|---|
| Memory (GB) | CPU Time | Memory (GB) | CPU Time | |
| 0.9924 | 0.6601 | 0.9917 | 0.7087 | |
| 1.9707 | 0.8078 | 1.6581 | 0.8167 | |
| 3.1454 | 1.1445 | 2.2623 | 0.8679 | |
| 4.6662 | 1.2814 | 2.9167 | 0.9177 | |
| 6.3642 | 2.0607 | 3.5851 | 0.9812 | |
| 8.3831 | 1.8004 | 4.2083 | 1.0390 | |
| 10.514 | 2.1802 | 4.3177 | 1.0939 | |
| 11.528 | 2.4548 | 5.1668 | 1.2197 | |
Besides, the well-studied IE-FFT algorithm [17], being a typical instance of the pre-correction-based methods, is also used to calculate this example. Similar to the configurations of the pre-splitting-based methods employed, the grid spacing for the IE-FFT is set to 0.1 and the expansion order is set to 3. Then, using as the reference, the relative error of the obtained surface current coefficients is calculated, which is 2.96E-3. Referring to Fig. 8, we can see that such error is close to the error of the PSG-FFT(-ACA) algorithm with about 0.45 . Moreover, for the IE-FFT algorithm, the memory requirement is G and the CPU time required is m. Referring to Table 1, we can see that such cost is slightly lower than that of the PSG-FFT algorithm with about 0.45 . From the above numerical results, it can be known that the computational performance of the IE-FFT algorithm during the solution stage is slightly better than that of the PSG-FFT algorithm. However, it should be emphasized that such slight advantage of the IE-FFT algorithm is at the price of the additional grid-based numerical correction operations during the setup (precomputation) stage.
B. Monopole antenna on top of large platform
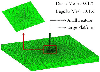
In the following, a more realistic example is considered, i.e., a monopole antenna on top of a large platform, as shown in Fig. 9. Clearly, this is a typical multiscale structure and often encountered in many practical scenarios. The width and height of the platform are 4.0 and 0.3 , respectively. Moreover, the width and height of the monopole antenna are 0.06 and 0.6 , respectively. The object surface is discretized with the multiscale triangular meshes. Specifically, the monopole antenna is discretized with meshes of edge length about 0.01 , while the large platform is discretized with meshes of edge length about 0.1 . With such mesh, a total of 24,807 RWG functions are generated.
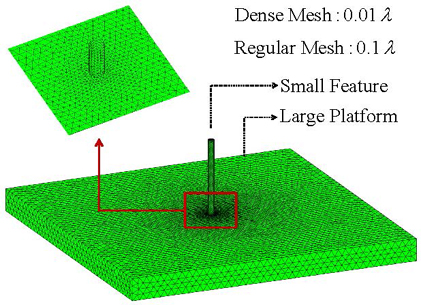
Figure 9: Mesh configurations of a small monopole antenna on top of a large platform. A multiscale mesh is used to discretize this object. The monopole antenna is discretized using dense mesh of about 0.01 , while the large platform is discretized with regular mesh ofabout 0.1 .
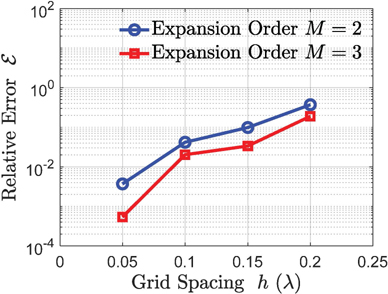
Figure 10: Relative errors of the surface currents coefficients with respect to different grid spacings and expansion orders . The relative errors of the proposed PSG-FFT-ACA algorithm are illustrated. The surface currents coefficients obtained using the standard MoM are used as the reference.
The standard MoM and the proposed PSG-FFT-ACA algorithm are employed to calculate this example. Here, the pre-splitting threshold is chosen to be 0.35 . Using as the reference, the relative errors of are calculated for different grid spacings and different expansion orders . For clarity, the relative errors are illustrated in Fig. 10. The corresponding time and memory consumptions are recorded in Table 2. It can be clearly seen that, for decreasing grid spacing and increasing expansion order , the relative error decreases and the corresponding computational cost increases. In other words, by tuning and , we can trade off between accuracy and computational cost.
Table 2: Time and memory for the monopole-platform model with different grid spacing and expansion order
| Memory (GB) | CPU Time | Memory (GB) | CPU Time | |
|---|---|---|---|---|
| 1.0074 | 0.7863 | 1.1094 | 0.8256 | |
| 0.8643 | 0.2280 | 0.9662 | 0.2792 | |
| 0.8311 | 0.1554 | 0.9304 | 0.2106 | |
| 0.8243 | 0.1155 | 0.9261 | 0.1801 | |
C. Cone-shape object
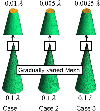
To further study the effectiveness of the matrix compression enhancement, a PEC cone model is then considered, as shown in Fig. 11. The height of the cone is 3.0 . The radii of the top and the bottom faces are 0.03 and 0.6 , respectively. The surface is discretized with a gradually-varied meshes. In particular, three mesh configurations are considered. For the three cases, the edge length for the regular part of the mesh is fixed to 0.1 , while the edge lengths for the dense part of the mesh are set to 0.01 , 0.005 , and 0.0025 , respectively. For clarity, the mesh settings considered are illustrated in Fig. 11.
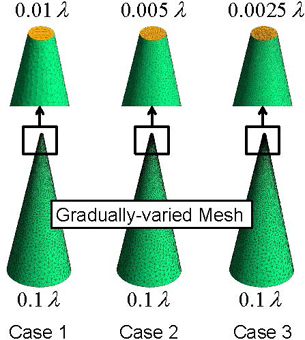
Figure 11: Mesh configurations of the PEC cone. A gradually-varied mesh is used to discretize the cone-shape object. The edge length for the regular part of the mesh is 0.1 . The edge lengths for the dense part of the mesh are 0.01 , 0.005 , and 0.0025 , respectively. For clarity, the enlarged views are also shown in the above.
Table 3: Time and memory for the cone model of case 1
| Algorithm | Memory (GB) | CPU Time | ||
|---|---|---|---|---|
| Total | Total | |||
| PSG-FFT | 0.3313 | 0.6286 | 12.128 | 0.6955 |
| PSG-FFT-ACA | 0.2418 | 0.4738 | 8.3050 | 0.6194 |
Table 4: Time and memory for the cone model of case 2
| Algorithm | Memory (GB) | CPU Time | ||
|---|---|---|---|---|
| Total | Total | |||
| PSG-FFT | 0.9611 | 1.6176 | 69.751 | 2.3978 |
| PSG-FFT-ACA | 0.4935 | 0.8778 | 35.127 | 1.8475 |
For each of these mesh configurations, we solve the corresponding equations first using the PSG-FFT algorithm which employs the uncompressed . Then, we recalculate these problems using the PSG-FFT-ACA algorithm which compresses with the ACA. Here, the splitting threshold is chosen to be 0.35 . Notice that, with such configuration of , all the interactions corresponding to occur within the subwavelength regime. Thus, the ACA compression can be applied effectively [21, 37]. In Table 3, 4, 5, we tabulate the time and memory consumptions of both the PSG-FFT algorithm and the PSG-FFT-ACA algorithm for the three mesh cases considered. It can be seen that, for all the cases, the PSG-FFT-ACA algorithm shows improved computational performances relative to the PSG-FFT algorithm. Further inspections show that the degree of improvements becomes more prominent when the dense mesh is finer. To make this more clear, we calculate the compression ratios of the evanescent matrix and use this as an indicator to measure the degree of improvements of the matrix compression enhancement. In Fig. 12, the compression ratios with respect to different mesh configurations are illustrated. We can clearly see that the compression ratio becomes higher when the dense mesh becomes finer. That is, the effectiveness of the proposed hybrid algorithm (with matrix compression enhancement) becomes more prominent when the ratio between the regular mesh size and the dense mesh size is larger.
Table 5: Time and memory for the cone model of case 3
| Algorithm | Memory (GB) | CPU Time | ||
|---|---|---|---|---|
| Total | Total | |||
| PSG-FFT | 2.6465 | 4.2615 | 181.47 | 4.4874 |
| PSG-FFT-ACA | 1.1579 | 2.0570 | 78.678 | 2.8009 |
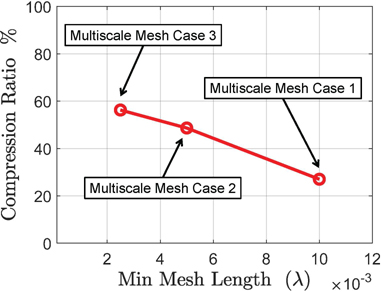
Figure 12: Compression ratios of the cone with different mesh configurations.
D. Aircraft model
A relatively large PEC aircraft model with multiscale meshes is finally considered, as shown in Fig. 13. In this model, both the length and the wingspan of the aircraft are about 16 . The surface is discretized with triangular meshes, resulting in 120,072 RWG functions. Here, a part of the aircraft surface on the wings is discretized with dense meshes of edge lengths about 0.02 , and the rest of the aircraft surface is discretized with regular meshes of edge lengths about 0.1 .
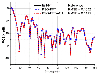
The bistatic RCS curves obtained by the PSG-FFT algorithm and the PSG-FFT-ACA algorithm are illustrated in Fig. 14. The pre-splitting threshold is here chosen to be 0.35 . The bistatic RCS curve obtained by the well-tested IE-FFT algorithm [17] is also shown in the figure and used as the reference to calculate the root mean square error (RMSE). We can see that these curves agree well with each other.
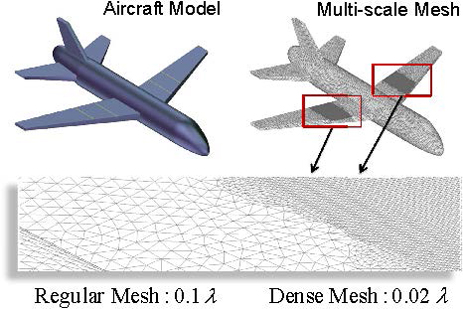
Figure 13: Geometry model and corresponding multiscale mesh of the PEC aircraft. Here, a part of the aircraft surface on the wings are discretized with a relatively dense mesh of 0.02 , while the rest of the aircraft surface is discretized with a regular mesh of 0.1 . The enlarged view of the multiscale mesh is also highlighted in the above.
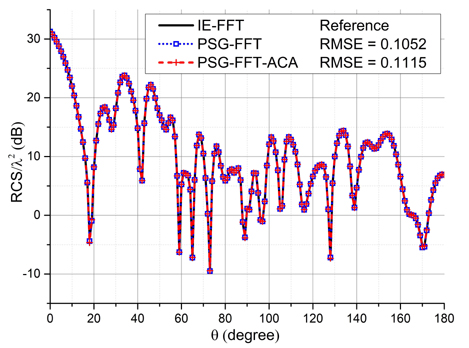
Figure 14: Bistatic RCS curves of the PEC aircraft model. The result obtained by the IE-FFT is used as the reference. The RMSE of the PSG-FFT and the PSG-FFT-ACA are calculated.
The time and memory consumptions of both the PSG-FFT algorithm and the PSG-FFT-ACA algorithm are tabulated in Table 6. From the table, we can see that the memory requirement of the evanescent matrix in the PSG-FFT-ACA algorithm is reduced by about , compared with that of the PSG-FFT algorithm. Meanwhile, the time cost for performing in the whole solution process is reduced by about . Thus, the time and memory cost related to the evanescent matrix can be greatly reduced, as a result of the matrix compression enhancement.
Nevertheless, the total cost of the overall algorithm are determined not only by the cost related to the evanescent matrix , but also determined by the cost related to the propagating matrix . For this relatively large object, the dense mesh region only occupies a relatively small portion of the overall object surface, and the ratio between the edge length (0.1 ) of the regular mesh and the edge length (0.02 ) of the dense mesh is here not extremely large. Thus, the time cost for performing still dominates the time cost for performing , and the reduction of the time cost for performing therefore only has a minor influence on the total time cost for performing . As a result, although the total time can be reduced due to the reduced cost related to , the reduction of the total time does not look very striking for this example.
Table 6: Time and memory for the aircraft model
| Algorithm | Memory (GB) | CPU Time | ||
|---|---|---|---|---|
| Total | Total | |||
| PSG-FFT | 3.5558 | 7.7408 | 76.910 | 23.580 |
| PSG-FFT-ACA | 2.3425 | 5.4033 | 48.053 | 21.431 |
IV. CONCLUSIONS
In this paper, a hybrid fast algorithm has been established for efficiently analyzing multiscale problems. In this algorithm, the Green’s function is a priori split into a singular but spatially localized part, and a smooth, oscillatory but bandlimited part. Then, the fundamental blocks for acceleration, i.e., the FFT and the matrix compression method (ACA), are applied to these two parts, respectively. Compared with the traditional methods which only employ the FFT for acceleration, the proposed hybrid algorithm can maintain low memory consumption in multiscale cases without compromising time cost, thus manifesting itself as a favorable multiscale extension of the traditional pure FFT-based methods. Furthermore, the required auxiliary geometric data structures herein can be constructed independent of each other, thus permitting the two kinds of acceleration methods to be connected seamlessly in a concise and elegant manner.
On the basis of the present work, several future directions may be explored. First, except for the Lagrange interpolation used in this work, other more accurate interpolation schemes (such as the Gaussian interpolation [15] or the fitting techniques [12]) can be employed to further improve the computational performance of the overall algorithm. Moreover, although only the PEC problems are considered here, extensions to the dielectric problems (especially inhomogeneous cases [16]) are clearly feasible. Furthermore, effective parallelization (especially on heterogeneous architectures [13]) of the proposed hybrid algorithm can be interesting subject of future research.
APPENDIX
The derivative functions of , which are used in (18) and (19), are given below
| (49) |
| (50) |
The derivative functions of , which are used in (30) and (31), are given below
| (51) |
| (52) |
ACKNOWLEDGMENT
This work was supported in part by the Fundamental Research Funds for the Central Universities (No. 2242022k30003), in part by the National Key Research and Development Project (No. 2019YFB1803202), and in part by the National Science Foundation of China (Nos. 62293492, 62131008, 61975177, U20A20164).
REFERENCES
[1] W. C. Chew and L. J. Jiang, “Overview of large-scale computing: the past, the present, and the future,” Proceedings of the IEEE, vol. 101, no. 2, pp. 227-241, Feb. 2013.
[2] M.-K. Li and W. C. Chew, “Multiscale simulation of complex structures using equivalence principle algorithm with high-order field point sampling scheme,” IEEE Trans. Antennas Propag., vol. 56, no. 8, pp. 2389-2397, 2007.
[3] Z.-G. Qian and W. C. Chew, “Fast full-wave surface integral equation solver for multiscale structure modeling,” IEEE Trans. Antennas Propag., vol. 57, no. 11, pp. 3594-3601, Nov. 2009.
[4] J. Zhu, S. Omar, and D. Jiao, “Solution of the electric field integral equation when it breaks down,” IEEE Trans. Antennas Propag., vol. 62, no. 8, pp. 4122-4134, Aug. 2014.
[5] R. F. Harrington, Field Computation by Moment Methods. New York: The MacMillian Co., 1968.
[6] J. M. Song and W. C. Chew, “Multilevel fast-multipole algorithm for solving combined field integral equations of electromagnetic scattering,” Microw. Opt. Technol. Lett., vol. 10, no. 1, pp. 14-19, Sep. 1995.
[7] J.-M. Song, C.-C. Lu, and W. C. Chew, “Multilevel fast multipole algorithm for electromagnetic scattering by large complex objects,” IEEE Trans. Antennas Propag., vol. 45, no. 10, pp. 1488-1493, Oct. 1997.
[8] W. C. Chew, J.-M. Jin, E. Michielssen, and J. Song, Fast and Efficient Algorithms in Computational Electromagnetics. Boston, MA: Artech House, 2001.
[9] M. Bleszynski, E. Bleszynski, and T. Jaroszewicz, “AIM: Adaptive integral method for solving large-scale electromagnetic scattering and radiation problems,” Radio Sci., vol. 31, no. 5, pp. 1225-1251, 1996.
[10] J. R. Phillips and J. K. White, “A precorrected-FFT method for electrostatic analysis of complicated 3-D structures,” IEEE Trans. Computer-Aided Design, vol. 16, no. 10, pp. 1059-1072, Oct. 1997.
[11] S. M. Seo and J.-F. Lee, “A fast IE-FFT algorithm for solving PEC scattering problems,” IEEE Trans. Magn., vol. 41, no. 5, pp. 1476-1479, May2005.
[12] J.-Y. Xie, H.-X. Zhou, W. Hong, W.-D. Li, and G. Hua, “A highly accurate FGG-FG-FFT for the combined field integral equation,” IEEE Trans. Antennas Propag., vol. 61, no. 9, pp. 4641-4652, Sep. 2013.
[13] S. Peng and C.-F. Wang, “Precorrected-FFT method on graphics processing units,” IEEE Trans. Antennas Propag., vol. 61, no. 4, pp. 2099-2107, Apr. 2013.
[14] L.-W. Li, Y.-J. Wang, and E.-P. Li, “MPI-based parallelized precorrected FFT algorithm for analyzing scattering by arbitrarily shaped three-dimensional objects,” Electromagn. Waves Appl., vol. 17, pp. 1489-1491, Jan. 2003.
[15] B. Lai, X. An, H.-B. Yuan, Z.-S. Chen, C.-M. Huang, and C.-H. Liang, “A novel Gaussian interpolation formula-based IE-FFT algorithm for solving EMscattering problems,” Microw. Opt. Tech. Lett., vol. 51, no. 9, pp. 2233-2236, Sep.2009.
[16] X.-C. Nie, L.-W. Li, N. Yuan, T. S. Yeo, and Y.-B. Gan, “Precorrected-FFT solution of the volume integral equation for 3-D inhomogeneous dielectric objects,” IEEE Trans. Antennas Propag., vol. 53, no. 1, pp. 313-320, Jan. 2005.
[17] J.-Y. Xie, H.-X. Zhou, W.-D. Li, and W. Hong, “IE-FFT for the combined field integral equation applied to electrically large objects,” Microw. Opt. Tech. Lett., vol. 54, no. 4, pp. 891-896, Apr.2012.
[18] S. Peng, C.-F. Wang, and J.-F. Lee, “Analyzing PEC scattering structure using an IE-FFT algorithm,” ACES Journal, vol. 24, no. 2, Apr. 2009.
[19] L. J. Jiang and W. C. Chew, “A mixed-form fast multipole algorithm,” IEEE Trans. Antennas Propag., vol. 53, no. 12, pp. 4145-4156, Dec.2005.
[20] X.-M. Pan, J.-G. Wei, Z. Peng, and X.-Q. Sheng, “A fast algorithm for multiscale electromagnetic problems using interpolative decomposition and multilevel fast multipole algorithm,” Radio Sci., vol. 47, no. 1, Feb. 2012.
[21] L.-F. Ma, Z. Nie, J. Hu, and S.-Q. He, “Combined MLFMA-ACA algorithm application to scattering problems with complex and fine structure,” Asia Pacific Microwave Conference, pp. 802-805,2009.
[22] W.-B. Kong, H.-X. Zhou, K.-L. Zheng, and W. Hong, “Analysis of multiscale problems using the MLFMA with the assistance of the FFT-based method,” IEEE Transactions on Antennas and Propagation, vol. 63, no. 9, pp. 4184-4188,2015.
[23] J. S. Zhao and W. C. Chew, “Three dimensional multilevel fast multipole algorithm from static to electrodynamic,” Microw. Opt. Technol. Lett., vol. 26, no. 1, pp. 43-48, 2000.
[24] L. J. Jiang and W. C. Chew, “Low-frequency fast inhomogeneous plane-wave algorithm,” Microw. Opt. Tech. Lett., vol. 40, no. 2, pp. 117-122, Jan. 2004.
[25] T. Xia, L. L. Meng, Q. S. Liu, H. H. Gan, and W. C. Chew, “A low-frequency stable broadband multilevel fast multipole algorithm using plane wave multipole hybridization,” IEEE Trans. Antennas Propag., vol. 66, no. 11, pp. 6137-6145, Nov.2018.
[26] H. Wallen and J. Sarvas, “Translation procedures for broadband MLFMA,” Prog. Electromagn. Res., vol. 55, pp. 47-78, 2005.
[27] D. Wulf and R. Bunger, “An efficient implementation of the combined wideband MLFMA/LF-FIPWA,” IEEE Trans. Antennas Propag., vol. 57, no. 2, pp. 467-474, Feb. 2009.
[28] D. T. Schobert and T. F. Eibert, “Fast integral equation solution by multilevel Green’s function interpolation combined with multilevel fast multipole method,” IEEE Trans. Antennas Propag., vol. 60, no. 9, pp. 4458-4463, Sep. 2012.
[29] I. Bogaert, J. Peeters, and F. Olyslager, “A nondirective plane wave MLFMA stable at low frequencies,” IEEE Trans. Antennas Propag., vol. 56, no. 12, pp. 3752-3767, Dec. 2008.
[30] O. Ergul and B. Karaosmanoglu, “Broadband multilevel fast multipole algorithm based on an approximate diagonalization of the Green’s function,” IEEE Trans. Antennas Propag., vol. 63, no. 7, pp. 3035-3041, July 2015.
[31] W.-B. Kong, H.-X. Zhou, K.-L. Zheng, X. Mu, and W. Hong, “FFT-based method with near-matrix compression,” IEEE Transactions on Antennas and Propagation, vol. 65, no. 11, pp. 5975-5983,2017.
[32] A. Bespalov, “Cost-effective solution of the boundary integral equations for 3D Maxwell problems,” Russ. J. Numer. Anal. Math. Modelling, vol. 14, no. 5, pp. 403-428, 1999.
[33] A. Bespalov, “On the use of a regular grid for implementation of boundary integral methods for wave problems,” Russ. J. Numer. Anal. Math. Modelling, vol. 15, no. 6, pp. 469-488. 2000.
[34] M. Frigo and S. Johnson, FFTW Manual [Online]. Available: http://www.fftw.org/
[35] R. Barrett, M. Berry, T. F. Chan, J. Demmel, J. M. Donato, J. Dongarra, V. Eijkhout, R. Pozo, C. Romine, and H. Van der Vorst, Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods. Philadelphia, PA, USA: SIAM,1994.
[36] M. Bebendorf and S. Rjasanow, “Adaptive low-rank approximation of collocation matrices,” Computing, vol. 70, no. 1, pp. 1-24, 2003.
[37] K. Zhao, M. N. Vouvakis, and J.-F. Lee, “The adaptive cross approximation algorithm for accelerated method of moments computations of EMC problems,” IEEE Trans. Electromag. Compat., vol. 47, no. 4, pp. 763-773, Nov. 2005.
[38] H.-X. Zhou, G.-Y. Zhu, W.-B. Kong, and W. Hong, “An upgraded ACA algorithm in complex field and its statistical analysis,” IEEE Trans. Antennas Propag., vol. 65, no. 5, pp. 2734-2739, May2017.
[39] S. M. Rao, D. R. Wilton, and A. W. Glisson, “Elettromagnetic scattering by surfaces of arbitrary shape,” IEEE Trans. Antennas Propag., vol. 30, no. 3, pp. 409-418, May 1982.
BIOGRAPHIES

Guang-Yu Zhu received the B.D. in electrical engineering from Nanjing Agricultural University, Nanjing, China, in 2012, and the Ph.D. degree in radio engineering from Southeast University, Nanjing, China, in 2020, respectively. He is currently a postdoctoral research fellow with the Department of Information Science and Electronic Engineering, Zhejiang University, Hangzhou, China. His research interests are in computational electromagnetics with focus on fast algorithms and domain decomposition methods.

Wei-Dong Li received the M.S. degree in mathematics and the Ph.D. degree in radio engineering from Southeast University, Nanjing, China, in 2003 and 2007, respectively. From January 2008 to January 2009, he was a visiting scholar with the Technische University Darmstadt, Germany. He is currently an associate professor with the State Key Laboratory of Millimeter Waves and the School of Information Science and Engineering, Southeast University. He has authored or coauthored over 40 technical articles. He serves as a reviewer for the IEEE Transactions on Antennas and Propagation and IET Microwave, Antennas and Propagation. His research interests are in computational EM with focus on integral-equation-based overlapped domain decomposition method, multilevel fast multipole algorithm, fast and accurate inter/extrapolation techniques, and basic functions.

Wei E.I. Sha received the B.S. and Ph.D. degrees in electronic engineering from Anhui University, Hefei, China, in 2003 and 2008, respectively. From July 2008 to July 2017, he was a post-doctoral research fellow and then a research assistant professor with the Department of Electrical and Electronic Engineering, University of Hong Kong, Hong Kong. From March 2018 to March 2019, he worked as a Marie Skodowska-Curie Individual Fellow with University College London, London, U.K. From October 2017, he joined the College of Information Science and Electronic Engineering, Zhejiang University, Hangzhou, China, where he is currently a tenure-tracked assistant professor. He has authored or coauthored 180 refereed journal articles, 150 conference publications (including five keynote talks and one short course), nine book chapters, and two books. His Google Scholar citation is 8193 with H-index of 45. His research interests include theoretical and computational research in electromagnetics and optics, focusing on the multiphysics and interdisciplinary research. His research involves fundamental and applied aspects in computational and applied electromagnetics, nonlinear and quantum electromagnetics, micro- and nano-optics, optoelectronic device simulation, and multiphysics modeling. Dr. Sha is a member of Optical Society of America (OSA). He served as a reviewer for 60 technical journals and technical program committee member for ten IEEE conferences. He was a recipient of the Applied Computational Electromagnetics Society (ACES) Technical Achievement Award in 2022 and PIERS Young Scientist Award in 2021. In 2015, he was awarded Second Prize of Science and Technology from Anhui Province Government, China. In 2007, he was awarded the Thousand Talents Program for Distinguished Young Scholars of China. He also received six Best Student Paper Prizes and one Young Scientist Award with his students. He also served as an associate editor for IEEE Journal on Multiscale and Multiphysics Computational Techniques, IEEE Open Journal of Antennas and Propagation, and IEEE Access.

Hou-Xing Zhou received the M.S. degree in mathematics from Southwest Normal University, Chongqing, China, in 1995, and the Ph.D. degree in radio engineering from Southeast University, Nanjing, China, in 2002. Since 2002, he has been with the State Key Laboratory of Millimeter Waves, Southeast University. He is currently a professor with the School of Information Science and Engineering, Southeast University. He has authored or coauthored 40 journal articles. His main research interests include numerical algorithms in computational EM, including the fast algorithm for spatial domain dyadic Green’s functions of stratified media, the multilevel fast multiple algorithm, the FFT-based fast algorithm, the IE-based domain decomposition method, the FEM-BI-based domain decomposition method, the higher order method of moments, and the parallel computation based on GPU/multicore-CPU platform. In addition, the full-wave simulation technology for the electromagnetic field distribution around the base-station is one of his current interests.

Wei Hong received the B.S. degree from the University of Information Engineering, Zhengzhou, China, in 1982, and the M.S. and Ph.D. degrees from Southeast University, Nanjing, China, in 1985 and 1988, respectively, all in radio engineering. Since 1988, he has been with the State Key Laboratory of Millimeter Waves and serves for the director of the lab, since 2003. In 1993, 1995, 1996, 1997, and 1998, he was a short-term visiting scholar with the University of California at Berkeley and at Santa Cruz, respectively. He is currently a professor with the School of Information Science and Engineering, Southeast University. He has been involved in numerical methods for electromagnetic problems, millimeter wave theory and technology, antennas, RF technology for wireless communications, and so on. He has authored and coauthored over 300 technical publications and two books. Dr. Hong was an elected IEEE MTT-S AdCom Member, from 2014 to 2016. He is a fellow of CIE, the vice president of the CIE Microwave Society and Antenna Society, and the chair of the IEEE MTT-S/AP-S/EMC-S Joint Nanjing Chapter. He was twice awarded the National Natural Prizes, thrice awarded the first-class Science and Technology Progress Prizes issued by the Ministry of Education of China and Jiangsu Province Government. He also received the Foundations for China Distinguished Young Investigators and for Innovation Group issued by NSF of China. He served as the associate editor for the IEEE Transactions on Microwave Theory and Techniques from 2007 to 2010, and one of the guest editors for the 5G special issue of the IEEE Transactions on Antennas and Propagation, in 2017.
ACES JOURNAL, Vol. 38, No. 9, 652–666
doi: 10.13052/2023.ACES.J.380904
© 2023 River Publishers