Aspect Based Feature Extraction in Sentiment Analysis using Bi-GRU-LSTM Model
Shilpi Gupta1, Niraj Singhal2, Sheela Hundekari3, Kamal Upreti4,*, Anjali Gautam5, Pradeep Kumar6 and Rajesh Verma4
1Shobhit Institute of Engineering & Technology (Deemed to-be University), Meerut, 250110, India
2Sir Chhotu Ram Institute of Engineering & Technology, Chaudhary Charan Singh University, Meerut, India
3School of Engineering and Technology, Pimpri Chinchwad University, Maval Talegaon, Pune, India
4CHRIST University, Delhi NCR Campus, Ghaziabad, India
5Manav Rachna International Institute of Research & Studies, Faridabad, Haryana
6JSS Academy of Technical Education, Noida, India
E-mail: er.shilpibansal@gmail.com; drnirajsinghal@gmail.com; sheelahundekari90@gmail.com; kamalupreti1989@gmail.com; anjali.gautam09@gmail.com; pradeep8984@gmail.com; rverma.amity@gmail.com
*Corresponding Author
Received 21 July 2024; Accepted 01 September 2024
Abstract
In Natural Language Processing (NLP), Sentiment Analysis (SA) is a fundamental process which predicts the sentiment expressed in sentences. In contrast to conventional sentiment analysis, Aspect-Based Sentiment Analysis (ABSA) employs a more nuanced approach to assess the sentiment of individual aspects or components within a document or sentence. Its objective is to identify the sentiment polarity, such as positive, neutral, or negative, associated with particular elements disclosed within a sentence. This research introduces a novel sentiment analysis technique that proves to be more efficient in sentiment analysis compared to current methods. The suggested sentiment analysis method undergoes three key phases: 1. Pre-processing 2. Extraction of aspect sentiment and 3. Sentiment analysis classification. The input text data undergoes pre-processing through the implementation of four typical text normalization techniques, which include stemming, stop word elimination, lemmatization, and tokenization. By employing these methods, the provided text data is prepared and fed into the aspect sentiment extraction phase. During the aspect sentiment extraction phase, features are obtained through a series of steps, including enhanced ATE (Aspect Term Extraction), assessment of word length, and determination of cosine similarity. By following these steps, the relevant features are extracted on the basis of aspects and sentiments involved in the text data. Further, a hybrid classification model is proposed to classify sentiments. In this work, two of the Deep Learning (DL) classifiers, Bi-directional Gated Recurrent Unit (Bi-GRU) and Long Short-Term memory (LSTM) are used in proposing a hybrid classification model which classifies the sentiments effectively and provides accurate final predicted results. Moreover, the performance of proposed sentiment analysis technique is analyzed experimentally to show its efficacy over other models.
Keywords: Sentiment analysis, NLP, text processing, aspect sentiment extraction, and dl based sentiment classification.
1 Introduction
The relation between our actions and sentiments plays a crucial role in our daily lives. The process of sentiment analysis is regarded as a vital procedure for understanding the manner in which a text, such as a review, tweet, or article, conveys its expression [10]. This procedure has attention over a broad range of applications in various fields like social media, marketing, business, healthcare, etc. In terms of social media, understanding the emotions of people is beneficial for Social Networking Site (SNS) in several ways [1]. For instance, it aids in creating more space for users by engaging them in SNS platforms via recommending the posts, items or contents based on user interests [3]. It also helps platforms to understand the public opinion in terms of public figures, political campaigns and businesses. These benefits are achieved by empathetic and user-friendly human-computer interaction systems in the context of the social media [8]. This is why, sentiment analysis has been a subject of growing interest in various research domains over the years. Examples for application involves analyzing diverse public data across social media platforms are Reddit, YouTube, Facebook, Twitter and others [9]. The exploration and utilization of such data have garnered considerable attention from researchers due to its both theoretical and practical significance [5].
Sentiment analysis [25] has received substantial attention from researchers over the last decade due to its numerous practical applications. It involves the automated extraction of emotions, attitudes, and opinions from online content [2]. Many individuals actively utilize online review platforms, forums, comment’s sections on news websites, SNSs, and personal blogs to express their views, which can encompass both positive and negative sentiments towards individuals, locations, and events. These expressions of attitudes can be categorized as sentiments [7].
The increasing prevalence of social media and online social networks has led to a massive proliferation of publicly accessible user-generated data on the web. However, only a small fraction of this data is readily usable [6]. Extracting valuable insights from an extensive dataset is a challenging yet highly important task in today’s world [4]. As a result, a novel sentiment analysis method enabled by aspect-based feature extraction is proposed. The proposed sentiment analysis technique is effectively implemented by making two important contributions which are as follow:
• Proposing an enhanced way of aspect term extraction in aspect sentiment extraction phase by using Term Frequency – Inverse Document frequency (TF-IDF) vectorizer technique.
• Implementing a novel classification model by hybridizing the common Bi-GRU and LSTM classifiers to analyze sentiments.
The purpose of implementing the hybrid approach of Bi-GRU and LSTM classifiers can be explained with the help of an example. Consider a movie review, “The movie started off boring, but the ending was fantastic”. When analyzing the review, Bi-GRU captures the word context in both forward and backward directions to determine the overall sentiment. Long-term dependencies within the text can be preserved by the LSTM component, such as the sentiment conveyed at the start of an extended review. Thus, the hybrid model could provide a nuanced classification by efficiently balancing the conflicting views.
The implementation of the proposed sentiment analysis technique is structured as follows: Section 2 reviews existing works. Section 3 outlines the complete process of the proposed sentiment analysis technique, encompassing preprocessing, aspect sentiment extraction, and sentiment classification. Section 4 provides in-depth details of various experimental analyses. The research work is concluded in Section 5.
Table 1 Comparative analysis of existing work
| Author | Approach Used | Dataset Used | Performance |
| Demotte et al. [1] | Capsule network | Crowd-Flower US Airline dataset | 82.04 |
| Twitter Sentiment Gold dataset | 86.87 | ||
| Ahmed Alsayat et al. [2] | Ensemble deep learninglanguage model | Twitter coronavirus hashtag dataset | 92.65 |
| Amazon Reviews | 96.87 | ||
| Yelp Reviews | 97.5 | ||
| Selvi Munuswamy et al. [3] | Support Vector Machine Algorithm with N-Grams Techniques | YELP websites | 92 |
| Liang-Chu Chen et al. [4] | LSTM | Militarylife PTT board of Taiwan’s messages | 84.08 |
| Bi-LSTM | 85.4 |
2 Literature Review
This section covers the contribution of various researchers in the field of sentiment analysis. Table 1 discusses the comparative analysis of existing work.
In 2023, P. Demotte et al., [1] developed capsule networks-based social media content analyzing technique using Twitter data. This technique did not rely on linguistic resources but instead utilized the Crowd-Flower US Airline dataset and the Twitter Sentiment Gold dataset, achieving accuracy rates of approximately 82.04% and 86.87%. Consequently, the experimental results of the developed capsule networks-based social media content analysis technique demonstrated improved accuracy. Processing brief sequence of text from social media platforms with inconsistent context and background will be difficult.
In 2021, Ahmed Alsayat [2] implemented a sentiment analyzing technique using an ensemble model. This technique was implemented on an LSTM network which trained on LSTM network and underlying meaning behind words on emergency circumstances like COVID-19 pandemic. The implemented technique was evaluated using Twitter coronavirus hashtag dataset, as well as datasets from Amazon and Yelp, across various analyses. It consistently demonstrated enhanced performance compared to other methods. It has been observed that after applying ensemble model, the performance on some of the dataset found to be low.
In 2021, Selvi Munuswamy et al. [3] developed a recommendation system named sentiment-based rating prediction approach which worked on social user reviews. This approach evaluated a user’s sentiment on an item using sentiment dictionary. Then, the item’s popularity was evaluated in accordance with three sentiments to predict and result accurate recommendations. In addition, the n-gram technique was used to improve the accuracy of the approach by adding new feature in syntax and semantic analysis accompanied by Support Vector Machine (SVM) to classify social media data effectively. By considering sentiments and semantics for predicting user interest, this developed approach has resulted with more accurate recommendations.
In 2020, Liang-Chu Chen et al. [4] introduced a methodology for sentiment analysis by proposing a self-developed military sentiment dictionary to classify sentiments from social media. The introduced methodology was analyzed with various DL models in terms of several parameter calibration combinations. The introduced methodology achieved superior results in terms of accuracy and F1-measure. The author utilized LSTM and Bi-LSTM model and achieve a maximum accuracy of 92.68%.
In 2020, Mary Sowjanya Alamanda [5] developed an aspect-based sentiment analysis framework which was developed on the basis of extraction of sentiment from sentiment and polarity classification. In this paper, complex polarity aspects preferred by users were extracted automatically by Machine Learning (ML) and DL approaches. Additionally, a search engine was developed to reply on tweets and reviews based on user’s interests.
In [16], the authors constructed a hybrid model of CNN and BiGRU for Aspect based Sentimental Analysis.
The proposed model is then compared with Long-Short Term Memory model (LSTM), Convolutional Neural Network model (CNN), and Convolutional Neural Network (C-LSTM) model and it was found that there was an improvement of 12.12% of accuracy as compare to other models.
The authors in this paper [17] compared the different text embedding techniques for aspect term extraction and utilized Long Short-Term Memory (LSTM) model with Conditional Random Field (CRF) on SemEval datasets. According to the experimental findings, Bi-directional Long Short-Term Memory (BiLSTM) outperformed the other models. The authors in [18] implemented deep learning model for named entity recognition (NER). They used hybrid model of CNN and LSTM on CoNLL03 and ACE05 datasets for feature extraction and proved to be the best in terms of accuracy as compared to other models.
The authors [19] categorized the sentiment from financial news using a combination of stacked Bi-LSTM, Bidirectional LSTM (Bi-LSTM), and Doc2vec with LSTM. The Twitter API has been used to gather coronavirus tweets from Twitter. The proposed model achieved the accuracy score of 96.37% and comparison was made with other classifiers like kNN, Naïve Bayes, CNN-RNN, Random Forest and AC-BiLSTM. The author in the paper [20] classified the sentiment of financial news using a combination of stacked Bi-LSTM, Bidirectional LSTM (Bi-LSTM), and Doc2vec with LSTM. The model stacked Bi-LSTM has achieved the maximum accuracy score and precision score of 96% and 92% as compare to other models.
3 Systematical Procedure of Aspect Term Extraction based Sentiment Analysis with Hybridized Bi-GRU and LSTM Model
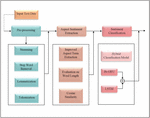
Sentiment analysis, essentially an opinion mining strategy, aims to analyze how a person’s emotional or sentimental tone is conveyed within a piece of text. Employing deep learning techniques, it assesses text data to classify it as neutral, positive, or negative, or to provide a sentiment score. In this sentiment analysis research work, the raw text data is given as an input. Initially, the raw input text data undergoes a series of pre-processing steps, including stemming, stop word removal, lemmatization, and tokenization. These processes are commonly employed in natural language processing (NLP) for text data preparation, as they are widely recognized for their ability to reduce dimensionality. Subsequently, the sentiment-based feature extraction process is executed to extract complex features from the pre-processed text. These complex features are obtained by identifying crucial aspects and sentiments through improved Aspect Term Extraction (ATE), word length analysis, and cosine similarity. Then, the analysis on sentiment is effectively carried out by the hybrid classification model which is proposed by the integration of Bi-GRU and LSTM classifiers [21, 22]. The retrieved complex features are concatenated into a whole feature set, which is then fed into this hybrid classification model for analysis. Further, the average of the resultant intermediate scores obtained from the hybridized classifiers is the final predicted results of the proposed sentiment analysis technique. Figure 1 provides the detailed description of the processes involved in the proposed sentiment analysis technique.
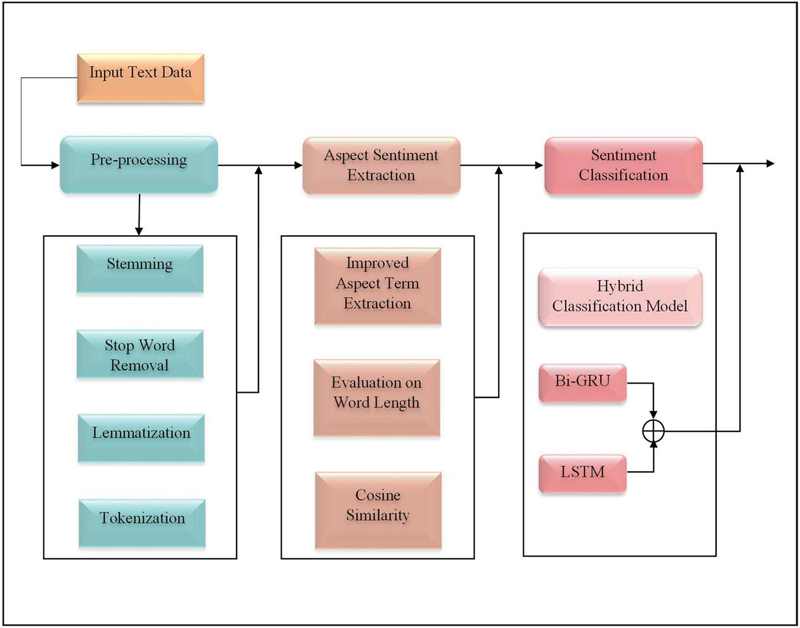
Figure 1 Architecture of proposed aspect-based feature extraction enabled sentiment analysis technique.
3.1 Pre-processing
In general, pre-processing is a technique that involves cleaning and converting raw data into a suitable format for subsequent processing. This research focuses on sentiment analysis, where raw text data serves as the input. In the proposed sentiment analysis technique, the input raw text data is subjected to the following phases: stemming, stop word removal, lemmatization, and tokenization, which are considered normalizing techniques [9]. These pre-processing phases are elaborated as below.
3.1.1 Stemming
This technique is used to transform all words in the raw text data, into their root or base forms, known as stem. The procedure utilizes with a lookup table to locate words and their corresponding base forms. This proves advantageous by reducing the need for extensive count computations. For instance, words like ‘talk,’ ‘talks,’ ‘talking,’ and ‘talked’ all share the common base word ‘talk’.
3.1.2 Stop word removal
This technique eliminates frequently occurring words from the raw text data, since these words provide limited information for sentiment analysis. For instance, words like ‘a,’ ‘an,’ ‘the,’ ‘is,’ ‘are,’ ‘was,’ ‘were,’ and so on fall into this category. This enhances the model’s capacity to extract significant information and connections within the text by allowing the Bi-GRU and LSTM layers to concentrate on more significant terms. By lowering the quantity of tokens the model must process, it also expedites training.
3.1.3 Lemmatization
This technique converts all words in the raw text data, into their respective base form known as lemma. This approach represents an improvement compared to the stemming technique. For example, “The morning light streamed through the window, filling the room with warmth” and “Her smile was like a ray of light on a gloomy day”. While considering these two phrases, the lemmatization technique will treat the word ‘light’ differently depend on its usage in these phrases. It also converts different word variations, such as changing ‘tore’ to ‘tear,’ ‘woke’ to ‘wake,’ ‘much’ to ‘more,’ and so on. This method operates by taking into account context and language information, making it a more beneficial choice for enhancing the efficiency of the proposed sentiment analysis approach. By doing this, the vocabulary is condensed and semantically related words are handled similarly, which enhances the model’s capacity to identify patterns and connections in the data.
3.1.4 Tokenization
This technique transforms a sentence within the raw text data, into a collection of words called ‘tokens’ which serve as the essential building components. Subsequently, the analysis is conducted on these tokens. This technique generally interprets the way the word expressed by analyzing the sequence of words.
Through these steps, the raw text data is subjected to processing, resulting in pre-processed text data referred to as . As a result of pre-processing on raw text data, the resultant pre-processed text data is now normalized, with noise removed and dimensions reduced. Since both the Bi-GRU and LSTM models depend on the sequential sequence of tokens, accurate tokenization is essential for accurately capturing the temporal dependencies.
3.2 Aspect Sentiment Extraction
The extraction of aspect sentiment is an important step in this research work because it aids to retrieve essential aspects and sentiments involved in pre-processed text data, . The relevant features to classify sentiments are extracted using essential aspects and sentiments which retrieved from . The retrieval of essential aspects and sentiments is done by following three steps.
(1) Extraction of improved aspect term Conventionally, the aspect terms [13, 34] are extracted from the text data on the basis of Named Entity recognition (NER) task. First of all, the given pre-processed text data, is prepared based on Inside-Outside-Beginning labels (IOB) tagging strategy which is a strategy used to annotate and tag sequences of tokens. The terms which are used to denote the IOB labels of the aspect term are represented as and where denotes the beginning label, denotes the inside label and denotes the outside label. For example, the phrase ‘The price is affordable although the service is poor.’ Will be organized as a sequence of tokens, where denotes a token after tokenization and the total number of token is denoted as . However, the traditional approach to aspect and sentiment extraction proves inefficient due to certain drawbacks, including the identification of implicit aspects instead of explicit ones, token misalignment, the presence of multi-word aspects etc. By considering these disadvantages, the conventional way of ATE is improved by the involvement of TF-IDF vectorizer technique-based aspect term extraction [28] which effectively extracts the required aspect terms from the pre-processed text data, . The TF-IDF vectorizer technique [15, 35] transforms the text data into vector format i.e., it fitted the pre-processed text data, and transformed into TF-IDF vectors. Further, the resultant vectors are used as a computing metrics to calculate cosine similarity [10]. Cosine similarity is a metric used as a feature in sentiment analysis by measuring the similarity between the word vectors of individual words and a reference vector representing sentiment and its formulation is expressed in Equation (1) by adding in it.
| (1) |
where, the coefficient of variance, in which and indicates the standard deviation and median of TF-IDF vectors. But, conventionally, in which indicates the harmonic mean. This replacement is occurred to evaluate the cosine similarity between the TF-IDF vectors in a more precise way by which required aspect terms are extracted.
(2) Evaluation on word length The word length [14, 33] of extracted aspect terms is then evaluated. This evaluation provides the aspect terms’ verbosity or complexity in pre-processed text data, . This evaluation is carried out by evaluating the number of characters that a particular aspect term has. Basically, this metric quantifies the size of the word.
(3) Finding cosine similarity At last, the cosine similarity between the vectors is once more evaluated using the conventional cosine similarity equation which is formulated in Equation (2).
| (2) |
From these steps, the essential aspects and sentiments are effectively extracted from the pre-processed text data, . And the essential aspects and sentiments as a whole are represented as feature set, which is used to analyze sentiments by hybrid classification model.
3.3 Sentiment Analysis via Hybrid Classification Model
The sentiment analysis is carried out using the hybrid classification model introduced in this study. This hybrid classification model is formed by combining two deep learning [30] classifiers, namely Bi-GRU and LSTM. Bi-GRU effectively gathers contextual information from past and future sequences, while LSTM manages long-term dependencies to boost performance and flexibility in sequential data jobs. Since previous existing model like SVM models lack a memory system, these models handle each instance on its own without taking into account inputs from the past or the future [31, 32].
The rationale for combining these classifiers lies in their contrasting characteristics. The choice to hybridize them is driven by their divergent traits: Bi-GRU exhibits low memory usage, whereas LSTM consumes more memory. Also, LSTM excels in capturing long-range dependencies, while Bi-GRU may not be as effective in this regard. Hence, the hybridization serves the purpose of enhancing the efficiency of the proposed sentiment analysis technique
3.3.1 Bi-GRU approach for sentiment analysis
Bi-GRU [12, 23, 24] is a neural network model that represents a variation of the GRU. It is structured by the combination of two individual GRUs in forward and backward direction. The feature set, is provided as an input to Bi-GRU in which the given input is processed by both the forward and backward GRU simultaneously. The input sequence to be inputted into the forward and backward GRUs is represented as . This approach is advanced due to ability to store the past and future data at any time, t. In forward direction, the hidden states in the forward GRU are computed and in backward direction, the hidden states in the backward GRU are computed. In forward GRU, the given input sequence, is processed from left to right with update gate and reset gate. The update gate in GRU has a control over hidden state in terms of which information to be added to it. The computation on update gate using sigmoid activation function is carried out by considering the input, () and previous hidden state () and it is formulated in Equation (3). And the computation on reset gate is represented in Equation (4).
| (3) | ||
| (4) |
where, the weight matrices of update and reset gates are and corresponding. The computation on hidden state () and new memory content is performed by using the candidate cell state which is formulated in Equation (6). The term in the Equation (6) represents the weight of the candidate state.
| (5) | ||
| (6) |
The computation of forward GRU () and backward GRU () are expressed in Equations (7) and (8). Then, the both forward and backward GRU are concatenated to obtain the output of Bi-GRU approach and it represented as mathematically in Equation (9). Thus, the intermediate score of Bi-GRU approach obtained from Equation (9) and it is indicated as .
| (7) | ||
| (8) | ||
| (9) |
3.3.2 LSTM approach for sentiment analysis
Among deep learning techniques, LSTM [11, 26] stands out as a modification of the Recurrent Neural Network (RNN) architecture. It is widely employed in scenarios where dealing with sequential data featuring substantial dependencies is essential. The key components of LSTM include the input gate, forget gate, output gate, and memory cell. For sentiment analysis [27, 29], the LSTM processes the feature set, attained from the feature extraction stage. The feature set, denoted as , is fed into the input gate (), which takes into account both the current input () and the previous hidden state (), determining what information should be stored in the cell state (). The weighted combination of the input and the previous hidden state is subjected to a sigmoid activation function (), which yields values within the range of [0, 1]. The mathematical expression for the computation of the input gate using the sigmoid activation function can be seen in Equation (10).
| (10) |
Then, the information stored in a cell state () is discarded or forgotten by the control of forget gate () by the way it processes previous hidden state () and current input (). This gate also utilizes sigmoid activation function to give values in the range [0, 1]. The computation on forget gate using sigmoid activation function is formulated in Equation (11).
| (11) |
Subsequently, the output gate has a control over cell state () i.e., which information in the cell state will be utilized for producing the output hidden state (). The output gate () also utilizes sigmoid activation function to give values in the range [0, 1]. The computation on output gate using sigmoid activation function is formulated in Equation (12).
| (12) |
Memory cell is responsible for training and storing information at each time step, t. It is associated with cell state which executes the overall sequence by permitting it to store and retrieve information and tanh activation function is applied to the cell state. The computation on cell state using tanh activation function is formulated in Equation (13) and the updation cell state is expressed in Equation (13). This cell state updation is carried out by integrating the new cell state () and previous cell state ().
| (13) | ||
| (14) |
Then, the cell state’s () filtered version is the output hidden state and it is controlled by output gate which is formulated in Equation (15). It provides appropriate information for the current time step from the cell state.
| (15) |
In these expressions, the terms and indicates weight matrix and bias factors. The weight matrices and bias factors of input gate, forget gate, output gate and memory cell are represented as and , respectively.
Therefore, the resultant intermediate score attained from the LSTM approach is specified as . Finally, the intermediate scores of Bi-GRU and LSTM approaches are averaged which is the final predicted result, on sentiment analysis.
4 Results and Discussion
4.1 Dataset Description
The proposed sentiment analysis framework was simulated in Python. The sentiment was analyzed using Coronavirus tweets NLP – Text Classification dataset. There are 41157 reviews in this dataset. We analyzed sentiments based on different sources, including the location, the tweet at and the original tweet. The output labels are Neutral, Positive, Negative, Extremely Negative and Extremely Positive.
4.2 Experimental Setup
The experimental platform is constructed for the implementation of this work. Table 2 depicts the experimental settings used in the proposed approach.
| Parameters | Value |
| Epochs | 1 |
| Batch_size | 1280 |
| Validation_split | 0.2 |
| Activation function | Relu |
| Optimizer | RMSprop |
| Drop_out | 0.2 |
4.3 Performance Analysis
An evaluation was carried out to assess the classification performance of Bi-GRU+LSTM method and traditional approaches. This assessment involved the consideration of a variety of performance metrics, including specificity, Matthews Correlation Co-efficient (MCC), False Negative Rate (FNR), F-measure, accuracy, False Positive Rate (FPR), precision, Net Predictive Value (NPV), and sensitivity. Furthermore, the Bi-GRU+LSTM approach was compared to conventional algorithms such as Recurrent neural network (RNN), Long Short term Memory (LSTM), Deep Neural Network (DNN), Support Vector Machine (SVM), and Bi-directional Gated Recurrent Unit (Bi-GRU).
4.4 Validation on Positive Metric
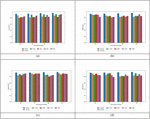
Figure 2 reveals the evaluation of Bi-GRU+LSTM in comparison to Bi-GRU, LSTM, DNN, SVM, and RNN regarding positive metric for sentiment analysis framework. To achieve accurate sentiment classification, the model needs to generate maximal positive metric ratings. At a training rate of 60%, the Bi-GRU+LSTM scheme achieved an accuracy of 0.924. In contrast, the conventional approaches exhibited lower accuracy scores, specifically Bi-GRU with 0.8766, LSTM with 0.7992, DNN with 0.8198, SVM with 0.8209, and RNN with 0.8487, respectively. Additionally, the greatest precision is acquired using the Bi-GRU+LSTM methodology is extremely greater than Bi-GRU, LSTM, DNN, SVM and RNN, correspondingly. Moreover, the Bi-GRU+LSTM approach demonstrated a sensitivity of 0.9429 at the training rate 90, whilst the Bi-GRU, LSTM, DNN, SVM and RNN offered minimized sensitivity values. This serves to showcase that the Bi-GRU+LSTM is unequivocally more successful at classifying the sentiment. This accomplishment is enabled by the Improved Aspect Term Extraction employing a hybrid classification approach (Combining Bi-GRU and LSTM).
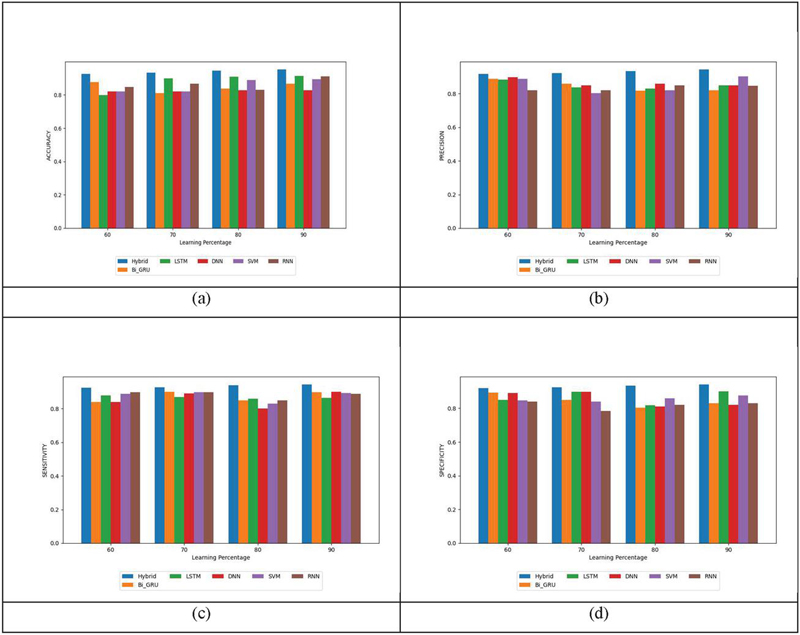
Figure 2 Assessment on Bi-GRU+LSTM and conventional strategies regarding positive metric.
4.5 Validation on Negative Metric
Figure 3 illustrates the comparative negative metric examination of Bi-GRU+LSTM in contrast to Bi-GRU, DNN, SVM, LSTM, and RNN for sentiment analysis framework. For accurate sentiment classification, it is preferable for the model to generate lower negative metric scores. Furthermore, when the learning percentage is set at 80, the FPR of the Bi-GRU+LSTM methodology is 0.07609. In comparison, the FPR values for Bi-GRU, LSTM, DNN, SVM, and RNN are 0.1738, 0.1387, 0.1500, 0.1490, and 0.1587, respectively. In addition, in the training rate 90, the minimal FNR is offered using the Bi-GRU+LSTM approach is 0.0629, even though the Bi-GRU, LSTM, DNN, SVM and RNN scored higher FNR values. This suggests that the Bi-GRU+LSTM approach excels in sentiment classification. This enhanced performance can be attributed to the implementation of improved aspect term extraction method coupled with a hybrid classification approach involving both Bi-GRU and LSTM.
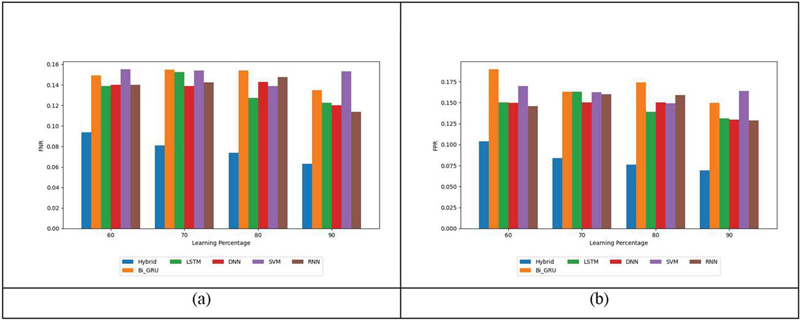
Figure 3 Assessment on Bi-GRU+LSTM and conventional strategies regarding negative metric.
4.6 Validation on Other Metric
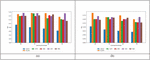
Figure 4 illustrates the contrasting performance evaluation of Bi-GRU+LSTM when compared to Bi-GRU, LSTM, DNN, SVM, and RNN in the context of other metrics. Maximizing the value of these other metrics is crucial for achieving effective sentiment classification. Similarly, when the training rate is set at 60%, the F-measure of the Bi-GRU+LSTM scheme reaches 0.920038, while Bi-GRU, LSTM, DNN, SVM, and RNN attain lower F-measure scores. Mainly, the Bi-GRU+LSTM scored greater MCC values than Bi-GRU, LSTM, DNN, SVM and RNN. Thus, the betterment of the Bi-GRU+LSTM methodology is demonstrated and this is owing to Improved Aspect Term extraction and Hybrid classification approach.
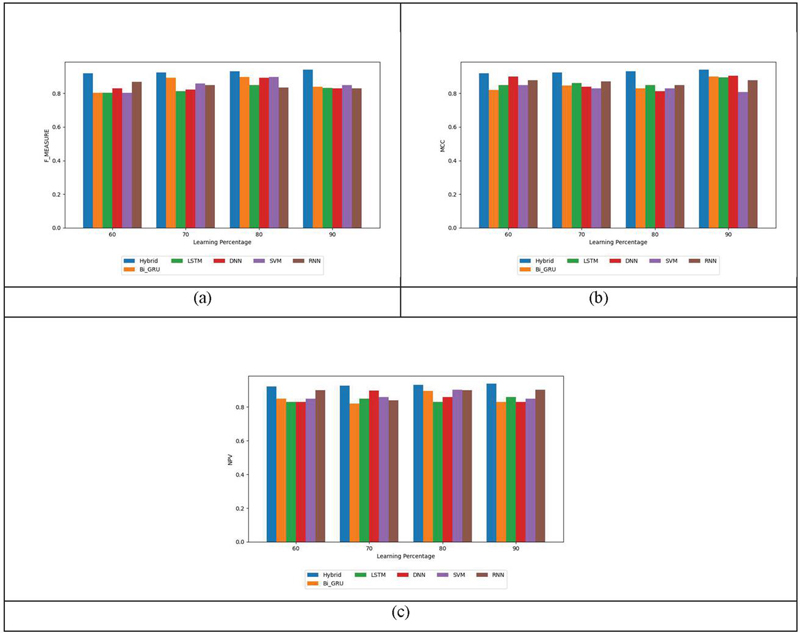
Figure 4 Assessment on Bi-GRU+LSTM and conventional strategies regarding other metric.
4.7 Ablation Evaluation on Bi-GRU+LSTM
Table 3 presents the ablation study conducted on both the Bi-GRU+LSTM model and the model utilizing conventional aspect terms for sentiment analysis. The ablation analysis methodically examines how the inclusion or enhancement of particular features within the Bi-GRU+LSTM approach impacts its performance. This systematic process enables a comprehensive understanding of the unique contributions these features provide towards enhancing the overall effectiveness of the Bi-GRU+LSTM scheme. Moreover, the NPV of Bi-GRU+LSTM approach is 0.924987 and model with conventional aspect term is 0.809683. Furthermore, the FNR of the Bi-GRU+LSTM methodology 0.081039 and model with conventional aspect term 0.139898.
Table 3 Ablation analysis on Bi-GRU+LSTM and model with conventional aspect term
| Metrics | Model with Conventional Aspect Term | Bi-GRU+LSTM |
| Sensitivity | 0.88778 | 0.927899 |
| Specificity | 0.82188 | 0.924788 |
| Accuracy | 0.899379 | 0.932787 |
| Precision | 0.802877 | 0.921769 |
| F-measure | 0.81989 | 0.924909 |
| MCC | 0.847688 | 0.922981 |
| NPV | 0.809683 | 0.924987 |
| FPR | 0.153989 | 0.083789 |
| FNR | 0.139898 | 0.081039 |
4.8 Statistical Assessment on Accuracy
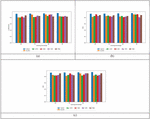
Table 4 provides a statistical evaluation on comparing Bi-GRU+LSTM to Bi-GRU, LSTM, DNN, SVM, and RNN for sentiment analysis. This analysis focuses on evaluating the reliability of metaheuristic techniques. To ensure highly accurate estimations, each approach undergoes a meticulous investigation. This comprehensive assessment involves the evaluation of key statistical measures, including minimum, median, standard deviation, mean, and maximum values. These metrics collectively provide a thorough insight into the performance and reliability of the strategies under investigation. Mainly, for the median statistical metric, the accuracy of the Bi-GRU+LSTM scheme is 0.939387, though the Bi-GRU is 0.853274, LSTM is 0.905158, DNN is 0.824131, SVM is 0.855535 and RNN is 0.857783, correspondingly. Moreover, the accuracy of the Bi-GRU+LSTM method is 0.951979 under the maximum statistical metric, whilst the Bi-GRU, LSTM, DNN, SVM and RNN scored minimal accuracy ratings.
Table 4 Statistical evaluation on accuracy
| Statistical Metrics | Bi-GRU+LSTM | Bi-GRU | LSTM | DNN | SVM | RNN |
| Mean | 0.938913 | 0.848404 | 0.880626 | 0.824308 | 0.856467 | 0.863956 |
| Median | 0.939387 | 0.853274 | 0.905158 | 0.824131 | 0.855535 | 0.857783 |
| Std-Dev | 0.010662 | 0.026043 | 0.047198 | 0.004434 | 0.035548 | 0.029809 |
| Min | 0.924899 | 0.810388 | 0.799279 | 0.81988 | 0.820909 | 0.82988 |
| Max | 0.951979 | 0.876679 | 0.912909 | 0.829091 | 0.893889 | 0.910376 |
5 Conclusion
The proposed aspect-based feature extraction enabled sentiment analyzing technique was more effective in analyzing sentiments than the state-of-the-art models. Its effectiveness was proved by evaluating the proposed sentiment analysis technique under various experimental analyzes. The enhanced performance of proposed aspect-based feature extraction enabled sentiment analysis technique was achieved by three fundamental stages such as pre-processing, aspect sentiment extraction and classification on sentiment analysis. The input text data was processed by stemming, stop word removal, lemmatization and tokenization techniques in pre-processing stage. Then, the aspect sentiment extraction stage followed steps such as improved ATE, evaluation on word length and finding cosine similarity to extract relevant features by retrieving essential aspects and sentiments from it. Finally, the sentiments in input text data were classified by a hybrid classification model which was proposed by hybridizing Bi-GRU and LSTM classifiers. In conclusion, the efficiency of the proposed aspect-based feature extraction enabled sentiment analysis technique was validated and proved as an effective technique.
As the number of parameters grows when Bi-GRU and LSTM models are combined, the model’s complexity and computational cost also get increased. This overall results in longer training periods, particularly for large datasets. The model could be further expanded to process multi-modal data, such as image and audio combinations, to enhance performance on tasks.
References
[1] P. Demotte, K. Wijegunarathna, D. Meedeniya& I. Perera, “Enhanced sentiment extraction architecture for social media content analysis using capsule networks,” Multimedia Tools and Applications, vol. 82, pp. 8665–8690, 2023.
[2] A. Alsayat, “Improving Sentiment Analysis for Social Media Applications Using an Ensemble Deep Learning Language Model,” Arabian Journal for Science and Engineering, vol. 47, pp. 2499-2511, 2022.
[3] S. Munuswamy, M. S. Saranya, S. Ganapathy, S. Muthurajkumar and A. Kannan, “Sentiment Analysis Techniques for Social Media-Based Recommendation Systems,” National Academy Science Letters, vol. 44, pp. 281–287, 2021.
[4] L. Chen, C. Lee and M. Chen, “Exploration of social media for sentiment analysis using deep learning,” Soft Computing, vol. 24, pp. 8187–8197, 2020.
[5] M. S. Alamanda, “Aspect-based sentiment analysis search engine for social media data,” CSIT, vol. 8, pp. 193–197, 2020.
[6] G. Xiao, G. Tu, L. Zheng, T. Zhou, X. Li, S. H. Ahmed, D. Jiang, “Multimodality Sentiment Analysis in Social Internet of Things Based on Hierarchical Attentions and CSAT-TCN With MBM Network,” IEEE Internet of Things, vol. 8, issue 16, pp. 12748–12757, Aug 2021.
[7] H. Zhang, J. Wu, H. Shi, Z. Jiang, D. Ji, T. Yuan, G. Li, “Multidimensional Extra Evidence Mining for Image Sentiment Analysis,” IEEE Access, vol. 8, pp. 103619–103634, 2020.
[8] S. V. Balshetwar, A. RS and D. J. R, “Correction to: Fake news detection in social media based on sentiment analysis using classifier techniques,” Multimedia Tools and Applications, 2023.
[9] M. Mhatre, D. Phondekar, P. Kadam, A. Chawathe, K. Ghag, “Dimensionality reduction for sentiment analysis using pre-processing techniques,” in International Conference on Computing Methodologies and Communication, Erode, India, 2017, pp. 16–21.
[10] S. Bhattacharjee, A. Das, U. Bhattacharya, S. K. Parui, S. Roy, “Sentiment analysis using cosine similarity measure,” in IEEE 2nd International Conference on Recent Trends in Information Systems (ReTIS), Kolkata, India, 2015, pp. 27–32.
[11] S. Poornima and M. Pushpalatha, “Prediction of Rainfall Using Intensified LSTM Based Recurrent Neural Network with Weighted Linear Units”, Atmosphere, vol. 10, 668, 2019.
[12] S. Wang, C. Shao, J. Zhang, Y. Zheng and M. Meng, “Traffic flow prediction using bi-directional gated recurrent unit method, “ Urban Informatics, vol. 1, issue 16, 2022.
[13] H. Yang, B. Zeng, J. Yang, Y. Song, R. Xu, “A multi-task learning model for Chinese-oriented aspect polarity classification and aspect term extraction”, Neurocomputing, vol. 419, pp. 344–356, 2021.
[14] V.V. Bochkarev, A.V. Shevlyakova, V.D. Solovyev, “Average word length dynamics as indicator of cultural changes in society,” Social Evolution and History, vol. 14, issue 2, pp. 153–175, 2012.
[15] J. Jeong, “Identifying Consumer Preferences From User-Generated Content on Amazon.Com by Leveraging Machine Learning,” in IEEE Access, vol. 9, pp. 147357-147396, 2021.
[16] Z. Gao, Z. Li, J. Luo, X. Li, “Short text aspect-based sentiment analysis based on CNN+ BiGRU.” Applied Sciences, vol. 12, issue 5, 2022.
[17] L. Augustyniak, T. Kajdanowicz, T, P. Kazienko, “Comprehensive analysis of aspect term extraction methods using various text embeddings,” Computer Speech and Language, vol. 69, 2021.
[18] E. Parsaeimehr, M. Fartash, J. K. Torkestani, “Improving Feature Extraction Using a Hybrid of CNN and LSTM for Entity Identification,” Neural Processing Letters, vol. 55, issue 5, pp. 5979–5994, 2023.
[19] R. Seth, R., A. Sharaff, “Sentiment Data Analysis for Detecting Social Sense after COVID-19 using Hybrid Optimization Method,” SN Computer Science, vol. 4, issue 5, 2023.
[20] A. Sharaff, T. R. Chowdhury, and S. Bhandarkar, “LSTM based Sentiment Analysis of Financial News,” SN Computer Science, vol. 4, issue 5, 2023.
[21] B. Harjo, R. Abdullah, “Attention-based Sentence Extraction for Aspect-based Sentiment Analysis with Implicit Aspect Cases in Hotel Review Using Machine Learning Algorithm, Semantic Similarity, and BERT,” International Journal of Intelligent Engineering & Systems, vol. 16, issue 3, 2023.
[22] Z. Gao, Z. Li, J. Luo, X. Li, “Short text aspect-based sentiment analysis based on CNN+ BiGRU,” Applied Sciences, vol. 12, issue 5, 2022.
[23] M. Belguith, C. Aloulou, B. Gargouri, “Aspect Level Sentiment Analysis Based on Deep Learning and Ontologies,” SN Computer Science, vol. 5, issue 1, 2024.
[24] X. Zhang, J. Xu, Y. Cai, X. Tan, C. Zhu, “Detecting Dependency-Related Sentiment Features for Aspect-Level Sentiment Classification,” IEEE Transactions on Affective Computing, vol. 14, issue 1, 2023.
[25] G. Dubey, H. P. Singh, K. Sheoran, G. Dhand, P. Singh, “Drug review sentimental analysis based on modular lexicon generation and a fusion of bidirectional threshold weighted mapping CNN-RNN,” Concurrency and Computation: Practice and Experience, vol. 35, issue 3, 2022.
[26] A. Kumar, N. Kumar, J. Kuriakose, Y. Kumar, “A review of deep learning-based approaches for detection and diagnosis of diverse classes of drugs,” Archives of Computational Methods in Engineering, vol. 30, pp. 3867–3889, 2023.
[27] N. Parveen, P. Chakrabarti, B. T. Hung, A. Shaik, “Twitter sentiment analysis using hybrid gated attention recurrent network,” Journal of Big Data, vol. 10, pp. 1–29, 2023.
[28] Z. Ahanin, M. A. Ismail, N. S. S. Singh, A. AL-Ashmori, “Hybrid feature extraction for multi-label emotion classification in English text messages,” Sustainability, vol. 15, issue 16, 2023.
[29] S. Sachin, A. Tripathi, N. Mahajan, S. Aggarwal, P. Nagrath, “Sentiment analysis using gated recurrent neural networks,” SN Computer Science, vol. 1, pp. 1–13, 2020.
[30] K. Maity, S. Bhattacharya, S. Saha, M. Seera, “A Deep Learning Framework for the detection of Malay hate speech,” IEEE Access, vol. 11, 2023.
[31] Bhatnagar, S., Dayal, M., Singh, D., Upreti, S., Upreti, K., and Kumar, J. (2023). Block-Hash Signature (BHS) for Transaction Validation in Smart Contracts for Security and Privacy using Blockchain. Journal of Mobile Multimedia, 19(04), 935–962. https://doi.org/10.13052/jmm1550-4646.1941.
[32] Singh, A., Singh, D., Upreti, K., Sharma, V., Rathore, B. S., and Raikwal, J. (2022). Investigating New Patterns in Symptoms of COVID-19 Patients by Association Rule Mining (ARM). Journal of Mobile Multimedia, 19(01), 1–28. https://doi.org/10.13052/jmm1550-4646.1911.
[33] Aggarwal, D., Mittal, S., Upreti, K., and Nayak, P. (2024). Reward Based Garbage Monitoring and Collection System Using Sensors. Journal of Mobile Multimedia, 20(02), 391–410. https://doi.org/10.13052/jmm1550-4646.2026.
[34] Upreti, K., Kushwah, V. S., Vats, P., Alam, M. S., Singhai, R., Jain, D., and Tiwari, A. (2024). A SWOT analysis of integrating cognitive and non-cognitive learning strategies in education. European Journal of Education, 00, e12614. https://doi.org/10.1111/ejed.12614.
[35] Upreti Kamal, Vats Prashant, Srinivasan Aravindan, Daya Sagar K. V, Mahaveer Kannan, R, Charles Babu, G, “Detection of Banking Financial Frauds Using Hyper-Parameter Tuning of DL in Cloud Computing Environment”, International Journal of Cooperative Information Systems, Aug, 2023, World Scientific Publishing Co., https://doi.org/10.1142/S0218843023500247.
Biographies

Shilpi Gupta is pursuing her Ph.D. from Shobhit Institute of Engineering and Technology, (Deemed-to-be University), Meerut. She is currently working as an Assistant Professor in the Department of Computer Science. She has guided various students for their project work. She is having more than fifteen years of teaching experience. Her area of interest are Sentiment Analysis, Natural Language Processing and Data Mining.

Niraj Singhal is Graduate in Computer Science and Engineering, M.Tech. in Computer Engineering and, Ph.D. (Computer Engineering & Information Technology). He is Fellow, Senior Member and member of several National/International bodies. He is serving as reviewer and member of advisory board for several International/National journals and International/National Conferences also. He has guided hundreds of undergraduate engineering students for their project work and postgraduate engineering students for their thesis work. He has guided many Ph.D. scholars and, also guiding many. He has more than one hundred and fifty research publications to his credit in National/International journals/conferences of repute. He has twenty-eight years of rich experience of administration, coordinating, supervising and teaching at various levels. Presently, he is working as Director at Sir Chhotu Ram Institute of Engineering and Technology (SCRIET), Chaudhary Charan Singh University, Meerut (NAAC A++ Accredited). His area of interest includes web information retrieval, smart cities and software agents.

With an illustrious academic journey spanning over 25 years, Currently working with renowned University, Pimpri Chinchwad University, Pune. Professor Dr. Sheela Hundekari embodies a remarkable blend of scholarly prowess and practical expertise. Armed with a Ph.D. and a diverse array of qualifications including an MBA, MCA, and MCM, their academic voyage has been marked by an insatiable thirst for knowledge and an unwavering commitment to excellence.
Dr. Sheela Hundekari is not merely confined to the academic realm; they have garnered acclaim on a global scale through their certifications and training endeavors. Holding five prestigious certifications, including three in Java and two in Oracle, Professor Dr. Sheela stands as a paragon of technical proficiency and industry relevance. Their designation as a NASSCOM certified trainer further solidifies their status as a leading authority in the field.
In addition to their instructional prowess, Professor Dr. Sheela Hundekari is an avid researcher, with a prolific portfolio of national and international research papers to their credit. Their contributions to the academic discourse have not only enriched their respective fields but have also spurred innovation and progress.

Kamal Upreti is currently working as an Associate Professor in Department of Computer Science, CHRIST (Deemed to be University), Delhi NCR, Ghaziabad, India. He completed is B. Tech (Hons) Degree from UPTU, M. Tech (Gold Medalist), PGDM (Executive) from IMT Ghaziabad and PhD in Department of Computer Science & Engineering. He has completed Postdoc from National Taipei University of Business, TAIWAN funded by MHRD.
He has published 50+ Patents, 32+ Magazine issues and 110+ Research papers in in various reputed Journals and international Conferences. His areas of Interest such as Modern Physics, Data Analytics, Cyber Security, Machine Learning, Health Care, Embedded System and Cloud Computing. He has published more than 45+ authored and edited books under CRC Press, IGI Global, Oxford Press and Arihant Publication. He is having enriched years’ experience in corporate and teaching experience in Engineering Colleges.
He worked with HCL, NECHCL, Hindustan Times, Dehradun Institute of Technology and Delhi Institute of Advanced Studies, with more than 15+ years of enrich experience in research, Academics and Corporate. He also worked in NECHCL in Japan having project – “Hydrastore” funded by joint collaboration between HCL and NECHCL Company. He has completed project work with Joint collaboration with GB PANT & AIIMS Delhi, under funded project of ICMR Scheme on Cardiovascular diseases prediction strokes using Machine Learning Techniques from year 2017–2020 of having fund of 80 Lakhs. He got 3 Lakhs fund from DST SERB for conducting International Conference, ICSCPS-2024, 13–14 Sept 2024. Recently, he got 10 Lakhs fund from AICTE – Inter-Institutional Biomedical Innovations and Entrepreneurship Program (AICTE-IBIP) for 2024–2026. He has attended as a Session Chair Person in National, International conference and key note speaker in various platforms such as Skill based training, Corporate Trainer, Guest faculty and faculty development Programme. He awarded as best teacher, best researcher, extra academic performer and Gold Medalist in M. Tech programme.

Anjali Gautam is working as an Associate Professor in the School of Computer Applications, Manav Rachna International Institute of Research & Studies. She holds a Doctorate Degree in Computer Science from University of Delhi, where her research contributed significantly to develop Recommender Systems for large-scale data. With her background in computer science, she has developed a keen interest in machine learning models, cyber-physical systems & data mining. Dr. Anjali has published numerous papers in reputable indexed journals and has presented her work at various international conferences. She is also actively involved in other research related activities such as chairing a session in international conference and a reviewer for research publication. Dr. Anjali’s work continues to influence and shape the understanding of machine learning, driving further advancements in the field.

Pradeep Kumar working as assistant professor in computer science and engineering JSS Academy of technical education Noida. He has completed Ph.D. computer engineering and engineering at Department of Computer Engineering Shobhit Institute of Engineering & Technology (Deemed-to-be University), Meerut, 250110. He has obtained his M.Tech. in Computer Science and engineering Department of Computer Engineering Shobhit Institute of Engineering & Technology (Deemed-to-be University), with first class. He obtained his B.Tech in Computer Engineering and engineering degree from college of engineering Roorkee, India in 2006 with first class.

Rajesh Verma, is an Associate Professor at Christ University, Delhi NCR Campus, is celebrated for his expertise in management education. Holding a Ph.D. in Management from SMVDU, Katra, he has cleared the UGC NET in Management and holds an MBA (Marketing) from MDU Rohtak and a PGDM (Marketing) from Lal Bahadur Shastri Institute of Management, Delhi. With nearly two decades in academia, His specializes in Marketing Management, Business Research Methods, Statistics for Management, and Strategic Management. He has co-authored influential books on these subjects, exemplifying his scholarly contributions. As a faculty and mentor, he ensures academic excellence and fosters critical thinking and research skills among students. His extensive research at national and international levels underscores his commitment to advancing management knowledge, making him a pivotal figure at Christ University in nurturing future management leaders.
Journal of Mobile Multimedia, Vol. 20_4, 935–960.
doi: 10.13052/jmm1550-4646.2048
© 2024 River Publishers