GRU Based Time Series Forecast of Oil Temperature in Power Transformer
Haomin Chen1, Lingwen Meng2, Yu Xi1,*, Mingyong Xin2, Siwu Yu2, Guangqin Chen1 and Yumin Chen1
1Digital Grid Research Institute, China Southern Power Grid, Guangzhou, Guangdong, 510000, China
2Electric Power Research Institute of Guizhou Power Grid Co. Ltd., Guiyang, Guizhou, 550000, China
E-mail: xiyu@csg.cn
*Corresponding Author
Received 05 July 2022; Accepted 28 July 2022; Publication 03 January 2023
Abstract
With the continuous progress of the society, the demand for electrical power is urgent. The transformer plays an important role in the power energy transmission. The oil temperature inside transformer effectively could reflect working condition of the transformer, which makes it necessary to monitor and forecast the oil temperature to monitor the operating status of the power transformer. However, the oil temperature time series data generated by the power transformer has the characteristics of being complex and nonlinear. In recent years, long and short time memory networks (LSTM) are often used to predict transformer oil temperature. Gated recurrent unit (GRU) is a new version for LSTM. In the structure of GRU, there exist two gates, which are updating gate and resetting gate, respectively. Compared with LSTM network, The structure of GRU is simpler and its effect is better. A novel predicting method for transformer oil temperature is proposed based on time series theory and GRU in this paper, which is verified on the dataset of the oil temperature of the transformers in the two regions. The experimental results are compared with traditional time series prediction models to demonstrate that the proposed method is effective and feasible.
Keywords: Oil temperature, power transformer, deep learning, LSTM, GRU.
1 Introduction
In the power system, the power transformer is an expensive and key equipment in the transmission and distribution network. In the process of operation, it is easy to suffer the combined impact of thermal, electrical and mechanical stresses, which results in transformer failure [1]. Therefore, the power transformer plays an important role in transmitting electricity flexibly and safely. A picture of normal power transformer is demonstrated in Figure 1. The thermal characteristic is one of the important indications for the secure and stable operation of transformer. A useful indicator to detect the thermal characteristic of transformer is the transformer oil temperature. At present, many substations still use mechanical pointer pressure gauges, whose database is established through manual periodic readings. In addition, the prediction and early warning of parameters are also completed through manual data analysis. Although the automatic collection of transformer oil temperature has been realized, its prediction and early warning are completed through manual data analysis. With the fast progress of power system automation, intelligent forecast of the temperature of power transformer oil is a research field full of research value and theoretical significance [2, 3].

Figure 1 A typical power transformer picture.
Thermal circuit model calculation technology is a traditional forecast method of oil temperature in transformer, and it is fundamentally based on the thermal circuit model calculation of transformer equipment. Through the process of heat transfer inside transformer, the heat path pattern is built to predict the temperature of oil. This method requires detailed equipment parameters and operation parameters. The thermal circuit models of transformers with different types and different working modes are quite different. Incomplete parameters or inaccurate settings will lead to large prediction accuracy error.
There is a certain correlation between transformer oil temperature and other transformer monitoring parameters. Simple linear fitting method can not accurately express the relationship between oil temperature and other transformer monitoring parameters. Machine learning methods has much better nonlinear fitting capability. With machine learning based algorithms, the relationship between transformer working status and oil temperature can be well shown [4]. Commonly used machine learning models include artificial neural network method, support vector machine, etc. [5, 6]. Using machine learning algorithm for modeling, we assume that there is a good correlation between network input and network output, otherwise the model could be easily over fitted and the forecast performance will be poor. At the same time, the model dimension and the model training speed could be affected with more redundant input. Neural network algorithm is a quite significant kind of algorithm in artificial intelligence. It is self-adaptive and self-learning. Neural network algorithm has good nonlinear reflection ability and stable performance. It is more suitable for signal processing, control, pattern recognition and fault diagnosis. The forecast method of oil temperature inside transformer can be realized with neural network algorithm. Some scholars have used BP neural network to forecast the oil temperature inside transformer. He et al. [7] uses neural network to forecast the top oil temperature inside transformer, but the method is a short-term prediction. Qi et al. [8] uses a kernel limit learner and a bootstrap method to obtain top-level oil temperature prediction intervals with different confidence levels. Yu Xi et al. [3] forecast the oil temperature inside transformer with support vector machine (SVM) and the experiment data is transformer’s three-phase load with real and imaginary parts. At the same time, the model parameters are optimized with particle swarm optimization (PSO). Since there exist many factors affecting oil temperature predicting, the authors introduced confidence intervals to decide the forecast results. Wei Rao, et al. [9] introduced an association rules-based oil temperature forecasting method with Bayesian network, which could enhance the predicting capability of RBF-NN. Fei Xiao, et al. [10] proposed a new intelligent forecast method with machine learning methods for timely abnormal oil temperature monitoring. The method built a dynamic association learning model with decision forests algorithm to forecast oil temperatures based on transformer parameters, power load, as well as weather condition under the normal running status.
The oil temperature data generated by the power transformer is a time series sequence. The forecast of oil temperature inside transformer is in nature a time series prediction. Time series forecast analysis is a kind of complex prediction modeling method. It predicts the data information of the event in the future from the event data generated in the past. The time series models rely on the sequence of events. If the order of values of the input changes, the forecast results of model are variable [11], which usually leads to low prediction accuracy of the above prediction method. Today, deep learning methods are widely used in various fields, and time series prediction tasks are no exception. Many DNN models perform much better simple machine learning methods. These deep neural networks (DNN) models include short-term and long-term memory network (LSTM) [12, 13] and gated recurrent unit (GRU) [13]. Three gates exist inside LSTM structure, and they are inputting gate controlling input value, forgetting gate control memory value and output gate controlling output value, respectively. GRU is a new version of LSTM network. Inside the structure of GRU, there exist two kinds of gates and they are updating gate and resetting gate. GRU has simpler structure and better effect than LSTM network, so it is a commonly used network. GRU can also solve the long dependency problem in founded in RNN networks. A major feature of GRU [13] is that it can perform prediction based on historical and current values accurately, which makes it more appropriate to deal with power transformer oil temperature time series prediction problems.
The rest of the paper contains 3 sections. In Section 2, we have a brief description of the RNN, LSTM and GRU algorithms and theories related to our research. In Section 3, we verify our method by the experiments on the dataset of the oil temperature of the transformers in the two regions. In Section 4, we summarize our work and discuss some ideas about improvements of our future work.
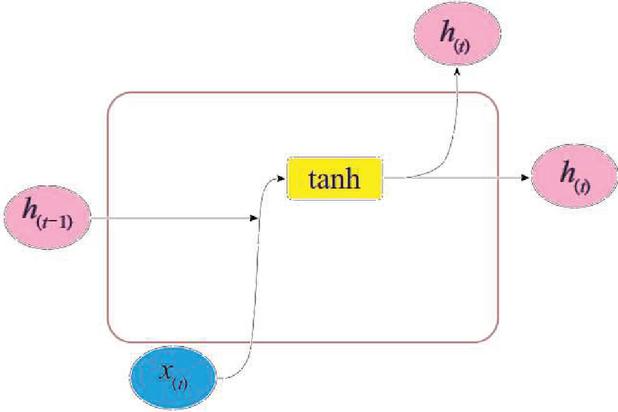
Figure 2 Internal structure of neurons in RNN.
2 Recurrent Neural Network (RNN) and GRU Neural Network
2.1 Structure of Recurrent Neural Network (RNN)
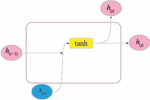
Recurrent neural network(RNN) is different from the traditional feed-forward neural network (FNN). The RNN can process the relationship between the input data before and after the time. In the traditional neural network models, the input data starts from the input layer, through the hidden layers, and at last to the output layer. All of the layers are fully linked, but the nodes in the middle of each layer are not linked. The traditional neural networks can not solve certain problems [13]. For example, it is necessary to predict each word inside a sentence. The next word in the sentence depends on the previous word. However, the words after and before the sentence are not independent, and there is a connection between the words. For a sequence, the output of the RNN will depend on the previous output value. The specific fact is that the existing output in the RNN will remember the previous data and utilize the memorized information in the current input value. Every node in the hidden layer is linked. At the same time, the hidden layer’s input contains the input value at the existing moment and the output value at the previous moment. The typical recurrent neural network structure is depicted in Figure 2. The gradient of standard recurrent neural network will disappear when the error is propagated back. To solve the gradient vanishing problem, we usually choose to use its variant models, such as LSTM [15, 16] and GRU [17]. The structure of the standard recurrent neural network is simple. Figure 3 is the internal structure diagram of the standard RNN. The status value of the neuron at moment t is decided by the status value of the previous moment and the hyperbolic tangent function value of the network input at moment t. This value will not only be used as the output of the existing neuron, but also enter the next neuron as the status value at moment t. It is difficult for the network to remember the information for a quite long range time, and can not judge the “useful” and “useless” of the input signal and the last neuron state value. When the time interval is increasing, LSTM and GRU can resolve the issue that it is very difficult for standard RNN to learn the long-distance dependency in the input sequence.
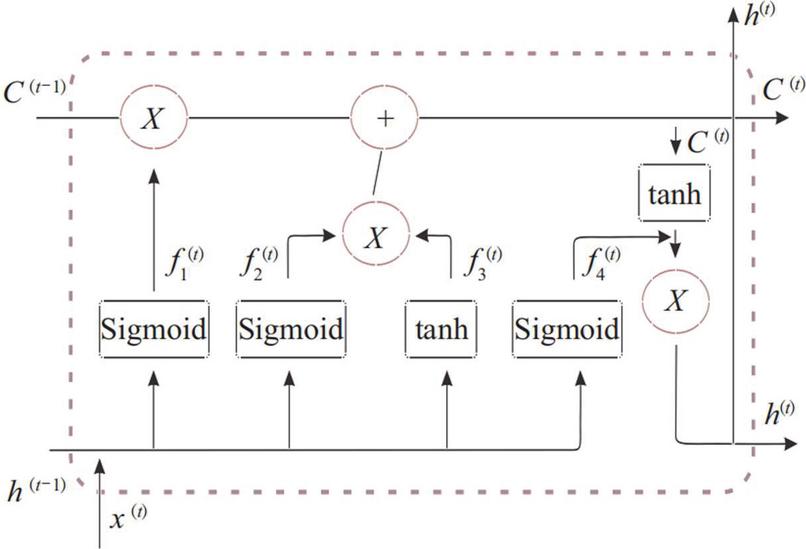
Figure 3 Internal structure of LSTM neurons.
2.2 Structure of Long Short-Term Memory (LSTM) Neural Network
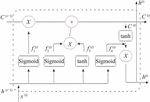
Different from the standard RNN neural network, LSTM and GRU introduce the concept of “gate”, including forget, input and output three gates. Compared with GRU, LSTM has one more “cell state”. Sepp Hochreiter and Jurgen Schmidhuber in 1997 proposed long short-term memory (LSTM) and it gradually improved by a few scholars who are Hasim Sak, Alex Graves, and Wojciech Zaremba. The key idea of LSTM is that the LSTM can learn the storage, and read in the long-term status from it. The LSTM signal transmission process is shown in Figure 3. When the state c of long-term across the network from left to right, it firstly passes through the forgetting gate and loses some storage, and then it adds some new memories (the memory decided by the inputting gate) through adding operation. The result is then directly sent out with no any further transition. Therefore, in every moment procedure, some information gets lost, and some information are added. Following the addition procedure, the long term state is replicated and transmitted through the tanh functionality, and the final result is then sorted out by the output gate. Then the short-term states h is produced.
(1) forgetting gate: as the first gate of the network, it needs to filter the network information and determine the preservation or retention of the information. It is expressed as the following:
| (1) |
(2) inputting gate: the inputting gate is separated into two procedures. One is to select to update the value, and another step is to determine the candidate status to transmit forward. The algorithms of and are as the following:
| (2) | ||
| (3) |
Integrate the information and update the cell status. The output is:
| (4) |
(3) Output gate: the output gate is used to output information. Information is output after processing the cell state and integrating it with the initial information, which can be divided into
| (5) | ||
| (6) |
where are random weights given by the function; is activation function sigmoid value, is state value of the previous neuron; is neuron input value at the moment, are bias values and is neuron cell state at the moment.
2.3 Structure of Gate Recurrent Unit (GRU)
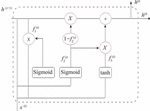
The gate recurrent unit (GRU) neural network is an modified version of long short term memory (LSTM) neural network, and GRU was proposed by CHO kyunghyun (2014) [13]. The most remarkable achievement is to avoid the long dependence problem in recurrent neural networks. However, the structure of LSTM is more complicated, and there are also existing problems such as heavy training time cost and long forecast time. The gate recurrent unit improves the LSTM structure just to solve the above problems. Forgetting gate, inputting gate and outputting gate are proposed in the LSTM neural network. The design of these “Gates” is to remove or enhance the input information into the neural cell unit to control the cell state. The GRU neural network improves the structure design of the “gate”, integrates the forgetting gate and the inputting gate in the LSTM into an updating gate, which optimizes the unit structure originally composed of three gates into a unit structure composed of two gates. Meantime, the cell state has been fused and several extra enhancements have been proposed. In GRU the signal transmission process is depicted in Figure 4.
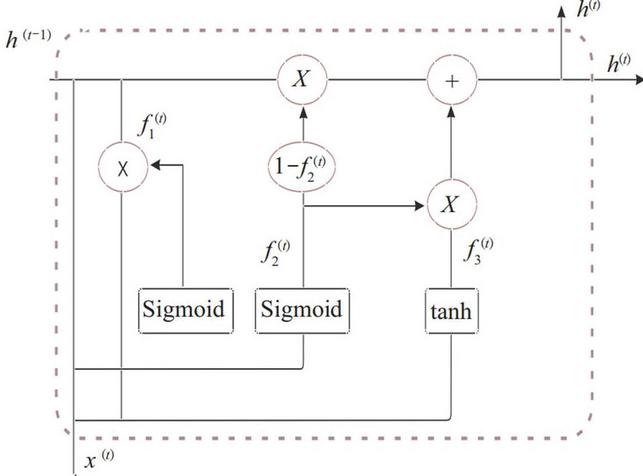
Figure 4 Internal composition of GRU unit.
Resetting gate: is used to control whether the candidate state calculation depends on the state at the previous time. The algorithm is
| (7) |
The candidate status at the current time is
| (8) |
3 Experiment Results and Analysis
3.1 Power Transformer Dataset
The dataset in this manuscript adopts the ETT small data set in the power transformer data set [18]. The ETT-small data set contains data from two power transformers for two years. Each data point marked with m is recorded every minute from two regions in the same Chinese province, called ETT-small-m1 and ETT-small-m2, respectively. In addition, we use h to mark the dataset variants with one hour granularity, namely ETT-small-h1 and ETT-small-h2. Every data point has 8-dimensional characteristics, which are the recording date of the data point, the predicted value oil temperature and six different kinds of external load values. The missing values in the data have been pre-processed with the cleaning method. The data set is very important for the study of the time series data. The data is real and effective, and the amount of data is also very large. The ETT-small-h1, ETT-small-m1, the ETT-small-h2 and ETT-small-m2 dataset are used in the experiments. For each dataset 80% of the data are used as the training dataset and the remaining 20% are employed as the testing dataset for performance comparison.
3.2 Experimental Results Comparison and Analysis
In this manuscript, we use the structure of RNN network in Pytorch to build the LSTM and GRU models. No matter which network structure of RNN, LSTM or GRU, they have unified requirements for input, and the input data are sequential data. The hyper parameters setting are that input_dim is 15, hidden_dim is 2048, num_layers is 1 and output_dim is 1. The loss function use MSELoss() and the optimizer uses Adam. The learning rate used is 0.00001. The proposed method diagram is shown in Figure 5.
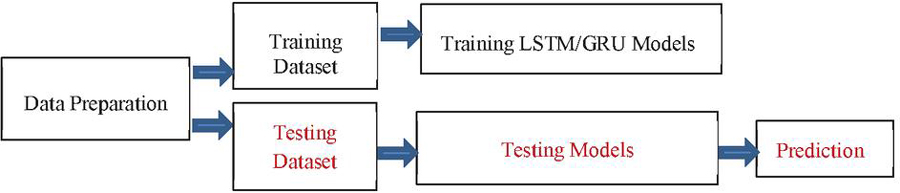
Figure 5 The block diagram of the proposed method.
In order to verify the correction and effectiveness of the proposed method, we employ the oil temperature of power transformers described Section 3.1 and compare the results of LSTM and GRU with seasonal auto-regressive integrated moving average (SARIMA) model, which is one of the commonly used time series prediction and analysis methods. SARIMA model has fast calibration calculation and self-learning ability [19–21]. It is very suitable for online real-time prediction and analysis, and is widely used in the prediction scenarios of time series in various fields. At last, the prediction results are analyzed. According to the error analysis in statistics, we mainly use the root mean square error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) to measure the effectiveness of the compared methods. We assume that and are the ground truth and label and the forecast values, separately. These indicators can be formulated as follows.
| (9) | |
| (10) | |
| (11) |
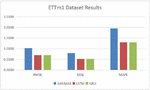
Tables 1, 2, Figures 6 and 7 show the prediction accuracy comparison results, with SARIMAX, LSTM and GRU methods, on data set ETT-small-h1, ETT-small-m1, respectively.
Table 1 Prediction accuracy comparison results on data set ETT-small-h1
| RMSE | MAE | MAPE(%) | |
| SARIMAX | 1.3903 | 1.0000 | 5.5051 |
| LSTM | 1.5414 | 1.2598 | 6.7398 |
| GRU | 0.9766 | 0.6236 | 3.4506 |
Table 2 Prediction accuracy comparison results on data set ETT-small-m1
| RMSE | MAE | MAPE(%) | |
| SARIMAX | 1.0267 | 0.7891 | 1.9594 |
| LSTM | 0.6977 | 0.5213 | 1.2951 |
| GRU | 0.6971 | 0.5221 | 1.2978 |
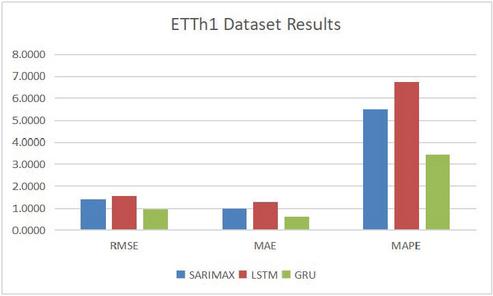
Figure 6 Comparison results on dataset ETTh1.
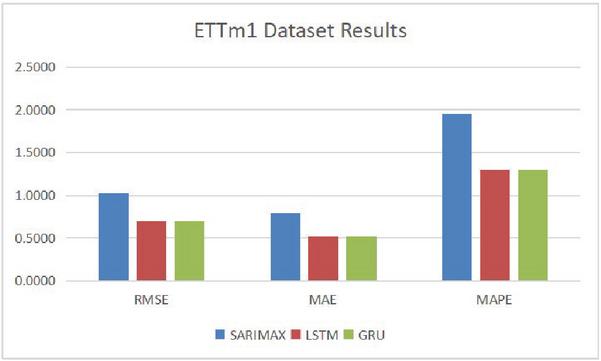
Figure 7 Comparison results on dataset ETTm1.
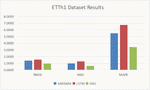
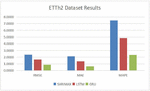
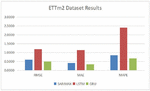
Tables 3, 4, Figures 8 and 9 show the prediction accuracy comparison results, with SARIMAX, LSTM and GRU methods, on data set ETT-small-h2, ETT-small-m2, respectively.
Table 3 Prediction accuracy comparison results on data set ETT-small-h2
| RMSE | MAE | MAPE(%) | |
| SARIMAX | 2.3971 | 2.1312 | 7.4880 |
| LSTM | 1.6407 | 1.3934 | 4.8557 |
| GRU | 0.8549 | 0.6616 | 2.3561 |
Table 4 Prediction accuracy comparison results on data set ETT-small-m2
| RMSE | MAE | MAPE(%) | |
| SARIMAX | 0.6013 | 0.4183 | 0.8476 |
| LSTM | 1.1991 | 1.1356 | 2.4082 |
| GRU | 0.5007 | 0.3450 | 0.6774 |
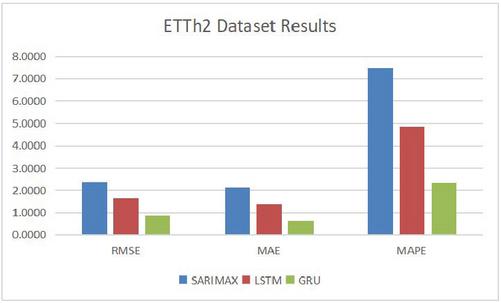
Figure 8 Comparison results on dataset ETTh2.
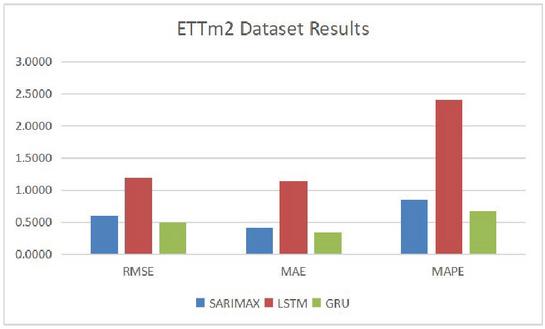
Figure 9 Comparison results on dataset ETTm2.
From Tables 1 to 4 and Figures 6 to 9, it can be demonstrated that our proposed GRU based prediction method has the best performance. The specific reasons are analyzed as following. The transformer oil temperature has characteristics of randomness, fluctuation and uncertainty, which is a typical nonlinear unstable sequence. The nonlinear mapping ability of neural networks, LSTM and GRU, can setup the mapping relationship for output and input under the premise of uncertain specific functional relationship. Therefore, LSTM and GRU methods have potential advantages in training and predicting transformer oil temperature time series, because the neural network has better nonlinear mapping capability and generalizing ability. Neural network can establish the mapping relationship between input and output without a thorough understanding of the system. Traditional SARIMAX model is a static regression model in nature, but the transformer oil temperature time series is nonlinear and dynamic. In addition, the current time series prediction value will be affected by the current input information and historical information, and GRU model has a unique gate cycle structure, which is not available in the traditional neural network structure. Due to the advantages of the GRU model, the proposed prediction method also can be employed in other time series prediction problems.
4 Conclusion
Power transformer plays a crucial role in the whole power grid and its normal operation decides the regular operation of the whole power grid. The oil inside the transformer is important [22, 23]. In order to accurately predict the working condition of transformer, the oil temperature prediction method is often used to provide a reference for the working condition of transformer. As the power transformer oil temperature time series is nonlinear and dynamic, LSTM and GRU based methods have potential advantages in predicting transformer oil temperature time series, because the neural network has better nonlinear mapping capability and generalizing ability. GRU is a new version of LSTM network. In GRU model, there exist only two gates which are updating gate and resetting gate. GRU has simpler structure and better effect, compared with LSTM network, so GRU is also a very useful network, currently. GRU can fix the long dependency problem too in RNN networks. A new method for predicting transformer oil temperature was proposed based on time series theory and GRU in this paper, which is verified on the dataset of the oil temperature of the transformers in the two regions. Finally, the results demonstrated that the proposed method can better learn the features of the oil temperature data, and have a good generalization.
In future, more dataset could be used to verify the effectiveness of the proposed method in this paper. In addition, the combination of different algorithms will be studied to predict to the power transformer oil temperature.
References
[1] Fauzi, Nur Afini et al. “Fault Prediction for Power Transformer Using Optical Spectrum of Transformer Oil and Data Mining Analysis.” IEEE Access 8 (2020): 136374–136381.
[2] Zhengang Zhao, Zhengyu Yang, Yuyuan Wang, et al., Error Analysis of Transformer Hot Spot Temperature Measurement, Distributed Generation & Alternative Energy Journal, Vol 36 Iss 4, Aug. 2021.
[3] Yu Xi, Dong Lin, Li Yu, Bo Chen, Wenhui Jiang and Guangqin Chen, Oil temperature prediction of power transformers based on modified support vector regression machine, International Journal of Emerging Electric Power Systems, May 16, 2022, https://doi.org/10.1515/ijeeps-2021-0443
[4] Kabir, Farzana, Foggo, Brandon and Yu, Nanpeng. (2018). Data Driven Predictive Maintenance of Distribution Transformers. 312–316. 10.1109/CICED.2018.8592417.
[5] Lin, J., Su, L., Yan, Y., Sheng, G., Xie, D., Jiang, X. Prediction Method for Power Transformer Running State Based on LSTM_DBN Network. Energies 2018, 11, 1880. https://doi.org/10.3390/en11071880
[6] Hosein Nezaratian, Javad Zahiri, Mohammad Fatehi Peykani, Amir Hamzeh Haghiabi, Abbas Parsaie, A genetic algorithm-based support vector machine to estimate the transverse mixing coefficient in streams, Water Quality Research Journal (2021) 56(3): 127–142. https://doi.org/10.2166/wqrj.2021.003
[7] He Q, Si J, Tylavsky D J. Prediction of top-oil temperature for transformers using neural networks[J]. Power Delivery IEEE Transactions on, 2000, 16(4):825–826.
[8] Qi X, Li K, Yu X, et al. Transformer Top Oil Temperature Interval Prediction Based on Kernel Extreme Learning Machine and Bootstrap Method[J]. Proceedings of the Csee, 2017, 37(19):5821–5828.
[9] Wei Rao, Lipeng Zhu, Sen Pan, Pei Yan and Junfeng Qiao, Bayesian Network and Association Rules-based Transformer Oil Temperature Prediction, Journal of Physics: Conference Series, Vol. 1314, 3rd International Conference on Electrical, Mechanical and Computer Engineering 9–11 August 2019, Guizhou, China.
[10] Fei Xiao, Guo-jian Yang, Wei Hu, Research on Intelligent Diagnosis Method of Oil Temperature Defect in Distribution Transformer Based on Machine Learning, Proceedings of 25th International Conference on Electricity Distribution, Madrid, 3–6 June 2019, pp. 676–680.
[11] Ali Taheri, Ali Abdali, Abbas Rabiee. (2020). Indoor distribution transformers oil temperature prediction using new electro- thermal resistance model and normal cyclic overloading strategy: an experimental case study. IET Generation Transmission & Distribution. 14. 5792–5803. 10.1049/iet-gtd.2020.0457.
[12] Hochreiter, Sepp and Schmidhuber, Jürgen, 1997. Long Short-Term Memory. Neural Computation. 9(8): 1735–1780. doi: 10.1162/neco.1997.9.8.1735.
[13] Cho, KyungHyun et al., 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv:1412.3555.
[14] Jiang Mingyang, Xu Li, Zhang Kaijun, Ma Yuanxing, Recurrent Neural Network Prediction Of Wind Speed Time Series Based On Seasonal Exponential Adjustment, Acta Energiae Solaris Sinica, Vol. 43, No. 2, Feb. 2022.
[15] Karevan Z, Suykens J A K. Transductive Lstm For Time- Series Prediction: An Application To Weather Forecasting[J]. Neural Networks, 2020, 125:1–9.
[16] Muzaffar S, Afshari A. Short-Term Load Forecasts Using LSTM Networks[J]. Energy Procedia, 2019, 158:2922–2927.
[17] Ravanelli, Mirco, Brakel, Philemon, Omologo, Maurizio, Bengio, Yoshua (2018). “Light Gated Recurrent Units for Speech Recognition”. IEEE Transactions on Emerging Topics in Computational Intelligence. 2(2): 92–102.
[18] Zhou, Haoyi, Zhang, Shanghang, Peng, Jieqi, Zhang, Shuai, Li, Jianxin, Xiong, Hui and Zhang, Wancai. (2020). Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting.
[19] Ayanlowo E A, Oladapo Ifeoluwa, Ajewole K P, “Investigating the pattern of Inflation in Nigeria using SARIMAX model”, IJIRMPS International Journal, 2020. https://www.academia.edu/44210567
[20] Arunraj, Nari, Ahrens, Diane and Fernandes, Michael. (2016). Application of SARIMAX Model to Forecast Daily Sales in Food Retail Industry. International Journal of Operations Research and Information Systems. 7. 1–21. 10.4018/IJORIS.2016040101.
[21] Chen Y, Tjandra S. Daily Collision Prediction with SARIMAX and Generalized Linear Models on the Basis of Temporal and Weather Variables:[J]. Transportation Research Record, 2018.
[22] Ye Chen, Chuan Luo, Wenjiao Xu, et al., Study on Oil Flow Characteristics and Winding Temperature Distribution of Oil-immersed Transformer, Distributed Generation & Alternative Energy Journal, Vol. 35 Iss. 3, Apr. 2021.
[23] Zhengang Zhao, Zhangnan Jiang, Yang Li, et al., Effect of Loads on Temperature Distribution Characteristics of Oil-Immersed Transformer Winding, Distributed Generation & Alternative Energy Journal, Vol. 37 Iss. 2, Oct. 2021.
Biographies

Haomin Chen received the B.S. degree and M.S. degree in Electrical Engineering from South China University of Technology, Guangzhou, China. He is currently a professorate senior engineer in Digital Grid Research Institute, China Southern Power Grid, Guangzhou, China. His research interests include smart grid and intelligent substation.

Lingwen Meng received the B.S. degree and M.S. degree in Electrical Engineering from Shandong University, Weihai, China. She is currently a senior engineer in Institute of Electric Power Research of Guizhou Power Grid, Guiyang, China. Her research interests include smart grid and intelligent substation.

Yu Xi received the B.S. degree and M.S. degree in Electrical Engineering from South China University of Technology, Guangzhou, China. He is currently an engineer in Digital Grid Research Institute, China Southern Power Grid, Guangzhou, China. His research interests include smart grid and intelligent substation.

Mingyong Xin received the B.S. degree and M.S. degree in Instrument and Meter Engineering from University of Electronic Science and Technology of China, Chengdu, China. He is currently a senior engineer in Institute of Electric Power Research of Guizhou Power Grid, Guiyang, China. Her research interests include AI, smart grid and intelligent substation.

Siwu Yu received the B.S. degree from China University of Mining and Technology, and M.S. degree in environmental science from Research Center for Eco-Environmental Sciences, Chinese Academy of Sciences, Beijing, China. He is currently a senior engineer in Institute of Electric Power Research of Guizhou Power Grid, Guiyang, China. Her research interests include AI, smart grid and intelligent substation.

Guangqin Chen received the B.Eng. degree and M.Eng. degree in Electrical Engineering from South China University of Technology, Guangzhou, China. He is currently working in the Digital Grid Research Institute, China Southern Power Grid, mainly engaged in the research of digital grid and intelligent substation.

Yumin Chen received the B.S degree in Electrical Engineering from Wuhan University, M.S degree in Electrical & Electronic Engineering from Nanyang Technological University. Currently, she is working as an associate engineer in Digital Grid Research Institute, China Southern Power Grid, Guangzhou, China. Her research interests include multi-energy system, microgrid operation as well as smart grid.
Distributed Generation & Alternative Energy Journal, Vol. 38_2, 393–412.
doi: 10.13052/dgaej2156-3306.3822
© 2023 River Publishers