Human Motion Capture Data Retrieval and Segmentation Technology for Professional Sports Training
Hui Chen
Wuhan Sports Institute, Hubei, 430079, China
E-mail: chen0308.@163.com; hui_chen21@yahoo.com
Received 06 September 2021; Accepted 30 October 2021; Publication 15 November 2022
Abstract
Human motion capturing is frequently used in sports research. The focus of this research is to help the user choose an appropriate motion capture system for their experimental setup for sports activities that addresses the challenges of linear size and acceptable fits with non-linear futures. In this paper, the eigenvalue combination was used to represent different motion postures, so as to construct an index space related to the motion sequence; and according to this index space, fast and accurate motion retrieval was done; at the same time, a motion data segmentation method based on MVU nonlinear dimensionality reduction was proposed. MVU can overcome the shortcomings that the linear size is reduced and difficult to deal with nonlinear features, and can better fit human motion data, and achieve higher accuracy.
Keywords: Professional sports training, human motion capture data retrieval, data retrieval and segmentation technology, capture data.
1 Introduction
Motion capture technology is to obtain the direction and position data of the key movement parts of the object by a special sensing device, then, the motion data is analyzed by computer, and the corresponding motion data is assigned to the 3D virtual model generated by 3D parts, so as to drive the 3D role model to do the corresponding action (Keator, et al., 2008) [1]. Motion capture in sport is used to monitor and record sportsmen human motion in everyday life in order to study their health fitness, sports ability, technical skills, illness cause, preventive, and healing. Sensing movement in the scene, processing the observed data, and recording the processed information are the three main functions (Zhang, et al., 2020; Raju, et al., 2018) [2, 3]. It can be used in the fields of film and television animation, biological gait analysis, industrial design, man-machine engineering, etc. The commonly used motion capture systems can be divided into inertial, optical, acoustic and electromagnetic systems in principle. Motion capture technology has been widely used in the special effects animation in the film and television. The motion capture device can capture the action of the actor accurately, and assign the action data to the 3D role model, this virtual character will act as lifelike as an actor, and improve the efficiency and reality of animation (Chen, et al., 2014) [4]. However, traditional motion capture devices are expensive and difficult to popularize in the low-end industry and education industry. With the more and wider application of motion capture technology, some relatively cheap practical motion capture technology began to appear, such as the IPI optical motion capture based on micro Kinect3D camera technology, inertial motion capture based on motion sensor and so on. The emergence of these technologies makes it possible for motion capture technology to be popularized in professional sports training applications (Hyyppa, et al., 2001) [5]. In recent years, with the development of 3D human motion capture technology and the rapid development of multimedia technology, a large number of visual, realistic, expressive human motion capture data is recorded, saved and effectively applied in the three-dimensional animation, film production and games industry (Ranjan, et al., 2008) [6]. However, a large number of motion capture data also increases the difficulty of effective management and reuse. Therefore, how to accurately and efficiently retrieve the motion database has become an important research target in this field (Ardichvili, et al., 2002) [10].
2 Material and Methods
2.1 MVU Dimensionality Reduction
(1) Primitive dimensionality reduction algorithm. Prior to modelling, dimensionality reduction is a data preprocessing method used on data. Dimensionality reduction aims to reduce the number of dimensions in numerical input data while preserving the information’s key relationships. There are numerous dimensionality reduction various algorithms, and that there is no single ideal solution for all datasets (Qiu et al., 2021) [7]. Maximum variance unfolding (MVU) is a nonlinear dimensionality reduction learning algorithm based on the concept of local isometry, and it can be considered as a special case of KPCA which can automatically learn the training data of the kernel matrix K. Kernel PCA projects the dataset into a higher-dimensional region where it can be linear separated using a kernel function. KPCA is based on the premise that many data which aren’t differentiable in their original space can be rendered continuously separate by projected it onto a high dimension environment (Huifeng, et al., 2020) [8]. A kernel, convolution matrix, or masking is a tiny structure for use in image analysis for blurring, filtering, embossing, edge enhancement, and other tasks. A convolution between the kernels and an images is used to achieve it. A linear technique is PCA. That really is, it can be used on information which can be separated linearly. Kernel PCA projects a dataset into the a higher-dimensional subspace, where it could be linearly separated, using a kernel function. To represent data in lesser dimensions, the traditional PCA typically generates linear principal components. Non-linear principal components are sometimes required. If we use traditional PCA to examine the data beneath, we will be unable to discover a decent represented path. KPCA solves this problem (Huifeng, et al., 2020) [9]. MVU is the condition of Euclidean distance between adjacent points before and after preserving a mapping in a high-dimensional data stream. The distance transformation is a useful tool in image processing and pattern matching since it estimates the distance between each object in the scene and the nearest border. The Euclidean distance is calculated among two pixels measured in a single direction that use the Euclidean standard. Compared with PCA, both of them have the same optimal function expression, which can be regarded as the nonlinear form of PCA (Gutiérrez, et al., 2007) [11]. More importantly, the MVU dimension can better maintain the distribution of training data. The basic algorithm of MVU is as follows: setting X=[x, x,…, x] is a high-dimensional data set, and Y=[y, y,…, y] is a low dimensional dataset after dimension reduction, and the MVU algorithm sets a constraint condition based on local isometry. In this condition, the maximum of the points is unfolded, and then the original data manifold is restored. The algorithm first constructs a neighborhood graph G according to X, if x is the k nearest neighbor of x, then the weight value is Wij 1, otherwise Wij 0. When missing values is accepted, NP-hard is by far the most reasonable cost function. Despite continued potential efforts to calculate globally optimized solution, getting a polynomial time approach is impossible until P=NP. The NP-complete category is a subset of NP decision making problems in which all NP issues may be simplified to them and in time complexity (Saravanan et al., 2015) [12]. This is a nonconvex quadratic programming problem under the constraint of square equality, and it is transformed into a semidefinite programming problem to obtain the optimal solution. Semidefinite programming is much more generalized than linear programming, and they’re just as simple to fix. These algorithms, like linear regression, have exponential worst-case computation and work admirably in operation (Malarvizhi, et al., 2021) [13]. Defining the kernel matrix of Y: Kij yiyj, then, the semidefinite programming can be transformed into:
| (1) | |
| (2) |
Setting K* is the optimal solution of the optimization problem, and is the first eigenvalue of K*, is the first I element of the corresponding eigenvector, and the spectral decomposition of K* is carried out, then there is: . Therefore, the first element of n-dimensional mapping of high-dimensional data is .
(2) Dimension reduction error measurement. Due to the inevitable loss of data in the dimensionality reduction process, in order to measure the error of the original data, residuals is used to judge. By defining the percentage of energy, there is:
| (3) |
(3) Original dimension of the data set, that is, the dimension of the original collection information. d is the dimension of dimensionality reduction, which is used to analyze the dimension after reducing the original data. is the first a eigenvalue of the kernel matrix K* of the original data set. Because the eigenvalue reveals the original information corresponding to the direction of the eigenvector when the original data sets are projected onto the reduced dimension data set, represents the amount of information retained when the dimension is reduced to the d dimension. The error between the existing dimension reduction results and the original data can be clearly measured by the residual error.
2.2 Content Based Motion Capture Data Retrieval Technology
(1) Feature extraction of motion data. The original motion capture data, such as BVH format, uses the rotation angle and the overall offset of each joint of the human body relative to the parent joint to describe the motion gesture, and the high acquisition frequency frame describes the motion trajectory and constitutes a larger two-dimensional raw data space (Zhang, et al., 2001) [14]. Key frame method: The technique of selecting a frames or combination of images which have a decent sample of a shot is known as key frame extract. This must keep the shot’s core element while removing the majority of the repetitive shots. The retrieved images provide more clear and accurate representation of the moment information. It contains data that specifies where a changeover should begin or end. Firstly, the simple features are defined according to the motion data, and then the key frames are extracted to represent the whole motion sequence. A set of orthogonal spherical harmonic basis functions is used to represent the motion trajectory, and the harmonic coefficient is used as the coding result, so that an intuitive and standardized query method is provided, but the dynamics of human motion can’t be captured. The local linear regression model is used to learn multiple Laplasse operator graphs to preserve the local geometric structure of the motion data, these graphs are then combined to complement feature information. According to the customized features of relationship between the specific limbs and the relationship between the body and the environment, it can save more time and have better retrieval effect than the direct inter frame comparison.
(2) Indexing and similarity matching. How to construct the index structure after feature extraction is the premise to ensure the efficiency, accuracy and flexibility of similarity matching. A good index structure should be compact, independent of database size and easy to update, at the same time, it supports subsequence and fuzzy search. The similarity is the last stage of motion retrieval, and the algorithm should have a good time and space complexity, and be able to find a reasonable compromise between the numerical similarity and similar logic, so as to get the search results which can meet user needs. The human body structure is divided into two parts, and the key postures are extracted from all the moving fragments, and then the representative key posture is found by AP clustering, thus the index table of motion sequence expressed by each part of the body is established. Using real-time assessments of each flexible body position, the human body structure could be shortened to a collection of rigid bodies joined by a hinge joint that comprises of a much more rigid body shape in an imaging system based on inertial sensors. The human body’s real-time motion would then be defined, and elements of the body position estimate is used as the foundation for motion capture using inertial sensors. Affinity propagation is a plot-based grouping method comparable to k Means or K medoids which does not require the number of nodes to be estimated prior to starting the process. The connections between the data sets are fed into AP, which then finds exemplars based on a set of parameters. The measured values start communicating before a high-quality collection of exemplars is produced. At the same time, it is needed to establish a word lookup tree, and then use regular expressions to represent the sample features and compare with the tree feature sequence, but it is needed to build a large number of trees to correspond to all the features, and a certain number of prior knowledge is needed.
3 Results
3.1 Motion Segmentation Method Based on MVU
The aim of movement analysis is to simplify and separate the dynamically motion pixels in a stream from the backdrop action. Moving objects are responsible for the regions of the image which do not record correctly. When analyzing a movement, it is assumed that the dimensions needed to describe the different stages of the movement are different. At the same time, the more movement stage the movement contains, the more complex the motion data is, and the more dimensions required to describe the movement. The MVU approach learns information from common functionalities while retaining both local distances and angles between all neighbors of each point in the data collection. By retaining local similarities, the MVU approach retains the greatest variation in dimensionality reduction operations. In the MVU reduction process, when mapping to the subspace, more dimensions are needed to get a motion with the same error. That is to say, describing multiple merging segments with the description of a single motion segment is bound to lead to a sharp increase in errors. By observing the error, the frame with sharp error will be observed, which can be concluded that the frame is the segmented frame of the moving sequence.
(1) Dimension reduction process. In the analysis of human motion behavior, the joint point angle is used as the motion feature in general. In order to avoid the universal lock, four variables are used to replace Euler angle to carry on the feature extraction. Considering that the joint points of foot and hand have little influence on the human posture, only 14 joint points are selected, thus avoiding unnecessary errors. Firstly, according to the neighborhood parameter k, the isometry constraints are constructed for the original data, and the frontier relation v is calculated, and the Euclidean distance dis (i, j) between xi and other points xj in X is calculated. If xi is the k adjacent point of xj, then two points are adjacent to each other, and the edge weight is dis (i, j), otherwise xi and xj are interrupted in V. The kernel function is introduced to solve the optimization problem, and the optimal solution K* is obtained, so that the eigenvalue can be obtained by spectral decomposition according to the optimal solution.
(2) Iterative eigenvalue estimation. In the actual process of solving, the calculation of eigenvalue is very complex, so it is particularly important to estimate the range of eigenvalues by matrix elements. In this paper, iterative eigenvalue estimation is used to simplify the computational complexity. From the disc theorem, the given n order matrix A is known, when the n disks of A do not intersect each other, there is an estimate formula:
| (4) |
Thus the approximate value of i can be obtained. The concrete implementation of iterative estimation method is as follows: algorithm 1-1 calculates the approximate eigenvector input of the matrix A: matrix A, approximate amplitude ; output: approximate eigenvector y, approximate eigenvalue .
There is arbitrary nonzero vector uo for m 1, 2, 3,…, the LU decomposition is carried out, namely, (A-I) LU:
When , the iteration is stopped, and the result is: . The approximate eigenvector is: .
3.2 Segmentation Process
First of all, a variable length window with length of K is selected for the original motion sequence to be segmented, and the window grows forward as the frame is imported. The frame of the window is reduced by MVU dimension, and the residual R of the segment motion and the original data is calculated. In the case of constant dimension, the window is extended, the amplitude is s frames. Where s represents extended segment, and it can effectively reduce the computation responsibility. After getting the residual value sequence of every s frame, the residual growth is very slow for the motion sequence of same stage, but when the motion sequence begins to change, the required dimension increases, and then the residual error increases suddenly, and the segmentation point can be judged according to the slope increasing point. Setting the residual increase is , in which, is the residual of the current window, and is the residual of the previous window. When the D mutation occurs, the frame is the frame whose action changes. The mean value of the residuals is increased, and then the frame can be seen as the frame of motion segmentation. At this point, the zero residual R is reset, and the timing window is reset, and the residual data is reduced by MVU, and so on.
3.3 Definition and Extraction of Motion Features
Feature extraction can reduce the dimension of the original motion data, and avoid the similarity comparison of high-dimensional data directly, on the other hand, effective features can represent the semantic meaning of human motion, and the matching of features is more in line with people’s cognition of motion, and the retrieval results are more accurate. In this paper, the key frame sequences are extracted from the moving fragments in the database. The database, namely, all the moving fragments are defined: . After key frame extraction, each key frame corresponds to a human gesture in the moving segment: (j is the key frame number). Therefore, the original m frame motion fragment can be expressed as: . The original motion data is reduced effectively (the compression rate is generally about 10%), and it can still capture all the action expression information needed in the retrieval. According to the Laban Movement Analysis (LMA) definition, human movement contains many characteristics: (1) structural characteristics and physical characteristics; (2) dynamic and intention of movement; (3) human form in sports. Laban Movement Analysis is a technique for determining how the physical motions connect to the personality. The first step in achieving your record information capacity is to understand your own range of motion from source to effects. The four parts of Laban’s motion paradigm that would provide a valuable basis for structuring basic physical education classes are body, area, work, and relationships. Flexible, scaling, and adaptation are structural features that have shown to be effective in increasing the perceptual capacities of artificial systems and have the potential of making a substantial difference. Kinematic chains are examined in LMA in regard to spatial Shaping capabilities and dynamic properties. The full motion specification that really can participate in all pattern over time and future value set is described by the human form. One of the basic requirements of indexing motion databases is that these features need to be included. As far as possible, all the features that can be refined can better describe actions and improve the accuracy of retrieval results. According to the structure of human body, a group of body segments S are divided, as shown in Figure 1. Then, a set of Boolean motion features F(p) {fk(p)} (k corresponds to feature ordinal number) is defined, among them, each feature corresponds to a specific action characteristic of the action gesture p, and different features are calculated from different body segment sets. Although each motion feature corresponds to a key frame pose , some motion characteristics, such as joint instantaneous velocity, are calculated from adjacent frames in a certain range , so the motion dynamics are preserved.
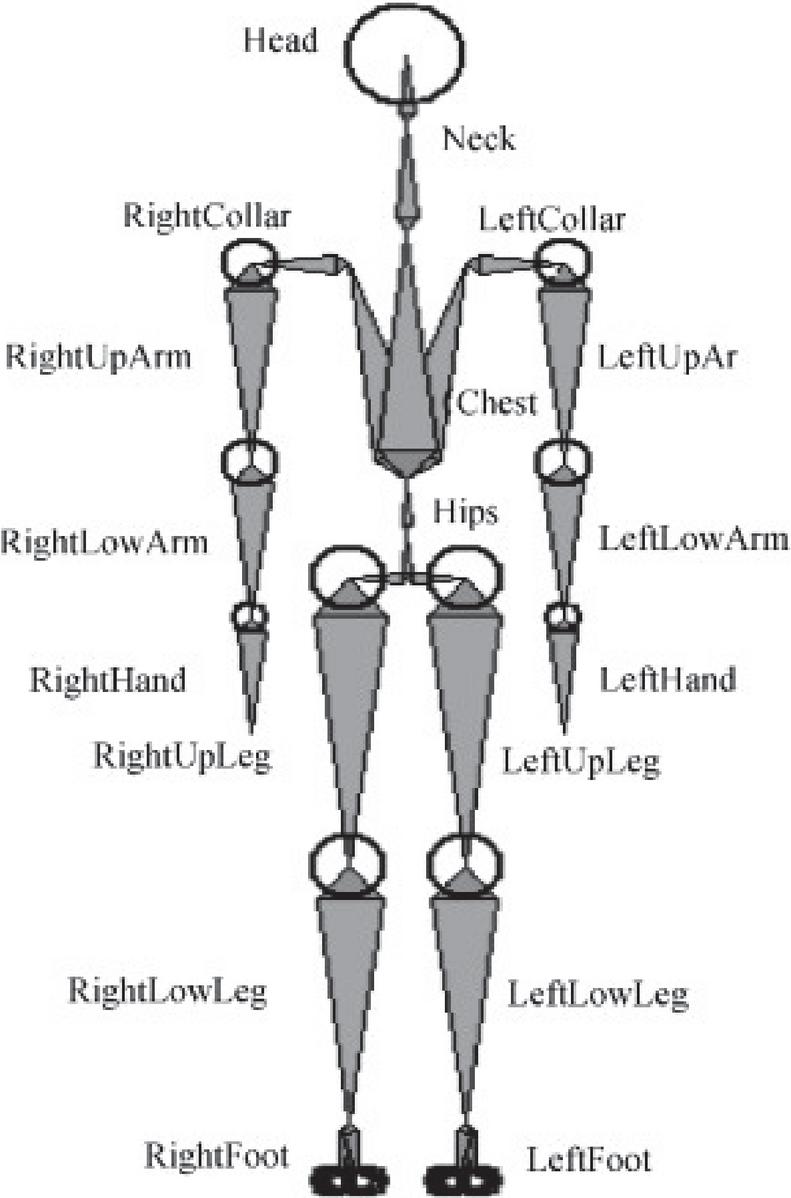
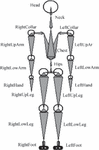
Figure 1 Human skeleton segmentation model.
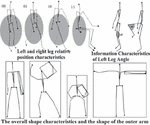
Referring to LMA, feature sets are mainly divided into body characteristics, dynamic features and contour features. (1) Body characteristics mainly describe the structure and geometric characteristics of human motion, this category helps to identify which parts of the body are moving, where there are contact and movement patterns of the body parts. In motion analysis, body features are a technique and vocabulary for characterizing, interpreting, analyzing, and recording all types of human movement. The definition of human motion characteristics is shown in Figure 2. In the definition of this part of the feature, taking into account that the degrees of freedom of some joints of the human body are usually less than 3, therefore, some of the unlikely pose features can be ignored directly to simplify feature space. The analysis of human motion characteristics is shown in Table 1.
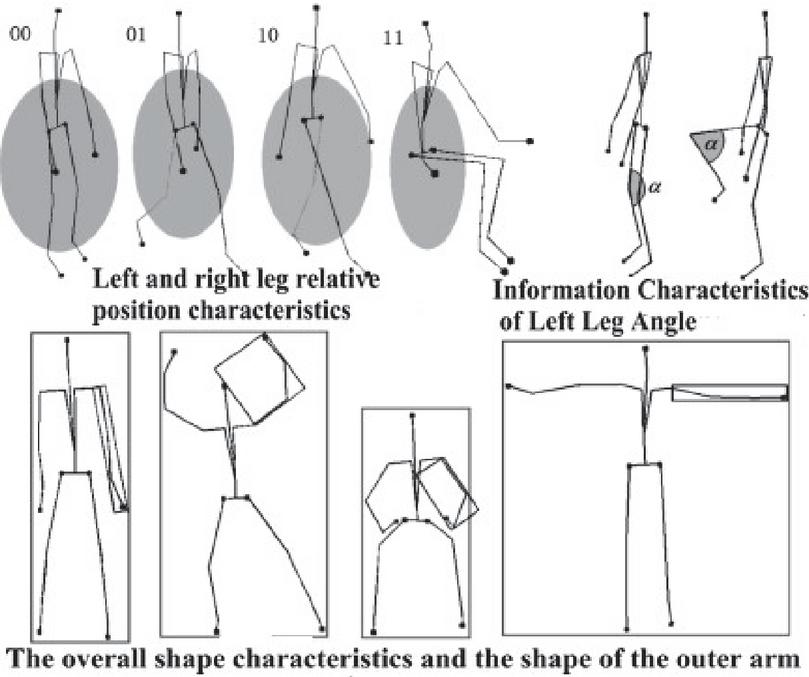
Figure 2 An example of definition of human motion.
Table 1 Analysis of human motion characteristics
| Classification | Content | Characterization |
| Movement performance | This feature shows whether the human body is in motion at present, and calculates whether or not the displacement between the adjacent poses exceeds the threshold. | This feature is mainly aimed at the displacement of limbs and whole body. |
| Relative position | This feature describes the relative position of the limbs. | This feature can describe the position of each part of the body, and it is the most important part of the defined feature. |
| Orientation information | This feature indicates whether there is a big change in the orientation of the upper and lower parts of the human body relative to the base posture of the two parts. | This feature can describe the rotation, movement toward information change and contact information between limbs, and can calculate whether the limbs contact (the distance between the two limbs is smaller than the threshold). |
| Included angle information | It can calculate the angle of the limbs in the current posture and whether the angle between the two parts of the upper and lower parts of the human body is smaller than the threshold value. | It can judge whether the person is standing or crouching through the angle between the thigh and leg and between the upper body and the lower body. |
(2) The dynamic characteristics describe more the logical dynamics of action. The same body posture may be represented by two completely different movements. For example, forward hand movements, gently handed something and angrily pushing in the meaning are completely different, this is what the geometric location features can’t express. In motion analysis, body features are a technique and vocabulary for characterizing, interpreting, analyzing, and recording all types of human movement. According to the LMA, there are four dynamic characteristics: space, intensity, time and smoothness. The detailed analysis is shown in Table 2. (3) Contour features describe the outline of human motion. The feature defines the whole shape of human body and limbs. Because a set of references key poses is available, it is possible to deduce a simplified version of each gesture series that can accommodate the variation in movements made by various people.
Table 2 LMA
| Classification | Content | Characterization |
| Space | The space feature distinguishes the motion track from straight line or non-line, which is calculated from the distance ratio between the current posture and the pre delta frame interval. | It can show the environmental relationship of the current movement. |
| Intensity | The characteristic of violent motion is that the velocity value changes from big to small, the speed is very fast, and the deceleration is obvious, and the slow speed of movement is even slower. | Time features and intensity characteristics can describe the whole process of movement from stillness to motion to end of stillness in detail. For example, the sudden knock on the door is abrupt and violent, while the take-off on the ground appears suddenly and slowly. |
| Time | Time features correspond to intensity characteristics, which can distinguish whether movement is abrupt or steady according to the movement speed. | |
| Smoothness | It can describe the continuity of motion in a certain time range. | It is reflected in whether the velocity curve has many peaks and troughs in the range of time [j-,j+, namely, whether acceleration and deceleration switch are frequent. |
4 Discussions
In order to verify the accuracy and validity of the algorithm, a set of continuous time series motion data with different motion behaviors was segmented. The experiment used the American CMU database, and chose eighty-sixth video capture database which included walking, running, sitting, climbing, reading and a series of sports, and 10 of them were selected for motion segmentation. The main movements are shown in Figure 3.
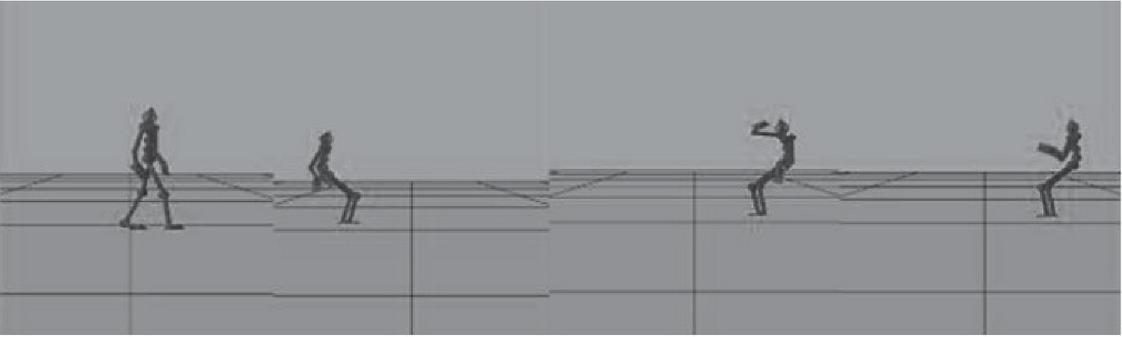
Figure 3 Main motion posture.
In order to measure the performance index of motion segmentation method, the formula is as follows:
The segmentation results are shown in Table 3. From the analysis of the two experimental results, the advantages of this method can be clearly understood.
Table 3 Segmentation accuracy and recall rate of different methods
| Segmentation Methods | Accuracy Rate | Recall Rate |
| PCA | 76.23% | 81.14% |
| PPCA | 89.35% | 89.5% |
| Method in this study | 91.11% | 93.27% |
Experiment 1: the segmentation results for 86_01 are as follows: (simple sequence segmentation): the motion sequence was a combined motion sequence with the length of 4580, which included different movements, such as walking, squatting and climbing, and the dimension reduced by MVU was 10. The results show that the sequence consists of five stable fragments, including walking, standing long jump, kicking and punching. The segmentation results were compared with PCA and manual segmentation results as well as coarse segmentation results, as shown in Figure 4. Because the second standing long jump movement was slow, PCA failed to correctly carry on the right segmentation for the first standing long jump, at the same time, kicking and boxing were not properly separated, but identified as a motion. The motion segmentation based on MVU successfully separated the slow second standing long jump stage, at the same time, correctly separated kicking and boxing into two different sports, achieved the successful implementation of the action of similar segmentation, and improved the segmentation accuracy.
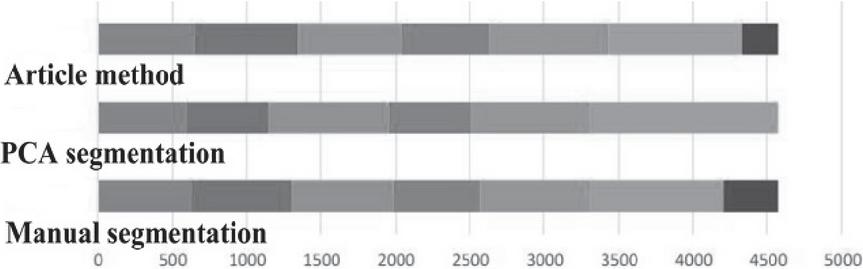
Figure 4 A comparison of the results of the experiment 1.
Experiment 2: the results for 86_09 are as follows: the motion sequence was a combined motion sequence with the length of 4531, including walking, sitting, reading, looking, walking and other sports, and the dimension reduced by MVU was 10. The results are shown in Figure 5. The sequence consisted of five stable fragments. However, PCA segmentation did not achieve the correct segmentation for the sitting behavior, the motion segmentation based on MVU successfully hit the segmentation of this segment, and improved the segmentation accuracy of complex motion successfully. PCA is a dimensionality reduction method that utilizes your input and breaks it down into principal components using transforms (PC). Each PC is chosen in an orthogonal orientation that optimizes the data’s linear variability. PCA is essentially a method that generates numerical information in x, y, and z coordinates and converts it to x’, y’, and z’ coordinates which maximize linear variation. MVU segmentation is a significant and widely used analytical method that may be applied to a variety of situations. It aids in displaying the architecture of a data collection while maintaining the best description of higher to a lower dimension for improved two or three-dimensional representations.
By comparing the segmentation results of the above experiments, it can be concluded that the motion segmentation method based on MVU can basically guarantee the correct segmentation of moving sequences and obtain more accurate segmentation results. At the same time, this method fails to divide the two movements of reading and overlooking. The reason is that reading and overlooking of the two movements are too close, and the distance is smaller than the threshold of the interval window, thus resulting in larger error of residual calculation. This is the main direction of further research in the future.
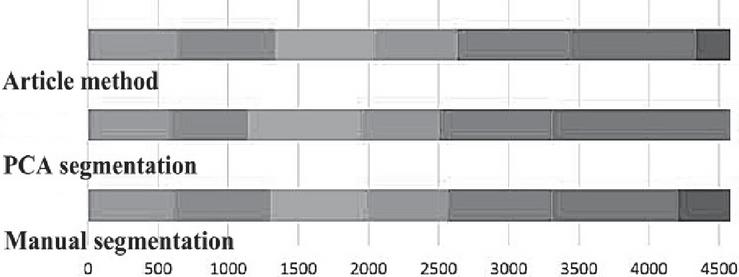
Figure 5 A comparison of the results of the experiment 2.
5 Conclusions
With the development of 3D human motion capture technology, a large number of motion capture data increases the difficulty of its effective management and reuse. In this paper, the combination of eigenvalues was used to represent different motion postures to construct index space, and complete fast and accurate motion retrieval based on the index space. A motion data segmentation method based on MVU nonlinear dimensionality reduction was proposed. The computational complexity of the motion sequence was reduced by iterating the eigenvalues, and then the residual of the motion sequence was computed by the eigenvalues, and the sequence window was expanded to construct the residual curve. In the future work, nonlinear dimensionality reduction motion segmentation algorithm will be further optimized.
References
[1] Keator D B, Grethe J S, Marcus D, et al., A national human neuroimaging collaboratory enabled by the Biomedical Informatics Research Network (BIRN)[J]. IEEE Transactions on Information Technology in Biomedicine, 2008, 12(2): 162–172.
[2] Zhang, N., Han, Y., Crespo, R. G., & Martínez, O. S. Physical education teaching for saving energy in basketball sports athletics using Hidden Markov and Motion Model. Computational Intelligence, 2020, 1–16.
[3] Raju Kannadasan, N. Prabakaran, S. C. Rajkumar and Rishin Haldar. Web Camera Based Motion Detector Application [J]. 2nd International Conference on Trends in Electronics and Informatics (ICOEI), 2018, 75–77.
[4] Ranjan J, Goyal D P, Ahson S I. Data mining techniques for better decisions in human resource management systems[J]. International Journal of Business Information Systems, 2008, 3(5): 464–481.
[5] Chen C L P, Zhang C Y. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data[J]. Information Sciences, 2014, 275: 314–347.
[6] Hyyppa J, Kelle O, Lehikoinen M, et al., A segmentation-based method to retrieve stem volume estimates from 3-D tree height models produced by laser scanners[J]. IEEE Transactions on geoscience and remote sensing, 2001, 39(5): 969–975.
[7] Qiu, Yonghong, et al., Design of an Energy-Efficient IoT Device with Optimized Data Management in Sports Person Health Monitoring Application. [J]. Transactions on Emerging Telecommunications Technologies, 2021.
[8] Huifeng, W., Shankar, A., & Vivekananda, G. Modelling and simulation of sprinters’ health promotion strategy based on sports biomechanics. [J]. Connection Science, 2020, 1–19.
[9] Huifeng, W., Kadry, S. N., & Raj, E. D. Continuous health monitoring of sportsperson using IoT devices based wearable technology. [J]. Computer Communications, 2020, 160, 588–595.
[10] Ardichvili A. Knowledge management, human resource development, and internet technology [J]. Advances in developing human resources, 2002, 4(4): 451–463.
[11] G Gutiérrez M, García-Rojas A, Thalmann D, et al., An ontology of virtual humans[J]. The Visual Computer, 2007, 23(3): 207–218.
[12] Saravanan, V., Pralhaddas, K.D., Kothari, D.P. et al., An optimizing pipeline stall reduction algorithm for power and performance on multi-core CPUs. [J]. Human-centric Computing and Information Sciences, 2015, 5, 2.
[13] P. Malarvizhi Kumar et al., “Clouds Proportionate Medical Data Stream Analytics for Internet of Things-based Healthcare Systems,” in IEEE Journal of Biomedical and Health Informatics, 2021, 1–1.
[14] Zhang T, Kuo C C J. Audio content analysis for online audiovisual data segmentation and classification[J]. IEEE Transactions on speech and audio processing, 2001, 9(4): 441–457.
Biography

Hui Chen Master of Physical Education and Training, lecturer, graduated from the Wuhan Sports University in 2010, Worked in Wuhan Sports University, her research interests include Theory and practice of modern sports training and theory and practice of physical training.
Journal of Mobile Multimedia, Vol. 19_2, 419–436.
doi: 10.13052/jmm1550-4646.1923
© 2022 River Publishers