Cloud Replica Management-Based Hybrid Optimization
Mohamed Redha Djebbara
Department of Mathematics and Computer Science, faculty of exact sciences and informatics, University Abdelhamid Ibn Badis Mostaganem, Algeria
E-mail: redha.djebbara@univ-mosta.dz
Received 27 December 2023; Accepted 29 July 2024
Abstract
This research addresses the challenges in cloud-based replica management by proposing a novel strategy employing a Genetically Implied Greywolf with Oppositional Learning (GIGOL) hybrid optimization technique. This approach optimizes multi-objectives such as response time, load balancing, availability, replication cost, and energy consumption, ensuring cost-effectiveness and energy efficiency. The GIGOL model integrates Genetic Algorithm, opposition learning, and Grey Wolf Optimization, aiming to achieve optimal replica placement. The study emphasizes resolving overhead issues through machine learning techniques for efficient cloud-based replica management. Performance evaluation showcases improvements in response time, load balancing, availability, replication cost, and energy consumption, highlighting the effectiveness of the proposed approach within budget constraints and management policies.
Keywords: Cloud Computing, replica management, multi-objectives, GIGOL, oppositional learning.
1 Introduction
The cloud-based storage system is nowadays obtaining tremendous popularity throughout the world, which is incorporated with massive storage space in a common platform [1]. Cloud-based data replication is an active research topic that provides an enhancement in the distribution system in terms of effective data accessing facilities [2]. The replication process generates the resemble data of the actual data, which could be from the same data center or obtaining from a different remote location [3]. Cloud replica management enables two kinds of replication processes, which execute the static service and dynamic replication service. The static replica is created based on analyzing statically during the development of the cloud storage model. Conversely, the dynamic replica is based on analyzing the historical data of the user and the capability of storage space [4].
The research related to replica management is based on utilizing an enhanced technique to obtain an optimized result based on the system bandwidth. Moreover, data availability is also a considerable factor for effective distribution in the platform of the data center [5]. The contribution of the resource manager towards the replica placement process is inevitable in data reliability management [6]. In this, the replica placement process is inevitable for mitigating time consumption, complexity in storing data, and bandwidth, etc [7]. By analyzing the previous researches related to replica management strategies, the optimization-based technique to data replica placement policies could provide a better outcome in terms of cost, load balancing, and time consumption [8]. The replica placement policies are adopted with placement rules which considered the availability of the file, the load consumption of the node, and the cost taken for transmission in the network [9].
Therefore, the need for incorporating the energy-efficient clustering approach based on dynamic replica placement is highly demanded [10, 11]. In the data nodes, the replicas will be added based on their increments, which leads to load balancing issues while the replica placement process [12, 13]. The major contribution of this research work is:
• To introduce a new multi-objective-based hybrid optimization technique for efficient cloud-based replica management. The multi-objectives like response time, load balancing, availability, replication cost, and energy consumption are taken into consideration.
• To develop a new hybrid optimization technique referred to as Genetically Implied Greywolf with Oppositional Learning (GIGOL), by incorporating the Genetic algorithm (GA), opposition learning, and Grey Wolf Optimization (GWO) technique.
• The paper discusses how static and dynamic replication methods manage waiting times, bandwidth, and system migration costs to improve cloud-based services.
• The paper provided Gentically Implied Greywolf with Oppositional Learning, a hybrid optimization method. GA, Opposition Learning, and Grey Wolf Optimization (GWO) are used to arrange replicas cost-effectively, energy-efficiently, and quickly.
The following sections are articulated based on considering the research articles in Section 2. The problem statements are highlighted in Section 3. In Section 4, the methodology of the proposed concept is explained in detail for better understanding. In Section 5, the results and discussion parts are illustrated in detail based on obtained results values in terms of performance analysis metrics. Section 6 provides a comparative analysis and finally provides the conclusion part.
2 Related Articles
This section incorporated a brief literature review based on considering several research articles in terms of the replica management process.
In this paper, Yanling Shaoa et al. [14], have developed and entitled an adaptive replica placement strategy based on proposing the dynamic replica creation algorithm. In this technique, they considered the data bloc as the data unit where access frequency is the essential considerable factor to determine the relationship between the several replicas in the dynamic environment to confirm the availability of the requirements.
In this paper, Su Peng et al. [15], have suggested a novel identity-based RDIC strategy is provided by neglecting the occupation of PKI. In this technique, a compressed authentication array is enabled EDid-MRPDP to execute sequential validation for many data owners and cloud servers have parallel accessing capabilities for effective performance. This technique provides a better dynamic updating facility and a multi-replica batch checking facility.
Carlos Guerrero et al. [16], have provided the novel technique, which is based on optimization technique for file locality determination, the check the availability of the file, and reduce the replica migration expenses in a platform of Hadoop. With this scheduling approach, the objective factors of replication management can be obtained in terms of obtaining better results.
In this paper, T. Hamrouni et al. [17], have suggested a novel approach in terms of applying data mining techniques for enhancing the grid management process. This work initially adopts the knowledge-based approach for qualifying the data replication and selection process. The considerable technique for this work is the data mining process is associated with data replication and selection policies.
In 2023, Radha et al. [18] analyzed a new M[X]/G/1 queue model with three service levels and one server. Two services are offered in the first phase. The server then provides level two services. Service disruptions are inevitable. This system anticipates a second-phase service outage. Thus, it is repaired immediately. Server maintenance vacations are added. The vacation preparation step incorporates pre-processing. The paradigm includes reneging, setup time, and standby server. System parameters are examined using numerical examples.
By analyzing various research articles, a novel technique is designed in this work to achieve an effective scheme to replica management process with the utilization of the machine learning technique.
3 Problem Statement
Replica Management in cloud computing is considered a highly demanded research topic in recent days. In this section, we provide some of the issues of the existing technology of replica management.
• The existing problem is not efficient for providing the results in terms of energy efficiency, time, and budget-oriented results.
• Node selection is essential to the process for obtaining a better data placement process; however, the existing technology may not provide a better solution for the node selection process.
• Data availability should be considered for reducing the cost during replica creation.
• Load balancing should be considered for reducing user access latency [19].
The above-mentioned problems are to be addressed by effective technology; therefore, we provide the novel technology to resolve the existing issues of replica management in cloud computing.
4 Proposed Methodology
Cloud enables a broad scale data distribution service with tremendous storage space to the remote management process. The data can be enabled as per the demand of the client from the cloud source. Cloud has been adopted with multiple replication strategy for enabling better placement policies. Data replication enhances data availability, performance enhancement by query latency, and maintains the dynamic platform in terms of an effective load balancing approach. In this work, the cloud-based replica management strategy is suggested with the utilization of a hybrid technique which is incorporated with the Genetic algorithm and Grey Wolf Optimization technique. By utilizing this hybrid technique, the optimal replica placement can be achieved in terms of cost-effective, energy-efficient, less time consumption rate. For this work, based on massive research analysis the problems are identified and focus to mitigate by this proposed approach. The following will be an insight into the overall process of this research mechanism.
Cloud-Based Replica Management
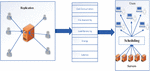
In a cloud-based environment, data sharing processes are significant and are executed in a dynamic environment. In this environment, the availability of resources is in a heterogeneous form which leads to complications. Therefore, the need for developing an effective technique to deal with the problems in existing technology by implementing the novel idea in it. This work has provided a better replication management technique to enable a better solution by adopting an effective technique. Fig1 illustrates the overall execution process of a Genetically Implied Greywolf with Oppositional Learning (GIGOL) hybrid optimization technique.
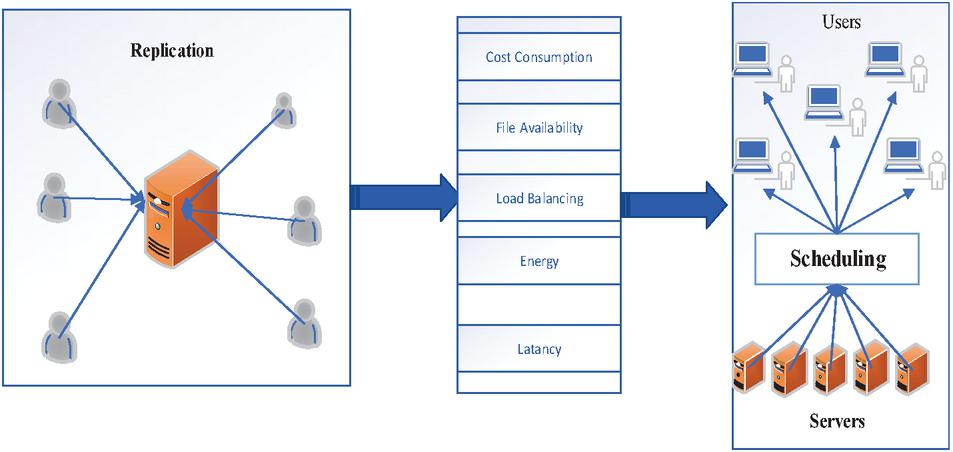
Figure 1 Multi-Objective scheduling in a dynamic cloud environment.
Grey Wolf Optimization
The significant steps of Grey Wolf Optimization are:
Stage 1: Initially produce the population randomly, and initialize parameters,
Stage 2: Calculate the fitness of the grey wolf individual, and save the first three individual’s state with the maximum fitness,
Stage 3: update each grey wolf’s position information. In this way, Getting the next generation population and then bring up-to-date the values of parameters,
Stage 4: Then calculate the fitness of new population’s individuals,
Stage 5: Do again stages 2–4 until obtaining the optimal outcome or iterations reaching the highest number.
Genetic Algorithm
In this proposed work, the Genetic Algorithm technique is utilized for enhancing the performance of the proposed system with the enabling features of the technique. The genetic algorithm provides the result based on generating the new population with the collected features of two-parent nodes.
Opposition based learning for the initial population approach
In terms of population iteration, the performance of the algorithm sets the foundation of the diversity of the beginning population for swarm intelligence optimization. The population’s improved diversity will decrease the calculation time and enhance the worldwide merging of the algorithm. Still, When producing populations, Grey Wolf Optimization uses random initialization, similar to other algorithms. The searching performance of the algorithm will get a certain impact by this. To increase the performance of algorithm search, an opposition-based learning strategy is proposed. To produce a new Individual position, it using the opposite points of known Individual positions. Thus the search population will increase their diversity. Currently presently, in several swarm optimization algorithms, the opposite based learning concept has been applied successfully. The opposite point is defined as given below:
Imagine, an individual is Z () in the population L, then the opposite point of the component on each dimension is , where and are the minor limits and the higher of the th dimension, respectively. In the state of the above classification, the Opposition-Based Learning strategy initializes the population is given below:
(a) Approximately prepare the population L. Then calculate each position ’s opposite point , and all the opposite points constitute the opposition population L.
(b) The initial population L are gauged with the opposition population L’s fitness of each individual. Then rank it in descending order.
(c) Choose the top N grey wolf individuals of the last initial population with the highest fitness.
The Optimal Retention Based Selection Process
The growth of each generation of the population is straightly affecting the optimization result of the algorithm, for the population evolution-based intelligent optimization algorithm. It is Compulsory to protect the better individuals directly, to receive the great individuals in the paternal population without being destroyed to the next generation. An effective way to protect great individuals is by using an optimal retention selection strategy in genetic algorithms. To increase the effectiveness of the algorithm, this paper merging with the Grey Wolf Optimization. Assume, the present population is L (), the fitness of the individual is . The specific operation is given below:
(a) First Calculate each individual’s Fitness . Then arrange the results in descending order.
(b) To copy the next generation of population, select the individuals with the highest fitness.
(c) Then calculate the remaining individual’s total fitness R and each selected individual’s probability .
(d) At last, calculate the individual’s cumulative fitness value . After that, the selection process is made until the number of individuals in the children population is reliable with the parent population.
The Population Partitioning Mechanism based Crossover Operation
For Cracking huge-scale high-dimensional optimization problem, due to the reduction of population diversity in the late evolution the Grey Wolf Optimization algorithm is easy for local best results, To confirm the algorithm searches for all result spaces and to overcome issues caused by huge-scale and complexity.
In the Hybrid Grey Wolf algorithm, The entire population L is divided into Sub-population ; . The best size of each sub-population was tested to be 5 x 5. To increase the diversity of the population were cross-operated the individuals of each sub-population.
The cross-operation has a very significant role in genetic algorithm. To produce new individuals this is the main way. In the enhanced algorithm of this paper, in a linear crossover manner sub-population’s each individual is cross-operated. Producing the equivalent random number for sub-population’s each individual . The equivalent individual is paired for cross-operation, when the random number is less than the crossover probability . For example: Crossover (l1,l2)
(a) Produce a random number
(b) Two parents ) and ) are produced, two children ) and ):
Elite Individual’s Mutation Process
Due to the existence of the optimal preservation strategy-based selection operation, the grey wolf individuals are focused in a minor optimal region in the later stage of the iteration process in the entire population. It will easily lead to the loss of population diversity. When solving high dimensional multimodal functions, if the present optimal individual is a locally best result, then the algorithm is easy for a local result. To perform elite individual’s mutation process in the population, this paper introduces the mutation process in Hybrid Grey Wolf Optimization. The specific process is given below:
Assume the optimal individual is and the mutation process is executed on with the mutation probability . That is select a gene from the optimal individual with probability , instead of the gene with a random number between higher and minor limits to produce an individual . The specific process is given below:
Where,
= Random no in [0,1]
= Minor limits of the individual
= Higher limits of the individual
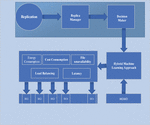
With this approach, the cloud-based replica management process can be enhanced. The fig2 provides the execution process of the proposed work. In the initial step, execute the replication process, the replica manager is acted as a decision manager. By utilizing the hybrid machine technique, all the replicas can be stored in the right location and the consequences of the system are managed effectively.
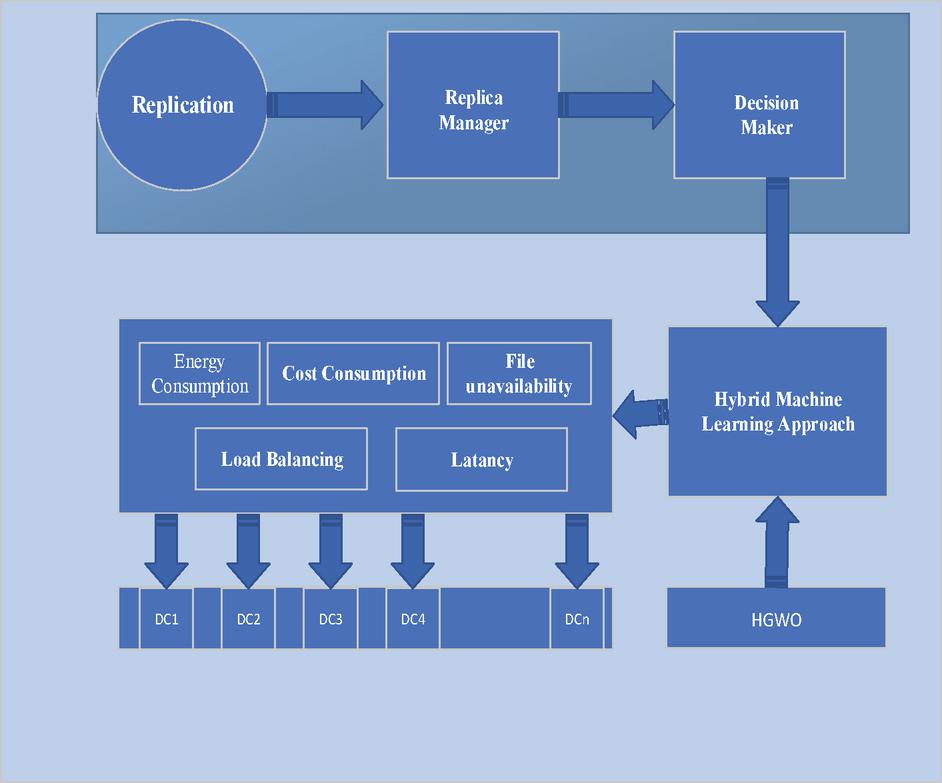
Figure 2 Illustrates the overall execution process of cloud-based replication processes.
Furthermore, the proposed technique provides a platform to deal with problems in existing technology. The GIGOL provides a better solution for optimization problems, and provide benefits by load balancing, energy consumption reduction, Cost control, time reduction, and file unavailability management. In the following section, the results obtained are shown and explained in detail. Therefore, the proposed technique can be considered as an effective technique for dealing with existing problems.
5 Result and Discussion
The results are obtained on basis of analyzing the performance of the proposed technique by the parameters such as energy consumption, time consumption, budget consideration, throughput, delivery ratio, and Latency. The results are obtained based on these metrics are tabulated in terms of the proposed technique and existing technique. Moreover, the results are obtained based on executing node based results and the rate based results analysis. Therefore, the proposed technique is proven to be more effective than existing techniques. In the following, the results are obtained based on analyzing various performance analyses such as response time, load balancing, availability, replication cost, and energy consumption. Based on considering these metrics, the proposed technique is proven to be a better technique than other existing techniques.
Table 1 Provides the results based on considering node
| Proposed GIGOL | |||||
| Node | Energy Consumption | Time Consumption | Throughput | Delivery Ration | Latency |
| 20 | 24.062211 | 0.719187 | 376 | 782.75 | 610 |
| 40 | 22.011249 | 1.359974 | 142 | 289.95 | 176 |
| 60 | 21.725402 | 1.301087 | 129 | 265.35 | 351 |
| 80 | 22.974539 | 3.084184 | 101 | 237.3875 | 2730 |
| 100 | 22.238232 | 1.683421 | 57 | 127.75 | 1320 |
| Existing technique EFTRM | |||||
| 20 | 24.753734 | 19.986463 | 43 | 450.4 | 7238 |
| 40 | 22.641715 | 35.15296 | 0 | 147.05 | 5869 |
| 60 | 22.416316 | 40.713986 | 0 | 135.55 | 8100 |
| 80 | 24.427089 | 9.964285 | 21 | 157.7375 | 9317 |
| 100 | 22.960534 | 8.964285 | 0 | 70.06 | 6985 |
Table 2 Provides the results based on considering the rate
| Proposed GIGOL | |||||
| Node | Energy Consumption | Time Consumption | Throughput | Delivery Ration | Latency |
| 100 | 21.27099 | 19.004027 | 118 | 233 | 185 |
| 200 | 21.75804 | 15.138611 | 50 | 164.25 | 108 |
| 300 | 22.205221 | 15.61962 | 41 | 155.43 | 495 |
| 400 | 21.629648 | 13.975414 | 43 | 157.9725 | 1427 |
| 500 | 22.238232 | 14.249172 | 32 | 146.214 | 1329 |
| Existing technique EFTRM | |||||
| 100 | 22.960535 | 28.664922 | 53 | 173.23 | 6985 |
| 200 | 22.945679 | 25.209163 | 36 | 156.71 | 13985 |
| 300 | 22.919517 | 23.688078 | 31 | 151.093333 | 20985 |
| 400 | 22.899769 | 22.88372 | 28 | 148.35 | 27985 |
| 500 | 22.874971 | 22.332481 | 20 | 146.644 | 34985 |
Table 1 Analysis:
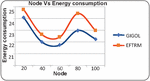
• Energy Consumption: The proposed technique generally consumes less energy than the existing technique across different nodes.
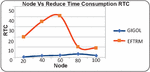
• Time Consumption: The proposed technique significantly reduces time consumption compared to the existing technique.
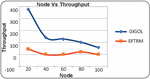
• Throughput: The proposed technique achieves higher throughput, indicating more efficient data processing.
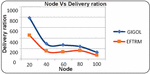
• Delivery Ratio: The proposed technique shows better delivery ratios, especially notable in lower node counts.
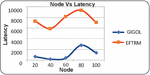
• Latency: The proposed technique demonstrates much lower latency, enhancing responsiveness and performance.
Table 2 Analysis:
• Energy Consumption: The proposed technique has slightly lower energy consumption across different rates compared to the existing technique.
• Time Consumption: The proposed technique consistently reduces time consumption across different rates.
• Throughput: The proposed technique maintains higher throughput, although it decreases as the rate increases.
• Delivery Ratio: The proposed technique generally shows a higher delivery ratio, with a slight decline at higher rates.
• Latency: The proposed technique exhibits significantly lower latency, particularly as the rate increases.
Comparative Summary
From the provided metrics and analysis, it is evident that the proposed technique outperforms the existing technique across various performance indicators, such as energy consumption, time consumption, throughput, delivery ratio, and latency. This makes the proposed technique more efficient and effective for the given applications.
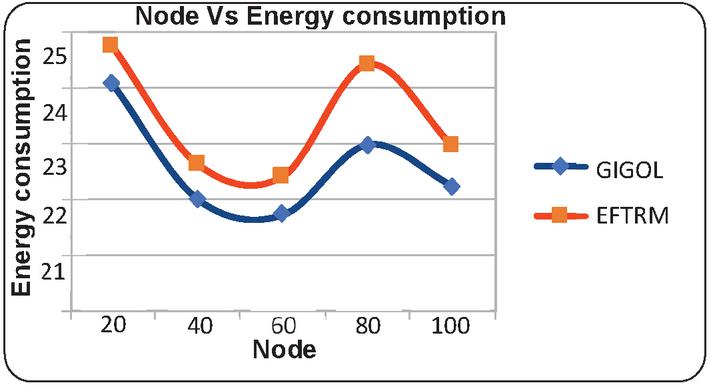
Figure 3 Illustrates the graphical results of node based on energy consumption.
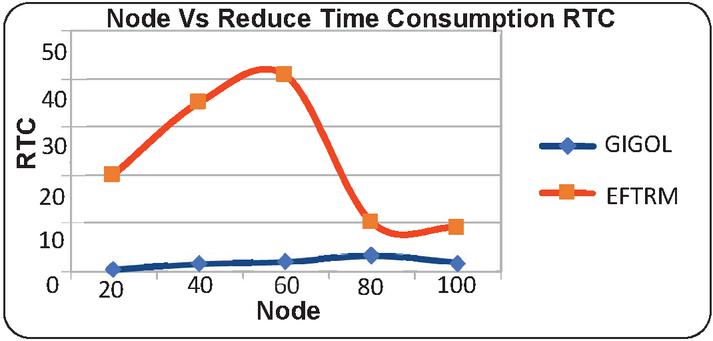
Figure 4 Illustrates the graphical results of node based on time consumption.
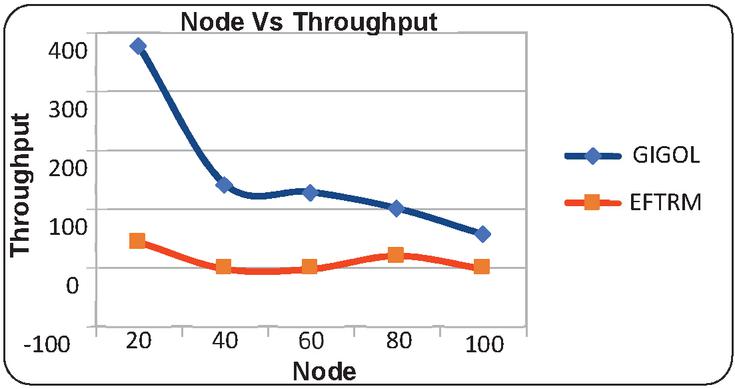
Figure 5 Illustrates the graphical results of node based on throughput.
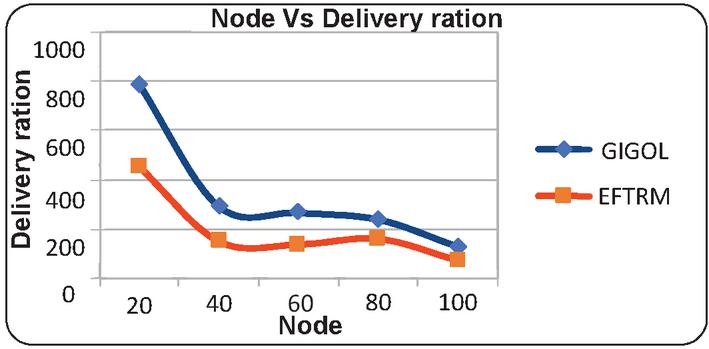
Figure 6 Illustrates the graphical results of node based on delivery ration.
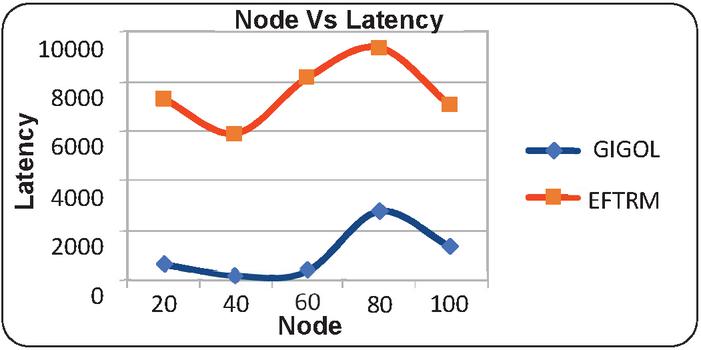
Figure 7 Illustrates the graphical results of node based on latency.
6 Comparative Analysis
This section focuses on comparative analysis based on considering the performance-based results which are compared with the existing technique with the proposed technique. In Table 1, the results are tabulated according to respective constraints which are obtained based on the node-based analysis. The node is utilized as 20, 40, 60, 80, and 100 for performance calculation. The results obtained based on analyzing energy consumption which shows the proposed technique consumes a lesser amount of energy than the existing technique. The time-based analysis is considered based on obtained results which shows less time consumption. Likewise, it would reduce and latency whereas the threshold values and the delivery ratio are high. In similar to node-based analysis, Table 2 provides results based on a rate where the rate is determined as 100, 200, 300, 400, and 500. The obtained results showed energy, time, latency is high and the remaining results are high. Therefore, the proposed work can be considered as an efficient model for the cloud replica management process. Moreover, the results are provided as graphical illustrations which come below.
Moreover, the results are compared with the existing technique, to emphasize the proposed work is effective to provide energy-efficient replica management mechanisms on the platform of the cloud.
7 Conclusion
The research field has incorporated numerous technologies to provide successful cloud services. Due to overhead difficulties, temporal complexity, high energy conception, high expense, etc., replica management is a dangerous study topic in this sector. For effective cloud-based replica management, a novel multi-objective hybrid optimization approach was presented. GIGOL combines genetic algorithm (GA), opposition learning, and Grey Wolf Optimization (GWO). This hybrid approach (GIGOL) allows for cost-effective, energy-efficient, and time-efficient replica placement. The GIGOL hybrid optimization method enhances cloud replica management theory. Genetic Algorithms, Opposition Learning, and Grey Wolf Optimization may improve the field by providing a more effective solution. Conservation is affected by duplicate management goals using energy. Green cloud service firms use GIGOL hybrid optimization to reduce energy use. Some conditions suit GIGOL hybrid optimization. It may need validation and adaptation for additional cloud environments, applications, and industries. Cloud infrastructure and workload patterns affect hybrid performance. Thus, issues may be addressed and performance evaluated based on energy consumption, budget, time, throughput, delivery ratio, and latency. Thus, the suggested replica management methodology is successful, and future improvements will focus on system performance. Examine dynamic replica management goals. To optimize response time, load balancing, and energy use, provide adaptive optimization algorithms for modifying cloud settings.
References
[1] Shao, Yanling, Chunlin Li, and Hengliang Tang. “A data replica placement strategy for IoT workflows in collaborative edge and cloud environments.” Computer Networks, Vol. 148, pp. 46–59, 2019.
[2] Peng, Su, Fucai Zhou, Jin Li, Qiang Wang, and Zifeng Xu. “Efficient, dynamic and identity-based remote data integrity checking for multiple replicas.” Journal of Network and Computer Applications, Vol. 134, pp. 72–88, 2019.
[3] Khalajzadeh, Hourieh, Dong Yuan, Bing Bing Zhou, John Grundy, and Yun Yang. “Cost-effective dynamic data placement for efficient access of social networks.” Journal of Parallel and Distributed Computing, Vol. 141, pp. 82–98, 2020.
[4] Jaradat, A., Alhussian, H., Patel, A. and Fati, S.M., 2020. Multiple users replica selection in data grids for fair user satisfaction: A hybrid approach. Computer Standards & Interfaces, 71, p. 103432.
[5] Pan, Shaoming, Lian Xiong, Zhengquan Xu, Yanwen Chong, and Qingxiang Meng. “A dynamic replication management strategy in distributed GIS.” Computers & geosciences, Vol. 112, pp. 1–8, 2018.
[6] Grace, R. Kingsy, and R. Manimegalai. “Dynamic replica placement and selection strategies in data grids—a comprehensive survey.” Journal of Parallel and Distributed Computing, Vol. 74, No. 2, pp. 2099–2108, 2014.
[7] Gharehpasha, S., Masdari, M. and Jafarian, A., 2021. Virtual machine placement in cloud data centers using a hybrid multi-verse optimization algorithm. Artificial Intelligence Review, 54, pp. 2221–2257.
[8] Li, Chunlin, YaPing Wang, Hengliang Tang, Yujiao Zhang, Yan Xin, and Youlong Luo. “Flexible replica placement for enhancing the availability in edge computing environment.” Computer Communications, Vol. 146, pp. 1–14, 2019.
[9] Xu, X., C. Yang, and J. Shao. “Data replica placement mechanism for open heterogeneous storage systems.” Procedia Computer Science, Vol. 109, pp. 18–25, 2017.
[10] Li, C., Liu, J., Lu, B. and Luo, Y., 2021. Cost-aware automatic scaling and workload-aware replica management for edge-cloud environment. Journal of Network and Computer Applications, 180, p. 103017.
[11] Li, Chunlin, YaPing Wang, Hengliang Tang, and Youlong Luo. “Dynamic multi-objective optimized replica placement and migration strategies for SaaS applications in edge cloud.” Future Generation Computer Systems, Vol. 100, pp. 921–937, 2019.
[12] Ke, X., Guo, C., Ji, S., Bergsma, S., Hu, Z. and Guo, L., 2021, September. Fundy: A scalable and extensible resource manager for cloud resources. In 2021 IEEE 14th International Conference on Cloud Computing (CLOUD) (pp. 540–550). IEEE.
[13] Hamrouni, Tarek, Sarra Slimani, and F. Ben Charrada. “A survey of dynamic replication and replica selection strategies based on data mining techniques in data grids.” Engineering Applications of Artificial Intelligence, Vol. 48, pp. 140–158, 2016.
[14] Rajput, N., Pandey, R.K. and Chauhan, A., 2022. Fuzzy optimisation of a production model with CNTFN demand rate under trade-credit policy. International Journal of Mathematics in Operational Research, 21(2), pp. 200–220.
[15] Kulshrestha, R. and Shruti, 2021. Performance evaluation of call admission control based on signal quality in cellular mobile networks. International Journal of Mathematics in Operational Research, 20(1), pp. 1–19.
[16] Guerrero, Carlos, Isaac Lera, and Carlos Juiz. “Migration-aware genetic optimization for map reduce scheduling and replica placement in hadoop.” Journal of Grid Computing, Vol. 16, No. 2, pp. 265–284, 2018.
[17] Hamrouni, Tarek, Sarra Slimani, and F. Ben Charrada. “A survey of dynamic replication and replica selection strategies based on data mining techniques in data grids.” Engineering Applications of Artificial Intelligence, Vol. 48, pp. 140–158, 2016.
[18] Radha, S., Maragathasundari, S. and Swedheetha, C., 2023. Analysis on a non-Markovian batch arrival queuing model with phases of service and multi vacations in cloud computing services. International Journal of Mathematics in Operational Research, 24(3), pp. 425–449.
[19] Li, Chunlin, YiHan Zhang, and Youlong Luo. “Adaptive Replica Creation and Selection Strategies for Latency-Aware Application in Collaborative Edge-Cloud System.” The Computer Journal, Vol. 63, No. 9, pp. 1338–1354, 2020.
Biographies

Mohamed Redha Djebbara is a teacher/researcher at the Mathematics and Computer Science Department, Faculty of exact Sciences and Computer Science at the University of Mostaganem, Algeria. He was graduated in 2001 from Computer Science Department, University of Oran1, Algeria. He received his Post graduation degree in computer science in 2010. He obtained his Phd, at the University of Science and Technology Mohamed Boudiaf USTO-MB Oran, in 2018. His research interests include Distibuted Systems, Grids, Cloud computing, Multicriteria Decision Support and Artificial Intelligence.
Journal of Mobile Multimedia, Vol. 20_4, 917–934.
doi: 10.13052/jmm1550-4646.2047
© 2024 River Publishers