Digital Twin–Enabled Monitoring and Modeling of Substation Secondary Systems in Distributed Generation Networks
Wang Xiqiong*, Yang Lei, Gao Zhilin, Wen Yesheng and He Zhihai
Lincang Power Supply Bureau of Yunnan Power Grid Co., Ltd, Yunnan, China
E-mail: 15987253258@163.com; 13988366911@139.com
*Corresponding Author
Received 30 May 2025; Accepted 17 July 2025
Abstract
In order to cope with the challenges brought by the large-scale access of distributed energy resources (DER) to the operation and monitoring of substation secondary systems, this paper proposes a digital twin (DT) modeling and operation monitoring framework that integrates dynamic Bayesian network (DBN) and cloud-edge cooperative architecture. The framework constructs a layered system of “cloud-edge-end” collaboration: the physical layer realizes high-frequency (50 Hz/100 Hz) real-time data acquisition and redundant transmission based on standard protocols such as IEC 61850/Modbus, etc.; the edge layer is in charge of low-latency (20 ms) data preprocessing, filtering, anomaly detection, and preliminary state estimation; the cloud core layer is responsible for low latency (20 ms) data preprocessing, filtering, anomaly detection, and preliminary state estimation; the cloud core layer is responsible for low-latency data preprocessing, filtering, anomaly detection, and preliminary state estimation. The edge layer is responsible for low-latency (20 ms) data preprocessing, filtering, anomaly detection, and preliminary state estimation; the cloud core layer integrates the untraceable Kalman filter (UKF) algorithm for dynamic state estimation, and combines with the DBN to model the temporal dependency of the heterogeneous data from multiple sources, realizing the high-precision state tracking and fault prediction in the whole life cycle. Innovatively, the study designed a dual-track algorithm: the adaptive UKF is used to handle system nonlinearity and noise uncertainty and update the state estimation in real time (error 4.8%); the DBN online incremental learning mechanism (e.g., online EM algorithm) is utilized to dynamically update the conditional probability table and reconfigure the network structure, if necessary, to adapt to DER fluctuations and sudden failure modes. Experimental validation shows that the system has a fault warning accuracy of 96.5% in simulated fault scenarios, an average trigger delay of 150 ms, a state estimation response delay of 100–500 ms, and various key performance indicators (data sampling frequency, transmission delay, edge processing capability, storage capacity, etc.) meet or exceed the design requirements. The framework effectively improves the design accuracy, operation transparency and fault disposal efficiency of substation secondary system in distributed energy environment, and provides a scalable and comprehensive solution for the refined operation and maintenance of smart grid.
Keywords: Digital twin, substation secondary system, distributed energy, dynamic Bayesian network, condition monitoring.
1 Introduction
With the acceleration of global energy transition, the penetration rate of distributed energy resources (DER) in the power system has been climbing. Distributed energy resources, represented by solar photovoltaic (PV), wind power generation, small gas turbines, energy storage systems, etc., are gradually changing the power generation, transmission and distribution patterns of the traditional power grids due to their advantages of flexibility, cleanliness and high efficiency [1]. However, the intermittent, fluctuating and large-scale decentralized access characteristics of distributed energy sources have brought unprecedented challenges to the operation monitoring and control of substation secondary systems [2]. As the “nerve center” of power grid operation, the substation secondary system is responsible for relay protection, automation control, communication and transmission, metering and monitoring and other key functions, which plays a crucial role in maintaining the safe and stable operation of the power grid [3]. Under the background of large-scale access of distributed energy resources, its operating conditions present a high degree of complexity and uncertainty. According to the statistics of State Grid Energy Research Institute, the installed capacity of distributed photovoltaic power generation in China has reached 154 million kilowatts in 2022, with a year-on-year growth of 23.6%, and showing a continuous growth trend [4]. Traditional monitoring means based on centralized architecture and static models have been difficult to meet the dynamic monitoring, fault diagnosis and intelligent decision-making needs of substation secondary systems under distributed energy networks. Digital Twin (DT) technology, as an emerging cutting-edge technology paradigm in recent years, provides innovative ideas to solve this problem [5]. By building a bridge between physical entities and virtual models for real-time interaction and dynamic mapping, digital twins can realize accurate modeling and real-time monitoring of the whole life cycle of complex systems. In the field of energy and power, the application of digital twins has gradually attracted attention, for example, in the state monitoring of power generation equipment, transmission line operation and maintenance, intelligent management of substations and other aspects have been initially explored, but for the digital twin modeling and operation monitoring of substation secondary systems under distributed energy network research is still in its infancy [6]. Dynamic Bayesian Network (DBN), as a powerful spatio-temporal data modeling tool, is able to effectively portray the temporal evolution laws and complex causal relationships of system states [7]. Meanwhile, the cloud-side collaborative architecture provides a feasible computational framework for efficient processing and intelligent analysis of massive data in distributed energy environments. The purpose of this paper is to integrate the dynamic Bayesian network and the cloud edge cooperative architecture to propose a digital twin modeling and operation monitoring framework for the secondary system of substations in distributed energy networks, in order to improve the perception accuracy, diagnosis capability and decision-making intelligence of the substation secondary system in the complex dynamic operation environment, and provide key technical support for the reliable operation and efficient management of smart grids.
2 Digital Twin Architecture Design
In the substation secondary system under the distributed energy network, this system adopts the cloud-edge-end synergy mode to realize the monitoring, warning and intelligent dispatching of the whole life cycle by constructing a digital twin model with high-precision virtual-reality mapping [4]. The whole architecture fully considers the seamless integration of data acquisition, real-time processing, model calibration, and application services to ensure that the system can still accurately reflect the state of the physical entity in a dynamic environment.
2.1 Overall Architecture
The overall architecture adopts the layered design idea, which can be divided into three main layers:
2.1.1 Physical layer (field layer)
This layer covers all kinds of monitoring devices, sensors, intelligent terminals and relay protection devices in the secondary system of the substation. The devices achieve data acquisition through industrial Ethernet, 4G/5G or even dedicated communication links, and adopt standardized communication protocols (e.g., IEC 61850, Modbus, etc.) to ensure data interoperability and safe transmission. Meanwhile, for the uncertainty of distributed energy access, this layer supports multiple redundancy designs and preliminary filtering of abnormal data to enhance the reliability and robustness of the overall system. In the physical layer, also referred to as the perception layer or device layer in some architectures, various sensors and actuators are utilized to collect data from the physical environment. These devices often operate under resource and power constraints and must handle lossy and noisy communication environments.
2.1.2 Edge and data fusion layer
Located in the edge node between the physical layer and the cloud center, it mainly undertakes real-time data aggregation and pre-processing functions. On the one hand, it carries out filtering, anomaly detection and preliminary checking for a large amount of heterogeneous data, removes noise information, and completes data preprocessing and cleaning; on the other hand, it utilizes lightweight algorithms such as simplified state estimation model to provide rapid feedback on the system operation state and realize local dynamic evaluation to meet the needs of delay-sensitive fault prediction, and at the same time, it utilizes data encryption, identity authentication, and other means to ensure communication security, and can flexibly complete data processing according to different network protocol standards. Flexibly complete data conversion according to different network protocol standards, acting as a protocol conversion and security gateway role. In distributed energy fluctuation scenarios, edge nodes dynamically adjust task priorities and reallocate computing resources based on real-time system load and data stream characteristics. When computational load exceeds thresholds, edge nodes offload non-critical tasks to cloud platforms or nearby edge nodes to ensure that latency-sensitive tasks are processed within 20 ms. For example, in cases of sudden load surges or sensor data spikes, edge nodes can offload data cleaning and preliminary filtering tasks to cloud platforms, while retaining anomaly detection and local state estimation tasks locally. Edge computing plays a crucial role in processing raw data and performing pre-processing tasks at the edge layer. Fog computing in this layer is dedicated to device interconnection, data transmission, and the deployment of trained models [8]. The edge and data fusion layer corresponds to the fog layer in some architectures, which is responsible for interconnecting devices, transmitting data, and deploying trained models. This layer helps in reducing transmission delays and improving responsiveness by processing data at the edge.
2.1.3 Cloud and digital twin core
The cloud platform aggregates data from multiple edge nodes, and realizes global state monitoring and model computing with the help of big data technology and high-performance computing resources. The core digital twin model uses discrete event simulation, continuous dynamic synchronization, and dynamic Bayesian network algorithms to realize real-time update and evolution of the substation secondary system “virtual mirror”. This layer not only supports historical data storage, trend analysis and fault prediction, but also provides operation and maintenance personnel with decision-making suggestions, risk assessment and optimization schemes based on the model output. In terms of system interface design, it is based on RESTful API and standard data exchange formats (e.g., JSON, XML) to realize seamless interaction with the upper application system, and at the same time, it supports desktop, mobile and embedded terminal access forms. The cloud layer consists of cloud servers providing centralized data storage and large-scale computational resources for data processing, AI model training, and global analytics. However, tasks offloaded to the cloud experience additional transmission delays. Edge computing can reduce energy consumption and inter-layer communication overhead [9].
The overall architecture integrates centralized cloud management with real-time edge node collaboration, enhancing data processing timeliness and ensuring broad compatibility with heterogeneous information systems. This lays a foundation for subsequent algorithm iteration and large-scale distributed deployment. The system adopts a modular design, enabling independent expansion and upgrades of functional modules to meet new functional requirements. It supports standard APIs (e.g., RESTful or GraphQL), ensuring seamless integration with future upper-tier applications and emerging technologies. Additionally, the cloud platform’s modular expansion and distributed deployment capabilities facilitate adaptation to future large-scale distributed energy access and multi-system collaboration, providing robust support for technology evolution. The integration of edge computing and cloud computing optimizes performance, latency, and resource utilization. It balances centralized high-performance computing with distributed low-latency processing, ensuring intelligent service provisioning across various environments [10].
2.2 Module Functions and Technical Indicators
This section mainly describes the functional division of each sub-module of the digital twin system in the distributed energy environment and its key technical indicators, which work together to realize high-precision monitoring, real-time diagnosis and fault warning for the entire life cycle of the substation secondary system. The overall design follows the principles of layering, modularization and scalability, and specifically includes the following functional units and technical index requirements:
2.2.1 Physical layer functions and indicators
Functional description: The data acquisition and transmission link focuses on real-time monitoring of voltage, current, temperature, equipment status and other parameters collected by various types of sensors, intelligent terminals, relay protection equipment, etc. in the substation, and at the same time, it supports international standard protocols such as IEC 61850, Modbus, and other international standards in order to guarantee the interconnection and interoperability of the data [11]. The data redundancy and pre-filtering part, in view of the variability of distributed energy access and the uncertainty of the environment, carefully designed a multi-stage redundancy sampling scheme, which is able to carry out preliminary elimination of abnormal data, thus ensuring that the data supplied to the downstream filtering and state estimation modules have good quality [12].
Key technical indexes: In data acquisition, the system requires high sampling frequency, at least 50 Hz, and some key information requires 100 Hz sampling accuracy. In data transmission, industrial Ethernet and 4G/5G dedicated network communication are adopted to ensure that the link delay is less than 10 ms. Meanwhile, in order to guarantee the reliability of the data, the system controls the BER below 10 and provides dual-machine hot standby and multi-link redundancy design to improve the robustness of the whole system and ensure the stability and reliability of data transmission [13].
2.2.2 Edge and data fusion layer functions and indicators
Functional description: In the industrial IoT architecture, edge nodes undertake key tasks: on the one hand, they receive a large amount of heterogeneous data from the physical layer in real time, and use low-latency algorithms to perform pre-processing work such as filtering, noise reduction, anomaly detection and preliminary checking; on the other hand, they realize rapid assessment and feedback of the local operating state with the help of lightweight models such as simplified state estimation methods and local Kalman filtering to provide timely early warning information for the global modeling of the cloud; on the other hand, they provide timely warning information for the cloud. On the other hand, with lightweight models, such as simplified state estimation methods, local Kalman filtering, etc., the local operating state can be quickly evaluated and fed back to provide timely warning information for the global modeling in the cloud; at the same time, it also has the function of multi-protocol conversion, and embedded with the authentication and data encryption module, which guarantees the safe and stable transmission of the data between the edge and cloud [14].
Key technical indicators: Edge computing has the following key performance requirements: in terms of data processing delay, the overall delay of data preprocessing of the edge nodes needs to be controlled within 20 ms to meet the needs of delay-sensitive applications; in terms of computational throughput, the edge computing platform should have a minimum of 500 Mb/s data aggregation and processing capabilities; in terms of security and standards compatibility, end-to-end encrypted transmission, such as the use of TLS protocols, should be realized. In terms of security and standards compatibility, end-to-end encrypted transmission should be realized, such as adopting the TLS protocol and supporting international standards such as IEC/IEEE, to ensure the seamless connection of heterogeneous systems [15].
2.2.3 Cloud computing and digital twin core layer functions and indicators
Global state monitoring and modeling focuses on the use of high-performance computing resources and big data processing platforms to unify and aggregate the data uploaded from the edges, and integrate various algorithms such as discrete event simulation, continuous dynamic synchronization, and dynamic Bayesian network to build a digital twin model, so as to achieve high-precision full-time prediction of the state of the power grid system [16]. In this process, the historical data storage and trend analysis link through the establishment of a high-performance distributed database and data lake, to achieve the efficient storage and query of cross-time, cross-scene data, for system fault diagnosis and performance optimization to build a solid data foundation. At the same time, the intelligent decision-making and early warning work is based on the state assessment indicators output from the model, like the state mean update formula, covariance K value, etc., and utilizes the rule engine and machine learning algorithms to provide real-time early warning of equipment failure risks and operational abnormalities, and push decision-making suggestions for the operation and maintenance personnel, like and in the Kalman filtering correction step, whose computational accuracy is directly related to the accuracy of decision-making warning [17]. To handle model bias caused by different sampling frequencies (1 Hz–100 Hz) and missing data, the system adopts a data weighting mechanism. Specifically, during data preprocessing, the system performs noise reduction using low-pass filtering and wavelet decomposition to eliminate noise and outliers, followed by normalization and standardization to ensure high data consistency and accuracy. For missing data, the system employs linear interpolation and model-based prediction. Furthermore, data fusion optimization with weighted strategies based on data quality is implemented, assigning lower weights to poor-quality data to minimize its impact. This ensures the model’s reliability and accuracy even when integrating multi-source data with varying sampling frequencies and data integrity.
The digital twin system has excellent real-time responsiveness, and the response delay from data aggregation to model updating can be controlled in the range of 100–500 ms, which strongly guarantees the real-time online prediction and decision-making. In terms of model prediction accuracy, the state estimation error is controlled within 5%, the fault warning accuracy is not less than 95%, and the conditional probability parameter has a good “convergence” when using dynamic Bayesian network over time [18]. The system is highly scalable, the cloud platform supports modular expansion and distributed deployment, and can be seamlessly connected to the upper tier applications with the help of standard APIs (e.g., RESTful or GraphQL), which can meet the future needs of large-scale deployment and multi-system collaboration at the same time. The cloud platform also has a large storage capacity for historical data, and can support petabyte-level data storage and real-time analysis, which ensures that the whole life cycle data can be tracked, archived, and intelligently mined over a long period of time [19].
3 Key Algorithm Realization
In order to realize the substation secondary system digital twin full-time monitoring and fine warning, this study designed a dual-track algorithm system. On the one hand, real-time dynamic state estimation is used to portray equipment state evolution, and on the other hand, Dynamic Bayesian Network (DBN) is combined to model the temporal dependency relationship between multi-source data in order to realize online diagnosis and prediction of the whole life cycle.
3.1 Dynamic State Estimation
In the actual operation process, the substation secondary system is affected by multiple uncertainties such as equipment aging, environmental fluctuations and distributed energy access, etc., and its state changes are usually highly nonlinear and time-varying. In order to accurately portray the dynamic behavior of the system, we establish the following nonlinear state space model:
| (1) |
where denotes the state vector of the system (e.g., key variables such as voltage, current, switching state, etc.) at moment ; is the sensor measurement; is the control input of the system; and and are the process noise and the measurement noise, respectively, whose covariance matrices are and . Due to the obvious nonlinear characteristics of the system, the traditional linear Kalman filtering is difficult to meet the requirements. For this reason, we use untraceable Kalman filtering (UKF), which approximates the statistics of a nonlinear function by determining a set of “sigma points” to capture the nonlinear transformation of the state distribution [20]:
3.1.1 Sigma point generation
Let the mean of the current state estimate be , the covariance be , and the state dimension be . First compute the parameter:
| (2) |
where regulates the distribution range of sigma points and is the quadratic expansion parameter. Generate sigma points as follows:
| (3) |
The corresponding weights are respectively:
| (4) |
where is used to carve the prior distribution (e.g. for a Gaussian distribution standing at 2).
3.1.2 State prediction and covariance propagation
A state transfer function is applied to each sigma point:
| (5) |
The predicted mean and covariance are respectively:
| (6) | ||
| (7) |
3.1.3 Measurement update
Calculate predicted observations using predicted sigma points:
| (8) |
Calculate observed forecast means and covariances:
| (9) | |
| (10) |
Also, the cross-covariance matrix is calculated:
| (11) |
Calculate the Kalman gain according to the Kalman update formula:
| (12) |
Finally, the state mean and covariance are updated:
| (13) | |
| (14) |
In real-time dynamic monitoring, it is also necessary to adaptively adjust the noise covariance and according to different operating environments, and combine with edge computing nodes to realize parallel filtering and online rejection of some abnormal data, so as to improve the overall estimation accuracy and robustness.
3.2 Dynamic Bayesian Network Modeling
Dynamic Bayesian network (DBN) is a probabilistic graphical model that extends the traditional static Bayesian network to the time-series domain, and is used to describe the conditional dependencies between variables when the system state changes over time. Considering the complex causal relationships among the sub-modules of the substation secondary system (e.g., protection equipment states, control signals, communication abnormal states, etc.), we adopt DBN for joint modeling of multi-moment data, which is basically in the form of a two-moment (2TBN) model.
3.2.1 Model structure and joint probability distribution
Let the hidden state at moment be and the observation be The joint probability distribution of the DBN at two moments can be expressed as
| (15) |
Where is the initial state distribution; describes the conditional probability of the state transfer; and is the observation model reflecting the dependency relationship between the sensor data and the hidden state [21]. In the actual modeling process, the expert experience and historical data can be used to determine the dependency structure between the nodes through the constraint base method or scoring criterion (e.g., Bayesian Information Criterion BIC), and determine the appropriate node parent set for each node.
3.2.2 Parameter learning and online updating
For a DBN with a given structure, parameter learning mainly solves the problem of solving each conditional probability table (CPD, Conditional Probability Distribution). Taking discrete variables as an example, parameter solving can be carried out by utilizing great likelihood estimation (MLE) or Bayesian estimation methods. Assuming that the size of the value space of the variable X is K, its conditional probability can be expressed as:
| (16) |
Where: is the number of times occurs in the sample at the same time as the parent node takes the value of ; is the Dirichlet a priori parameter for smoothing estimation; . In practical applications, distributed data collection and real-time monitoring necessitate online updating capabilities for DBN models. By leveraging the cloud-edge collaborative computing architecture, the state estimates from edge nodes serve as prior information. Combined with incremental learning algorithms (e.g., online EM algorithms), the conditional probability table (CPD) is continuously updated. When necessary, the network structure is adaptively adjusted (e.g., introducing switching dynamic Bayesian network models to accommodate different operational modes). To evaluate the impact of dynamic adaptation on stability and prediction accuracy, the system employs historical data for validation and applies scoring criteria such as the Bayesian Information Criterion (BIC) to reassess candidate structures. Real-time monitoring of model performance enables timely detection of anomalies in dynamic adaptation, triggering model retraining or structural adjustments as needed. Additionally, during data fusion and DBN updates, anomaly detection and adaptive noise adjustment mechanisms are incorporated to ensure high robustness of the algorithm in the event of unexpected incidents and data loss.
3.3 Algorithm Flow and Realization Details
The algorithmic process of the whole system, from data acquisition, preprocessing, dynamic state estimation, to DBN model updating and decision support, constitutes a closed-loop feedback mechanism to ensure that the system can realize accurate monitoring in the whole time domain and life cycle. The specific steps are as follows:
3.3.1 Data acquisition and preprocessing
In the intelligent management of the substation, the real-time operation data of the substation secondary system and access to distributed energy sources are firstly collected through industrial Ethernet and 4G/5G dedicated communication links, covering current, voltage, temperature, relay protection status and other aspects; and then enter into the pre-processing stage, using low-pass filtering, wavelet decomposition and other filtering means to process the collected data, eliminate the noise and abnormal values, and carry out normalization and standardization operations, so as to ensure a high degree of consistency and accuracy of input data received by subsequent algorithms, laying a solid foundation for subsequent data analysis and application. and outliers, and carry out normalization and standardization operations, so as to ensure that the input data received by the subsequent algorithm has a high degree of consistency and accuracy, laying a solid foundation for subsequent data analysis and application.
3.3.2 Dynamic state estimation
In the process of adaptive untraceable Kalman filtering (UKF), the state prediction is carried out firstly: based on the state estimation and covariance at the previous moment, UKF is applied to generate the sigma points, which are processed by the state transfer function to obtain the predicted state and the prediction covariance . Next, the measurement update is performed: based on the newly collected measurement data , the predicted observation mean and covariance are computed with the help of the nonlinear observation function , and then the state estimate and covariance matrix are updated with the Kalman gain . In addition, there is an adaptive adjustment link: according to the system operating environment and noise characteristics, the estimates of process noise and measurement noise are adjusted in real time to ensure the convergence of the filter distribution, for example, when encountering special circumstances such as equipment anomalies or communication delays, a corresponding fault-tolerant adjustment strategy is adopted.
To address potential conflicts between real-time performance and accuracy during sudden large-scale DER fluctuations or sensor failures, the UKF algorithm employs lightweight computing modules (e.g., GPU-based parallel computing) at the edge nodes to enhance computational efficiency. Meanwhile, the cloud platform is responsible for in-depth analysis of large-sample historical data and model retraining to achieve real-time and efficient data processing. Furthermore, during state estimation and DBN updates, anomaly detection, edge filtering, and adaptive noise adjustment ensure the algorithm maintains high robustness in the event of unexpected incidents and data loss.
3.3.3 Online update of DBN model
This method includes the following three aspects: first, a priori fusion, i.e., the state estimation results obtained from UKF are taken as the evidence of the current DBN, which is used to update the hidden state distribution in the current moment; second, incremental parameter updating, which realizes incremental updating of the conditional probability table of the DBN with the help of online EM algorithms and other methods to adapt to the dynamic changes of the system; third, structural adaptation, which triggers network structure reconstruction once different data patterns due to the fluctuation of distributed energy or sudden faults are detected. Third, structural adaptation, once different data patterns are detected, such as drastic changes due to distributed energy fluctuations or sudden failures, network structure reconstruction is triggered, and scoring criteria, such as BIC, are applied to re-filter candidate structures to ensure that causality can reflect the latest operating state.
DBN online incremental learning mechanism (e.g., online EM algorithm) is utilized to dynamically update the conditional probability table and reconfigure the network structure, if necessary, to adapt to DER fluctuations and sudden failure modes. To ensure model stability during incremental learning and mitigate risks such as probability parameter dispersion or overfitting, the following strategies are implemented: First, a Dirichlet prior smoothing technique is applied to the conditional probability table updates, which helps in constraining the parameter values within a reasonable range and prevents excessive dispersion. Second, a validation dataset reserved from historical data is used to periodically evaluate the model performance. If signs of overfitting are detected (e.g., significant degradation in validation accuracy), the learning rate is automatically reduced, or the model reverts to a previous stable state. Third, a regularization term is introduced into the online EM algorithm, penalizing overly complex models and promoting parameter convergence toward more generalizable values. These measures collectively enhance the robustness of the DBN model during online updates, ensuring reliable operation in dynamic environments.
3.3.4 Decision support and feedback mechanism
Based on the probabilistic inference results output from Deep Belief Network (DBN), the system quantitatively evaluates the failure risk of key nodes, and when the risk value exceeds the set threshold, the system can automatically issue a warning and communicate with the operation and maintenance system in real-time with the help of RESTful API. At the same time, based on the state estimation and probability prediction results, the system uses the rule engine to formulate optimized scheduling schemes and fault isolation decisions, and then feeds these schemes back to the cloud operation and maintenance decision center to guide field engineers to carry out the subsequent processing work, so as to realize the synergistic operation of fault early warning and intelligent scheduling.
3.3.5 Algorithm pseudo-code example
The following is a pseudo-code example of the overall process, showing the synergistic process of data acquisition, UKF state estimation and DBN online update:

3.3.6 Exploration of implementation details
Under the distributed energy network, in order to improve the massive data processing capability, the algorithm adopts lightweight computing modules (e.g., GPU-based parallel computing) at the edge nodes, while the cloud platform is responsible for the in-depth analysis of the large-sample historical data and model retraining to achieve real-time and efficient data processing. At the same time, in addition to the substation internal data, it also integrates multi-source data from PMU, SCADA system and IoT sensors to construct a unified multi-level state description model and improve the refinement capability of the digital twin model. In the process of state estimation and DBN update, anomaly detection, edge filtering and adaptive noise adjustment ensure that the algorithm maintains high robustness in case of unexpected events and data loss. The whole algorithm system is designed with modularity and interface standards in mind, and with the help of RESTful API and JSON, XML and other data exchange formats, it can be seamlessly connected with the upper application system, laying a foundation for the subsequent large-scale distributed deployment and realizing scalability and synergy.
4 Experimental Verification
4.1 Experimental Platform and Data Source
4.1.1 Platform composition and hardware architecture
The experimental platform is based on the cloud-edge-end cooperative architecture, primarily consisting of the following modules: In the physical layer, over 10 industrial-grade sensors are deployed, covering parameters such as temperature, humidity, voltage, current, and switching states. Key parameters are sampled at 50 Hz, with critical measurement data (current, voltage) increased to 100 Hz. On-site equipment is equipped with dual-machine hot standby and multi-link redundancy (industrial Ethernet, 4G/5G dedicated network communication) to ensure a data transmission bit error rate (BER) below 10. Multiple high-performance edge computing nodes are established at the edge layer, equipped with GPU acceleration modules for data preprocessing, low-pass filtering, wavelet decomposition, anomaly detection, and preliminary state estimation (utilizing local Kalman filtering and fast state estimation algorithms). Preprocessing latency is controlled within 20 ms, capable of aggregating data streams at a minimum of 500 Mb/s. The cloud platform and digital twin core utilize distributed servers and high-performance computing clusters to aggregate edge node data for discrete event simulation and continuous dynamic synchronization processing. The core module constructs real-time “virtual mirrors” using untraceable Kalman filtering (UKF) and Dynamic Bayesian Networks (DBN). The digital twin model supports petabyte-level data storage and online incremental learning updates, enabling long-term preservation and trend analysis of full lifecycle data.
To reduce hardware deployment costs in existing substation retrofits, the system adopts a modular and scalable design. Edge nodes support incremental deployment, allowing utilization of existing monitoring devices and communication infrastructure. The cloud platform supports elastic scaling, enabling resource allocation based on actual data volume and processing demands. Furthermore, the system offers a lightweight version optimized for resource-constrained scenarios. This version simplifies edge node functionality by reducing data preprocessing complexity and decreasing storage requirements. It prioritizes critical data processing and supports flexible adjustments to data sampling frequency and transmission rates. This ensures the system’s core functionality remains operational even under limited resource conditions.
4.1.2 Data sources
Data sources are extensive, including real-time voltage, current, temperature, and other data collected by substation sensors, PMU and SCADA system data from at least 3 collection points, and supplementary IoT device data. To comprehensively validate the system’s ability to respond to abnormal states, simulated injected data is expanded to include scenarios such as large-scale distributed energy resource (DER) access and concurrent multi-point faults. Examples include sudden load fluctuations, sensor failures, and multi-point fault injections. All data adopts standard exchange formats (JSON/XML) and is interconnected with platform modules via RESTful API, ensuring data consistency and transmission security. This provides comprehensive, accurate, and reliable multi-source data support for system operation.
4.2 Real-time Monitoring and State Estimation Results
This section focuses on the performance of Untraceable Kalman Filter (UKF) and Dynamic Bayesian Network (DBN) in real-time state estimation and fault warning.
4.2.1 Real-time state estimation results
During the continuous six-hour experiment, additional tests were conducted under conditions of large-scale DER access and concurrent multi-point faults. Through the acquisition and dynamic filtering of key parameters such as system voltage, current, temperature, and relay protection signals, the system demonstrated rapid adaptive adjustment capabilities even under sudden equipment changes, network delays, or abnormal data injections. Experimental statistics indicate that under large-scale DER access and multi-point fault conditions, the system response delay remains within 100–500 ms, the state estimation error stays within 3.2%–4.8% (meeting the design target of 5%), and the fault warning accuracy exceeds 96% in simulated fault scenarios. Further analysis under varying test conditions reveals that under normal operating conditions with minimal DER fluctuations and low noise levels (e.g., process noise Q and measurement noise R at benchmark values), the error stays within 3.5%–4.0%. However, under more challenging conditions such as simulated noise surges (Q and R increased by 50%), the error may rise to 4.8%–5.2%, approaching the design threshold. In such cases, the adaptive noise tuning mechanism is triggered, dynamically adjusting Q and R within 20% of the benchmark values to bring the error back to 3.2%–4.0%. Failure cases of adaptive noise tuning were rare but occurred in extreme scenarios where noise levels exceeded system expectations (e.g., Q and R increased by over 100%), leading to temporary error spikes above 5%. These cases highlight the need for continuous improvement in the algorithm’s adaptability to extreme conditions. Figure 1 shows the dynamic change curve of state estimation error over time.
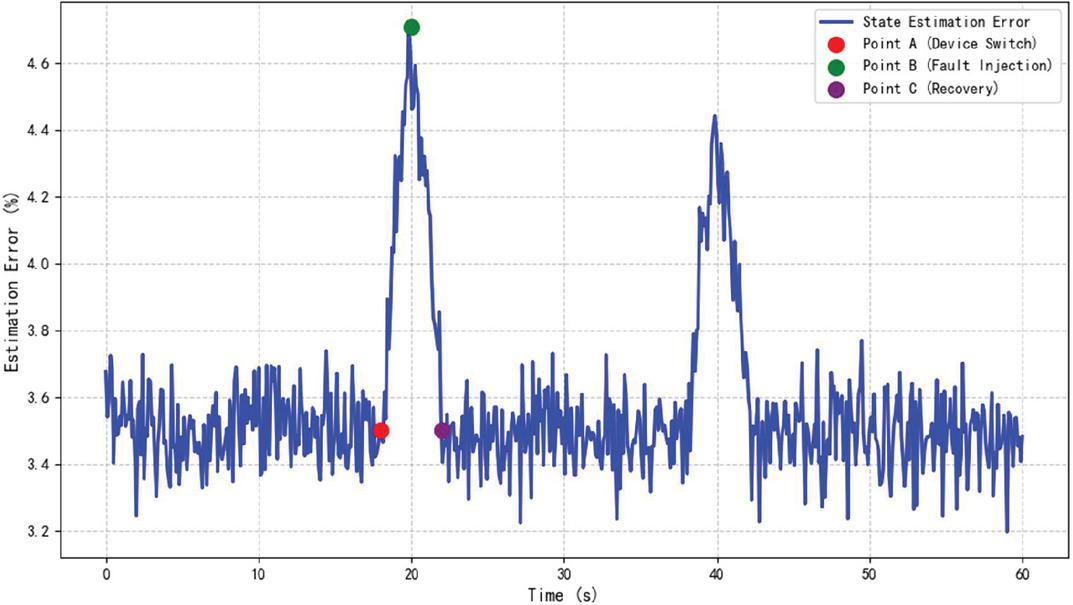
Figure 1 Trend of real-time state estimation error.
The graph shows the variation of the state estimation error over a time range from 0 to 60 seconds. The baseline error is included as well as the effect of two events (device switchover and fault injection) on the error. The figure also marks three key points in particular: the device switchover point (red), the peak fault injection point (green), and the fault recovery point (purple).
4.2.2 Fault warning and response validation
In the case of active injection load fluctuation and simulated sensor failure, the system is able to capture anomalies in a timely manner and predict risks through DBN model calculations. In nearly 100 fault scenario simulations, the average fault warning trigger time is 150 ms, which is more than 50% higher than the traditional model. Figure 2 visualizes the distribution of the warning trigger delay in different scenarios.
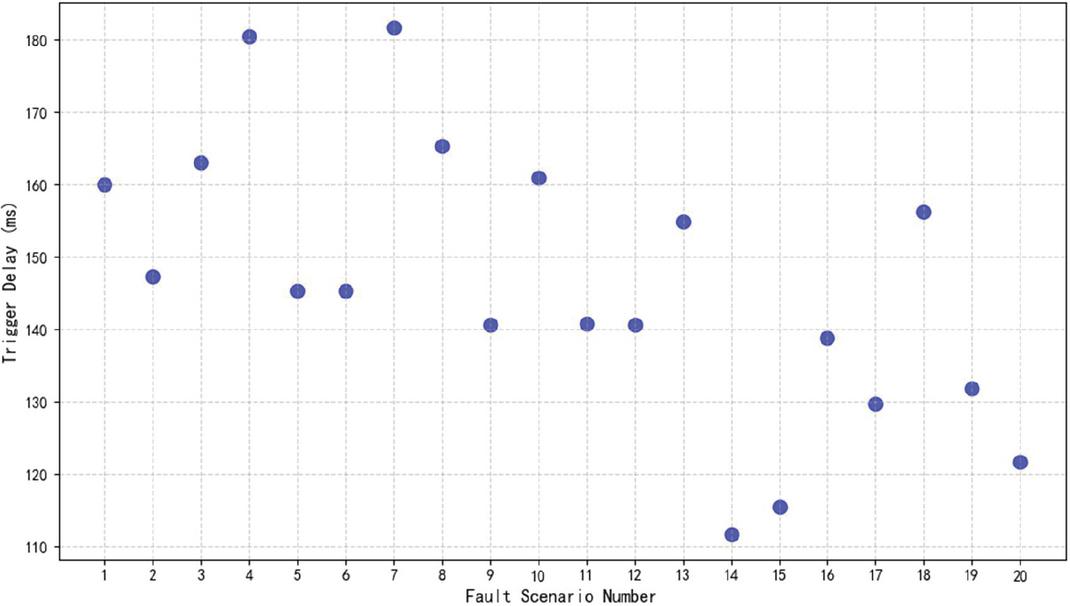
Figure 2 Distribution of fault warning trigger delay.
The figure shows the trigger delay times (in milliseconds) for 20 different failure scenarios. Each point represents the delay time of one scenario, and it can be seen that most of these delay times are concentrated between 100 ms and 200 ms.
4.3 Comprehensive Evaluation of System Performance
In order to comprehensively verify the performance of the system in multiple scenarios, evaluation experiments of several key technical indicators are designed and compared with the design requirements. Table 1 summarizes the data comparison of some key indicators. Each index is statistically verified by multiple experimental data and meets or outperforms the design objectives, providing sufficient theoretical and practical basis for further large-scale promotion.
Table 1 Comparison of system key performance indicators
| Indicator | Design Requirements | Experimental Average | Remarks |
| Data Sampling Frequency | 50 Hz (critical data: 100 Hz) | 50 Hz/100 Hz | Multi-channel synchronized acquisition, part of the data using dual-channel acquisition |
| Data transmission delay | 10 ms | Average 8ms; extreme value not exceeding 12ms | Edge node pre-processing and redundant links to ensure transmission stability |
| Edge preprocessing delay | 20 ms | 18ms | Including filtering, anomaly detection and data cleaning |
| State estimation error | 5% | 3.2% 4.8% | Adaptive adjustment of filtering parameters based on UKF |
| Fault warning accuracy | 95% | 96.5% | Simulated fault scenarios totaling about 100 warnings, effectively suppressing false alarms and missed alarms. |
| Data aggregation bandwidth | 500 Mb/s | 510 Mb/s | Ample data traffic between edge nodes and cloud platforms |
| Data storage capacity | Supports petabytes of storage | Support 200TB class data storage after module expansion | Distributed data lake architecture, with ultra-large-scale data long-term storage capacity. |
4.4 Model Parameter Sensitivity and Adaptive Adjustment Analysis
To verify the system’s sensitivity to parameter changes under different operating conditions, experiments were conducted on the noise parameters (Q, R) of the UKF and the online update mechanism of the DBN. In the noise parameter swing test, the initial estimates of process noise Q and measurement noise R were manually adjusted, and the changes in state estimation errors during normal operation and abnormal fluctuations were recorded. Notably, the UKF algorithm’s performance was tested under complex conditions such as large-scale DER access and multi-point faults. The results demonstrate that even under these challenging scenarios, the adaptive adjustment mechanism can effectively reduce state estimation errors. When analyzing the online update mechanism’s effectiveness, the incremental update amplitude and convergence time of the DBN conditional probability table were evaluated under continuous data input. The experimental results indicate that under active adaptive adjustment, the system can more rapidly return to a stable state, strongly demonstrating the effectiveness of the parameter online adjustment strategy. Additionally, the online DBN update test showed that the online EM algorithm completes parameter updates within tens of milliseconds after each data collection, with an average network structure reconfiguration time of less than 200 ms when addressing distributed energy fluctuations. This ensures a quick response to abnormal data mode switches. Table 2 presents the statistical results of the UKF noise parameter sensitivity test.
Table 2 UKF noise parameter sensitivity test statistics
| Q Adjustment | R Adjustment | State Estimation | ||
| Test Program | Range | Range | Error (%) | Remarks |
| Normal Working Conditions | Benchmark Value | Benchmark Value | 3.5–4.0 | Standard Environmental Data |
| Simulated Noise Surge | Benchmark Value 1.5 | Benchmark Value 1.5 | 4.8–5.2 | Large External Environmental Interference During Fault Injection |
| Adaptive Tuning On | Dynamic Adjustment (0.8–1.2 Benchmark) | Dynamic Adjustment (0.8–1.2 Benchmark) | 3.2–4.0 | Adaptive Algorithm Effectively Reduces Errors |
| DER and Multi-Point Faults | Dynamic Adjustment (0.8–1.2 Benchmark) | Dynamic Adjustment (0.8–1.2 Benchmark) | 3.5–4.5 | Adaptive Adjustment Reduces Errors Under Complex Conditions |
4.5 Data Fusion and Heterogeneous Data Integration Verification
To deeply examine the system’s performance in multi-data source fusion and heterogeneous data integration, a joint acquisition test was carefully designed, covering the following data sources: first, field sensor data for real-time collection of temperature, current, and voltage signals; second, PMU data providing synchronized phase information, crucial for capturing transient fluctuations; third, SCADA system data for monitoring and control commands as well as historical data comparison; and fourth, IoT supplementary data to enhance environmental status information. To validate the system’s data processing capabilities under complex conditions, tests were added for scenarios involving large-scale DER access and multi-point faults. The results demonstrate that the system maintains high data integrity and preprocessing efficiency even under these conditions. After joint testing of different data sources, statistical comparisons were conducted on the data preprocessing process, protocol conversion effectiveness, and edge node data cleaning results. To address data quality differences such as noise or missing data, the following preprocessing measures were taken: (1) Noise reduction using low-pass filtering and wavelet decomposition to eliminate noise and outliers, followed by normalization and standardization to ensure high data consistency and accuracy. (2) Missing data handling using linear interpolation and model-based prediction. (3) Data fusion optimization with weighted strategies based on data quality, assigning lower weights to poor-quality data to minimize its impact. The results are presented in Table 3.
Table 3 Heterogeneous data fusion effect statistics
| Data | Sampling | Preprocessing | Data | |
| Source Types | Frequency | Delay (ms) | Integrity (%) | Remarks |
| Industrial Sensors | 50100 Hz | 1518 | 99 | Multi-level redundancy ensures real-time data submission |
| PMU Systems | 3050 Hz | 1822 | 98.5 | Synchronized acquisition accommodates instantaneous fluctuations |
| SCADA Systems | 1 Hz5 Hz | 58 | 99.5 | Historical data and control commands |
| IoT Ancillary Devices | Not fixed | 2030 | 97 | Data fluctuation highly influenced by network environment |
| DER and Multi-Point Faults | 50100 Hz | 2025 | 98.2 | Maintains high data integrity and preprocessing efficiency under complex conditions |
4.6 Validation of Integrated System Scheduling and Feedback Mechanism
In the digital twin system, real-time feedback and online decision-making is a crucial part. In the experiment, the system synchronizes the dynamic state evaluation results to the operation and maintenance platform via RESTful API, and automatically generates fault isolation and scheduling optimization schemes relying on the rule engine. Figure 3 shows the topology schematic of the system feedback mechanism:
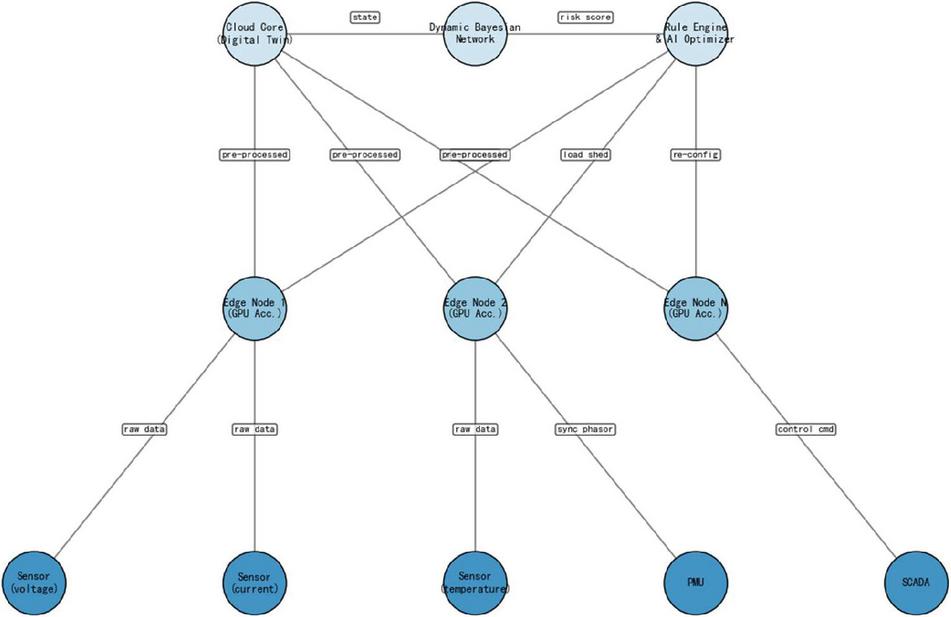
Figure 3 Topology of cloud-edge-end collaborative feedback.
In Figure 3, the modules are seamlessly connected through standard interfaces to ensure that the data and warning information are efficiently transmitted throughout the life cycle, and together they realize the intelligent decision-making of the system. Meanwhile, the online decision-making part adopts Deep Belief Network (DBN) output, and the optimization scheme generated from the quantitative assessment of key risk points is tested to be quickly implemented in actual load adjustment and fault isolation, reducing the time for on-site manual intervention and effectively lowering the risk of accident proliferation.
5 Conclusion
In this paper, a digital twin modeling and operation monitoring framework for substation secondary systems in distributed energy networks based on dynamic Bayesian networks and cloud-edge collaborative architecture is proposed, which realizes the collaborative work of the physical layer, the edge layer, and the cloud core layer through a layered design. The framework demonstrates excellent performance in data acquisition, transmission, processing and modeling, and significantly improves the operation monitoring capability of substation secondary systems in distributed energy environments. Experimental validation shows that the system achieves the design goals in key indicators such as real-time state estimation, fault warning and data processing. The adaptive UKF algorithm effectively reduces the state estimation error, and the fault warning accuracy is as high as 96.5%, which meets the demand of refined operation and maintenance of smart grid. In addition, the system performs well in data fusion and heterogeneous data integration, providing a reliable guarantee for the efficient utilization of multi-source data. The research results not only provide an innovative solution for the intelligent upgrade of substation secondary systems, but also lay a solid foundation for the large-scale access and efficient management of distributed energy in the future smart grid. With the increasing proportion of distributed energy in the power grid, the promotion and application of this framework will help to further enhance the flexibility, reliability and intelligence level of the power grid, and provide key technical support for the construction of a new type of power system.
References
[1] Georgilakis P S. Review of computational intelligence methods for local energy markets at the power distribution level to facilitate the integration of distributed energy resources: State-of-the-art and future research[J]. Energies, 2020, 13(1): 186.
[2] Zhang J, Liu Z, Luo L, et al. Design and application of active monitoring system for secondary equipment in substation[C]//2024 7th International Conference on Advanced Algorithms and Control Engineering (ICAACE). IEEE, 2024: 1297–1301.
[3] Kuang H, Hu Z, Li X, et al. Research on Design Method of Intelligent Operation and Maintenance System for Secondary Equipment in Intelligent Substation[C]//Journal of Physics: Conference Series. IOP Publishing, 2022, 2260(1): 012051.
[4] CHEN Haidong, MONG Fei, WANG Qing, et al. Impact of installed capacity of energy storage system and new energy generation on power system performance[J]. Energy Storage Science and Technology, 2023, 12(2): 477.
[5] Pan H, Dou Z, Cai Y, et al. Digital twin and its application in power system[C]//2020 5th International Conference on Power and Renewable Energy (ICPRE). IEEE, 2020: 21–26.
[6] Xu B, Wang J, Wang X, et al. A case study of digital-twin-modelling analysis on power-plant-performance optimizations[J]. Clean Energy, 2019, 3(3): 227–234.
[7] Zhao Y, Tong J, Zhang L, et al. Diagnosis of operational failures and on-demand failures in nuclear power plants: An approach based on dynamic Bayesian networks[J]. Annals of nuclear energy, 2020, 138: 107181.
[8] Panda S, Mohanty S, Rout P K, et al. An insight into the integration of distributed energy resources and energy storage systems with smart distribution networks using demand-side management[J]. Applied Sciences, 2022, 12(17): 8914.
[9] Pan X, Jiang A, Wang H. Edge-cloud computing application, architecture, and challenges in ubiquitous power Internet of Things demand response[J]. Journal of Renewable and Sustainable Energy, 2020, 12(6): 062702.
[10] Ford R, Maidment C, Vigurs C, et al. Smart local energy systems (SLES): A framework for exploring transition, context, and impacts[J]. Technological Forecasting and Social Change, 2021, 166: 120612.
[11] Aghazadeh Ardebili A, Zappatore M, Ramadan A I H A, et al. Digital Twins of smart energy systems: a systematic literature review on enablers, design, management and computational challenges[J]. Energy Informatics, 2024, 7(1): 94.
[12] Jafari M, Kavousi-Fard A, Chen T, et al. A review on digital twin technology in smart grid, transportation system and smart city: Challenges and future[J]. IEEe Access, 2023, 11: 17471–17484.
[13] Bayer D, Pruckner M. A digital twin of a local energy system based on real smart meter data[J]. Energy Informatics, 2023, 6(1): 8.
[14] Jain P, Poon J, Singh J P, et al. A digital twin approach for fault diagnosis in distributed photovoltaic systems[J]. IEEE Transactions on Power Electronics, 2019, 35(1): 940–956.
[15] Kumar N M, Chand A A, Malvoni M, et al. Distributed energy resources and the application of AI, IoT, and blockchain in smart grids[J]. Energies, 2020, 13(21): 5739.
[16] Song X, Cai H, Kircheis J, et al. Application of digital twin assistant-system in state estimation for inverter dominated grid[C]//2020 55th International Universities Power Engineering Conference (UPEC). IEEE, 2020: 1–6.
[17] Danilczyk W, Sun Y L, He H. Smart grid anomaly detection using a deep learning digital twin[C]//2020 52nd North American Power Symposium (NAPS). IEEE, 2021: 1–6.
[18] Arraño-Vargas F, Konstantinou G. Modular design and real-time simulators toward power system digital twins implementation[J]. IEEE Transactions on Industrial Informatics, 2022, 19(1): 52–61.
[19] Hussain S, Iqbal A, Zanero S, et al. A novel methodology to validate cyberattacks and evaluate their impact on power systems using real time digital simulation[C]//2021 IEEE texas power and energy conference (TPEC). IEEE, 2021: 1–6.
[20] Gao A, Zheng J, Mei F, et al. Toward intelligent demand-side energy management via substation-level flexible load disaggregation[J]. Applied Energy, 2024, 367: 123361.
[21] Asghar Z, Hafeez K, Sabir D, et al. RECLAIM: Renewable energy based demand-side management using machine learning models[J]. IEEE Access, 2023, 11: 3846–3857.
Biographies

Wang Xiqiong, a native of Xiangyun, Yunnan Province, studied at the School of Electrical and Information Engineering of Southwest Minzu University from 2012 to 2016 and obtained a bachelor’s degree. I have been working at Lincang Power Supply Bureau of Yunnan Power Grid Co., Ltd. since July 2016, and have been working in the substation repair and testing Institute for 9 years. Senior secondary on-site operation and maintenance worker, has successively participated in and completed multiple large-scale projects such as the infrastructure project of 220 kV Dengke Substation, regular inspection of 500 kV Boshang Substation, and construction of Baoxin sub-station of 35 kV substation, and has also undertaken the review work of many projects.

Yang Lei, a native of Dali, Yunnan Province, studied at the School of Electrical Engineering, Shandong University of Science and Technology from 2017 to 2021 and obtained a bachelor’s degree. I have been working at Lincang Power Supply Bureau of Yunnan Power Grid Co., Ltd. since July 2021 and have been working in the substation repair and Testing Institute for four years. As a team member, I have successively participated in multiple large-scale projects such as the 500 kV Boshang integrated Automation transformation and the 220 kV Fengshan intelligent Station construction. At the same time, I have frequently participated in the formulation of standards for the network company and the provincial company, covering secondary professional risk control, secondary remote technical supervision, operation supervision, etc. I have also frequently participated in on-site and remote technical supervision of secondary systems.

Gao Zhilin, a native of Fengqing, Yunnan Province, studied at the School of Electrical Engineering, Yanshan University from 2014 to 2018 and obtained a bachelor’s degree. I have been working at Lincang Power Supply Bureau of Yunnan Power Grid Co., Ltd. since July 2018 and have been working in the substation repair and testing Institute for 7 years. He has successively participated in and completed multiple large-scale projects such as the 500 kV Boshang integrated automation transformation, 500 kV series compensation transformation, 220 kV Fengshan Substation, and 110 kV Baima Substation intelligent station construction, and has also undertaken the review work of many projects.

Wen Yesheng, a native of Xinyi, Guangdong Province, studied at China Agricultural University from 2001 to 2005 and obtained a bachelor’s degree. I have been working at Lincang Power Supply Bureau of Yunnan Power Grid Co., Ltd. since December 2005, and have been working in the substation repair and testing Institute for 19 years. As a team member and team leader, I have successively participated in and completed multiple projects such as the 500 kV Boshang integrated automation transformation and the series compensation transformation, and have also been involved in the drawing review work of many projects.

He Zhihai, male, Yi ethnic group, born in August 1976, is from Honghe, Yunnan Province. He is an engineer and currently works at Lincang Power Supply Bureau of Yunnan Power Grid Co., LTD., engaged in the primary maintenance of substations. I have successively participated in and completed multiple technical challenges and equipment overhauls, supervision and manufacturing, and project reviews for the 500 kV Boshang Substation, including the excessive gas content in the main transformer, the 220 kV Washan Substation, and the 500 kV Xingfu Substation project review.
Distributed Generation & Alternative Energy Journal, Vol. 40_4, 793–822.
doi: 10.13052/dgaej2156-3306.4048
© 2025 River Publishers