Air-to-Ground Path Loss Modeling in UAV Networks Via GSA-Based Hyperparameter Optimization
Pham Thi Quynh Trang1, 2, Nguyen Thi Phuoc Van3, Duong Thi Hang4, Dinh Trieu Duong2,*, and Trinh Anh Vu2
1Department of Electronic Engineering Hanoi University of Industry, Hanoi, 100000, Vietnam pham.trang@haui.edu.vn
2Department of Electronic and Telecommunication Engineering Vietnam National University, Hanoi, 100000, Vietnam duongdt@vnu.edu.vn, vuta@vnu.edu.vn
∗Corresponding Author
3Department of Information Technology Thanh Do University, Hanoi, 100000, Vietnam ntpvan@thanhdouni.edu.vn
4Department of Electronic and Telecommunication Engineering Electric Power, Hanoi, 100000, Vietnam hangdt_dtvt@epu.edu.vn
Submitted On: August 07, 2025; Accepted On: April 17, 2026
ABSTRACT
In Unmanned Aerial Vehicle (UAV) communications, Air-to-Ground (A2G) channel modeling is complex due to high mobility and environmental dynamics. While Machine Learning (ML) and Deep Learning (DL) techniques have been adopted to improve prediction accuracy over traditional empirical models, their performance remains highly dependent on hyperparameter configuration. Recent techniques such as Random Search and Bayesian Search are commonly used for hyperparameter tuning; however, they often struggle with convergence efficiency and prediction stability. To address these challenges, this study aims to develop a hyperparameter tuning framework based on the Gravitational Search Algorithm (GSA) to enhance the predictive performance of ML-based A2G models. The framework is applied to K-Nearest Neighbors (KNN), Decision Tree (DT), Random Forest (RF), and Long Short-Term Memory (LSTM) models at 1 GHz, 2 GHz, and 5.8 GHz. Experimental results demonstrate that GSA-optimized models demonstrate improved predictive stability and competitive accuracy, with GSA-LSTM and GSA-RF achieving an Root Mean Square Error (RMSE) of 5.46 dB, representing a improvement over the free-space model. The proposed approach demonstrates improved robustness compared to conventional search strategies.
Keywords: Air-to-Ground channel modeling, Bayesian search, deep learning, gravitational search algorithm, hyperparameter optimization, machine learning, path-loss prediction, random search, unmanned aerial vehicles..
1 INTRODUCTION
The rapid expansion of 5G and the emergence of beyond-5G (B5G/6G) networks are driving an unprecedented increase in wireless traffic and intensifying the need for adaptable, high-capacity communication infrastructures [1]. Among emerging technologies, UAV have become a prominent trend due to their flexible deployment, strong line-of-sight connectivity, and effectiveness in enhancing coverage, disaster recovery, and capacity offloading in dense urban environments. As these cutting-edge systems transition toward 6G, the integration of intelligent and autonomous components becomes essential to manage the dynamic nature of A2G links [2, 3].
Accurate A2G path-loss (PL) modeling is critical for UAV-assisted communication, as it directly influences link budget design, coverage estimation, and interference management [4]. Traditional PL models, such as empirical, deterministic, and analytical, often struggle to capture the complexity of A2G propagation, particularly in dense urban scenarios. Empirical models (e.g., Log-Distance, Okumura–Hata) fit measurement-based path-loss formulas, offering simplicity and fast computation. Their accuracy, however, is limited to the environments and frequencies used for calibration, making them poorly suited for highly variable A2G channels.
Deterministic models, particularly ray-tracing techniques, rely on physical propagation laws and detailed three-dimensional environmental information to achieve high prediction accuracy. However, their practical applicability is often constrained by substantial computational complexity and the requirement for high-resolution geographical data, which limit scalability in large-scale or dynamically evolving environments [5, 6, 7]. Consequently, recent research has increasingly focused on ML and DL-based path-loss modeling approaches, which have demonstrated strong predictive capability across diverse propagation scenarios [8, 9, 10].
Despite these advancements, the performance of ML/DL models remains highly sensitive to hyperparameter configuration. It is widely recognized that hyperparameter optimization (HPO) plays a critical role in influencing convergence behavior, generalization performance, and training efficiency [11]. In the context of ML-based path-loss prediction, hyperparameter tuning is frequently conducted through manual adjustment or conventional search strategies, which may result in suboptimal convergence and increased computational burden, particularly in complex A2G propagation environments. Furthermore, a unified and systematic optimization framework capable of consistently supporting heterogeneous ML and DL architectures under varying propagation conditions has not been comprehensively investigated.
To address these challenges, this paper proposes a hyperparameter optimization framework based on the GSA for A2G path-loss prediction. The main contributions are:
(i) Development of a GSA-based hyperparameter optimization framework for KNN, DT, and RF models.
(ii) Architecture and hyperparameter optimization for LSTM, including the number of neurons, learning rate, and training epochs.
(iii) A comprehensive evaluation of KNN, DT, RF, and LSTM models for A2G PL prediction using a publicly available dataset in dense urban environments.
The rest of this paper is organized as follows. Section 2 introduces the system model, while section 3 presents the path-loss modeling approach. Section 4 formulates the optimization problem, and section 5 describes the proposed GSA-based solution. Numerical results and discussions are provided in section 6, and conclusions are drawn in section 7.
2 SYSTEM MODEL
2.1 UAV-to-Ground Link
The system model is illustrated in Fig. 1. A communication link is established between a UAV and ground receivers. The UAV hovers at an altitude of 200 meters, while the receivers are located 2 meters above ground. The A2G communication channel is characterized by three key parameters: the distance between the UAV and the receiver, the elevation angle formed by the transmitter-receiver line, and the carrier frequency. In this work, the carrier frequencies of 1 GHz, 2 GHz, and 5.8 GHz are investigated.
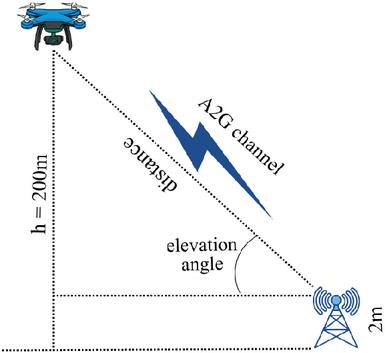
Figure 1 The system model.
2.2 The data set
The dataset utilized in this study was obtained from the publicly available Mendeley Data repository [12], which is associated with the work reported in [7]. The dataset was originally generated through electromagnetic ray-tracing simulations using Wireless Insite in a dense urban environment. The surveyed region covers approximately 0.748 km² and includes 1,419 buildings, predominantly high-rise structures. It comprises 36,753 propagation samples collected at carrier frequencies of 1 GHz, 2 GHz, and 5.8 GHz. Each record contains parameters such as the 3D UAV–receiver distance, elevation angle, and measured path loss.
In this work, the dataset is used solely to evaluate the proposed GSA-based hyperparameter tuning framework. No additional simulation or virtual laboratory platform was developed or accessed by the authors.
Each data record consists of the following features: distance, elevation angle, carrier frequency, and receiver location (altitude and 3D coordinates). After preprocessing, the dataset is randomly split into training and testing sets in an 80/20 ratio.
3 PATH LOSS MODELING
Accurate modeling of path loss is essential for predicting the performance of A2G channels. In this study, both traditional free-space models and machine learning-based approaches are considered.
3.1 The free space model
The free space path loss (FSPL) model is commonly used as a baseline for channel loss estimation. The path loss is expressed as:
| (1) |
Where stands for the route loss calculated for free space propagation using Friis’ law at a reference distance of one meter.
| (2) |
Where: c is speed of light; f is carrier frequency; is the path loss exponent; and is the shadow fading obey Gaussian distribution with zero mean 0 and standard deviation of [13].
Although FSPL provides a simple estimate, it cannot capture complex urban propagation effects, motivating the use of machine learning models.
3.2 Machine learning-based path loss prediction
Machine learning has recently been applied to model path loss under complex propagation conditions. The performance of each ML model depends on factors such as the dataset, algorithm, network architecture, and hyperparameters. While certain parameters can adjust automatically during training, key hyperparameters, such as the number of layers, number of neurons, and learning rate, must be defined in advance and have a substantial influence on overall model performance [14, 15].
Common hyperparameter optimization methods include:
Grid Search performs an exhaustive evaluation of all defined hyperparameter combinations to identify the optimal model. However, this brute-force approach is often computationally prohibitive and time-consuming [16].
Random Search (RS) improves efficiency by randomly sampling hyperparameters but fails to utilize historical performance data to guide the optimization process, resulting in limited convergence efficiency [17].
Bayesian Optimization (BO) is an informed search strategy that builds a probabilistic surrogate model to guide the selection of hyperparameters based on past evaluations. This iterative learning process makes it highly effective for complex, high-dimensional search spaces where exhaustive testing is infeasible [18].
Metaheuristic algorithms, such as Genetic Algorithm (GA) and Particle Swarm Optimization (PSO), are widely used for complex hyperparameter optimization. GA mimics evolutionary processes but often suffers from slow convergence [19, 20]. Conversely, PSO leverages swarm intelligence for faster convergence but remains sensitive to initialization and prone to local optima trapping [21].
In this work, the GSA is utilized due to its algorithmic simplicity and demonstrated global search capability. It is proposed as an efficient solution for the specific task of ML hyperparameter tuning, providing researchers with another reliable option for accurate A2G path loss estimation.
4 PROBLEM FORMULATION
Let and denote the observed and predicted path loss values, respectively. Let denote the hyperparameter search space and represent a candidate hyperparameter vector. The HPO problem is formulated as minimizing the mean absolute error (MAE):
| (3) |
This formulation constitutes a non-convex optimization problem, where the search space typically contains mixed continuous, discrete, and categorical variables. Given the high dimensionality and non-linearity of this space, conventional tuning strategies are often computationally inefficient or prone to suboptimal convergence. Therefore, a global optimization strategy is required to effectively explore the feasible set . In the next section, the GSA is introduced as a suitable metaheuristic framework to address this challenging optimization problem.
5 PROPOSED APPROACH
5.1 Gravitational search algorithm
The GSA is a population-based metaheuristic inspired by Newton’s law of gravity and mass interactions [22]. In GSA, each agent (candidate solution) is treated as an object whose mass reflects the quality of its solution. Better solutions correspond to heavier masses that exert stronger gravitational forces, attracting other agents towards promising regions of the complex search space. This mechanism facilitates simultaneous exploration (global search) and exploitation (local refinement).The gravitational force exerted by agent on agent at time is calculated based on their masses and distance:
| (4) |
where is the gravitational constant, represents the masses, is the Euclidean distance between agents and , and is a small constant. The net force () acting on agent is the randomized sum of forces from all better agents (Kbest).
| (5) |
The acceleration () and subsequent velocity () are updated based on the net force and inertial mass:
| (6) |
Finally, the agent’s position , which represents the candidate solution, is updated:
| (7) |
GSA has been widely used in various optimization tasks, including hyperparameter tuning in machine learning [23, 24]. However, to the best of our knowledge, no prior work has applied GSA to the HPO problem for A2G channel modeling. In this study, GSA is selected for its simplicity and strong global search capability, which make it well-suited for non-convex optimization. In the A2G path-loss HPO problem, each agent encodes a candidate hyperparameter vector, and its fitness is evaluated based on the model’s prediction error (Equation 3). Through iterative updates, GSA effectively explores the search space to identify near-optimal configurations, thereby improving model accuracy and generalization.
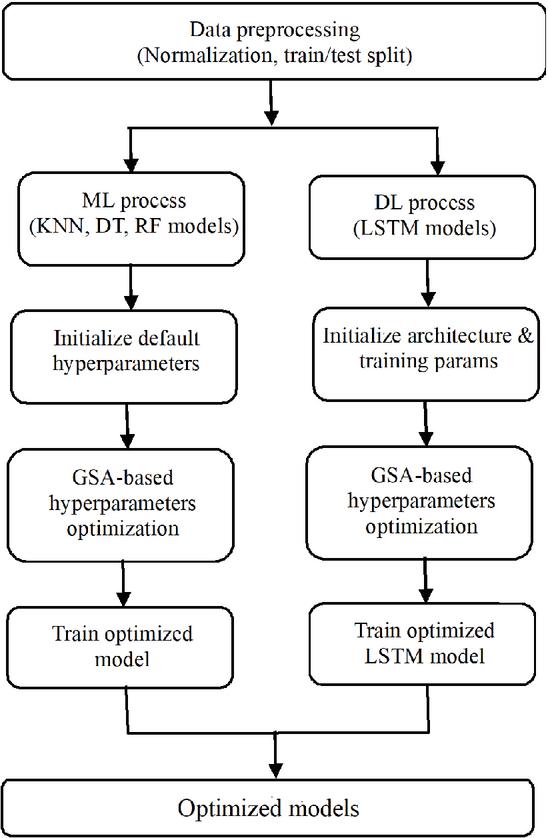
Figure 2 Proposed GSA-ML/DL process.
5.2 The hyperparameter tuning algorithm
In machine learning, hyperparameters are predefined configuration variables that control the training process and model structure, such as the number of layers, the number of neurons, or the learning rate. Proper selection of hyperparameters significantly influences model accuracy and generalization performance.
Figure 2 presents the detailed workflow of the proposed GSA-based hyperparameter tuning algorithm for A2G path loss prediction. The process begins with data preprocessing, including normalization and train–test splitting. The preprocessed dataset is then distributed into two parallel branches corresponding to conventional ML models and DL models.
In the ML branch, KNN, DT, and RF models are first initialized with default hyperparameters. In parallel, the DL branch initializes the LSTM architecture and its associated training parameters.
For both branches, hyperparameter tuning is formulated as a numerical optimization problem and solved using the GSA. The algorithm searches the predefined hyperparameter space by iteratively generating candidate configurations and evaluating them using a prediction error metric computed on the validation data.
Once the optimal hyperparameter set is identified for each model, the models are retrained using the optimized configuration. Finally, the optimized ML and DL models are evaluated and compared to determine the most accurate model for A2G channel prediction.
This structured and parallel tuning strategy ensures consistent hyperparameter optimization across heterogeneous learning paradigms while maintaining fairness in model comparison.
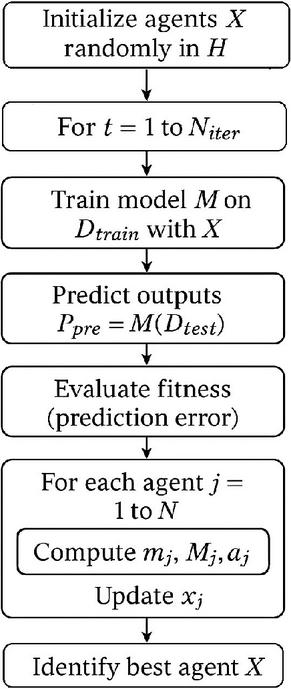
Figure 3 Flowchart of GSA-based hyperparameter optimization.
Set as the hyperparameter vector to be optimized, where is the number of hyperparameters. In the GSA context, each represents an agent’s position.
and denote the training and testing datasets, respectively.
Algorithm 1 HPO via GSA |
Input: k, N (number of agents), (number of iterations), , Output: X = [x1, x2, …, xk], the best hyperparameters 1: Initialize X randomly in 2: For t = 1 to : 3: Train model on with parameters X 4: Predict outputs 5: Evaluate fitness (Equation 3) 6: For each agent j = 1 to N: 7: For each hyperparameter i = 1 to k: 8: Compute (Equation 4–6) 9: Update (Equation 7) 10: End for 11: End for 12: Identify the best agent X 13: End for |
The hyperparameter optimization procedure using GSA is summarized in Algorithm 1.
Figure 3 shows a flowchart of the GSA-based hyperparameter optimization process. The algorithm iteratively updates a population of agents (candidate hyperparameters) based on gravitational forces, evaluates model fitness, and returns the best hyperparameters. The overall time complexity is , where is the number of iterations, is the number of agents, is the number of hyperparameters, and is the model training cost.
6 RESULTS AND DISCUSSION
Predicted values were generated by feeding the held-out test dataset into the trained ML/DL model, while observed values (ground truth) were sourced directly from the target variable of the test data (as described in Section 2.2).
6.1 Performance evaluation
Two statistical properties, namely MAE and RMSE [25], are selected as measures to assess the performance of various models. By comparing the anticipated path loss with the test set’s data, they may be computed as:
| (8) | ||
| (9) |
In this:
denotes the overall count of test samples
is the predicted and is the observed value.
6.2 Hyperparameters tuning for machine learning
This section presents the results of hyperparameter optimization for the RF, KNN, and DT algorithms in predicting path loss. Although each algorithm provides a large set of hyperparameters, not all of them have a significant impact on model performance. Therefore, in this study, we focus on optimizing only the core hyperparameters that directly influence prediction accuracy, such as depth, number of estimators, split criteria, and neighborhood size [26]. This reduces the search space and makes the optimization more efficient while preserving modeling performance. The reduced sets considered in this study are:
Table 1 shows the accuracy based on MAE and RMSE parameters of each model in predicting A2G channel loss when selecting the hyperparameters based on the suggestions of the optimization methods.
Table 1 The accuracy of models
| Optimize Method | Model | MAE | RMSE |
| Default hyperparameters | Decision tree | 4.79 | 7.25 |
| KNN | 5.82 | 7.95 | |
| Random forest | 3.80 | 5.41 | |
| Random Search | Decision tree | 5.76 | 7.89 |
| KNN | 4.13 | 5.81 | |
| Random forest | 5.62 | 7.69 | |
| Bayes Search | Decision tree | 5.83 | 7.98 |
| KNN | 4.09 | 5.93 | |
| Random forest | 4.34 | 5.90 | |
| GSA | Decision tree | 4.49 | 6.43 |
| KNN | 3.98 | 5.59 | |
| Random forest | 3.85 | 5.46 | |
| Free space | 9.29 | 12.63 |
The quantitative results in Table 1 indicate that machine learning models substantially outperform the traditional free-space path-loss model in predicting A2G channel loss. The free-space model yields an MAE of 9.29 dB and an RMSE of 12.63 dB, which are considerably higher than those achieved by data-driven approaches such as DT, KNN, and RF. This confirms that learning-based models are more capable of capturing the complex propagation characteristics in A2G environments.
It can also be observed that default hyperparameter configurations do not consistently provide optimal performance. While the RF model achieves relatively strong results with default parameters (MAE 3.80 dB, RMSE 5.41 dB), the DT and KNN models exhibit noticeable performance gaps under default settings. This highlights the importance of systematic hyperparameter tuning, particularly for models that are sensitive to parameter selection.
To ensure fair comparison, RS, BO, and the proposed GSA-based hyperparameter optimization were conducted within the same search space and using the same dataset. The results show that the GSA-based approach provides competitive and consistently strong performance across different models. For example, the GSA-optimized DT, KNN, and RF models achieve MAE values of 4.49 dB, 3.98 dB, and 3.85 dB, respectively, with corresponding RMSE values of 6.43 dB, 5.59 dB, and 5.46 dB. Although the RF model with default parameters achieves slightly lower RMSE in a single run, the proposed GSA-based framework demonstrates stable and comparable performance across multiple architectures, indicating its effectiveness as a unified and model-independent optimization strategy.
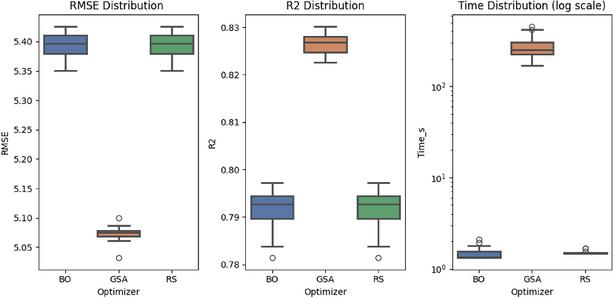
Figure 4 Distribution of RMSE, and execution time for the RF model.
To further analyze the performance characteristics of the optimization strategies, 100 independent runs were conducted for each method (RS, BO, and GSA) using the RF model. RF is selected as a representative ensemble tree-based model due to its practical relevance and sensitivity to hyperparameter configuration.
Figure 4 presents the boxplots of RMSE, , and execution time distributions. Here, denotes the coefficient of determination, which measures the proportion of variance in the target variable explained by the model [25].
The accuracy distributions indicate that the GSA-based approach achieves the lowest median RMSE and the highest median among the compared methods. In addition, the interquartile range (IQR) of GSA is relatively narrower, suggesting reduced variability and more consistent convergence behavior across repeated runs. By contrast, RS and BO exhibit slightly larger dispersion, indicating higher sensitivity to stochastic sampling and initialization.
The runtime analysis shows that GSA requires longer computation time compared to RS and BO, which is expected for population-based metaheuristic algorithms. However, this additional cost occurs during the offline hyperparameter tuning phase and does not affect real-time inference once the optimal configuration is determined. Overall, these results illustrate the trade-off between computational overhead and optimization stability, with the proposed method offering improved robustness at the expense of increased search time.
Table 2 Hyperparameters for LSTM model
| Hyperparameter | Value |
| Number LSTM node | 44 |
| Number Dense node | 35 |
| Learning rate | 0.001 |
| Epoch | 100 |
6.3 Hyperparameter tuning for deep learning
This section presents the results of hyperparameters search for an LSTM-based deep learning model. The path loss prediction model consists of an LSTM layer, a dropout layer, one dense layer, and an output layer. Using Algorithm 1, the searched hyperparameters include the number of LSTM nodes, Dense nodes, and learning rate. A population of 20 agents with 10 iterations was used; the results are summarized in Table 2.
Figure 5 compares the MAE and RMSE of the proposed models with the free space model, showing that machine learning methods achieve significantly higher accuracy. Accuracy depends on the model and chosen hyperparameters. With the recommended hyperparameters, KNN, RF, and LSTM models yield nearly equivalent A2G path loss predictions, confirming the effectiveness of the proposed hyperparameter search achieve.
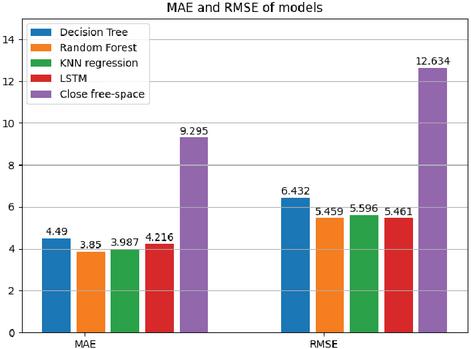
Figure 5 Predictive accuracy of various ML and DL schemes.
In summary, the experimental evaluation demonstrates the effectiveness of the proposed GSA-based hyperparameter tuning algorithm from three complementary perspectives. First, in terms of predictive performance, the optimized models consistently achieve improved accuracy across different learning architectures, with substantial RMSE reduction compared to the traditional free-space model and competitive results relative to RS and BO. Second, the robustness analysis based on 100 independent runs confirms that the proposed approach provides enhanced convergence stability and reduced variability, as reflected by narrower interquartile ranges and higher median values. Third, the framework exhibits strong generalizability, as it successfully enhances both conventional machine learning models and deep learning architectures such as LSTM. While the proposed GSA-based approach improves predictive performance and robustness, like other population-based metaheuristic algorithms, it does not provide a strict mathematical guarantee of global optimality. Nevertheless, its empirical results demonstrate clear and consistent advantages over conventional search strategies. Collectively, these findings indicate that the proposed method serves not merely as a model-specific tuning strategy, but as a systematic and architecture-independent optimization framework suitable for reliable A2G path-loss modeling in UAV communication systems.
7 CONCLUSION
This study proposes a machine learning-based framework for predicting A2G path loss between a UAV and a ground-based user device. In addition, a HPO approach based on the GSA is developed to automate model configuration and improve predictive performance. Numerical results show that the GSA-optimized hyperparameters enhance the accuracy of the A2G path-loss prediction model compared with default configurations and conventional optimization strategies, such as RS and BO. Future work will extend the proposed framework to multi-UAV scenarios and more complex propagation environments to better reflect practical deployment conditions. Furthermore, deep learning models tailored for terahertz (THz) band communications will be investigated, where propagation characteristics exhibit heightened sensitivity to environmental factors.
REFERENCES
[1] M. Z. Chowdhury, M. Shahjalal, S. Ahmed, and Y. M. Jang, “6G wireless communication systems: Applications, requirements, technologies, challenges, and research directions,” IEEE Open Journal of the Communications Society, vol. 1, pp. 957–975, 2020.
[2] O. T. H. Alzubaidi, M. N. Hindia, K. Dimyati, K. A. Noordin, A. N. A. Wahab, F. Qamar, and R. Hassan, “Interference challenges and management in B5G network design: A comprehensive review,” Electronics, vol. 11, 2022.
[3] B. Li, Z. Fei, and Y. Zhang, “UAV communications for 5G and beyond: Recent advances and future trends,” IEEE Internet of Things Journal, vol. 6, no. 2, pp. 2241–2263, 2019.
[4] M. Polese, M. Giordani, T. Zugno, A. Roy, S. Goyal, D. Castor, and M. Zorzi, “Integrated access and backhaul in 5G mmWave networks: Potential and challenges,” IEEE Communications Magazine, vol. 58, no. 3, pp. 62–68, 2020.
[5] T. S. Rappaport, Y. Xing, G. R. MacCartney, A. F. Molisch, E. Mellios, and J. Zhang, “Overview of millimeter wave communications for fifth-generation (5G) wireless networks—with a focus on propagation models,” IEEE Transactions on Antennas and Propagation, vol. 65, no. 12, pp. 6213–6230, 2017.
[6] Q. Zhu, M. Yao, F. Bai, X. Chen, W. Zhong, B. Hua, and X. Ye, “A general altitude-dependent path loss model for UAV-to-ground millimeter-wave communications,” Front Inform Technol Electron Eng 22, vol. 22, p. 767–776, 2021.
[7] N. E.-D. Safwat, F. Newagy, and I. M. Hafez, “Air-to-ground channel model for UAVs in dense urban environments,” IET Communications, vol. 14, pp. 1751–8628, 2020.
[8] K. J. Jang, S. Park, J. Kim, Y. Yoon, C.-S. Kim, Y.-J. Chong, and G. Hwang, “Path loss model based on machine learning using multi-dimensional Gaussian process regression,” IEEE Access, vol. 10, pp. 115061–115073, 2022.
[9] A. Tahat, T. Edwan, H. Al-Sawwaf, J. Al-Baw, and M. Amayreh, “Simplistic machine learning-based air-to-ground path loss modeling in an urban environment,” in 2020 Fifth International Conference on Fog and Mobile Edge Computing (FMEC), pp. 177–183, IEEE, Paris, France, 2020.
[10] J. Ethier and M. Chateauvert, “Machine learning-based path loss modeling with simplified features,” IEEE Antennas and Wireless Propagation Letters, vol. 23, no. 7, pp. 2238–2242, 2024.
[11] B. Bischl and M. Binder, “Hyperparameter optimization: Foundations, algorithms, best practices, and open challenges,” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 13, no. 2, p. e1484, 2023.
[12] N. E.-D. Safwat, “Path loss data for UAV channel modeling,” Mendeley Data, 2021.
[13] T. S. Rappaport, Y. Xing, G. R. MacCartney, A. F. Molisch, E. Mellios, and J. Zhang, “Overview of millimeter wave communications for fifth-generation (5G) wireless networks—with a focus on propagation models,” IEEE Transactions on Antennas and Propagation, vol. 65, no. 12, pp. 6213–6230, 2017.
[14] E. Elgeldawi, A. Sayed, A. R. Galal, and A. M. Zaki, “Hyperparameter tuning for machine learning algorithms used for Arabic sentiment analysis,” Informatics, vol. 8, no. 4, p. 79, 2021.
[15] P. Probst, A.-L. Boulesteix, and B. Bischl, “Tunability: Importance of hyperparameters of machine learning algorithms,” Journal of Machine Learning Research, vol. 20, no. 53, pp. 1–32, 2019.
[16] P. R. Lorenzo, J. Nalepa, M. Kawulok, L. S. Ramos, and J. Ranilla, “Particle swarm optimization for hyper-parameter selection in deep neural networks,” in Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’17, pp. 481–488, 2017.
[17] J. Bergstra and Y. Bengio, “Random search for hyper-parameter optimization,” Journal of Machine Learning Research, vol. 13, no. 10, pp. 281–305, 2012.
[18] V. Nguyen, “Bayesian optimization for accelerating hyper-parameter tuning,” in 2019 IEEE Second International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), pp. 302–305, 2019.
[19] F. G. Lobo, D. E. Goldberg, and M. Pelikán, “Time complexity of genetic algorithms on exponentially scaled problems,” in Annual Conference on Genetic and Evolutionary Computation, pp. 151–158, Morgan Kaufmann Publishers, Las Vegas, Nevada, USA, 2000.
[20] F. Itano, M. A. de Abreu de Sousa, and E. Del-Moral-Hernandez, “Extending MLP ANN hyper-parameters optimization by using genetic algorithm,” in 2018 International Joint Conference on Neural Networks (IJCNN), pp. 1–5, IEEE, Rio de Janeiro, Brazil, 2018.
[21] L. Yang and A. Shami, “On hyperparameter optimization of machine learning algorithms: Theory and practice,” Neurocomputing, vol. 415, pp. 295–316, 2020.
[22] A. Hashemi, M. B. Dowlatshahi, and H. Nezamabadi-Pour, “Gravitational search algo rithm: Theory, literature review, and applications,” Handbook of AI-based Metaheuristics, pp. 119–150, 2021.
[23] D. Ezzat, A. E. Hassanien, and H. A. Ella, “An optimized deep learning architecture for the diagnosis of COVID-19 disease based on gravitational search optimization,” Applied Soft Computing, vol. 98, pp. 106742–106742, 2020.
[24] W. M. Alenazy and A. S. Alqahtani, “Gravitational search algorithm based optimized deep learning model with diverse set of features for facial expression recognition,” J Ambient Intell Human Comput, vol. 13, no. 2, pp. 829–844, 2020.
[25] J. Isabona and V. M. Srivastava, “Hybrid neural network approach for predicting signal propagation loss in urban microcells,” in 2016 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), pp. 1–6, IEEE, Agra, India, 2016.
[26] scikit learn. (2025). User Guide [Online]. Available: https://scikitlearn.org/stable/user_guide.html
BIOGRAPHIES

Pham Thi Quynh Trang received the B.S. and M.S. degrees from VNU University of Engineering and Technology in 2000 and 2006, respectively. She is currently pursuing a Ph.D. degree in telecommunication engineering at VNU. She is interested in wireless communication, wireless sensor network optimization algorithms, digital signal processing, neural networks, applications of nature-inspired algorithms, and FPGA technology.

Nguyen Thi Phuoc Van completed her doctoral degree at Massey University in New Zealand in 2020, specializing in the School of Engineering and Advanced Technology. From 2020 to 2022, she worked as a researcher at the Big Data Integration Research Center at the National Institute of Information and Communications Technology (NICT) in Japan. She was a research fellow at the Centre for Health Research, University of Southern Queensland, Australia, from 2022 to 2024. Currently, she is a lecturer at Thanh Do University in Hanoi, Vietnam. Her research interests encompass communication systems, vital signs sensing systems, sensing technology for monitoring human healthcare conditions, and the application of artificial intelligence in communication and healthcare navigator systems.

Duong Thi Hang has been a lecturer at the Faculty of Electronic Engineering, Hanoi University of Industry since 2000. She received the B.S and M.S. degrees from VNU University of Engineering and Technology in 2000 and 2005, respectively. She is currently pursuing a Ph.D. degree in telecommunication engineering at VNU. Her main research interests are indoor positioning systems, machine learning, pattern classification, and nature-inspired algorithm applications.

Dinh Trieu Duong is a lecturer at Wireless Communication Department of VNU University of Engineering and Technology. His main research interests are Signal Processing for Multimedia Communications, Development of High Performance Multimedia Image, Video Codecs for Real-time Image, Video Transmission over Wire/Wireless Networks.

Trinh Anh Vu is a retired Assoc. Prof. at Wireless Communication Department of VNU University of Engineering and Technology. His main research interests are High-speed Transmission in wireless communications, Massive MIMO systems for 5G, Milimeter wave communications, FPGA design of communication System.
ACES JOURNAL, Vol. 41, No. 4, 306–314
DOI: 10.13052/2026.ACES.J.410402
© 2025 River Publishers