Design of an Optimized Self-Acclimation Graded Boolean PSO with Back Propagation Model and Cuckoo Search Heuristics for Automatic Prediction of Chronic Kidney Disease
Anindita Khade1, 2,*, Amarsinh V. Vidhate1 and Deepali Vidhate3
1Department of Computer Engineering, Ramrao Adik Institute of Technology, DY Patil University, Nerul, Maharashtra, India
2Department of Computer Engineering, SIES Graduate School of Technology, Nerul, Navi Mumbai Maharashtra, India
3Department of Biochemistry, School of Medicine DYPU, Nerul, Maharashtra, India
E-mail: aninditaac1987@gmail.com; amar.vidhate@rait.ac.in; deepali.vidhate@dypatil.edu
*Corresponding Author
Received 09 April 2023; Accepted 09 August 2023; Publication 13 October 2023
Abstract
Objectives: A kind of Artificial Neural Network (ANN) known as a Back Propagation Neural Network (BPNN) has been extensively applied in a variety of sectors, including medical diagnosis, optical character recognition, stock market forecasting, and others. Many studies have employed BPNN to create decision-support tools for doctors to use while making clinical diagnoses. Chronic Kidney Disease (CKD) is one such kind of disease which has been receiving due importance from the past decades due to lack of symptoms in its early stages. The goal of this work is to demonstrate the performance of Artificial Intelligent (AI) algorithms in the early detection of CKD.
Method: We received 800 patients’ real-time data from DY Patil Hospitals for this investigation. Self-Acclimation Graded Boolean PSO (SAG-BPSO), a modified version of Particle Swarm Optimization (PSO), has been proposed and used in this study to accomplish feature selection. Cuckoo Search Algorithm (CSA) has been used to optimise the weights and biases of the BPNN. Finally, this hybrid model is combined with BPNN for final predictions. Finally, a comparison is made between few state of art algorithms and the proposed approach.
Results: The accuracy noted on applying BPNN on the dataset was approximately 91.45%. The combined model of BPNN+SAGBPSO provided an accuracy of about 92.25%. The accuracy achieved for the hybrid model of BPNN+SAGBPSO+CSA was approximately near to 98.07%.
Conclusions: This research used SAGBPSO for feature selection and CSA for finalizing the weights and biases of BPNN. The research implemented BPNN, BPNN+SAGBPSO and BPNN+SAGBPSO+CSA on our real time dataset. The proposed hybrid model BPNN+SAGBPSO+CSA outperformed all the state of art deep learning algorithms in terms of performance metrics.
Keywords: CKD, prediction, deep learning, back propagation networks, particle swarm optimization, cuckoo search algorithm.
1 Introduction
CKD has become a global threat from the past decade [1]. It has become one of the primary causes of death in developing countries like India. CKD occurs when your kidneys are incapable of filtering wastes from the blood. The functionality of kidney is usually denoted by a parameter known as Glomerular Filtration Rate (GFR) [2]. If the eGFR (estimated Glomerular Filtration Rate) is less than 60 ml/min for more than three months, we claim that a person may suffer from CKD. The problem which the physicians have faced in the past decade is that this kind of diseases are to some extent asymptomatic [3]. This creates a big challenge for the doctors to predict and curb this disease at an early stage. Any patient who slips into the stage 4 of CKD has very high changes of moving into the stage 5 which is otherwise known as End Stage Renal Disease (ESRD). The mortality rate for people moving into ESRD stage is quite high in developing countries like India [4]. Moreover, the costs associated with these kinds of diseases is quite high. The financial burden of dialysis and subsequent transplantations is very huge in the developing countries [4]. Research has proved that there is a lot of potential in data mining techniques if they are explored for detection of such kind of dreadful diseases. Researchers have implemented many Machine Learning(ML) algorithms which have been used in the prediction of multiple diseases like Cancer [5], Brain Tumours [6] etc. Advanced metaheuristic algorithms which are biologically inspired have been observed to provide better results as compared to the traditional algorithms [7]. Human errors can be reduced to a great extent with the integration of Expert Decision Support systems with Electronic Health Records (EHR) [8]. This has evidentially improvised patient outcomes. Back Propagation Neural Networks (BPNN) are kind of networks which fine tune their weights based on the error received from the previous epoch. Since, backpropagation networks keep on updating their weights and learn from their errors, they provide a better and reliable model for any kind of classification problem [9]. BPNN with more than two layers have been used widely under many applications [9]. Isa et al. [10] proposed a hybrid Multilayer Perceptron (MLP) network where the authors combined the clustering approach from Radial Basis Function (RBF) and combined it with the MLP. They then tested their approach on seven benchmark datasets present in the UCI machine learning repository. The authors further compared their approach with twelve different classifiers and concluded that their proposed approach is better as compared to the other classifiers. Hornik et al. [11] in their research conducted an in depth study of multilayer feed forward networks and concluded that feed forward networks are the best known approximators. The authors in [12] proposed a hybrid Feed Forward network where they combined Gravitational Search Algorithm (GSA) with PSO for optimization of the weights and bias factors respectively. They also implemented Fuzzy rules with the GSA for improvising the output of the classifier. The authors implemented these algorithms on CKD as well as Mesothelioma (MES) dataset available on University of California, Irvine(UCI) machine learning repository. The study explored various combinations of models on the given datasets and concluded that their proposed hybrid approach was better as compared to the others. The authors in [13] proposed an adaptive conjugate gradient learning algorithm which can be used for training the multilayer feed forward networks. The authors suggested approaches for updations in the momentum and learning rate of the network by introduction of their algorithm. The further analysis showed that the adaptive neural network performed well as compared to the traditional back propagation network. The authors in [14] proposed an introduction of Marquardt algorithm for training Backpropagation algorithms. They compared the algorithms with conjugate gradient algorithm and learning rate algorithm. They concluded that the proposed approach was superior as compared to the others. A lot of research has been carried out for finding out the contributions of different Genetic Algorithm (GA) in the field of decision-making. Adem K [15] in his research explored the importance of using PSO as a feature selection method. The author tested various algorithms like Support Vector Machines (SVM), k-Nearest Neighbours (kNN) and Radial Basis Functions (RBF) and Random Subspace algorithms. They compared the accuracy of these algorithms with and without the introduction of PSO in it. The author concluded that the introduction of a feature selection module with the Random Subspace algorithm provided the maximum accuracy. Rustam et al. [16] in their work proposed a combination of SVM-RFE (Recursive Feature Elimination) for detection of CKD from the gene expression data available on National Centre for Biotechnology (NCBI). They explored the use of PSO for the gene selection task. They later compared the hybrid algorithms and concluded that the inclusion of PSO in the model (RPSO) had a positive effect on the overall performance of the system. The authors in [17] used a combined approach of Artificial Neural Networks (ANN) and PSO for behavioural predictions along with structural optimizations for honeycomb sandwich heliostats. The study concluded that the combined effect of ANN-PSO provide a flexible and a time efficient tool for predicting the structural optimizations for heliostat designers as per the requirements. The authors [18] in their research analyzed the disadvantages of PSO as in the algorithms starts converging near the global optima. To overcome this issue the researchers combined the PSO algorithm with Neural Networks which are trained using Gradient Descent Algorithm. After significant comparisons, the authors concluded that this hybrid approach was better as compared to Adaptive PSO in terms of convergence and accuracy. It is usually an overhead for the Neural Networks to decide on the required biases and weights while updations, in case of error. To curb this issue, Mohapatra et al., [19] in their research proposed a modified heuristic algorithm called Modified Cuckoo Search Algorithm (CSA) which was responsible for adjustment of the weights. The authors tested the above said algorithm on four benchmark datasets from UCI machine learning algorithms. The authors implemented Multilayer Perceptron (MLP-CSA) and Radial Basis Function (RBF-CSA) and concluded that these algorithms were superior as compared to their older versions. The authors Rohit S et al., [20] in their research provided an empirical analysis of problems faced by the traditional versions of Cuckoo Search algorithms. Moving in the direction they proposed three different versions of Cuckoo Search algorithms. These revised versions were compared with 24 datasets with different number of attributes. Moreover, these algorithms were compared with basic state of art algorithms like Flower Pollination Algorithm (FPA), Bat Algorithm (BA) etc. The analysis demonstrated the proposed versions performed better than the state of art algorithms.
This paper presents an empirical evaluation of a hybrid model consisting of Back Propagation algorithm with meta heuristic algorithm Cuckoo Search Algorithm for weight and bias updations for early predictions of CKD. Further, this model is trained using an optimization algorithm named Self Acclimation Graded Binary Particle Swarm Optimization (SAGBPSO).
The contributions of this research are as follows:
(1) A hybrid model is proposed (BPNN-CSA) which uses Cuckoo Search algorithm to predict the weights of Back Propagation Networks.
(2) An advanced version of PSO called as SAGBPSO has been proposed which uses advanced heuristics in feature selection.
(3) An empirical evaluation of these algorithms has been performed on the CKD dataset (BPNN+SAGBPSO+CSA).
(4) A comparison of all these algorithms with the state of art algorithms have been performed based on performance metrics.
The structure of this paper is as follows. Section 2 provides a description of the data used in this research and the suggested methodology. The implementation’s outcomes and comparisons with several state-of-the-art models are discussed in Section 3. Section 4 talks about the conclusion and the future works.
2 Methods and Tools
2.1 Dataset Details
The dataset of patients was received from DY Patil Hospitals, Nerul, Navi Mumbai. The dataset consisted of 800 records collected over a period of 2 years from January 2021 to December 2022. It was a completely balanced dataset with 400 records of CKD patients and 400 of non-CKD patients respectively. All ethical protocols have been followed while gathering data.
The dataset included 21 decision making attributes and 1 classification attribute. These are the attributes which are tested by clinicians for determination of CKD. The attributes and their details are presented in Table 1.
Table 1 Attributes contributable to CKD with their acceptable ranges
| Features | Units | Acceptable Ranges | Observed Ranges from Real Time Data |
| age | – | 25–60 | 25–60 |
| gender | – | M-Male F-Female | M-Male F-Female |
| vol | ml | 2–7 ml | 2–5 ml |
| sg | mg/dl | 0–1.25 | 0–1.25 |
| freq | ml | 0–7 | 0–5 |
| sod | mg/dl | 0–177 | 0–163 |
| pot | mEq/L | 0–55 | 0–47 |
| chlo | mEq/L | 0–76 | 0–76 |
| phos | mEq/L | 0–89 | 0–83 |
| prot | gms | 0–12 | 0–9 |
| alb | gms | 0–10 | 0–5 |
| glob | gms | 0–15 | 0–7 |
| urea | mgs/dl | 0–197.2 | 4.75–183.3 |
| creatinine | mgs/dl | 0–26.2 | 0–11.4 |
| bun | mgs/dl | 0–183 | 0–165 |
| uric acid | mEq/L | 0–421 | 0–391 |
| rbc | millions/cmm | 3.0–12.0 | 5.0–9.0 |
| wbc | cells/cumm | 2.0–15.0 | 6.0–11.0 |
| pcv | cells/cumm | 0–73 | 0–54 |
| pe | – | yes,no | yes,no |
| ane | – | yes,no | yes,no |
| classification | – | ckd/notckd | ckd/notckd |
2.2 Pre-processing Techniques
The data received from the hospital was not standardized for using in back propagation algorithms. As a result, we had to perform basic pre-processing techniques on the dataset. They have been explained in the following paragraph. This dataset had total of 18 nominal attributes and 3 categorical attributes.
(i) Handling Missing Data
Few of the records had missing data under some attributes. The best way to avoid the same is to delete those records. But the dataset size was less, as a result, we computed those values by mean imputation method. In this method, the missing entries were replaced by the mean of those columns. This was possible only for the nominal attributes.
(ii) Data Encoding
Categorical values had to be converted to numerical values for ease of calculations. As a result, we replaced the yes/no in the categorical values as 1 and 0 respectively.
(iii) Data Standardization
For further ease of calculations and to maintain a standardization on the data received, we implemented normalization techniques under which all the data got scaled between 1 and 1 respectively.
2.3 Particle Swarm Optimization (PSO)
It is a kind of heuristic technique which tries to design an optimal solution by keeping in mind the movement of birds in search of food.
By recreating the movement and clustering of birds, the heuristic technique known as Particle Swarm Optimization (PSO) determines the ideal solution. Another way to describe it is as a social psychology-based algorithm. The essential concept of PSO, according to Kennedy and Eberhart [21], is to presume that a flock of birds is present in a specific area. The flock gradually approaches the single food source in the area by following the bird closest to it, changing its search orientation, and exchanging information through messages with one another. The fundamental idea behind PSO is that a single particle can determine the best solution (P) for the particle by itself, and a group of particles can determine the best solution (G) by interacting with one another [22]. Each particle modifies the direction of search and velocity in each iteration depending on its own impulse (P) and (G).
The position and velocity for particle i in a p-dimensional search space are defined as by Equations (1) and (2) respectively.
| (1) | ||
| (2) |
Where x and v are the position and the velocity of the particles respectively.
These parameters are reformed with the help of the Equation (3):
| (3) |
Where is the maximum number of iterations carried out and is the weight of inertia.
The velocity updation is done using Equation (2.3)
Here c1 and c2 are the two coefficients, r is any random number, represents the position of the particle, is the optimal position and in the optimal best.
And position updations are done using Equation (5)
| (5) |
2.3.1 BPSO
Binary PSO is a technique in which position of a particle is determined by binary values (0 or 1) instead of discrete values [23]. A particle’s velocity is determined by both its own experience and the experience of other particles. Each particle’s velocity is determined using its prior velocity, personal best (pBestPos), and global best (gBestPos). The objectives of BPSO have been achieved by super imposing sigmoidal activation function on the discretized velocity.
This type of system may face the problem of convergence.
2.3.2 Proposed-SAGBPSO
Providing a solution over the same we propose our advanced PSO algorithm named as SAGBPSO-Self Acclimation based Binary PSO, which will follow a hierarchical structure.
In this algorithm, we divide all the particles into two groups masters and slaves [31]. Every particle with a high fitness value is marked as master and the others are slaves. While processing, if any slave gets a better fitness value as compared to its current master, the slave gets updated to become a master now. The slaves are trained to follow their masters only. Updations on the pBestPos and gBestPos was made based on the following rules:
(1) If the fitness value of particle x is lower than the fitness value of pBestPos, set pBestPos of particle x to the location of particle x.
(2) If any pBestPos is changed and its fitness criteria falls below the fitness criteria of the current gBestPos, set gBestPos to the updated pBestPos of particle x.
2.4 Cuckoo Search Algorithm (CSA)
The cuckoo search method is thought to be the most effective meta-heuristic optimization technique, driven by the cuckoo birds’ obligate brood parasitism behaviour. Therefore, to improve the BPNN weights for future use in the prediction process, CSA employing Levy flights is examined in the current research [24]. The nest of another bird is used by cuckoos to lay its eggs [24]. If these eggs are identified as being strange, they can either be accepted or discarded. The cuckoo eggs are highly likely to resemble the host bird’s eggs, which lowers the likelihood that they will be discovered. The method then employs the random walk-through Levy flight behaviour [32]. The algorithmic rules are as follows.
(1) Every cuckoo lays a single egg at a time and places it in a random nest.
(2) The best nests with top-notch solutions (eggs) will endure to the following iteration.
(3) It is assumed there are a set number of host nests available. A probability P which has only two options [0,1] is used to realize a foreign egg host.
The updation of the weights using Levy Flight algorithm is done using Equation (6).
| (6) |
Where is the new updated weight, is the old weight, is the learning rate and is the Levy distribution for any specified random walk.
2.5 Back Propagation Neural Networks
The back propagation algorithm is a weight adjustment training algorithm used to reduce output error in neural networks [25]. After one epoch, the predicted output is compared to the expected output, and error is produced depending on the difference. This error spreads throughout the network backward. The error is adjusted, and this process repeats upto the time a higher accuracy is not achieved [26]. There are total four types of Back propagation Networks namely Levenberg Marquardt, Bayesian regularization, Resilient Back Propagation and Scaled Conjugate.
We tried and implemented all the four algorithms on our real time dataset.
The results have been depicted in Figure 1.
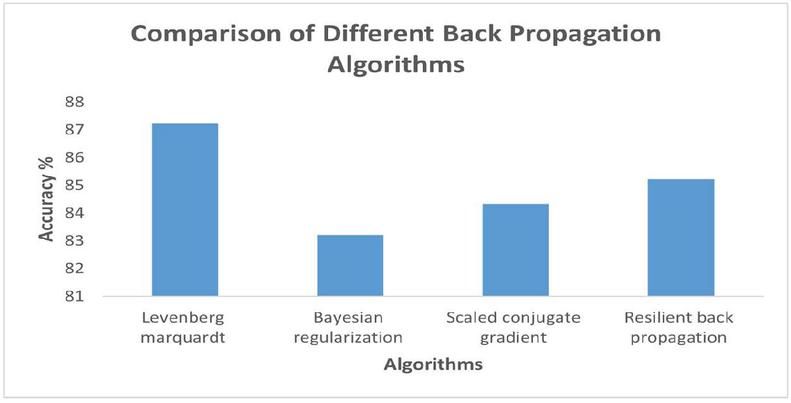
Figure 1 Performance of various back propagation algorithms.
Also, we tested the above said algorithms for their training time. This can be depicted from Table 2.
Table 2 Performance of various back propagation algorithms
| Algorithm | Training Time in ms |
| Levenberg Marquardt | 5.35 |
| Scaled Conjugate | 8.67 |
| Bayesian Regularization | 13.78 |
| Resilient Backpropagation | 22.32 |
We have used Levenberg Marquardt in our research since it gave us the best performance.
2.6 Development of Proposed Hybrid Models
We have applied SAGBPSO and CSA to the BPNN network for getting optimal results. These mechanisms are referred to as BPNN+SAGBPSO and BPNN+SAGBPSO+CSA respectively. The second phase was to perform a comparative analysis of all the methods and verify the advantages we receive when introducing our proposed model.
2.6.1 BPNN+SAGBPSO
The input layer in the dataset that was received had 21 variables, the hidden layer neurons are set to have 12 layers, and the final output layer is either labelled as CKD or NON CKD. A PSO contains 60 particles, each of which is positioned by use of a matrix. The best weights and biases are determined in the subsequent steps.
1. The results of PSO are significantly influenced by the particle’s individual acceleration coefficient (a1), the acceleration coefficient of the participating group (a2), the maximum weight of inertia (), and the minimum weight of inertia () [12].
Table 3 Parameter selection for SAGBPSO
| a1 | a2 | ||
| 2 | 2 | 0.7 | 0.3 |
2. Initial particle velocity and position are determined by random numbers, with values ranging from 0 to 1.
3. Use Equation (3) to compute the output from the input layer to the hidden layer, and then Equation (8) to determine the final outcome from the hidden layer to the output layer. The output is the categorization outcome determined by BPNN.
Where n represents the number of input nodes, is the weight of ith node to jth node, is the bias introduced and is the input.
| (8) |
where is the bias for output layer and is the weight of hidden layer j to output layer k.
4. Calculate each particle’s fitness value and contrast it with the fitness value from the previous iteration. The current particle position becomes the new if the initial adaptive value is superior.
5. Compare the fitness values of 60 particles. Within them, the population-optimal solution G is the least of them.
6. As the number of iterations rises, the inertia weight P’s value will drop, allowing the particle to enhance its capacity for local exploration in a subsequent iteration.
7. Update the particles’ position and velocity using Equations (2.3) and (5).
8. Repeat the steps 5 to 7 until 400 iterations are done.
2.6.2 BPNN+SAGBPSO+CSA
To optimize BPNN, this part combines PSO and CSA. The reasons behind combining the two is that CSA has a benefit in optimization. However, there were few significant issues with CSA [27]. To address this issue, we propose a combination of PSO + CSA. This will help eradicating the issues introduced due to CSA. Parameters used for this hybrid model were
Table 4 Parameter selection for SAGBPSO+CSA
| a1 | a2 | |||
| 2 | 2 | 0.7 | 0.3 | 0.1 |
After basic pre processing techniques, the following steps were followed:
(1) Define the best(t) and worst(t) based on the above equations.
(2) Update the velocity and positions of particles using the equation using Equations (9) and (2.6.2) respectively.
| (9) | ||
| (10) |
(3) Repeat the above steps until total number of iterations are not equal to 400.
3 Results and Discussions
Performance Metrics
The above algorithms were compared using the standard performance evaluation parameters like Accuracy, Precision, Recall, F1 score, Specificity, Root Mean Square Error (RMSE) and Area Under Curve (AUC).
Table 5 Performance evaluation of hybrid model
| Model | Accuracy | Precision | Recall | F1 Score | Specificity | RMSE | AUC |
| BPNN | 91.45 | 91.36 | 91.17 | 91.76 | 91.34 | 0.3321 | 0.715 |
| BPNN+PSO | 91.47 | 91.06 | 92.17 | 91.16 | 91.44 | 0.4321 | 0.725 |
| BPNN+SAGBPSO | 92.25 | 92.73 | 92.56 | 93.32 | 94.12 | 0.4312 | 0.671 |
| BPNN+SAGBPSO+CSA | 98.07 | 98.43 | 98.43 | 98.12 | 98.12 | 0.8316 | 0.732 |
The performance of the models is mainly dependent on the number of particles and number of iterations used while optimization. System Performance in terms of system accuracy based on varying number of particles for Max 400 iterations is depicted in Table 6.
Table 6 Performance for 400 iterations
| Number of Particles/No of Iterations | 20 | 40 | 60 |
| BPNN | 90.25 | 91.43 | 91.50 |
| BPNN+SAGBPSO | 92.34 | 92.22 | 93.67 |
| BPNN+SAGBPSO+CSA | 98.12 | 98.07 | 98.54 |
Parameters for analysis were number of particles selected for further decision making. We tested the two hybrid models each for 20, 40 and 60 particles.
To check the feature selection ratio, we compared PSO and proposed SAGBPSO to determine the number of selected features. The results of the same are depicted in Table 7.
Table 7 Features selected from PSO and SAGBPSO
| Algorithms | No. of Features Selected |
| PSO | 9 |
| SAGBPSO | 4 |
To verify whether inclusion of CSA has benefited in the faster updation of weights and biases and subsequently faster predictions, we tested the time required for results with and without inclusion of CSA. The findings are depicted in Table 8.
Table 8 Time taken for prediction
| Algorithms | Time Taken in ms |
| BPNN | 24.09 ms |
| BPNN+CSA | 13.87 ms |
To further set up the comparison of our model with the existing state of art models, we tested our model on the CKD Dataset available online at the UCI machine learning repository [27]. This dataset consisted of 400 records (150 CKD and 250 Non CKD patients). This dataset had total 25 attributes. The algorithms under considerations were Support Vector Machines (SVM), Naive Bayes (NB), Logistic Regression (LR), Artificial Neural Networks (ANN), XGBoost (XGB), K Nearest Neighbors (KNN) and Decision Tree (DT). The results depicted in Figure 2 show that our proposed hybrid model (BPNN+SAGBPSO+CSA) performed exceptionally well as compared to the current models for the benchmark dataset too.
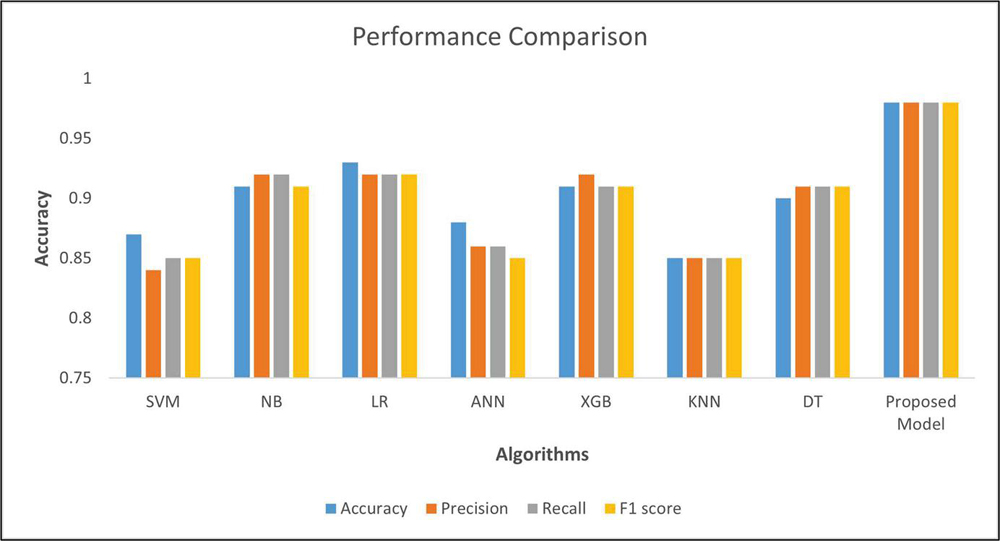
Figure 2 Comparison of proposed model with state of art models.
Further we present a comparative analysis between the works presented by multiple literatures and our proposed approach in Table 9. The analysis shows that, the proposed approach is a superior model as compared to the others.
Table 9 Comparisons with other works presented in literature
| Study | Models Explored | Accuracy | Precision | Recall | F1 Score |
| [28] | (Random Forest) RF | 93.7 | 93.9 | 92.5 | 93.7 |
| SVM | 92.9 | 91.1 | 92.7 | 91.8 | |
| DT | 93.5 | 93.4 | 93.6 | 92.5 | |
| [29] | SVM | 92.0 | 96.0 | 87.0 | 92.0 |
| K NN | 92.0 | 98.0 | 88.0 | 92.0 | |
| [30] | NB | 94.0 | 95.0 | 94.0 | 94.0 |
| KNN | 65.0 | 65.0 | 65.0 | 65.0 | |
| SVM | 93.0 | 93.0 | 94.0 | 93.0 | |
| Proposed Study | BPNN | 91.45 | 91.36 | 91.17 | 91.34 |
| BPNN+SAGBPSO | 92.25 | 92.73 | 92.56 | 93.32 | |
| BPNN+SAGPSO+CSA | 98.07 | 98.43 | 98.43 | 98.12 |
From the results, we can see that the proposed hybrid model outperforms all the other traditional models which have been described in the literature. This type of approach will in turn help the medical fraternity in early diagnosis of dreadful diseases like CKD.
4 Conclusions
This research focused on using a hybrid self-learning BPNN for prediction of CKD. We have also proposed and used SAGBPSO, which is a variant of PSO and CSA for optimization of weights and biases of BPNN. Both the proposed models (BPNN + SAGBPSO) and (BPNN + SAGBPSO + CSA) gave sound accuracy when supplied with real time data. The proposed models proved to be better in terms of performance metrics as compared to all the standard algorithms described in the study when executed on the online dataset available.
Few limitations associated with any DL algorithm is that the size of the data always remains a constraint. We have worked on only 800 records; hence performance may vary if the size of data varies. Moreover, with further advancement in time, there may be few more new parameters which can help in faster prediction of CKD. Our study is based on a limited set of parameters.
Future Works can be in the direction of using the other heuristic optimization algorithms like Ant Colony Optimization (ACO), Simulated Annealing (SA), Genetic Algorithms (GA) for the prediction of CKD or any other diseases. Moreover, unsupervised algorithms also can be explored to understand their contribution in prediction of CKD.
References
[1] V. A. Luyckx, M. Tonelli, and J. W. Stanifer, ‘The global burden of kidney disease and the sustainable development goals’, Bull. World Health Organ., vol. 96, no. 6, pp. 414–422D, Jun. 2018.
[2] ‘Chapter 1: Definition and classification of CKD’, Kidney Int. Suppl. (2011), vol. 3, no. 1, pp. 19–62, Jan. 2013.
[3] C. Weber et al., ‘Optimized identification of advanced chronic kidney disease and absence of kidney disease by combining different electronic health data resources and by applying machine learning strategies’, J. Clin. Med., vol. 9, no. 9, p. 2955, Sep. 2020.
[4] P. Saravanan and N. C. Davidson, ‘Risk assessment for sudden cardiac death in dialysis patients’, Circ. Arrhythm. Electrophysiol., vol. 3, no. 5, pp. 553–559, Oct. 2010.
[5] K. Kourou, T. P. Exarchos, K. P. Exarchos, M. V. Karamouzis, and D. I. Fotiadis, ‘Machine learning applications in cancer prognosis and prediction’, Comput. Struct. Biotechnol. J., vol. 13, pp. 8–17, 2015.
[6] F. M. Refaat, M. M. Gouda, and M. Omar, ‘Detection and classification of brain tumor using machine learning algorithms’, Biomed. Pharmacol. J., vol. 15, no. 4, pp. 2381–2397, Dec. 2022.
[7] A. Darwish, ‘Bio-inspired computing: Algorithms review, deep analysis, and the scope of applications’, Futur. Comput. Inform. J., vol. 3, no. 2, pp. 231–246, Dec. 2018.
[8] R. T. Sutton, D. Pincock, D. C. Baumgart, D. C. Sadowski, R. N. Fedorak, and K. I. Kroeker, ‘An overview of clinical decision support systems: benefits, risks, and strategies for success’, NPJ Digit. Med., vol. 3, no. 1, p. 17, Feb. 2020.
[9] N. Borisagar, D. Barad, and P. Raval, ‘Chronic kidney disease prediction using back propagation neural network algorithm’, in Advances in Intelligent Systems and Computing, Singapore: Springer Singapore, 2017, pp. 295–303.
[10] N. A. Mat Isa and W. M. F. W. Mamat, ‘Clustered-Hybrid Multilayer Perceptron network for pattern recognition application’, Appl. Soft Comput., vol. 11, no. 1, pp. 1457–1466, Jan. 2011.
[11] K. Hornik, M. Stinchcombe, and H. White, ‘Multilayer feedforward networks are universal approximators’, Neural Netw., vol. 2, no. 5, pp. 359–366, Jan. 1989.
[12] M.-L. Huang and Y.-C. Chou, ‘Combining a gravitational search algorithm, particle swarm optimization, and fuzzy rules to improve the classification performance of a feed-forward neural network’, Comput. Methods Programs Biomed., vol. 180, no. 105016, p. 105016, Oct. 2019.
[13] H. Adeli and S. L. Hung, ‘An adaptive conjugate gradient learning algorithm for efficient training of neural networks’, Appl. Math. Comput., vol. 62, no. 1, pp. 81–102, Apr. 1994.
[14] M. T. Hagan and M. B. Menhaj, ‘Training feedforward networks with the Marquardt algorithm’, IEEE Trans. Neural Netw., vol. 5, no. 6, pp. 989–993, 1994.
[15] K. Adem, ‘Diagnosis of chronic kidney disease using random subspace method with particle swarm optimization’, Uluslar. Muhendis. Arast. Ve Gelistirme Derg., vol. 10, no. 3, pp. 1–5, Dec. 2018.
[16] Z. Rustam, M. A. Syarifah, and T. Siswantining, ‘Recursive Particle Swarm Optimization (RPSO) schemed support vector machine (SVM) implementation for microarray data analysis on Chronic Kidney Disease (CKD)’, IOP Conf. Ser. Mater. Sci. Eng., vol. 546, no. 5, p. 052077, Jun. 2019.
[17] S. O. Fadlallah, T. N. Anderson, and R. J. Nates, ‘Artificial neural network–particle swarm optimization (ANN-PSO) approach for behaviour prediction and structural optimization of lightweight sandwich composite heliostats’, Arab. J. Sci. Eng., vol. 46, no. 12, pp. 12721–12742, Dec. 2021.
[18] M. M. Noel, ‘A new gradient based particle swarm optimization algorithm for accurate computation of global minimum’, Appl. Soft Comput., vol. 12, no. 1, pp. 353–359, Jan. 2012.
[19] P. Mohapatra, S. Chakravarty, and P. K. Dash, ‘An improved cuckoo search based extreme learning machine for medical data classification’, Swarm Evol. Comput., vol. 24, pp. 25–49, Oct. 2015.
[20] R. Salgotra, U. Singh, and S. Saha, ‘New cuckoo search algorithms with enhanced exploration and exploitation properties’, Expert Syst. Appl., vol. 95, pp. 384–420, Apr. 2018.
[21] A. Kumar, N. Sinha, A. Bhardwaj, and S. Goel, ‘Clinical risk assessment of chronic kidney disease patients using genetic programming’, Comput. Methods Biomech. Biomed. Engin., vol. 25, no. 8, pp. 887–895, Jun. 2022.
[22] A. G. Gad, ‘Particle Swarm Optimization algorithm and its applications: A Systematic Review’, Arch. Comput. Methods Eng., vol. 29, no. 5, pp. 2531–2561, Aug. 2022.
[23] Z. Kou and L. Xi, ‘Binary particle swarm optimization-based association rule mining for discovering relationships between machine capabilities and product features’, Math. Probl. Eng., vol. 2018, pp. 1–16, Oct. 2018.
[24] A. S. Joshi, O. Kulkarni, G. M. Kakandikar, and V. M. Nandedkar, ‘Cuckoo search optimization- A review’, Mater. Today, vol. 4, no. 8, pp. 7262–7269, 2017.
[25] J. Parab, M. Sequeira, M. Lanjewar, C. Pinto, and G. Naik, ‘Backpropagation neural network-based machine learning model for prediction of blood urea and glucose in CKD patients’, IEEE J. Transl. Eng. Health Med., vol. 9, p. 4900608, May 2021.
[26] C. Mondol et al., ‘Early prediction of chronic kidney disease: A comprehensive performance analysis of deep learning models’, Algorithms, vol. 15, no. 9, p. 308, Aug. 2022.
[27] E. M. Senan et al., ‘Diagnosis of chronic kidney disease using effective classification algorithms and Recursive Feature Elimination techniques’, J. Healthc. Eng., vol. 2021, p. 1004767, Jun. 2021.
[28] D. A. Debal and T. M. Sitote, ‘Chronic kidney disease prediction using machine learning techniques’, J. Big Data, vol. 9, no. 1, Nov. 2022.
[29] V. Singh, V. K. Asari, and R. Rajasekaran, ‘A deep neural network for early detection and prediction of Chronic Kidney Disease’, Diagnostics (Basel), vol. 12, no. 1, p. 116, Jan. 2022.
[30] M. A. Islam, M. Z. H. Majumder, and M. A. Hussein, ‘Chronic kidney disease prediction based on machine learning algorithms’, J. Pathol. Inform., vol. 14, no. 100189, p. 100189, Jan. 2023.
[31] Mohammad Shabbir Alam, Siti Zura A. Jalil, Kamal Upreti, Analyzing recognition of EEG based human attention and emotion using Machine learning, Materials Today: Proceedings, Volume 56, Part 6, 2022, Pages 3349–3354, ISSN 2214-7853, https://doi.org/10.1016/j.matpr.2021.10.190.
[32] K. Upreti, N. Kumar, M. S. Alam, A. Verma, M. Nandan and A. K. Gupta, “Machine Learning-based Congestion Control Routing Strategy for Healthcare IoT Enabled Wireless Sensor Networks,” 2021 Fourth International Conference on Electrical, Computer and Communication Technologies (ICECCT), 2021, pp. 1–6, doi: 10.1109/ICECCT52121.2021.9616864.
[33] Palanikkumar, D., Upreti, K., Venkatraman, S., Suganthi, J. R., Kannan, S. et al. (2022). Fuzzy Logic for Underground Mining Method Selection. Intelligent Automation & Soft Computing, 32(3), 1843–1854.
[34] A. Singh, D. Singh, K. Upreti, V. Sharma, B. Singh Rathore, and J. Raikwal, “Investigating New Patterns in Symptoms of COVID-19 Patients by Association Rule Mining (ARM),” Aug. 25, 2022. https://doi.org/10.13052/jmm1550-4646.1911 (accessed Mar. 05, 2023).
[35] Kapoor, A. et al. (2023). Cardiovascular Disease Prognosis and Analysis Using Machine Learning Techniques. In: Shaw, R.N., Paprzycki, M., Ghosh, A. (eds) Advanced Communication and Intelligent Systems. ICACIS 2022. Communications in Computer and Information Science, vol. 1749. Springer, Cham. https://doi.org/10.1007/978-3-031-25088-0\_15.
Biographies

Anindita Khade is a student of PhD in Computer Engineering in RAIT under DYPU university. She is doing her research work under the guidance of Dr. Vidhate. She is also working as an Assistant Professor in SIES Graduate School of Technology, Nerul. She has over 13 years of teaching experience. She has over 25 research papers in international conferences and journals. Her areas of interest are data analytics, machine learning, artificial intelligence. She can be contacted at aninditaac1987@gmail.com.

Amarsinh V. Vidhate is working as a professor & Head, Department of computer engineering at Ramrao Adik Institute of Technology, D Y Patil deemed to be a university, Navi Mumbai, India. He has 26+ years of academic experience and almost 80+ national and international research papers, published at international conferences and referred journals. His areas of research are Protocol Stacks, Computer Networking & Security, VaNET, IoT, and healthcare applications with the assistance of AI, ML & Data Science. He is a PG guide and Ph.D. guide at the University of Mumbai and D Y Patil, Deemed to be University. His special interest is in mass education and designing content that is useful for the masses to make them employable. He is a member of professional bodies like IEEE, CSI, and ISTE. He can be contacted at amar.vidhate@rait.ac.in.

Deepali Vidhate is working as a Professor and Head of the Biochemistry Department at D Y Patil deemed to be University School of Medicine, Navi Mumbai, India. She has 25+ years of academic experience and almost 30+ national and international research papers, published at international conferences and referred journals. Her areas of research are Biomarkers for early prediction of diseases and AI, ML & Data Science applications in medicine. She is a PG guide and Ph.D. guide at the D Y Patil, Deemed to be University. She can be contacted at deepali.vidhate@dypatil.edu.
Journal of Mobile Multimedia, Vol. 19_6, 1395–1414.
doi: 10.13052/jmm1550-4646.1962
© 2023 River Publishers