Optimal Allocation in Enterprise Human Resource Management through Intelligent Scheduling Algorithms
Yun Wu* and Yong Liu
Teaching Quality Monitoring and Evaluation Center, Shandong Huayu University of Technology, Dezhou, Shandong 253034, China
E-mail: wuyyunw@outlook.com
*Corresponding Author
Received 17 November 2025; Accepted 26 January 2026
Abstract
The paper provides a brief introduction to the mathematical model of project scheduling optimization and the genetic algorithm (GA) used to optimize the human resource allocation scheme. The GA was improved by co-evolution and adaptive genetic parameters. Subsequently, simulation experiments were conducted, and the improved algorithm was also compared with the particle swarm optimization (PSO) algorithm and traditional GA. The results demonstrated that the improved GA converged to stability more quickly during the search for the optimal solution, resulting in a more excellent objective function upon convergence. Overall, the scheme optimized by the improved GA exhibited lower human resource costs and a shorter completion cycle.
Keywords: Intelligent scheduling, human resource management, genetic algorithm, co-evolution.
1 Introduction
In practice, due to the complexity of the internal enterprise structure, the diverse range of employee skills, and the fluctuating nature of market demand, achieving scientific allocation and effective scheduling of human resources has always posed a significant challenge for enterprise managers. Traditional resource allocation methods often rely on the subjective judgment of experienced managers or the formulation of plans based on simple rules [1–3]. Although these approaches may initially meet daily operational needs, they prove inadequate when faced with unexpected events, interdepartmental collaboration, and long-term planning. Intelligent scheduling algorithms are automated decision-making tools that are grounded in mathematical models and computer algorithms. Their goal is to identify the optimal solution through precise data analysis and intricate logical operations [4]. These algorithms can automatically generate optimal or near-optimal personnel allocation strategies by analyzing and processing vast amounts of historical data and real-time information, thereby realizing precise scheduling and dynamic optimization of human resources [5]. The application of such algorithms can not only help reduce labor costs and enhance work efficiency but can also effectively address complex issues, such as unforeseen tasks, employee mobility, and interdepartmental collaboration. Monteiro et al. [6] employed a multi-objective -constraint method to achieve Pareto optimal solutions for daily surgical scheduling. Li et al. [7] developed a mixed-integer programming model for the balanced scheduling of multi-skill human resources and optimized it using an enhanced branch-and-bound method. Additionally, Wu et al. [8] conducted a field study to delineate the fundamental functional requirements of human resource management in universities. They subsequently performed detailed system analysis, design, and implementation according to the object-oriented software engineering development approach. This paper introduces the mathematical model for project scheduling optimization and the genetic algorithm (GA) used to optimize human resource allocation schemes. The algorithm was optimized through co-evolution and adaptive genetic parameters. Moreover, simulation experiments were conducted. The limitation of this paper is that the robustness of the adopted adaptive genetic parameters has not been fully verified. Therefore, the future research direction is to further verify and improve the robustness of the algorithm and supplement the mathematical adjacency matrix representation of the network.
2 Optimization Algorithms for Enterprise Human Resource Allocation
2.1 Project Scheduling Optimization Model
Traditional human resource scheduling heavily relies on the experience of managers, which is effective for short-term, small-scale projects. However, it often falls short in finding the most suitable scheduling solution for long-term, large-scale projects. Intelligent scheduling algorithms use mathematical models and computer optimization algorithms to design the optimal human resources scheduling scheme.
When using intelligent scheduling algorithms to optimize the human resource allocation scheme, a corresponding mathematical model must be established [9]. A large project of human resources scheduling in enterprises can be divided into sub-projects in sequence; these sub-projects can be abstracted as a directed node network graph , where is the collection of sub-projects (nodes), is the collection of relationships between the sub-projects (directed edges), and is the collection of the duration of the sub-projects. In reality, both large project and sub-projects in the implementation process are subject to a variety of factors. If all of these factors are taken into account, this will lead to a very complex mathematical model, increasing the difficulty of optimization. Therefore, in order to reduce the difficulty of calculation, this paper sets certain assumptions in the construction of the project scheduling optimization model: (1) each sub-project has only one completion plan, and the plan requires a fixed type of skills and skill proficiency; (2) each worker can only participate in a sub-project in a period; (3) the proficiency of the skills used by workers during the completion of sub-projects is fixed; (4) workers can not stop the sub-project halfway. The model objective function is:
| (1) |
where is the labor cost, is the completion cycle, is worker ’s proficiency in skill , with a minimum of 0 and a maximum of 1, is the unit salary for skill [10], is the workload of sub-project , is the amount of work that worker completes in sub-project using skill is the number of workers, is the number of sub-projects, denotes the elapsed time required to complete sub-project by a worker whose is 1, and is the collection of sub-projects on the critical path in .
The constraints of the project scheduling optimization model are:
| (2) |
where and are the start times of sub-projects and , is the duration of , denotes the existence of directed edges between and , with in front of , denotes the number of workers with skill participating in sub-project , is the number of workers with skill in the collection of workers, is the number of workers in sub-project , and is the maximum number of workers that can be accommodated in sub-project [11].
2.2 Optimization Algorithm for the Project Scheduling Optimization Model
After the project scheduling optimization model is constructed, the final goal is to minimize and by allocating workers to each sub-project using an optimization algorithm. This paper employs a GA to perform the optimization calculation and introduces adaptive crossover, mutation probability, and co-evolution to enhance it [12]. The steps to improve the GA are as follows.
(1) The multidimensional chromosome coding method is used in the population. An example of this coding method is shown in Table 1. The length of the multidimensional chromosome is , and each sub-project represents a genetic locus. Each locus contains both the sub-project priority dimension and the worker allocation scheme dimension. The sub-project priority is only one-dimensional, and a total of integers from “1” to “” are randomly assigned to each locus of this dimension. When there is a conflict of workforce allocation between sub-projects, the smaller the priority integer of the sub-project locus, the higher priority the human resource arrangement will be [13]. The worker allocation scheme has dimensions; each dimension represents the allocation scheme of a worker in each sub-project genetic locus. When the worker does not have the skills to deal with a certain sub-project, the value of the worker in the sub-project genetic locus is “1”, indicating that the sub-project will not be assigned to the worker. When the worker has the corresponding skills, if a sub-project is assigned to the worker, then the value of the corresponding genetic locus will be “1”; otherwise, it will be “0”. When randomly generating chromosomes, except for the part of the genetic loci whose value is fixed at “1” due to the skill mastered by the worker, chromosomes at the genetic loci in the rest of dimensions are randomly generated according to the above rules, and whether the chromosome scheme meets the restriction conditions is determined. The scheme is regenerated if it does not meet the conditions.
Table 1 Examples of coding
| Sub-project No. | 1 | 2 | … | ||
| Priority | 3 | 5 | … | 2 | |
| Worker allocation scheme | Worker 1 | 1 | 0 | … | 1 |
| Worker 2 | 1 | 0 | … | 1 | |
| … | … | … | … | … | |
| Worker | 0 | … | … | 1 |
(2) Decoding the population chromosome means assigning workers to each sub-project based on the allocation scheme outlined in the chromosome, calculating the fitness of the chromosome, and determining whether the optimization should be terminated. If it is terminated, the optimal allocation scheme within the population is outputted; otherwise, the process proceeds to the next step. The termination criteria can be met when the number of optimization iterations reaches a specified threshold or when the fitness value converges to a stable state, i.e., the difference of the fitness value is smaller than 10-6. The threshold of the number of iterations is set to avoid excessively long optimization time caused by non-convergence due to large fluctuations in the fitness value during the optimization process. Convergence stability means that the difference in the fitness value before and after iteration no longer changes, indicating that the solution represented by the chromosome obtained through optimization almost no longer changes. In this study, the objective function of the project scheduling optimization model is used as the fitness function [14].
(3) The chromosomes in each population are arranged in order of fitness. Then, the optimal chromosome in population 1 is duplicated to replace the worst chromosome in population 2, the optimal chromosome in population 2 is duplicated to replace the worst chromosome in population 3, and the optimal chromosome in population 3 is duplicated to replace the worst chromosome in population 1. This step is the co-evolution operation. Its principle is to split the original population into multiple sub-populations and let each of them iteratively search for the optimal solution independently, so as to expand the search directions. Meanwhile, the excellent chromosomes in each sub-population are used to replace the inferior chromosomes in other sub-populations, enabling the exchange of excellent gene fragments among the independent sub-populations and preventing the independent sub-populations from falling into local optimal solutions.
(4) The selection operation refers to directly replicating the top-performing chromosomes within the population into the offspring chromosomes. In this study, the single-point crossover operation is utilized to swap the values at the same locus of two chromosomes in the population based on the crossover probability, but the value of “1” remains unchanged. The single-point mutation operation means randomly altering the value at a single locus of a chromosome within the population according to the mutation probability, and the value of “1” remains unchanged. In addition, this paper adopts adaptive crossover and mutation probability [15] to improve the performance of optimization:
| (3) |
where and are the crossover and mutation probabilities, respectively, are constants between 0 and 1, is the maximum fitness value within the current population, is the fitness value of the chromosome for crossover and mutation, and is the mean fitness value of the current population.
(5) Return to step (2) after genetic operations.
3 Simulation Experiments
3.1 Experimental Data
In this study, a medium-sized project of a construction company was selected as the simulation subject, and the project process network diagram is shown in Figure 1. The project was segmented into ten sub-projects. Eight workers participated in this project, and three types of skills were necessary for project execution. The unit salaries for skills 1, 2, and 3 were 400 yuan, 300 yuan, and 500 yuan, respectively. Parameters related to the sub-projects within the enterprise project process are detailed in Table 2, while the skill proficiency levels of the workers are outlined in Table 23. The parameters in Table 3 were all from the selected project parameters.
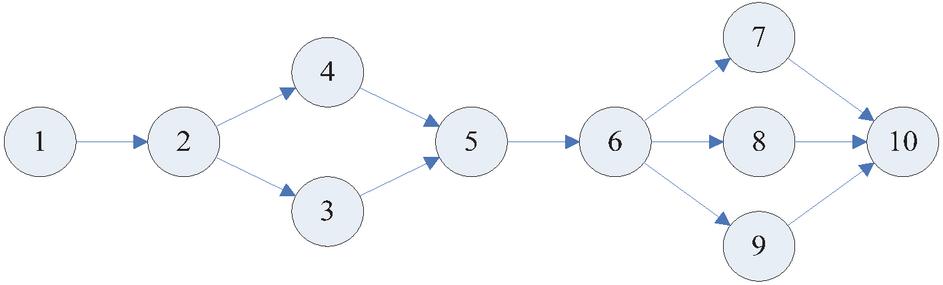
Figure 1 The enterprise project process network diagram.
Table 2 Parameters related to sub-projects within the enterprise project process
| Sub-project | Time Spent | Workload | Maximum Number of | Required Skill |
| No. | on Sub-projects /h | /h | Participants /Person | Type No. |
| 1 | 40 | 30 | 3 | 1 |
| 2 | 80 | 120 | 5 | 3 |
| 3 | 75 | 60 | 6 | 2 |
| 4 | 100 | 80 | 4 | 1 |
| 5 | 95 | 110 | 6 | 1 |
| 6 | 60 | 90 | 5 | 2 |
| 7 | 45 | 60 | 5 | 3 |
| 8 | 80 | 100 | 6 | 2 |
| 9 | 110 | 70 | 3 | 1 |
| 10 | 30 | 40 | 4 | 1 |
Table 3 Worker skill proficiency
| Skill Type No. | 1 | 2 | 3 |
| Worker 1 | 1 | 0 | 0.6 |
| Worker 2 | 0 | 0.8 | 1 |
| Worker 3 | 0.5 | 1 | 0 |
| Worker 4 | 1 | 0.4 | 0 |
| Worker 5 | 0.8 | 0 | 1 |
| Worker 6 | 0.3 | 0 | 1 |
| Worker 7 | 1 | 0.7 | 1 |
| Worker 8 | 0 | 1 | 0.2 |
3.2 Experimental Setup
In the improved GA, there were three populations, each with ten chromosomes. The selection operation within the populations retained the optimal two chromosomes. The probability-related parameters and of the crossover operation were 0.7 and 0.8, respectively. The probability-related parameters and of the mutation operation were 0.1 and 0.2, respectively.
To validate the efficacy of the algorithm, it was compared with other optimization algorithms, namely the traditional GA and particle swarm optimization (PSO) algorithm. The parameters for the traditional GA are as follows. A single population contained 30 chromosomes. The two best chromosomes were retained during selection. The crossover probability was 0.8, and the mutation probability was 0.2. The maximum number of iterations was 100. The relevant parameters for the PSO algorithm included a population containing 30 particles, an inertia weight of 0.6, a learning factor of 0.1, and a maximum iteration limit of 100 cycles.
3.3 Experimental Results
The iteration curves of the three optimization algorithms optimizing the worker allocation scheme are shown in Figure 2. The figure illustrates that, as the number of iterations increased, the objective functions converged gradually to stability in all three optimization algorithms. The improved GA exhibited the fastest convergence, becoming stable after approximately 20 iterations. The traditional GA stabilized after approximately 40 iterations, whereas the PSO algorithm converged at a slower pace, stabilizing after around 60 iterations. When comparing the objective functions of these algorithms after stabilization, it was found that the PSO algorithm had the highest objective function value, followed by the traditional GA, and the improved GA achieved the lowest value.
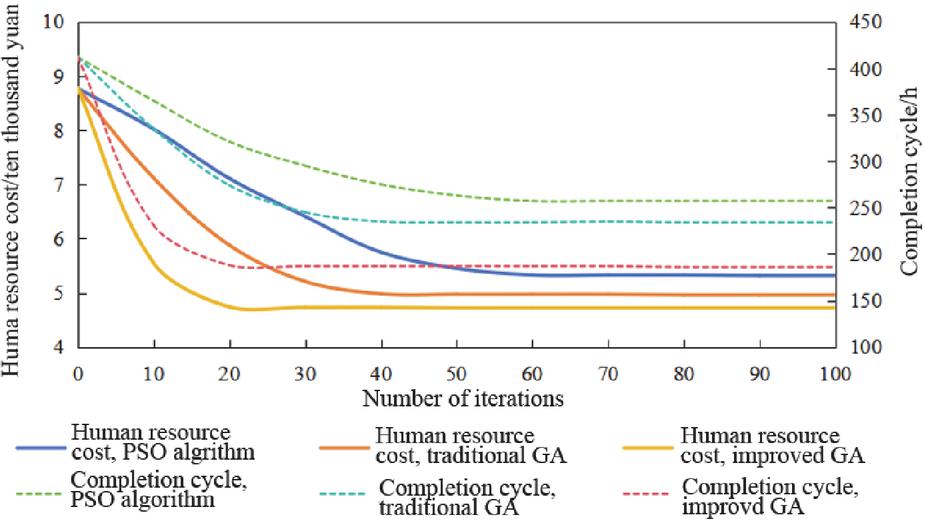
Figure 2 Convergence curves.
Three optimization algorithms were utilized for human resource allocation. The objective of the scheme is to achieve the lowest possible human resource cost and the shortest possible completion cycle, i.e., it is a multi-objective optimization problem. In such a problem, multiple optimization objectives often impose constraints on each other; therefore, they cannot reach the optimal solution simultaneously but can reach more than one relatively optimal solution through mutual compromise. Table 4 presents the optimization outcomes of several schemes under the three optimization algorithms. It is evident that, overall, the allocation scheme optimized by the improved GA exhibited lower human resource costs and shorter completion cycles. Additionally, it was also seen that as the human resource costs gradually increased, the completion cycles reduced, providing decision-makers with the flexibility to select the most suitable allocation scheme based on specific requirements.
Table 4 Selected optimization schemes under the three optimization algorithms
| Scheme | PSO | Traditional | Improved | |
| Project Objective | No. | Algorithm | GA | GA |
| Human resource cost/ten | Scheme 1 | 6.11 | 5.21 | 4.72 |
| thousand yuan | Scheme 2 | 6.15 | 5.13 | 4.63 |
| Scheme 3 | 6.13 | 5.33 | 4.87 | |
| Completion cycle/h | Scheme 1 | 263.9 | 229.3 | 170.3 |
| Scheme 2 | 258.9 | 234.6 | 171.5 | |
| Scheme 3 | 260.7 | 228.4 | 170.2 |
Due to space constraints, only the worker scheduling Gantt chart for scheme 3 generated by the improved GA is presented here, as shown in Figure 3. The figure illustrates that the entire project was segmented into ten sub-projects. Specifically, sub-project 1 required workers 1, 4, and 5; sub-project 2 required workers 1, 2, 5, 6, and 7; sub-project 3 required workers 3, 7, and 8; sub-project 4 required workers 1, 4, 5, and 6; sub-project 5 required workers 1, 4, 5, and 7; sub-project 6 required workers 2, 3, 7, and 8; sub-project 7 required workers 5, 6, and 7; sub-project 8 required workers 2, 3, and 8; sub-project 9 required workers 1 and 4; and sub-project 10 required workers 1, 4, 5, and 7. Sub-projects 3 and 4 were synchronized, and sub-projects 7, 8, and 9 were also synchronized.
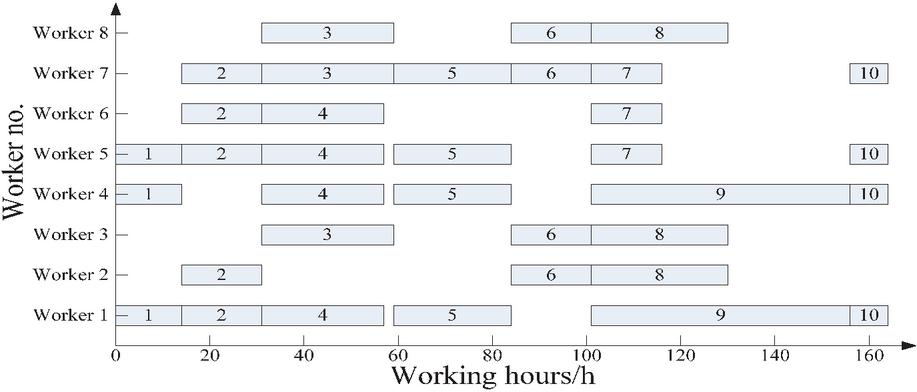
Figure 3 The Gantt chart of worker scheduling in scheme 3 provided by the improved GA.
4 Conclusion
This paper optimized the GA used for improving human resource allocation schemes through co-evolution and adaptive genetic parameters, followed by simulation experiments. Comparisons were made with the PSO algorithm and traditional GA. The improved GA demonstrated the fastest convergence, stabilizing after approximately 20 iterations, followed by the traditional GA at around 40 iterations, and the PSO algorithm displayed the slowest convergence, stabilizing after approximately 60 iterations. The schemes optimized by the improved GA exhibited lower human resource costs and shorter completion cycles. The set of the human resource allocation schemes under multi-objective optimization showed that as the human resource costs increased, the completion cycles gradually reduced, thus decision-makers can select the most suitable scheme based on specific requirements.
References
[1] E. Yağmur, A. Sarucan, ‘Nurse Scheduling with Opposition-Based Parallel Harmony Search Algorithm’, J. Intell. Syst., 28(4), pp. 633–647, 2017.
[2] T. H. Hejazi, A. A. Barzanooni, ‘Joint optimization of cost and reliability indices in complex systems through maintenance scheduling and human resource allocation: A mixed approach of cellular automata and discrete-event simulation’, Reliability Assessment and Optimization of Complex Systems, pp. 65–92, 2025.
[3] Y. Cao, A. Wang, T. Ding, ‘Human resource scheduling technology based on improved genetic algorithm for pulse assembly beat balancing’, Proc. SPIE, 12566, pp. 1–7, 2023.
[4] Z. Sun, Z. Tian, Z. G. Gong, ‘An met a, cognitive based logistics human resource modeling and optimal scheduling’, Eng. Appl. Artif. Intel., 130(Apr.), pp. 107760.1–107760.13, 2024.
[5] L. Ding, ‘An examination of the usefulness of a quantitative appraisal method in nursing human resource management in primary hospital operating rooms: An example of integrated collaborative scheduling’, Medicine, 103(19), pp. 5, 2024.
[6] T. Monteiro, N. Meskens, T. Wang, ‘Surgical scheduling with antagonistic human resource objectives’, Int. J. Prod. Res., 53(24), pp. 1–16, 2015.
[7] T. T. Liao, Z. Xu, M. Li, ‘A Research on Multi-skill Human Resource Leveling-Scheduling Model of Software Development Project’, Ind. Eng. J., 18, pp. 69–74, 2015.
[8] Y. Wu, D. Chen, ‘Design and Implementation of Human Resource Optimal Scheduling System Based on B/S Architecture’, J. Hum. Resour. Sustain. Stud., 12(1), pp. 1–14, 2024.
[9] C. Xi, ‘Research on Human Resource Allocation of Vulnerable Groups in Enterprises Based on a Resource Scheduling Algorithm’, J. Inst. Eng. (India), Ser. C, 104(2), pp. 339–344, 2023.
[10] B. Jiang, Y. J. Ma, L. J. Chen, B. D. Huang, Y. Y. Huang, L. Guan, ‘A Review on Intelligent Scheduling and Optimization for Flexible Job Shop’, Int. J. Control Autom. Syst., 21(10), pp. 3127–3150, 2023.
[11] X. Y. Wen, X. N. Lian, Y. J. Qian, Y. Y. Zhang, H. Q. Wang, H. Li, ‘Dynamic scheduling method for integrated process planning and scheduling problem with machine fault’, Robot. CIM, 77, pp. 1–22, 2022.
[12] W. Xu, H. Y. Sun, A. L. Awaga, Y. Yan, Y. J. Cui, ‘Optimization approaches for solving production scheduling problem: A brief overview and a case study for hybrid flow shop using genetic algorithms’, Adv. Prod. Eng. Manag., 17(1), pp. 45–46, 2022.
[13] L. Lin, M. Gen, ‘Hybrid evolutionary optimisation with learning for production scheduling: state-of-the-art survey on algorithms and applications’, Int. J. Prod. Res., 56(1–2), pp. 193–223, 2018.
[14] L. S. Dias, M. G. Ierapetritou, ‘Data-driven feasibility analysis for the integration of planning and scheduling problems’, Optim. Eng., 20(4), pp. 1029–1066, 2019.
[15] H. Togo, K. Asanuma, T. Nishi, Z. Liu, ‘Machine Learning and Inverse Optimization for Estimation of Weighting Factors in Multi-Objective Production Scheduling Problems’, Appl. Sci.-Basel, 12(19), pp. 9472, 2022.
Biographies

Yun Wu, born in October 1985, is a doctoral student in Al-Farabi Kazakh National University. She is working at Shandong Huayu University of Technology as an associate professor. She is interested in human resource management and project management.

Yong Liu, born in August 1991, is a doctoral student in Al-Farabi Kazakh National University. He is working at Shandong Huayu University of Technology as a lecturer. He is interested in human resource management.
Journal of ICT Standardization, Vol. 14_2, 185–198
doi: 10.13052/jicts2245-800X.1422
© 2026 River Publishers