A Combined Approach for a Privacy-Aware Digital Forensic Investigation in Enterprises
Ludwig Englbrecht* and Günther Pernul
Chair of Information Systems, University of Regensburg, Germany
E-mail: ludwig.englbrecht@ur.de; guenther.pernul@ur.de
*Corresponding Author
Received 09 November 2020; Accepted 14 November 2020; Publication 10 March 2021
Abstract
Stricter policies, laws and regulations for companies on the handling of private information arise challenges in the handling of data for Digital Forensics investigations. This paper describes an approach that can meet the necessary requirements to conduct a privacy-aware Digital Forensics investigation in an enterprise. The core of our approach is an entropy-based identification algorithm to detect specific patterns within files that can indicate non-private information. Therefore we combine various approaches with the goal to detect and exclude files containing sensitive information systematically. This privacy-preserving method can be integrated into a Digital Forensics examination process to prepare an image which is free from private as well as critical information for the investigation. We implemented and evaluated our approach with a prototype. The approach demonstrates that investigations in enterprises can be supported and improved by adapting existing algorithms and processes from related subject areas to implement privacy-preserving measures into an investigation process.
Keywords: Digital forensics, enterprise forensics, privacy-aware, privacy-preserving, privacy.
1 Introduction
Private as well as government organizations are exposed to an increasing number of IT security threats. Since not all incidents can be completely mitigated, a forensic investigation can become inevitable if an incident occurs. A digital forensic investigation can be very time consuming and cost intensive. Some of these impacts are so immense that the competitiveness or even the existence of companies is threatened.
In the case of a fraud investigation within a company or government organization, data must be extracted from several devices, which can contain sensitive data of employees or customers. In these cases, data privacy protection issues arise. These cases require the approval of any individual who may have private data on these devices. This can be an exhausting task for companies with a large number of employees and customers [18]. Additionally, there are regulations in the EU such as the GDPR, which require companies to take appropriate technical and organizational measures to protect personal data. Article 8 of the EU Charter of Fundamental Rights states that everyone has the right for the protection of their own personal data.
More precisely the GDPR1 defines personal data, its processing and its privacy assurance as follows: ‘Personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.
These data must be protected during the operational processing. According to the GDPR, this data needs to be stored in encrypted form as well. Nevertheless, during the execution of business processes (e.g. offer preparation or order processing) unencrypted versions of business documents are created and deleted on the employee’s PC.
Such data may only be processed for specified purposes and with the consent of the data subject. Violations of these regulations can lead to high fines. Therefore, Digital Forensics (DF) and Digital Forensics Readiness (DFR) are affected by these regulations, especially in an enterprise and governmental environment [23]. Typically forensically-sound images of entire media are created with little respect for any private data contained thereon. Thus the privacy of uninvolved persons (but also of criminals) can be significantly violated.
Seized material made available for a DF investigation can contain irrelevant data for the specific case of an investigation. The information can be split into four categories (non-private and non-relevant; non-private and relevant; private and relevant; private and non-relevant) which decide if an investigator gets granted access or gets it denied [13]. The first category contains all irrelevant uncritical information that can be viewed, extracted, and analyzed by the investigator without further precautions. The second category includes information that is relevant but not critical in the company’s eyes. These can also be used by the investigators for the analysis. The third category, however, requires special procedures. It contains critical information that can be relevant to the investigation. In this case, the investigator must be given access under certain conditions. The last category contains critical information that is not relevant to the investigation and therefore must be blocked from the investigator. Critical information may vary, but in all cases it contains private information which is of the utmost caution to an enterprise within an investigation. In any case, this information comes from other persons covered by the protection of the concept of personal data. This data can originate from customers or employees who also use their work machines for private purposes, which can be allowed in companies. Therefore, this data must be hidden or removed before an investigator can access the seizure material.
Such a modification process creates problems caused by the dependencies that DF has on handling the seized material. The main reason for this is that integrity must always be maintained so that the evidence found is demonstrably in its original state and has not been tampered with or altered during the analysis process. It is necessary that applications ensure this integrity even though the material under investigation has either been extracted or modified to conceal information from the investigator. This also requires an extraction tool for corporate forensics to remove or encrypt private information. Either way, these tools must provide an automated approach to filter or hide sensitive data before it can be accessed by the examiner. The investigator plays a major role in sharing information. Basically, investigators must be trusted for the current situation in most cases, creating a vulnerable place for attacks. This means that they can be attacked by malicious groups through social engineering or even be malicious themselves. With an automatic filter or a hiding approach, it would not matter if the investigators are “less” trustworthy and a risk for exposing private data can be reduced.
This paper focuses on a new approach on how privacy protection mechanisms can be implemented into DF in an enterprise environment. By focusing on company-relevant data, we make use of these specific characteristics for the protection of privacy and address the following research question: How can a privacy-aware DF investigation approach be implemented in an enterprise environment?
To answer this question, we introduce a new method to prepare a hard-drive image which pre-filters private data out of examination material. The intention of this approach addresses the problem with a possible automated approach to remove sensitive data before investigators get their hands on the examination material. The approach will be applied between the collection and examination process phase of a DF investigation and decides if a specific file will be forwarded to a DF investigator.
The paper is structured as follows: First an overview of background knowledge and a literature review of the current situation of privacy protection and details on the implementations that currently exist are provided. Based on that, identified requirements for a new approach will be developed in Section 3. This method uses the file entropy to distinguish between private and enterprise data objects. The Subsections 3.1, 3.2 and 3.3 show how these can be integrated and automated within a DF investigation. In Subsection 3.4, a prototypical implementation of the concept is shown. In Section 4 a profound evaluation of the concept is carried out. A discussion about the proposed concept and its limitations is provided in Section 5. Section 6 gives a summary of the proposed concept and an outlook on future work.
2 Background and Related Work
Enterprise forensics is a sub-discipline of DF. The main objective is to provide well-founded answers to questions regarding how an information system should operate based on business processes and which digital traces are created by the application systems. Furthermore, the role of a certain computer in the company and the persons who have access to the computer or associated application systems must also be examined [33]. Additionally, the guidelines that need to be followed during the execution of business processes must be identified [1].
Taking the previously mentioned requirements into consideration, enterprise forensics develops and provides methods and techniques for the use of business processes in DF investigations in enterprises. Furthermore, it deals with methods and tools for identification, collection, analysis, and presentation of digital traces from enterprise application systems [21].
2.1 Privacy Protection/Preserving vs. Digital Forensics
Privacy protection or privacy preserving can be understood for this purpose in the following ways: Burmester et al. [6] defines privacy as the control over one’s own data, which includes identity, personal data and personal activities. Overall, it must be possible to share personal information with selected parties. On the other hand, Halboob et al. [13] state that, as an example, private data may also be relevant in a crime investigation. They proposed different privacy levels for privacy-preserving computer forensics and motivated for a fully automatic data selection for selecting the private and/or relevant data.
The main goal in DF is to find credible evidence in extracted data. Therefore, digital investigators try to collect as much data as available to ensure that no possible trace is lost. Furthermore, the evidences’ integrity needs to be ensured to assure its admissibility in a court of law. These reasons lead to an extraction process that does not exclude any information but preferably only clusters similar file types of a seizure device. But this process might endanger the privacy of unrelated persons in favor of integrity. This was widely accepted over the past years due to the fact that digital information did not consist of a large amount of private information and the regulations were not as strict as today. The proportion of private information on digital devices rapidly increased over the years and therefore privacy protection is necessary and enforceable within a DF investigation process.
Therefore, privacy-protection needs to be included in the real-world forensic process. It must even be applied to the DF examination and analyzing process. Aminnezhad et al. [2] proposed in their survey that DF still has privacy issues and investigate trends that retrieve key evidence without infringing user privacy. On the contrary, Srinivasan [31] proposed that privacy-preserving actions put restrictions on DF and hence limits its capabilities. This is the reason why Srinivasan declared ten policies that must be enforced onto the investigation process of DF. These include integrity, encryption, and deletion rules to not only protect the user but the investigator in charge to not be in danger of getting into conflict with privacy protection laws.
2.2 Current State of Privacy Protection in Digital Forensics
The policies and laws protecting the privacy of employees or other persons interacting with the company and its systems may limit or even prohibit a DF investigation [36].
Halboob et al. [13] identified two research paths that have been pursued to enable privacy protection in DF: A policy-based and cryptographic-based approach. The first approach is a method in which an organization must define and publish privacy policies and statements in order to make data owners aware of their rights and of how their private data should be handled. The second pursued path is a cryptographic-based approach. This area focuses on the assertion that any collected material is the private property of the owner and must be encrypted immediately. The authors also defined privacy level and access guidelines for investigators to support them in handling private information [13].
Saleem et al. [27] also analyzed existing approaches to implement data privacy into the DF investigation process. They detected a differentiation between preservation and protection in the context of DF. Preservation focuses on documenting every action of the investigation and keeping the integrity of digital evidence throughout the whole process. Protection aims to protect human rights and ensures that they are preserved throughout the investigation.
They also identified the use of two different concepts of privacy which are called soft and hard privacy. In the soft version of data privacy, a data owner loses control over his personal data and must trust the investigator. The concept of hard privacy focuses only on revealing the most necessary data for the investigation [27].
In some practical implementation of data protection in DF, the seizure material of possible evidence will be encrypted before the investigator has access to the data. The research showed two different approaches to searching for data on a digital device without revealing private information. The first is private database search, where a user encrypts the data beforehand and stores the encrypted data in an untrusted environment. Song et al. [30] presented a method that allows a user to perform keyword searches on the encrypted data without revealing the keywords or the data. This approach has been further developed by Hou et al. [14] to perform multiple keyword search over encrypted data by utilizing homomorphic encryption scheme. With this the investigators can obtain the necessary evidence while keeping the investigation subject confidential. This also allows to protect irrelevant data exposed to the investigators.
To do this, the user creates an index array containing the encrypted keywords. These correlate with a table that contains the position of these keywords in the encrypted documents. If enough keywords are known, a searcher gets access to a specific document. This method was one of the first implementations of keyword search and allowed users to perform a secure keyword search in an untrusted environment.
Another method described by Hou et al. [15] is Searchable Public Key Encryption (SPKE). In this case the user encrypts emails together with an index file with his public key and stores the index together with the emails on an untrusted server. It is possible for people without keys to add keywords, but only the owner of the private key can decrypt the emails and retrieve information. The second approach to search for data on a server is public database search, which allows users to hide query actions on the server with Private Information Retrieval (PIR). But in this case the data itself is unencrypted and therefore not relevant for the work but mentioned here for completeness. Based on Searchable Symmetric Key Encryption (SSKE) many other researchers like Curtmola et al. [9], Ballard et al. [4], Chang and Mitzenmacher [8] improved these original ideas to increase efficiency, security and confidentiality.
In 2013, Hou et al. [16] improved their own idea with secret exchange possibilities. It was initially developed for key protection but can also be used during collecting evidence in DF.
An implementation of the keyword search in DF is presented within the approach of Armknecht and Dewald [3] from the year 2015. This was designed to allow a company to encrypt data using Armknecht and Dewald’s schema so that the investigator can receive the data and perform keyword searches on it. The suggested keyword search takes multiple keywords and displays only objects that reach a certain threshold for matching keywords in the message. It also includes a blacklist that allows the company to protect private information from malicious investigation.
Another approach to enhance privacy is to exclude irrelevant personal data from the analysis process. This gives the possibility to exclude even a slight possibility to unintentional hand over private information to unauthorized parties. However, this technique has a major problem in maintaining the integrity of digital evidence by modifying or removing data from the copied image. Turner [34] explains that Selective Imaging in DF is seen as a decision not to capture all possible information and was therefore not accepted. But lately it has gained a higher reputation as an alternative for application areas where a full coverage is no longer possible due to vast amounts of data. Turner categorized Selective Imaging into three types:
• Manual Selective Imaging
• Semi-automatic Selective Imaging
• Automatic Selective Imaging
During manual Selective Imaging, the examiner decides which files must be captured. This means that the investigator has software that allows him to browse the files and select the relevant ones. This is already critical because the investigator has access to all information at the beginning. Therefore, a holistic privacy protection is not possible with this approach. In a semi-automatic approach, the investigator selects certain file types based on the extension, e.g. JPEG, MP3 or AVI. It is also possible to select files with a specific function signature or hash. After configuration, an application automatically collects all files corresponding to the selected configuration during the preparation phase. In a fully automated Selective Imaging process, the examiner only needs to select the target device and location for the final image. The application itself detects any possible traces within the chosen image and creates an examination image consisting only of relevant file objects. However, this has one major disadvantage. The biggest challenge with Selective Imaging is preserving the origin of the object extracted from the device. This means that it can be argued that the integrity of the extracted files is compromised, making them useless as evidence. Therefore, Turner provided measures to prove integrity preservation [34].
It is easier to create a complete image of a device and verify integrity by hash comparison, but without this possibility, applications need other mechanisms to prove that a file or object is in its original state. To achieve this, Turner named the following possible ways to prove integrity:
• Physical sector location (runs)
• Logical cluster locations within a volume, with the addition of an offset from the beginning of the physical device
• Folder location specified from the root folder, this must include partition reference information
Nevertheless, the examiner decides which method to use to maintain integrity. According to Turner, each of these methods requires attributes of origin to prove integrity. These consist of four attributes - uniqueness, unambiguousness, conciseness, and repeatability [34]. These are the attributes that are important to prove data integrity in court. It depends essentially on which methods are better understood by a judge that the integrity of an object is proven by the chosen method. For an automatic Selective Imaging procedure, Turner also points out that it is necessary for an application first to inherit all the knowledge of a technical examiner and a lawyer. Secondly, the application must know that it has collected all possible traces and has not missed any important evidence. Given all these aspects, there is much to improve and develop. Turner [34] started in 2006 with the idea of evidence bags. So, the found evidence is put in a special bag. Each bag contains a file with a specific extension. It also has a meta-data file that contains information about the investigator involved and the last change to the bag. Each unit is linked to an index file that contains the integrity hash value and the location of the evidence on the original physical device to verify integrity.
In 2013, Stüttgen et al. [32] revived the Turner approach [34] and developed a new method to use partial imaging in AFF4 format. It was developed as an open forensic evidence container. The authors state that Selective Imaging can be generic and usable for all data objects and not only for files. This makes it possible to create image files that are essentially a collection of data with the associated meta-data. They explain that the meta-data must have enough information to find the position of an object completely and unambiguously on its hard disk. They assume that the data object can be stored in a hierarchical structure on disk and extracted at any level. In order to understand this, the data object contains a bit stream that represents the information. The meta-data describes the object and contains information about the object, such as the inheritance and the layer from which it was extracted. Therefore, the meta-data looks different depending on which layer the data object was extracted. In the investigation process, the method of Stüttgen et al. can be used to start a preliminary analysis of devices in order to identify potentially relevant traces before the actual investigation process. Their approach consisted of three modules: a selective imager, a partial image connector and, a partial image verifier. These modules essentially extract the promising data objects, store them together with the corresponding meta-data and verify their origin.
Another scientific work by Grier and Richard [12] in 2015 focuses on accelerating the process of Selective Imaging and making it even more flexible. Their idea is to define parts of physical hard disks that contain non-relevant data and can therefore be ignored in the backup process. For this purpose, they developed a procedure with two properties:
• Does not require ad-hoc interaction but must be definable beforehand
• Does not demanding reads of the entire disk and makes use of pointers, index and meta-data to identify the location of data
They also use super setting approximations, i.e. keyword searches in sectors that have a high chance of containing relevant data. Grier and Richard propose profiles that predefine specific important data objects and sectors depending on the case. These profiles are based on given cases in the research process. It is important to note that physical devices contain a large proportion of data objects of structural use for the operating system that are not relevant to an investigation, so they can be ignored in the mapping process to allow a faster extraction process. These papers show that Selective Imaging is and will be even more important now and in the future as the demand for disk space, cloud computing, and data protection laws to protect people grows. In this context, a semi- or fully automated approach to Selective Imaging, with the ability to recognize certain information, may also include the automatic removal of unwanted data consisting of private information in order to take a look at data protection.
The main purpose of secure deletion is to protect privacy. The idea is to delete all sensitive data about a person without the possibility of recovering the data [7]. In this context, Castiglione et al. [7] has marked the following steps in 2011:
1. locations of sensitive data on a hard drive must be rewritten to prevent recovery
2. removal of referral meta-data that can lead to deleted data
3. removal of any possible traces towards the wiped data or its deletion
The reason why secure deletion is a widespread research topic in many areas is due to the nature of OS not to delete files immediately. Castiglione et al. [7] point out that OS leave data that can persist on hard drives. One reason for this is, for example, a restraint application such as the recycle bin. Another cause is the deletion process of an OS. It does not really remove data from the hard disk but removes the pointer and declares the specific disk space as free. So, the data remains until the new ”unused” disk space has been overwritten. Also implemented restrictions and write restrictions to extend the life of hard disks prevent the complete erasure of data. These problems require the need for secure deletion of private data from physical storage media.
Therefore, Castiglione et al. [7] proposed an automatic, selective and secure deletion approach for digital evidence. The idea is an application that securely automatically deletes all data objects specified by the user using a chosen method and eliminates the deletion application itself also to remove the trace of the deletion process. Castiglione et al. [7] suggested many methods that are not discussed further due to the different research focus of this paper, but overall it demonstrates the necessity and possibility of secure deletion of private data. In 2017, Zoubek and Sack [38] took up the topic of secure deletion and placed it in the focus of deleting irrelevant data in the DF collection process. Therefore they developed a tool that enables a sound selective deletion for images of partitioned NTFS hard disks with provenance verification techniques. They have developed five modules to make automatic deletion usable for DF investigation: Selector, Matcher, Carve-Cleaner, Hash calculator and Deletion module. The tools developed by Zoubek and Sack [38] were based on German laws that prohibit knowledge of a suspect’s private life. This work shows that data protection is becoming increasingly important in DF. Therefore, an automatic process for filtering irrelevant data for a case must be developed and integrated.
Document Clustering. Clustering has the potential to reduce the workload of the extraction process for a DF investigation. It can be used to group only useful data objects, allowing it to serve as a filtering algorithm. Therefore, several relevant methods of document clustering have been researched and analyzed.
Dumais et al. [11] already worked on clustering in 1998, but under the name of text categorization and classification. They also pointed out that large companies had trained employees in manual clustering at the time of creating their work and that automation is a necessity for real-time classification and information extraction. Therefore, they demonstrated a variety of algorithms capable of enabling clustering. They analyzed five learning cluster methods:
• Find Similar
• Decision Trees
• Naïve Bayes
• Bayes Nets
• Support Vector Machines
In general, Kim and Lee [17] describe document clustering as the goal of dividing a large group of documents into smaller groups that relate to specific topics. It is important to reduce the information overload into smaller parts in order to also reduce the time needed to retrieve useful information. Kim and Lee [17] also point out that clustering depends heavily on external information which is user-specific and must first be fed into the clustering algorithm. The most commonly used document clustering algorithms are called AHC algorithms. These always start with each document being a cluster and merge the two largest clusters one after the other until a termination criterion is met. In the end, the influence of user input on the clustering algorithm was measured compared to no user input. The results were promising to help users organize a large amount of information.
Dagher and Fung [10] made use of document clustering in DF to cluster documents stored on a suspect’s computer. The subject-based semantic document clustering by Dagher et al. has the ability to bundle documents into topics. It uses an extended synonym list to find frequently used terms of criminal activities. The pre-processing phase starts with the normalization of all words in the document. In order to reduce dimensionality, Dagher and Fung [10] have also removed stop words and tokenized names. Nevertheless, each document corresponding to a subject of interest is initially defined by the investigator.
A holistic overview of current considered privacy-aware areas with its accomplished level in DF is given by Nieto et al. [22]. The authors highlight the conflicting goals of privacy and the conduction of a DF investigation as well as unsolved challenges. By contrasting existing privacy-aware methods for DF in Database, Computer, Server, Networks, Applications, Mobile, Cloud and IoT a high demand for adaptation is shown. They propose a possible re-usage of different techniques from different areas in DF. Our approach can be associated to Browser and Applications forensics and propose a concrete solution to perform a privacy-aware investigation that goes beyond generic frameworks and provide a method applicable for different types of applications.
Our paper is based on previously mentioned approaches, combines and extends them for a DF investigation in enterprises. It aims at an automated process to provide the DF investigator with a prepared hard-drive image containing only enterprise relevant data.
3 An Entropy-Based Selective Imaging Approach for DF
The focus on enterprise-relevant data within a DF investigation will be utilized for the intended purpose. Thereby common patterns within files that are created and left behind during a business process execution are recorded and reused. In particular, these can be final data (e.g. a PDF file of an invoice) or temporary files created during the execution of tasks. Additionally, data from operational communication, such as emails, can also be used.
In our approach we have decided to use the entropy as an abstract measure to determine the similarity of files. The Shannon entropy is the baseline for a lot of different metrics. Due to the fact that it measures the uncertainty associated with prediction of the value of a random variable it can be used to measure privacy [35]. However, if the overall value or multiple sub-values are assessed in terms of deviation from a given target value, explicit conclusions can be drawn about the similarity of information.
In order to identify and use only business-related data for the investigation process, Subsection 3.1 of this section shows the filtering process and Subsection 3.2 the use of entropy distribution to compare the relevant data in detail. In Subsection 3.3 a conceptual combination of entropy-based selective imaging is described. An actual implementation is proposed in Subsection 3.4.
3.1 Entropy-Based Filtering Process
This paper attempts to use the Shannon Entropy Equation to calculate the randomness and frequency distribution of a file and compare these results to a reference file. In detail, the structure and content of the reference file is an abstract representation of common enterprise related documents. This data is acquired from business process-related data before the analysis.
This approach focuses on the file-based level of a physical device. To do this, all text-related data objects, such as emails, needs first to be restored, identified and clustered using clustering methods. This is followed by an entropy-based comparison with reference files, which do not contain private information. These objects can then be either removed, anonymized, or encrypted using the methods described in Section 2. To calculate the entropy of file objects, the Shannon Entropy Equation [28] has been selected since it provides a structure-based view inside files and can used as a flexible measurement to compare two files based on its structure. This formula is shown below:
| (1) |
The Equation (1) shows that a file will be read as a byte stream. In the set the different bytes are sorted in their valence. The record is used to measure the randomness in the result of events. Within Equation (1), is a specific event and is the probability that the event will occur.
The result of an application of the entropy calculation is a number between zero, which means that the file is not random, and eight as maximum, which is a highly random data object with unpredictable byte order. Shannon developed the formula to measure how compressible a particular data object is. This capability allows it to detect anomalies within a file, since malicious code is usually injected into an inconspicuous file in compressed form. This increases the randomness of a data object.
In 2010, Mc Creight and Weber [20] patented the idea of comparing files with an entropy-based near-match analysis method. It also utilizes the Shannon Entropy Equation and uses the results to compare a reference file with another file on a physical drive to determine if they are similar. The proposed approach in this paper is based on this idea, and it not only checks whether a particular file is similar to a reference file, but also goes into more detail and detects whether the file contains private information. In addition to the proposed entropy-based privacy method, the work will also combine structured clustering methods, which will be explained in the next section.
We developed a new filtering procedure for the DF investigation process to enable privacy protection. The developed approach is located between the collection and examination tasks of the DF investigation process. More specifically, before an investigator can access the collected material, the filtering procedure is used to remove all private information automatically. This is done to meet the goal of protecting individuals’ privacy and to comply with legal requirements.
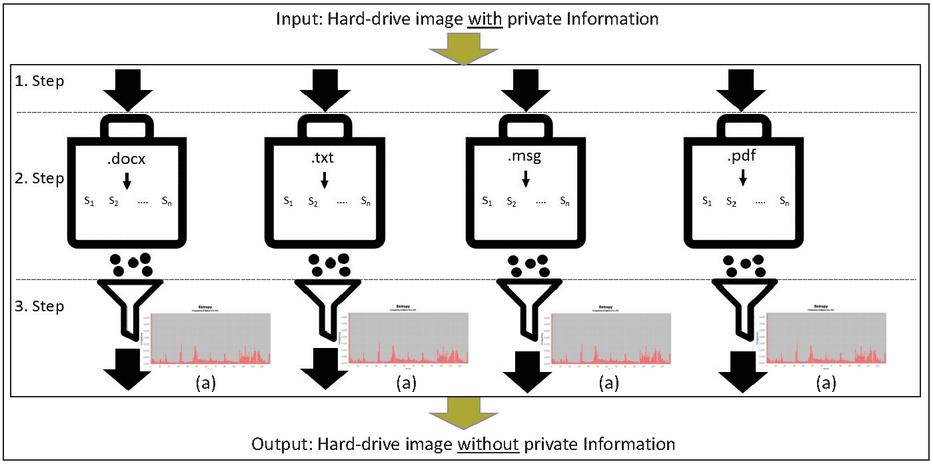
Figure 1 Clustering procedure.
The procedure shown in Figure 1 consists of three phases. These are arranged according to granularity. The arrangement goes from a rough filtering, which only pays attention to certain file types, to a fine filtering. The rough filtering method makes use of the idea of Turner [34] to create evidence bags. Those bags store the prior specified relevant file types. This is done by providing specific file-header information. Non-relevant file types are marked as irrelevant and will be removed from the filtering process.
The second fine filtering method goes to the word level of the file objects to detect predefined words that occur most frequently in private messages and in addition, words determined by the investigator to not be relevant for the investigation. It makes use of the algorithm developed by Dagher and Fung [10] to filter out objects that contain specific words defined in a Look Up List prepared and provided beforehand.
The first two phases can be a big advantage in efficiency since it excludes a large part of irrelevant data. Pre-processing the image and reducing the number of objects in each step, makes it possible to go through the more complex and time-consuming processes with a smaller number of objects. This can possibly reduce the overall time required to create an examination image. The subject-based semantic document clustering proposed by Dagher and Fung [10] clusters the data objects inside the bags even further into subject vectors. This step bundles the remaining objects into topics and filters specific clusters of topics that are not relevant for the investigation. Despite the use of this remarkable filtering mechanism, private data (of the same file type) can still remain.
The third step will be the entropy-based data protection filter procedure developed in this paper. It uses the Shannon Entropy Equation [28] to filter the remaining data objects (see (a) in Figure 1). This compares the entropy frequency with predefined reference objects to determine the purpose of the files. It detects the remaining private information and excludes it from the evidence bags. The result is an examination image consisting only of relevant data objects that are free of private information. The procedure is split up into modules to allows a more straightforward modification of the approach.
To sum it up, the procedure described before and shown in Figure 1 is applied to create an image from a hard-drive that does not contain private files. In our context this relates to not enterprise-related files (e.g. private email or vacation photos) stored on the employees PC. In step 1 a full file recovery using file carving techniques is performed on the hard-drive. The result is used for step 2 and filtering and clustering mechanism are applied. Since within the evidence bags could still remain files with private content a structure-based comparison based on the files entropy distribution is performed in step 3. This ensures that only company-relevant data is included in the evidence bag that contains PDF documents.
3.2 Identifying Relevant Data Objects
In the third step, the three-level filter algorithm uses the Shannon Entropy Equation [28] to determine whether a particular data object contains information that is relevant to the investigation. The algorithm calculates the entropy of both the data object and a reference object. Not only the entropy value of the whole file, but the frequency distribution within the file, which is a partial result for the calculation of the Shannon entropy is also used. The entropy-structure of one file can be represented as a vector and enables the measurement of the similarity of both files.
We use for the calculation of the entropy a byte stream as an input value. Usually the encoding format can make a big difference to the result (e.g. the reference file is encoded following GBK but a private file is in UTF-8, or a reference image file is in PNG but a private file is JPG). Since we focus on business related files that are created during the process execution we assume that the same kind of software produces and consumes those files. Consequently, the expected encoding format can be strongly limited and a constant structure can be assumed.
The cosine similarity was selected since it can handle missing attributes between two elements, irrespective of their magnitude. By comparing this measurement with the Euclidean distance, high divergences are limited. The similarity of both entropy data-sets converted into two -dimensional vectors ( and ), can be defined as follows:
| (2) |
An illustration of the application of the cosine similarity measurement on two entropy data-sets (representing two files) is shown in Figure 2.
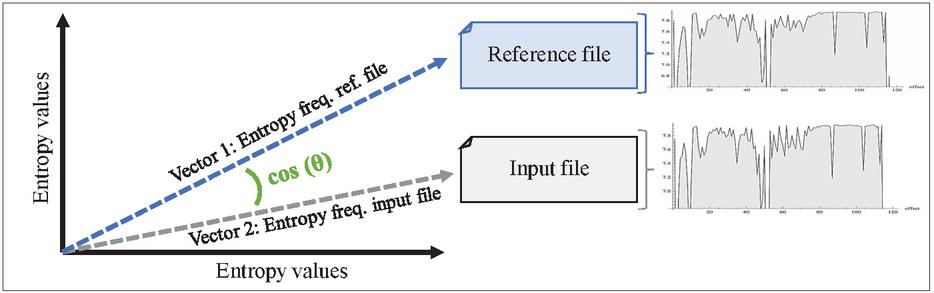
Figure 2 Application of the cosine similarity measurement.
With this, the algorithm determines the deviation values of both files. Additionally, another value representing the deviation of the deltas between the frequency (cosine similarity) and the entropy is calculated. Finally, these values are analyzed and compared with a threshold value. If a value is above a certain threshold, the variable is considered as an indicator that the file object contains private information. The threshold values and reference object files mentioned before must be specified in a configuration file for the algorithm. These must be defined for each file type, since the file-specific byte structures need to be considered properly.
3.3 Conceptual Design of an Entropy-based Selective Imaging
In order to make the newly developed Selective Imaging procedure suitable for practical use, it must be automated. It reinforces the intention not to provide the possibility to obtain information during the filtering process. This sub-section explains in detail why automation of the process is necessary, what level of automation can be achieved, and inputs required beforehand to make this possible.
The basic idea of the automation is to make an investigation process more efficient. In this case, efficiency means reducing time and costs as well as minimizing errors in the entire process. There is also the possibility to outsource the task to less qualified employees, as the process is a black box for them, and all they need to know is the input needed to get the desired output.
The entire process shown in Figure 1 is automated and gets all necessary information from the configuration file. The first phase of the process requires the information about file extensions and relevant sections on the disk and the OS which the disk has managed as well as recovered files from file-carving software to begin filtering and grouping the data into evidence bags. Phase two of the process requires the lookup list to verify that one of the words from the list is within the clustering file objects. The entropy-based filtering algorithm developed in step three uses prepared reference files and the corresponding thresholds to decide about the relevance of the file.
The result will be a fully usable image that can be examined without the problem of sharing private information and according to the rules of GDPR not to share private information of employees with others inside or outside the company. This is made possible by the prior removal of non-business-related data. One of the biggest problems with selective images is proving their integrity so that they can be used in court. To address this problem, two ideas can be pursued.
First, the original image used must be archived. This serves to reproduce the imaging process in the first step to show that the process has worked correctly. Second, the method creates the corresponding meta-data file that contains information about the relevant file objects on the hard-drive. The approach follows Turner’s idea of creating evidence bags [34]. The meta-data contains information about their location on the real physical drive, when they were extracted as well as a hash value of the original file. These measures can be implemented to prove the integrity of digital evidence in court.
3.4 Implementation of an Entropy-based Selective Imaging
Clustering can be used at two different stages of the extraction process. It can be run directly when extracting file objects from the physical drive/archive image, or it can be applied after that process, so that it only consumes a predefined number of data objects. These data objects can be provided with any existing DF tool, such as EnCase.2 Also other algorithms can be added to remove more non-relevant data from the seizure material, such as the Selective Imaging ideas of [12] or [38], which can be used prior to applying the proposed method to reduce the effort and processing time in the extraction process. Both papers implement the reduction of data objects for the investigation process by safely removing non-relevant and critical data. The integration of the proposed entropy-based method also depends on whether it is fully integrated into a DF extraction application or used as a stand-alone tool. However, the process will have the same work flow.
For the evidence bag clustering, the algorithm starts by retrieving relevant file extensions declared in the configuration file. This information is a precondition to start building evidence bags. First, the algorithm creates one bag per relevant file extension. After creating evidence bags, the next step goes through the archived image to extract the relevant files. These are placed in the appropriate evidence bags. In addition, the algorithm creates a meta-data file that contains the extraction date, the exact location of the file on the input image, and the hash of the original file. The procedure from [34] is shown in Algorithm 1 and provides an overview of the Evidence Bag clustering by comparing the file types with those specified in the configuration file and bundling them. Non-relevant objects are sorted out.
Algorithm 1 Evidence bag clustering (step 2)
Require:
for each in do
end for
for each in do
for each in do
if then
end if
end for
end for
Content-based clustering is used to pre-filter certain phrases that cannot be considered relevant. Therefore, a dictionary file containing certain words or phrases is required. This Lookup file must be customized for each organization. In some cases, it will contain basic words that do not specify relevant data, but it will also be adapted to specific business issues depending on the organization’s main business. This information could also include possible critical information.
This step requires that evidence bags have to be created and contain files. If this is done, the algorithm iterates through each bag and feeds the files as well as the Lookup file into the content-based clustering algorithm. The complex part of the content-based clustering algorithm is not presented in detail because it was developed by Dagher and Fung [10] and is implemented only as a method in this approach.
The content-based algorithm (Algorithm 2) returns a boolean result. True means that the file contains a word of the dictionary and removes it from the bag. False means that the file stays in the bag. The Algorithm 2 shows the proposed procedure of the content-based clustering method.
Algorithm 2 Content based clustering
Require: and
for each in do
for each in do
if then
end if
end for
end for
Algorithm 2 starts by checking whether a Look Up List existed and whether there was at least one evidence bag, otherwise the algorithm can not operate. Then the algorithm runs through the bags and files inside the bags. For each file, the algorithm of Dagher and Fung [10] is applied and if the algorithm finds a word from the Look Up List, it stops and returns true. In this case, the file is removed from the evidence bag.
Our method is divided into two procedures because it consists of two different parts. The first part takes care of the calculation of all necessary values for the decision process. The second part takes those values to decide whether a file can be removed or not.
To perform a comparison a previously defined set of business-related files needs to be provided. Those files are further annotated as reference files. This set needs to be a profound recording of files that are created during the execution of business processes. This can involve different types of applications ranging from an email client, enterprise resource planning system to a vendor-specific purchase tool. Further an honest and reliable employee needs to perform regular actions during the recording of created files on a PC. By combining all relevant files with its origin will further be annotated as a reference file repository.
Since our approach relies on the actual content of the files we adjusted a stateless Continuous Data Protection (CDP)3 software to capture every version of a file with its actual content.
A CDP provides the technique to observe and restore files during the executing of business processes. Compared to meta-data from the file-system this method enables to rebuild the actual content of files that existed in the past. Thus, to gain useful insights into the generation of relevant files during the business operations, we developed the tool SauvegardeEx4, based on the CDP software Sauvegarde5 which is an open-source and stateless implementation of CDP.
To build a solid and trustworthy base for the needed reference files a profound recording of the origin of a specific file is needed. Data provenance defines how data came to its current state. This technique logs the origin and all activities performed on a specific file. This mechanism is used in secure auditable logging as well as in DF. With the introduction of CamFlow an approach was provided to integrate this mechanism with acceptable resource consumption into current systems [24]. CamFlow is the practical implementation of the whole-system provenance concept of Pohly et al. [25]. This is a kernel-level provenance capturing system that leverages the Linux Security Modules (LSM) framework.
Next to similar provenance systems operating on application or workflow level, CamFlow captures all information flows between processes on the system and enables a holistic and complete view on all file modifications that occurred on the system [24]. By combining CamFlow with SauvegardeEx we enable a method for a trustworthy and complete recording of all file transformations originated by the used business applications.
Figure 3 shows how the business-related reference files are recorded and combined with data provenance. Therein a) gives a profound recording of all involved actions during the creation and modification of a specific file. This is the meta-description about how a file came to its current state. It documents that a specific enterprise application has affected a specific file and a ground-truth basis for the reference files is given. SauvegardeEx in b) illustrates how the actual content of the created files is recorded and stored on a server. Those files are the reference files needed for our approach and the later comparison process.
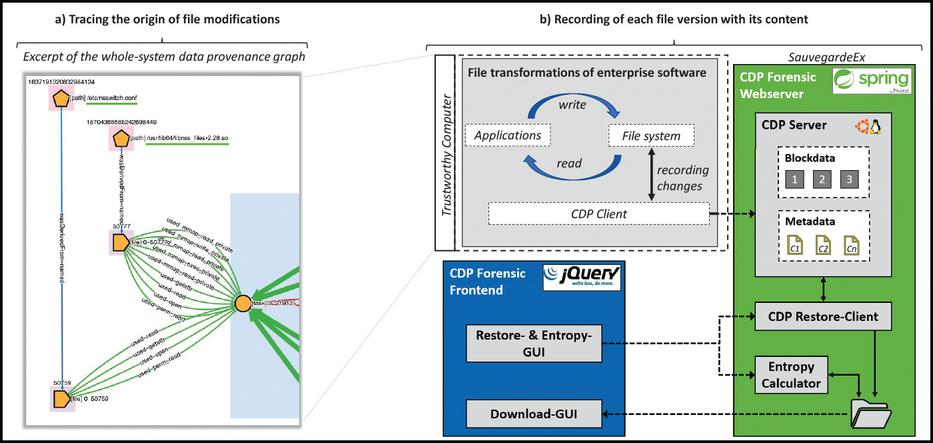
Figure 3 Recording of reference files with SauvegardeEx and CamFlow.
The core of the entropy-based filter algorithm uses the result of the local entropy calculation (calculation of the entropy of each block consisting of n-Bytes)6 and compares them with reference files. We have evaluated various approaches within the development of this method. As a result, a combined approach proved to be the most successful measure. This method proceeds with the following values:
• of the entropy comparison of reference and examination file
• of the frequency distribution of reference and examination file
• Threshold values
• An acceptable degree of variations of the threshold values
Based on these values, the algorithm decides if a specific file will remain in the evidence bag. The pseudo-code in Algorithm 3 shows how the comparison method is implemented to determine the privacy level of a file.
Algorithm 3 Comparison process (step 3)
Require: (reference-file byte-stream); (examination-file byte-stream);
Pthreshold; Ethreshold; variance
; ;
; ;
//E calc. local entropy values:
//E calc. the entropy value of the whole file:
if then
end if
if then
end if
if
and then
end if
if then
Classify examination-file as not-private
end if
The algorithm calculates three values (frqDifference, entropyDifference and a combination of both). The first represents the delta of the frequency distributions by using the cosine similarity. The second value shows the delta of the local entropy equation between reference (pr_in) and examination file (pe_in).
The normalization of the submitted examination file (pe_in) as an input is a crucial factor for the comparison process. The similarity measurement with the cosine similarity needs two vectors with the same size as an input. Since a file cannot be easily normalized (because of the length and structure of the bytes) we performed the normalization on the given array of local entropy values of n-bytes. This means that the abstract representation of the file is given and the different size of the input vector and the vector of a reference file are equalized by compression or expansion of the array. Figure 4 illustrates the normalization process for the similarity measurement.
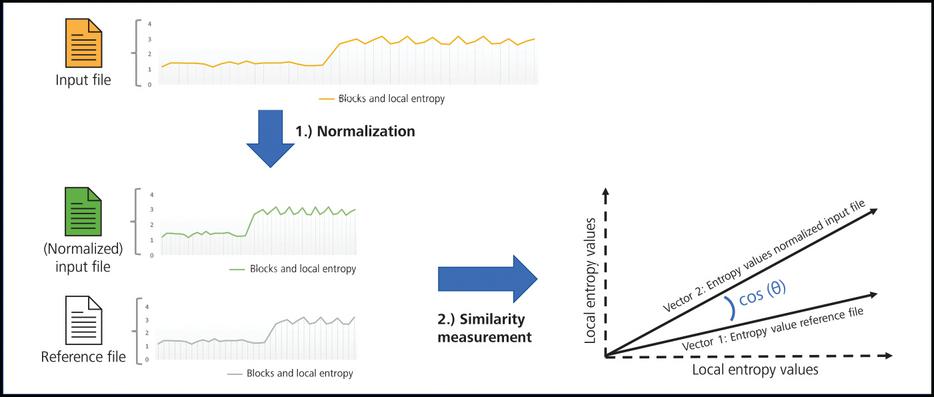
Figure 4 Illustration of the normalization process of the input file.
The last variable of our algorithm is the difference between the deviations of the frequency distribution and the entropy equation. After the calculation, the variances and thresholds must also be read from a configuration file. Further, the calculated values are compared with the thresholds. The calculated variables are used to decide if the file object can be forwarded for the investigation or must be removed.
The proposed filter method was implemented as a prototypical Java application.7 The classification algorithm was implemented together with an API using Spring Boot.8 The creation of a REST Web service with SpringMVC, is based on the Model-View-Controller principle of object-oriented programming and can therefore be easily integrated into an existing program.
Several interfaces have been implemented so that the prototype can be implemented into an existing forensic investigation process. This feature allows checking a recovered file regarding privacy automatically. When a file is uploaded, a comparison is started and an output file is stored in the “results” directory. The previous interfaces just return one or multiple URIs to the results files. The reason why this has been implemented in this way is that the comparison process can take a long time. As soon as the calculations are completed, the user can retrieve his result file by retrieving the URI(s).
The Web-Service consists of the following interfaces: uploadFile, uploadMultipleFiles, getCalculation, addToDirectory, addMultipleToDirectory, clearInputAndOutput, and deleteEntry.
As mentioned above, the procedure requires a threshold to determine whether the file can be used for later analysis. In order to test the correct functionality of the implementation, several trials were carried out to verify the program logic. In the prototype the function to generate a heat map for the comparison process was implemented. This allows to visually check if a certain test file has a high similarity to a business related file. In Figure 5 the test files are shown on the y-axis and business files on the x-axis. The darker a point within the heat-map, the lower the deviation (see a and b within the figure). Consequently, it can be concluded that a specific file has no business context.
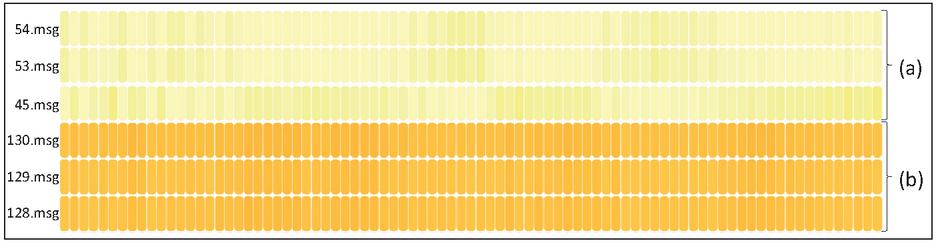
Figure 5 File comparison heat-map.
4 Evaluation of the Concept
This section presents how the developed prototype is used to demonstrate the function of the entropy-based filter algorithm. This is done by loading emails from a fictitious company into the process and comparing the results. For a proper experiment the Precision and Recall test has been chosen. In order to assess and adjust the method 100 test runs were carried out.
We decided to create 100 emails wherein 50% represent business related emails and the remaining 50% relate to private emails. All created emails contain English text and are in HTML-format. Only business-related emails include a signature with a logo and links to social media sites of the fictitious company.
For the creation of the test and reference objects we used the describe combination of a modified CDP software with the name SauvegardeEx and CamFlow (see sub-section 3.4) during the creation and saving of emails with Thunderbird 78.4.0 on a PC running Ubuntu 20.10. Since reliable reference files are needed for applying our algorithm those files are recorded and the origin of the created files is documented through a whole-system data provenance graph.
4.1 Precision and Recall Measurement
Precision and Recall use the method of accumulating False Positives (FP), False Negatives (FN), True Positives (TP), and True Negatives (TN) from multiple test runs. Precision is defined as the probability that an object is relevant when selected by the algorithm and Recall is the probability that a relevant object is returned by the algorithm as described by Losada et al. in 2005, [19]. The formula for Precision p and Recall r is as follows:
| (3) |
On the one hand, FP is the number of elements marked as removable by the algorithm, although they should not have been excluded. On the other hand, FN represents the number of elements not selected by the algorithm despite of containing private information. The next important value is TP, which contains all elements correctly identified and removed by the algorithm. The last value is TN, which represents the number of elements correctly identified as relevant and not removed by the entropy-based algorithm. Although TN is mentioned, it has no effect on the Precision and Recall results since it is not part of the Equation (3), but for completion it is included in the test results.
In order to evaluate and improve the accuracy of the process, it was necessary to introduce a certain degree of variation to reduce the possibility of wrong decisions by the algorithm. This section focuses on the use of Precision and Recall to find the correct deviation metric. This is determined by testing the algorithm. We generated 20 emails, ten from a fictitious company and ten from private individuals. These were used as reference files and are not included in the test-data set described later. Since the method requires three values to make a decision, three tables were created. The first table shows the difference between the frequency distributions of the test and the reference file. In the second table, the difference between the entropy equations of the two files is displayed. The final table takes the results of the previous tables and contains their discrepancies.
In order to produce 100 test runs, we generated 50 business related emails and 50 private emails. Each email is compared with the previously mentioned twenty reference files. We assume that step 1 and step 2 of our filtering process (see Subsection 3.1) have been carried out correctly and only step 3 (see Algorithm 3) needs to be performed. Since our algorithm considers the comparison of one examination file with one reference file we decided to compare one examination file with all twenty reference files and choose the best match. These test results will be used to decide if an item must be sorted out for the newly created image. The next step will focus on the use of the individual results of the experiment. Therefore, the next task will be divided into four parts. The first three parts will look at each phase of the process and what the results would be if only this technique were used to decide the future of the given object file. Then the fourth part will consider all the results and make the decision based on all of them, showing that each part is valuable and necessary to make a sound decision. The variation is calculated based on the combined decision. Then the algorithm performs the fourth test with a variation of the parameters. The thresholds used for each decision variable are the following:
• for frequency distribution 0.001
• for entropy equation value 0.01
• for frequency distribution and entropy equation 0
These parameters were identified by analyzing a small subset for the fictitious company. These will be used in the following test cases.
Frequency Distribution – Precision/Recall analysis. In this experiment 100 results were generated and analyzed with the Precision and Recall method. In the beginning, the frequency distribution probability is in the spotlight. It started with the determination of the FP, FN, TP and TN with the threshold of 0.001. According to the deviation measured with the cosine similarity of the frequency, the algorithm correctly classified 44 emails from a total of 50 non-enterprise emails, as shown in Table 1. This also means that it would not have removed 6 that would have been contained in the investigation image. At least 21 business emails would have been (falsely) filtered out of the image. The Precision and Recall of these results are as follows:
Table 1 Frequency distribution results
| TP | TN | FP | FN | |
| 44 | 29 | 21 | 6 | 100 |
| (4) |
With the results in Equation (4) and in consideration of the frequency distribution as the only decision value, the algorithm would have correctly identified almost 88% of all elements as private or irrelevant. However, the Precision would have been 67.67%, which means that almost 7/10 business emails were correctly identified. Therefore, the frequency distribution has the potential for a decent decision algorithm. However, it is not enough to be the only decision value because there is a lack accuracy, which makes it necessary to include other values in the analysis process.
Entropy equation – Precision/Recall analysis. Considering only the difference of the Shannon Entropy Equations of the reference and examination file was examined next. Therefore the entropy value of the whole files has been used for comparison. These results did not turn out to be very good. Almost 1/3 of all emails were falsely filtered out by the algorithm. Also 23 emails were not filtered out although they contained private critical information.
Table 2 Entropy equation results
| TP | TN | FP | FN | |
| 27 | 36 | 14 | 23 | 100 |
| (5) |
In detail the Entropy Equation results from Table 2 proved to be imprecise with a Precision of 65.85%, which means that nearly 66% of the emails have been classified incorrectly and could have been used for the investigation image. This is indeed an unsatisfactory result that does not make the Entropy Equation itself useful to make a choice. A Recall of 54% shows that 46% of irrelevant emails were not correctly identified as shown in Equation (5). This means that almost half of all non-business emails were transferred to the investigation image and seen by the investigator. Therefore, the indicator of the Shannon Entropy Equation is not sufficient as a decision factor. For this reason, it is necessary to introduce a third decision variable.
Deviation (Frequency Distribution/Entropy Equation) – Precision/Recall analysis. Overall, this shows that the frequency distribution is better suited for a full file comparison than the final Entropy Equation. Due to its ability to analyze the files as a byte stream, a byte comparison can take place, which makes it possible to identify similar structures on a more granular level. But making the whole algorithm dependent on a single decision variable is not sufficient. For this reason, the deviation between frequency distribution and the entropy equation was analyzed. The results showed that there was a correlation between the distribution and final equation results.
It seemed that if the delta of the entropy equation was higher than the deviation of the frequency distributions, a file contained private information, or in case it was the other way around, it was more likely that a file contained no private data. For this reason, an additional test was performed. It determined whether the difference between the results of 1 was greater than those of 2. In the end, the test results in Table 3 showed that the Delta f/e had a Precision of 52% with a Recall of 39.39% presented in Equation (6). This result also does not show a good score for a final decision.
Table 3 Delta frequency distribution/ entropy equation results
| TP | TN | FP | FN | |
| 13 | 55 | 12 | 20 | 100 |
| (6) |
Final analysis of a combination – Precision/Recall. Overall, the three decision variables evaluated separately did not show a good Recall and only the comparison of the frequency distribution deviation had a promising Precision of 67.67%. This is the reason why all three variables were combined to see if they are better suited together for the algorithm. Since all three methods were combined, all of the three methods had to be positive to make the decision for removing the considered element, which ended with a final Precision of 73.53% and a Recall of 50% shown in Equation (7).
Table 4 Combination of all three decision variables (no variation)
| TP | TN | FP | FN | |
| 25 | 41 | 9 | 25 | 100 |
| (7) |
According to these results, which are presented in Table 4, it was shown that the algorithm in its current state achieves a good Precision of 73.53%, but has a big problem identifying some emails to be deleted. The Recall reaches only 50%, which means that too many irrelevant emails are not removed from the final investigation image.
Addition of the variance parameter. The previous results are all without variation, and this means that values close to the threshold are not considered separately, although they are the candidates that are incorrectly sorted out or retained in the end. These have a great influence on the Precision and Recall results. This means that with a decent variance, the algorithm has the potential for improvement. For this reason, a final experiment was carried out. By analyzing the wrong decisions, it has been shown that a variability parameter of 4.2 gives the best results. This was determined for the next experiment. Once again, Precision and Recall were calculated to determine FP, FN, TP and TN in the 100 comparisons.
Table 5 Combination of all three decision variables (with variation)
| TP | TN | FP | FN | |
| 48 | 25 | 25 | 2 | 100 |
| (8) |
Table 5 and Equation (8) show significant improvements in FN with a reduction by 8% in case of not identifying private emails. That ends the experiment with the result of a Precision of 65.75% and a significantly better Recall of 96%. With those improvements in the algorithm the suitability has been significantly increased.
The evaluation shows that the entropy equation and frequency entropy deviation alone are not sufficient to make a decision. However, the frequency distribution deviation alone provided the best results but it still had a poor Recall. By combining all values, only a small improvement could be achieved. However, by introducing and considering variance values, a very reasonable result was achieved.
5 Discussion and Limitations
This work introduces a new method to prepare forensically-sound images for a DF investigation in enterprises which pre-filters private data out of examination material. In comparison, currently available methods focus on preventing investigators from accessing all data on an image but do not remove it which means that the risk of information leakage is still present. The intention of the presented method addresses the problem with a possible automated approach to remove sensitive data before investigators get their hands on the data. Nonetheless, the approach has its limitations.
The proposed approach needs a previously performed full recovery of deleted files to decide if a specific file is forwarded to a DF investigator. The approach relies on the correctness of the chosen file recovery method to perform the privacy-based filtering. An application of this mechanism on encrypted data is not possible since the entropy-based comparison will not work properly in this case. Considering the greater usage of encrypted file systems, the applicability of the proposed solution will be limited. It is essential to extract the key of the encrypted drive to have an unencrypted hard disk image and to access business-relevant files.
Also relevant data for the examination which are stored in excluded file types by using steganography techniques cannot be considered. Additionally, this procedure of reduction of files from an imaging hard drive will interfere in any case in which anti-forensic techniques may have been used. Moreover, a clever attacker can learn the procedure of this investigation method and modify the files through specific manipulation. The resulting misidentification of relevant traces is one of the biggest limitations of the approach.
The method is mainly built on the entropy distribution within a file. Additionally, it is enhanced by adding the ideas of Turner [34] which has been even further improved by the clustering method of Dagher and Fung [10]. A profound performance measurement with other approaches needs to be conducted.
Further our approach needs a profound repository of business-related reference files. A significant amount of reference files and the documentation of its origin is needed to make a valid conclusion about the privacy of a particular file. Even if this base is comprehensively arranged, it must be continuously maintained and frequently updated. Especially software updates of applications used in an enterprise can modify the storage and processing of the files. Affected files by updated software must be added to the repository accordingly.
Nevertheless, the proposal utilizes the focus on business related files which are mainly generated during the execution of business processes. Therefore, the range of results for the collection of samples in advance is manageable.
6 Conclusion and Future Work
If a security incident or fraud is detected within an enterprise, it must be examined by a DF investigation. A company can easily find itself in the conflicting position of having to investigate the incident for a court of law and protecting employees’ privacy during the investigation. This paper provides an approach for an effective privacy-preserving technique.
After introducing DF in enterprises, privacy protection and currently established methods of privacy protection into the forensics process, the need for a privacy-preserving method for DF within an enterprise was identified. Also the purpose of a new method and how it can be useful in the enterprise environment was stated. A combined approach of selective imaging, document clustering & entropy-based filtering and a profound recording of business-related files for building a repository of reference-files is given.
A prototypical implementation of the concept was carried out as a REST Web-Service. Based on this, the approach was extensively evaluated and it was shown that it operates appropriately.
The proposed entropy-based Selective Imaging method for the DF extraction process gives a new perspective on how to identify and filter specific files. Focusing on business-relevant data within Enterprise Forensics is systematically used and combined with the cosine similarity measurement to achieve this goal.
Since this approach relies on a constant and similar structure of business related files a more sophisticated similarity measurement based on similarity hashing [26] (e.g. the Similarity Preserving Hashing algorithm MRSH-v2 from Breitinger and Baier [5]) can be evaluated and (if appropriate) applied. Even further this will help to adjust the algorithm. One example of modifying the process would be focusing on specific signatures like the footer in an email and only focus on searching for that specific fingerprint inside other data objects. With that it would be possible to distinguish the possibility of distortion through binary streams like pictures inside files. Nevertheless, those modifications must be analyzed and implemented into a test application to identify the advantages compared to comparing the complete file objects.
Further we plan to extend our approach with a more advanced machine learning model to sharpen the differentiation between business related documents and private documents by exploring the semantic content of those documents.
The presented method can be integrated into a DF examination process to prepare an image which is free from private as well as critical information for the investigation. In future work the implementation of the concept and the developed web-service into the forensics platform Autopsy9 is planned.
The method also needs to be further tested in a real-world environment and be refined by DF experts and feedback from law enforcement agencies.
Acknowledgments
This article is an extended version of a paper presented at the 9 International Workshop on Cyber Crime (IWCC 2020) held in conjunction with the 15 International Conference on Availability, Reliability and Security (ARES 2020). This paper was kindly invited for a consideration in this journal.
Notes
1https://gdpr.eu/eu-gdpr-personal-data/
2https://www.guidancesoftware.com/encase-forensic
3CDP is defined by the Storage Networking Industry Association as a methodology for continuously capturing and storing data changes. This enables recovering data from the past at any point in time [29, 37].
4https://github.com/LudwigEnglbrecht/sauvegardeEX
5https://github.com/dupgit/sauvegarde
6https://github.com/dupgit/entropie
7https://github.com/LudwigEnglbrecht/DF-privacy_aware_file_checker_v2
8https://spring.io/projects/spring-boot
9https://www.sleuthkit.org/autopsy/
References
[1] Rafael Accorsi, Claus Wonnemann, and Thomas Stocker. Towards forensic data flow analysis of business process logs. In Proceedings of the 2011 Sixth International Conference on IT Security Incident Management and IT Forensics, IMF ’11, pages 3–20. IEEE Computer Society, 2011.
[2] Asou Aminnezhad, Ali Dehghantanha, and Mohd Taufik Abdullah. A survey on privacy issues in digital forensics. International Journal of Cyber-Security and Digital Forensics, 1(4):311–324, 2012.
[3] Frederik Armknecht and Andreas Dewald. Privacy-preserving email forensics. Digital Investigation, 14:127–136, 2015.
[4] Lucas Ballard, Seny Kamara, and Fabian Monrose. Achieving efficient conjunctive keyword searches over encrypted data. In Sihan Qing, Wenbo Mao, Javier López, and Guilin Wang, editors, Information and Communications Security, pages 414–426, Berlin, Heidelberg, 2005. Springer Berlin Heidelberg.
[5] Frank Breitinger and Harald Baier. Similarity preserving hashing: Eligible properties and a new algorithm mrsh-v2. In Marcus K. Rogers and Kathryn C. Seigfried-Spellar, editors, Digital Forensics and Cyber Crime – 4th International Conference, ICDF2C 2012, Lafayette, IN, USA, October 25-26, 2012, Revised Selected Papers, volume 114 of Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, pages 167–182. Springer, 2012.
[6] Mike Burmester, Yvo Desmedt, Rebecca Wright, and Alec Yasinsac. Security or privacy, must we choose? In Symposium on Critical Infrastructure Protection and the Law. 2002.
[7] Aniello Castiglione, Giuseppe Cattaneo, Giancarlo de Maio, and Alfredo de Santis. Automatic, selective and secure deletion of digital evidence. In Leonard Barolli, editor, International Conference on Broadband and Wireless Computing, Communication and Applications (BWCCA), 2011, pages 392–398, Piscataway, NJ, 2011. IEEE.
[8] Yan-Cheng Chang and Michael Mitzenmacher. Privacy preserving keyword searches on remote encrypted data. In John Ioannidis, Angelos Keromytis, and Moti Yung, editors, Applied Cryptography and Network Security, pages 442–455, Berlin, Heidelberg, 2005. Springer Berlin Heidelberg.
[9] Reza Curtmola, Juan Garay, Seny Kamara, and Rafail Ostrovsky. Searchable symmetric encryption. In Ari Juels, Rebecca Wright, and Sabrina de Di Capitani Vimercati, editors, Proceedings of the 13th ACM conference on Computer and communications security, page 79, New York, NY, 2006. ACM.
[10] Gaby G. Dagher and Benjamin C.M. Fung. Subject-based semantic document clustering for digital forensic investigations. Data & Knowledge Engineering, 86:224–241, 2013.
[11] Susan Dumais, John Platt, David Heckerman, and Mehran Sahami. Inductive learning algorithms and representations for text categorization. In Niki Pissinou, editor, Proceedings of the seventh international conference on Information and knowledge management, pages 148–155, New York, NY, 1998. ACM.
[12] Jonathan Grier and Golden G. Richard. Rapid forensic imaging of large disks with sifting collectors. Digital Investigation, 14:34–44, 2015.
[13] Waleed Halboob, Ramlan Mahmod, Nur Izura Udzir, and Mohd. Taufik Abdullah. Privacy levels for computer forensics: Toward a more efficient privacy-preserving investigation. Procedia Computer Science, 56:370–375, 2015.
[14] Shuhui Hou, Tetsutaro Uehara, S. M. Yiu, Lucas C. K. Hui, and K. P. Chow. Privacy preserving multiple keyword search for confidential investigation of remote forensics. In Proceedings of the 2011 Third International Conference on Multimedia Information Networking and Security, MINES ’11, page 595–599, USA, 2011. IEEE Computer Society.
[15] Shuhui Hou, Tetsutaro Uehara, S. M. Yiu, Lucas C.K. Hui, and K. P. Chow. Privacy preserving confidential forensic investigation for shared or remote servers. In Xiamu Niu, editor, Seventh International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), 2011, pages 378–383, Piscataway, NJ, 2011. IEEE.
[16] Shuhui Hou, Siu-Ming Yiuy, Tetsutaro Ueharaz, and Ryoichi Sasakix. A privacy-preserving approach for collecting evidence in forensic investigation. International Journal of Cyber-Security and Digital Forensics (IJCSDF), 2(1):70–78, 2013.
[17] Han-Joon Kim and Sang-Goo Lee. A semi-supervised document clustering technique for information organization. In Arvin Agah, editor, Proceedings of the ninth international conference on Information and knowledge management, pages 30–37, New York, NY, 2000. ACM.
[18] Frank Y.W. Law, Patrick P.F. Chan, S. M. Yiu, K. P. Chow, Michael Y.K. Kwan, Hayson K.S. Tse, and Pierre K.Y. Lai. Protecting digital data privacy in computer forensic examination. In 2011 Sixth IEEE International Workshop on Systematic Approaches to Digital Forensic Engineering, Oakland, California, USA, 05.05-06.05.2011, pages 1–6, New York (NY), 2011. IEEE Computer Society.
[19] David E. Losada, Juan M. Fernández-Luna, Cyril Goutte, and Eric Gaussier, editors. A Probabilistic Interpretation of Precision, Recall and F-Score, with Implication for Evaluation: Advances in Information Retrieval. Springer Berlin Heidelberg, 2005.
[20] Shawn McCreight and Dominik Weber. System and method for entropy-based near-match analysis, 2010. US Patent App. 12/722,482.
[21] Stefan Meier. Digitale Forensik in Unternehmen. PhD thesis, University of Regensburg, 2017.
[22] Ana Nieto, Ruben Rios, Javier Lopez, Wei Ren, Lizhe Wang, Kim-Kwang Raymond Choo, and Fatos Xhafa. Privacy-aware digital forensics. Computing. Institution of Engineering and Technology, 2019.
[23] Sungmi Park, Nikolay Akatyev, Yunsik Jang, Jisoo Hwang, Donghyun Kim, Woonseon Yu, Hyunwoo Shin, Changhee Han, and Jonghyun Kim. A comparative study on data protection legislations and government standards to implement digital forensic readiness as mandatory requirement. Digital Investigation, 24:93–100, 2018.
[24] Thomas Pasquier, Xueyuan Han, Mark Goldstein, Thomas Moyer, David Eyers, Margo Seltzer, and Jean Bacon. Practical whole-system provenance capture. In Proceedings of the 2017 Symposium on Cloud Computing, pages 405–418. ACM, 2017.
[25] Devin J. Pohly, Stephen McLaughlin, Patrick McDaniel, and Kevin Butler. Hi-fi: collecting high-fidelity whole-system provenance. In Proceedings of the 28th Annual Computer Security Applications Conference, pages 259–268. ACM, 2012.
[26] Vassil Roussev, Yixin Chen, Timothy Bourg, and Golden G. Richard III. md5bloom: Forensic filesystem hashing revisited. Digital Investigation, 3(Supplement-1):82–90, 2006.
[27] Shahzad Saleem, Oliver Popov, and Ibrahim Bagilli. Extended abstract digital forensics model with preservation and protection as umbrella principles. Procedia Computer Science, 35:812–821, 2014.
[28] Claude E. Shannon. A mathematical theory of communication. Bell System Technical Journal, 27(3):379–423, 1948.
[29] Yonghong Sheng, Dongsheng Wang, Jinyang He, and Dapeng Ju. TH-CDP: an efficient block level continuous data protection system. In International Conference on Networking, Architecture, and Storage, pages 395–404, 2009.
[30] Dawn Xiaodong Song, David A. Wagner, and Adrian Perrig. Practical techniques for searches on encrypted data. In 2000 IEEE Symposium on Security and Privacy, Berkeley, California, USA, May 14-17, 2000, pages 44–55. IEEE Computer Society, 2000.
[31] S. Srinivasan. Security and privacy vs. computer forensics capabilities. Information Systems Control Journal, 4:1–3, 2007.
[32] Johannes Stüttgen, Andreas Dewald, and Felix C. Freiling. Selective imaging revisited. In Holger Morgenstern, editor, Seventh International Conference on IT Security Incident Management and IT Forensics (IMF), 2013, pages 45–58, Piscataway, NJ, 2013. IEEE.
[33] Hal Tipton. Investigating inside the corporation. Computer Fraud & Security Bulletin, 1993(2):4–10, 1993.
[34] Philip Turner. Selective and intelligent imaging using digital evidence bags. Digital Investigation, 3:59–64, 2006.
[35] Isabel Wagner and David Eckhoff. Technical privacy metrics: A systematic survey. ACM Comput. Surv., 51(3):57:1–57:38, 2018.
[36] Alec Yasinsac and Yanet Manzano. Policies to Enhance Computer and Network Forensics. In Proceedings of the 2001 IEEE Workshop on Information Assurance and Security. 2001.
[37] Xiao Yu, Yu-an Tan, Zhizhuo Sun, Jingyu Liu, Chen Liang, and Quanxin Zhang. A fault-tolerant and energy-efficient continuous data protection system. J. Ambient Intell. Humaniz. Comput., 10(8):2945–2954, 2019.
[38] Christian Zoubek and Konstantin Sack. Selective deletion of non-relevant data. Digital Investigation, 20:92–98, 2017.
Biographies

Ludwig Englbrecht studied Business Information Systems at the University of Regensburg, Germany and at the Queensland University of Technology, Australia. His major field of study was IT-Security during his master studies. Currently he is a research assistant of Prof. Dr. Günther Pernul and Ph.D. candidate at the University of Regensburg, Germany. His research focus is on new approaches in IT-Forensics (Digital Forensics) and Digital Forensic Readiness.

Günther Pernul received both the diploma degree and the doctorate degree (with honors) from the University of Vienna, Austria. Currently he is full professor at the Department of Information Systems at the University of Regensburg, Germany. Prior he held positions with the University of Duisburg-Essen, Germany and with University of Vienna, Austria, and visiting positions the University of Florida and the College of Computing at the Georgia Institute of Technology, Atlanta. His research interests are manifold, covering data and information security aspects, data protection and privacy, data analytics, and advanced data centric applications.
Journal of Cyber Security and Mobility, Vol. 10_1, 27–64.
doi: 10.13052/jcsm2245-1439.1012
© 2021 River Publishers