A Semi-Supervised Electromagnetic Imaging Algorithm Based, on Generative Adversarial Networks
Chun Xia Yang1, Chi Zhou1, Shuang Wei1, and Mei Song Tong2
1Shanghai Engineering Research Center of Intelligent Education and Bigdata, Shanghai Normal University, Shanghai 200234, China, chunxiay@shnu.edu.cn, 1000528179@smail.shnu.edu.cn, weishuang@shnu.edu.cn
2Department of Electronic Science and Technology, Tongji University, Shanghai 201804, China, mstong@tongji.edu.cn
Submitted On: December 06, 2024; Accepted On: February 09, 2026
Abstract
In electromagnetic imaging applications, acquiring labeled data for supervised learning poses a significant challenge due to the high cost and time-consuming annotation processes. To address this limitation, we propose a semi-supervised electromagnetic imaging algorithm leveraging generative adversarial networks (GANs), which effectively integrates limited labeled data with abundant unlabeled measurements. Unlike conventional approaches that directly learn from raw scattered data, our method employs diffraction tomography (DT)-generated images as network inputs, thereby embedding spatial prior knowledge of scatterers to mitigate inherent artifacts such as boundary blurring and speckle noise. The framework features a modified U-Net architecture augmented with convolutional block attention modules (CBAMs) and residual blocks, enhancing feature extraction and segmentation robustness. Furthermore, adversarial training is introduced to refine the segmentation network using pseudo-labels generated from unlabeled DT images, enabling the discriminator to enforce physical consistency between labeled and unlabeled domains. Extensive simulations demonstrate the superiority of our method: when trained with only 100 labeled samples and 1,000 unlabeled samples, the proposed algorithm achieves a reduction in mean squared error (MSE) compared to purely supervised counterparts. Additional validation on the handwritten digits and the “Austria” profile highlights its strong generalization capability for reconstructing unseen targets. This work bridges the gap between data-driven deep learning and physical priors, offering a practical solution for high-precision electromagnetic imaging under limited supervision.
Keywords: Generative adversarial network, inverse problems, semi-supervised learning..
1 INTRODUCTION
With the rapid advancement of technology, electromagnetic techniques and theories have shown remarkable vitality. As an important branch of electromagnetic technology, microwave imaging has been widely applied in various fields such as remote sensing [1] and oil exploration [2]. In comparison to conventional cameras, the penetrative ability of electromagnetic waves renders them impervious to darkness or adverse weather conditions, thereby augmenting camera imaging capabilities. Although computed tomography (CT) [3] continues to be indispensable for high-resolution anatomical imaging and rapid diagnostics, microwave imaging provides distinct advantages in specific clinical contexts, such as eliminating exposure to ionizing radiation and facilitating cost-effective repetitive monitoring [4]. This underscores its potential as a complementary modality for applications sensitive to radiation exposure [5].
Traditional physics-based electromagnetic inverse scattering methods can be primarily categorized into two types: (1) linear approximation methods (e.g., Born/Rytov approximations), and (2) iterative optimization frameworks that minimize data-model discrepancies through regularization techniques. Although linear approximation methods provide computational efficiency suitable for real-time imaging, their reliance on approximation conditions limits their applicability scope. For example, the Born approximation, due to its dependence on the weak scattering assumption and neglect of multiple scattering effects, may encounter substantial loss of accuracy when handling electrically large or strongly scattering targets. On the other hand, iterative optimization methods enhance reconstruction fidelity but are accompanied by computationally intensive processes that hinder practical applications. These limitations become particularly critical in biomedical dynamic monitoring and time-sensitive remote sensing scenarios, where balancing computational complexity and imaging accuracy remains a challenging issue [6].
Such inherent constraints of traditional physics-driven approaches have driven the exploration of data-driven deep learning frameworks, which aim to bypass iterative computations while retaining the ability to model nonlinear scattering phenomena [7, 8]. Wei and Chen [9] proposed a convolutional neural network (CNN) based on the U-Net architecture to solve the full-wave inverse scattering problem, introducing and comparing several CNN-based training schemes, including the back-propagation scheme (BPS) [10] and the dominant current scheme (DCS). Sanghvi et al. [11] introduced a deep learning-based framework to address the electromagnetic inverse scattering problem. This framework builds upon and extends the capabilities of existing physics-based inversion algorithms. These algorithms, such as contrast source inversion (CSI) [12], subspace optimization methods (SOM) [13], and their variants, often struggle with getting trapped in false local minima when recovering objects with high contrast values. They also proposed a novel CNN architecture called the contrast source network (CS-Net). Xu et al. [14] proposed an inversion method based on U-Net network to solve the phaseless data direct inverse scheme (PD-DIS) for phase free electromagnetic backscatter imaging problems. Ye et al. [15] proposed a linear imaging method for homogeneous background problems and applied a GAN with an attention mechanism to address super-resolution tasks.
Most segmentation frameworks are based on typical segmentation networks, such as U-Net, which extract multi-scale features in a fully supervised manner. Although these methods have demonstrated success, the reliance on extensive measurement data for fully supervised learning approaches is time-consuming and expensive. In electromagnetic imaging, the scarcity of high-quality labeled data presents a substantial obstacle for data-driven reconstruction methods. Semi-supervised learning (SSL) addresses this limitation by leveraging both limited labeled data and abundant unlabeled measurements in a unified framework. Core SSL mechanisms, such as consistency regularization (which enforces prediction invariance under perturbations of unlabeled inputs) [16] and adversarial constraints (which align reconstructions with physical priors through generative-discriminative interactions) [17], facilitate robust feature learning even under weak supervision. These approaches have demonstrated efficacy in domains like medical imaging, where similar low-data conditions prevail [18]. This success provides a strong rationale for adopting SSL principles in microwave imaging, enabling the utilization of unlabeled experimental or simulated data to enhance model generalizability.
The structure of this paper is as follows. Section 2 introduces the physical model and its mathematical description for the microwave imaging problem. Section 3 provides a comprehensive explanation of the design and implementation of a semi-supervised imaging network based on GAN. Section 4 presents the experimental design, dataset construction, and subsequent analysis of experimental results. Finally, in section 5, we conclude with a summary of our findings.
2 ELECTROMAGNETIC IMAGING MODEL
The physical model of the microwave imaging problem is shown in Fig. 1. Within the spatial domain, an imaging region D encompasses scatterers of diverse shapes. Microwave imaging is a non-contact method that employs antennas positioned in an observation region S outside the imaging domain D to transmit and receive electromagnetic waves. When incident electromagnetic waves illuminate the scatterer, a scattered field is generated, which combines with the incident field to form the total field received by the antennas. The microwave imaging problem involves deducing the shape, position, and material properties of scatterers within the imaging region D based on measured scattered data at receiving points.
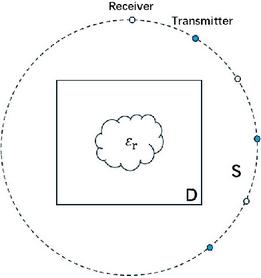
Figure 1 The physical model of microwave imaging problems.
For the two-dimensional problem, the scattering process is described by the following formula:
| (1) |
where and denote the incident field and the total field, respectively. is the wave number of the background medium, represents the two-dimensional Green’s function in background, denotes the position of the receiving antenna, represents the position of an arbitrary point within the imaging region, and represents the contrast distribution within the imaging region with being the relative permittivity at position . The function governs wave propagation in the background medium and connects the contrast distribution with scattered field measurements as the integral kernel. The goal of inverse scattering is to determine the contrast distribution in the imaging region using scattered field data from the observation region. The contrast function quantifies permittivity variations and relates to material properties like conductivity and polarization through electromagnetic relations [19]. Analyzing the distribution of is critical for distinguishing material heterogeneity, such as tumors versus healthy tissues in biomedical imaging, and resolving ambiguities in inverse scattering problems. Its magnitude and spatial gradients directly determine scattering field perturbations [20].
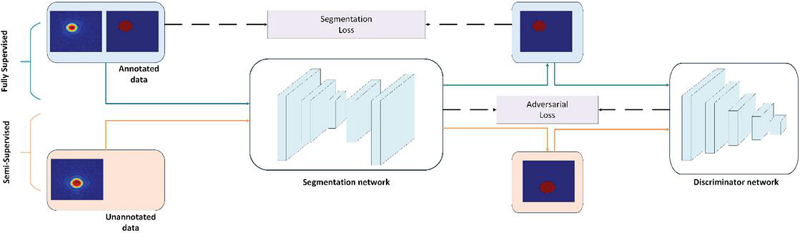
Figure 2 The semi-supervised imaging network based on GAN.
To alleviate the learning complexity of neural networks, this study initially employs the diffraction tomography (DT) algorithm [21] to obtain an approximate contrast image, which is subsequently inputted into a segmentation network to generate a refined contrast image with enhanced resolution. The DT algorithm is a linear inversion method based on the Born approximation [22]. In the case of weak scattering intensity, the incident field can be approximated as being equivalent to the total field , allowing equation (1) to be reformulated as
| (2) |
where denotes the scattered field. After a series of derivations, the above equation can be expressed as
| (3) |
In equation (4), both the transmitting and receiving antennas are approximated as ideal line sources, with position vectors and in two-dimensional space, respectively. The Fourier transform of , denoted by , is defined as and . Here, and denote the unit vectors in the directions of and , respectively. Based on the linear approximation in equation (4), the DT algorithm generates initial contrast images under weak scattering conditions. These images often suffer from boundary blurring and speckle noise, especially for strong scatterers. To address this, we use DT images as inputs to the segmentation network instead of raw scattering data. This introduces a physical prior into the network, enabling it to retain target spatial distribution information while focusing on denoising and enhancing the DT images.
3 SEMI-SUPERVISED INVERSION ALGORITHM
The proposed semi-supervised framework, illustrated in Fig. 2, employs a Generative Adversarial Network (GAN) [23] architecture comprising a segmentation generator and a discriminator. The workflow operates in two phases:
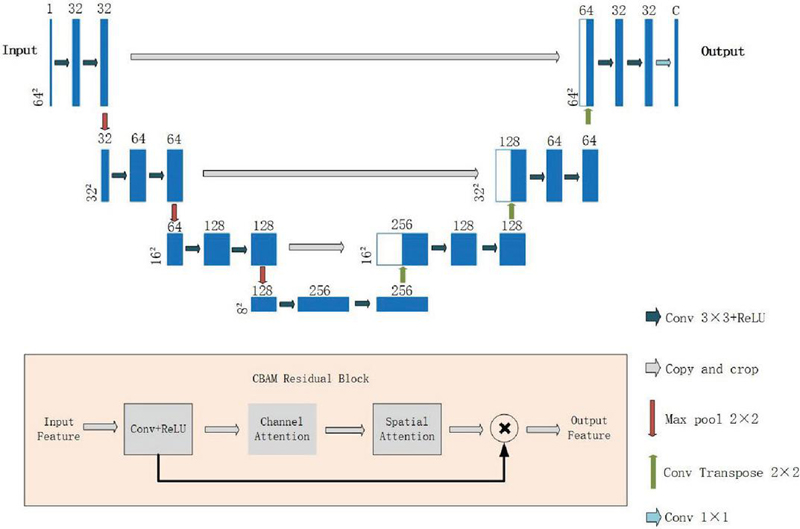
Figure 3 The structure of the segmentation network.
3.1 Supervised pre-training
The segmentation generator is initially trained on limited labeled data to establish baseline mapping capabilities between electromagnetic measurements and target structures.
3.2 Adversarial refinement with unlabeled data
Pseudo-label Generation: Unlabeled measurements are processed by the pre-trained generator to produce segmentation probability maps (pseudo-labels).
Discriminative Evaluation: The discriminator receives three inputs: (i) ground-truth labels from labeled data, (ii) generator predictions for labeled data, and (iii) pseudo-labels for unlabeled data. It outputs a probability score to assess segmentation plausibility against physical priors.
Adversarial Optimization: Through iterative minimax training, the generator learns to produce segmentation maps that deceive the discriminator (by aligning with physical priors), while the discriminator improves its ability to distinguish authentic versus generated labels. This dual competition regularizes ill-posed segmentation tasks by enforcing consistency across labeled and unlabeled domains.
Figure 3 shows the schematic of the segmentation network, a modified U-Net for DT image segmentation. The U-Net architecture, originally designed for biomedical image segmentation [24], exhibits intrinsic compatibility with electromagnetic inverse scattering problems due to the following characteristics. (1) Encoder-Decoder Symmetry: The encoder (contracting path) progressively extracts multi-scale scattering features from raw measurement data, while the decoder (expanding path) reconstructs high-resolution permittivity maps through transposed convolutions. This aligns with the ill-posed mapping from sparse measurements to continuous physical properties. (2) Skip Connections: By enabling cross-layer feature fusion between the encoder and decoder, skip connections preserve both low-frequency structural priors and high-frequency details. This effectively addresses the challenges posed by multi-scale scattering phenomena, such as weak single scattering versus strong multiple scattering.
To address the challenges of boundary blurring and noise in DT images, the segmentation network incorporates Convolutional Block Attention Modules (CBAM) [25] and residual blocks [26] into the U-Net architecture. By effectively integrating low-level information, these additions facilitate the generation of enhanced high-level features, thereby aiding in the identification of scatterers from DT images [27]. The CBAM comprises channel attention and spatial attention modules, which enhance the feature extraction capability of CNNs in a more comprehensive and effective manner. Moreover, training deep learning networks can encounter diverse challenges, including instability during the training process. By integrating residual blocks with skip connections, we can effectively stabilize the training of extremely deep neural networks.

Figure 4 The structure of the discriminant network.
The architecture of the discriminator network is depicted in Fig. 4 and comprises a straightforward CNN. The discriminator outputs a probability to evaluate the quality of input segmentation results. A value close to 1 denotes high quality, while a value close to 0 indicates low quality.
The segmentation network is trained by minimizing the following loss function:
| (4) |
where and represent the supervised segmentation loss and adversarial loss, respectively. The weight for adversarial learning, denoted as , is set to 0.02, following the loss function weights specified in [28]. For labeled pairs, the segmentation network is trained to map DT images to their corresponding ground truth contrast maps by minimizing the supervised loss , which is defined as the pixel-wise mean squared error (MSE). For unlabeled DT images , the pre-trained generator produces pseudo-labels . Subsequently, the discriminator evaluates both the labeled data and the pseudo-labeled data to calculate the adversarial loss . Equation (4) can be expanded in more detail as:
| (5) | ||
Where represents the total number of pixels in the imaging region, and respectively indicate the contrast values at the i-th pixel in the ground truth image and the predicted labeled image. In the adversarial loss term, encompasses both labeled DT images and unlabeled DT images . Typically, the number of labeled data is significantly smaller than that of unlabeled data, resulting in an inherent imbalance during network training. To address this issue, this study employs data augmentation techniques on the labeled dataset, such as image flipping and rotation, to enhance both diversity and quantity of training samples.
4 SIMULATION EXPERIMENT AND ANALYSIS
In this experiment, the key parameters, including the imaging domain size, antenna configuration, and operating frequency, are rigorously aligned with the electromagnetic model described in section 2. The imaging region is a square area with a side length of 2 m located in free space, which is further divided into a grid consisting of pixels. The origin of the coordinate system is located at the center of this imaging region. In the observation region outside the imaging area, there are a total of 16 transmitting antennas and 32 receiving antennas arranged symmetrically around the origin within a radius of 3 m. The incident wave operates at a frequency of 0.4 GHz. In every measurement, each transmitting antenna sequentially emits electromagnetic waves to illuminate the imaging region, while all receivers concurrently capture the scattered waves from the scatterer. This process yields a total of -dimensional scattering data. In this paper, the Method of Moments (MoM) is used to solve the forward scattering problem, generating synthetic scattering data which are then processed by the DT algorithm to reconstruct preliminary images for the GAN input.
4.1 Test 1: Circular scatterers
In the first test, the dataset consists of circular scatterers with random sizes and positions. The relative permittivity of the target ranges randomly from 1.1 to 3.0 (contrast ranging from 0.1 to 2.0), with radii between 0.1 and 0.3 m, in intervals of 0.01 m. The coordinates of the center of the targets are within the range of (0.5 m to 0.5 m, 0.5 m to 0.5 m).
To validate the effectiveness of the proposed network enhancement and semi-supervised learning under the adversarial training mechanism, we conducted a comparative analysis of three models under identical experimental conditions: (1) Basic U-Net: A standard U-Net without CBAM or residual blocks; (2) Supervised GAN: The generator adopts a U-Net architecture integrated with CBAM and residual blocks, and is trained exclusively on labeled data; and (3) GAN-based SSL: The semi-supervised method combining labeled and unlabeled data with adversarial training. The segmentation and the discriminator network are both optimized using the Adam optimizer, with an initial learning rate set to . The training process is iterated for 2000 epochs to ensure convergence is achieved. Through this iterative procedure, the learning rate gradually reduces to . These parameter settings are determined based on optimal values obtained from experimental simulations.
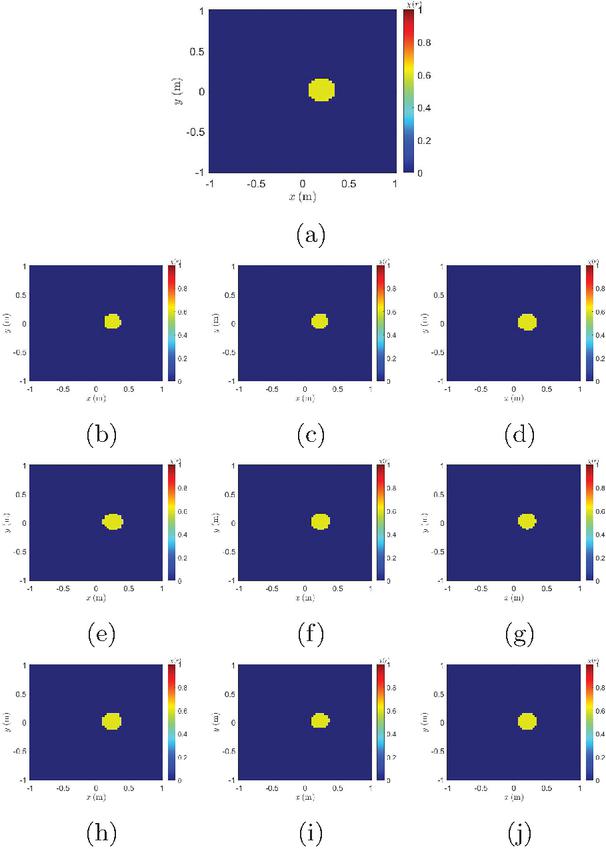
Figure 5 Imaging results of circular scatterers. (a) Actual target. (b)–(d) Basic U-Net results trained with 100, 200, and 500 labeled datasets. (e)–(g) Supervised GAN results trained with 100, 200, and 500 labeled datasets. (h)–(j) GAN-based SSL results trained with 100, 200, and 500 labeled samples plus 1000 unlabeled samples.
The quality of the segmented image is evaluated by using the MSE and the structural similarity (SSIM) index [29]. The calculation formula for SSIM is as follows:
| (6) |
where and represent the mean contrast values of images and , respectively. Additionally, the variances of the contrast in images and are denoted by and , respectively, while their covariance is indicated by . The constants and are crucial for maintaining stability, where and . Here, represents the range of pixel values (specifically, the range of relative permittivity values in this experiment), while and are assigned as 0.01 and 0.03 respectively.
Three experimental sample sets were established, with 100, 200, and 500 labeled samples allocated to each group respectively, while the number of unlabeled samples was consistently maintained at 1000 across all groups.
Table 1 MSE values for circular scatterers
| Method | Labeled Samples | ||
| (1000 Unlabeled) | |||
| 100 | 200 | 500 | |
| Basic U-Net | 1.2412 | 0.8634 | 0.7180 |
| Supervised GAN | 1.0762 | 0.8023 | 0.6659 |
| GAN-based SSL | 0.8283 | 0.6711 | 0.5511 |
| Reduction | |||
| (SSL vs. Supervised) | 23.0% | 16.4% | 17.2% |
Table 2 SSIM values for circular scatterers
| Method | Labeled Samples | ||
| (1000 Unlabeled) | |||
| 100 | 200 | 500 | |
| Basic U-Net | 0.9486 | 0.9563 | 0.9599 |
| Supervised GAN | 0.9531 | 0.9611 | 0.9621 |
| GAN-based SSL | 0.9587 | 0.9639 | 0.9716 |
The imaging results for one of the samples are presented in Fig. 5, where the GAN-based SSL method demonstrates the most accurate reconstructions. As shown in Tables 1 and 2, the basic U-Net consistently exhibits the highest MSE and the lowest SSIM across all labeled data settings, indicating its limited ability to address boundary blurring and speckle noise inherent in DT images. By integrating channel attention mechanisms via CBAM and residual blocks, as well as incorporating discriminators, the supervised GAN achieves a significant performance improvement. Nevertheless, the GAN-based SSL method further enhances segmentation accuracy by effectively leveraging unlabeled data. Specifically, compared to the supervised GAN, the semi-supervised approach reduces MSE by , , and for datasets with 100, 200, and 500 labeled samples, respectively. Similarly, SSIM values show substantial increases when unlabeled data is introduced. These findings confirm that both architectural enhancements (CBAM and residual blocks) and semi-supervised adversarial training contribute to improving the model’s robustness and precision.
4.2 Test 2: MNIST digits
To further validate the model’s performance and compare it with other semi-supervised methods, we conducted experiments on the MNIST dataset. This dataset contains handwritten digits from 250 individuals, covering all ten numerical symbols ranging from 0 to 9. To augment the sample data and improve the model’s generalization capability, each sample was augmented with a randomly sized and positioned circular scatterer. The relative permittivity for all samples was set within the range of 1.1 to 2.0 (with a contrast range of 0.1 to 1.0).
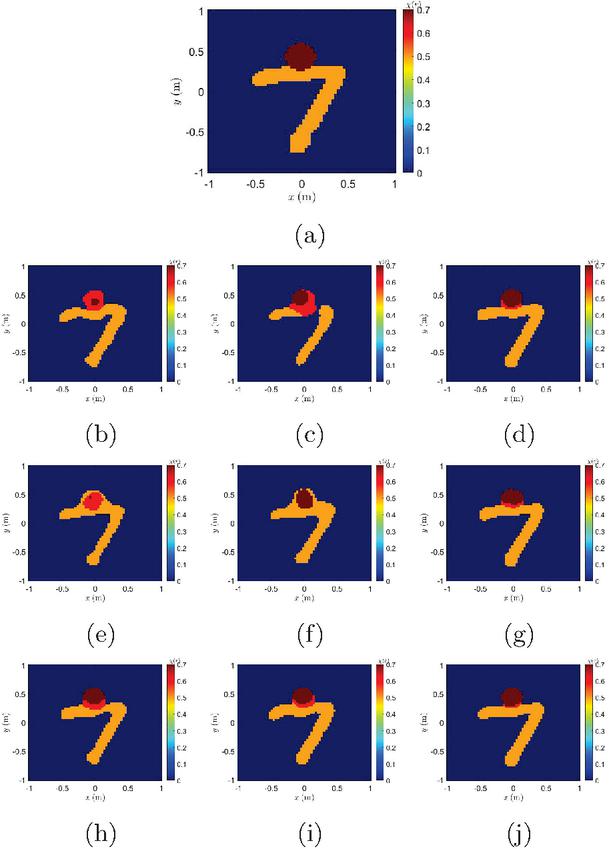
Figure 6 Imaging results of handwritten digits. (a) Real target. (b)-(d) Supervised GAN results trained on 1000, 2000, and 5000 labeled datasets. (e)-(g) Mean Teacher results trained with labeled to unlabeled data ratios of 1:9, 1:4, and 1:1. (h)-(j) GAN-based SSL results trained with labeled to unlabeled data ratios of 1:9, 1:4, and 1:1.
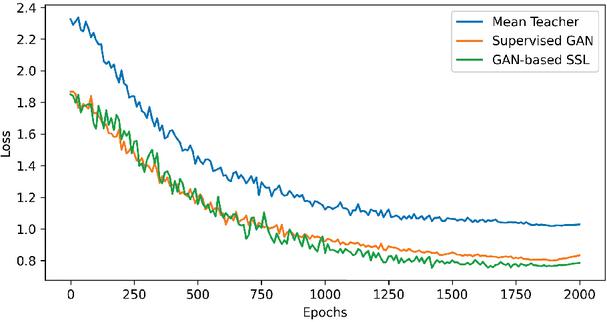
Figure 7 The curves of training loss versus epochs.
The model was trained and tested on three datasets with labeled-to-unlabeled ratios of 1:9 (1000:9000), 1:4 (2000:8000), and 1:1 (5000:5000). For comparison, we additionally implemented the Mean Teacher method [30], a widely adopted semi-supervised learning approach in computer vision. The Mean Teacher model employed the same U-Net backbone as our segmentation network, with an exponential moving average (EMA) decay rate of 0.99 for the teacher weights. All hyperparameters, including the learning rate and optimizer, were kept consistent across models to ensure a fair comparison.
Table 3 MSE values for handwritten digits
| Method | Labeled Samples | ||
| (10000 in Total) | |||
| 1000 | 2000 | 5000 | |
| Mean Teacher | 1.0339 | 1.0276 | 0.7177 |
| Supervised GAN | 0.9172 | 0.8326 | 0.7087 |
| GAN-based SSL | 0.8523 | 0.7847 | 0.6891 |
| Reduction | |||
| (SSL vs. Supervised) | 7.1% | 5.8% | 2.8% |
Table 4 SSIM values for handwritten digits
| Method | Labeled Samples (10000 in Total) | ||
| 1000 | 2000 | 5000 | |
| Mean Teacher | 0.8780 | 0.8821 | 0.9124 |
| Supervised GAN | 0.8932 | 0.9009 | 0.9149 |
| GAN-based SSL | 0.8981 | 0.9056 | 0.9172 |
The experimental results demonstrate that the SSL method based on GAN significantly outperforms both the supervised GAN and the Mean Teacher model on the MNIST dataset. In the imaging results of a representative sample shown in Fig. 6, the GAN-based SSL reconstructs the target edges more accurately and clearly. Figure 7 shows the training loss versus epochs curves for the Mean Teacher, supervised GAN, and GAN-based SSL methods when the ratio of labeled to unlabeled data is 2000:8000. As illustrated in Table 3, under conditions of limited labeled data (1000:9000), the MSE of GAN-based SSL is lower than that of the supervised GAN, and it retains a advantage even as the amount of labeled data increases (5000:5000). The Mean Teacher model exhibits inferior performance due to issues with pseudo-label noise. Furthermore, the results presented in Table 4 corroborate the GAN-based SSL method achieves the highest SSIM scores across all configurations. These findings underscore the efficacy of SSL in leveraging unlabeled data via adversarial training to enhance boundary clarity, particularly in scenarios with limited labeled data.
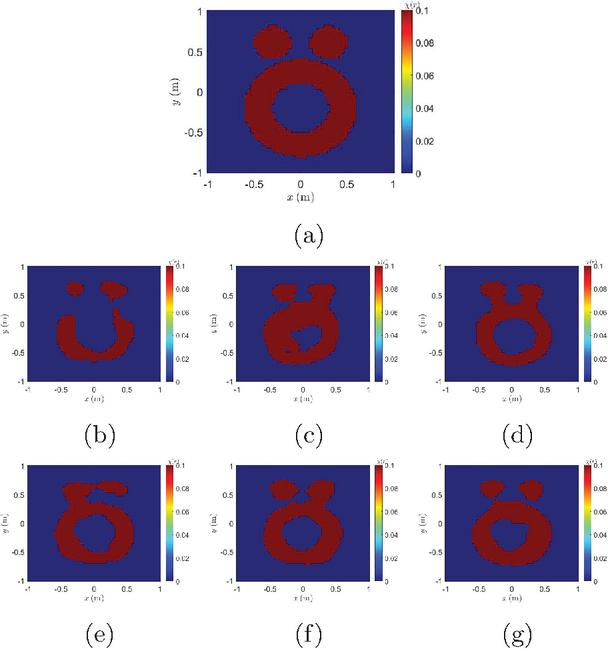
Figure 8 The imaging results of the “Austria” profile using the MINIST data-trained network. (a) Real profile. (b), (c), and (d) show supervised GAN results trained on 1000, 2000, and 5000 labeled datasets, respectively. (e), (f), and (g) present SSL results from models trained with labeled to unlabeled data ratios of 1:9, 1:4, and 1:1, respectively.
4.3 Test 3: “Austria” profile
To further validate the generalization capability of the proposed model, we employed a test example known as the “Austria” profile to evaluate the trained segmentation model. The “Austria” profile differs significantly from the profiles present in the MNIST training database, as shown in Fig. 8 (a). It consists of two disks and a ring. Both disks have radii of 0.2 m and are centered at coordinates (0.3, 0.6) m and (0.3, 0.6) m, respectively. The inner and outer radii of the ring measure 0.3 m and 0.6 m, respectively. The relative permittivity of the target is specified as 1.1.
The segmentation networks trained on the MNIST dataset in Test 2 were utilized to reconstruct this target. As shown in Fig. 8, the results demonstrate that after incorporating the unlabeled data, the GAN-based SSL can effectively approximate the position, size, and shape of the unseen scattering target. This highlights its superior generalization ability and robustness.
5 CONCLUSION
In this study, we propose a SSL model based on the GAN architecture. This model uses DT images as input instead of scattering data and leverages adversarial generation training to effectively utilize unlabeled data, thereby significantly improving the segmentation quality of scatters in DT images. DT relies on the fast Fourier transform (FFT), with a computational complexity of only . This efficiency satisfies the timeliness requirements for real-time imaging. Regarding GAN components, while the offline training phase is time-consuming, particularly during semi-supervised adversarial training, the online inference phase is relatively rapid. The integration of GPU acceleration and other advanced technologies ensures that the system can effectively meet the demands of real-time imaging. In practical applications, factors such as sensor noise, antenna position errors, and environmental disturbances may degrade image quality. To enhance imaging stability in complex environments, multi-physical field inversion combined with data from other sensors (e.g., optical or infrared) can be explored. In the experimental section, the model’s generalization capability for unknown targets has been validated using the MNIST dataset and the “Austria” profile test. However, the diversity of scatterer materials, shapes, and background media in real-world scenarios presents challenges. To address this issue, future work will focus on incorporating more sophisticated physical simulations (such as inhomogeneous backgrounds and multi-target coupling) during the training phase to improve the model’s adaptability to complex scenes.
References
[1] R. W. King, M. Owens, and T. T. Wu, Lateral Electromagnetic Waves: Theory and Applications to Communications, Geophysical Exploration, and Remote Sensing. Berlin: Springer Science & Business Media, 2012.
[2] R. Streich, “Controlled-source electromagnetic approaches for hydrocarbon exploration and monitoring on land,” Surveys in Geophysics, vol. 37, pp. 47–80, 2016.
[3] R. Kramme, K.-P. Hoffmann, and R. S. Pozos, Springer Handbook of Medical Technology. Berlin: Springer Science & Business Media, 2011.
[4] M. Maier, S. Paul, M. Rother, S. Di Meo, M. Pasian, J. Schoebel, and V. Issakov, “Microwave imaging for breast cancer detection-a comparison between VNA and FMCW radar,” IEEE Journal of Microwaves, vol. 5, no. 2, pp. 291–304, 2025.
[5] R. Chandra, H. Zhou, I. Balasingham, and R. M. Narayanan, “On the opportunities and challenges in microwave medical sensing and imaging,” IEEE Transactions on Biomedical Engineering, vol. 62, no. 7, pp. 1667–1682, 2015.
[6] M. Salucci, M. Arrebola, T. Shan, and M. Li, “Artificial Intelligence: New frontiers in real-time inverse scattering and electromagnetic imaging,” IEEE Transactions on Antennas and Propagation, vol. 70, no. 8, pp. 6349–6364, 2022.
[7] X. Liu, K. Zheng, and J. Li, “An electromagnetic scattering mechanism recognition method based on deep learning,” Applied Computational Electromagnetics Society (ACES) Journal, vol. 40, no. 01, pp. 10–19, Jan. 2025.
[8] C. X. Yang, J. J. Meng, S. Wei, and M. S. Tong, “A dual-input electromagnetic inverse scattering algorithm based on improved U-Net”, Applied Computational Electromagnetics Society (ACES) Journal, vol. 39, no. 11, pp. 961–969, Nov. 2024.
[9] Z. Wei and X. Chen, “Deep-learning schemes for full-wave nonlinear inverse scattering problems,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 4, pp. 1849–1860, 2018.
[10] X. Chen, Computational Methods for Electromagnetic Inverse Scattering. Hoboken, NJ: John Wiley & Sons, 2018.
[11] Y. Sanghvi, Y. Kalepu, and U. K. Khankhoje, “Embedding deep learning in inverse scattering problems,” IEEE Transactions on Computational Imaging, vol. 6, pp. 46–56, 2019.
[12] P. M. Van Den Berg and R. E. Kleinman, “A contrast source inversion method,” Inverse Problems, vol. 13, no. 6, p. 1607, 1997.
[13] X. Chen, “Subspace-based optimization method for solving inverse-scattering problems,” IEEE Transactions on Geoscience and Remote Sensing, vol. 48, no. 1, pp. 42–49, 2009.
[14] K. Xu, L. Wu, X. Ye, and X. Chen, “Deep learning-based inversion methods for solving inverse scattering problems with phaseless data,” IEEE Transactions on Antennas and Propagation, vol. 68, no. 11, pp. 7457–7470, 2020.
[15] X. Ye, N. Du, D. Yang, X. Yuan, R. Song, S. Sun, and D. Fang, “Application of generative adversarial network-based inversion algorithm in imaging 2-D lossy biaxial anisotropic scatterer,” IEEE Transactions on Antennas and Propagation, vol. 70, no. 9, pp. 8262–8275, 2022.
[16] N. Karaliolios, F. Chabot, C. Dupont, H. Le Borgne, Q.-C. Pham, and R. Audigier, “Generalized pseudo-labeling in consistency regularization for semi-supervised learning,” in 2023 IEEE International Conference on Image Processing (ICIP), pp. 525–529, 2023.
[17] P. Wang, J. Peng, M. Pedersoli, Y. Zhou, C. Zhang, and C. Desrosiers, “CAT: Constrained adversarial training for anatomically-plausible semi-supervised segmentation,” IEEE Transactions on Medical Imaging, vol. 42, no. 8, pp. 2146–2161, 2023.
[18] X. Xie, J. Niu, X. Liu, Q. Li, Y. Wang, and S. Tang, “DK-consistency: A domain knowledge guided consistency regularization method for semi-supervised breast cancer diagnosis,” in 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp. 3435–3442, 2021.
[19] W. C. Chew, Waves and Fields in Inhomogenous Media. Hoboken, NJ: John Wiley & Sons, 1999.
[20] J. D. Shea, P. Kosmas, S. C. Hagness, and B. D. Van Veen, “Contrast-enhanced microwave breast imaging,” in 2009 13th International Symposium on Antenna Technology and Applied Electromagnetics and the Canadian Radio Science Meeting, pp. 1–4, 2009.
[21] C. Yang, J. Zhang, and M. S. Tong, “An FFT-accelerated particle swarm optimization method for solving far-field inverse scattering problems,” IEEE Transactions on Antennas and Propagation, vol. 69, no. 2, pp. 1078–1093, 2020.
[22] A. Onufriev, D. A. Case, and D. Bashford, “Effective Born radii in the generalized Born approximation: The importance of being perfect,” Journal of Computational Chemistry, vol. 23, no. 14, pp. 1297–1304, 2002.
[23] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020.
[24] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5–9, 2015, Proceedings, Part III 18, pp. 234–241, 2015.
[25] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” in Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19, 2018.
[26] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778, 2016.
[27] C. X. Yang, X. Yang, J. Zhang, C. Zhou, and M. S. Tong, “An electromagnetic imaging algorithm based on generative adversarial network for limited observation angle,” Applied Computational Electromagnetics Society (ACES) Journal, vol. 40, no. 8, pp. 702–713, Aug. 2025.
[28] L. Han, Y. Huang, H. Dou, S. Wang, S. Ahamad, H. Luo, Q. Liu, J. Fan, and J. Zhang, “Semi-supervised segmentation of lesion from breast ultrasound images with attentional generative adversarial network,” Computer Methods and Programs in Biomedicine, vol. 189, p. 105275, 2020.
[29] Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 60–612, 2004.
[30] A. Tarvainen and H. Valpola, “Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results,” Advances in Neural Information Processing Systems, vol. 30, 2017.
Biographies

Chun Xia Yang received the Ph.D. degree in electronic science and technology from Tongji University, Shanghai, China, in 2017. During her doctoral studies, she also conducted research at the Department of Electrical and Computer Engineering, University of Illinois at Urbana-Champaign, Champaign, IL, USA as a visiting student between 2014 and 2016. She is currently an associate professor at the Department of Communication Engineering, Shanghai Normal University, Shanghai, China. Her ongoing research interests primarily revolve around electromagnetic inverse scattering for imaging and computational electromagnetics.

Chi Zhou received the M.S. degree in Electronic Information from Shanghai Normal University, Shanghai, China, in 2025. He is currently affiliated with Wenyin Cloud Computing Co., Ltd, Shanghai, China. His research mainly focuses on electromagnetic inverse scattering.

Shuang Wei received the B.S. degree and the M.S. degree from the Huazhong University of Science and Technology, Wuhan, China, in 2005 and 2007 respectively, and the Ph.D. degree in electrical and computer engineering from the University of Calgary, Calgary, Canada, in 2011. She is now an Associate Professor with College of Information, Mechanical and Electrical Engineering, Shanghai Normal University, Shanghai, China. From 2021 to 2022, she was a Visiting Scholar at the Shanghai Key Laboratory of Navigation and Location-based Services, School of Sensing Science and Engineering, School of Electronic Information and Electrical Engineering, Shanghai Jiao Tong University, Shanghai, China. Her current research interests include array signal processing, signal estimation and detection, computational intelligence, and compressed sensing.

Mei Song Tong received the B.S. and M.S. Degrees from Huazhong University of Science and Technology, Wuhan, China, respectively, and Ph.D. degree from Arizona State University, Tempe, Arizona, USA, all in electrical engineering. He is currently a Humboldt Awardee Professor in the Chair of High-Frequency Engineering, Technical University of Munich, Munich, Germany, and is on leave from the Distinguished/Permanent Professor and Head of Department of Electronic Science and Technology, and Vice Dean of College of Microelectronics, Tongji University, Shanghai, China. He has also held an adjunct professorship at the University of Illinois at Urbana-Champaign, Urbana, Illinois, USA, and an honorary professorship at the University of Hong Kong, China. He has published more than 700 papers in refereed journals and conference proceedings and co-authored eight books or book chapters. His research interests include electromagnetic field theory, antenna theory and technique, modeling and simulation of RF/microwave circuits and devices, interconnect and packaging analysis, inverse electromagnetic scattering for imaging, and computational electromagnetics.
Prof. Tong is a Fellow of IEEE, Fellow of the Electromagnetics Academy, Fellow of the Japan Society for the Promotion of Science (JSPS), and Fellow of International Academy of Artificial Intelligence Sciences (AAIS). He has been the chair of Shanghai Chapter since 2014 and the chair of SIGHT committee in 2018, respectively, in IEEE Antennas and Propagation Society. He has served as an associate editor or guest editor for several well-known international journals, including IEEE Antennas and Propagation Magazine, IEEE Transactions on Antennas and Propagation, IEEE Transactions on Components, Packaging and Manufacturing Technology, International Journal of Numerical Modeling: Electronic Networks, Devices and Fields, Progress in Electromagnetics Research, and Journal of Electromagnetic Waves and Applications. He also frequently served as a session organizer/chair, technical program committee member/chair, and general chair for some prestigious international conferences. He was the recipient of a Visiting Professorship Award from Kyoto University, Japan, in 2012, and from University of Hong Kong, China, 2013. He advised and coauthored 15 papers that received the Best Student Paper Award from different international conferences. He was the recipient of the Travel Fellowship Award of USNC/URSI for the 31th General Assembly and Scientific Symposium (GASS) in 2014, Advance Award of Science and Technology of Shanghai Municipal Government in 2015, Fellowship Award of JSPS in 2016, Innovation Award of Universities’ Achievements of Ministry of Education of China in 2017, Innovation Achievement Award of Industry-Academia-Research Collaboration of China in 2019, “Jinqiao” Award of Technology Market Association of China in 2020, Baosteel Education Award of China in 2021, Carl Friedrich von Siemens Research Award of the Alexander von Humboldt Foundation of Germany in 2023, and Technical Achievement Award of Applied Computational Electromagnetic Society (ACES) of USA in 2024. In 2018, he was selected as the Distinguished Lecturer (DL) of IEEE Antennas and Propagation Society for 2019–2022, and in 2024–2025, he was selected to the Top Scientists List for both Career-Long Impact and Single-Year Impact by Elsevier and Stanford University.
ACES JOURNAL, Vol. 41, No. 01, 38–47
DOI: 10.13052/2026.ACES.J.410105
© 2026 River Publishers