Secure Data Sharing in Cloud Using an Efficient Inner-Product Proxy Re-Encryption Scheme
Masoomeh Sepehri1, Alberto Trombetta2 and Maryam Sepehri1
- 1Department of Computer Science, University of Milan, Milan, Italy
- 2Department of Computer Science and Communication, University of Insubria,Varese, Italy
E-mail: masoomeh.sepehri@unimi.it; maryam.sepehri@unimi.it; alberto.trombetta@uninsubria.it
Received 1 December 2017; Accepted 6 December 2017;
Publication 9 January 2018
Abstract
With the ever-growing production of data coming from multiple, scattered, highly dynamical sources (like those found in IoT scenarios), many providers are motivated to upload their data to the cloud servers and share them with other persons with different purposes. However, storing data on cloud imposes serious concerns in terms of data confidentiality and access control. These concerns get more attention when data is required to be shared among multiple users with different access policies. In order to update access policy without making re-encryption, we propose an efficient inner-product proxy re-encryption scheme that provides a proxy server with a transformation key with which a delegator’s ciphertext associated with an attribute vector can be transformed to a new ciphertext associated with delegatee’s attribute vector set. Our proposed policy updating scheme enables the delegatee to decrypt the shared data with its own key without requesting a new decryption key. We experimentally analyze the efficiency of our scheme and show that our scheme is adaptive attribute-secure against chosen-plaintext under standard Decisional Linear (D-Linear) assumption.
Keywords
- Attribute-based cryptography
- Secure data sharing
- Fine-grained access control
- Proxy re-encryption
1 Introduction
The emerging trend of sharing information among different users (esp. businesses and organizations) aiming to gain profit, has recently attracted a tremendous amount of attention from both research and industry communities. However, despite all benefits that data sharing inevitably provides [33], many organizations are reluctant to share their data with others due to the large initial investments of expensive infrastructure setup, large equipment, and daily maintenance cost [12]. With the advent of cloud computing; data outsourcing paradigm makes shared data much more accessible as users can retrieve them from anywhere with significant cost benefits. There are major concerns, with data confidentiality in the cloud as organizations lose control of their data and disclose sensitive information to a service provider that is not fully trusted. In addition, most organizations do not wish to grant full access privilege to other users. To this purpose, many research efforts have been dedicated to solve these issues by proposing cryptographically enforced access control mechanisms to set access policies for encrypted data such that only users with appropriate authorization can have access. Hence, many cryptographic-based approaches have been proposed and among them, attribute-based encryption (ABE) schemes [28] look very promising since they bind fine-grained access control policies to the data and they do not require an access control manager to check the access policies in real time. In ABE scheme, data is encrypted based on the set of attributes (key-policy ABE [10]) or according to an access control policy over attributes (ciphertext-policy ABE [2]), such that the decryption of ciphertext is possible only if a set of attributes in the user’s private key matches with the attributes of the ciphertext, so that the data can be encrypted without exact knowledge of the users set that will be able to decrypt. Moreover, in ABE scheme senders and recipients are decoupled because they do not need to pre-share secrets, which simplifies key management for large-scale and dynamic systems and which makes data distribution more flexible. Furthermore, the ABE scheme is more strongly resistant to collusion attacks than traditional public key encryption schemes [2]. Although access control mechanisms based on ABE schemes present advantages regarding reduced communication, storage management and provide a fine-grained access control, they are not suitable for scenarios in which data must be shared among different parties with different access policies. A straightforward solution for applying a new access policy to the data is to decrypt the data and then re-encrypt it with a new access policy. However, this approach is very time-consuming and causes much computational overhead. These issues can be addressed by the adopting an attribute-based proxy re-encryption (ABPRE) scheme that delegates the re-encryption capability to a semi-trusted proxy who can transform the encrypted data to those encrypted under a different access policy by using the re-encryption key, which reduces the computational overhead of the data owner and the sensitive information as well as the user’s private key cannot be revealed to the proxy. Although ABPRE approaches preserve the privacy of shared data among users with different access policies, they do not sufficiently protect the attributes associated with the ciphertexts. For example, in a healthcare scenario medical data require a high degree of privacy since they are accessed by many parties such as patients or staffs (e.g. doctors, nurses, care practitioners, etc.,) from a different department or belonging to different hospitals. Therefore, even partial exposure of those attributes could hurt the patient’s privacy. Thus, access control system based on ABE are not enough to provide appropriate protection for sensitive data in some scenario like healthcare. Instead, predicate encryption (PE) scheme [14] can solve the above problems by offering the “attribute-hiding” property (which means that is not possible to determine the set of attributes with which the ciphertext is encrypted) as well as the “payload-hiding” property where a ciphertext conceal the plaintext. Informally, in the attribute-hiding, the secrecy of challenge attributes and is ensured against the adversary having private key if the compatibility condition < holds (here, denotes the standard inner product). In this work, we construct an adaptive secure attribute-hiding scheme through a proxy re-encryption method obtained with a non-trivial modification of a well known inner-product-based, attribute-based encryption scheme proposed by Park [26]. Unlike the existing scheme [32], we formally show that our proposal is adaptively secure for attribute-hiding (attribute-hiding in the sense of the definition by
The work is organized as follows: in Section 2 we present and analyze the related works; in Section 3 we introduce the definitions of inner-product encryption IPE and inner-product proxy re-encryption IPPRE and their security definitions; in Section 4 we present cryptographic primitives and complexity assumptions which are used in our proposed protocol; in Section 5 we provide a high-level view of the system in which we deploy in our scheme; in Section 6 we provide a detailed description of our proposed scheme and security proof based on standard game-based techniques; in Section 7 we show that our scheme can be efficiently implemented; finally, in Section 8 we draw some conclusions and propose some lines for future work.
2 Related Work
Proxy re-encryption scheme. Recently, several research papers have been developed for secure data sharing in the cloud [27, 30, 31]. Most of these works have adopted proxy re-encryption (PRE) scheme which was first proposed by Mambo and Okamoto [24] as a way to support the delegation of decryption rights. A seminal paper by Blaze et al. [3] proposed a bidirectional PRE scheme (called BBS) based on El-Gamal scheme [8] and introduced the notion of “re-encryption key”. Using this key, a semi-trusted proxy server transforms a ciphertext encrypted under the delegator’s public key into another ciphertext of the same plaintext encrypted under delegate’s public key without revealing the underlying plaintext and user private key. Although BBS proxy re-encryption scheme is secure against chosen-plaintext attacks (CPA); however, it requires pre-sharing private key between parties in order to compute re-encryption key and has bidirectional property i.e., re-encryption key can be used to transform ciphertext from the delegator to the delegatee and vice versa, therefore it is only useful when the trust relationship between involved parties is mutual. Moreover, the scheme is not suitable for group communication since the proxy has to preserve n re-encryption key for n group members. Furthermore, BBS proxy re-encryption scheme exposed to collusion attacks, if the proxy colludes with one party they can recover the private key of the other party. To tackle these disadvantages, Ateniese et al. [1] proposed the first unidirectional and collusion resistant proxy re-encryption scheme without requiring pre-sharing between parties, based on bilinear maps.
Although proxy re-encryption techniques enable secure data sharing among different users in the cloud, they do not enforce fine-grained access control policies on the shared data. To address this issue, the traditional PRE approach has been extended with functionalities taken from attribute-based encryption (ABE) scheme in which both ciphertexts and user’s private keys are associated with an attribute set and a user can decrypt a ciphertext only if the set of attributes in his private key match the attributes associated to the ciphertext [2, 10, 28].
Attribute-based proxy re-encryption scheme. An attribute-based proxy re-encryption (ABPRE) scheme was first proposed by Guo et al. [13] based on an (key-policy) attribute-based encryption scheme [10] and a general proxy re-encryption scheme. Under this scheme, a semi-trusted proxy server transforms a ciphertext associated with a set of attributes into a new ciphertext associated with different attributes set, without leakages about the plaintext and user private key. It has been proven that the security of the proposed scheme in the standard model based on decisional bilinear Diffie-Hellman (DBDH) assumption.
By adopting identity-based proxy re-encryption [11] to the construction of ciphertext-policy attribute-based encryption (CP-ABE) scheme [7], Liang et al. [21] presented the first ciphertext-policy attribute-based proxy re-encryption (CP-ABPRE) scheme. In this scheme, a proxy transforms a ciphertext generated under an access policy to another one corresponding to the same plaintext but to a different access policy. Their scheme satisfies
Later, Luo et al. [22] presented a ciphertext-policy ABPRE, which supports AND-gates access policies on multi-value attributes, negative attributes, and wildcards (which means the attributes don’t appear in the AND-gates, therefore they are not considered in decryption algorithm). Their scheme satisfies the properties of PRE, such as unidirectionality, non-interactivity and multi-hop. Moreover, their scheme has two new properties: (i) re-encryption control: the encryptor can decide whether the ciphertext can be re-encrypted or not, and (ii) extra access control: the proxy can add extra access policy to the ciphertext during re-encryption process.
The computation cost of the previous ABPRE schemes is according to the number of attributes in the system, which implies huge computational overhead. To address this issue, based on Emura et al.’s [9] CP-ABE scheme which has a constant ciphertext length, Seo et al. [29] presented a CP-ABPRE scheme with constant number of pairing operations, which reduced significantly the computational cost and ciphertext length compared to previous ABPRE schemes. They reduced the number of pairing operation by using an exponential operation which can easily calculate the summation of the exponent. Therefore, they calculated the exponent and then computed the pairing operation just once. Their scheme can be adapted to various applications including e-mail forwarding and distributed file systems.
Most of the previous CP-ABPRE schemes [21, 22, 29, 36] only support AND-gates access structure on (multi-valued) positive and negative attributes. This limits their practical use. Therefore, it is desirable to propose a CP-ABPRE system supporting more expressive and flexible access policy. To tackle this issue, Li [18] presented a new CP-ABPRE scheme using matrix access structure policy which supports any monotonic access formula. Their scheme satisfies the properties of both PRE and CP-ABPRE schemes, such as unidirectionality, non-interactivity, multi-hop, re-encryption control, extra access control and secret key security providing a guarantee for the delegator such that if the proxy and all delegatees collude, they can not recover his master secret key. Moreover, they described the security model called Selective-Policy Model for their CP-ABPRE scheme based on [21].
The aforementioned CP-ABPRE schemes are only secure against selective chosen-plaintext attacks (CPA). The CPA security might not be sufficient enough in an open network since it only achieves the very basic requirement from an encryption scheme, which only allows an encryption to be secure against “passive” adversaries. Nevertheless, in a real network scenario, there might exist “active” adversaries trying to tamper an encryption in transit and next observing its decryption such that to obtain useful information related to the underlying data. Therefore, a CP-ABPRE system being secure against chosen-ciphertext attacks (CCA) is needed to prevent the above subtle attacks and enables the system to be further developed. To address this issue, based on the Waters’s CP-ABE scheme [35], Liang et al. [19] proposed the first secure CP-ABPRE scheme against selective chosen-ciphertext attacks (CCA) which supports any monotonic access structures. Moreover, They constructed their proposed scheme in the random oracle model and they showed that their scheme can be proven CCA secure under the decisional q-parallel bilinear Diffie-Hellman exponent (q-parallel BDHE) assumption.
However, a CP-ABPRE system with selective security limits an adversary to choose an attack target before playing security game. Therefore, an adaptively CCA secure CP-ABPRE scheme is needed in most of the practical network applications. Thus, Liang et al. [20] proposed the first adaptively CCA-secure CP-ABPRE scheme by integrating the dual system encryption technology with selective proof technique. Their scheme supports any monotonic access structure such that users are allowed to fulfill more flexible delegation of decryption rights. This scheme is proven adaptively CCA secure in the standard model without loss of expressiveness on access policy. However, their scheme demands a number of paring operations that implies huge computational overheads.
Recently, Li et al. [17] proposed an efficient and adaptively secure
Predicate encryption scheme. Although the attribute-based proxy re-encryption schemes have desirable functionality, they do not guarantee attribute-hiding property i.e., a ciphertext conceals the associated attributes as well as the plaintext so that no information about attributes is revealed during the decryption process. Therefore, to preserve the confidentiality of the attributes associated with the ciphertext, a seminal paper of Katz et al. [14] introduced the notion of predicate encryption (PE) as a generalized (fine-grained) notion of public key encryption that allows one to encrypt a message as well as attributes. In predicate encryption scheme, a ciphertext associated with attribute set I ∈ Σ can be decrypted by a private key SKf corresponding to the predicate f ∈ℱ if and only if f(I) = True. Katz et al. [14] also presented a special type of predicate encryption for a class of predicates called inner-product encryption (IPE). In IPE, both ciphertext and private key are associated with vector and respectively and the ciphertext can be decrypted by the private key if and only if (here, denotes the standard inner-product). Their method represents a wide class of predicates including conjunction and disjunction formulas and polynomial evaluations.
Later, Okamoto et al. [25] proposed a hierarchical predicate encryption (HPE) scheme for inner-product encryption. They used n-dimensional vector spaces in prime order bilinear groups and achieves full security under the standard model. In [16], Lewko et al. showed a fully secure IPE scheme based on composite bilinear groups resulting low practical efficiency. Although these IPE constructions achieve attribute-hiding properties, the security of their schemes is not under well-known standard assumptions. A different work of Park [26] presented an efficient IPE scheme supporting the attribute-hiding property. Their scheme is based on prime order bilinear groups and secure against the well-known Decision Bilinear Diffie-Hellman (BDH) and Decision Linear assumptions.
3 Definitions
In this section, we formally define the syntax of inner-product encryption (IPE) and inner-product proxy re-encryption (IPPRE) and their security properties. Our IPE definition follows the general framework of that given in [26]. Throughout this section, we consider the general case where Σ denotes an arbitrary set of attribute vectors and ℱ denotes an arbitrary set of predicates involving inner-products over Σ.
Definition 1. An inner-product predicate encryption scheme (IPE) for the class of predicates ℱ over the set of attributes Σ consists of PPT algorithms Setup, KeyGen, Encrypt and Decrypt such that:
SetupIPE: takes as input a security parameter λ and a positive dimension n of vectors. It outputs a public key PK and a master secret key MSK.
KeyGenIPE: takes as input a public key PK,a master secret key MSK, and a predicate vector . It outputs a private key associated with vector .
EncryptIPE: takes as input a public key PK,an attribute vector and a message M ∈ℳ. It outputs a corresponding ciphertext .
DecryptIPE: takes as input a private key , and the ciphertext . It outputs either a massage M if , i.e., , or the distinguished symbol ⊥ if .
Definition 2. An inner-product predicate encryption scheme for predicate ℱ over attributes Σ is attribute-hiding secure against adversary 𝒜 under chosen plaintext attacks is given as follows:
Setup. The challenger runs the Setup algorithm and it gives the public key PK to the adversary 𝒜.
Phase 1. The adversary 𝒜 is allowed to adaptively issue a polynomial number of key queries. For a private key query , the challenger gives to 𝒜.
Challenge. For a challenge query , subject to the following restriction:
- for all private key queries or
- two challenge messages are equal, i.e X0 = X1, and any private key query satisfies .
The challenger flips a random b ∈{0,1} and computes the corresponding ciphertext as ← Encrypt. It then gives to the adversary.
Phase 2. The adversary 𝒜 is allowed to adaptively issues polynomial number of key queries. For a private key query subject to the aforementioned restrictions.
Finally, 𝒜 outputs its guess b′∈{0,1} for b and wins the game if b = b′. An advantage 𝒜 in attacking IPE is defined as . Therefore, an IPE scheme is attribute-hiding if all polynomial time adversaries have at most negligible advantage in the above game. If the restriction 1 in challenge is allowed for 𝒜, an IPE scheme is payload-hiding if all polynomial time adversaries have at most negligible advantage in the game.
Definition 3. An inner-product proxy encryption (IPPRE) scheme creates a re-encryption key ReKeythat gives the possibility of transforming a ciphertext associated with a vector into a new ciphertext encrypting the same plaintext but associated with a different vector , while maintaining the confidentiality of the underlying plaintext. IPPRE scheme for the class of predicates ℱ over n–dimensional vectors Σ for message space ℳ, consists of seven PPT algorithms Setup, Encrypt, KeyGen, Re-KeyGen, Re-Encrypt and Decrypt such that:
SetupIPPRE: takes as input a security parameter λ and a dimension n of vectors. It outputs a public key PK and a master secret key MSK.
EncryptIPPRE: takes as input the public key PK, a vector ∈ Σ of attributes and a message M ∈ℳ to output a ciphertext .
KeyGenIPPRE: takes as input the master secret key MSK, the public key PK and a predicate vector . It outputs a private key associated with vector .
Re-KeyGenIPPRE: takes as input the master secret key MSK and two vectors and . It outputs a re-encryption key that transforms a ciphertext that could be decrypted by into a ciphertext encrypted with vector .
Re-EncryptIPPRE: takes as input a re-encryption key and a ciphertext to output a re-encrypted ciphertext .
DecryptIPPRE: takes as input the ciphertext and the private key . It outputs either a message M if , i.e., , or the distinguished symbol ⊥ if .
From here on, we use the terms Level-1 (L1) and Level-2 (L2) to denote ciphertexts obtained as the output of Encrypt and Re-Encrypt algorithms, respectively.
Correctness. The correctness property requires to decrypt the ciphertext by the appropriate private key. More precisely, for the two levels L1 and L2 we have:
L1: Decrypt (KeyGen , Encrypt
L2: Decrypt (KeyGen (MSK,PK,), Re-Encrypt (Re-KeyGen (KeyGen ,
where satisfies satisfies , MSK is a master secret key, PK is a public key, is a ciphertext related to message M and an attribute vector .
Definition 4 (Attribute-Hiding for Level-1 Ciphertexts (AH-L1)). An inner-product proxy re-encryption (IPPRE) scheme, predicate ℱ over vectors Σ is attribute-hiding secure Level-1 against adversary 𝒜 under chosen-plaintext attacks (CPA) if for all probabilistic polynomial-time PPT, the advantage of 𝒜 in the following security game Γ is negligible in the security parameter.
Setup. The challenger ℬ runs Setup (λ, n) algorithm and gives the public key PK to 𝒜.
Phase 1. 𝒜 adaptively makes a polynomial number of queries as:
- Private key query: For a private key query the challenger gives KeyGen (MSK, PK, ) to 𝒜, where R indicates that is randomly selected from KeyGen according to its distribution.
- Re-encryption key query: For a re-encryption key query with , the challenger computes Re-KeyGen (MSK, ) where KeyGen (MSK, PK, ) and gives the re-encryption key to the adversary.
- Re-encryption query: For a re-encryption query computes the re-encryption key Re-KeyGen (MSK, ), where KeyGen (MSK, PK, ) and Re-Encrypt (PK, ).
Challenge. For a challenge query under the condition that:
– Any private key query and re-encryption key query , for l = 1,…,p1 where p1 is the maximum number of private key queries requested by the adversary, M0 = M1 if and in the case that .
The challenger ℬ samples a random bit , where U indicates that b is
Phase 2. 𝒜 may continue to request private key queries, re-encryption key queries and re-encryption queries subject to the same restrictions as before and the condition for the re-encryption queries.
Re-encryption Query: For a re-encryption query of the form for t = 1,…,p2 where p2 is the maximum number of re-encrypted queries, under the condition that M0 = M1 if and for any decryption key query for if .
The challenger computes Re-KeyGen and Re-Encrypt , and it gives to the adversary.
Guess. 𝒜 outputs a bit b′ and succeeds if b′ = b.
Hence, we define the advantage 𝒜 as . The IPPRE scheme is attribute-hiding Level-1 ciphertext if all polynomial time adversaries have at most negligible advantage in the above game.
Definition 5 (Attribute-Hiding for Level-2 Re-encrypted Ciphertexts
Setup, Phase 1: These algorithms are defined as the same as those we defined in Definition 4, respectively.
Challenge: Upon receiving the query from the adversary with the restrictions that if , for any private key query , the challenger ℬ samples a random bit and gives:
Re-Encrypt(PK, Re-KeyGen(PK, KeyGen(PK, SK,),), Encrypt . Then the challenger gives the result to the adversary.
Phase 2: The adversary 𝒜 may continue to request private key queries, re-encryption key queries and re-encryption queries under the restrictions we mentioned in challenge phase.
Guess: 𝒜 outputs its guess b′ ∈{0,1}b and wins the game b = b′.
We define the advantage of 𝒜 as . Hence, the scheme is predicate- and attribute-hiding for re-encrypted ciphertexts if all polynomial time adversaries have at most negligible advantage in the above game. To prove this statement for each run of the game, we define a variable if for challenge for l = 0,1 and , otherwise.
4 Cryptographic Background and Complexity Assumptions
In this section, we define Bilinear Map following the notation in [5] and review some general assumptions we use in Section 6 to prove the security of our construction.
Bilinear Map. Let 𝔾 and 𝔾T be two multiplicative cyclic groups of prime order p, and g be a generator of 𝔾. A pairing (or bilinear map) e : 𝔾 × 𝔾 → 𝔾T is a function that has the following properties [5]:
- Bilinear: a map e : 𝔾 × 𝔾 → 𝔾T is bilinear if e(ua, vb) = e(u, v)ab for all u, v ∈ 𝔾 and a, b ∈ ℤp∗.
- Non-degenerate: e(g,g)≠1. The map does not send all pairs in 𝔾×𝔾 to the identity in 𝔾T. Since 𝔾 and 𝔾T are groups of prime order, this implies that if g is a generator of 𝔾 then e(g,g) is a generator of 𝔾T.
- Computable: there is an efficient algorithm to compute the map e(u, v) for any u, v ∈ 𝔾.
A map e is an admissible bilinear map in 𝔾 if satisfies the three properties above. Note that e( , ) is symmetric since e(ga, gb) = e(g, g)ab = e(gb, ga).
Decisional Bilinear Diffie-Hellman (DBDH) Assumption [5]. Let a,b,c ∈ ℤp∗ be chosen at random and g be a generator for 𝔾. The Decisional BDH assumption is defined as follows: given (g,ga,gb,gc,Z) ∈ 𝔾4 × 𝔾T as input, determine whether Z = e(g,g)abc or Z is a random in 𝔾T.
The Decision Linear (D-Linear) Assumption [4]. Let z1,z2,z3,z4, ∈ ℤp∗ be chosen at random and g be a generator for 𝔾. The Decision Linear assumption is defined as follows: given (g,gz1,gz2,gz1z3,gz2z4,Z) ∈ 𝔾6 as input, determine whether Z = gz3+z4 or Z is random in 𝔾. We consider an equivalently modified version such as: given (g,gz1,gz2,gz1z3gz4,Z) ∈ 𝔾6 as input, determine whether Z = gz2(z3+z4) or Z is random in 𝔾.
Definition 6. We say that the {Decision BDH, Decision Linear} assumption holds in 𝔾 if the advantage of any polynomial time algorithm is solving the {Decision BDH, Decision Linear} problem is negligible.
5 System Model
In this section, we present a streamlined version of secure and private data sharing system in a healthcare environment to show how to deploy an IPPRE scheme in such real-world scenarios. A IPPRE-based data sharing healthcare system including five entities Data Owner, Authorized Users Owner, Cloud Storage Server, Trust Authority and the Proxy Server works as follows:
Initialization. This step is run by a Trust Authority (TA) who is responsible for key issuing and attribute management. As shown in Figure 1, the authority first generates master secret key MSK and public key PK,and then distributes PK and access policy Ai to each data owner i (e.g., Owner 1 from hospital 1 and Owner 2 from hospital 2). It also generates private keys for Authorized Users (User 1 (e.g., a group of care practitioners) and User 2 (e.g., specialist)).
Data Upload. This step is run at data owner side. Consider that the owner 1 from hospital 1 is willing to store and share its medical records via the Cloud Storage Server in such a way that only care practitioners from hospital 1 can have access. The owner 1 encrypts its own data (e.g., message M1) under a set of associated attributes A1 (e.g., EncryptA1 (M1)), where A1 indicates access privilege on the owner l’s data. In a similar way, the owner 2 uploads its encrypted message (M2).
Data Access. This step is run between the authorized users and the cloud server (Level-1) or between authorized users through the cloud using a proxy server (Level-2).
- Level-1. User 1 who satisfies A1 can access to the owner l’s data using its own private key associated with a vector .
- Level-2. There are some situations in which the user 1 needs to share the owner 1’s medical data with the user 2 from hospital 2 who is able to decrypt only the ciphertexts associated with an access policy A2 (attribute vector in Figure 1), but not the access policy A1 (attribute vector in Figure 1). In this case, a Proxy Server is used to translate the data encrypted with access policy A1 to the one under access policy A2 in an efficient way without revealing the data (payload-hiding property) and its corresponding attributes (attribute-hiding property).
In our system model, we assume that the cloud and proxy server are honest-but-curious i.e., they will correctly execute the protocol, and will not deny services to the authorized users. But they are curious to learn information about data contents.
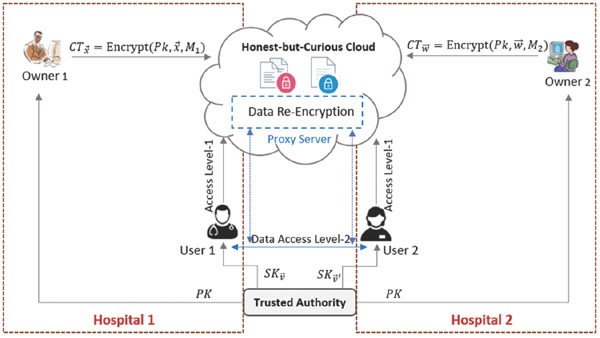
Figure 1 IPPRE-based data sharing healthcare system model.
6 The Main Construction
In this section, we construct our IPPRE scheme in detail and give intuition about our proof. The scheme consists of six algorithms namely Setup, Encrypt, KeyGen, Decrypt, Re-KeyGen, Re-Encrypt. We describe our construction with considering the following assumptions:
Assumptions:
- some positive integer n, Σ = (ℤp∗)n is the set of attributes,
- a vector ∈ Σ, each component vi belong to the set
ℤp∗, and - a message M ∈ ℳ and a vector each belongs to Σ and ℳ = 𝔾T.
6.1 The Construction
(PK, MSK) ← Setup (λ,n). On input a security parameter λ ∈ ℤ+ and the number of attributes n, Setup algorithm runs init(λ)1 to get the tuple (p, 𝔾, 𝔾T,e). It then picks a random generator g ∈ 𝔾, random exponents δ1,δ2,𝜃1,𝜃2,{w1,i}i=1n,{t1,i}i=1n,{f1,i,f2,i}i=1n,{h1,i,h2,i}i=1n in ℤp∗. It also picks a random g2 ∈ 𝔾 and a random Ω ∈ ℤp∗ to obtain {w2,i}i=1n,{t2,i}i=1n in ℤp∗ under constraints that:
For i = 1, …, n, the Setup algorithm first computes:
and then sets:
Finally, the Setup algorithm outputs the public key PK (including (p, 𝔾, 𝔾T,e)) and master secret key MSK as:
KeyGen . On input vector , public key PK and master secret key MSK, the algorithm randomly picks exponents λ1,λ2,{ri}i=1n,{ϕi}i=1n in to output the private key as:
Encrypt (). On input vector , a message M ∈ 𝔾T and the public key PK, the algorithm selects random exponents s1,s2,s3,s4 ∈ ℤp∗ to get ciphertext as the follows:
Where we define each component of as the following, 1 ≤i ≤ n:
In this step, random elements {W1,is1,W2,is1,T1,is1,T2,is1,} are used to mask each component xi of a vector . For instance, the ciphertext C1,i is in the form W1,is1F1,is2U1xis3, which is not easily tested even if we use prime order groups equipped with a symmetric bilinear map. If we omit W1,is1, the resulting term F1,is2U1xis3 is enough for hiding xi component, however, for the case that xi = 0 in ℤp∗, the term becomes F2,is2 that can be tested as using bilinear maps.
Re-KeyGen . The algorithm first calls the KeyGen algorithm and picks a random d ∈ ℤp∗ to compute g2d and g2dδ2,g2-dδ1,g2d𝜃2,g2-d𝜃1. It then calls the Encrypt algorithm to encrypt g2d under the vector using Encrypt and outputs .
To compute the re-encryption key, the Re-KeyGen algorithm picks random exponents λ1′,λ2′,{ri′}i=1n,{ϕi′}i=1n in ℤP∗ and computes 1 ≤ i ≤ n as:
Where we have:
The Re-KeyGen algorithm with the inputs vectors consists of two parts: a modified decryption key vector and a ciphertext encrypted with vector . The modified decryption key differs from a normal decryption key: in the decryption procedure, a normal decryption key combines with elements of the ciphertext to recover the binding factor that is used for hiding the message (e.g., e(g,g2)-s2); the modified decryption key instead produces the product of the blinding factor with another new binding factor. This new blinding factor can only be removed with the combination of a group element encrypted in the Re-KeyGen algorithm (e.g., g2d) and the element B = gs1Ω in the ciphertext. Therefore, the Level-2 access of the Decrypt algorithm consists of the original blinded message, the product with the new blinding factor obtained by decrypting the original ciphertext with the modified decryption key in the Re-Encrypt algorithm, the element B from the original ciphertext and the ciphertext component of the Re-KeyGen algorithm.
Re-Encrypt . On input a re-encryption key and ciphertext, the algorithm outputs
computing , the algorithm checks if the attributes list in satisfies the attributes set of if not, returns ⊥; otherwise, 1 ≤ i ≤ n, it calculates the following pairings to output :
Where we have:
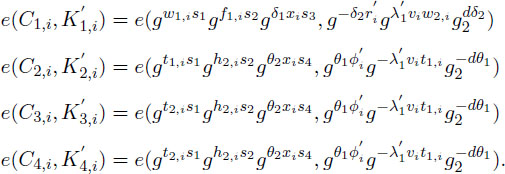
Hence, we expand the above formula as follows:
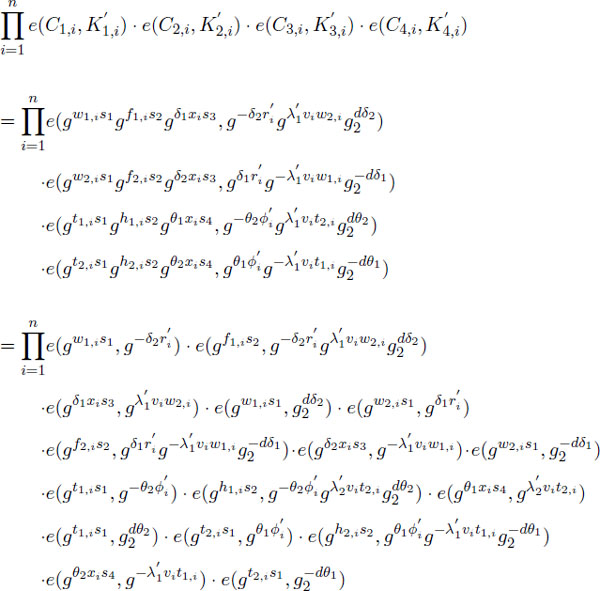
Finally, the algorithm outputs ĈT to obtain:
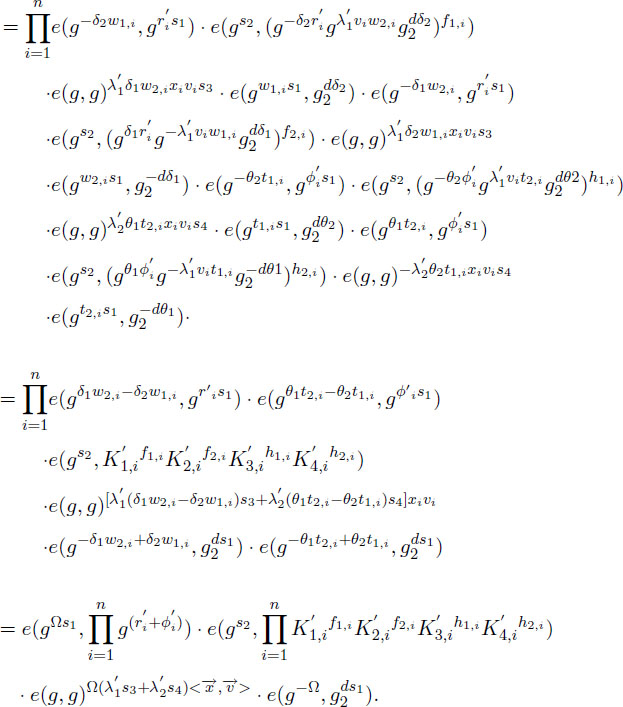
Finally, the algorithm outputs to obtain:
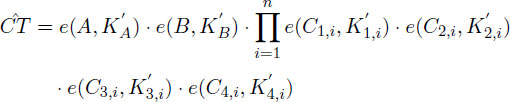
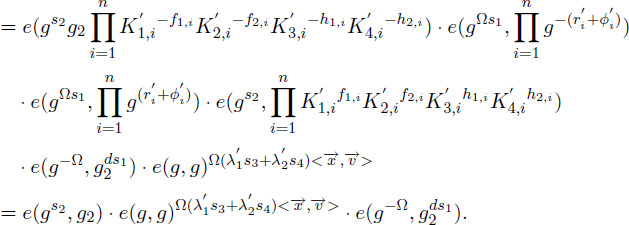
M ←Decrypt . On input the ciphertext and a private key , the algorithm proceeds differently according to two Level-1 or Level-2 access:
Level-1 access. If is an original well-formed ciphertext, then algorithm decrypts using the private key:
to output message M:
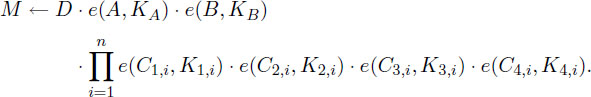
In this step, the masking elements used in Encrypt algorithm have to be canceled out. To this purpose, the proposed scheme generates two relative pairing values, a positive and a negative in order to be removed at the end. This can be checked by the following equality:
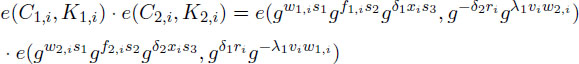
where both e(gw1,is1,gλ1viw2,i) and e(gδ1xis3,g-δ2ri) are canceled out. Additionally, we need to remove e(gw1,is1,g-δ2ri). e(gw2,is1,gδ1ri) that are changed into one pairing as e(gΩs1,gri). This value is also eliminated by the additional computation of e(B,KB) in the decryption procedure.
Correctness.
Assume the ciphertext is well-formed the vector . Then, we have:
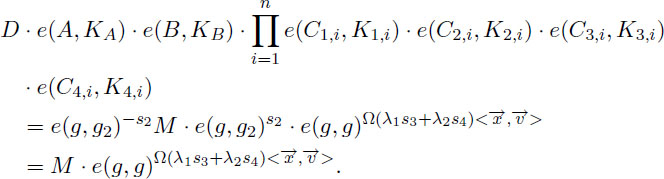
It is worth noting that the term e(g,g2)s2 is generated from the pairing computation e(A,KA) = e(g2 ∏ i=1nK1,i-f1,i2,i-f2,iK3,i-h1,iK4,i-h2,i). Thus, the output of the above result is M if in ℤp∗. If in ℤp∗, then there is only such case that λ1s3 + λ2s4 = 0 in ℤp∗ with probability at most 1/p, as in the predicate-only IPE scheme.
Level-2 access (from here on referred to as Re-Decrypt). If is a re-encrypted well-formed ciphertext, then it is of the form ). The algorithm first decrypts using as above to obtain g2d as Decrypt ()
Then, it calculates: = e(B,g2d) = e(gs1Ω,g2d) and obtains the message as M ← D ⋅ ⋅
The Level-2 access of the Decrypt algorithm consists of the original blinded message, the product with the new blinding factor obtained by decrypting the original ciphertext with the modified decryption key in the Re-Encrypt algorithm, the element B from the original ciphertext and the ciphertext component of the Re-KeyGen algorithm. To decrypt a re-encrypted ciphertext of Level-2 access, the proposed scheme first decrypts the ciphertext component of the Re-KeyGen algorithm to obtain the group element, then combines this group element with the element B from the original ciphertext to use the result removing both the original blinding factor of the message and the new binding factor introduced by the Re-Encrypt algorithm. Finally, the message is recovered if the vector associated with the ciphertext and the vector associated with the private key m orthogonal vectors (e.g., ).
Correctness.
To verify the correctness, we compute D ⋅ ⋅ as:
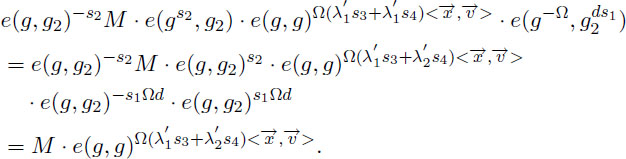
The result outputs M if in ℤp∗. If in ℤp∗, then there is only such case that (λ1′s3 + λ2′s4) = 0 in ℤp∗ with probability at most 1/p, as in the predicate-only IPE scheme.
Level-1 access. If is an original well-med ciphertext, then algorithm decrypts using the private key:
to output message M:
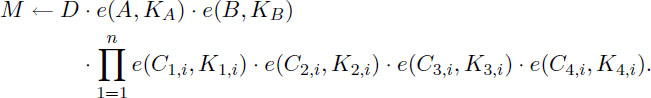
In this step, the masking elements used in Encrypt algorithm have to be canceled out. To this purpose, the proposed scheme generates two relative pairing values, a positive and a negative in order to be removed at the end. This can be checked by the following equality:
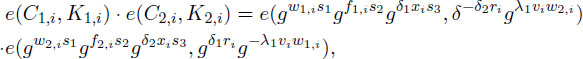
where both e(gw1,is1,gλ1viw2,i) and e(gδ1,ixis3,g-δ2ri) are canceled out. Additionally, we need to remove e(gw1,is1,g-δ2ri) ⋅ e(gw2,is1,gδ1ri) that are changed into one pairing as e(gΩs1,gri). This value is also eliminated by the additional computation of e(B,KB) in the decryption procedure.
Correctness.
Assume the ciphertext is well-formed the vector .
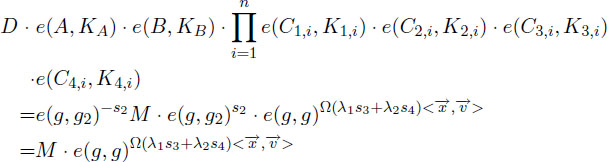
It is worth noting that the term e(g,g2)s2 is generated from the pairing computation of e(A,KA) = e(g2 ∏ i=1nK1,i-f1,i2,i-f2,iK3,i-h1,iK4,i-h2,i). Thus, the output of the above result is M if in ℤp∗. If in ℤp∗, then there is only such case that λ1s3 + λ2s4 = 0 in ℤp∗ with probability at most 1/p, as in the predicate-only IPE scheme.
Level-2 access (from here on referred to as Re-Decrypt). If CT is a re-encrypted well-formed ciphertext, then it is of the form CT′ = (A, B, CT, , D = e(g,g2)-s2M). The algorithm first decrypts CT using SK as above to obtain g2d as Decrypt (SK, CT) → g2d.
Then, it calculates: = e(B,g2d) = e(gs1Ω,g2d) and obtains the message as M ← D ⋅ ⋅.
The Level-2 access of the Decrypt algorithm consists of the original blinded message, the product with the new blinding factor obtained by decrypting the original ciphertext with the modified decryption key in the Re-Encrypt algorithm, the element B from the original ciphertext and the ciphertext component of the Re-KeyGen algorithm. To decrypt a re-encrypted ciphertext of Level-2 access, the proposed scheme first decrypts the ciphertext component of the Re-KeyGen algorithm to obtain the group element, then combines this group element with the element B from the original ciphertext to use the result removing both the original blinding factor of the message and the new
Correctness.
To verify the correctness, we compute D ⋅ ⋅ as:
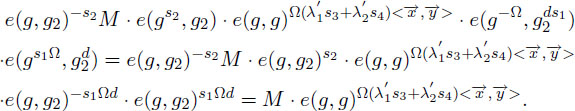
The result outputs M if in ℤp∗. If in ℤp∗, then there is only such case that (λ1′s3 + λ2′s4) in ℤp∗ with probability at most 1/p, as in the predicate-only IPE scheme.
6.2 Proof of Security
Here, we describe a mechanism to show that our proposed scheme achieves the security requirements according to the definitions stated in the Section 3. For Level-1 and Level-2 ciphertext challenge, an adversary may request private key, re-encryption key and re-encryption queries by choosing vectors at the beginning of the security game. For instance, in the case of Level-1 access, the adversary outputs two vectors and queries corresponding to a vector such that where M0 = M1. The adversary goal is to decide which one of the two vectors is associated with the challenge ciphertext. In the case of Level-2 access, the adversary outputs challenge vectors along with for re-encryption keys. The adversary goal is to decide which one of the two vectors is associated with the re-encrypted query.
To prove the Level-1 access, similarly to [14] we suppose that our encryption system contains two parallel sub-systems. That is, a challenge ciphertext will be encrypted with respect to one vector in the first subsystem and a different vector in a second sub-system. Let denote a ciphertext encrypted using vector (that is orthogonal to everything) in intermediate game to prove indistinguishably when encrypting to corresponding to and when encrypting to corresponding to as:
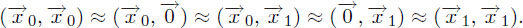
This structure allows us to use a simulator (challenger) that will essentially work in one subsystem without knowing what is happening in the other one [14]. It determines whether a sub-system encrypts the given vector or the zero vector. Details of this proof is given in [26].
To prove the Level-2 access, we apply game transformation proof [15] with a multiple sequence of games whose aim are to change components of the challenge ciphertext to independent ones from challenge bit b (random form). In the following we discuss it in details.
In the following, we show that the proposed IPPRE scheme is predicate-and attribute-hiding re-encrypted ciphertext (Level-2) against chosen-plaintext attacks provided the underlying IPE scheme under the Decision Linear assumption holds in 𝔾.
Proof of Theorem 1 (PAH-L2: Predicate- and Attribute-hiding
We consider two cases in the proof of Theorem 1 according to the value of mentioned in the Definition 5. This value holds the following claims:
- For any private key query , the variable when it holds .
- For any private key query , the variable when it holds .
Theorem 1. The IPPRE scheme is predicate- and attribute-hiding for re-encrypted ciphertexts against chosen-plaintext attacks provided underlying IPE scheme is fully attribute-hiding. For any adversary 𝒜 there exist probabilistic machines 𝜖1-1,𝜖1-2,𝜖2-1 and 𝜖2-2 whose running times are essentially the same as that of 𝒜, such that for any security
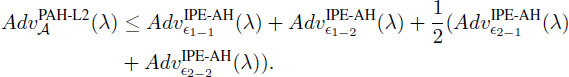
Proof. We execute a preliminary game transformation from Game 0 (original game in Definition 5) to Game 0′, which is the same as Game 0 except flip a coin before setup, and the game is aborted at the final step if . Hence, the advantage of Game 0′ is a half of that in Game 0. The value is chosen independently from , and therefore the probability that the game is aborted is that is . Moreover, in Game 0′.
Hence, we have:
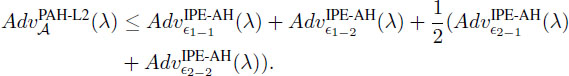
Therefore, to show how our scheme is predicate- and attribute-hiding for re-encrypted ciphertext under D-Linear assumption, we consider the two cases as bellow:
Proof of Theorem 1 in the case
Lemma 1. The proposed IPPRE scheme is predicate- and attribute-hiding for re-encrypted ciphertexts against chosen-plaintext attack in the case under the attribute hiding underlying IPE scheme.
For any adversary 𝒜, there exists probabilistic mechanisms 𝜖1-1 and 𝜖1-2, whose running times are essentially the same as that of 𝒜 such that for any security parameter λ in the case .
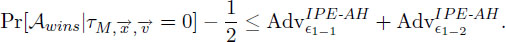
The aim is that CT is changed to a ciphertext with random attribute and random attribute message. We apply the game transformation consisting of three games Game 0′, Game 1 and Game 2. In Game 1, the CTb under vector is changed to CT = Encrypt (PK,,R) where chosen uniformly random from Σ and random value R ∈ 𝔾T.
In the case , the adversary does not request private key query such that < b, >= 0. Hence, CTb is changed to EncryptIPE (PK,,R) by using the attribute-hiding security underlying IPE scheme.
Proof of Lemma 1. In order to prove the Lemma 1, we consider the following games. We only describe the components which are changed in the other games.
Game 0′. Same as Game 0 except that flip a coin before setup, and the game is aborted if τM,,≠SM,,. We consider the case with τM,, = 0 and rely to the challenge query (0,1,M0,M1,0,1,
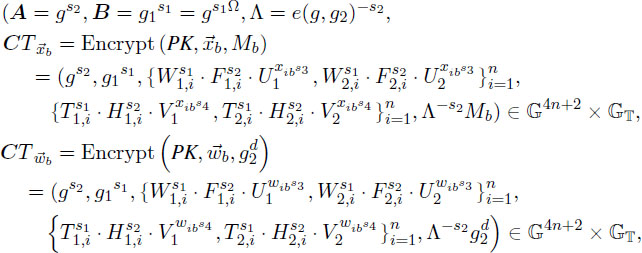
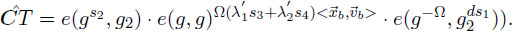
Game 1. Game 1 is the same as Game 0′ except that the reply to challenge query for is as follows:
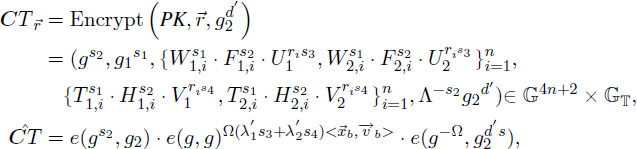
where and .
Game 2. Game 2 is the same as Game 1 except that the reply to challenge query for (0,1,M0,M1,0,1,0,1) is as the follows:
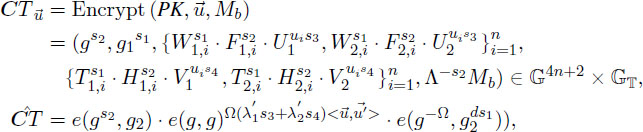
where . We note that and are chosen uniformly and independent from b and b, respectively. CT is generated as in Game 1.
Let Adv𝒜(0′)(λ), Adv𝒜(1)(λ) and Adv𝒜(2)(λ) be the advantages of 𝒜 in Games 0, 1 and 2, respectively. We will use three lemmas (Lemmas 2, 3, 4) that evaluate the gaps between pairs of neighboring games. From these lemmas we obtain:
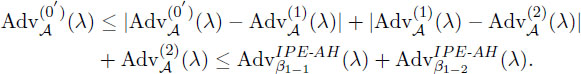
Lemma 2. For any adversary 𝒜, there exists a probabilistic machine β1-1 and β1-2, whose running time is essentially the same as that of 𝒜, such that for any security parameter λ,|Adv𝒜(0′)(λ) -Adv𝒜(1)(λ)|≤ Advβ1-1IPE-AH(λ) + Advβ1-2IPE-AH(λ).
Proof of Lemma 2. We construct probabilistic machines β1-1 and β1-2 against the fully-attribute hiding security using an adversary 𝒜 in a security game (Game 0′ or Game 1) as a block box. To this purpose, we consider the intermediate game Game 1′ that is the same as Game 0′ except that CT of the reply the challenge re-encrypted ciphertext is of the form of Game 1. Hence to prove that |Adv𝒜(0′)(λ) - Adv𝒜(1′)(λ)|≤ Advβ1-1IPE-AH(λ), we construct a probabilistic machine β1-1 against the fully attribute-hiding security using the adversary 𝒜 in a security game (Game 0′ or Game 1′) as block box as follows:
- β1-1 plays a role of the challenger in the security game against the adversary 𝒜.
β1-1 generates a public and secret key and provides 𝒜 with the public key and keeps the secret key as details are stated in Section 6.
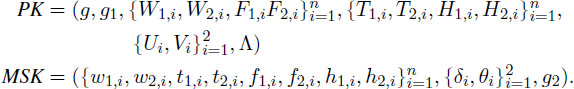
- When a private key query is issued for a vector , β - 1 computes a normal form decryption key and provides 𝒜 with SK = (KA,KB,{K1,i,K2,i}i=1n,{K3,i,K4,i}i=1n).
- When a re-encryption key query is issued for (,), β1-1, computes a normal form re-encryption key RK, = (KA′,KB′,{K1,i′,K2,i′}i=1n,
{K3,i′,K4,i′}i=1n) along with CT = (PK,,g2d). - When a re-encryption query is issued for (,,CT), the challenger β1-1 computes a normal form of re-encryption CT′ and provides 𝒜 with CT′ = (A,B,CT,,D).
- When a challenge query is issued for (0,1,M0,M1,0,1,0,1),
β1-1 picks a bit and computes CT,CT,CT′. The β1-1 submits (Xb := g2d,X(1-b) := R,,:= ,1-b := ) to the attribute-hiding challenger underlying IPE scheme (See Definition 1) where R and are chosen independently uniform. It then receives CTβ for . Finally β1-1 provides 𝒜 with a challenge ciphertext CTb′ = (A,B,CTb = CTβ,,D). - 𝒜 finally outputs b1. β1-1 outputs β = 0 if b = b′, otherwise outputs β = 1. Since CT′ of the challenge re-encrypted ciphertext is of the form Game 0′ (resp. Game 1 if β = 0 (resp. β = 1), the view of 𝒜 given by β1-1 is distributed as Game 1′ (resp. Game 0′) if β = 0 (resp. β = 1). Then, .
In a similar way, we construct a probabilistic machine β1-2 against the fully attribute-hiding security using an adversary 𝒜 in a security game (Game 1′ or Game 1) as a block box. Game 1 is the same as Game 1′ except that CT of the reply to the challenge re-encrypted ciphertext CT where . Hence, we have |Adv𝒜(1′)(λ) - Adv𝒜|(1)(λ)|≤ Advβ1-2IPE-AH(λ). Therefore, we can prove this Lemma by using hybrid argument.
Lemma 3. For any adversary 𝒜,Adv𝒜(1)(λ) = Adv𝒜(2)(λ).
Proof of Lemma 3. From the adversary’s view CT of Game 1 and CT of Game 2 where are information theoretically indistinguishable.
Lemma 4. For any adversary 𝒜,Adv𝒜(2)(λ) = 0.
Proof of Lemma 4. The value b is independent from adversary’s view in Game 2. Hence, 𝒜,Adv𝒜(2)(λ) = 0.
Proof of Theorem 1 in the case τM,,=1
Lemma 5. The proposed IPPRE scheme is predicate- and attribute-hiding for re-encrypted ciphertexts against chosen-plaintext attack in the case τM,,=1 under the attribute hiding underlying IPE scheme.
For any adversary 𝒜, there exists probabilistic mechanisms 𝜖2-1 and 𝜖2-2, whose running times are essentially the same as that of 𝒜 such that for any security parameter λ in the case τM,,=1.
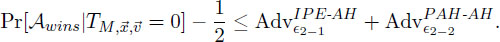
The aim of game transformation here is that CTb is changed to ciphertext with opposite attribute (1-b). Again, we employ two games Game 0′ and Game 1. In Game 1, the CTb is changed to Encrypt (PK,(1-b),g2d), respectively, by using the fully attribute-hiding security of the IPE scheme.
Proof of Lemma 5. To prove this lemma, we consider the following games:
Game 0′. Same as Game 0 except that flip a coin before setup, and the game is aborted if τM,,≠SM,,. We consider the case with τM,, = 1. Again here we only describe the components which are changed in the other games. The reply to challenge query for (M,,,0,1) with (M,,) = (M0,0,0) = (M1,1,1) is:
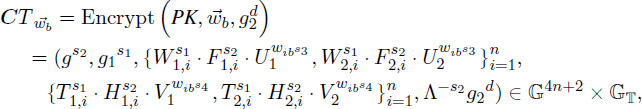
where .
Game 1. Game 1 is the same as Game 0′ except that the reply to the challenge query for (M,,,0,1) with M,, = (M0,0,0) = (M1,1,1) is:
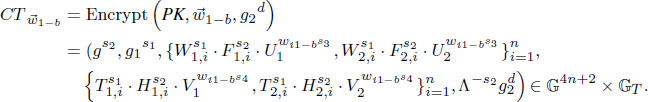
Let and be the advantage of in Game 0$^{'}$ and Game 1, respectively. In order to evaluate the gaps between pairs of neighboring games, we consider the following Lemmas (6 and 7). We have:
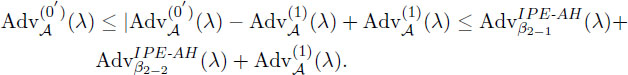
The proof is completed from the Lemma 7 since .
Lemma 6. For any adversary 𝒜, there exists a probabilistic machines β2-1 and β2-2, whose running time is essentially the same as that of 𝒜, such that for any security parameter λ,|Adv𝒜(0′)(λ) -Adv𝒜(1)(λ)|≤ Advβ2-1IPE-AH(λ) + Advβ2-1IPE-AH(λ).
The proof of this lemma is similar to the Lemma 2.
Lemma 7. For any adversary 𝒜,|Adv𝒜(1)(λ) = -Adv𝒜(0′)(λ). The challenge re-encrypted ciphertext for the opposite bit 1 -b to the challenge bit b and the others components are normal forms in Game 1. Hence, success probability Pr[Succ𝒜(1)] in Game 1 is 1 - Pr[Succ𝒜((0′))], where Succ𝒜(0′) is success probability in Game 0′. Therefore, we have Adv𝒜(1)(λ) = -Adv𝒜(0′)(λ).
7 Experimental Evaluation
In this section, we present our evaluation results of the proposed inner-product proxy re-encryption (IPPRE) scheme in terms of computation and communication costs as well as storage overhead. We present both theoretical and the experimental results with the assumption that a total number of attributes in the system is equal to n.
7.1 Theoretical Results
The computational load, defined in terms of number of computational steps required to perform a given task, can be described in the following terms, depending on the party who is performing the task itself:
- Computational Load of the Trusted Authority. The trusted authority has to execute three algorithms: Setup, KeyGen and Re-KeyGen. In the Setup algorithm, the main computation overhead consists of (8n + 5) exponentiation operations on the group 𝔾1 and one pairing operation e(g,g2) that can be ignored since it can computed in advance (pre-computed). The main computation overhead of KeyGen algorithm belongs to the private key generation, which consumes (9n) exponentiation operations on the group 𝔾2. The Re-KeyGen algorithm requires (12n + 2) exponentiation operations on the group 𝔾1 encrypting g2d and (13n) exponentiation operations on the group 𝔾2 for generating re-encryption key.
- Computational Load on the Data Owner. The computational overhead on the side of the data owner is caused by the execution of the Encrypt algorithm, which needs (12n + 2) exponentiation operations on the group 𝔾1 and one exponentiation operations on the group 𝔾T.
- Computational Load on the Proxy. The proxy is responsible for transforming the ciphertext by executing the Re-Encrypt algorithm, which requires (4n + 2) pairing operations.
- Computational Load for Users. The computational overhead on the user side is mainly caused by the Decrypt algorithm. According to our protocol, we have two Decrypt algorithms: one decrypting a ciphertext and another decrypting a re-encrypted ciphertext. The computational overhead of the former consists of (4n + 2) pairing operations. The computational overhead of the latter consists of (4n+3) pairing operations.
- Communication Load. The original ciphertext has four parts: A = gs1,
B = gs1Ω,{C1,i,C2,i}i=1n and {C3,i,C4,i}i=1n. Each Ci has three elements. The ciphertext contains (12n + 2) 𝔾1 and a (1) 𝔾T group elements in total. The re-encrypted ciphertext contains (4n + 2)𝔾T group elements. - Storage Load for Users. The main storage load of each user is for the private key SK, which represents (9n)𝔾2 group elements in total.
7.2 Experimental Results
We implemented our scheme in C using the Pairing-Based Crypto (PBC) library [23]. The experiments were carried out on Ubuntu 16.04 LTS with 2.60 GHz 8x Intel(R) Core(TM) i7-4720HQ CPU and 16 GB RAM.
Using Different Types of Elliptic Curves. The choice of elliptic curve parameters impacts on the credential, signature sizes, and the computational efficiency. We measured the execution time of our scheme on three different types of elliptic curves with 80 bits of security level: SuperSingular (SS) curve
Table 1 Curve Parameters
| Type of Elliptic Curve | SuperSingular | MNT159 | MNT201 | BN |
| Bit length of q | 512 | 159 | 201 | 158 |
| Bit length of r | 160 | 158 | 181 | 158 |
| Embedding Degree | 2 | 6 | 6 | 12 |
| Curve | y2 = x3 + x | y2 = x3 + ax + b | y2 = x3 + ax + b | y2 = x3 + b |
Elliptic curves are classified into two categories: symmetric bilinear group (e : 𝔾1 × 𝔾2 → 𝔾T, 𝔾1 = 𝔾2) and asymmetric bilinear group (e : 𝔾1 × 𝔾2 → 𝔾T, 𝔾1≠𝔾2). To achieve fast pairing computation, elliptic curves from symmetric bilinear groups with small embedding degree are chosen. On the other hand, elliptic curves from asymmetric bilinear groups with high embedding degree offer a good operation for short group element size. For a symmetric bilinear group, we selected the SuperSingular curve over a prime finite field with embedding degree of 2 and the base field size of 𝔾 equal to 512 bits. Then for asymmetric bilinear groups, we considered two MNT curves (namely MNT159 and MNT201) with embedding degree of 6 and one BN curve with embedding degree of 12 and the base 2 and 3, the execution time of each algorithm of our scheme considering an increasing number of attributes from 5 to 30 over 100 runs. The execution time of each algorithm increases linearly with the number of attributes according to its computational overhead (see Section 7.1).
The computational overhead of Encrypt algorithm is dominated by exponentiation operation on group 𝔾1 and therefore MNT159 curve and SS curve respectively with smaller and larger base field size of 𝔾1 2 have the best and worst encryption performance. As shown in Table 3, for 5 attributes, the Encrypt algorithm takes about 19ms under MNT159 curve and 41ms under SS curve. On the other hand, the computational overhead of the KeyGen and the Re-KeyGen algorithms is dominated by exponentiation operation on group 𝔾2. As we can see from Table 3, the execution time of the KeyGen and the Re-KeyGen algorithms under BN curve that has smaller base field size of 𝔾2 3 among other curves is more efficient.
The embedding degree of elliptic curves directly influences the size of 𝔾T and increases the complexity of pairing computation. Therefore, the
Table 2 Average execution time (ms) of each algorithm of the proposed IPPRE scheme on eliptic curves SS and MNT159
| Curve | SS | MNT159 | ||||
| Attribute.num | 5 | 10 | 30 | 5 | 10 | 30 |
| Encrypt | 41.6 | 78.6 | 234 | 19 | 33.8 | 91.5 |
| Keygen | 54.6 | 108.5 | 318.7 | 157 | 308.7 | 935 |
| Decrypt | 13.4 | 24.9 | 69.5 | 33.2 | 61.5 | 173.6 |
| Re-encrypt | 13.5 | 24.8 | 71.1 | 33 | 61.6 | 176.3 |
| Re-keygen | 131.1 | 240.9 | 715.5 | 273.5 | 509.7 | 1497.3 |
| Re-Decrypt | 17.2 | 28.9 | 73.9 | 47.2 | 76.6 | 188.9 |
SS curve with embedding degree of 2 has the best execution time for the algorithms Re-Decrypt, Decrypt and Re-Decrypt among other curves, as we can see in Tables 2. While, the BN curve with embedding degree 12 has higher execution time for the Re-Decrypt, Decrypt and Re-Decrypt algorithms. Specifically, from the Tables 2 and 3 we can see that, in the case of 5 attributes the Decrypt and Re-Decrypt algorithms take less than 18ms for the SS curve and less than 63ms for MNT curves, while for 10 attributes these algorithms take about 29ms for SS curve and less than 100ms for MNT curves.
Table 3 Average execution time (ms) of each algorithm of the proposed IPPRE scheme on eliptic curves MNT201 and BN
| Curve | MNT201 | BN | ||||
| Attribute.num | 5 | 10 | 30 | 5 | 10 | 30 |
| Encrypt | 25 | 45.4 | 123.7 | 34 | 48.9 | 106 |
| Keygen | 205 | 403.4 | 1219 | 40.2 | 79.4 | 241.2 |
| Decrypt | 42.8 | 80 | 235.6 | 367.4 | 691.4 | 2082.6 |
| Re-encrypt | 43.7 | 80.6 | 231.2 | 367.3 | 700.3 | 2025.4 |
| Re-keygen | 359.7 | 668.2 | 1960.9 | 87.8 | 153.5 | 447.4 |
| Re-Decrypt | 63.1 | 100.7 | 250.4 | 380.5 | 711.8 | 2036.8 |
8 Conclusions
In this paper, we extend Park’s inner-product encryption method [26]. We present a new inner-product proxy re-encryption (IPPRE) scheme for sharing data among users with different access policies via the proxy server. The proposed scheme allows updating attribute sets without re-encryption, making policy updates extremely efficient. We fulfill the security model for our IPPRE and show that the scheme is adaptive attribute-secure against chosen plaintext under standard Decisional Linear (D-Linear) assumption. Moreover, we test the execution time of each algorithm of our protocol on different types of elliptic curves. The execution times hint that our approach is the first step towards a promising direction. As a future work, we plan to show how to apply our scheme to achieve a multi-authority version [6].
References
[1] G. Ateniese, K. Fu, M. Green, and S. Hohenberger (2006). Improved proxy re-encryption schemes with applications to secure distributed storage. ACM Trans. Inf. Syst. Secur., 9, 1–30.
[2] J. Bethencourt, A. Sahai, and B. Waters (2007). Ciphertext-policy attribute-based en cryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy, SP ’07, (IEEE Computer Society: Washington, DC, USA), 321–334.
[3] M. Blaze, G. Bleumer, and M. Strauss (1998). Divertible Protocols and Atomic Proxy Cryptography. Springer: Berlin, Heidelberg, 127–144.
[4] D. Boneh, X. Boyen, and H. Shacham (2004). Short Group Signatures. Springer: Berlin, Heidelberg, pp. 41–55.
[5] D. Boneh and M. Franklin (2001). Identity-Based Encryption from the Weil Pairing. Springer: Berlin, Heidelberg, 213–229.
[6] M. Chase (2007). Multi-authority attribute based encryption. In Proceedings of the 4th Theory of Cryptography Conference, TCC 2007, Amsterdam, The Netherlands. (ed) Salil P. Vadhan, Theory of Cryptography, Lecture Notes in Computer Science, Vol. 4392, (Springer),
[7] L. Cheung and Calvin C (2007). Newport. Provably secure ciphertext policy ABE. IACR Cryptology ePrint Archive, 2007:183.
[8] T. El Gamal (1985). “A public key cryptosystem and a signature scheme based on discrete logarithms,” in Proceedings of CRYPTO 84 on Advances in Cryptology, New York, NY, USA, (Springer-Verlag New York, Inc.), 10–18.
[9] K. Emura, A. Miyaji, A. Nomura, K. Omote, and M. Soshi (2009). A Ciphertext-Policy Attribute-Based Encryption Scheme with Constant Ciphertext Length. Springer: Berlin, Heidelberg, 13–23.
[10] V. Goyal, O. Pandey, A. Sahai, and B. Waters (2006). “Attribute-based encryption for fine-grained access control of encrypted data,” in Proceedings of the 13th ACM Conference on Computer and Communications Security, CCS ’06, (ACM: New York, NY, USA), 89–98.
[11] M. Green and G. Ateniese (2007). Identity-Based Proxy Re-encryption. Springer: Berlin, Heidelberg, 288–306.
[12] H. Guo, F. Ma, Z. Li, and C. Xia (2015). “Key-exposure protection in public auditing with user revocation in cloud storage,” in Revised Selected Papers of the 6th International Conference on Trusted Systems, INTRUST 2014, (LNCS, Vol. 9473), 127–136.
[13] S. Guo, Y. Zeng, J. Wei, and Q. Xu (2008). Attribute-based re-encryption scheme in the standard model. Wuhan University Journal of Natural Sciences, 13, 621–625.
[14] J. Katz, A. Sahai, and B. Waters (2008). Predicate Encryption Supporting Disjunctions, Polynomial Equations, and Inner Products. Springer: Berlin, Heidelberg, 146–162.
[15] Y. Kawai and K. Takashima (2013). Fully-anonymous functional proxy-re-encryption. IACR Cryptology ePrint Archive, 2013:318.
[16] A. Lewko, T. Okamoto, A. Sahai, K. Takashima, and B. Waters (2010). Fully Secure Functional Encryption: Attribute-Based Encryption and (Hierarchical) Inner Product Encryption. Springer: Berlin, Heidelberg, 62–91.
[17] H. Li and L. Pang (2016). Efficient and adaptively secure attribute-based proxy reencryption scheme. IJDSN, 12, 5235714:1–5235714:12.
[18] K. Li (2013). Matrix access structure policy used in attribute-based proxy re-encryption. CoRR. abs/1302.6428, eprint: arXiv:1302.6428.
[19] K. Liang, L. Fang, W. Susilo, and D. S. Wong (2013). “A ciphertext-policy attribute-based proxy re-encryption with chosen-ciphertext security,” in 2013 5th International Conference on Intelligent Networking and Collaborative Systems, 552–559.
[20] K. Liang, M. H. Au, W. Susilo, D. S. Wong, G. Yang, and Y. Yu (2014). An Adaptively CCA-Secure Ciphertext-Policy Attribute-Based Proxy
[21] X. Liang, Z. Cao, H. Lin, and J. Shao (2009). “Attribute based proxy re-encryption with delegating capabilities,” in Proceedings of the 2009 ACM Symposium on Information, Computer and Communications Security, ASIACCS 2009, Sydney, Australia, 276–286.
[22] S. Luo, J. Hu, and Z. Chen (2010). “Ciphertext policy attribute-based proxy re-encryption,” in Proceedings of the 12th International Conference on Information and Communications Security, ICICS’10, (Springer-Verlag: Berlin, Heidelberg), 401–415.
[23] B. Lynn (2007). Pairing Based Cryptography Library. Available at: http://crypto.stanford.edu/pbc/
[24] M. Mambo and E. Okamoto (1997). Proxy cryptosystems: Delegation of the power to decrypt ciphertexts. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, 80A, 54–63.
[25] T. Okamoto and K. Takashima (2009). Hierarchical Predicate Encryption for Inner-Products. Springer: Berlin, Heidelberg, 214–231.
[26] J. H. Park (2011). Inner-product encryption under standard assumptions. Des. Codes Cryptography, 58, 235–257.
[27] Z. Qin, H. Xiong, S. Wu, and J. Batamuliza (2017). A survey of proxy re-encryption for secure data sharing in cloud computing. IEEE Transactions on Services Computing, PP(99), 1–1. doi: 10.1109/TSC.2016.2551238
[28] A. Sahai and B. Waters (2005). Fuzzy Identity-Based Encryption. Springer: Berlin, Heidelberg, 457–473.
[29] H. Seo and H. Kim (2012). Attribute-based proxy re-encryption with a constant number of pairing operations. J. Inform. and Commun. Convergence Engineering, 10, 53–60.
[30] M. Sepehri, S. Cimato, and E. Damiani (2017). “Efficient implementation of a proxy-based protocol for data sharing on the cloud,” in Proceedings of the Fifth ACM International Workshop on Security in Cloud Computing, SCC@AsiaCCS 2017, Abu Dhabi, United Arab Emirates, April 2, 2017, pp. 67–74.
[31] M. Sepehri, S. Cimato, E. Damiani, and C. Y. Yeuny (2015). “Data sharing on the cloud: A scalable proxy-based protocol for privacy-preserving queries,” in Proceedings of the 7th IEEE International Symposium on Ubisafe Computing in Conjunction with 14th IEEE Conference on Trust, Security and Privacy in Computing and Communications, TrustCom/BigDataSE/ISPA, Helsinki, Finland, 1357–1362.
[32] M. Sepehri, and A. Trombetta (2017). Secure and Efficient Data Sharing with Atribute-based Proxy Re-encryption Scheme. In Proceedings of the 12th International Conference on Availability, Reliability and Security. ACM: Reggio Calabria, Italy, 1–63.
[33] D. Thilakanathan, S. Chen, S. Nepal, and R. A. Calvo (2014). Secure Data Sharing in the Cloud. Springer: Berlin, Heidelberg, 45–72.
[34] B. Waters (2009). Dual System Encryption: Realizing Fully Secure IBE and HIBE under Simple Assumptions. Springer: Berlin, Heidelberg,
[35] B. Waters (2011). Ciphertext-Policy Attribute-Based Encryption: An Expressive, Efficient, and Provably Secure Realization. Springer: Berlin, Heidelberg, 53–70.
[36] S. Yu, C. Wang, K. Ren, and W. Lou (2010). “Attribute based data sharing with attribute revocation,” in Proceedings of the 5th ACM Symposium on Information, Computer and Communications Security, ASIACCS ’10, (ACM: New York, NY, USA), 261–270.
Biographies

Masoomeh Sepehri is a Ph.D. candidate in Computer Science at the University of Milan. Her research activity mainly focused on the design of cryptographic protocols for secure data sharing in the cloud computing and Internet of Things.

Alberto Trombetta is Associate Professor at the Department of Scienze Teoriche e Applicate at Insubria University in Varese, Italy. His main research interests include security and privacy issues in data management systems, applied cryptography and trust management.

Maryam Sepehri received the Ph.D. degree in Computer Science from the University of Milan, Italy, in 2014. She is currently pursuing postdoctoral research fellow at the University of Waterloo, Canada. Her research interest includes privacy-preserving query processing over encrypted data.
Journal of Cyber Security, Vol. 6_3, 339–378.
doi: 10.13052/jcsm2245-1439.635
This is an Open Access publication. © 2017 the Author(s). All rights reserved.
1 init is an algorithm that takes as input a security parameter ln and outputs a tuple (p, 𝔾, 𝔾T,e), where 𝔾 and 𝔾T are groups of prime order p and e : 𝔾 × 𝔾 → 𝔾T is a bilinear map.
2 The base field size of 𝔾1 MNT159, BN, MNT201 and SS curves are 159 bits, 160 bits, 201 bits and 512 bits, respectively [23].
3 The base field size of 𝔾2 BN, MNT159, SS and MNT201 curves are 320 bits, 477 bits, 512 bits and 603 bits, respectively [23].