Prediction and Guidance of Negative Public Opinion Dissemination Based on a Sentiment Classification Algorithm
Jianbao Zhang1,* and Zhengang Li2
1School of Marxism, Beijing Wuzi University, Beijing 101149, China
2Institute of Sociology, Chinese Academy of Social Sciences, Beijing 100005, China
E-mail: zhangjbjb@hotmail.com
*Corresponding Author
Received 21 April 2025; Accepted 25 September 2025
Abstract
The continuous spread of negative public opinion may have a detrimental impact on the stability of society, requiring timely guidance. This study used the spread of negative public opinion on Weibo as a case. Original Weibo posts related to the “Zhuhai Pedestrian Collision Case” published between 11 November 2024 and 31 November 2024 were crawled. A bidirectional gated recurrent unit (BiGRU) algorithm combined with an attention mechanism called the BiGRU-Att emotion classification algorithm was proposed to classify positive and negative public opinions. The negative public opinions were used to form time series data. A BiGRU-Att-Kalman filtering algorithm was designed to predict the spread of negative public opinions. It was found that the BiGRU-Att algorithm exhibited an F1 value of 0.9248 in sentiment classification, outperforming classification algorithms such as support vector machine. The root-mean-square error and mean absolute error (MAE) values of the BiGRU-Att-Kalman filtering algorithm in the prediction of negative public opinion dissemination were 201.25 and 115.62, respectively, with , outperforming prediction algorithms such as GM (1,1). These results highlight the effectiveness of the proposed methods in sentiment classification and forecasting harmful opinion dissemination, thereby offering valuable insights for opinion management.
Keywords: Sentiment classification, negative public opinion, gated recurrent unit, dissemination prediction.
1 Introduction
Influenced by the rapid development of the Internet, social media platforms such as Douyin, Weibo, and other social media platforms have gradually become important venues for netizens to express their opinions and participate in public opinion discussions [1]. This trend has led to faster and broader dissemination of public opinion, posing challenges for relevant departments in managing public opinion. In particular, the dissemination of negative public opinion in some emergencies may cause panic and anxiety among netizens. If negative public opinions cannot be guided and dealt with in a timely manner, it is not conducive to social stability [2]. In the era of big data, the volume of public opinion data continues to grow. In order to extract valuable information from these data, more and more methods have been applied [3]. Zhao et al. [4] developed an aspect-based sentiment analysis model that extracted terms using association rules and the word2vec algorithm. They compared the classification performance of support vector machine (SVM) and other models, concluding that the convolutional neural network (CNN) model significantly enhanced fine-grained sentiment analysis of public opinion. Cui et al. [5] introduced a novel negative public opinion early warning assessment index. They conducted experiments on the COVID-19 Weibo sentiment dataset and discovered that the method was effective in early warning by analyzing negative public opinion topics. Peng et al. [6] established a system of online public opinion early warning indicators and built a model using the genetic algorithm-back propagation (GA-BPNN) algorithm. They found that the proposed algorithm exhibited higher accuracy than methods like decision trees. Karamouzas et al. [7] proposed an automated monitoring mechanism to track public opinion on Twitter and applied it to the 2016/2020 U.S. Presidential Election tweets dataset. This paper focuses on predicting and managing the spread of negative public opinion on the Weibo platform. A gated recurrent unit (GRU)-based sentiment classification algorithm was developed to identify negative public opinion and forecast its future dissemination. This research aims to provide scientific support for relevant departments in guiding public opinion, understanding netizens’ sentiment changes, preventing the proliferation of negative public opinion, and achieving stable public opinion management.
2 Sentiment Classification Algorithm
In natural language processing (NLP), sentiment classification plays a significant role [8]. Early sentiment classification algorithms identified the emotional tendencies of text based on constructed sentiment dictionaries [9]. With the advancement of machine learning and deep learning, many algorithms have been developed and applied in sentiment classification [10]. This paper took Weibo text data as examples. First, negative public opinions were classified from Weibo text data to provide support for the subsequent negative public opinion dissemination and guidance. A web crawler program collected original Weibo posts related to the “Zhuhai Pedestrian Collision Case” published between 11 November and 31 November 2024. The event description is illustrated in Figure 1. The crawling keyword was specified as “Zhuhai Pedestrian Collision.” The collected data underwent cleaning processes to eliminate symbols, emoticons, topic labels, and other irrelevant information. A total of 8408 valid text data were collected and manually labelled. 5861 positive opinions (1) and 2547 negative opinions (0) were obtained as the experimental dataset. Some examples of the texts are presented in Table 1.

Figure 1 “Zhuhai Pedestrian Collision Case” (left: screenshot from Weibo; right: translation).
| Text | Label |
| (Translation: The murderer must be severely punished! All efforts should be made to treat the injured!) | 1 |
| (Translation: Hope all the wounded can be safe and sound.) | 1 |
| (Translation: It’s so terrifying. Tomorrow and accidents, we don’t know which one will come first.) | 0 |
| (Translation: Seriously, it wouldn’t be an exaggeration to define this matter as a terrorist attack. It was too kind to him that he wasn’t shot dead on the spot!) | 0 |
The recurrent neural network (RNN) has demonstrated strong performance in processing text sequence data [11]. The GRU is an enhanced RNN structure that addresses the issues of excessive parameters and slow convergence encountered by conventional RNN models when handling long sequence data. The GRU is widely used in text processing, data prediction, and other applications [12]. In this study, the GRU is employed as a sentiment classification algorithm. Initially, the Jieba toolkit [13] was utilized for text segmentation. As text data cannot be directly input into the GRU, it was converted into word vectors using the word2vec model [14] before being fed into the GRU for feature extraction. To effectively capture global sequences, a bidirectional GRU (BiGRU) was adopted to integrate information from both the forward and backward sequential information. The structure is outlined in Figure 2.
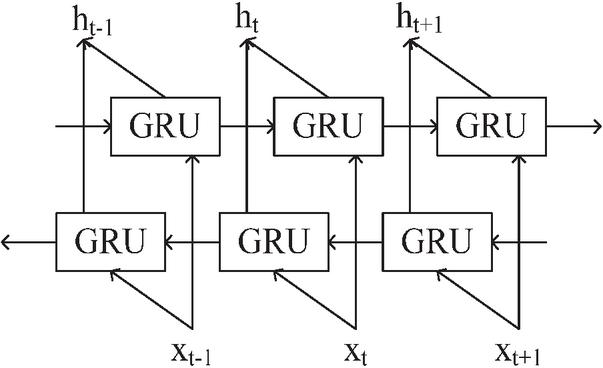
Figure 2 BiGRU structure.
As in Figure 2, the BiGRU consists of a forward GRU and a backward GRU. It is assumed that at time , the input of the forward GRU is and the hidden layer sate is . The output of the update gate is written as:
| (1) |
where is the activation function and is the weight matrix of the update gate.
The output of the reset gate can be written as:
| (2) |
where is the weight matrix of the reset gate.
The candidate state can be written as:
| (3) |
where is the weight matrix of the candidate state.
Eventually, the hidden layer state at time can be written as:
| (4) |
Similarly, the hidden layer state of the backward GRU at time can be obtained. Finally, the hidden layer state of the BiGRU can be written as:
| (5) |
The attention mechanism [15] can assign more weights to the areas that need attention to obtain more details related to the task. In order to improve the sentiment classification ability of the BiGRU further, this paper combined it with the attention mechanism, and firstly calculated the attention weight :
| (6) | |
| (7) |
where is the randomly initialized attention weight. The output of the attention layer is:
Finally, the output of the attention layer was used as the input of the softmax layer, and the softmax classifier was utilized to classify the microblog text’s sentiment. The flow of the designed BiGRU-Att sentiment classification algorithm is shown in Figure 3.

Figure 3 The BiGRU-Att sentiment classification algorithm.
3 Prediction Algorithm for Negative Public Opinion Dissemination
Predicting the spread of negative public opinion involves forecasting the number of Weibo texts identified as negative public opinion during a particular event. A higher count of negative public opinions typically indicates a broader dissemination of negative sentiment. Given that the BiGRU is suitable for predicting time-series data [16], the BiGRU-Att model developed in the preceding section was also utilized. In view of the complexity of the text sequence data, in order to further improve the prediction accuracy the BiGRU-Att model was combined with Kalman filtering (KF) [17] to dynamically adjust the results, and the BiGRU-Att-KF dissemination prediction algorithm was established. The dissemination of negative public opinions was quantified using the total number of negative public opinions within unit time . A training set was established. The input of the BiGRU-Att-KF model is , and the output is . For the output results of the BiGRU-Att model, the process of dynamic adjustment using KF is as follows.
(1) State variable estimation
Based on the estimated number of negative public opinions at time and the control input of the system, the number of negative public opinions at time was estimated:
| (8) |
where is the state transfer matrix from time to and is the conversion coefficient between the control input and state vector.
Then, mean square error matrix at time was used to estimate mean square error matrix at time :
| (9) |
where is the mean square error matrix of the process noise.
(2) State variable correction
Based on the difference between the true value at time and the estimated value, the estimated value at time was corrected to get the final prediction result for the number of negative public opinions:
| (10) | |
| (11) |
where is the Kalman gain matrix, is the true value of the number of negative public opinions at time , and is the product of the estimated state vector and measurement system parameters.
4 Results and Analysis
4.1 Experimental Setup
The experiment was carried out on a system running Windows 10, with an Intel Core i7-12600kf processor and 32 GB memory. It used Python 3.8 as the development language, the PyTorch framework as the platform, and PyCharm as the tool.
The labelled 8408 Weibo text dataset was divided into a training set and a test set according to 8:2, which was used to test the performance of the sentiment classification algorithm BiGRU-Att. The evaluation indicators are as follows.
(1) Accuracy (A)
| (12) |
(2) Precision (P)
| (13) |
(3) Recall rate (R)
| (14) |
(4) F1
| (15) |
In the above equations, is the number of positive public opinions correctly categorized as positive, is the number of negative public opinions correctly categorized as negative, is the number of negative public opinions misclassified as positive, and is the number of positive public opinions misclassified as negative.
The labelled 2547 negative public opinions were sorted according to the times series. The dataset was split into a training set and a test set in an 8:2 ratio. The data was sorted in a rolling order by hour. The number of negative public opinions in four consecutive periods was used as input to predict the number in the fifth period. The evaluation indicators are as follows.
(1) Root mean square error (RMSE)
| (16) |
(2) Mean absolute error (MAE)
| (17) |
(3) Coefficient of determination
| (18) |
In the above equations, refers to the true value and is the predicted value of the BiGRU-Att-KF model.
4.2 Results Analysis
In sentiment classification algorithms, the dimensions of word vectors impact the classification results. The classification accuracy of the BiGRU-Att model under different word vector dimensions is presented in Figure 4.
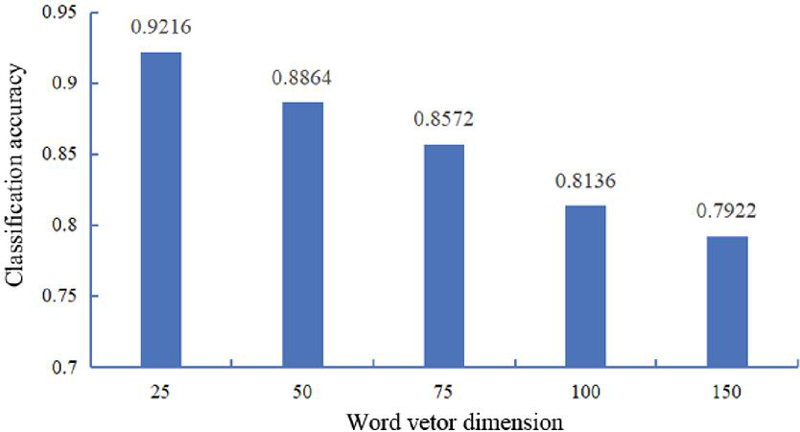
Figure 4 Classification accuracy under different numbers of word vector dimensions.
According to Figure 4, the BiGRU-Att model achieved the highest classification accuracy of 0.9216 when the word vector dimension was set to 25. As the word vector dimension increased, the classification accuracy of the BiGRU-Att model decreased. This result suggested that the algorithm performed optimally when the word vector dimension was set to 25. Therefore, a word vector dimension of 25 was used for all subsequent experiments.
Moreover, the BiGRU-Att model was compared with other classification models.
Table 2 Comparison of sentiment classification performance
| A | P | R | F1 | |
| SVM [18] | 0.7352 | 0.7334 | 0.7216 | 0.7275 |
| BPNN [19] | 0.7764 | 0.7852 | 0.7977 | 0.7914 |
| CNN [20] | 0.8446 | 0.8321 | 0.8233 | 0.8277 |
| BiLSTM [21] | 0.8934 | 0.9012 | 0.8897 | 0.8954 |
| BiGRU | 0.9136 | 0.9177 | 0.9184 | 0.9180 |
| BiGRU-Att | 0.9216 | 0.9252 | 0.9244 | 0.9248 |
Table 2 shows that the SVM algorithm performed poorly in sentiment classification, achieving an F1 value of only 0.7275. The two neural network algorithms, BPNN and CNN, also showed moderate performance with F1 values of 0.7914 and 0.8277, respectively. The BiGRU algorithm demonstrated an improvement in accuracy of 0.0202 and F1 value of 0.0226 compared to the BiLSTM algorithm, highlighting the advantage of the BiGRU over the BiLSTM. Furthermore, after introducing the attention mechanism, the BiGRU-Att algorithm achieved an accuracy of 0.9216 and an F1 value of 0.9248, showing an increase of 0.008 and 0.0068 compared to the BiGRU algorithm. This result demonstrated the enhancement effect of combining the attention mechanism on classification performance, indicating that the BiGRU-Att algorithm can effectively differentiate between positive and negative opinions in Weibo text.
To validate the advantages of the BiGRU-Att-KF model for predicting negative public opinion dissemination, it was compared against other prediction models.
Table 3 Comparison of dissemination prediction performance
| GM (1,1) [22] | 386.45 | 197.51 | 0.84 |
| RNN | 369.84 | 171.22 | 0.89 |
| BiLSTM | 354.58 | 161.25 | 0.93 |
| BiGRU | 336.58 | 142.77 | 0.94 |
| BiGRU-Att | 248.85 | 131.25 | 0.96 |
| BiGRU-Att-KF | 201.25 | 115.62 | 0.98 |
Table 3 shows that the traditional GM(1,1) model was less effective in predicting negative public opinion dissemination, as indicated by high RMSE and MAE values. The prediction errors of the BiLSTM and BiGRU algorithms were lower, and the BiGRU algorithm performed better, showing its good accuracy in prediction. The prediction error of the BiGRU-Att model was further reduced, . The RMSE value of the BiGRU-Att-KF model for predicting negative public opinion dissemination was 201.25, the MAE value was 115.62, and . This result indicated that the BiGRU-Att-KF model can provide an accurate prediction of future negative public opinion dissemination.
Based on the predictions generated by the BiGRU-Att-KF model for the number of negative public opinions, an early warning line can be established. If the relevant departments determine that the early warning line indicates a high level of negative public opinion, they can proactively deploy resources and formulate countermeasures to mitigate negative sentiments among netizens. Then, public opinion was guided according to the early warning line. If the number of negative public opinions in a certain hour is lower than the early warning line, it proves that the number of negative public opinions is within the controllable range. However, if the number exceeds the warning line, immediate action should be taken to guide public opinion in a positive direction and prevent the situation from escalating.
5 Conclusion
This research paper focused on utilizing Weibo text as a dataset and employed the BiGRU-Att algorithm for sentiment classification of positive and negative public opinions. Subsequently, the harmful public opinion dissemination prediction is carried out using the BiGRU-Att-KF algorithm. Experimental results demonstrate that the BiGRU-Att algorithm exhibits strong classification performance, achieving an F1 value of 0.9248. Moreover, the BiGRU-Att-KF model accurately predicts harmful public opinion dissemination with minimal errors. The findings suggest that the BiGRU-Att-KF model can be effectively utilized for pessimistic public opinion prediction, providing a scientific basis for guiding public opinion in practice.
References
[1] D. Zhang, Q. Guo, Z. Ning, L. Zhang, F. Wan, ‘Visual Analysis of Public Opinion Based on Keywords’, 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), pp. 74–78, 2021. DOI: 10.1109/ICPECA51329.2021.9362632.
[2] B. Cai, W. Li, ‘Analysis of microblog public opinion based on big data technology’, IOP Conf. Ser.: Mater. Sci. Eng., vol. 806, pp. 012002, 2020. DOI: 10.1088/1757-899X/806/1/012002.
[3] R. Zhu, Q. Ding, M. Yu, J. Wang, M. Ma. ‘Early Warning Scheme of COVID-19 related Internet Public Opinion based on RVM-L Model’, Sustain. Cities Soc., vol. 74, pp. 1–5, 2021. DOI: 10.1016/j.scs.2021.103141.
[4] Y. Zhao, Y. Li, Y. Liu, Q. Li, ‘Aspect Based Fine-Grained Sentiment Analysis for Public Policy Opinion Mining’, International Symposium on Knowledge and Systems Sciences, vol. 2022, pp. 202–217, 2022. DOI: 10.1007/978-981-19-3610-4_15.
[5] S. Cui, Y. Han, S. Zhu, Y. Li, X. Wu, ‘Research on early warning of negative public opinion based on sentiment topic modeling’, J. Tsinghua Univ. (Sci. Technol.), vol. 64, no. 10, pp. 1771–1784, 2024. DOI: 10.16511/j.cnki.qhdxxb.2024.27.005.
[6] L. J. Peng, X. G. Shao, W. M. Huang, ‘Research on the Early-Warning Model of Network Public Opinion of Major Emergencies’, IEEE Access, vol. 9, pp. 441162–44172, 2021. DOI: 10.1109/ACCESS.2021.3066242.
[7] D. Karamouzas, I. Mademlis, I. Pitas, ‘Public opinion monitoring through collective semantic analysis of tweets’, Soc. Netw. Anal. Min., vol. 12, no. 1, pp. 91, 2022. DOI: 10.1007/s13278-022-00922-8.
[8] Z. Ahanin, M. A. Ismail, T. Herawan, ‘Performance evaluation of multilabel emotion classification using data augmentation techniques’, Malays. J. Comput. Sci., vol. 37, no. 2, pp. 154, 2024. DOI: 10.22452/mjcs.vol37no2.4.
[9] K. Jia, Z. Li, ‘Chinese Micro-Blog Sentiment Classification Based on Emotion Dictionary and Semantic Rules’, International Conference on Computer Information and Big Data Applications, vol. 2020, pp. 309–312, 2020. DOI: 10.1109/CIBDA50819.2020.00076.
[10] C. Yuan, ‘Analysis and Management of Flu Disease Public Opinion Based on Machine Learning’, J. Med. Imag. Health In., vol. 11, no. 7, pp. 1791–1797, 2021. DOI: 10.1166/jmihi.2021.3706.
[11] Z. Mahmood, I. Safder, R. M. A. Nawab, F. Bukhari, R. Nawaz, A. S. Alfakeeh, N. R. Aljohani, S. U. Hassan, ‘Deep sentiments in Roman Urdu text using Recurrent Convolutional Neural Network model’, Inform. Process. Manag., vol. 57, no. 4, pp. 1–14, 2020. DOI: 10.1016/j.ipm.2020.102233.
[12] U. Zaman, J. Khan, E. Lee, S. Hussain, A. S. Balobaid, R. Y. Aburasain, K. Kim, ‘An Efficient Long Short-Term Memory and Gated Recurrent Unit Based Smart Vessel Trajectory Prediction Using Automatic Identification System Data’, Comput. Mater. Con., vol. 81, no. 1, pp. 1789–1808, 2024. DOI: 10.32604/cmc.2024.056222.
[13] C. Tang, C. Shen, J. Zhang, Z. Guo, ‘Identification of Safety Risk Factors in Metro Shield Construction’, Buildings, vol. 14, no. 2, pp. 19, 2024. DOI: 10.3390/buildings14020492.
[14] H. Tang, H. Zhu, H. Wei, H. Zheng, X. Mao, M. Lu, J. Guo, ‘Representation of Semantic Word Embeddings Based on SLDA and Word2vec Model’, Chinese J. Electron., vol. 32, no. 3, pp. 647–654, 2023. DOI: 10.23919/cje.2021.00.113.
[15] H. Wu, D. Tang, Y. Cai, C. Zheng, ‘Research on Early Fault Identification of Cables Based on the Fusion of MTF-GAF and Multi-Head Attention Mechanism Features’, IEEE Access, vol. 12, pp. 81853–81866, 2024. DOI: 10.1109/ACCESS.2024.3401254.
[16] Y. Zhang, G. M. Tumibay, ‘Stock Price Prediction Based on the Bi-GRU-Attention Model’, Journal of Computer and Communications, vol. 12, no. 4, pp. 72–85, 2024. DOI: 10.4236/jcc.2024.124007.
[17] S. Wang, Y. Lei, ‘An unscented Kalman filter under unknown input without direct feedthrough for joint input and system identification of structural systems’, Mech. Syst. Signal Pr., vol. 208, no. Feb., pp. 1–23, 2024. DOI: 10.1016/j.ymssp.2023.110951.
[18] W. R. Salem Jeyaseelan, P. Sudhakaran, V. Rajakani, A. Parameswari, ‘Support Vector Machine Classification using Proximity Authentication and Surveillance System in IoT Industrial Network’, Teh. Vjesn., vol. 31, no. 1, pp. 233, 2024. DOI: 10.17559/TV-20230602000691.
[19] J. Zhao, H. Yan, L. Huang, ‘A joint method of spatial–spectral features and BP neural network for hyperspectral image classification’, Egypt. J. Remote Sens., vol. 26, no. 1, pp. 107–115, 2023. DOI: 10.1016/j.ejrs.2022.12.012.
[20] M. N. Rachmatullah, Sutarno, R. F. Isnanto, ‘Video Anomaly Classification Using Convolutional Neural Network’, Comput. Eng. Appl. J., vol. 13, no. 1, pp. 74, 2024. DOI: 10.18495/comengapp.v13i1.468.
[21] S. Gomathi, K. N. Ram, N. A. B. Mary, ‘Triplet encoded sequence based membrane protein classification using BiLSTM’, Multimed. Tools Appl., vol. 83, no. 36, pp. 84251–84273, 2024. DOI: 10.1007/s11042-024-19010-4.
[22] G. Chen, J. Luo ‘Prediction of Skid Resistance of Steel Slag Asphalt Mixture Based on Grey Residual GM(1,1)-Markov Model’, J. Mater. Civil Eng., vol. 36, no. 1, pp. 4023518.1–4023518.11, 2024. DOI: 10.1061/JMCEE7.MTENG-16280.
Biographies

Jianbao Zhang was born in Jiangsu Province of China in 1982 and graduated from Renmin University as a doctor of philosophy in 2015. He has published more than 20 papers focusing on youth education, which is his lasting interest. He was once awarded the title of “Young Talents of Beijing Universities” and is currently the Vice Professor and Executive Dean of the School of Marxism at Beijing Wuzi University.

Zhengang Li was born in Inner Mongolia Autonomous Region in 1979 and obtained his Ph.D. in sociology from Beijing Normal University in 2016. He is now working in The Institute of Sociology, Chinese Academy of Social Sciences, specializing in social policy research and social big data analysis.
Journal of ICT Standardization, Vol. 13_3, 243–256.
doi: 10.13052/jicts2245-800X.1331
© 2025 River Publishers