Structure Preserving Large Imagery Reconstruction
Received 28 May 2014; Accepted 20 August 2014 Publication 7 October 2014
Journal of Cyber Security, Vol. 3, 263–288.
doi: 10.13052/jcsm2245-1439.332
Copyright © 2014 River Publishers. All rights reserved.
Ju Shen1, Jianjun Yang2, Sami Taha-abusneineh3, Bryson Payne4 and Markus Hitz4
- 1Department of Computer Science, University of Dayton, 300 College Park, Dayton, OH 45469, USA
- 2Department of Computer Science and Information Systems, University of North Georgia, Oakwood, GA 30566, USA
- 3Computer Science Department, Palestine Polytechnic University (PPU), Ein Sara Street, Hebron, Palestine
- 4Department of Computer Science and Information Systems, University of North Georgia, Dahlonega, GA 30597, USA
jshen1@udayton.edu, jianjun.yang@ung.edu, staha77@yahoo.com, {bryson.payne; markus.hitz}@ung.edu
Abstract
With the explosive growth of web-based cameras and mobile devices, billions of photographs are uploaded to the internet. We can trivially collect a huge number of photo streams for various goals, such as image clustering, 3D scene reconstruction, and other big data applications. However, such tasks are not easy due to the fact the retrieved photos can have large variations in their view perspectives, resolutions, lighting, noises, and distortions. Furthermore, with the occlusion of unexpected objects like people, vehicles, it is even more challenging to find feature correspondences and reconstruct realistic scenes. In this paper, we propose a structure-based image completion algorithm for object removal that produces visually plausible content with consistent structure and scene texture. We use an edge matching technique to infer the potential structure of the unknown region. Driven by the estimated structure, texture synthesis is performed automatically along the estimated curves. We evaluate the proposed method on different types of images: from highly structured indoor environment to natural scenes. Our experimental results demonstrate satisfactory performance that can be potentially used for subsequent big data processing, such as image localization, object retrieval, and scene reconstruction. Our experiments show that this approach achieves favorable results that outperform existing state-of-the-art techniques.
1 Introduction
In the past few years, the massive collections of imagery on the Internet have inspired a wave of work on many interesting big data topics. For example, by entering a keyword, one can easily download a huge number of photo streams related to it. Moreover, with the recent advance in image processing techniques, such as feature descriptors [1], pixel-domain matrix factorization approaches [2–4] or probabilistic optimization [5], images can be read in an automatic manner rather than relying on the associated text. This leads to a revolutionary impact to a broad range of applications, from image clustering or recognition [6–12] to video synthesis or reconstruction [13–15] to cyber-security via online images analysis [16–19] to other scientific applications [20–24].
However, despite the numerous applications, poor accuracy can be yielded due to the large variation of the photo streams, such as resolution, illumination, or photo distortion. In particular, difficulties arise when unexpected objects present on the images. Taking the Google street view as an example, the passing vehicles or walking passengers could affect the accuracy of image matching. Furthermore such unwanted objects also introduce noticeable artifacts and privacy issue in the reconstructed views.
To resolve these issues, object removal [25, 26] is an effective technique that has been widely used in many fields. A common approach is to use texture synthesis to infer missing pixels in the unknown region, such as [27, 28]. Efros and Leung [29] use a one-pass greedy algorithm to infer the unknown pixels based on an assumption that the probability distribution of a target pixel’s brightness is independent from the rest of the image given its spatial neighborhood. Some studies propose example-based approaches to fill the unknown regions, such as [27–29]. These approaches failed to preserve the potential structures in the unknown region. Bertalmio et al. [30] apply partial differential equations (PDE) to propagate image Laplacians. While the potential structures are improved in the filled region, it suffers from blurred synthesized texture. Drori et al. [31], propose an enhanced algorithm to improve the rendered texture. Jia et al. [32] propose an texture-segmentation based approach using tensor-voting to achieve the same goal. But their approaches are computationally expensive. A widely used image in-painting technique developed by Criminisi et al. [26] aims to fill the missing region by a sequence of ordered patches by using the proposed confidence map. The priority of each patch is determined by the edge strength from the surrounding region. However, the potential structures in the in-painted region can not be well preserved, especially for those images with salient structures. The authors Sun et al. in [33] make an improvement through structure propagation, while this approach requires additional user intervention and the results may depend on the individual animators.
As an extension of our early work [34], we propose an automatic object removal algorithm for scene completion, which would benefit large imagery processing. The cue of our method is based on the structure and texture consistency. First, it predicts the underlying structure of the occluded region by edge detection and contour analysis. Then structure propagation is applied to the region followed by a patch-based texture synthesis. Our proposed approach has two major contributions. First, given an image and its target region, we develop an automatic curve estimation approach to infer the potential structure. Second, an orientated patch matching algorithm is designed for texture propagation. Our experiments demonstrate satisfactory results that outperform other techniques in the literature.
The rest of the paper is organized as follows: in Section 2, we give an example to demonstrate the basic steps of our image completion algorithm. Then we define the model and notations in Section 3. Details are further explained in Section 4. The experiment results are presented in Section 5. Finally we conclude the paper and our future work in Section 6.

Figure 1 Example object removal on an image (a) The original image (b) The result image
2 A Simple Example
The process of our framework is: for a given image, users specify the object for removal by drawing a closed contour around it. The enclosure is considered as the unknown or target region that needs to be filled by the remaining region of the image. Figure 1(a) shows an example: the red car is selected as the removing object. In the resulting image, Figure 1(b), the occluded region is automatically recovered based on the surrounding available pixels.
Our algorithm is based on two observations: spacial texture coherence and structure consistency along the boundaries between the target and source regions. To ensure spacial coherence, many exemplar-based methods have been proposed to find the potential source texture for the target region. By traversing the available pixels from the known region, a set of “best patches” are found to fill the target region. Here the definition of “best patch” refers to a small region of contiguous pixels from the source region that can maximize a certain spacial coherence constraint specified by different algorithms. A typical example can be found in [26]. However, a naive copy-and-paste of image patches may introduce noticeable artifacts, though the candidate patches can maximize a local coherence. To resolve this problem, structure preservation is considered to ensure the global consistency. There have been several techniques presented for structure propagation to ensure smooth and natural transitions among salient edges, such as the Sun’s method [33], which requires additional user input to finish the task.
3 The Approach
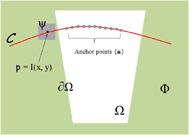
First let us define some notations for the rest of paper. The target region for filling is denoted as Ω; the remaining part Φ(=I – Ω) is the region whose pixels are known. The boundary contours are denoted as ∂Ω that separate Φ and Ω. A pixel’s value is represented by p = I(x, y), where x and y are the coordinates on the image I. The surrounding neighborhood centered at (x, y) is considered as a patch, denoted by Ψp, whose coordinates are within [x ± Δx, y ± Δy], as shown in Figure 2. In our framework, there are three stages involved: structure estimation, structure propagation, and remaining part filling.
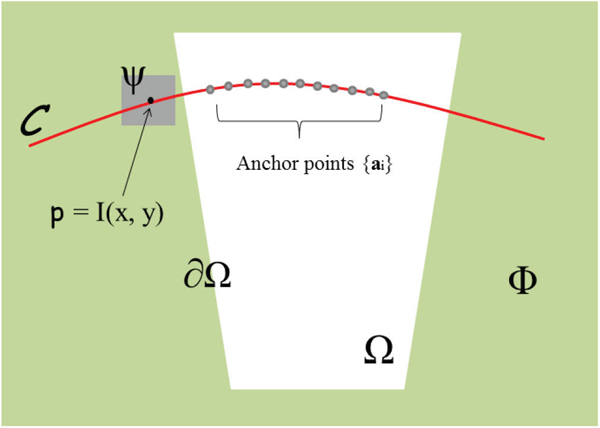
Figure 2 Symbols definition
Structure Estimation: In this stage, we estimate the potential structures in the target region Ω. To achieve this, we apply gPb Contour Detector [35] to extract the edge distribution on the image:
where, Gx and Gy are the first derivative of Gaussian function with respect to x and y axis . After computing Iedges, most of the strong edges can be extracted via threshold suppression. Inspired by the level lines technique [36], the edges in Ω can be estimated by linking matching pairs of edges along the contour.
Structure Propagation: After the structures are estimated, textures along the structures are synthesized and propagated into the target region Ω. We use Belief Propagation to identify optimal patches of texture from the source region Φ and copy and paste them to the structures in Ω.
Remaining Part Filling: After the structure propagation, the remaining unfilled regions in Ω are completed. We adopt the Criminisi’s method [26], where a priority-based patch filling scheme is used to render the remaining target region in an optimal order.
In the following subsections, we present the details of each step of the proposed algorithm. In particular, we give emphasis to the first two steps: structure estimation and structure propagation, which provide the most contribution of this proposed technique.
3.1 Structure Estimation
In this stage, we estimate the potential structures in Ω by finding all the possible edges. This procedure can be divided into two steps: Contour Detection in Φ and Curve Generation in Ω.
3.1.1 Contour Detection in Φ
We first segment the region Φ by using gPb Contour Detector [35], which computes the oriented gradient signal G(x, y, θ) on the four channels of its transformed image: brightness, color a, color b and texture channel. G(x, y, θ) is the gradient signal, where (x, y) indicates the center location of the circle mask that is drawn on the image and θ indicates the orientation. The gPb Detector has two important components: mPb Edge Detector and sPb Spectral Detector [35]. According to the gradient ascent on F-measure, we apply a linear combination of mPb and sPb (factored by β and γ):
Thus a set of edges in Φ can be retrieved via gPb. However, these edges are not in close form and have classification ambiguities. To solve this problem, we use the Oriented Watershed Transform [35] and Oriented Watershed Transform [37] (OWT-UCM) algorithm to find the potential contours by segmenting the image into different regions. The output of OWT-UCM is a set of different contours {Ci} and their corresponding boundary strength levels {Li}.
3.1.2 Curve Generation in Ω
After obtaining the contours {Ci} from the above procedure, salient boundaries in Φ can be found by traversing {Ci}. Our method for generating the curves in Ω is based on the assumption: for the edges on the boundary in Φ that intersects with the ∂Ω, it either ends inside Ω or passes through the missing region Ω and exits at another point of ∂Ω. Below is our algorithm for identifying the curve segments in Ω:
Algorithm 3.1 Identifying curve segments in Ω

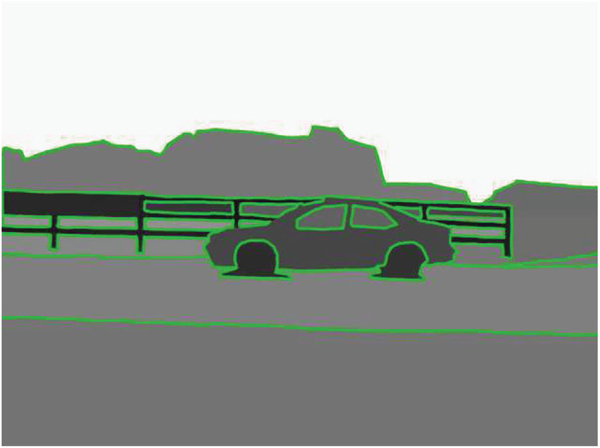
Figure 3 Contour extraction by adjusting the value of t
In algorithm 3.1, it has three main parts: (a) collect all potential edges {Ex} in Φ that hits ∂Ω; (b) identify optimal edge pairs {(Es, Et)} from {Ex}; (c) construct a curve Cst for each edge pair (Es, Et).
Edges Collection: The output of OWT-UCM are contours sets {Ci} and their corresponding boundary strength levels {Li}. Given different thresholds t, one can remove those contours C with weak L. Motivated by this, we use the Region-Split scheme to gradually demerge the whole Φ into multiple sub-regions and extract those salient curves. This process is carried out on lines 1–9: at the beginning the whole region Φ is considered as one contour; then iteratively decrease t to let potential sub-contours {Ci} faint out according the boundary strength; Every time when any edges e from the newly emerged contours {C} were detected of intersecting with ∂Ω, they are put into the set {E}.
Optimal Edge Pairs: the motivation of identifying edge pairs is based on the assumption if an edge is broken up by Ω, there exists a pair of corresponding contour edges in Φ that intersect with ∂Ω. To find the potential pairs {(Es, Et)} from the edge list {Ex}, we measure the corresponding enclosed regions similarities. The neighboring subregions which are partitioned by the edge Es are used to compare with the corresponding subregions of another edge Et. This procedure is described on lines 7 – 9 of the algorithm 3.1. For simplicity, the superscripts (s) and (t) are removed and the neighboring subregions are list in a sequential order. Each neighboring region is obtained by lowing down the threshold value t to faint out its contours as Figure 3 shows.
To compute the similarity between regions, we use the Jensen-Shannon divergence [38] method that works on the color histograms:
where H1 and H2 are the histograms of the two regions ϕ1, ϕ2; i indicates the index of histogram bin. For any two edge (Es, Et), the similarity between them can be expressed as:
i and j are the exclusive numbers in {1, 2}, where 1 and 2 represent the indices of the two neighboring regions in Φ around a particular edge. The Lmax is the max value of the two comparing edges’ strength levels. The first multiplier is a penalty term for big difference between the strength levels of the two edges. To find the optimal pairs among the edge list, dynamic programming is used to minimize the global distance: , where s ≠ t and s, t ∈ {0, 1,. .., size({Ei})}. To enhance the accuracy, a maximum constraint is used to limit the regions’ difference: d(H1, H2) < δH. If the individual distance is bigger than the pre-specified threshold δH, the corresponding region matching is not considered. In this way, it ensures if there are no similar edges existed, no matching pairs would be identified.
Generate Curves for each (Es, Et): we adopt the idea of fitting the clothoid segments with polyline stoke data first before generating a curve [39]. Initially, a series of discrete points along the two edges Es and Et are selected, denoted as {ps0, ps1,..., psn, pt1,..., ptm}. These points have a distance with each other by a pre-specified value Δd. For any three adjacent points {pi-1, pi, pi+1}, the corresponding curvature ki could be computed according to [40]:
Combining the above curvature factors, a sequence of polyline are used to fit these points. The polylines are expected to have a possibly small number of line segments while preserving the minimal distance against the original data. Dynamic programming is used to find the most satisfied polyline sequence by giving a penalty for each additional line segment. A set of clothoid segments can be derived corresponding to each line segment. After a series rotations and translations over the clothoid, a final curve C is obtained by connecting each adjacent pair with G2 continuity [39]. Figure 4 demonstrates the curve generation result.
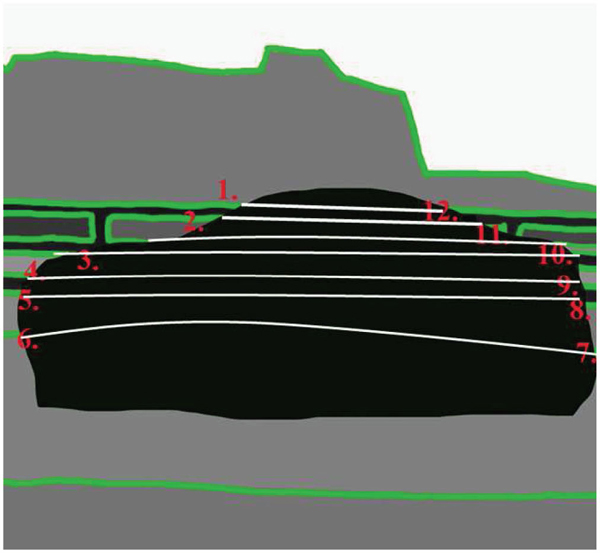
Figure 4 Optimal structure generation in Ω
3.2 Structure Propagation
After the potential curves are generated in Ω, a set of texture patches, denoted as {Ψ0, Ψ1,...}, need to be found from the remaining region Φ and placed along the estimated curves by overlapping with each other with a certain proportion. Similar to the Sun’s method [33], an energy minimization based Belief Propagation(BP) framework is developed. We give different definitions for the energy minimization and passing messages, the details of which can be found in algorithm 3.2.
In our algorithm, the anchor points are evenly distributed along the curves with an equal distance from each other Δd. These points represent the center where the patches are placed, as shown in Figure 2. In practice, we define . The is the source texture patches in Φ . They are chosen on from the neighborhood around ∂Ω. According to the Markov Random Field definition, each ai is considered as a vertex and represents a edge between two neighboring nodes i and j.
Among the traditional exemplar-based methods, when copy a texture patch from the source region Φ to the target region Ω, each Ψi have the same orientation as , which limits the varieties of the texture synthesis.
Algorithm 3.2 Belief Propagation for Structure Completion

Noticing that different patch orientations could produce different results, we introduce a scheme called Adaptive Patch by defining a new configuration for the energy metric E and message M.
Intuitively, the node energy Ei (ti) can be defined as the Sum of Square Difference(SSD) by comparing the known pixels in each patch Ψi with the candidate patch in . But this could limit the direction changes of the salient structure. So instead of using SSD on the two comparing patches, rotation transformation is performed to the candidate patch before computing the SSD. Mathematically, Ei (ti)can be formulated as:
where represents the 2D rotation matrix with an input angle parameter θ along the orthogonal vector that is perpendicular to the image plane. Since the size of a patch is usually small, the rotation angle θ can be specified with an arbitrary number of values. In our experiment, it is defined as . Parameter λ represents the number of known pixels in Ψi that overlap with the rotated patch P is a penalty term that discourage the candidate patches with smaller proportion of overlapping pixels with the neighboring patches. Here, we define P as (l is the length of Ψ). αλ is the corresponding normalization factor.
In a similar way, the energy Eij (ti, tj) on each edge ℰij can be expressed as:
where i and j are the corresponding indices of the two adjacent patches in Ω. The two parameters for Ψi indicate the index and rotation for the source patches in . We adopt a similar message passing scheme as [33] that message Mij passes by patches Ψi is defined as:
Through iterative message passing on the MRF graph to minimize the global energy, an optimal configuration of {ti} for the patches in {Ψi} can be obtained. The optimal matching patch index is defined as:
Where k is the index of one of the neighbors of the patch . To compute an minimum energy cost, dynamic programming is used: at each step, different states of can be chosen. The edge represents the transition cost from the state of at step i to state of at step i to state of at step j. Starting from i = 0, an optimal solution is achieved by minimizing the total energy :
where represents a set of different total energy values at the current step i. In the cases of multiple intersections between curves C, we adopted the idea of Sun’s method [33], where readers can refer to for further details.
3.3 Remaining Part Filling
After the structure curves are generated in Ω, we fill the remaining regions by using the exemplar-based approach in [26], where patches are copied from the source region Φ to the filling region Ω in a priority order. The priority is determined by the extracted edges in Φ that intersect with ∂Ω. To ensure the propagated structures in Ω maintain the same orientation as in Φ , higher priorities of texture synthesis are given to those patches that lie on the continuation of stronger edges in Φ .
According to Criminisi’s algorithm [26], each pixel on a image has a confidence value and color value. The color value can be empty if it is in the unfilled region Ω. For a given patch ΨP at a point p, its priority is defined as: priority (p) = C(p).D(p), where C(p) and D(p are the confidence map and data term that are define as:
and
where q represents the surrounding pixels of p in the patch . is the area of the patch ΨP. The variable np is a unit orthogonal vector that is perpendicular to the boundary ∂Ω on the pointp. The normalization factor α is set as 255 as all the pixels are in the range [0, 255] for each color channel. So in such a way, the priority for each pixel can be computed. For further details, we refer readers to the Criminisi’s algorithm [26] for more explanations.
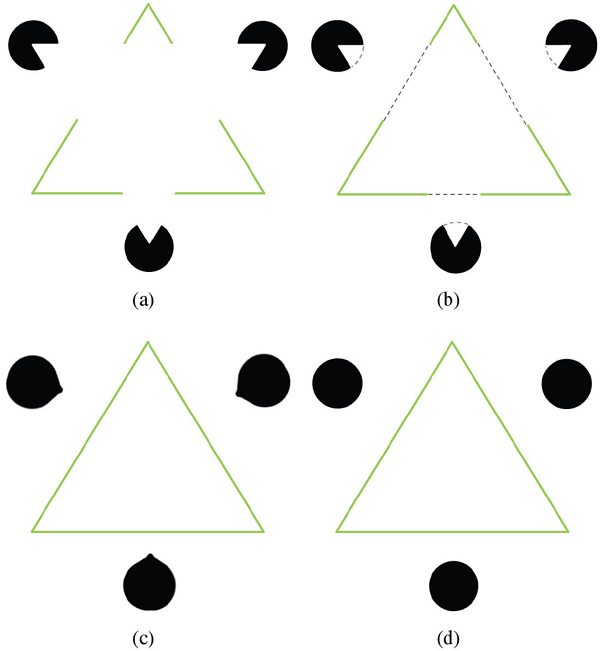
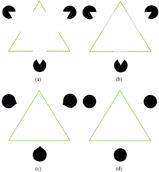
Figure 5 Kanizsa triangle experiment (a) Original image (b) Curve reconstruction for the missing region Ω (c) Result image by criminisi’s method (d) Result image by our method
4 Experiments
In our experiments, to evaluate our algorithm, different styles of images are tested from natural scenes to indoor environment that has strict structure. Our algorithm obtains satisfactory results in terms of texture coherence and structural consistency. The algorithm is implemented in C++ code with OpenCV library. All the images results are generated on a dual-core PC with CPU 2.13GHz and Memory 2G. For the images with the regular resolution 640 x 480, the average computation cost is about 52 seconds.
To verify the performance of the algorithm, we first compare the result of our method with the one proposed in [26] on the well-known Kanizsa triangle in terms of structure coherence and texture consistency. As shown in Figure 5(a), the white triangle in the front is considered as Ω that needs to be filled. First, a structure propagation is performed based on the detected edges along ∂Ω. The dash curves in Figure 5(b) indicate the estimated potential structure in the missing area Ω, which are generated by our structure propagation algorithm. Texture propagation is applied to the rest of the image based on the confidence and isophote terms. One can notice both the triangle and the circles are well completed in our result Figure 5(d) comparing with Criminisi’s method in Figure 5(c).
Figure 6 demonstrates the advantage of our method by preserving the scene structure after removing the occluded object. The original image data can be find publicly at the website1. Figure 6(b) shows the target region (the bungee jumper) for removal marked in green color. Figure 6(c), 6(d) are the image reconstruction results by the Criminisi’s and our methods respectively. One can notice the roof area in Figure 6(c) is broken by the grass which introduces noticeable artifact, while the corresponding part remains intact in our result. Furthermore, in contrast to the Criminisi’s method, the lake boundary is naturally recovered thanks to our structure estimation procedure, as shown in 6(d). In terms of the time performance for the original image of 205 × 307 pixels, our method performed 10.5 seconds on the computer of dual-core PC with CPU 2.13GHz and 2GB of RAM, to be compared with 18 seconds of Criminisi’s on a 2.5 GHz Pentium IV with 1 GB of RAM.

Figure 6 Result comparison with criminisi’s method [26]

Figure 7 Result comparison with sun’s method [33]

Figure 8 Demo 1- Bottle removal (a) Original image (b) Image with user’s label for removal (c) Generated structure in the missing region (d) Result image

Figure 9 Demo 2- Tree removal 1 (a) Original image (b) Image with user’s label for removal (c) Generated structure in the missing region (d) Result image

Figure 10 Demo 3- Tree removal 2 (a) Original image (b) Image with user’s label for removal (c) Generated structure in the missing region (d) Result image
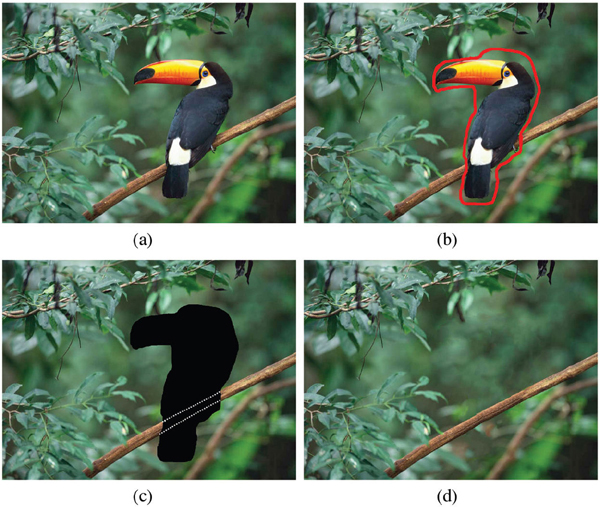
Figure 11 Demo 4- Bird removal (a) Original image (b) Image with user’s label for removal (c) Generated structure in the missing region (d) Result image
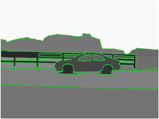
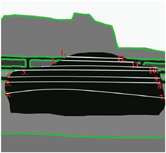
Another existing work we choose to compare with is the Sun’s method, which also aims to preserve the original structure in the recovered image. However, the difference is that Sun’s method requires manual intervention during the completion process. The potential structure in the target region needs to be manually labeled by the designer, which can vary according to individuals. Figure 7 demonstrates a comparison between Sun’s and our methods. In the original image, the car is considered as the target object for removal, which is marked in black color in Figure 7(b). In Figures 7(c), 7(d), the potential structures in the target region are labeled by [33] and automatically estimated by our method, which produce different results, as shown in Figures 7(e), 7(f). To compare the computation speed, our methods performed 51.7 seconds to process this image (640 × 457), in contrast with the Sun’s fewer than 3 seconds for each curve propagation (3 curves in total) and 2 to 20 seconds for each subregion (4 subregions in total) on a 2.8 GHz PC. Moreover, we save the potential labor work on specifying the missing structures by the user.
To further demonstrate the performance, a set of images are used for scene recovery: ranging from indoor environment to natural scenes. Figure 8 shows the case of indoor environment, where highly structural patterns often present, such as the furniture, windows, walls. In Figure 8, the green bottle on the office partition is successfully removed while preserving the remaining structure. In this example, five pairs of edges are identified and connected by the corresponding curves that are generated in the occluded region Ω. Guided by the estimated structure, plausible texture information is synthesized to form a smooth intensity transition across the occluded region with little artifact.
For the outdoor environment, as there are fewer straight lines or repeating patterns existing in the natural world, the algorithm should provide the flexibility to generate irregular structures. Figure 9 and 10 show the results of removing trees in the nature scenes. Several curves are inferred by matching the broken edges along ∂Ω and maximizing the continuity. We can notice the three layers of the scene (sky, background trees, and grass land) are well completed. In Figure 11, it shows a case that a perching bird is removed from the tree. Our structure estimation successfully completes the tree branch with smooth geometric and texture transitions. Without such structure guidance, those traditional exemplar-texture based methods can easily produce notice-able artifacts. For example, multiple tree branches may be generated as the in-painting process and directions largely rely on the matching patches.
5 Conclusion
In this paper, we present a novel approach for foreground objects removal while ensure structure coherence and texture consistency. The core of our approach is to use structure as a guidance to complete the remaining scene, which demonstrates its accuracy and consistency. This work would benefit a wide range of applications, from digital image restoration (e.g. scratch recovery) to privacy protection (e.g. remove people from the scene). In particular, this technique can be promising for the online massive collections of imagery, such as photo localization and scene reconstructions. By removing foreground objects, the matching accuracy can be dramatically improved as the corresponding features are only extracted from the static scene rather than those moving objects. Furthermore it can generate more realistic views because the foreground pixels are not involved in any image transformation and geometric estimation.
As one direction of our future work, we will apply this object removal technique to scene reconstruction applications that can generate virtual views or reconstruct the 3D data from a set of images. Multiple images can give more cues of the potential structure and texture in the target region. For example, through corresponding features among different images, intrinsic and extrinsic parameters can be estimated. Then the structure and texture information can be mapped from one image to another image. So for a particular target region for completion, multiple sources (from different images) can contribute the estimation. As such, Our current algorithm needs to be modified adaptively to take the advantage of the extra information. An optimization framework could be established to identify optimal structures and textures to fill the target region.
References
[1]Jim Jing-Yan Wang, Halima Bensmail, and Xin Gao. Joint learning and weighting of visual vocabulary for bag-of-feature based tissue classification. Pattern Recognition, 46(12):3249–3255, 2013.
[2]Jim Jing-Yan Wang, Halima Bensmail, and Xin Gao. Multiple graph regularized nonnegative matrix factorization. Pattern Recognition, 46(10):2840–2847, 2013.
[3]Q. Sun, P. Wu, and Y. Wu. Unsupervised multi-level non-negative matrix factorization model: Binarydata case. International Journal of Information Security, 3(4):245–250, 2012.
[4]Jing-Yan Wang, Islam Almasri, and Xin Gao. Adaptive graph regularized nonnegative matrix factorization via feature selection. In Pattern Recognition (ICPR), 2012 21st International Conference on}, pages 963–966. IEEE, 2012.
[5]Ju Shen and S.-C.S. Cheung. Layer depth denoising and completion for structured-light rgb-d cameras. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 1187–1194, 2013.
[6]Yuzhu Zhou, Le Li, Tong Zhao, and Honggang Zhang. Region-based high-level semantics extraction with cedd. In Network Infrastructure and Digital Content, 2010 2nd IEEE International Conference on}, pages 404–408. IEEE, 2010.
[7]Ju Shen and Wai tian Tan. Image-based indoor place-finder using image to plane matching. In Multimedia and Expo (ICME), 2013 IEEE International Conference on, pages 1–6, 2013.
[8]Yuzhu Zhou, Le Li, and Honggang Zhang. Adaptive learning of region-based plsa model for total scene annotation. arXiv preprint arXiv:1311.5590, 2013.
[9]Le Li, Jianjun Yang, Kaili Zhao, Yang Xu, Honggang Zhang, and Zhuoyi Fan. Graph regularized non-negative matrix factorization by maximizing correntropy. arXiv preprint arXiv:1405.2246, 2014.
[10]Q. Sun, F. Hu, and Q. Hao. Context awareness emergence for distributed binary pyroelectric sensors. In Proceeding of 2010 IEEE International Conference of Multi-sensor Fusion and Integration of Intelligent Systems, pages 162–167, 2010.
[11]Le Li, Jianjun Yang, Yang Xu, Zhen Qin, and Honggang Zhang. Document clustering based on max-correntropy non-negative matrix factorization. 2014.
[12]Q. Sun, F. Hu, and Q. Hao. Mobile target scenario recognition via low-cost pyroelectric sensing system: Toward a context-enhanced accurate identification. IEEE Transactions on Systems, Man and Cybernetics: Systems, 4(3):375–384, 2014.
[13]Ju Shen, Anusha Raghunathan, Sen ching Cheung, and Rita Patel. Automatic content generation for video self modeling. In Multimedia and Expo (ICME), 2011 IEEE International Conference on, pages 1–6, 2011.
[14]Ju Shen, Changpeng Ti, Sen ching Cheung, and R.R. Patel. Automatic lip-synchronized video-self-modeling intervention for voice disorders. In e-Health Networking, Applications and Services (Healthcom), 2012 IEEE 14th International Conference on}, pages 244–249, 2012.
[15]Ju Shen, Changpeng Ti, Anusha Raghunathan, Sen ching Cheung, and Rita Patel. Automatic video self modeling for voice disorder. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 1187–1194, 2013.
[16]Li Xu, Zhenxin Zhan, Shouhuai Xu, and Keying Ye. Cross-layer detection of malicious websites. In Proceedings of the third ACM conference on Data and application security and privacy, pages 141–152. ACM, 2013.
[17]Jianjun Yang and Zongming Fei. Hdar: Hole detection and adaptive geographic routing for ad hoc networks. In Computer Communications and Networks (ICCCN), 2010 Proceedings of 19th International Conference on, August 2010.
[18]Li Xu, Zhenxin Zhan, Shouhuai Xu, and Keying Ye. An evasion and Counter-Evasion study in malicious websites detection. In 2014 IEEE Conference on Communications and Network Security (CNS) (IEEE CNS 2014), San Francisco, USA, 2014.
[19]Jianjun Yang and Zongming Fei. Broadcasting with prediction and selective forwarding in vehicular networks. In International Journal of Distributed Sensor Networks, 2013.
[20]Yi Wang, Arnab Nandi, and Gagan Agrawal. SAGA: Array Storage as a DB with Support for Structural Aggregations. In Proceedings of SSDBM, June 2014.
[21]Hong Zhang, Fengchong Kong, Lei Ren, and Jian-Yue Jin. An inter-projection interpolation (ipi) approach with geometric model restriction to reduce image dose in cone beam ct (cbct) computational modeling of objects presented in images. In Fundamentals, Methods, and Applications Lecture Notes in Computer Science, volume 8641, pages 12–23, 2014.
[22]Yi Wang, Wei Jiang, and Gagan Agrawal. Scimate: A novel mapreduce-like framework for multiple scientific data formats. In Cluster, Cloud and Grid Computing (CCGrid), 2012 12th IEEE/ACM International Symposium on, pages 443–450. IEEE, 2012.
[23]Hong Zhang, Vitaly Kheyfets, and Ender Finol. Robust infrarenal aortic aneurysm lumen centerline detection for rupture status classication. In Medical Engineering and Physics, volume 35(9), pages 1358–1367, 2013.
[24]Hong Zhang, Lin Yang, David J. Foran, John L. Nosher, and Peter J. Yim. 3d segmentation of the liver using free-form deformation based on boosting and deformation gradients. In IEEE International Symposium on Biomedical Imaging (ISBI), 2009.
[25]Bertalmio M. Sapiro G. Ballester C. and Caselles V. Image inpainting. Proceedings of ACM SIGGRAPH 2000, pages 417–424, 2000.
[26]A. Criminisi P. Prez and K. Toyama. Region filling and object removal by exemplar-based inpainting. IEEE Trans. Image Process, 13(9): 1200–1212, Sep 2004.
[27]M. Ashikhmin. Synthesizing natural textures. Proc. ACM Symposium on Interactive 3D Graphics, pages 217–226, March 2001.
[28]A. Efros and W.T. Freeman. Image quilting for texture synthesis and transfer. Proc. ACM Conf. Comp. Graphics (SIGGRAPH), pages 341–346, August 2001.
[29]A. Efros and T. Leung. Texture synthesis by non-parametric sampling. Proc. Int. Conf. Computer Vision, pages 1033–1038, September 1999.
[30]M. Bertalmio L. Vese G. Sapiro and S. Osher. Simultaneous structure and texture image inpainting. Proc. Conf. Comp. Vision Pattern Rec., 2003.
[31]I. Drori D. Cohen-Or and H. Yeshurun. Fragment-based image completion. ACM Trans. on Graphics, 22(3):303–312, 2003.
[32]J. Jia and C.-K. Tang. Image repairing: Robust image synthesis by adaptive nd tensor voting. Proc. Conf. Comp. Vision Pattern Rec., 2003.
[33]Jian Sun. Lu Yuan. Jiaya Jia. and Heung-Yeung Shum. Image completion with structure propagation. ACM Transactions on Graphics (TOG) - Proceedings of ACM SIGGRAPH, 2005.
[34]Jianjun Yang, Yin Wang, Honggang Wang, Kun Hua, Wei Wang, and Ju Shen. Automatica objects removal for scene completion. IEEE INFOCOM Workshop on Security and Privacy in Big Data, Toronto, Canada, 2014.
[35]Pablo Arbeláez. Michael Maire. Charless Fowlkes and Jitendra Malik. Contour detection and hierarchical image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33:898–916, May 2011.
[36]Lab. d’Anal. Numerique. Univ. Pierre et Marie Curie. Paris. Disocclusion: a variational approach using level lines. IEEE Transactions on Image Processing, 11:68–76, Feb 2002.
[37]Pablo Arbeláez. Boundary extraction in natural images using ultrametric contour maps. Conference on Computer Vision and Pattern Recognition Workshop, 2006. CVPRW ’06, pages 182–190, Jun 2006.
[38]P. W. Lamberti, A. P. Majtey, A. Borras, M. Casas, and A. Plastino. Metric character of the quantum jensen-shannon divergence. Phys. Rev. A, 77:052311, May 2008.
[39]James McCrae and Karan Singh. Sketching piecewise clothoid curves. Computers and Graphics, 33:452–461, Aug 2009.
[40]Mullinex G and Robinson ST. Fairing point sets using curvature. Computer Aided Design, 39:27–34, 2007.
Biographies

Ju Shen is an Assistant Professor from the Department of Computer Science, University of Dayton (UD), Dayton, Ohio, USA. He received his Ph.D. degree from University of Kentucky, Lexington, KY, in USA and his M.Sc degree from University of Birmingham, Birmingham, United Kingdom. His work spans a number of different areas in computer vision, graphics, multimedia, and image processing.

Jianjun Yang Jianjun Yang received his B.S. degree and his first M.S. degree in Computer Science in China, his second M.S. degree in Computer Science during his doctoral study from University of Kentucky, USA in May 2009, and his Ph.D degree in Computer Science from University of Kentucky, USA in 2011. He is currently an Assistant Professor in the Department of Computer Science and Information Systems at the University of North Georgia. His research interest includes wireless networking, computer networks, and image processing.

Sami Taha Abu Sneineh is currently an assistant professor at Palestine Polytechnic University (PPU). He received his Ph.D. degree in May 2013 in Computer Vision at the University of Kentucky (UK) under the supervision of Dr. Brent Seales. Sami earned a B.Sc in Electrical Engineering from Palestine Polytechnic University in 2001 and M.Sc in Computer Science from Maharishi University of Management in 2006. His research focus is on computer vision in minimally invasive surgery to improve the performance assessment. Sami has worked for three years as consultant software engineer at Lexmark Inc. and four years as consultant programmer at IBM before joining UK. He started his teaching experience as TA in the computer science department. He received a certificate and an award in college teaching and learning in 2012. His goal is to contribute in improving the higher education system and raise the education standards.

Bryson Payne received his B.S. degree in Mathematics from North Georgia College & State University, USA in 1997, his M.S. degree Mathematics from North Georgia College & State University, USA in 1999, and his Ph.D degree in computer science from Georgia State University, USA in 2004. He was the (CIO) Chief Information Officer in the North Georgia College & State University (former University of North Georgia). He is currently an Associate Professor in the Department of Computer Science and Information Systems at the University of North Georgia. He is also a CISSP (Certified Information Systems Security Professional). His research interest includes image processing, web application and communications.

Markus Hitz received his B.S. degree and M.S. degree of Computer Science in Europe and his Ph.D degree of Computer Science in USA. He is currently a Professor and Acting Head in the Department of Computer Science and Information Systems at the University of North Georgia. His research interest includes networking, simulation and communications.