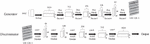Improved DCGAN for Solar Cell Defect Enhancement
Deng Hao and Yilihamu Yaermaimaiti*
College of Electrical Engineering, Xinjiang University, 830046, Xinjiang Urumqi, China
E-mail: 65891080@qq.com
*Corresponding Author
Received 08 February 2023; Accepted 01 March 2023; Publication 10 July 2023
Abstract
Aiming at the problems of serious overfitting and poor training results caused by too small a data set of solar cell defect images in the process of deep learning training, an improved DCGAN generation countermeasure network model is proposed. Firstly, CLAHE preprocessing is used to enhance the defect image features, which can improve the defect contrast and avoid excessive noise enhancement at the same time; Secondly, the NAM attention module is introduced into DCGAN to improve the quality of the defect image; Finally, S-RELU is used to replace Leaky Relu in DCGAN discriminator to avoid the influence of too much negative information with gradient on the decision of discriminator. The experimental results of classification and detection show that the data enhancement effect of the improved model is better. Compared with the original model, its accuracy is improved by 2.51%, and the mapped value is improved by 1.92%, which proves the effectiveness of the proposed algorithm.
Keywords: solar cell, GAN, pretreatment, attention module, data enhancement.
1 Introduction
In recent years, with the increasing demand for energy, solar energy as a renewable energy source has received more and more social attention, and the application of solar panels has become more and more widespread [1–3]. Solar panels may have a variety of defect types in the production process, such as broken grids, cracks, black sheets, solid black, etc. These defects may reduce the efficiency of use in light cases, or cause more serious safety accidents in heavy cases [4]. Therefore, defect detection of solar panels in the production process is crucial [5].
Deep learning is widely used in defect detection as a pixel-level detection method to achieve high-precision classification and detection tasks through complex models and large amounts of data [6]. However, the difficult data acquisition of solar cell electroluminescence (EL) defect images can cause severe overfitting of the detection model and limit the detection effect. Traditional data enhancement expands the dataset by inversion, mirroring, and tilting, but the data enhancement obtained by the coordinate transformation-based approach is limited, and difficult to generate new data volumes [7]. GOODFELLOW [8] et al. proposed Generative Adversarial Networks (GAN), which generate data by The network is trained to generate realistic images by the feature distribution of the sample, which provides a new idea for the expansion of the dataset.
With the introduction of generative adversarial networks, a large number of variants of them have appeared in domestic and international research. mirza [9] et al. solved the defect of the unsupervised model to the supervised model by introducing conditional variables in the GAN model to guide the model to generate specific image data. Tarkovsky et al. [10] proposed adding Wasserstein distance to the GAN model by adding Wasserstein distance instead of JS scatter to solve the problem of training instability, but the processing of weight cropping will lead to a difficult model training process. Ishaan Gulrajani et al. [11] based on the original WGAN (Wasserstein Generative Adversarial Networks) reintroduced the gradient penalty and forced a constraint on the Lipschitz function, which improved the training speed of the model as well as the quality of the generated images. Jinli Yang et al. [12] combined the improved Deep Convolutional Generative Adversarial Networks (DCGAN) with deep neural networks to solve the data set imbalance problem in the field of cyber security situational awareness. Zunxiong Liu et al. [13] proposed a multi-scale parallel learning generative adversarial network structure, by performing multi-scale learning on low-resolution images by two sub-networks, and then fusing the information by a fusion network to generate high-resolution images.
For the solar cell defect enhancement method, the literature [14] achieves the data enhancement effect by traditional operations such as brightness conversion and flipping for some defective samples. The literature [15] proposed a true-false data fusion algorithm using DCGAN and image random stitching to fuse the generated images with the original images again randomly to form a new training set and alleviate the overfitting phenomenon. The literature [16] proposed a defective sample data enhancement approach through the normal sample-guided generative adversarial network to solve the solar cell defective sample imbalance problem and balanced the performance of the network model by introducing adaptive weight constraints in the weights of the discriminator. In the literature [17], a fully connected auxiliary classifier generative adversarial network is proposed to achieve solar cell EL image data enhancement by deepening the overall network structure and introducing multiple fully connected layers in the discriminator.
For the limited effect of traditional data enhancement with the original DCGAN, to improve the quality of the generated samples of solar cell EL defect images, this experiment adds a layer of network structure to the generator as well as the discriminator of the original DCGAN network by improving the original DCGAN, and introduces a normalization-based Attention Module (NAM) in the discriminator, and propose an improved Normalization-based Attention Module-Deep Convolutional Generative Adversarial Networks (NAM-DCGAN) enhance the discriminator’s ability to discriminate the samples generated by the generator and avoid the network model from generating low-quality defective samples. In the generator, NAM-DCGAN introduces residual units before each layer of deconvolution to enhance the ability of the generator to learn deep features of images by deepening the number of network layers, adding a NAM module between each layer of convolution in the discriminator, and combining the Softsign activation function with Rectified Linear Units (RELU). The S-Relu activation function is proposed to replace the Leaky Relu activation function in the discriminator [18], which solves the defect that Leaky Relu cannot converge when the input signal is negative and thus introduces too much negative information and further improves the quality of the generated samples.
2 Introduction of Related Algorithms
2.1 DCGAN
GAN is composed of two independent structures, the generator, and the discriminator. The generator is trained iteratively to transform Gaussian distributed random noise into image data, while the discriminator is used to determine the authenticity of the generated images, and the Nash equilibrium is achieved through the game training between the two. Convolutional neural networks are powerful in feature extraction as well as the generalization of images and reduce the complexity of the model and the risk of model overfitting through local perception as well as weight sharing of features.
DCGAN retains the powerful capability of GAN image generation, but also combines the advantages of CNN for sample feature extraction, which improves the quality of generated samples, accelerates model convergence, and effectively avoids model collapse in the image generation phase.
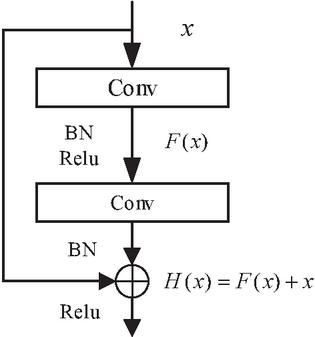
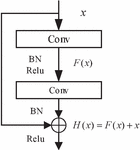
Figure 1 Residual cell structure.
2.2 Residual Unit
The residual unit, first proposed in the literature [19], is composed of a convolutional layer, a BN layer, and a Relu activation function, and its structure is shown in Figure 1. is the input data, is the transform function after convolutional processing, and performs the addition operation on and to obtain the desired output. The shallow network model has difficulty in fully learning the image in the feature learning process due to insufficient feature extraction capability, and purely increasing the number of convolutional layers will produce degradation problems. To address the above problems, the residual unit ensures that the image feature information is not lost after transformation by jumping connection, and replaces the traditional feature learning by using residual learning, which ensures the network layers are sufficient and avoids the network degradation problem at the same time.
Demands without considering the data volume. Taking into consideration this ratio, green IT technologies have important benefits in terms of:
• Reduce electricity costs and OPEX;
• Improve corporate image;
• Provide sustainability;
• Extend useful life of hardware;
• Reduce IT maintenance activities;
• Reduce carbon emissions and prevent climate change;
• Provide foundations for the penetration of renewable energy sources in IT systems.
2.3 NAM Attention Module
To avoid the interference of background noise and bus to the discriminator, this experiment introduces the NAM attention mechanism in the discriminator, which is a normalization-based attention module proposed by Liu [20] et al. The weights corresponding to the feature maps are computed only by the scaling factors in the BN layer, omitting additional parameters such as fully connected layers and convolution. For channel attention, as shown in Equation (1).
| (1) |
Where denote the mean and variance of small batch data, respectively. and are the affine transformation parameters obtained by backpropagation, where is the scaling factor and is the translational parameter. The scaling factor can reflect the trend of all channels. When the channel changes drastically, it indicates that the current channel contains a large amount of valid information and will be assigned a larger weight, and when the channel changes slowly, it indicates that the current channel information is relatively single and will be assigned a smaller weight. Figure 2 and Equation (2) represent the specific process and equation of the channel attention module, respectively.
| (2) |
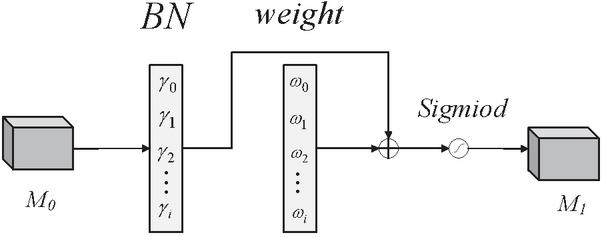
Figure 2 Channel attention mechanism.
in the figure represents the input feature map of the current module, represents the scale factor of channels, corresponding to the weight . Finally, the results are normalized by the Sigmoid activation function to obtain the output feature map , as shown in Equation (3).
| (3) |
3 Algorithm Improvement
3.1 S-Relu Activation Function
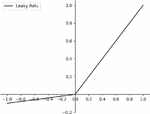
In the development of convolutional neural networks, the activation function can provide nonlinear functions to the network and enhance the expressiveness of the network model [21]. In the iterative process, to ensure that the parameters can be updated quickly to achieve optimality, the activation function needs to have a large enough derivative in the first half; to realize the fine-tuning function of the network, the derivative of the second half needs to converge to zero gradually; to avoid the neuron “necrosis to avoid the phenomenon of neuron “necrosis”, it is necessary to ensure that the activation function has enough negative information and there is a small gradient. The discriminator of the original DCGAN model adopts the Leaky Relu activation function except for the last layer, and the function expression is shown in Equation (4).
| (4) |
The function graph is shown in Figure 3.
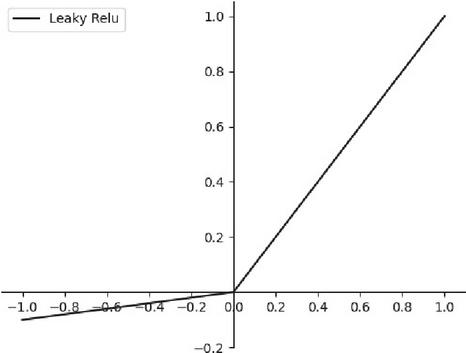
Figure 3 Leaky Relu function curve.
The positive half-axis of the Leaky Relu activation function is a linear activation function, which is simple to calculate and fast to train, improving the convergence speed of the model and effectively preventing the possibility of gradient disappearance, and the negative half-axis introduces the hyperparameter to solve the negative value truncation problem, where the value of is usually 0.01. However, Leaky Relu cannot converge by keeping the same gradient for the input negative value information, and the hyperparameter. The selection of hyperparameters will have different effects depending on the data set. To address the above problems, the S-Relu activation function is proposed in this experiment. The expression of the function is shown in Equation (5).
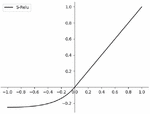
| (5) |
The function graph is shown in Figure 4.
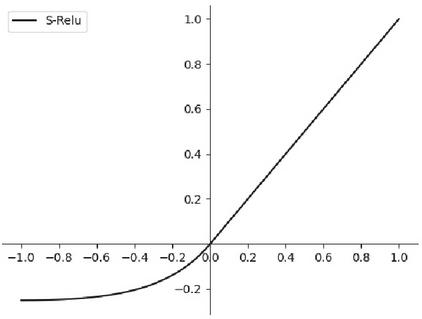
Figure 4 S-Relu function curve.
The Relu activation function, as a linear activation function, is simple to compute and fast to train, which helps to speed up the convergence of the model and prevent the gradient from disappearing, but the constant zero gradients of the negative half-axis will cause the learning to stop when the neuron input is negative, which has a certain impact on the feature information transfer in the model. the Softsign activation function has a relatively smooth learning curve, and the negative half-axis has a gradual convergence to zero gradients. Although the function as a whole has a good nonlinear fitting ability. When the value of X is too large or too small, the output of the Softsign activation function will be close to flat, and there is obvious saturation, resulting in a small update magnitude of the weights and the disappearance of the gradient, which is not conducive to the training of the model. In this experiment, the right half of the Relu activation function and the left half of the Softsign activation function are combined and defined as the S-Relu activation function, which not only makes up for the defects of the two activation functions but also ensures the effectiveness of the functions of both activation functions.
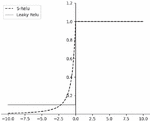
The combined derivative image of the S-Relu activation function and the Leaky Relu activation function is shown in Figure 5.
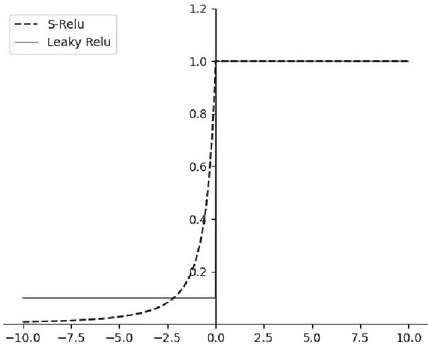
Figure 5 Derivative curves of S-Relu and Leaky Relu functions.
From Figure 5, we can see that when the input signal is at the right end of the zero point, both derivative images are consistent, and when the input signal is at the left end of the zero point, the derivative of the S-Relu activation function gradually decreases to zero, giving different gradients to the signals near and far from the zero point in the input data, which is more conducive to the model’s learning of the input data.
3.2 NAM-DCGAN Structure
In response to the low resolution of the original DCGAN generated images, which leads to insufficient detail generation and affects the classification and detection effects, this experiment expands one layer of deconvolution and convolution network structure on the generator and discriminator of the original DCGAN network, respectively, so that the generated image resolution can reach 128 128, and introduces the residual structure before each layer of deconvolution in the generator, and embeds in each layer of the discriminator The NAM attention mechanism module is embedded in each layer of the discriminator, and the S-Relu activation function is used to replace the Leaky Relu activation function in the generator and discriminator, and the Sigmoid activation function in the last layer remains unchanged. The structure of the improved DCGAN network model is shown in Figure 6.
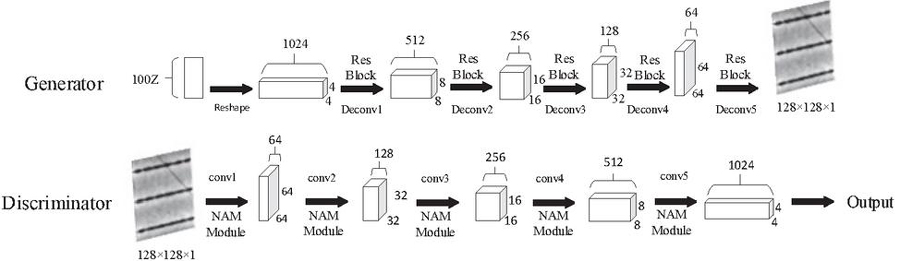
Figure 6 Improved DCGAN network model structure.
4 Experiment and Analysis
4.1 Data Sets and Pre-processing
The solar cell EL image dataset used in this study contains four types of defect data: Finger interruptions, Microcrack, Damage Sheet, and Black spot, some of which contain only a single type of defect and some of which contain multiple mixed defects.
To enhance the defect features of some images and not to over-enhance the noise interference of the images, this study adopts Contrast Limited Adaptive Histogram Equalization (CLAHE) preprocessing for the image data [20].
The CLAHE algorithm first trims the part of the histogram that is larger than the threshold parameter by adjusting the size of the threshold parameter, and then redistributes the trimmed part evenly in the histogram, after several trimming and redistribution operations, and finally until the exceeding part can be ignored, to achieve the restriction of the histogram distribution. The image after the redistribution process can effectively suppress the excessive enhancement of noise while improving the image contrast. CLAHE processing is shown in Figure 7.
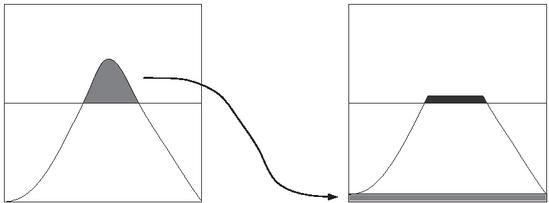
Figure 7 Schematic diagram of CLAHE algorithm.
The image after processing by the CLAHE algorithm is shown in Figure 8.
4.2 Experimental Parameters
The pre-processed images are used as the input of the improved network model and the improved network model respectively, and the parameters of both models are set according to Table 1.
4.3 Experimental Results and Analysis
In this study, four mainstream generative adversarial models of GAN, WGAN, auxiliary classifier generative adversarial network (ACGAN), DCGAN and the improved DCGAN were used to enhance the defective samples for the experiments respectively, and the results are shown in Figure 8. The model generates 16 images in each cycle, and one image is randomly selected as the representative after stitching according to different defect features in the corresponding cycle, where the top left, bottom left, top right and bottom right correspond to the generated black spot, damage sheet finger interruptions, and microcrack, respectively.

Figure 8 Comparison images before and after processing by CLAHE algorithm.
Table 1 Network model parameters before and after improvement
| Parameters | Meaning | Value |
| batch_size | Single batch sample value | 16 |
| nz | Potential vectors | 100 |
| beta1 | Optimization index decay | 0.5 |
| lr | Rate Learning Rate | 0.0002 |
| ngf | Transposed convolutional output Number of output channels | 64 |
| ndf | Convolution Output Number of channels | 64 |

Figure 9 Comparison of images generated before and after model improvement.
The image analysis shows that at the training times of 200, NAM-DCGAN generates fewer defect contours on this basis compared to the other four models, but the generated defect parts are very limited. At 400 training times, the defect profiles of the four models except GAN can be roughly distinguished, but the defect profiles of WGAN, ACGAN, and DCGAN are not very clear and are accompanied by distortion and noise, and the images generated by NAM-DCGAN also have slight distortion and noise, but the clarity is significantly better than the results of the remaining four models. The images generated by NAM-DCGAN also have slight distortion and noise, but the clarity is significantly better than the results of the other four models. At 600 training cycles, the images generated by GAN, WGAN, ACGAN, and DCGAN were clearer in the background and defects of solar panels, but some of the defects were not of high quality and had deformation, and NAM-DCGAN could generate more realistic images. The images generated by WGAN, ACGAN, DCGAN, and NAM-DCGAN are close to the real images.
4.4 Evaluation Indicators and Analysis
Compared with the improved model, the images generated by the improved model outperformed the former model in terms of quality in multiple training cycles. To further verify the effectiveness of the improved model in data enhancement, this study uses mirror enhancement, GAN, ACGAN, DCGAN, and NAM-DCGAN for data enhancement, and the generated images are passed through MobileNet-V3 and EfficientNet-Yolov3 pairs for classification and detection experiments, respectively. MobileNet-V3 has a small number of parameters and strong classification ability, which can effectively avoid overfitting and has a fast training speed. EfficientNet-Yolov3 utilizes EfficientNet to replace the backbone network of Yolov3, which greatly reduces the number of parameters and reduces the effect of overfitting. The same model has the same classification ability and detection ability, and when the generated images are closer to the style of the original images, the higher the classification rate and accuracy rate of the model, thus serving as a criterion for the quality of the image generation.
In the classification experiments, the original data were firstly enhanced by the above six ways in the ratio of 1:3, and then mixed with the original samples, and the final obtained samples were randomly divided into a training set, validation set, and test set in the ratio of 8:1:1 respectively as shown in Table 2.
Table 2 Sample quantity setting of classification experiment
| Dataset | Finger Interruptions | Microcrack | Damage Sheet | Black Spot | Total |
| Training set | 467 | 467 | 333 | 387 | 1654 |
| Validation set | 59 | 59 | 41 | 48 | 207 |
| Test set | 58 | 58 | 42 | 49 | 207 |
The divided dataset is fed into the MobileNet-V3 network for classification experiments. The accuracy of the model classification results is used as the merit of the enhanced results. To guarantee the validity of the experiments, the 10 times classification accuracy was averaged as the final experimental results. The experimental results are shown in Table 3.
Table 3 Classification experiment verification
| Enhancement Method | Accuracy % |
| GAN | 87.91 |
| Mirroring | 89.04 |
| WGAN | 90.72 |
| ACGAN | 91.63 |
| DCGAN | 92.16 |
| NAM-DCGAN | 94.67 |
The data in Table 3 shows that the accuracy rate of NAM-DCGAN is higher than the remaining five approaches in the classification experiment, which indicates that the data enhancement method implemented in this experiment can meet the requirements of the classification experiment and the enhancement effect is better than the remaining six approaches.
In the detection experiments, mixed defect images are added to the original samples and the images are enhanced in the above six ways, and the six samples are randomly divided into a training set, validation set, and test set in the ratio of 8:1:1, respectively, and the data of the six samples are shown in Table 4.
Table 4 Set the number of test samples
| Finger | Damage | Black | Mixed | |||
| Dataset | Interruptions | Microcrack | Sheet | Spot | Defects | Total |
| Training set | 467 | 467 | 333 | 387 | 189 | 1843 |
| Validation set | 59 | 59 | 41 | 48 | 23 | 230 |
| Test set | 58 | 58 | 42 | 49 | 24 | 231 |
The divided dataset is sent into the EfficientNet-Yolov3 network for detection experiments after defect labeling, and the mAP value of the model detection results is used as the merit of the enhancement results by the high or low mAP value. To ensure the validity of the experiments, the mAP values of the detection results were averaged as the final experimental results. The results of the detection experiments are shown in Table 5.
Table 5 Sample verification of detection experiment
| Enhancement Method | mAP% |
| GAN | 87.41 |
| Mirroring | 88.59 |
| WGAN | 89.58 |
| ACGAN | 90.73 |
| DCGAN | 91.05 |
| NAM-DCGAN | 92.97 |
The data in Table 5 shows that the mAP value of NAM-DCGAN is higher than the remaining five methods in the detection experiment, which indicates that the data enhancement method implemented in this experiment can meet the needs of the detection experiment and the enhancement effect is better than the remaining five methods.
Compared with the traditional mirror image enhancement, NAM-DCGAN will make subtle changes to the original defects and will generate some defect styles that are not in the original image, expanding the diversity of samples. By mixing different kinds of defects and training them, multiple defects can be obtained on a single generated image after fusion, further enhancing the diversity of samples.
Compared with the original model, the improved model structure enhances the generator’s ability to extract image features, improves the quality of the generated images, improves the discriminator’s ability to discriminate, and effectively avoids making correct decisions for low-quality images. The new activation function can effectively eliminate the impact of the model on the generated data by learning too much negative information.
4.5 Ablation Experiments
NAM-DCGAN improves the DCGAN model by fusing three strategies: the residual structure, the NAM attention mechanism, and the improved S-Relu activation function. To verify the effectiveness of the improved method, the generated images were subjected to classification and detection experiments on MobileNet-V3 and EfficientNet-Yolov3, respectively. The experimental parameters in the ablation experiments are consistent with those in the classification and detection experiments. The experimental parameters in the ablation experiments are consistent with those in the classification and detection experiments, as explained in the text. The experimental results are shown in Table 6.
Table 6 Ablation experiment
| Models | Classification Accuracy % | mAP% |
| DCGAN | 92.16 | 91.05 |
| S | 92.29 | 91.11 |
| R | 92.53 | 91.60 |
| N | 92.93 | 92.09 |
| RS | 93.15 | 92.24 |
| NS | 93.74 | 92.65 |
| RN | 94.41 | 92.82 |
| NAM-DCGAN | 94.67 | 92.97 |
Where S stands for S-Relu activation function, R stands for residual structure, and N stands for NAM attention module. From Table 6, we can see that the classification accuracy and mAP values are improved after introducing S-Relu activation function, residual module, and NAM attention module into DCGAN, which indicates that too much negative information with a gradient will affects the learning of the model, the residual module can improve the ability of solar panel defect image generation and the attention mechanism can make the model better target the defect part for After combining the three algorithms two by two, the classification accuracy and mAP values are improved, indicating the effectiveness of the algorithm fusion; after fusing the three algorithms, the accuracy and mAP values reach the highest. It can be concluded that all three proposed improvements are beneficial to improve the quality of solar cell defect image generation.
5 Concluding Remarks
In this experiment, we propose a generative adversarial network NAM-DCGAN combined with normalized attention to expand the defect image data for the difficult image acquisition of solar cell EL defect image data to meet the needs of classification and detection tasks, and make the following improvements.
(1) Introducing a residual module in the generator to enhance the image feature extraction capability.
(2) Introducing the NAM attention mechanism in the discriminator to enhance the model discriminative ability.
(3) The S-Relu activation function is used to replace the Leaky Relu activation function in the discriminator to avoid the interference of too much negative information with a gradient to the discriminator.
Compared with the traditional data augmentation and the original DCGAN, the training effect of the model obtained by augmentation is optimal in the case of the same amount of augmented data, and it can be used for augmenting the solar cell EL defect image dataset when the dataset samples are small.
Acknowledgements
The authors want to acknowledge the financial support from the National Natural Science Foundation of China (Project No.: 61866037, 61462082).
References
[1] Yaqub M, Sarkani S, Mazzuchi T A. Addressing Solar-PV Power Generation: Commercialization Assessment for the US Energy Market[J]. Distributed Generation & Alternative Energy Journal, 2013, 28(1): 56–80.
[2] Lin G T R. The promotion and development of solar photovoltaic industry: discussion of its key factors[J]. Distributed Generation & Alternative Energy Journal, 2011, 26(4): 57–80.
[3] Hosseini A, Zolfagharzadeh M M, Asghar Sadabadi A, et al. Social acceptance of renewable energy in developing countries: challenges and opportunities[J]. Distributed Generation & Alternative Energy Journal, 2018, 33(1): 31–48.
[4] Kabir E, Kumar P, Kumar S, et al. Solar energy: Potential and future prospects[J]. Renewable and Sustainable Energy Reviews, 2018, 82: 894–900.
[5] Balzategui J, Eciolaza L, Arana-Arexolaleiba N, et al. Semi-automatic quality inspection of solar cell based on Convolutional Neural Networks[C]//2019 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA). IEEE, 2019: 529–535.
[6] Zhang Shun, Gong Yihong, Wang Jinjun. Development of deep convolutional neural networks and its application in computer vision [J]. Journal of computer science, 2019, 42(03): 453–482
[7] Antoniou A, Storkey A, Edwards H. Data augmentation generative adversarial networks[J]. arXiv preprint arXiv:1711.04340, 2017.
[8] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[J]. Advances in neural information processing systems, 2014, 27.
[9] Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
[10] Arjovsky M, Chintala S, Bottou L. Wasserstein gan. arXiv 2017[J]. arXiv preprint arXiv:1701.07875, 2017, 30: 4.
[11] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved training of wasserstein gans[J]. Advances in neural information processing systems, 2017, 30.
[12] Yang Jinxuan, Yang Yu, Yao Chengpeng, Yin Kun. An intrusion detection method based on improved depth convolution generation countermeasure network [J]. Science, Technology and Engineering, 2022, 22(08): 3209–3215.
[13] Liu Zunxiong, Jiang Zhonghui, Ren Xingle. Image super resolution algorithm of multi-scale generation countermeasure network [J]. Science, Technology and Engineering, 2020, 20(13): 5217–5223.
[14] Liu Huaiguang, Ding Wancheng, Huang Qianwen. Research on defect detection method of photovoltaic cells based on lightweight convolutional neural network [J]. Applied Optics, 2022, 43(01): 87–94.
[15] Wang Yunyan, Zhou Zhigang, Luo Shuai. Defect detection of solar cells based on data enhancement [J]. Journal of Electronic Measurement and Instrumentation, 2021, 35(01): 26–32.
[16] Liu Kun, Wen Xi, Huang MINMING, et al. Defect enhancement method of solar cells based on generation countermeasure network [J]. Journal of Zhejiang University (Engineering Edition), 2020, 54(04): 684–693.
[17] Maas A L, Hannun A Y, Ng A Y. Rectifier nonlinearities improve neural network acoustic models[C].
[18] Zhang Yiping, Xu Shengzhi, Meng ziyao, et al. Data enhancement method of solar cell El image based on fc-acgan network [J]. Journal of solar energy, 2021, 42(10): 35–41.
[19] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770–778.
[20] Liu Y, Shao Z, Teng Y, et al. NAM: Normalization-based Attention Module[J]. arXiv preprint arXiv:2111.12419, 2021.
[21] Wang Hongxia, Zhou Jiaqi, Gu Chenghao, et al. Design of activation function in convolutional neural network for image classification [J]. Journal of Zhejiang University (Engineering Edition), 2019, 53(07): 1363–1373.
[22] Pizer S M, Amburn E P, Austin J D, et al. Adaptive histogram equalization and its variations[J]. Computer vision, graphics, and image processing, 1987, 39(3): 355–3.
Biographies

Deng Hao is a master’s student from Xinjiang University. As a master’s student, his main research areas are image generation, image classification, and target detection. His master’s thesis topic will focus on image generation of solar panel defects and defect target detection.

Yilihamu Yaermaimaiti Corresponding author, Male (Uyghur), Xinjiang Urumqi, Graduate Advisor, Associate Professor, Main research areas are artificial intelligence, pattern recognition, face recognition, target tracking, and detection.
Distributed Generation & Alternative Energy Journal, Vol. 38_5, 1383–1402.
doi: 10.13052/dgaej2156-3306.3852
© 2023 River Publishers