Sentiments Analysis and Text Summarization of Medicine Reviews Using Deep Sequential Iterative Model with Attention Encoder
B. Rajalaxmi Prabhu1,* and S. Seema2
1Department of Computer Science and Engineering, M.S. Ramaiah Institute of Technology, Bengaluru, India & Department of Computer Science and Engineering, NMAM Institute of Technology, VTU, Belagavi, India
2Department of Master of Computer Applications, M.S. Ramaiah Institute of Technology, Bengaluru, India
E-mail: laxmi123.prabhu@gmail.com
*Corresponding Author
Received 25 October 2021; Accepted 23 January 2022; Publication 17 March 2022
Abstract
In this day and age of data innovation, vast amounts of data are being generated daily, much of it is useless to the general public unless it is correctly handled. This year has seen a huge increase in social networks’ relevance, resulting in vast quantities of data provided by users. This vast amount of information is gathered from a variety of sources, including company websites, customer blogs, and item reviews. The text outline is probably the most significant point of view in daily life. Analysis of text sentiment is a method for assessing, summarising, and drawing conclusions about the most important content. In the field of sentiment analysis, attention methods have been crucial since they make use of sentiment lexicons to gather a huge amount of sentiment polarity information. With an attention mechanism that acts as a link between linguistic information with a strong emotional component and deep learning algorithms, it may be possible to boost text sentiment significantly. In the LSTM model, word sequence addictions can be captured over the long term. For the first time, scientists have developed an attention model that combines LSTM with an incredibly deep RNN model to tackle the problem of sentiment analysis in the real world. The iterative method trains the first set of word embeddings using a Word to Vector technique. With the Word2Vec algorithm, text strings are converted into a numerical value vector and distance between words and comparative words based on meaning are calculated. Using the attention strategy has the added benefit of potentially enhancing machine learning’s ability to learn sentiment representations. The attention model is more scalable and adaptable than previous approaches. The major objective of this work is to assess feelings and develop an abstracted content outline, decide on the semantic summarization of different materials and effectively process the data.
Keywords: Polarity, encoder, decoder, attention model, summarization.
1 Introduction
These days, a huge number of data is created and acquired as a result of the vast amount of data, and the most helpful information and wonderful overview of data can be found these days. Attention-based deep learning procedures are one strategy that has seen increased use in recent years. By focusing on relevant sections of a sequence, attention mechanisms can help neural networks perform better in a variety of tasks, such as sentiment analysis, emotion detection, machine translation, and speech recognition. Using recurrent neural networks (RNNs), we test the effectiveness of attention-based models in a variety of sentiment analysis scenarios. Many deep learning models, techniques of training as well as numerous hyper-parameters are used to examine self-attention, global attention, and hierarchical attention. Instead of using a long-term memory network to analyze sentiment, the suggested approach uses attention processes in a short-term memory network to extract the words with embedded word vectors. Model execution can be improved by applying a unique text count technique based on dynamic sparse encoding [1]. Dynamic attention encoder techniques are commonly used to encode sentiment subjectivity among the constituents. A dynamic attention encoder model and an attention-based model are used to evaluate large texts. Using the relevant association, the model is given polarity information. What we’re trying to do here is extract as many useful and thoughtful words from the model’s input as possible. Using attention-based embeddings, we separate the features of the phrase into a set of word vectors, which we then feed into the classifier [3]. This paper [2] uses a dynamic attention encoder model in conjunction with BILSTM to deal with issues caused by extended sequence dependence, as well as to extract the sentiment polarity from user reviews. Modified Using text summarization, the goal is to reduce the amount of text while still protecting the most important parts of the message. Only a few sentences from the given sentiment are taken into consideration while extracting text using an extraction approach. This method of abstractive text summarising aims to provide the reader with the most relevant information while yet maintaining a high level of semantic precision [5, 6]. As a result of its design, RNN with encoder and decoder models works better when dealing with data and text that have varying lengths. To summarise the text, we’ll use a brief version of each of the data’s big word sequences. To summarise long sentences, bidirectional RNN and LSTM are employed as encoder and decoder, respectively [7]. In this study, film reviews are categorized as either positive or negative, impartial to some degree. One or two methods for conducting thorough research have been put forth in recent years [4]. These traditional methods have yielded excellent results, but text sequence is also important when it comes to component design [8]. Due to their ability to understand knowledge without manual component construction, deep learning approaches have emerged as effective strategies.
2 Literature Review
Beginning in the early 1900s, sentiment and opinion mining became a well-established field of research. They finally became a significant study topic after synthesizing the data audits requested and opened in 2000. In 2005, just 101 publications were distributed on this topic; by 2015, that number has risen to roughly 5,699 pieces. Over the past 10 years, this means that the estimated study has expanded about tenfold, making it the fastest-growing in recent years. A person might seek advice from friends, neighbors, and family members before deciding in the early days of the internet [9]. Associations conducted assessments on its objects and administrations, including tests, evaluations, and population-wide assessments. Since the advent of the World Wide Web, particularly Web 2.0, where customers place a greater focus on substance, the way people share their opinions and viewpoints has drastically changed. Individuals can post their opinions, judgments, and sentiments in the form of Web diaries, social stages, dialogues, and surveys on their websites. and surveys. As a result of the wealth of data offered by Web 2.0 applications, evaluation mining has advanced at a rapid pace. Long-term interpersonal communication between Twitter and Facebook, for example, is more focused on the most recent items between 2014 and 2016 [10]. Various subjects became popular in the ongoing exchanges of mobile phones, financial and human emotions. In 2012, the importance of big data grows, and in 2013, Big Data Analytics becomes increasingly well-known. Cutting-edge information preparation techniques with huge dimensions, greatly extended capabilities, and sophisticated information designs generate extreme amounts of information [11]. Large-scale data requires new approaches and strategies to deal with unique computer opportunities for obtaining useful information without suffering from a delicate disaster. Since recently, another rapidly expanding exploration sector has been iterative: the use of artificial intelligence to solve these problems.
In this section, we present brief data on the various types of computations that were employed in the assumption study. The most beneficial research is distinguished by the judgment and subjectivity of the text in the study [12]. This article describes methods for a few hypothetical exams [13] that are based on deep learning methodologies, such as learning word implantation, slant characterization, and assessment extraction, that are based on deep learning methodologies. In this text, it is iterative that artificial intelligence be submitted for a sentence. Both studies made use of components of grammar as well as the TF-IDF to determine the loudness of the words under investigation [14]. In this paper, multiple techniques (namely CNN, RNN, and LSTM) to the problem of phrase polarity have been investigated and contrasted [15]. As a result, this paper [16] eliminated from the Word2vec device the highlights of several sources of information, customer data, and user information. In a nutshell, comparable tactics were applied in both cases. The use of an LSTM model that is dependent on the detection of feelings [17] is another approach that mixes assumptions with semantical highlights. Using the Amazon food dataset [18, 25], this paper conducted an in-depth investigation of how opinion research for a recommendation framework is conducted. The great majority of models are used to monitor information in the English language; however, just a small number of models monitor tweets in a variety of dialects, including Spanish, Thai, and Persian. Former experts have investigated tweets using a variety of models of extremes and profound learning, which they developed themselves. Models such as DNN, CNN, and crossbred methods are examples of such approaches [19]. Deep learning models are used in a variety of works that are focused not only on the concluding extreme of literary content but also on the investigation of viewpoint assumptions. In this research, angle-based notion inquiry was carried out using Senti-WordNet [20], which was based on semantic explanation to identify points of view and was based on angle-based notion inquiry. There were considerable degrees of item perspectives in the assurance of views in this article [26] which was included in the assurance of opinions assessments as well. In an independent experiment [21], three deep learning techniques, specifically CNN, RNN, and LSTM, were tested on a variety of datasets using different learning algorithms. The three techniques that were employed in this study were not compared, even though this was stated. The Word2vec device [22] is used to extract textual highlights from a variety of information sources, which are then converted into word implanting. There is a single window that contains both the global network degradation window [23, 24] and the neighbourhood setup window.
3 Proposed Methodology
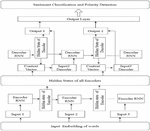
To assess the feelings associated with the customer review, we developed a model that makes use of a neural network with a closed recurrent unit that has learned how the vector word2vec of the surveys affects the vectors. The item review data is initially used as a fixed-length preprocessed by a variety of different ways before being used. These words of review are transformed into vector embeddings, which are then combined and arranged. Vector embedding, which is a technique for forming vectors in the hidden RNN layer, has been employed. The close association between the data corpus is maintained by these vector embeddings of the data.
The information in this article is derived from around two lakh customer reviews on websites. Each review contains information on the item, the user, the profile name, and the content of the review. During the preparation phases, information cleaning and highlight extraction have been carried out on the data. Several profound learning models were utilized during the preparation stage, and detailed outcomes in the following field were introduced. Comprehensive approaches for improving results and capturing semantic and syntactic data have been developed by this concept. The DL model is used to develop a pre-processed word embedding model, which is presented in this paper. The objective of this effort is to gain insight into specific words when the prior data does not provide enough information.
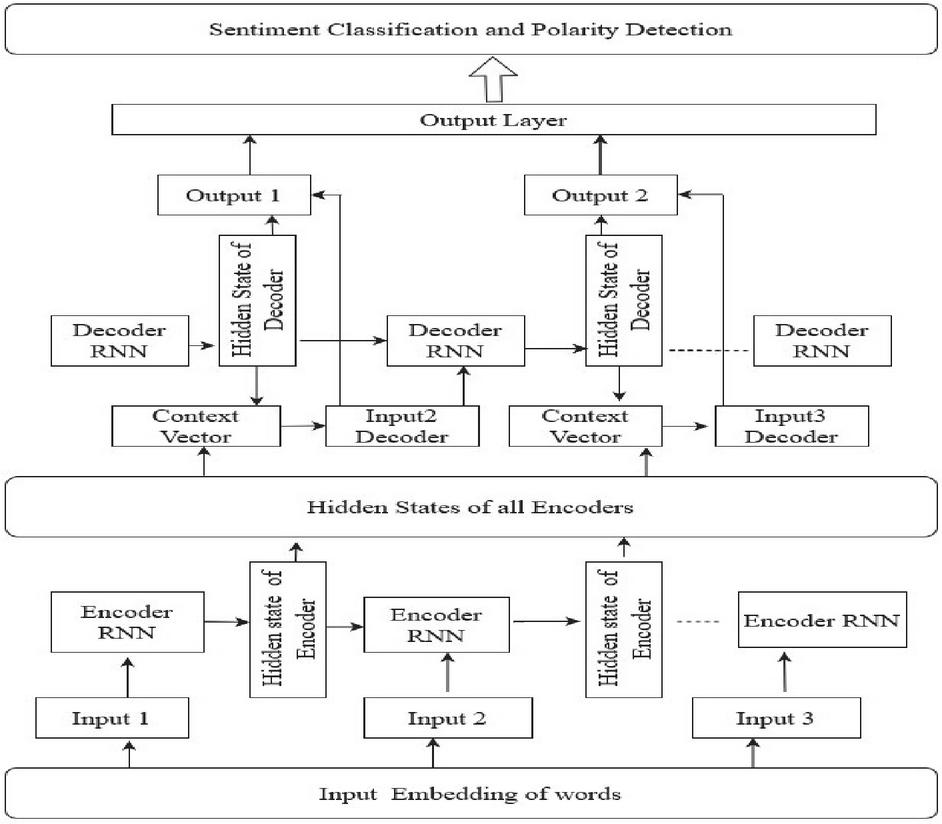
Figure 1 Model architecture.
To compute the optimized weight values of the context
Weight values of Deep Learning Modified Neural Network
Optimized weight values
Start:
Computing the population of dragonflies as
Computing the step vectors
the ending step is not met
Determine the Objective function for all
Determine and
Modify the near hood radius
the present dragonfly has at least one near dragonfly
Choose two crossness and carryout mutation
Update the step of the vector using equation
Update the state of the vector using variables
Stop
The vast amount of effort has resulted in the acceleration and expansion of the scope of numerous new research initiatives in the area. Specially created word embedding has been recommended as a result, and it is available to the wider community. Because of the mixing of several text sequence models, we were able to produce the well-known pre-prepared word embedding that was employed in the estimated phrases.
4 Experimental Results
To evaluate the performance of the model, several metrics were utilized, including accuracy, precision, recall, and F-score, as well as average measures such as macro, micro, and the weighted average score in some multiclass problems. Accuracy and precision were the most important metrics used. Precision recall, accuracy, and other measures are used to assess the model’s overall performance. To determine how many of them accurately forecast that they belong to a particular class of the text, precision is used. When there is more data, the recall is better, and vice versa. In our investigations, we make use of two different datasets customer reviews as well as medicine care reviews are also available.
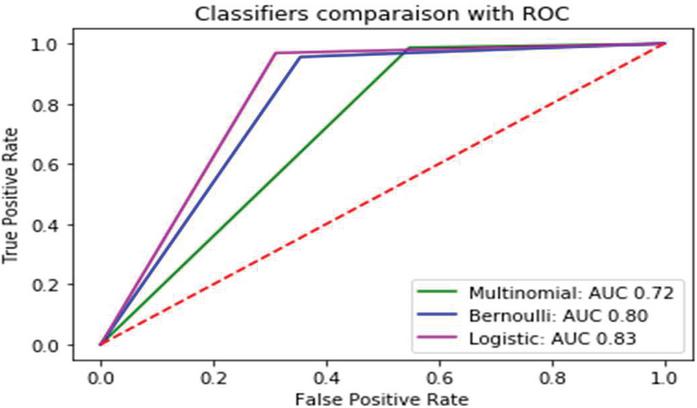
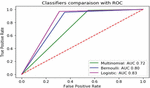
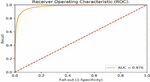
Figure 2 Roc comparison of item review data with baseline and other methods.
For both the item reviews and the medicine reviews, experiments are carried out using a variety of baseline models, including multinomial, Bernoulli, and logistic regression models, among others. The AUR-ROC curve is used to compare the performance of the models in the item reviews, as shown in Figure 2 of this document. If the AUC value is high, it indicates that the model will be able to distinguish between positive and negative reviews with ease.
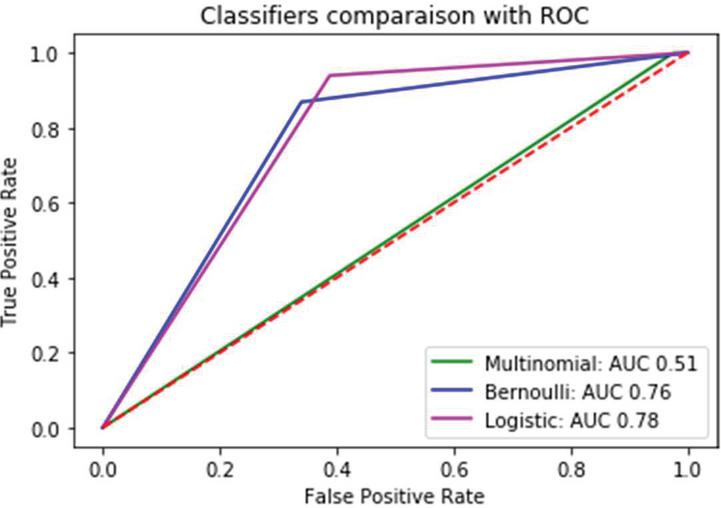
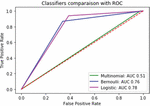
Figure 3 Roc curve comparison for Medicine reviews with baseline and other methods.
Figure 3 depicts a comparison of the performance of the models utilizing the AUR-ROC curve for medicine care reviews in comparison to one another. When comparing item reviews with medicine reviews, it is demonstrated that the logistic regression model performs significantly better in both instances.
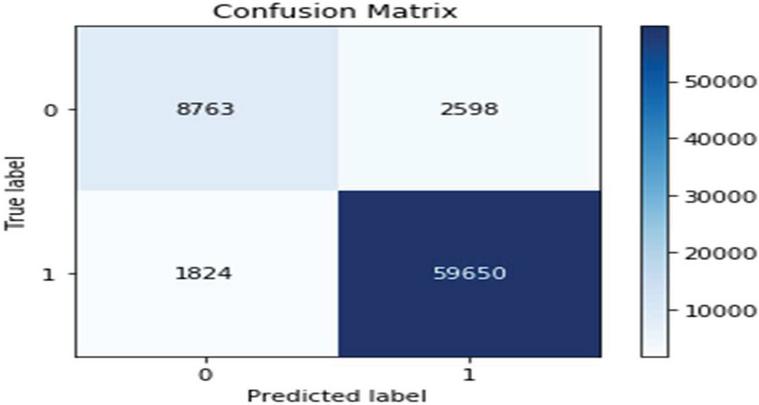
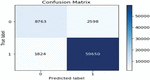
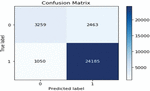
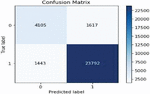
Figure 4 Matrix value for item reviews using basic model.
The Matrix value is primarily responsible for explaining the classification performance of the classifier concerning some test datasets. Figure 4 shows the matrix.
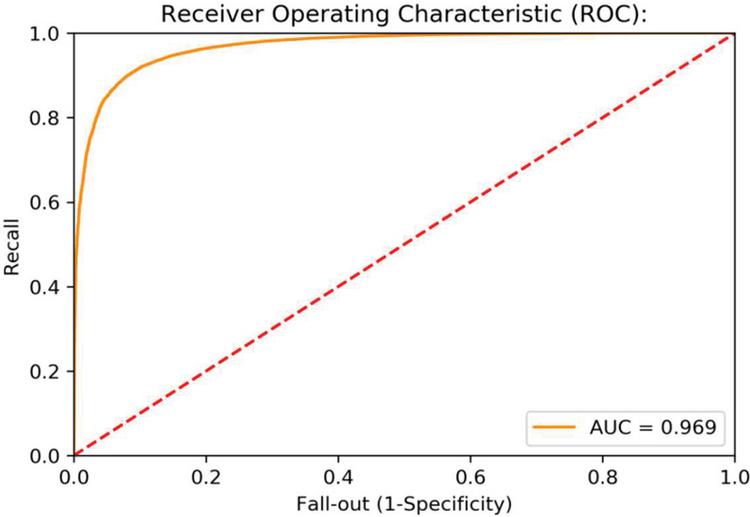
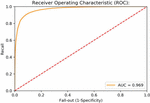
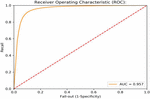
Figure 5 ROC curve value for item reviews using basic model.
To evaluate the performance of a baseline algorithm, it is important to collect data. Figure 5 depicts the ROC curve of the basic model.

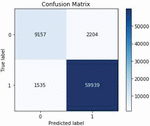
Figure 6 Confusion value for medicine reviews using basic model.
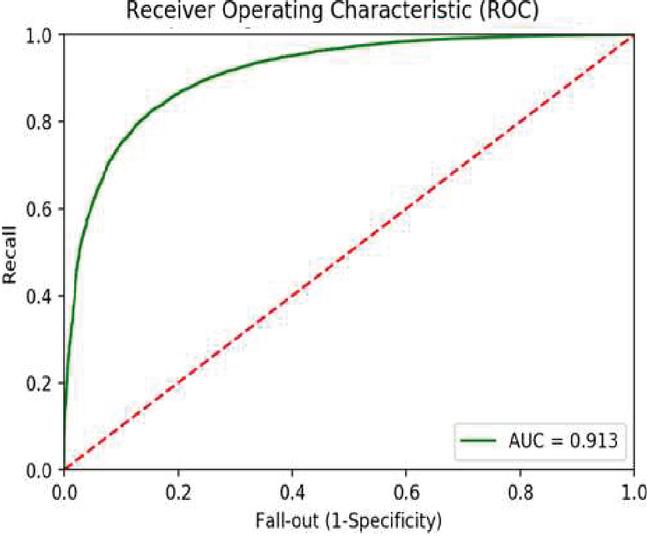
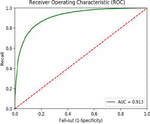
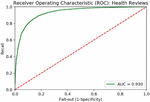
Figure 7 ROC curve data for medicine reviews using basic model.
When applied to medicine reviews, the AUC ROC curve for the basic model reveals that the area under the curve, as shown in Figure 7.
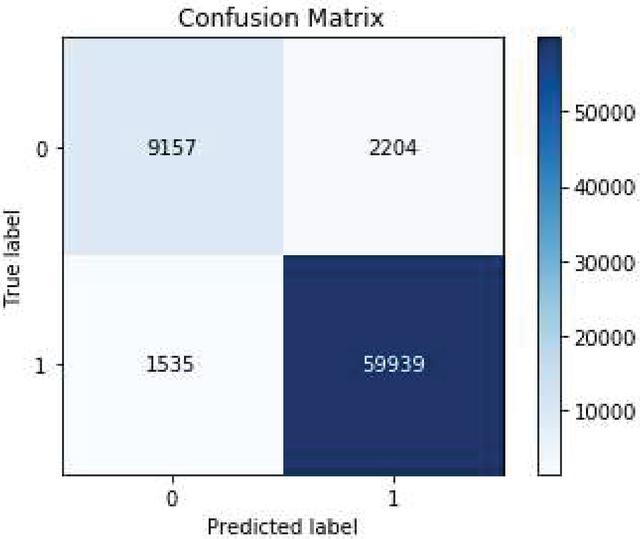
Figure 8 Matrix value for item reviews using iterative iterrative method.
Figure 8 depicts the Matrix value for the true and false classes for the basic model for item.
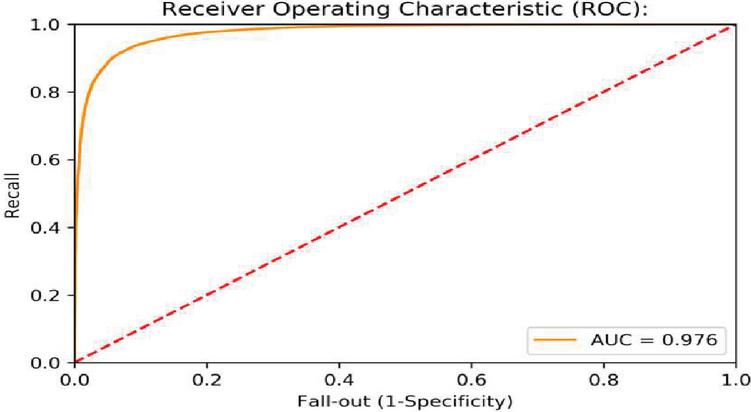
Figure 9 ROC data for item reviews using propsed iterative method.
When analyzing data visualization, it is necessary to check the area under the curve (AUC) or receiver operating characteristic (ROC) curve. Figure 9 depicts the AUC ROC curve obtained from the suggested model for item reviews data set.

Figure 10 Matrix data value of Medicine reviews using iterative iterative model.
Figure 10 depicts the Matrix value relating to true and false classes for the iterative model using medicine reviews. Figure 11 depicts the AUC ROC curve obtained from the suggested model for medicine review data.
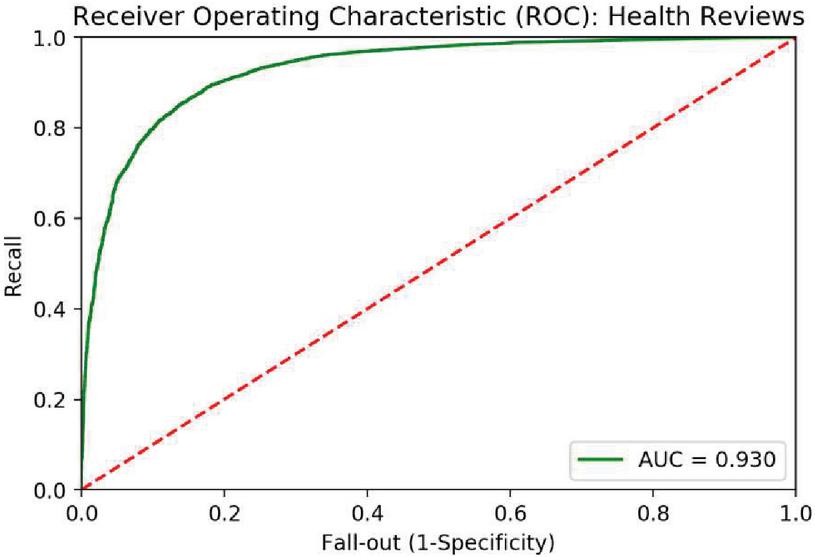
Figure 11 ROC curve for medicine using iterative iterative model.
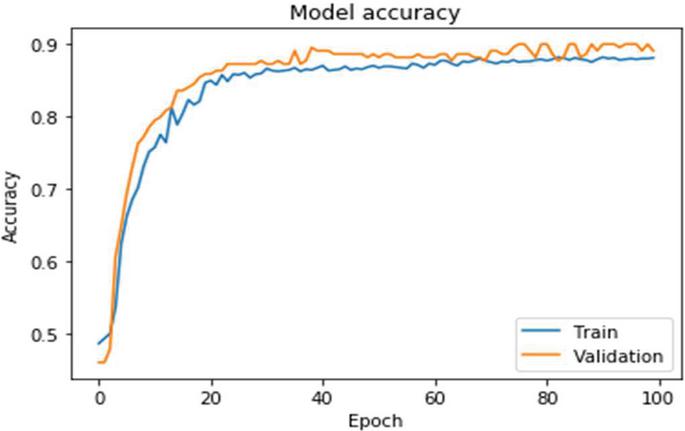
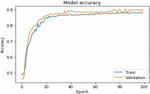
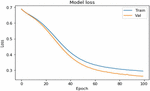
Figure 12 Accuracy with the medicine data using iterative method.
Figure 12 depicts the accuracy of the model when using the iterative approach on medicine data. Both datasets were processed using two layers of bidirectional LSTM in conjunction with the attention encoder neural network and the dynamic attention model. The suggested bidirectional model is equipped with an encoder, which allows for efficient execution. Based on medicine data, Figure 13 depicts the model loss caused by the iterative approach.
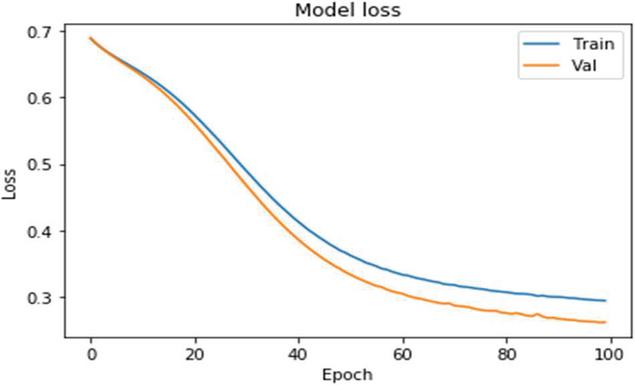
Figure 13 Shows the model loss with Iterative Approach on Medicine data.
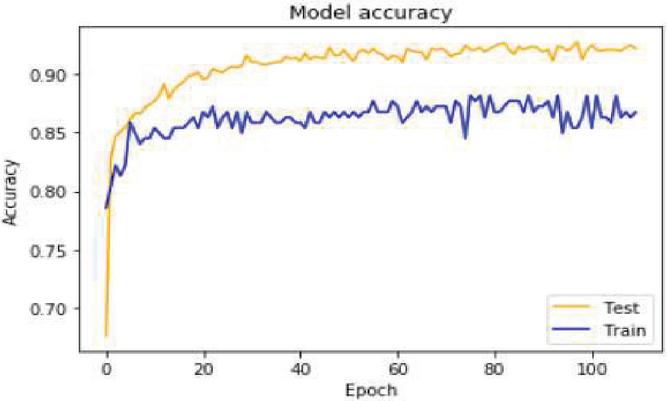
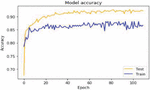
Figure 14 Accuracy value of item reviews using Iterative approach.
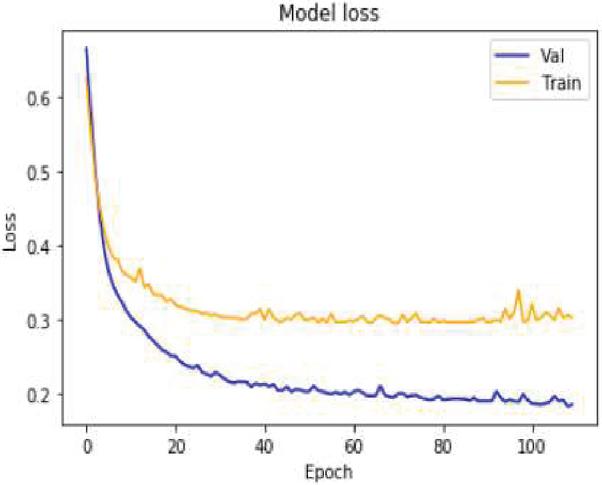
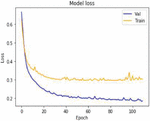
Figure 15 Shows the model loss value with Iterative approach on Item reviews.
The experimental results obtained through the use of the iterative methodologies are shown in the following section.
When compared to other simple basic models, the performance of the iterative model outperforms them, according to the findings. The accuracy value obtained using the basic approach on Item data is depicted in above figure.
Figure 14 depicts the accuracy of the suggested approach based on item evaluation data for 100 epoch’s model of basic in terms of accuracy and precision. Figure 15 shows the model loss value with Iterative approach on Item reviews.
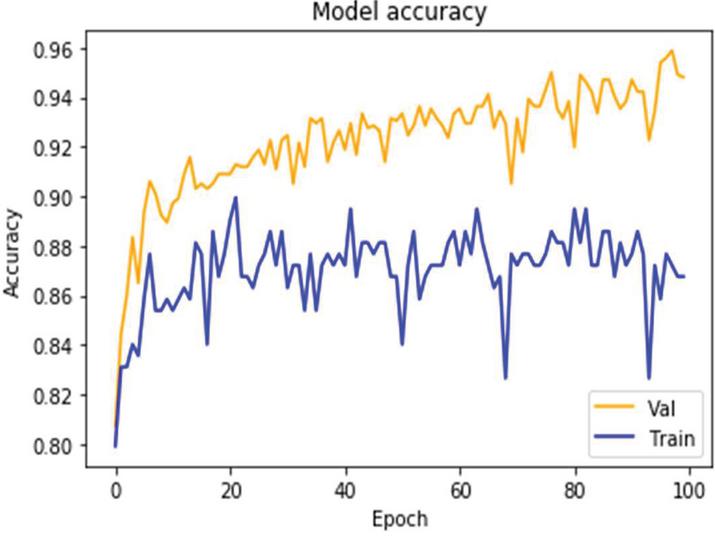
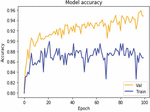
Figure 16 Accuracy value with real time medicine reviews on Iterative Approach.
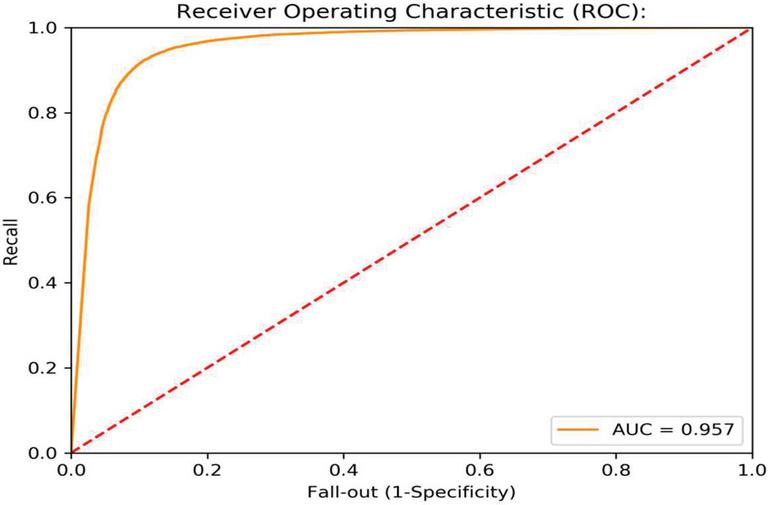
Figure 17 Shows the ROC value on real time medicine reviews using Iterative approach.

Figure 18 Summary and polarity value using basic method.

Figure 19 Summary and polarity value using iterative method.
When applied to item review data sets, the iterative approach results in a model loss value as depicted in Figure 15. It demonstrates that, as compared to the baseline models, the validation loss is reduced in the case of the suggested strategy. The accuracy findings and the value of the ROC curve for the real-time medicine review data set are depicted in Figures 16 and 17 respectively. The sentiments summary, as well as polarity detection, is obtained in this paper. Summary and polarity detection values are identified for both baselines as well as the proposed method shown in Figures 18 and 19. It is observed that the proposed methods give good results in terms of summary generation and the polarity scores concerning positive, negative, and neutral values.
Conclusion
To derive the sentiment from the reviews and evaluate summary from the text, this study examines the embedding’s of the words with deep neural network-based algorithms for item medicine review and real-time datasets. The results are presented in a table format. The purpose of this study is to examine the performance of several models and decide which model performs better on particular datasets, among others. Identifying the polarity of the reviews’ sentiments is a key part of this paper’s methodology. Sentiment classification is improved by including sentiment information into our embedding layer and employing the encoder in conjunction with the attention model, as demonstrated in the following experiments: Following that, we employ the Bidirectional LSTM layer with a forward and backward pass for encoding and decoding the text in question. Based on pre-trained word embedding and feature re extraction, we investigated how these techniques could improve the overall model performance, as well as classification outcomes. Finally, improved accuracy was obtained with the suggested model, demonstrating that BI-LSTM with the encoder and attention model worked well when compared to basic model, which was previously reported.
References
[1] Wang, Tianshi, et al. “A multi-label text classification method via dynamic semantic representation model and deep neural network.” Applied Intelligence 50.8 (2020): 2339–2351.
[2] Ji, Zhong, et al. “Video summarization with attention-based encoder–decoder networks.” IEEE Transactions on Circuits and Systems for Video Technology 30.6 (2019): 1709–1717.
[3] Abdi, Asad, et al. “Deep learning-based sentiment classification of evaluative text based on Multi-feature fusion.” Information Processing & Management 56.4 (2019): 1245–1259.
[4] Samek, Wojciech, and Klaus-Robert Müller. “Towards explainable artificial intelligence.” Explainable AI: interpreting, explaining and visualizing deep learning. Springer, Cham, 2019. 5–22.
[5] Anbazhagu, U. V., and R. Anandan. “Emotional interpretation using chaotic cuckoo public sentiment variations on textual data from Twitter.” International Journal of Speech Technology (2021): 1–10.
[6] Shiva Prasad, K. M., and T. Hanumantha Reddy. “Bidirectional Encoding Contextual Approach for Identification of Relevant Document in Corpus.” Journal of Information & Knowledge Management (2021): 2150014.
[7] Khattak, Faiza Khan, et al. “A survey of word embeddings for clinical text.” Journal of Biomedical Informatics: X 4 (2019): 100057.
[8] Van Lierde, Hadrien, and Tommy WS Chow. “Query-oriented text summarization based on hypergraph transversals.” Information Processing & Management 56.4 (2019): 1317–1338.
[9] Salminen, Joni, et al. “Machine learning approach to auto-tagging online content for content marketing efficiency: A comparative analysis between methods and content type.” Journal of Business Research 101 (2019): 203–217.
[10] De la Torre-Díez, Isabel, Francisco Javier Díaz-Pernas, and Míriam Antón-Rodríguez. “A content analysis of chronic diseases social groups on Facebook and Twitter.” Telemedicine and e-Medicine 18.6 (2012): 404–408.
[11] Rath, Mamata. “Intelligent Information System for Academic Institutions: Using Big Data Analytic Approach.” Interdisciplinary Approaches to Information Systems and Software Engineering. IGI Global, 2019. 207–232.
[12] Gupta, Garima, and Rahul Katarya. “Research on Understanding the Effect of Deep Learning on User Preferences.” Arabian Journal for Science and Engineering (2020): 1–40.
[13] Patel, Harshita, and B. Manjula Josephine. “Sentimental Analysis in Various Business Applications.” Sentiment Analysis and Knowledge Discovery in Contemporary Business. IGI Global, 2019. 31–43.
[14] Abualigah, Laith, et al. “Text summarization: a brief review.” Recent Advances in NLP: The Case of Arabic Language (2020): 1–15.
[15] Chen, Tao, et al. “Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN.” Expert Systems with Applications 72 (2017): 221–230.
[16] Zhang, Chengwei, et al. “Deep Learning for Design in Concept Clustering.” ASME 2017 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference. American Society of Mechanical Engineers Digital Collection, 2017.
[17] Gupta, Gitanjali, and Kamlesh Lakhwani. “Big Data Classification Techniques: A Systematic Literature Review.” Journal of Natural Remedies 21.2 (2020): 1–1.
[18] Jin, Mingmin, et al. “Combining deep learning and topic modeling for review understanding in context-aware recommendation.” Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018.
[19] Zhang, Ji, et al. “Relational intelligence recognition in online social networks—A survey.” Computer Science Review 35 (2020): 100221.
[20] Abid, Fazeel, et al. “Sentiment analysis through recurrent variants latterly on convolutional neural network of Twitter.” Future Generation Computer Systems 95 (2019): 292–308.
[21] Rhanoui, Maryem, et al. “A CNN-BiLSTM model for document-level sentiment analysis.” Machine Learning and Knowledge Extraction 1.3 (2019): 832–847.
[22] Krohn, Jon, Grant Beyleveld, and Aglaé Bassens. Deep Learning Illustrated: A Visual, Interactive Guide to Artificial Intelligence. Addison-Wesley Professional, 2019.
[23] Nadeau, Stephen E. “Neural population dynamics and cognitive function.” Frontiers in human neuroscience 14 (2020): 50.
[24] Yoon, Seunghyun, et al. “Detecting incongruity between news headline and body text via a deep hierarchical encoder.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 33. No. 01. 2019.
[25] Baddur, Rajalaxmi P., and Seema Shedole. “A Novel Approach for Sentiment Analysis Using Deep Recurrent Networks and Sequence Modeling.” Recent Patents on Engineering 14.3 (2020): 403–411.
[26] El-Affendi, Mohammed A., Khawla Alrajhi, and Amir Hussain. “A novel deep learning-based multilevel parallel attention neural (MPAN) model for multidomain arabic sentiment analysis.” IEEE Access 9 (2021): 7508–7518.
Biographies

B. Rajalaxmi Prabhu is currently working as an Assistant Professor in the Department of Computer Science and Engineering at NMAM Institute of Technology, Nitte, India. Pursuing research at M S Ramaiah Institute of Technology, Bangalore. She has around 8 years of teaching experience. She is a Life member of ISTE. She has published 10 research papers in the International Conferences/Journals. Her research interests include Natural Language Processing, Machine Learning and Data Mining.

S. Seema is currently working as a Professor and Head in Department of Master of Computer Applications at M S Ramaiah Institute of Technology, Bengaluru, India. She is actively involved in Research work in the area of Data mining and Bioinformatics. She has around 29 years of teaching experience. Has published more than 40 research papers in the International Conference/Journals in India and abroad. She is a life member of ISTE. Her areas of interest include Databases, Data mining and Big Data, Computer Graphics, Bioinformatics and Data Analytics.
Journal of Mobile Multimedia, Vol. 18_4, 1281–1300.
doi: 10.13052/jmm1550-4646.18415
© 2022 River Publishers