Implementation of Generative Adversarial Networks in Mobile Applications for Image Data Enhancement
Oleksandr Striuk* and Yuriy Kondratenko
Intelligent Information Systems Department, Petro Mohyla Black Sea National University, Mykolaiv, Ukraine
E-mail: oleksandr.striuk@gmail.com; yuriy.kondratenko@chmnu.edu.ua
*Corresponding Author
Received 24 January 2022; Accepted 07 June 2022; Publication 15 February 2023
Abstract
This article aims to explore and research GANs as a tool for mobile devices that can generate high-resolution images from low-resolution samples and reduce blurring. In addition, the authors also analyse the specifics of GAN, SRGAN, and ESRGAN loss functions and their features. GANs are widely used for a vast range of applied tasks for image manipulations. They’re able to synthesize, combine, and restore graphical samples of high quality that are almost indistinguishable from real data. The main scope of the research is to study the possibility to use GANs for the said tasks, and their potential implementation in mobile applications.
Keywords: Artificial intelligence, machine learning, ML, deep learning, DL, neural networks, generative adversarial network, GAN, super resolution, SR, low resolution, LR, SRGAN.
1 Introduction
1.1 General Overview
Image restoration is a highly demanded technique used in a wide range of applications: digital microscopy, astronomical photography, forensics, biology, cybersecurity, and so on [1, 2]. The image restoration process aims to estimate the clean, original image from a damaged, noisy graphical sample, since corruption may come in many forms such as camera misfocus, motion blur, or different types of noise.
There are many different approaches that allow to process low-quality graphical samples to increase their resolution and restore important features. In this article, we focus on an image restoration method using the super resolution generative adversarial network (SRGAN) framework, which is a modified version of the classical generative adversarial network (GAN) architecture [3, 4].
Standard GAN, SRGAN, ESRGAN, and TecoGAN have shown solid results in improving low-resolution images and videos in terms of efficiency, speed, and quality of output in the past few years. This is a major reason why this research focuses heavily on GAN frameworks.
The study analyses image enhancement techniques, focusing on super resolution. Super resolution refers to enlarging an image to a higher resolution, image deblurring means turning it into a sharp one from a blurry sample, and inpainting stands for filling in empty spaces or removing visual artifacts in an image by injecting synthesized data. All the listed approaches infer evaluating pixel data from available pixels. The restoration process aims to predict how they should look.
Of particular interest to the authors of the article are the possibilities of applying image restoration and enhancement approaches using GANs in the context of cybersecurity (identification of wanted suspects by low-resolution CCTV images, restoration of damaged fingerprints, etc.) and digital forensics (detecting and reverse-engineering photo or document manipulation) implementing these methods on mobile devices.
1.2 GAN Usage in Mobile Image Processing Apps
As for mobile applications, GANs hold a unique position and are very popular, especially as an entertainment tool. Popular mobile applications based on artificial neural networks, such as FaceApp and ZAO, allow you to edit the user’s face or even replace the face of a celebrity in the video with your own face. Some of these apps use algorithms like GAN or akin models. However, in the context of the above, it should be noted that the computations required to run such neural network models in real-time (as mobile software directly on mobile devices) are still too resource intensive. Therefore, the centralized company’s servers are used for such processing.
Using GAN super resolution models, low-resolution images obtained by mobile cameras can be upscaled to near DSLR/DSLM quality. Computing power is a major challenge here, since the implementation of a model like SRGAN on a mobile device requires a lot of system resources.
Tampubolon, Setyoko, and Purnamasari suggested a model that is smaller and requires fewer resources while maintaining single-image SR quality on mobile devices [5]. They converted, quantized, and compressed the SRGAN model utilizing Snapdragon Neural Processing Engine (SNPE) and obtained successful experimental data that confirmed SNPE-SRGAN’s capability of achieving images of high-resolution quality.
Jayakodi, Doppa, and Pande presented Scale-Energy Trade-off GAN (SETGAN) – a non-standard trade-off approach to image generation that balances generation accuracy and the energy used during processing [6]. In order to avoid the problem of long training time and high memory consumption, the authors trained their model on a remote server and utilized the trained GAN on edge devices. Results demonstrated that their client-server-based model was able to achieve a 56% increase in energy for a loss of 3% to 12% Structural Similarity Index Metric (SSIM) accuracy.
While the current generation of mobile devices usually doesn’t demonstrate sufficient resource performance potential, for the time being, neural network models for image manipulation can be successfully implemented on mobile platforms using the client-server approach.
2 GAN for Image Enhancement
2.1 Super Resolution Concept
SRGAN framework was developed by Ledig et al. [4] and described in their paper, where they applied GAN architecture for photo-realistic single image super resolution. Like other GAN implementations, SRGAN is a combined deep neural network that contains two sub-networks – generator network and discriminator network that compete with each other in a zero-sum game; the described method shows a successful approach of upscaling graphical samples by four.
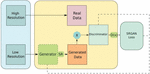
The SRGAN generator generates data based on the probability distribution, while the discriminator strives to identify whether this data is artificially generated or coming from a real input data. The generator network main task is to optimize the synthesized samples so that the discriminator cannot distinguish them from the real data (Figure 1).
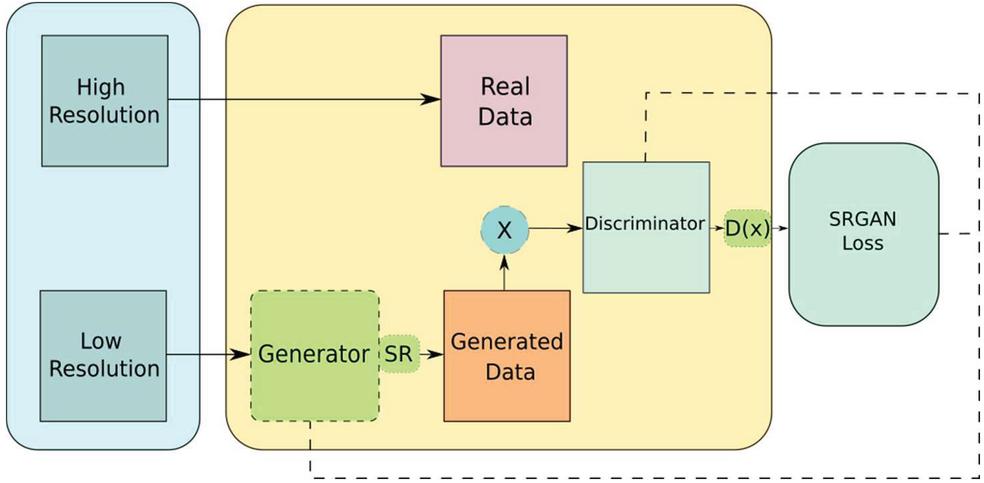
Figure 1 Schematic representation of the SRGAN.
The Generator network consists of residual network blocks in place of deep convolution modules, since residual blocks are more flexible in terms of learning and make it possible to maintain a deeper structure that allows them to synthesize results of better quality. There is a specific type of connection used in residual networks called “skip connections.”
2.2 SRGAN Model Specifics
SRGAN fundamentals are based on the conventional GAN algorithm presented by Goodfellow et al. that can be mathematically described as follows [3]:
| (1) |
where is the generator network; is the discriminator network; represents a scalar – sample of real training data; represents noise or a latent space vector extracted from a standard normal distribution; is a prior on input noise variables; is a prior on input real data variables; stands for expectation; is the discriminator network output that represents the probability that actually came from the data rather than from the generator; represents the value function of and in the two-player minimax game [3].
As for the SRGAN specific architecture, Ledig et al. applied perceptual loss, which is a combination of a content loss and an adversarial loss component. It evaluates a solution based on perceptually relevant features [4]:
| (2) |
where l stands for loss, SR stands for “super resolution,” is content loss, represents adversarial loss.
As for the adversarial loss, the authors mention that they added a generative component to the loss function, which stimulates the model to give preference to solutions that are based on the multiformity of natural images, by attempting to deceive the discriminator. The generative loss is presented as follows [4]:
| (3) |
where is generative loss, represents discriminator probability that the reconstructed image is a real high-resolution image, is reconstructed image, stands for “image low resolution.” Analyzing the approach, we can see that it looks almost like a binary cross-entropy loss function (BCELoss) [7] that is often used for binary classification.
The VGG loss with the ReLU activation layers was applied as a loss function, because of its closeness to perceptual similarity. Since the VGG19 has been trained on millions of images, feature extraction of such a pre-trained network provides strong benefits in terms of quantifying from the perceptual standpoint, and it evaluates how good graphical samples are. The content loss is calculated as follows [4]:
| (4) |
where stands for feature representations of a reconstructed image, is the reference image, and represent corresponding feature map matrices within the VGG network.
2.3 ESRGAN Framework
We used a pre-trained model – ESRGAN [8] – to test and validate the hypothesis of whether SRGAN can be used to improve low-resolution images obtained using different devices (mobile cameras, old scanners, etc.). The model was described by Wang et al. and contains its own architectural peculiarities that distinguish it from the original SRGAN. They replaced the conventional discriminator with the Relativistic average Discriminator (RaD). As a result, the discriminator loss () has gotten the following form [9]:
| (5) |
where is Relativistic average Discriminator [9], is the process of taking the average for all generated data in the mini-batch.
The generator’s adversarial loss is presented in a mirrorlike form [8]:
| (6) |
where and denote the input low-resolution image.
The proposed architecture allows the generator to benefit from the gradients from synthesized data and real data in adversarial learning. In standard SRGAN only the synthesized part is used.
As for the perceptual loss, the full loss for the generator looks like this [8]:
| (7) |
where denotes the content loss; it assesses the 1-norm distance from the recovered image and the ground-truth ; represent coefficients for balancing diverse loss terms.
3 Image Resolution Enhancement and Experimental Results
While we’re currently developing our own mobile SRGAN model, for testing purposes, we used the ESRGAN model with pre-trained weights and changeable interpolation parameters that provides smooth control and finer tuning of the neural network. In the future, we plan to finish developing our own mobile-oriented model using PyTorch Mobile, WGAN [10] (utilizes the 1st Wasserstein distance function), ESRGAN, and Lipschitz Continuity Condition regularization.
As a benchmark, we used two different freely available datasets:
(a) Sokoto Coventry Fingerprint Dataset (SOCOFing) – a biometric fingerprint database that contains 6,000 dactylograms from 600 African subjects, Figure 2 [11]; this dataset is also suitable for other tasks related to DL and GAN training [7].
(b) BIRDS 400 Dataset, which is designed specifically for species image classification, Figure 3 [12].
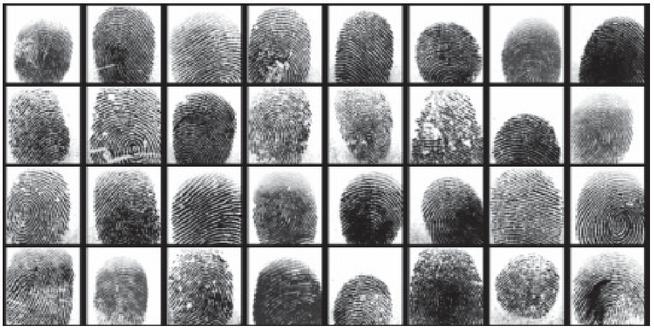
Figure 2 SOCOFing real fingerprint scans.

Figure 3 BIRDS 400 Dataset, image sample grid.
We prepared low-resolution (LR) images to subsequently process them using the model and increase the resolution of the original samples by four times, without losing the quality.
All the LR test samples have been resized to 96 by 96 pixels (randomly picked value) and converted to the PNG format using Python and PIL library. Our task was to increase the resolution of these experimental samples by 4 times; therefore, the resolution of the final image should be 384 by 384 pixels. After processing the selected sets of images by the model, we got the expected results.
First, we applied the model to the fingerprint samples, this is how samples looked like before enhancement in 96 by 96 pixels, Figure 4.

Figure 4 SOCOFing samples before processing, 96 by 96 pixels.
And here are how the samples look like after being upscaled by the model by 4 times, up to 384 by 384, Figure 5.

Figure 5 SOCOFing samples after processing.

Figure 6 BIRDS 400 Dataset samples before processing, 96 by 96 pixels.
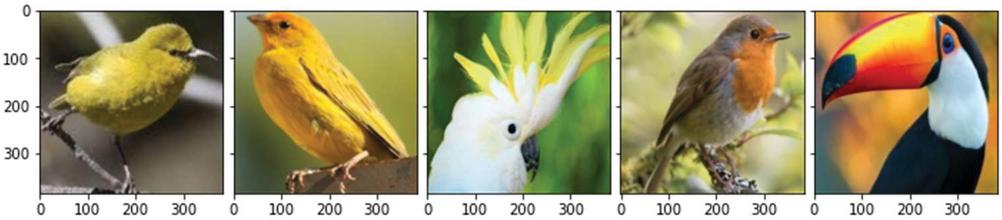
Figure 7 BIRDS 400 Dataset samples after processing, 384 by 384 pixels.
The following are results of processing image samples from the BIRDS 400 Dataset, Figures 6 and 7 respectively.
As we can see, the samples have been successfully upscaled to 384 by 384 pixels while maintaining maximum image quality.
The experiment demonstrates that a GAN-based model with an appropriately customized architecture and loss function is able to significantly increase the resolution of the processed image while maintaining the quality and stable graphic structure.
An even higher level of results can be achieved by further studying this approach and modifying the model experimentally.
4 New Directions, Perspectives, and Suggestions
4.1 Ways of Super Resolution Improvement
GAN-based super resolution approaches are of great importance today. This technology can significantly increase the quality of medical scans, telescopic and microscopic photo, maximize the quality of video surveillance camera storyboards, and much more. The variability in the application of super resolution models saves lives, allows criminals to be identified, or accelerates an important scientific discovery.
Although even the current generation of GAN models shows good results in image enhancement, these performances can be improved.
Wang et al. described a super resolution model with a generator network that contains an encoder block, which helps to generate more natural and clear images and retrieve additional important features [13].
Zhang et al. suggested a new GAN-based algorithm for MRI imaging that improves a classical super resolution approach. It involves a 3D perceptual-tuned network combined with a deep learning SR technique and transfer learning methods. The model showed its capability to converge better and produce results that are more visually appealing [14].
Yoon et al. presented the OUR-GAN model – the image generation framework that is based on an ultra-high-resolution (UHR) approach and synthesizes non-repetitive graphical samples with 4K or even higher resolution using only one training image [15]. The model learns from real UHR data and is able to generate large-scale, detailed images and maintain coherence across large scales. It synthesizes high-resolution UHR images using limited memory, which prevents boundary discontinuity, and demonstrates higher fidelity and diversity compared to other models.
Gaire et al. applied two-step GAN-based model for the super resolution problem [16]. The training process is split into two parts: (a) training a GAN model that maps real LR-images to a space of bicubic graphical data similar in size; (b) utilizing the nESRGAN+ framework trained on bicubically downsampled LR and HR image pairs to upscale the converted bicubic alike graphical samples. The obtained results demonstrate that the model performs better than other super resolution frameworks in terms of both quantitative and qualitative evaluation. As for shortcomings, some synthesized samples may have uneven artifacts.
Considering the above, we can conclude that along with the general architecture parameters, proper algorithmic approach should be applied to a specific deep learning model [1]. Each type of super resolution GAN framework can be optimized in terms of weight parameters, model topology, activation function class, batch size, learning rate, and number of epochs. The experimental approach remains the most effective method so far because there are no generally accepted universal rules on how many layers or neurons there should be, or what synaptic weight parameters should be applied.
4.2 Mobile Application Prospects
As we have previously discussed in paragraph 1.2, the least resource-intensive option for using artificial neural networks on mobile devices is the client-server (or cloud) combination. However, users might experience a slowed experience when computations are processed in the cloud. In the past few years, there have been promising developments that allow neural network models to run relatively stable directly on mobile devices.
For instance, a mobile photographer might take a shot of a bird that the neural network model recognizes as a bald eagle. Processing the captured image on his phone instead of on a remote server is much faster and creates a better user experience.
The following DL mobile frameworks have become very popular in recent years: Caffe2, DeepLearningKit, TensorFlow Lite, MACE, PyTorch Mobile, Paddle Lite, SNPE, and CoreML. These platforms enable the creation of efficient and stable mobile deep learning solutions.
High-quality photos are an important criterion for consumers when choosing smartphones, and neural processing units are one of the key pillars that help to maintain the quality of mobile shots. Machine learning algorithms help to recognize objects, deblur photos, enhance image quality, and improve color balance.
Ma et al. proposed a new deep neural network compression and kernel pruning approach that allows executing models in real-time without compromising accuracy [17]. The suggested method outperforms current popular DNN frameworks, such as TensorFlow-Lite, TVM, and Alibaba Mobile Neural Network with no accuracy loss.
Neural Processing Units (NPUs) have been developed specifically for mobile devices and are capable of running DL models quite a bit faster, but with lower accuracy. Tan and Cao described an MLMP algorithm to address the accuracy and performance issue [18]. According to the experiment results the suggested technique outperforms heuristic based algorithms.
There are still many challenging and complex problems in regard to DL-model deployment on mobile devices, but in the years ahead, thanks to advances in mobile machine-learning processors and the development of next-generation wireless technologies, mobile devices will be able to perform much more complex computations [19]. Considering the above, we can expect further development of portable pre-trained and full-scale SRGAN-like models that will be deployed on mobile devices without cloud-based, remote servers.
5 Conclusions
Taking into account the latest advances in machine learning methods [20], the development of software DL-frameworks for mobile devices [21], as well as hardware progress in the mobile device market, which consistently increases the computing power of portable gadgets, it can be stated that super-resolution models based on GANs are a promising technology that requires further attention both from the industry and academia.
Given the increasing popularity of intelligent services on mobile devices, a further surge in mobile software solutions based on deep learning [22] is highly expected in the next few years. In this context, (GANs are no exception) the meteoric rise in the development of this type of AI is evident. As the current research into deep learning on mobile devices is just at the beginning, this opens up a wide window of opportunity for the scientific community.
With increasingly efficient DL algorithms, more comprehensive neural networks, and state-of-the-art AI chips, GAN mobile applications will become standard in medical scan imaging, photo/graphical data enhancement, aerospace photography, computer vision, eye tracking, robotics, and various other domains [23–25]. As AI capabilities are becoming more sophisticated, AI-ready mobile devices will evolve as well and spur further innovation.
References
[1] O. Striuk and Y. Kondratenko, “Generative Adversarial Neural Networks and Deep Learning: Successful Cases and Advanced Approaches”, International Journal of Computing, vol. 20, no. 3, pp. 339–349, Sep. 2021.
[2] O. Striuk, Y. Kondratenko, I. Sidenko and A. Vorobyova, “Generative Adversarial Neural Network for Creating Photorealistic Images,” in Proceedings of 2020 IEEE 2nd International Conference on Advanced Trends in Information Theory (ATIT), 2020, pp. 368–371, doi: 10.1109/ATIT50783.2020.9349326.
[3] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, J. Bengio, “Generative Adversarial Networks,” in Proceedings of the In-ternational Conference on Neural Information Processing Systems (NIPS) 2014, pp. 2672–2680.
[4] C. Ledig et al., “Photo-realistic Single Image Super-Resolution Using a Generative Adversarial Network,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4681–4690.
[5] H. Tampubolon, A. Setyoko, F. Purnamasari, “SNPE-SRGAN: Lightweight Generative Adversarial Networks for Single-Image Super-Resolution on Mobile Using SNPE Framework,” Journal of Physics: Conference Series 1898 (2021) 012038, doi: 10.1088/1742-6596/1898/1/012038.
[6] N. K. Jayakodi, J. R. Doppa, P. P. Pande, “SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms,” in Proceedings of the 2020 IEEE/ACM International Conference on Computer Aided Design (ICCAD), 2020, pp. 1–9.
[7] O. Striuk and Y. Kondratenko, “Adaptive Deep Convolutional GAN for Fingerprint Sample Synthesis,” in Proceedings of 2021 IEEE 4th International Conference on Advanced Information and Communication Technologies (AICT), 2021, pp. 193–196, doi: 10.1109/AICT52120.2021.9628978.
[8] X. Wang et al., “Esrgan: Enhanced Super-resolution Generative Adversarial Networks,” in Proceedings of the European conference on computer vision (ECCV) workshops, 2018, pp. 1–23.
[9] A. Jolicoeur-Martineau, “The Relativistic Discriminator: A Key Element Missing from Standard GAN,” 2018, arXiv preprint arXiv:1807.00734.
[10] M. Arjovsky, S. Chintala, L. Bottou, “Wasserstein Generative Adversarial Networks,” in Proceedings of International conference on machine learning, 2017, pp. 214–223.
[11] Y. I. Shehu, A. Ruiz-Garcia, V. Palade, A. James, “Sokoto Coventry Fingerprint Dataset,” arXiv:1807.10609 [cs.CV], 2018, pp. 1–3.
[12] BIRDS 400 Dataset, [Online]. Available at: https://www.kaggle.com/datasets/gpiosenka/100-bird-species.
[13] H. Wang, W. Wu, Y. Su, Y. Duan and P. Wang, “Image Super-Resolution using a Improved Generative Adversarial Network,” in Proceedings of 2019 IEEE 9th International Conference on Electronics Information and Emergency Communication (ICEIEC), 2019, pp. 312–315, doi: 10.1109/ICEIEC.2019.8784610.
[14] K. Zhang, H. Hu, K. Philbrick, G. M. Conte, J. D. Sobek, P. Rouzrokh, B. J. Erickson, “SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks,” Tomography, 2022, vol. 8, pp. 905–919, https://doi.org/10.3390/tomography8020073.
[15] D. Yoon et al., “OUR-GAN: One-shot Ultra-High-Resolution Generative Adversarial Networks,” 2022, arXiv preprint arXiv:2202.13799.
[16] R.R. Gaire, R. Subedi, A. Sharma, S. Subedi, S.K. Ghimire, S. Shakya, GAN-Based Two-Step Pipeline for Real-World Image Super-Resolution. In: T. Senjyu, P.N. Mahalle, T. Perumal, A. Joshi (eds) ICT with Intelligent Applications. Smart Innovation, Systems and Technologies, vol. 248. Springer, Singapore, 2022, https://doi.org/10.1007/978-981-16-4177-0\_75.
[17] X. Ma et al., “PCONV: The Missing but Desirable Sparsity in DNN Weight Pruning for Real-Time Execution on Mobile Devices,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020.
[18] T. Tan and G. Cao, “Efficient Execution of Deep Neural Networks on Mobile Devices with NPU,” in Proceedings of the 20th International Conference on Information Processing in Sensor Networks (IPSN ’21), New York, USA, 2021, pp. 283–298, doi: https://doi.org/10.1145/3412382.3458272.
[19] Y. Kondratenko, O. Gerasin, O. Kozlov, A. Topalov, B. Kilimanov, “Inspection mobile robot’s control system with remote IoT-based data transmission,” Journal of Mobile Multimedia, vol. 17, is. 4. pp. 499–522, 2021, doi: 10.13052/jmm1550-4646.1742.
[20] Y. Kondratenko, I. Atamanyuk, I. Sidenko, G. Kondratenko, S. Sichevskyi, “Machine Learning Techniques for Increasing Efficiency of the Robot’s Sensor and Control Information Processing,” Sensors 2022, 22, 1062, https://doi.org/10.3390/s22031062.
[21] M. Tetyana, Y. Kondratenko, I. Sidenko, G. Kondratenko, “Computer Vision Mobile System for Education Using Augmented Reality Technology,” Journal of Mobile Multimedia, vol. 17, is. 4. pp. 555–576, 2021, doi: 10.13052/jmm1550-4646.1744.
[22] R.J. Duro et al., Eds.: Advances in Intelligent Robotics and Collaboration Automation, Series on Automation, Control and Robotics, River Publishers, Denmark, 2015.
[23] I. Sidenko et al., “Eye-Tracking Technology for the Analysis of Dynamic Data,” in Proceedings of 2018 IEEE 9th International Conference on Dependable Systems, Services and Technologies, DESSERT 2018, pp. 509–514, doi: 10.1109/DESSERT.2018.8409181.
[24] V. Zinchenko et al., “Computer Vision in Control and Optimization of Road Traffic,” in Proceedings of the 2020 IEEE 3rd International Conference on Data Stream Mining and Processing, DSMP 2020, 2020, pp. 249–254.
[25] Y.P. Kondratenko, V.M. Kuntsevich, A.A. Chikrii, V.F. Gubarev, Eds.: Advanced Control Systems: Theory and Applications. Series in Automation, Control and Robotics; River Publishers: Gistrup (2021), ISBN: 9788770223416.
Biographies

Oleksandr Striuk, Ph.D. student in Computer Science and researcher at Petro Mohyla Black Sea National University (PMBSNU). Master of Science in System Analysis/Computer Science, Master of Arts in Forensic Science and Law. His research areas include AI, machine learning, cybersecurity, digital forensics, mobile security, data protection.

Yuriy Kondratenko, Doctor of Science, Professor, Honour Inventor of Ukraine (2008), Corr. Academician of Royal Academy of Doctors (Barcelona, Spain), Head of the Department of Intelligent Information Systems at Petro Mohyla Black Sea National University (PMBSNU), Ukraine. He has received (a) the Ph.D. (1983) and Dr.Sc. (1994) in Elements and Devices of Computer and Control Systems from Odessa National Polytechnic University, (b) several international grants and scholarships for conducting research at Institute of Automation of Chongqing University, P. R. China (1988–1989), Ruhr-University Bochum, Germany (2000, 2010), Nazareth College and Cleveland State University, USA (2003), (c) Fulbright Scholarship for researching in USA (2015/2016) at the Dept. of Electrical Engineering and Computer Science in Cleveland State University. Research interests include robotics, automation, sensors and control systems, intelligent decision support systems, and fuzzy logic.
Journal of Mobile Multimedia, Vol. 19_3, 823–838.
doi: 10.13052/jmm1550-4646.1938
© 2023 River Publishers