Graphic Design of 3D Animation Scenes Based on Deep Learning and Information Security Technology
Jiao Tang
School of Fine Arts & Colored Lantern, Sichuan University of Science & Engineering, Zigong, 634000, China
E-mail: tangjiao@suse.edu.cn
Received 19 July 2023; Accepted 11 August 2023; Publication 11 September 2023
Abstract
This paper aims to use the improved Generative Adversarial Network (GAN) model for Three Dimensional (3D) animation graphic design, improve the efficiency of 3D animation graphic design, and promote the accuracy of model recognition. It acquires 3D animated scene color images from different perspectives. This paper performs 3D visualization through point clouds, outputs high-quality point cloud results, and uses Convolutional Neural Network (CNN), Earth-Mover (EM) distance, and Least Squares Method (LSM) to improve the GAN model. Finally, the effectiveness of the improved GAN in the graphic design of 3D animation scenes and the effects of different improved models in generating 3D animation scene images are analyzed. The results show that the computational loss amplitude of the improved GAN model using Label Smoothing processing deep convolutional neural network is between [2, 3]. The generator loss variation is smaller, and the image quality of the generated 3D animation scene is gradually improved. The training process of the LSM-improved model is more stable, and the loss value is lower than that of the EM distance improved model. The loss value of the generator is [0.3,0.5], and the loss value of the discriminator is [0.1,0.2]. The Inception score of the LSM-improved model is 0.0297 higher than that of the CNN-improved model and the EM distance improved model and 0.0198 higher than that of the GAN model.
Keywords: Generative adversarial network models, 3D animated scene images, graphic design, point cloud visualization.
1 Introduction
Three Dimensional (3D) animation scene design, as a key element in digital entertainment, gaming, and advertising (Yu and Ma, 2022), has attracted widespread attention and research in recent years. However, in the pursuit of efficient and high-quality design processes, there are still many challenges (Xu, 2023). To overcome these challenges, integrating Deep Learning (DL) technology with information security technology has become a key direction for achieving innovative progress. DL technology has achieved tremendous success in multiple fields due to its powerful feature extraction and pattern recognition capabilities. Especially in image processing, DL models, such as Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs) have demonstrated excellent image generation and transformation capabilities (Abdou, 2022; Suganyadevi et al., 2022). This brings new opportunities for the design of 3D animation scenes. Through DL models, the features and details of the scene can be learned from a large amount of data, resulting in more realistic, innovative, and high-quality images (Bouguettaya et al., 2022). However, its application in 3D animation scene design still needs to address many challenges despite the enormous potential of DL technology, including training stability, image quality, and data security (Dinh and Ogiela, 2022). Meanwhile, the importance of information security technology in the digital field cannot be ignored. Especially in digital entertainment, ensuring intellectual property rights and data security of images is crucial (Güler and Savaş, 2022). In the design of 3D animation scenes, it is necessary to focus on the generation of images and consider how to protect these generated images from the threat of malicious theft, tampering, and infringement. Therefore, integrating information security technology into 3D animation graphic design can not only improve the security of generated images but also provide more reliable guarantees for the digital entertainment industry.
Regarding applying DL algorithms in animation graphic design, Wang adopted the method of computer-assisted virtual reality to conduct in-depth research and analysis on graphic design in 3D animation scenes. The study treated each frame of a 3D animated character image as a digital sculpture scene and realized that 3D character animation solved problems like digital sculpture software weighting (Wang, 2021). Xu proposed a film and television animation design method using 3D visual communication technology and used DL to extract depth features. The multi-frame animation and animated video images were reconstructed based on visual communication. This research could achieve the high-precision reconstruction of video images in a short time (Xu, 2023). Ferstl et al. used DL methods to automatically generate natural speech animations synchronized with the input speech. They used a sliding window predictor to learn the arbitrary nonlinear mapping from phoneme tag input sequences to lip shapes, thereby accurately capturing natural motion and visual co-pronunciation effects (Ferstl et al., 2021). Purwins et al. constructed a network model of artistic graphic design using different types of DL algorithms (Purwins et al., 2019). The study found that the Long Short-Term Memory (LSTM) structure based on the attention mechanism was superior to other depth methods in art graphic design. The accuracy rate of the model and the quantitative evaluation of the art graphic design model remained above 90%. Regarding the research on information security technology in the design of 3D animation scenes, Wang applied digital watermarking technology to protect the intellectual property rights of 3D models. These digital watermarks could be embedded into 3D models to identify and track the source of the model to protect the rights of designers and prevent theft and infringement (Wang, 2023). Erdem et al. applied the design, manufacturing, and implementation of beam control for a 3D printed lens scanner used in visible light communication applications and implemented information security measures during the design and manufacturing process to prevent unauthorized model replication and tampering (Erdem et al., 2022). Bora et al. proposed that the biometric 3D animation algorithm is a new method based on facial detection AI algorithm. The algorithm created strings with randomly selected handwritten 3D animated characters, making Completely Automated Public Turing test to tell Computers and Human Apart simple. Humans could recognize, but it was difficult for robots to recognize (Bora and Jain, 2023). Somaiya et al. proposed a hybrid encryption algorithm for sharing multimedia files to create traceable design records and protect image property rights (Somaiya et al., 2023).
In summary, previous studies have shown significant progress in the application of DL methods in animation graphic design, such as using computer-aided virtual reality for high-quality graphic design and using 3D visual propagation technology for high-precision reconstruction of video images. However, these studies still have limitations in stability, detail accuracy, and other aspects. Additionally, the application of information security technology in 3D animation design has also become a focus of attention, and methods, such as digital watermarking and encryption, can help protect intellectual property and design security. However, these methods also need to be further improved. This paper aims to fill these research gaps and improve the efficiency, quality, and security of 3D animation scene design by combining DL and information security technologies. Most importantly, traditional graphic design has certain shortcomings in terms of accuracy. The method of extracting image width or extracting interference information from raw graphic data was used in the past to carry out 3D spatial plane design. These interfering information and unstructured factors are used to achieve label mapping linkage. However, this method often requires a large amount of manual processing of raw data, resulting in a significant workload. Therefore, this paper aims to fill these research gaps and improve the efficiency, quality, and security of 3D animation scene design by combining DL and information security technologies.
This paper aims to improve the design efficiency and accuracy of model recognition using an improved GAN model for 3D animation graphics design. The stability problem in the training process of GAN model is solved, and the quality of generated images is improved using different improvement methods, such as Least Squares Method (LSM). In the research design, an improved GAN model is chosen, and LSM is used to process deep CNNs to improve the stability of the model and image quality. From different perspectives, color images of 3D animation scenes are obtained and visualized through point clouds to provide high-quality point cloud output results for model training. Finally, the model training loss value and Inception score are used to evaluate the quality of images generated by different models. The research results show that the improved model processed using LSM exhibits better stability and quality in generating 3D animated scene images. The Inception score of the LSM-improved model is higher than other models, verifying the effectiveness of the improved method. This paper has made important innovative contributions in 3D animation and information security. Firstly, in 3D animation, the efficiency and quality of animation graphic design have been successfully improved by the improved GAN models. The stability of model training is improved by introducing the Label Smoothing (LS) processing method during the training process. In addition, the LSM-improved model further improves the quality of generated images, making the generated 3D animation scene images closer to the real scene. These innovative contributions have effectively promoted the advancement of the 3D animation field and provided strong support for designers to create better works. Secondly, this paper brings innovation to information security. The intellectual property rights and transmission security of design works are protected by applying information security technologies, such as digital watermarking and encryption methods. This innovative contribution has significant significance in preventing theft, infringement, and tampering, ensuring the integrity and authenticity of design works and providing powerful tools and methods for information security.
2 Theoretical Basis of 3D Animation Graphic Scene Design
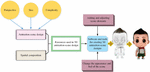
Scene design is a form of artistic expression, but only if it provides services for film and television animation rather than simple painting and art creation. The scene design should be organically combined according to the character positioning of the animation and the development needs of the plot to reflect its artistic value. In the current film and television animation production process, there is a phenomenon of playing on the spot in the scene design, reaching the extent that the scene changes too much. The connection between the upper and lower content of the animation scene is not handled well, which affects the playback effect of the animation. The real thing is simulated through the 3D software. Then, the internal structure of the product, working principle, and other processes are clearly displayed. Today, 3D technology is mainly used in healthcare, industry, machinery, TV packaging, film and television, and other industries. 3D animation scene design can provide exquisite space and rich visual effects for videos, games, and short films. The design steps of the 3D animation scene are shown in Figure 1.
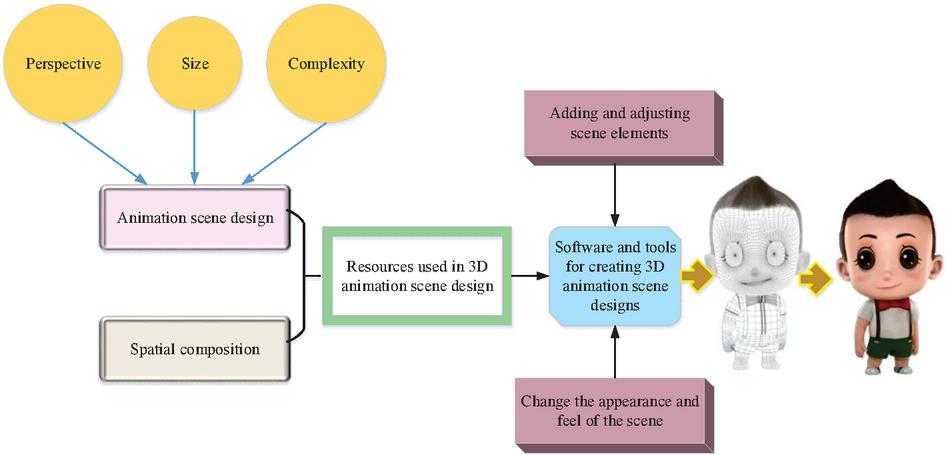
Figure 1 Design steps for a 3D animated scene.
As Figure 1 shows, it is necessary to define the design scene and its spatial composition to create a 3D animated scene. Designers need to determine the perspective, size, complexity, and spatial structure and elements of the scene. Next, it is crucial to identify a library, including the source used to create the 3D animated scene design, including textures, models, and materials. Finally, 3D animation scene design software and tools are identified, such as Unity, Maya, and professional scene design software, such as 3ds Max and Cinema Four-Dimensional. In creating a 3D animated scene design, designers can add and adjust scene elements according to the spatial structure of the scene. They can also use the collected resource library to create and change the look and feel of the scene so that the visual effect of the scene is animated. 3D scene animation design can create stunning 3D worlds and active avatars. Making 3D scene animation videos can meet various creative ideas. It requires the necessary tools, such as a 3D model editor, visual effects editor, and an image processing program to add special effects such as lights, shadows, and smoke to make the design scene realistic. In addition, beautiful 3D scenes can be created, including vegetation, stones, and buildings. Finally, some active avatars can be added to make the animated scene exciting (Patete and Marquez, 2022; Sh and Abdumonnonov, 2023). Figure 2 displays the steps to set up a scene in 3D animation.
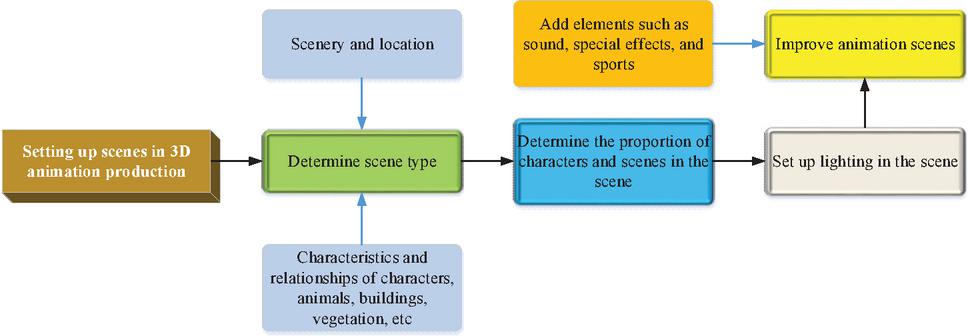
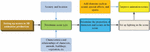
Figure 2 Steps to set up a scene in 3D animation.
From Figure 2, the first step in creating a 3D animated scene is to prepare a well-designed scene. The type of scene, the objects, and where they appear in the scene are determined. In addition, the characteristics of characters, animals, buildings, and vegetation and their relationships in the scene must be considered. Besides, the proportions of the characters and scenes in the scene should be determined. The character’s size is defined based on the scene’s size. After determining the ratio of the character to the scene, the character’s actions are set. For lighting settings in a scene, the type and number of light sources and the location of the light sources are determined based on the time, location, and environment of the scene. Good lighting can bring realistic shadows to the characters and increase the visual effect. Finally, add some details to the scene to improve the animation. Elements such as sound, effects, and motion can be added to enhance the visual experience of animation (Singh et al., 2020; Chattopadhyay et al., 2020).
3 Method
3.1 3D Data Acquisition of 3D Animation Scenes
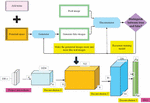
The process of acquiring 3D data for 3D animation scenes is complex. While two-dimensional cameras are cheap and ubiquitous, 3D perception often requires specialized hardware equipment. The method of obtaining 3D data for 3D animation scenes is shown in Figure 3.
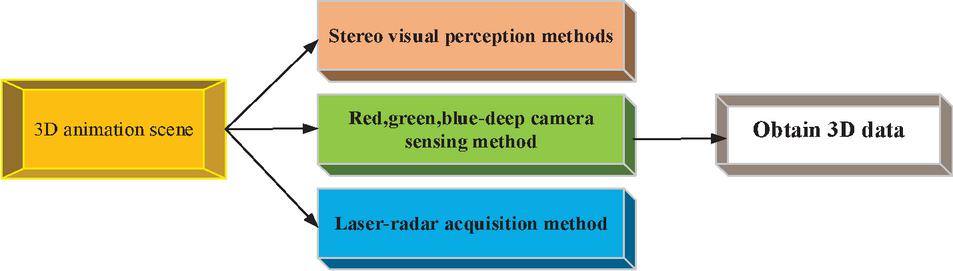
Figure 3 3D data acquisition method for 3D animation scenes.
In Figure 3, the 3D data obtained by 3D animation scenes include the stereoscopic visual perception method, Red, Green, Blue-Deep (RGBD) camera perception method, and Laser-Radar (LiDAR) acquisition method. In the construction of DL 3D animation scene graphic design, the 3D data of the 3D animation scene is obtained, and the 3D data is processed into the input of the image in the form of a point cloud. A point cloud is a collection of points in 3D space. A specific three-dimensional coordinate location determines each point, and other properties (color and depth) can be assigned. The 3D data representation of the point cloud is the original form in which the LiDAR data is obtained. Stereo vision systems and RGBD data, including images labeled with depth values for each pixel, are often converted into point clouds before further processing (Kaluarachchi et al., 2021; Faes et al., 2019; Shimada et al., 2021).
Table 1 Advantages and disadvantages of different DL algorithms in image recognition
| DL Method | Advantage | Disadvantages |
| CNN (Rączkowski et al., 2019) | It can conduct local perception and parameter sharing. It has representational learning ability and can perform translation invariant classification of input information based on a hierarchical structure. | Failure to consider differences in time and space dimensions. |
| GAN (Yadav and Jadhav, 2019) | Generate clear sample details | Difficult to optimize. The training process is unstable. |
| LSTM (Maier et al., 2019) | It can capture long-term dependencies in videos and simulate complex dynamics. | Large period, computational complexity, and time-consuming. |
| ImageNet (Elaziz et al., 2020) | It can be directly and effectively applied to various image recognition tasks with good generalization performance. | ImageNet assigns only one label to each image, resulting in a serious lack of expression of image content. |
3.2 Construction of 3D Animation Scene Graphic Design Model Based on DL
The bottom layer of computer vision, image processing, is basically based on signal reconstruction under certain assumptions. This reconstruction is not a 3D structural reconstruction. It refers to the original information that restores the signal, such as denoising. Existing DL models belong to neural networks. Neural networks can automatically extract features and patterns from large amounts of data to enable complex tasks such as image recognition. Image recognition enables computers to understand and analyze the content of images, such as objects, faces, and scenes. A common method for using DL for image recognition is to build a neural network model with images as input and categories or labels as output. Then, the model is trained using many annotated image data to make correct predictions for new images (Fujiyoshi et al., 2019). Table 1 shows the advantages and disadvantages of different DL algorithms in image recognition.
In summary, the GAN is used for image recognition. The purpose of GANs is to generate data that does not exist, similar to giving artificial intelligence imagination. In an image GAN, the generator is responsible for generating fake images. Assuming that the training set is a true image, the discriminator is responsible for distinguishing between real and fake images. In the process of “confrontation,” the generator generates as many false images as possible through continuous training, and the discriminator distinguishes the image’s authenticity as much as possible through continuous recognition. The training process of the generator is as follows. First, a network and a label are given. Then, update the input so that the label corresponding to the output image gradually approaches the given label. The training process of the discriminator is similar to that of a general neural network. In summary, the model generates an image through a “Generator” and enters it into a “Discriminator” along with the real image for recognition. “Discriminator” updates parameters with the loss of “true image and false generated image.” “Generator” updates parameters with the loss of “true generated image” (Sorin et al., 2020; Wang et al., 2019). The structure of the GAN is demonstrated in Figure 4.
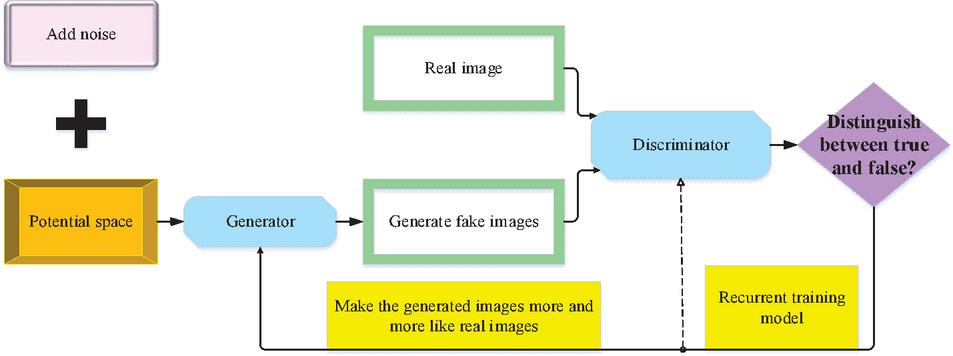
Figure 4 The structure of the GAN.
GAN solves the optimal parameter solution by minimizing the relative entropy between the generated and true distribution. The objective function of the discriminator can be expressed as:
| (1) |
In Equation (1), D represents the discriminator, G represents the generator, z is the input to the generator G, and z is the random noise. and perform logarithmic operations on the discriminant and generated values, respectively. E means expectation. satisfies the random noise of prior probabilities. The objective function of the generator can be expressed as:
| (2) |
The main meaning of Equation (2) is to make the generated value in the generator as small as possible and gradually approximate the real data. Therefore, the GAN training objective function is shown in Equation (3.2).
In Equation (3.2), D represents the discriminator, G represents the generator, and z is the input to the generator G. is a random noise whose z satisfies prior probability. R is the input of discriminator D. is a random noise whose z satisfies prior probability. is the objective function. In this GAN training process, G aims to generate images that are as realistic as possible. The stronger D’s ability, the greater . The solution result of the objective function is shown in Equation (4).
| (4) |
In Equation (4), represents the new discriminator parameter, is the true distribution data, and is the generated distribution data. represents the relative entropy of the discriminator. During the training process of GAN, it is found that GAN has problems such as gradient vanishing, resulting in unstable training. So, Deep Convolutional Neural Networks (DCNNs) are used to improve the structure of GANs (Baowaly et al., 2019; Pan et al., 2019). The improved GAN model is shown in Figure 5.
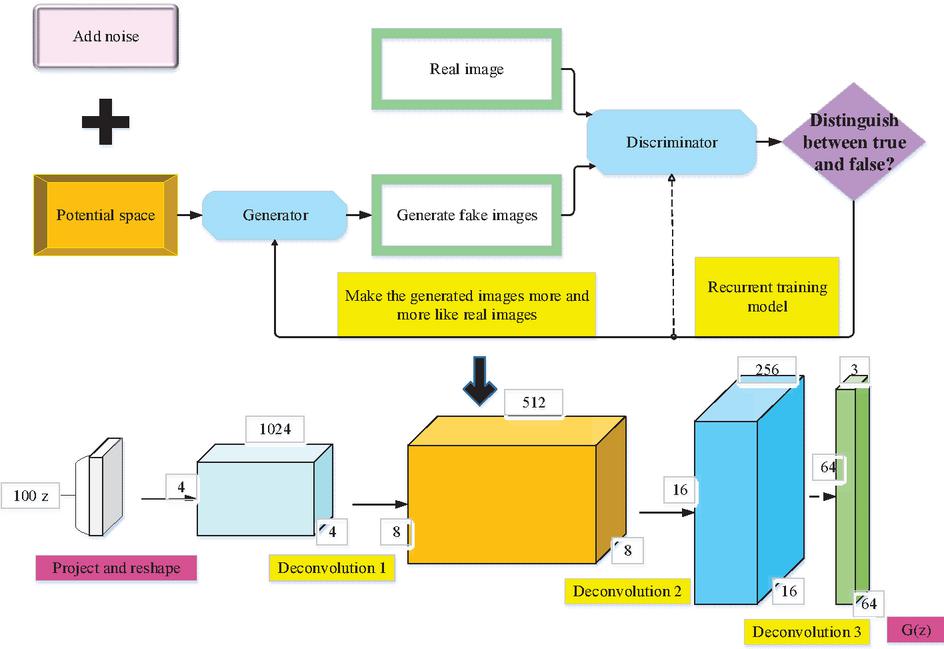
Figure 5 Improved GAN model.
From Figure 5, the improved GAN model does not modify the loss function of the original network structure but only modifies the network structure. Both the model generator and the discriminator abandon the pooling layer of the CNN, while the discriminator retains the overall architecture of the CNN. The generator replaces convolutional layers with deconvolutional layers. Using the Batch Normalization layer in the discriminator and generator can help deal with the training problems caused by poor initialization, speed up model training, and improve training stability. In the generator, the output layer uses the activation function, and all other layers use the Relu activation function. In the discriminator, all layers except the output layer use the LeakyRelu activation function to prevent the gradient from thinning. Finally, the Adam optimizer is used to optimize the training process. To improve GAN models, Earth-Mover (EM) distance can also be used to solve model gradient vanishing (Sandfort et al., 2019). EM distance can be calculated according to Equation (5).
| (5) |
In Equation (5), represents a set of and joint distributions. x represents the real sample, and y represents the generated sample. represents the distance between x and y, and E represents the expected value. is the Wasserstein value of and . The expression for improving the GAN using EM distance is shown in Equation (6).
| (6) |
Equation (6) is the optimal discriminator optimization to minimize the EM distance, satisfying the condition of . In addition to using EM distance improvement models, the Least Squares Method (LSM) can also be used to penalize samples that the discriminator determines as false to improve the quality of sample generation of true values (Johnson and Drangova, 2019). The objective function of the GAN using the LSM is shown in Equations (3.2)–(9).
| (7) | ||
| (8) | ||
| (9) |
In Equations (3.2)–(9), Equations (3.2) and (3.2) are the objective functions of the GAN model discriminator and generator improved by the LSM, respectively. Equation (9) represents the training function of the improved model. a, b, and c represent the LSM generation coefficients, respectively. In training, , , and .
3.3 Experimental System Construction and Model Performance Evaluation
This paper obtains color images of 3D animated scenes from different perspectives to use the improved GAN model for 3D animation graphic design, improve the efficiency of 3D animation graphic design, and promote the accuracy of model recognition. It performs 3D visualization through point clouds, effectively solves the problem of outdoor 3D reconstruction, and provides high-quality point cloud output results. A total of 8,756 3D animation scene images are obtained, and the image resolution is set to 96 96 by image preprocessing, and the pixel values of the images are normalized between [1,1]. The experimental environment configuration and parameter settings are given in Table 2.
Table 2 Experimental environment configuration and parameter settings
| Experimental Environment | |
| Configuration | Explanation |
| Experimental hardware environment | InterCore(TM)i5-7200U CPU@2.50GHz |
| Software environment | Windows 10 |
| Operating system | Ubuntu version 16.04 |
| CPU model | 2080 Ti graphics card |
| Programming language | Python 3.5 |
| Parameter setting | Explanation |
| Adam optimization algorithm | The learning rate is 0.0002, , |
| The slope of LeakyRelu | 0.2 |
| Batch size | 128 |
| Model training time | 10 Hours |
The loss value and the Inception score are used to evaluate the performance of the 3D animation scene graphic design model based on the improved GAN based on CNN (Sobh et al., 2023). The loss value can be obtained according to Equation (10).
| (10) |
In Equation (10), n is the number of training samples, is the true value, and is the predicted value. The Inception score calculation process is shown in Equations (11)–(14).
| (11) | ||
| (12) | ||
| (13) | ||
| (14) |
In Equations (11)–(14), represents the probability that x belongs to class i. is the entropy value of the label vector . N is the number of images, and exp has no specific meaning. is to generate an image from the generator, and is to input the generated image x into Inception to output the vector y. means that each generated image gets a probability distribution vector. relative entropy measures the distance between two probability distributions. It is non-negative. The higher the value, the less similar the two probability distributions are.
4 Results and Discussion
4.1 Improved GAN in 3D Animation Scene Graphic Design Generation Effect Analysis
The DCNN is used to improve the structure of the GAN. Meanwhile, LS is used to process the samples to prevent the model from predicting labels too confidently during training and improve the problem of poor generalization ability. The training loss of the improved GAN model based on DCNN is revealed in Figure 6.
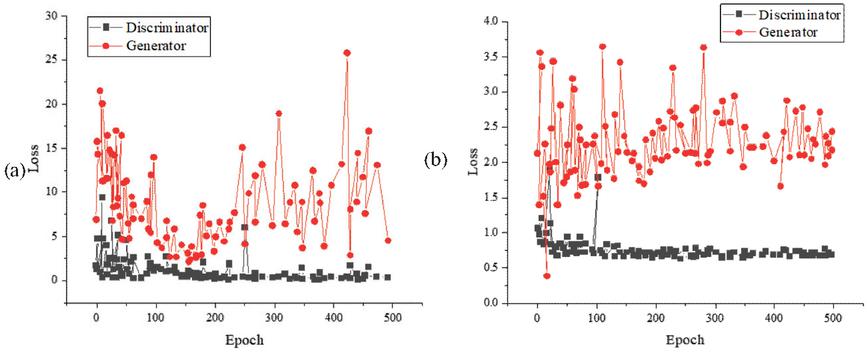
Figure 6 The training loss of the improved GAN model of DCNN ((a) is not using LS processing; (b) is using LS processing).
From Figure 6, when LS processing is not used, the loss value of the improved DCNN GAN model training generator fluctuates greatly with the increase in the number of iterations. The loss value first decreases and then increases. As the number of iterations grows, the loss value of the discriminator gradually decreases and tends to 0. When using LS processing, the loss value of the training generator of the improved GAN model of DCNN changes slightly with the increase in the number of iterations, and the loss value is between [2, 3]. The model training is more stable than Figure (a), indicating that in the GAN model improved by DCNN, the image quality of the 3D animation scene generated by LS processing gradually improves with the increase in the number of iterations. EM distance and LSM are used to improve the GAN model to solve the vanishing GAN gradient. The improved model training results are shown in Figure 7.
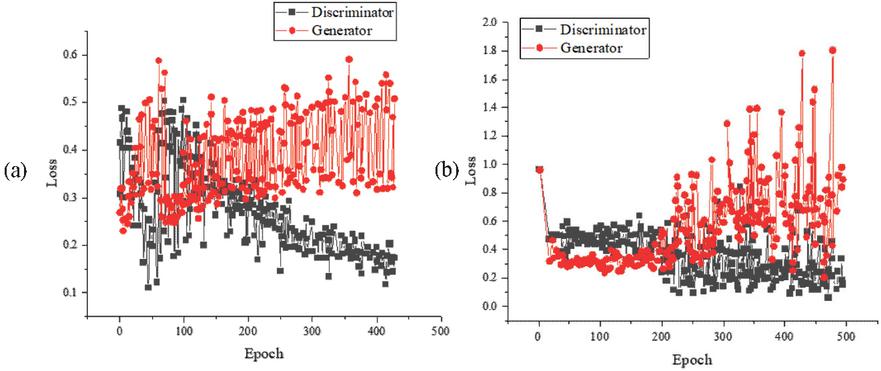
Figure 7 Improved model training result ((a) is the model improved by LSM; (b) is the model improved by EM distance).
From Figure 7, during the model training process, as the number of iterations increases, the loss value of the generator of the model improved by LSM shows a downward trend, and the range of activity is [0.3, 0.5]. The loss value of the discriminator shows a downward trend, and the range of the loss value is [0.1, 0.2]. After using the EM distance improvement model for 250 batches, the loss value of the discriminator shows a downward trend, and the change range is small. The loss value of the generator is constantly increasing, and the change is noticeable. Overall, compared with the EM distance improvement model, the training process of the LSM improvement model is more stable, and the loss value is lower.
4.2 Comparative Analysis of the Effect of Different DL Algorithms in the Graphic Design of 3D Animation Scenes
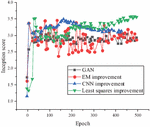
It is necessary to verify the improvement effect of CNN, EM distance, and LSM on GAN and the model’s effectiveness. The comparative analysis of the effects of different DL algorithms in the graphic design of 3D animation scenes is plotted in Figure 8.
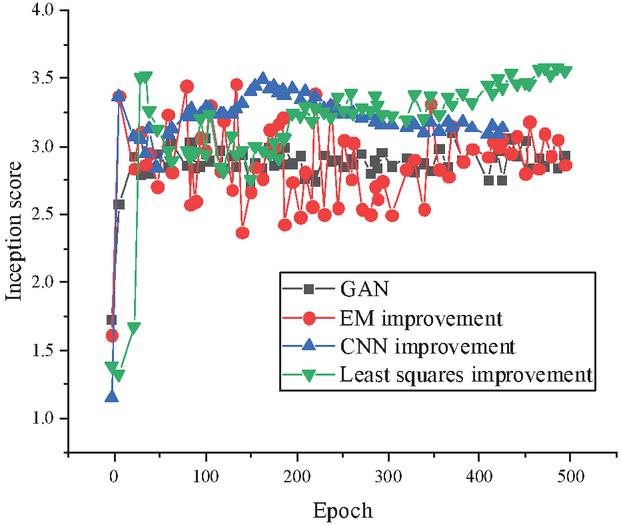
Figure 8 Comparative analysis of the effect of different DL algorithms in 3D animation scene graphic design.
From Figure 8, overall, the LSM-improved model has a higher Inception score than the CNN-improved model than the EM distance-improved model than the GAN. The EM distance improvement model is closest to the image effect of the 3D animation scene generated by the GAN model. CNN-improved model to generate images of 3D animated scenes better than GAN models.
4.3 Discussion
This paper studies the application of GAN model in 3D animation graphic design. Especially, the stability of the generator and discriminator is improved to promote image quality by introducing improved methods, such as LSM. Although the improved methods have improved the stability of training and the quality of results to some extent, they cannot fully solve the difficulties in GAN training, such as the problem of structure and gradient vanishing. This is consistent with the research results of Wang et al. Wang et al. accurately estimated depth images in U-Net using an effective new loss function combining Structural Similarity Index and Laplace operator. Their research demonstrated that U-Net performed better in depth image estimation tasks, and the proposed loss function improved the overall and detailed accuracy of the results (Wang et al., 2021). They improved the accuracy of the U-Net model in depth image estimation through a new loss function and emphasized the challenges in training DL models. Meanwhile, Yoo et al. proposed a DL-based Computer-Aided Design (CAD)/Computer-Aided Engineering framework. This framework automatically generated 3D CAD designs and evaluated their engineering performance, indicating that artificial intelligence could be applied in end-use product design (Yoo et al., 2021). Yoo et al.’s research is consistent with the research goal of this paper, which is to achieve the 3D animation graphic design through an improved GAN model, thereby providing better graphic effects and visualization for actual product design. Moreover, Li et al. proposed an image feature extraction model based on convolution operation. It was found that better dynamic line graphics were obtained after a certain level of smoothing, which could accurately convey the image features of traditional carving graphics and provide users with a good visual experience (Li and Tang, 2022). Both Li et al.’s research and this paper have improved the GAN model to generate high-quality 3D animated scene images to promote the quality and effectiveness of graphic design. Finally, Ding et al. constructed a product color design scheme generation model based on the product color emotional image dataset and conditional deep convolutional generation adversarial network and verified the effectiveness and applicability of the proposed method (Ding et al., 2023). This also reminds people that in future research, the application of conditional GAN in 3D animation graphic design can be further explored to improve the diversity and fidelity of generated results. In summary, this paper has achieved certain results, improving the efficiency and image quality of 3D animation graphic design through the improved GAN model.
5 Conclusion
This paper aims to improve the efficiency of 3D animation graphic design and the accuracy of model recognition using an improved GAN model. When exploring the effectiveness of different improvement methods, the following important results are found: (1) The loss value of the generator slightly changes with the increase of iteration times when the LS processing deep CNNs are used to improve the GAN models. The loss value is between [2, 3], and the model training is more stable compared to not using LS processing. (2) When different improved models are compared, the training process of the LSM-improved model is more stable, and the loss value is lower, which helps to improve the quality of generated images. (3) Regarding 3D animated scene image generation, the Inception score of the LSM-improved model is 0.0297 higher than that of the CNN-improved model and the EM distance improved model and 0.0198 higher than that of the GAN model. In the context of information security, the above research findings are of great significance. Firstly, stable model training can reduce the risk of malicious attacks, as the training process is less susceptible to interference or damage. Secondly, the integrity and authenticity of images can be protected during information transmission and sharing to prevent malicious tampering or the spread of false information by improving the quality and accuracy of generated images. Finally, using the LSM to improve the model’s Inception score further enhances the credibility and quality of the generated images, helping to ensure the reliability and availability of the generated 3D animation scene images in information security. In summary, the research results provide useful guidance and support for the application of information security technology in 3D animation graphic design.
For 3D animation designers, the specific application of the improved GAN model proposed here can significantly improve the efficiency and quality of animation graphic design by adopting the improved GAN model. This method can generate more realistic and high-quality 3D animation scene images, providing support for designers to create works with more visual impact and artistic sense. In addition, designers can more easily implement their creative ideas without worrying about model training issues by reducing the instability during the training process. In information security, the application of this method can also have a positive impact. Firstly, designers can ensure that the copyright and source of their works are not infringed upon by protecting intellectual property rights, such as embedding digital watermarks into 3D models. This is of great significance in preventing theft and infringement, thus safeguarding the rights and interests of designers. Secondly, using information security technologies, such as encryption methods, can ensure security during the sharing and transmission of design works. This helps to prevent malicious tampering and improper use, ensuring the integrity and credibility of the work.
The improvement of GAN model can only alleviate the training problem to a certain extent. In particular, there are still challenges to the structure and gradient vanishing. Given this deficiency, future research can attempt to design more effective improvement algorithms that specifically address issues, such as structure and gradient vanishing. Data augmentation techniques can also be utilized to generate more training data to increase the model’s generalization ability. In addition, an incremental training strategy can be considered to gradually introduce new training data and improved methods to improve model performance.
Moral Statement
This paper strictly follows ethical standards and laws and regulations, and the application of DL technology involved in the research will not infringe on personal privacy, intellectual property rights, and data security. In data collection and use, appropriate privacy protection measures have been taken to ensure the legitimate access and use of personal data. In terms of information security, encryption technology is adopted to ensure the security of the transmission and sharing process of design works. This paper aims to provide a safe and sustainable environment for the development and application of technology.
References
Abdou, M. A. (2022). Literature review: Efficient deep neural networks techniques for medical image analysis. Neural Computing and Applications, 34(8), 5791–5812.
Baowaly, M. K., Lin, C. C., Liu, C. L., and Chen, K. T. (2019). Synthesizing electronic health records using improved generative adversarial networks. Journal of the American Medical Informatics Association, 26(3), 228–241.
Bora, N. P., and Jain, D. C. (2023). A Web Authentication Biometric 3D Animated CAPTCHA System Using Artificial Intelligence and Machine Learning Approach. Journal of Artificial Intelligence and Technology, 3(3), 126–133.
Bouguettaya, A., Zarzour, H., Kechida, A., and Taberkit, A. M. (2022). Deep learning techniques to classify agricultural crops through UAV imagery: A review. Neural Computing and Applications, 34(12), 9511–9536.
Chattopadhyay, A., Nabizadeh, E., and Hassanzadeh, P. (2020). Analog forecasting of extreme-causing weather patterns using deep learning. Journal of Advances in Modeling Earth Systems, 12(2), e2019MS001958.
Ding, M., Yuan, Y., Zhang, X., and Sun, M. (2023). Product color emotional design based on deep learning. Computer Integrated Manufacturing System, 29(5), 1647.
Dinh, N., and Ogiela, L. (2022). Human-artificial intelligence approaches for secure analysis in CAPTCHA codes. EURASIP Journal on Information Security, 2022(1), 8.
Elaziz, M. A., Hosny, K. M., Salah, A., Darwish, M. M., Lu, S., and Sahlol, A. T. (2020). New machine learning method for image-based diagnosis of COVID-19. Plos one, 15(6), e0235187.
Erdem, M. C., Gürcüoğlu, O., Panayirci, E., Kurt, G. K., and Ferhanoğlu, O. (2022). 3D-printed actuator-based beam-steering approach for improved physical layer security in visible light communication. Applied Optics, 61(18), 5375–5380.
Faes, L., Wagner, S. K., Fu, D. J., Liu, X., Korot, E., Ledsam, J. R., … and Keane, P. A. (2019). Automated deep learning design for medical image classification by health-care professionals with no coding experience: a feasibility study. The Lancet Digital Health, 1(5), e232–e242.
Ferstl, Y., Neff, M., and McDonnell, R. (2021). ExpressGesture: Expressive gesture generation from speech through database matching. Computer Animation and Virtual Worlds, 32(3–4), e2016.
Fujiyoshi, H., Hirakawa, T., and Yamashita, T. (2019). Deep learning-based image recognition for autonomous driving. IATSS research, 43(4), 244–252.
Güler, O., and Savaş, S. (2022). Stereoscopic 3D teaching material usability analysis for interactive boards. Computer Animation and Virtual Worlds, 33(2), e2041.
Johnson, P. M., and Drangova, M. (2019). Conditional generative adversarial network for 3D rigid-body motion correction in MRI. Magnetic resonance in medicine, 82(3), 901–910.
Kaluarachchi, T., Reis, A., and Nanayakkara, S. (2021). A review of recent deep learning approaches in human-centered machine learning. Sensors, 21(7), 2514.
Li, Y., and Tang, Y. (2022). Design on intelligent feature graphics based on convolution operation. Mathematics, 10(3), 384.
Maier, A., Syben, C., Lasser, T., and Riess, C. (2019). A gentle introduction to deep learning in medical image processing. Zeitschrift für Medizinische Physik, 29(2), 86–101.
Pan, X., Yang, F., Gao, L., Chen, Z., Zhang, B., Fan, H., and Ren, J. (2019). Building extraction from high-resolution aerial imagery using a generative adversarial network with spatial and channel attention mechanisms. Remote Sensing, 11(8), 917.
Patete, A., and Marquez, R. (2022). Computer animation education online: a tool to teach control systems engineering throughout the Covid-19 pandemic. Education Sciences, 12(4), 253.
Purwins, H., Li, B., Virtanen, T., Schlüter, J., Chang, S. Y., and Sainath, T. (2019). Deep learning for audio signal processing. IEEE Journal of Selected Topics in Signal Processing, 13(2), 206–219.
Rączkowski, Ł., Możejko, M., Zambonelli, J., and Szczurek, E. (2019). ARA: accurate, reliable and active histopathological image classification framework with Bayesian deep learning. Scientific reports, 9(1), 14347.
Sandfort, V., Yan, K., Pickhardt, P. J., and Summers, R. M. (2019). Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Scientific reports, 9(1), 16884.
Sh, S. O., and Abdumonnonov, M. (2023). Problems of Creating Two and Three-Dimensional Drawings in the Programs of the Discipline “Computer Graphics” Intended for Teaching the Discipline “Drawing Geometry and Engineering Graphics” in the Direction of Construction and Vocational Education. Journal of Intellectual Property and Human Rights, 2(3), 27–30.
Shimada, S., Golyanik, V., Xu, W., Pérez, P., and Theobalt, C. (2021). Neural monocular 3d human motion capture with physical awareness. ACM Transactions on Graphics (ToG), 40(4), 1–15.
Singh, S. P., Wang, L., Gupta, S., Goli, H., Padmanabhan, P., and Gulyás, B. (2020). 3D deep learning on medical images: a review. Sensors, 20(18), 5097.
Sobh, A., Mosa, D. M., Khaled, N., Korkor, M. S., Noureldin, M. A., Eita, A. M., … and El-Bayoumi, M. A. (2023). How multisystem inflammatory syndrome in children discriminated from Kawasaki disease: A differentiating score based on an inception cohort study. Clinical Rheumatology, 42(4), 1151–1161.
Somaiya, R., Gonsai, A., and Tanna, R. (2023). Implementation and evaluation of EMAES–A hybrid encryption algorithm for sharing multimedia files with more security and speed. International journal of electrical and computer engineering systems, 14(4), 401–409.
Sorin, V., Barash, Y., Konen, E., and Klang, E. (2020). Creating artificial images for radiology applications using generative adversarial networks (GANs) – a systematic review. Academic radiology, 27(8), 1175–1185.
Suganyadevi, S., Seethalakshmi, V., and Balasamy, K. (2022). A review on deep learning in medical image analysis. International Journal of Multimedia Information Retrieval, 11(1), 19–38.
Wang, C. (2023). Exhaustive study on post effect processing of 3D image based on nonlinear digital watermarking algorithm. Nonlinear Engineering, 12(1), 20220288.
Wang, F., Wang, C., and Guan, Q. (2021). Single-shot fringe projection profilometry based on deep learning and computer graphics. Optics Express, 29(6), 8024–8040.
Wang, J., Yang, Z., Zhang, J., Zhang, Q., and Chien, W. T. K. (2019). AdaBalGAN: An improved generative adversarial network with imbalanced learning for wafer defective pattern recognition. IEEE Transactions on Semiconductor Manufacturing, 32(3), 310–319.
Wang, R. (2021). Computer-aided interaction of visual communication technology and art in new media scenes. Computer-Aided Design and Applications, 19(S3), 75–84.
Xu, C. (2023). Immersive animation scene design in animation language under virtual reality. SN Applied Sciences, 5(1), 42.
Yadav, S. S., and Jadhav, S. M. (2019). Deep convolutional neural network based medical image classification for disease diagnosis. Journal of Big data, 6(1), 1–18.
Yoo, S., Lee, S., Kim, S., Hwang, K. H., Park, J. H., and Kang, N. (2021). Integrating deep learning into CAD/CAE system: generative design and evaluation of 3D conceptual wheel. Structural and Multidisciplinary Optimization, 64(4), 2725–2747.
Yu, G., and Ma, C. (2022). Analysis of Scene Design in 3D Animation from the Perspective of Digital Media Art Design Psychology. Psychiatria Danubina, 34(suppl 1), 187–188.
Biography

Jiao Tang was born in Langzhong, Sichuan. P.R. China, in 1991. She received his PhD in formative arts from Mokwon University in Korea. Now, she works in School of Fine Arts & Colored Lantern, Sichuan University of Science&Engineering, His research interests include Visual Communication Design, Coloured-Lantern Art, Digital Art.
Journal of ICT Standardization, Vol. 11_3, 307–328.
doi: 10.13052/jicts2245-800X.1131
© 2023 River Publishers