Personalized Recommendation Framework Using Large Language Model and Chain-of-thought Prompting: A Case Study of a Computer Programming Course
Tew Hongthong, Nacha Chondamrongkul and Punnarumol Temdee*
Computer and Communication Engineering for Capacity Building Research Center, School of Applied Digital Technology, Mae Fah Luang University, Chiang Rai, Thailand
E-mail: 6471501001@lamduan.mfu.ac.th; nacha.cho@mfu.ac.th; punnarumol@mfu.ac.th
*Corresponding Author
Received 28 June 2025; Accepted 04 November 2025
Abstract
Traditional learning methodologies often fall short of accommodating diverse learner needs and adapting dynamically to individual learning paces and styles. This limitation underscores the growing need for personalized learning, which has the potential to significantly improve learning outcomes, foster deeper engagement, and enhance learner motivation. This study introduces a novel personalized recommendation framework (PRF) that leverages large language models (LLMs) and chain-of-thought (CoT) prompting techniques to advance personalized learning. Specifically, it proposes a strategic personalization framework that addresses learner heterogeneity by incorporating both preference-based and performance-based features. CoT prompting is integrated to simulate human-like sequential reasoning in LLMs, thereby improving the framework’s adaptability and effectiveness. A case study was conducted in a computer programming course, a domain that requires both conceptual understanding and practical problem-solving, to evaluate the proposed framework. The assessment involved 15 expert reviewers who examined the framework’s effectiveness and overall satisfaction. Experimental results showed that the proposed PRF generated recommendations perceived as significantly more satisfactory than those produced by the non-PRF system (M 4.50 0.30 vs. 3.73 0.21, p 0.001). In addition, the experts strongly agreed that the framework effectively identified students in urgent need of support, provided timely recommendations, and delivered personalized learning experiences aligned with individual learner needs.
Keywords: Recommendation system, personalized learning, chain-of-thought prompting, large language model.
1 Introduction
Personalized learning is a key component of modern education that tailors the learning process to the requirements, abilities, and interests of each student. A personalized recommendation system enables educators to offer customized learning trajectories, thereby enhancing student engagement, motivation, and overall outcomes. Such systems have become essential in contemporary education because students possess distinct learning styles and skill levels, and traditional teaching approaches are insufficient to address their diverse needs. More specifically, personalized learning aims to deliver educational experiences that meet individual needs and improve learning performance. In recent years, personalized learning has evolved through the integration of artificial intelligence (AI), which can analyze large datasets [1], predict learner preferences [2], and provide tailored resources and experiences [3]. AI-powered recommendation systems have significantly improved adaptive learning across disciplines. The evolution from basic AI-driven recommendation systems [4] to advanced models of knowledge diffusion [5] has accelerated the development of modern e-learning ecosystems [6–8].
Currently, large language models (LLMs) represent a major advancement in natural language processing. These AI models are capable of text recognition, generation, and a wide range of other tasks. LLMs employ deep learning techniques to generate human-like text and engage in meaningful dialogue, making them valuable tools for various educational applications. Prompting techniques are used to create input requests that guide LLMs toward desired outputs. One such technique is chain-of-thought (CoT) prompting [9], which encourages LLMs to perform complex reasoning through intermediate steps. Similar to human cognitive processes, CoT breaks a larger task or problem into smaller sub-tasks and then connects these steps into a logical sequence. Recently, several CoT-based methods have been made publicly available, including Google Gemini [10] and Meta’s large language model (Meta AI) [11].
Recent advancements in LLMs have significantly enhanced the capabilities of AI-driven educational systems, enabling more nuanced and context-aware learner interactions. A key innovation in this area is the application of CoT prompting, which guides LLMs to produce structured, step-by-step reasoning processes. While CoT prompting improves LLM performance in tasks such as arithmetic and common-sense reasoning by making reasoning processes more transparent, it often relies on rigid, human-annotated reasoning chains. This dependence presents challenges for real-world applications where labeled data are scarce or unavailable [12, 13]. Furthermore, LLMs with CoT prompting have been effectively employed in task-specific recommendation systems [14], particularly in computational thinking-oriented learning [15, 16]. However, there is currently no online learning framework that leverages LLMs and CoT prompting specifically for personalized learning, particularly for diverse learners with varying learning styles.
Existing AI-driven learning platforms primarily focus on adaptive content delivery or recommendation mechanisms but lack features that explicitly guide reasoning processes aligned with learners’ individual learning pathways. Additionally, most current solutions fail to integrate multimodal learning preferences (such as visual, auditory, and kinesthetic) and related behaviors into their reasoning models, resulting in limited inclusivity for diverse learner populations. While LLMs exhibit strong general reasoning capabilities, there is limited evidence of their systematic application in structured personalized education frameworks that combine CoT prompting with established pedagogical theories. This research gap highlights the novelty and necessity of developing such a framework. This study contributes to the field by demonstrating how CoT prompting can be effectively utilized to generate individualized learning recommendations that are not only tailored to learners’ performance and preferences but also supported by transparent reasoning paths. Unlike traditional black-box recommendation algorithms, CoT-based responses provide interpretable justifications that enhance learner understanding and self-regulation. By dynamically adapting explanations and recommendations to each learner’s unique profile, the proposed approach improves both the personalization and pedagogical value of AI-generated feedback. This contribution addresses a critical limitation in existing personalized learning systems and establishes a foundation for more explainable and learner-centered intelligent tutoring frameworks.
This study focuses on developing a personalized learning recommendation framework that leverages LLMs and CoT prompting to enhance individualized learning experiences. The framework is specifically applied to computer programming courses, which inherently require both conceptual understanding and practical problem-solving skills. The diversity of learning needs and varying levels of student proficiency make this context suitable for evaluating the effectiveness of a personalized learning approach. To achieve personalization, the proposed strategy incorporates both preference-based and performance-based features, enabling the LLM and CoT mechanisms to generate learner-specific recommendations. The effectiveness of the proposed framework was assessed through expert evaluations conducted within a computer programming course setting to validate its performance and practical relevance.
2 Related Works
This section reviews previous studies that provide the conceptual foundation for the proposed framework.
2.1 Personalized Recommendation Systems
Personalized recommendation systems are educational technologies designed to tailor learning experiences to individual students’ characteristics, interests, and needs. These systems optimize resource utilization, enhance engagement, and improve learning outcomes while fostering motivation and sustained progress [17]. In general, such systems consist of two primary components: learner modeling or classification, and the recommendation module [18]. Learner modeling evaluates student performance and characterizes learner attributes, whereas the recommendation module identifies suitable materials, activities, or learning pathways to strengthen understanding and engagement [19]. Learner modeling plays a crucial role in personalized recommendation systems, as it helps identify the unique traits and requirements of each student [20]. It is also fundamental to understanding differences in learning styles, pacing, and preferences [21]. Typically, learner models employ data-driven methods to build dynamic student profiles that capture aptitudes, learning preferences, strengths, weaknesses, and progress across subjects. These models analyze a variety of data, including performance results, behavioral patterns, demographics, and even biometric indicators [22]. Algorithms such as collaborative filtering [23], matrix factorization [24], deep learning [25], and reinforcement learning [26] are commonly applied to extract actionable insights from this data. Advancements in learner modeling have led to the development of intelligent tutoring systems such as Cognitive Tutor and AutoTutor [27]. More recent efforts incorporate affective computing – such as emotion recognition and sentiment analysis – to account for the emotional dimensions of learning [28]. These developments underscore the ongoing need to refine learner models for more effective, adaptive, and individualized educational experiences.
Personalized learning recommendation systems utilize various features such as learner profiles (e.g., learning style, competency level) [29], content attributes (e.g., topic, format, difficulty) [30], historical interactions (e.g., resource usage, ratings) [31], and contextual data (e.g., time of day, location) [32]. These systems are typically categorized into four main types: content-based, collaborative filtering, hybrid, and deep learning-based approaches [33]. Content-based systems match learning resources to a learner’s preferences. For example, a student interested in mathematics may receive related videos, exercises, or quizzes [34, 35]. Collaborative filtering systems, in contrast, draw on group behavior patterns to suggest learning materials [36], often using data such as user ratings and reviews [37]. Hybrid systems integrate both content-based and collaborative filtering methods, resulting in more accurate and diverse recommendations [38, 39]. Deep learning-based approaches can model complex relationships between learners and resources [40], but they still face challenges in adapting to individual learning needs, styles, and pacing due to technological constraints and limited interpretability.
2.2 Large Language Models (LLMs)
LLMs employ deep learning techniques to generate text that closely mimics human language [41]. Trained on massive datasets, these models can respond to diverse inputs with natural articulation, often relying on transformer-based neural network architectures for advanced natural language generation [42]. LLMs have demonstrated remarkable versatility across a wide range of tasks, including natural language processing and creative content generation, with their success largely attributed to sophisticated algorithms and extensive training data [43]. These models can be grouped by function, such as chatbots designed for conversational interaction, and content generation systems that produce written material like stories, essays, or reports [44, 45]. Another category includes language translation models trained on parallel corpora to convert text between languages. Recent studies have underscored the potential of LLMs in education, particularly in supporting language learning and adult education. They facilitate rapid content generation and personalized learning materials, although human oversight remains crucial to maintain quality and reliability [46]. While the integration of LLMs represents a significant advancement in personalized learning, several challenges persist, including implementation complexity and the difficulty of capturing the nuances of human language in complex learning contexts [47, 48]. These findings highlight both the promise and the limitations of LLMs as transformative tools in modern educational practice.
2.3 Chain-of-thought (CoT) Prompting
CoT prompting enhances the reasoning capabilities of LLMs by generating intermediate steps that simulate human thought processes for complex problem-solving. This reasoning behavior naturally emerges in large-scale LLMs when they are exposed to examples of CoT-based reasoning. Unlike standard prompts, which typically present only a question and a final answer, CoT prompting provides a logical sequence of reasoning steps leading to the conclusion. This structured approach improves problem-solving accuracy in areas such as arithmetic, commonsense reasoning, and symbolic reasoning by offering greater transparency into the model’s decision-making process. CoT prompting has emerged as a key technique for guiding LLMs toward coherent and contextually relevant interactions that more closely resemble human reasoning [49]. By structuring inputs in a logical and progressive manner, it enhances both the accuracy and context-awareness of model outputs [50]. Recent research continues to investigate the nuances of CoT’s effectiveness [51]. For instance, the program of thoughts method separates computation from reasoning through the use of external interpreters, further improving performance in numerical reasoning tasks – particularly in zero-shot scenarios – and outperforming traditional CoT methods [52]. In this study, a novel framework is proposed that integrates LLMs with CoT prompting to advance personalized learning systems. Leveraging LLMs’ capacity for sophisticated content generation, the framework employs a personalization strategy that adapts responses to diverse learner profiles. CoT prompting enhances this process by structuring reasoning to produce more relevant and pedagogically aligned content, particularly for computer programming courses. Unlike prior educational applications of LLMs, which have primarily focused on rapid content generation or interactivity in language and adult learning, this study extends their application to deliver a more nuanced and individualized approach to personalized learning.
2.4 AI-powered Learning Systems
Current AI-powered learning systems can be broadly classified into four categories: content retrieval, personalized learning, adaptive delivery, and reasoning-driven systems. Content retrieval systems, such as Study Pilot [53], aggregate diverse educational resources to support self-directed learning but lack explicit instructional reasoning mechanisms. Personalized learning systems, such as OpenRAG [54], employ modular, learner profile-based personalization through open-source pipelines designed primarily for secondary STEM education. Adaptive delivery systems, exemplified by LearnRAG [55], utilize hybrid retrieval techniques – including Best Matching 25 (BM25), term frequency-inverse document frequency (TF-IDF), and dense retrieval with Facebook AI Similarity Search (FAISS) indexing – to improve efficiency, although they offer limited metacognitive adaptability. Reasoning-driven systems, such as Graph-RAG for MOOCs [56] and PersonaRAG [57], incorporate cognitive mechanisms to enhance conceptual understanding and question–answer accuracy, yet their applications remain largely outside structured instructional settings.
2.5 The Proposed Framework
A review of the literature indicates that no prior work has explicitly integrated LLMs with CoT reasoning for personalized learning recommendations. This study advances AI-enhanced education by employing a CoT-augmented LLM to deliver explicit, step-by-step personalized recommendations, bridging scalable information retrieval with learner-centered and explainable pedagogy that supports instructional reasoning and metacognitive development. The primary contribution of this research is the introduction of a personalized strategy that integrates LLMs and CoT prompting within a personalized learning framework to help diverse learners achieve their individual learning goals. The proposed personalized recommendation framework (PRF) adopts a content-based approach that delivers appropriate learning materials tailored to each learner’s profile through the integration of both preference-based and performance-based features. The framework processes information sequentially, mirroring human reasoning patterns, to improve performance on tasks that require computational thinking and structured problem-solving. By tailoring step-by-step instructional recommendations to individual learners based on their performance and preferences, this integration is expected to enhance learning effectiveness and contribute to the advancement of personalized education systems.
3 Research Methodology
This study received a certificate of approval from the Mae Fah Luang University Ethics Committee on Human Research (Protocol No. EC 24110-13; dated April 1, 2024). The overall research methodology is illustrated in Figure 1.
Figure 1 Research methodology.
The details of each process are explained in this section.
3.1 Design and Development of Learner Profiles
For this study, each learner profile was developed based on two key feature types: performance and preference. The performance feature represents cognitive abilities, while the preference feature encompasses learning styles and other behaviorally oriented characteristics. The following subsections describe these two feature types in detail.
(1) Learner’s preference
Two primary groups of features were used to characterize each learner’s preferences: learning style attributes and behavior-oriented characteristics, as described below.
(1.1) Learning style
Learners differ in how they prefer to engage with and process content. Some learn best through visual materials such as videos or infographics, others through hands-on (kinesthetic) activities, while some prefer reading or listening to explanations. In this study, the VAK learning style model – comprising visual, auditory, and kinesthetic styles – was used to construct learner profiles. This model was selected for its simplicity, practicality, and widespread adoption in educational contexts [58]. It provides a clear structure for classifying learners according to how they prefer to receive and process information. Moreover, it remains highly effective in online learning environments, where digital platforms can deliver multimodal content aligned with diverse sensory preferences, thereby enhancing engagement and information retention.
The visual category includes learners who prefer annotated text or screenshot walkthroughs, short video demonstrations, and visual aids such as diagrams, flowcharts, or code maps, charts, and graphs to facilitate understanding. The auditory category includes learners who benefit most from listening to explanations or lectures, engaging in Q&A or self-explanation, and using podcasts or audio recordings to process information. The kinesthetic category encompasses learners who prefer hands-on activities, such as collaborative group work, experimenting with new tasks, or observing live demonstrations. By identifying a learner’s dominant style within this model, the framework can generate personalized recommendations that align with preferred modalities, thereby improving engagement and comprehension.
To capture more nuanced learning behavior, this study extends the VAK model by defining detailed learner profile categories that combine specific preferences across modalities. These hybrid profiles provide deeper insight into how students process information and allow the recommendation framework to adapt instructional strategies accordingly. It is assumed that each learner may exhibit multiple learning styles simultaneously, with each style represented by a degree of confidence, as shown in Table 1. Accordingly, the simulation was conducted under the assumption that a single learner can demonstrate characteristics of several learning styles at once.
| Learning | Degree of | |
| Styles (L) | Confidence | Description |
| V | V1 | Reading from texts and notes. |
| V2 | Watching videos and following instructions. | |
| V3 | Using diagrams, flowcharts/code maps, or graphs. | |
| A | A1 | Listening to explanations or lectures. |
| A2 | Self-explanation or brief instructor Q&A (verbal). | |
| A3 | Listening to podcasts or audio recordings. | |
| K | K1 | Working with others in a group. |
| K2 | Trying out new experiences or experimenting. | |
| K3 | Observing how something is done. |
(1.2) Behavior-oriented characteristics
Additional features were incorporated to capture a broader range of learner preferences based on behavioral interactions within online learning environments. These additional preference features are activity engagement (A) and system engagement (U). Their inclusion is supported by prior research [60], which emphasizes that learner preferences in digital learning environments extend beyond cognitive and sensory styles to include engagement behaviors and interaction patterns. Specifically, activity engagement (A) represents a learner’s tendency toward active participation and task completion. Prior studies indicate that learners differ in their preference for engaging proactively or participating passively in learning activities, and these tendencies directly influence interaction patterns and the effectiveness of personalized instruction. System engagement (U) refers to the frequency and intensity of a learner’s interactions with digital learning platforms. Learners exhibit distinct preferences regarding how often they access content and digital resources, and these preferences significantly shape their learning trajectories. Further details on behavior-based preference features are presented in Table 2.
Table 2 Behavior-oriented characteristics
| Behavior-oriented characteristics | Description |
| Activity engagement (A) | High engagement: Frequent use, full completion. Moderate engagement: Occasional use, partial completion. Low engagement: Minimal use, incomplete tasks. |
| System engagement (U) | High engagement: Total engagement 60 minutes per session. Moderate engagement: Total engagement between 30 and 59 minutes per session. Low engagement: Total engagement 30 minutes per session. |
By combining learning style attributes with activity engagement (A) and system engagement (U), the recommendation framework constructs a more comprehensive learner preference profile, thereby better supporting personalized and contextually appropriate learning experiences.
(2) Learner’s performance
Performance indicators provide valuable insights into learners’ cognitive abilities, knowledge levels, and learning progress, thereby supporting the generation of personalized and adaptive instructional recommendations. In this study, learner performance was analyzed using the performance level (P) classification, as presented in Table 3.
Table 3 Performance feature detail
| Features | Description |
| Performance | (1) High: A total score of 80% or higher (e.g., 32 out of 40). |
| level (P) | (2) Moderate: A total score between 50% and 79% (e.g., 20–31 out of 40). |
| (3) Low: A total score below 50% (e.g., 20 out of 40). |
By clearly defining this proportional content structure, educators and recommendation frameworks can more precisely monitor and evaluate student progress within specific content domains. These features enable more accurate identification of learning gaps and targeted areas for improvement, thereby enhancing the effectiveness and adaptability of personalized learning strategies.
3.2 Design and Development of Personalized Strategy
To generate personalized responses from LLMs, this study proposes a strategic framework that integrates CoT prompting with detailed learner profiles. The framework ensures that system-generated feedback is both logically structured and contextually appropriate for each learner’s profile. Specifically, the personalization strategy draws on learner profiles that combine preference and performance features. Using these features as inputs, the framework constructs a personalized prompt that guides the LLM to produce tailored recommendation messages. CoT prompting supports this process by decomposing complex tasks into clear, step-by-step reasoning paths that align with each learner’s preferred modalities and demonstrated performance level.
The personalized learning framework developed in this study is grounded in constructivism [61], metacognition [62], and behaviorism (operant conditioning) [63]. From a constructivist perspective, the framework emphasizes learner performance through active engagement and scaffolded problem-solving, enabling knowledge construction within authentic contexts. The integration of chain-of-thought (CoT) reasoning directly supports metacognitive development by externalizing the reasoning pathway, which encourages learners to reflect on, monitor, and regulate their thought processes. Simultaneously, principles of behaviorism – particularly operant conditioning – are incorporated through the inclusion of learning styles and behavioral factors, where personalized recommendations function as reinforcements that guide and sustain desirable learning behaviors. Together, these theoretical underpinnings ensure that the framework not only adapts instructional content to individual learners but also enhances performance, fosters reflective thinking, and strengthens grounded learning outcomes. To implement the proposed strategy, the framework includes several key components, as outlined in Table 4.
Table 4 Personalized strategy components and descriptions
| Required | ||
| Components | Description | features |
| Weakness (W) | Assigning topics that require improvement; the learner’s performance level (P) is below the cut-score; targeted remediation is required. | P |
| Strength (S) | Assigning topics that show mastery; the learner’s performance level (P) meets or exceeds the cut-score; assign extension tasks. | P |
| Learner engagement strategy (RE) | Adapts the recommendation strategy based on the learner’s activity (A) and system usage (U). | A, U |
| Learning style strategy (RL) | Selects the optimal content format by matching the learner’s VAK (visual, auditory, kinesthetic) profile. | L |
| Recommendation message (M) | Providing AI-generated, CoT-structured guidance with actionable next steps and motivational support. | RE, RL, S, W, P |
| Test completion status (G) | Tracking chapter-level progress (e.g., “Completed Ch. 1–2; Pending Ch. 3–4”) to monitor learning advancement. | P |
As shown in Table 4, each component is derived from its corresponding inputs. For instance, the recommendation message (M) is generated based on RE, RL, W, S, and P.
(1) Personalized recommendation algorithm
The algorithms for constructing personalized recommendations are presented in Algorithms 1–5 below:
| Algorithm 1: Retrieve learner profile |
| Input: Learner ID |
| Output: Learner Profile {L, A, U, P} |
| Begin: |
| 1. Query database using LearnerID |
| 2. Retrieve: |
| L learner info; A activity data; U system engagement; P performance |
| 3. Construct LearnerProfile {L, A, U, P} |
| 4. Return LearnerProfile |
| End |
| Algorithm 2: Determine strengths and weaknesses |
| Input: P {p…p}, T {t…t}, threshold |
| Output: S Strengths, W Weaknesses |
| Begin: |
| For each (p, t): |
| If p add t to S |
| Else add t to W |
| Return (S, W) |
| End |
| Algorithm 3: Determine engagement strategy (3 3 table lookup) |
| Input: Ai {A1, A2, A3}, Ui {U1, U2, U3} |
| Resources: StrategyTable[Ai, Ui] (RE, RecE) |
| Output: RE Engagement Strategy, RecE Recommended Actions |
| Begin: |
| RE StrategyTable[Ai, Ui].Strategy |
| RecE StrategyTable[Ai, Ui].Recommendations |
| Return (RE, RecE) |
| End |
| Algorithm 4: Determine personalized recommendation (v–a–k lookup) |
| Input: Vi {V1, V2, V3}, Ai {A1, A2, A3}, Ki {K1, K2, K3} |
| Resources: LearningActivitiesTable[Vi, Ai, Ki] (RL, RecL) |
| Output: RL Personalized Strategy, RecL Recommended Learning Activities |
| Begin: |
| RL LearningActivitiesTable[Vi, Ai, Ki].Strategy |
| RecL LearningActivitiesTable[Vi, Ai, Ki].Recommendations |
| Return (RL, RecL) |
| End |
| Algorithm 5: Generate personalized recommendation |
| Input: LearnerProfile {L, A, U, P}, RE, RL, S, W |
| Resources: RecE StrategyTable[A_level, U_level].Recommendations |
| RecL LearningActivitiesTable[V, A, K].Recommendations |
| PendingStatusTable: 0 “Complete”, 1–2 “Partially Complete”, 2 |
| “Incomplete”, all pending “Not Started” |
| Output: Recommendation, TestCompletionStatus |
| Begin |
| 1. CoT_Prompt Integrate(LearnerProfile, RE, RL, S, W, P, RecE, RecL) |
| 2. Recommendation LLM(CoT_Prompt) |
| 3. n_pending count(items in P with status {Pending, Missing, Unanswered}) |
| 4. if n_pending |P|then |
| TestCompletionStatus “Not Started” |
| else |
| TestCompletionStatus PendingStatusTable[n_pending] |
| 5. return (Recommendation, TestCompletionStatus) |
| End |
The integration of CoT prompting with learner-specific profiles represents a significant advancement in personalized recommendation systems. By aligning learning content with individual learning styles, performance data, and engagement patterns, the proposed algorithm generates recommendations that are both accurate and contextually relevant. The step-by-step reasoning process supported by CoT enhances transparency in decision-making and enables learning pathways to dynamically respond to each student’s unique needs. This structured yet flexible framework facilitates the delivery of truly personalized learning experiences, which are increasingly vital in diverse and evolving educational environments. Ultimately, the proposed framework fosters greater learner autonomy and contributes to improved academic outcomes.
(2) Sample generated recommendations
Examples of two learners with distinct profiles and their corresponding generated recommendations are presented in Table 5.
Table 5 Samples of student profiles and recommendations
| Items | Student 01 | Student 02 |
| Student name | Student 01 | Student 02 |
| Learning style (L) | V1A1K1 | V1A3K3 |
| Activity level (A) | High engagement | Moderate engagement |
| System engagement (U) | High engagement | High engagement |
| Score level (P) | High (30) | High (32) |
| Weakness (W) | Assignment operators; floating-point precision; if/if-else/nested if; continue; general loop concepts. | Assignment operators; floating-point precision; if/if-else/nested if; continue; general loop concepts. |
| Strengths (S) | Loop constructs; conditional logic; operators (modulo, comparison); data structures (lists, indexing, dictionaries). | Loop constructs; conditional logic; operators (modulo, comparison); data structures (lists, indexing, dictionaries). |
| Recommendation message (M) | Use structured readings, clear explanations, and peer collaboration; verify understanding through discussion and co-coding. | Use self-paced study in a quiet setting with step-wise demos and visual examples; emphasize independent problem-solving. |
| Test completion status (G) | (1) Pair-program a currency converter to practice +=, -= and float handling. (2) Co-design grading logic with nested if. (3) Convert for while using continue in a small team. | (1) Build a solo currency converter with unit tests. (2) Complete logic drills on nested conditions and continue. (3) Create a number-pattern generator to consolidate loop control. |
Table 5 illustrates how the proposed learning framework generates personalized recommendations based on distinct learner profiles. Although both Student 01 and Student 02 demonstrate similarly high performance scores and share comparable strengths and weaknesses in programming concepts, their learning styles and engagement behaviors differ substantially. Student 01 (V1A1K1) exhibits high levels of activity and system engagement, indicating a preference for structured and collaborative learning. Accordingly, the framework recommends peer-based activities such as co-coding sessions, group discussions, and guided logic exercises to reinforce conceptual understanding. In contrast, Student 02 (V1A3K3) displays a more independent and kinesthetic learning style with moderate activity engagement. For this learner, the framework suggests self-paced, hands-on activities supported by visual examples and individual problem-solving exercises. This differentiation demonstrates the framework’s capacity to deliver tailored learning experiences that align with each learner’s cognitive and behavioral profile, thereby enhancing engagement and promoting deeper conceptual understanding.
3.3 Implementation of Recommendation Framework
This section outlines the configuration and integration of the personalized learning recommendation framework developed to enhance learning outcomes. The key components of the technical implementation are presented in Table 6.
Table 6 Technical details of framework implementation
| Component | Description | Implementation details |
| LangChain Library | Supports the development of conversational AI agents. | Utilizes pretrained models for natural language understanding and generation. |
| OpenAI’s APIs | Enables custom interactions with OpenAI’s models for tailored educational experiences. | Provides access to powerful language models like GPT-4 through API calls for generating responses. |
| Vector DB | Manages document embeddings to facilitate efficient data retrieval. | Uses state-of-the-art embedding techniques to store and retrieve relevant documents quickly. |
| Chroma DB | Another database system used for managing document embeddings. | Similar to Vector DB, it enhances the speed and accuracy of data retrieval through efficient embedding storage. |
| External services | Includes services like OpenAI and HuggingFace for model responses and Wikipedia API for content retrieval. | Integrates various APIs to enhance the functionality and coverage of the recommendation system. |
| Recommendation module | Manages user requests and coordinates with other subsystems to process data and generate recommendations. | Employs advanced algorithms to interpret user data and generate personalized learning recommendations. |
As shown in Table 6, the learning framework employs various programming libraries and APIs to embed AI-driven functionalities within the learning platform. Figure 2 illustrates how learner interactions with subject content are facilitated through an interactive framework that incorporates prompting techniques.
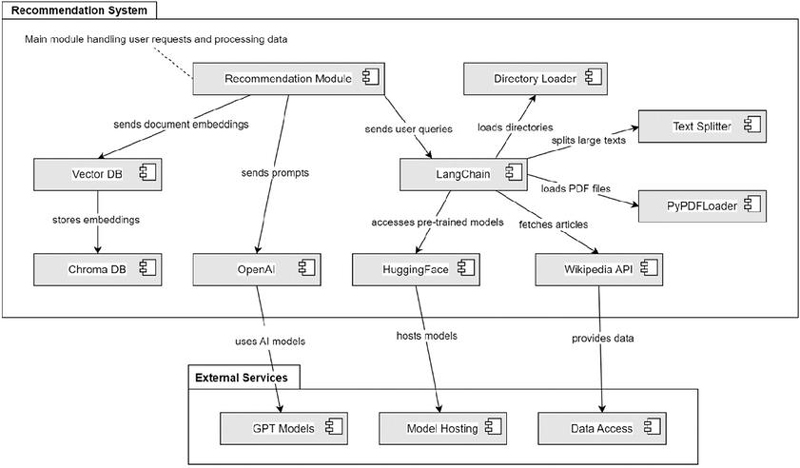
Figure 2 Architecture operationalizing the personalized-learning framework.
Figure 2 illustrates the architecture of the proposed recommendation framework, which functions as an integrated system for managing user requests and generating intelligent, context-aware recommendations. At its core, the recommendation module acts as the central controller, coordinating data flow and interactions among various components. The framework employs a directory loader to import data from directories, supported by Text Splitter and PyPDFLoader modules that divide large text files and extract content from PDF documents. Once the data are prepared, LangChain manages user queries and facilitates communication between internal components and external AI models. The Vector DB and Chroma DB store and retrieve document embeddings, enabling efficient semantic search and contextual matching. External AI resources, including OpenAI, Hugging Face, and the Wikipedia API, provide pretrained models and factual information that enhance the relevance and quality of recommendations. An external services layer offers access to GPT models, model hosting, and data access services, ensuring that the framework remains scalable, current, and capable of leveraging advanced AI models. Collectively, these interconnected modules enable the framework to process diverse data sources, interpret user intent, and deliver adaptive, personalized recommendations with high efficiency and contextual accuracy.
3.4 Evaluation of the Personalized Recommendation Framework (PRF)
An assessment was conducted to evaluate both the effectiveness of the proposed personalized recommendation framework (PRF) and expert satisfaction with its performance. The first assessment analyzed the statistical differences between the system with and without the PRF to determine whether integrating the PRF yields greater instructional benefits despite the longer computational time compared to the non-personalized version. The second assessment examined the perceived benefits of the proposed framework for real learners from an instructional perspective. The details of each assessment are described below.
(1) Evaluation of the effectiveness of the personalized framework
The evaluation was conducted against a baseline consisting of recommendations generated by the system without the personalized recommendation framework (PRF) to determine whether the inclusion of the proposed framework yields measurable improvements. The assessment focused on key metrics, including the quality, relevance, and perceived usefulness or satisfaction of the generated recommendations. A total of fifteen experts participated in the evaluation. All participants were university lecturers who taught computer programming-oriented courses and met the pre-specified criterion of having at least three years of teaching experience in the subject. Each expert reviewed the generated recommendations and completed a 10-item survey using a 5-point Likert scale (1 strongly disagree, 5 strongly agree) to capture their perceptions. The following hypotheses were established for analysis:
H0: There is no significant difference in mean satisfaction scores between recommendations generated by the system with and without the PRF.
H1: Recommendations generated by the system with the PRF achieve higher mean satisfaction scores than those without it.
To test these hypotheses, a paired t-test was performed at a significance level of .
(2) Evaluation of expert satisfaction
Based on the survey results, expert satisfaction with both systems (with and without the PRF) was analyzed in greater detail across specific satisfaction dimensions. The interpretation of mean scores was defined as follows: values between 4.51–5.00 indicate a very high level of agreement, 3.51–4.50 a high level, 2.51–3.50 a moderate level, 1.51–2.50 a low level, and 1.00–1.50 a very low level of agreement. This scoring and interpretation scheme provided a consistent basis for evaluating and interpreting the experts’ satisfaction with the proposed framework.
4 Results and Discussion
The results of the two assessments are presented and discussed in this section, with detailed findings summarized below.
4.1 Evaluation Results of the Effectiveness of PRF
Table 7 presents the satisfaction scores provided by fifteen experts for the recommendations generated by the system with and without the PRF.
Table 7 Average expert satisfaction scores for system with and without PRF
| Average satisfaction score | ||
| Question | System with PRF | System without PRF |
| 1. The recommendations provided by the method accurately reflect the individual learning needs of each student. | 4.5 | 3.67 |
| 2. The content suggested by the method is relevant and suitable for the educational level and capabilities of the students. | 4.5 | 4.0 |
| 3. The timing and pacing of the recommended interventions are appropriate for the students’ learning progressions. | 4.5 | 3.67 |
| 4. The method effectively identifies students who are in urgent need of support and provides timely recommendations for them. | 5 | 4.33 |
| 5. The recommendations include a diverse range of resources and activities that cater to different learning styles and preferences. | 4.5 | 3.67 |
| 6. The volume of content recommended by the method is manageable for students without causing overwhelm. | 4.5 | 4.00 |
| 7. The recommendations facilitate personalized learning experiences that are tailored to the unique needs of each student. | 5 | 4.33 |
| 8. The method’s recommendations encourage student engagement and motivation in the learning process. | 4 | 3.00 |
| 9. The feedback and follow-up actions suggested by the method are clear, actionable, and beneficial for student improvement. | 4 | 3.33 |
| 10. Overall, I am confident in the method’s ability to provide accurate and effective recommendations for enhancing student learning outcomes. | 4.5 | 3.33 |
As shown in Table 7, item-level satisfaction scores were higher for all 10 items when the personalized recommendation framework (PRF) was applied. The highest mean scores with the PRF were observed for Item 4 and Item 7 (both 5.00), while the lowest means were recorded for Item 8 and Item 9 (both 4.00). Even these lowest PRF means remained higher than their corresponding non-PRF means (3.00 and 3.33, respectively).
Table 8 presents the average mean differences across all key metrics, based on the responses of fifteen experts comparing the system with and without the PRF.
Table 8 Mean differences from experts for systems with and without the PRF
| Mean | |||
| Key Metric | System with PRF | System without PRF | Mean Difference |
| Quality (Item 1,3,4,9) | 4.33 | 3.56 | +0.77 |
| Relevance (Item 2,5) | 4.63 | 3.83 | +0.80 |
| Perceived usefulness and satisfaction (Item 6,7,8,10) | 4.50 | 3.78 | +0.72 |
| Overall average | 4.50 | 3.73 | +0.77 |
As shown in Table 8, the mean scores for the system with the PRF were consistently higher than those for the system without it. Quality averaged 4.33 with the PRF compared to 3.56 without (difference 0.77). Relevance averaged 4.63 with the PRF versus 3.83 without (difference 0.80). Perceived usefulness and satisfaction averaged 4.50 with the PRF compared to 3.78 without (difference 0.72). Overall, the system with the PRF achieved an average score of 4.50, while the system without it averaged 3.73 (difference 0.77). The statistical significance test comparing the two systems is presented in Table 9.
Table 9 Comparative satisfaction scores: System with and without PRF (paired t-test, one-tailed)
| System | N | Mean | S.D. | t | Sig. (1-tailed) |
| With PRF | 15 | 4.5 | 0.30 | 7.25 | 0.001* |
| Without PRF | 15 | 3.73 | 0.21 | ||
| *p 0.001. | |||||
As shown in Table 9, the results of the paired t-test reveal a highly significant difference in expert satisfaction between the two systems (t 7.25, p 0.001). Recommendations generated by the system with the personalized recommendation framework (PRF) (M 4.50, SD 0.30) received significantly higher satisfaction ratings than those generated by the system without the PRF (M 3.73, SD 0.21). This finding strongly supports the alternative hypothesis (H1), confirming that integrating the PRF produces recommendations perceived as more accurate, relevant, and useful. Although the PRF requires slightly more computational time, its structured reasoning – particularly through the CoT component – plays a key role in enhancing the quality and pedagogical value of the personalized guidance.
4.2 Evaluation Results of Expert Satisfaction
As shown in Table 7, the system without the personalized recommendation framework (PRF) received moderate-to-high ratings, with an overall mean of 3.73/5. Its primary strengths were in identifying learners in urgent need of support and providing personalization (both 4.33), along with solid ratings for relevance and manageable workload (4.00 each). However, lower scores were reported for engagement and motivation (3.00), clarity and actionability of feedback (3.33), and alignment with individual needs, pacing, and resource diversity. In contrast, experts rated the system with the PRF highly across all dimensions, yielding an overall mean of 4.50/5. The highest confidence was expressed in the framework’s ability to identify urgent learners and provide timely, personalized support (both 5.00). Accuracy to individual needs, relevance to learning level, pacing, resource diversity, and manageable workload each scored 4.50, reflecting consistent alignment with instructional priorities. Engagement and clarity of feedback were slightly lower but remained positive (4.00 each). Overall, experts viewed the CoT-enhanced approach as delivering reliably accurate, well-paced, and actionable recommendations that effectively support differentiated instruction. In summary, while the non-PRF system demonstrated some usefulness, it was perceived as less precise, less engaging, and less actionable than the personalized framework.
4.3 Discussion
Based on the satisfaction results, experts consistently favored the system with the PRF, citing higher overall satisfaction and top ratings for its ability to identify learners in urgent need of support and to deliver timely, truly personalized recommendations. The PRF-based system also performed strongly in terms of accuracy to individual needs, relevance, pacing, resource diversity, and manageable workload, indicating that its structured reasoning improves both instructional alignment and actionability. However, two areas still present opportunities for improvement: engagement and motivation and clarity and actionability of follow-up feedback. Although these dimensions received positive ratings, they were comparatively lower than other metrics. This suggests potential for enhancement through strategies such as incorporating motivational cues (e.g., gamified nudges) and refining feedback templates (e.g., stepwise corrections or exemplar-based guidance). A practical limitation of the PRF is its higher computational cost resulting from the chain-of-thought (CoT) structure, which may affect real-time performance as the system scales. This challenge could be mitigated through prompt optimization, caching mechanisms, or selectively applying CoT reasoning to complex or high-priority cases. Finally, given the relatively small expert panel, these findings should be considered promising yet exploratory, underscoring the need for validation with larger and more diverse instructor cohorts.
In this framework, personalization arises from the combined use of preference and performance features. Preference features determine how support is provided by aligning the format, pace, and interaction style with each learner’s habits, thereby enhancing relevance, motivation, and comfort. Performance features determine what to focus on by identifying errors, knowledge gaps, and learning plateaus, ensuring that recommendations target areas with the greatest potential for improvement. The table-lookup strategies enable fast and interpretable decision-making, while the CoT layer translates these insights into actionable guidance for instructors. Together, these elements improve accuracy (delivering the right content), usability (using the right format), and timeliness (at the right moment), ultimately increasing satisfaction and instructional effectiveness.
The proposed framework can be adapted to other courses by modifying its preference and performance features to reflect subject-specific characteristics. By redefining learning attributes, activities, and feedback modalities, the same personalization algorithm can be applied across multiple disciplines. The CoT component can also be fine-tuned with domain-specific prompts, supporting scalable and adaptable personalized learning across diverse educational contexts. A key limitation of this study is that the framework has not yet been tested with real learners, leaving its practical effectiveness and adaptability in authentic online classroom environments unverified. Without empirical validation, important factors such as learner engagement, cognitive load, and responsiveness to dynamic personalization cannot be fully assessed. Moreover, the simulation-based evaluation may not capture contextual influences such as instructor intervention, classroom diversity, or technological constraints. Future research should therefore include pilot implementations involving real learners to assess usability, learning outcomes, and scalability in practical settings.
In practical application, the proposed personalized learning framework has the potential to substantially enhance both teaching and learning effectiveness. By dynamically adapting content, modality, and feedback to each learner’s preferences and performance, it can improve engagement, comprehension, and knowledge retention. Teachers benefit from the actionable insights produced through the CoT layer, which enables more targeted support and timely intervention. At scale, the framework facilitates data-driven decision-making, reduces instructional workload, and promotes equity by ensuring that diverse learners receive personalized yet transparent learning experiences. Overall, its implementation can contribute to more efficient, inclusive, and learner-centered educational environments.
5 Conclusion
This study examined the integration of CoT prompting with LLMs in a personalized recommendation system, focusing on applications in computer programming courses. Specifically, it presented a novel PRF that employs LLMs and CoT prompting to enhance personalized learning in online environments. By incorporating both preference and performance features of learners, the framework effectively accommodates diverse learner profiles and adapts instructional delivery accordingly. The integration of CoT prompting enables human-like sequential reasoning within LLMs, improving the relevance and precision of generated learning recommendations. A case study conducted in a computer programming course – an area that requires both conceptual understanding and practical problem-solving – served as the evaluation context. The framework’s effectiveness and expert satisfaction were assessed through reviews from fifteen domain experts. Results indicated that the proposed PRF produced recommendations perceived as significantly more satisfactory than those generated without PRF (M 4.50 0.30 vs. 3.73 0.21, p 0.001). Experts also strongly agreed that the framework effectively identified students in urgent need of support, provided timely recommendations, and delivered personalized learning experiences tailored to individual learner needs. Future research on personalized learning frameworks integrating diverse prompting strategies and LLM architectures should focus on enhancing applicability, scalability, and validity while ensuring learner acceptance and trust. In particular, rigorous empirical testing across various subject domains and proficiency levels is essential to evaluate the adaptability, accuracy, and pedagogical value of such AI-driven personalized learning systems.
Acknowledgments
This study is part of the research project entitled ‘Virtual Learning Environment for Enhancing Self-directed Learning Skill and Software Development Skill: A Case Study of High School Students in Chiang Rai Municipality,’ which is funded by the Basic Research Fund 2024, Thailand Science Research and Innovation (TSRI). The publication is supported by Mae Fah Luang University.
References
[1] Ifenthaler, D., and C. Schumacher. 2023. Reciprocal issues of artificial and human intelligence in education. J. Res. Technol. Educ. 55: 1–6. [Online]. Available: https://doi.org/10.1080/15391523.2022.2154511.
[2] How, M. 2019. Future-ready strategic oversight of multiple artificial superintelligence-enabled adaptive learning systems via human-centric explainable AI-empowered predictive optimizations of educational outcomes. Big Data Cogn. Comput. 3: 46. [Online]. Available: https://doi.org/10.3390/BDCC3030046.
[3] Alonso, J., and G. Casalino. 2019. Explainable artificial intelligence for human-centric data analysis in virtual learning environments. pp. 125–138. [Online]. Available: https://doi.org/10.1007/978-3-030-31284-8\_10.
[4] Pardamean, B., T. Suparyanto, T. W. Cenggoro, D. Sudigyo, and A. Anugrahana. 2022. AI-based learning style prediction in online learning for primary education. IEEE Access 10: 35725–35735.
[5] Wan, P., X. Wang, Y. Lin, and G. Pang. 2021. A knowledge diffusion model in autonomous learning under multiple networks for personalized educational resource allocation. IEEE Trans. Learn. Technol. 14: 430–444.
[6] Zalavra, K., Papanikolaou, Y., Dimitriadis, and C. Sgouropoulou. 2022. Personalising learning: towards a coherent learning design framework. In Proc. Int. Conf. Adv. Learn. Technol. (ICALT). pp. 77–79.
[7] Murtaza, Y., J. A. Ahmed, F. Shamsi, et al. 2022. AI-based personalized e-learning systems: issues, challenges, and solutions. IEEE Access 10: 81323–81342.
[8] Zheng, A., Naghizadeh, and Yener. 2022. DiPLe: learning directed collaboration graphs for peer-to-peer personalized learning. In IEEE Inf. Theory Workshop (ITW). pp. 446–451.
[9] Rukmono, S. A., L. Ochoa, and M. R. V. Chaudron. 2023. Achieving high-level software component summarization via hierarchical chain-of-thought prompting and static code analysis. In IEEE Int. Conf. Data Softw. Eng. (ICoDSE). pp. 7–12.
[10] Gemini Team Google. 2023. Gemini: a family of highly capable multimodal models. arXiv. [Online]. Available: https://arxiv.org/abs/2312.11805.
[11] Touvron, H., T. Lavril, G. Izacard, X. Martinet, M. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. 2023. LLaMA: open and efficient foundation language models. arXiv abs/2302.13971.
[12] Shum, K., S. Diao, and T. Zhang. 2023. Automatic prompt augmentation and selection with chain-of-thought from labeled data. arXiv. [Online]. Available: https://doi.org/10.48550/arXiv.2302.12822.
[13] Mani, G., and G. B. Namomsa. 2023. Large language models (LLMs): representation matters, low-resource languages and multi-modal architecture. In IEEE AFRICON. pp. 1–6.
[14] Du, C., J. Tian, H. Liao, J. Chen, H. He, and Y. Jin. 2023. Task-level thinking steps help large language models for challenging classification task. In Proc. Conf. Empirical Methods Nat. Lang. Process. Singapore. pp. 2454–2470.
[15] Feng, G., B. Zhang, Y. Gu, H. Ye, D. He, and L. Wang. 2024. Towards revealing the mystery behind chain of thought: a theoretical perspective. In Adv. Neural Inf. Process. Syst. 36.
[16] Zhang, H., and D. C. Parkes. 2023. Chain-of-thought reasoning is a policy improvement operator. arXiv (Cornell University). doi: 10.48550/arxiv.2309.08589.
[17] Shvetsov, A. N., A. P. Sergushicheva, I. A. Andrianov, M. V. Kharina, and O. Yu. Zaslavskaya. 2020. Student model implementation in the digital educational environment for IT specialists training. J. Phys. Conf. Ser. 1691(1): 012080.
[18] Hao, L., and Q. Liu. 2020. Design of resource recommendation model for personalized learning in the era of big data. In Proc. Annu. Meet. Manage. Eng. (AMME). pp. 181–187. Assoc. Comput. Mach.
[19] Corral, H. Y., J. Clemente, and D. Rodríguez. 2018. Competence-based recommender systems: a systematic literature review. Behav. Inf. Technol. 37(10–11): 958–977.
[20] Pang, F., K.-L. Lu, and W.-J. Gu. 2020. Review on student profile in educational research. In Proc. 5th Int. Conf. Distance Educ. Learn. (ICDEL). pp. 21–24. doi: 10.1145/3402569.3402585.
[21] Bodily, R., J. Kay, I. Vincent, Aleven, et al. 2018. Open learner models and learning analytics dashboards: a systematic review. In Proc. 8th Int. Conf. Learn. Anal. Knowl. (LAK). pp. 41–50.
[22] Yang, F., and F. W. B. Li. 2018. Study on student performance estimation, student progress analysis, and student potential prediction based on data mining. Comput. Educ. 123: 97–108. doi: 10.1016/j.compedu.2018.04.006.
[23] Kulkarni, A. B., A. Shivananda, A. Kulkarni, and V. A. Krishnan. 2023. Applied Recommender Systems with Python. doi: 10.1007/978-1-4842-8954-9.
[24] Camilli, F., and M. Mézard. 2022. Matrix factorization with neural networks. arXiv (Cornell University). doi: 10.48550/arxiv.2212.02105.
[25] Chinnasamy, P., K. B. Sathya, B. J. Jebamani, A. Nithyasri, and S. Fowjiya. 2023. Deep learning: algorithms, techniques, and applications – a systematic survey. Deep Learn. Res. Appl. Nat. Lang. Process. pp. 1–17.
[26] Nian, R., J. Liu, and B. Huang. 2020. A review on reinforcement learning: introduction and applications in industrial process control. Comput. Chem. Eng. 139: 106886. doi: 10.1016/j.compchemeng.2020.106886.
[27] AlShaikh, F., and N. Hewahi. 2021. AI and machine learning techniques in the development of intelligent tutoring system: a review. In Proc. Int. Conf. Innov. Intell. Inform., Comput., Technol. (3ICT). Zallaq, Bahrain. pp. 403–410. doi: 10.1109/3ICT53449.2021.9582029.
[28] Rajendran, R., S. Iyer, and S. Murthy. 2019. Personalized affective feedback to address students’ frustration in ITS. IEEE Trans. Learn. Technol. 12(1): 87–97. doi: 10.1109/TLT.2018.2807447.
[29] Wei, X., S. Sun, D. Wu, and L. Zhou. 2021. Personalized online learning resource recommendation based on artificial intelligence and educational psychology. Front. Psychol. 12. doi: 10.3389/fpsyg.2021.767837.
[30] Liu, J. Y. 2018. A survey of deep learning approaches for recommendation systems. J. Phys. Conf. Ser. 1087: 062022. doi: 10.1088/1742-6596/1087/6/062022.
[31] Hengst, F. D., E. M. Grua, A. E. Hassouni, and M. Hoogendoorn. 2020. Reinforcement learning for personalization: a systematic literature review. Data Sci. 3(2): 107–147. doi: 10.3233/ds-200028.
[32] Yu, X., D. Wei, Q. Chu, and H. Wang. 2018. The personalized recommendation algorithms in educational application. In Proc. Int. Conf. Inf. Technol. Med. Educ. (ITME). Hangzhou, China. pp. 664–668. doi: 10.1109/ITME.2018.00153.
[33] Raj, N. S., and V. G. Renumol. 2021. A systematic literature review on adaptive content recommenders in personalized learning environments from 2015 to 2020. J. Comput. Educ. 9(1): 113–148. doi: 10.1007/s40692-021-00199-4.
[34] Zhao, X., and B. Liu. 2020. Application of personalized recommendation technology in MOOC system. In Proc. Int. Conf. Intell. Transp., Big Data Smart City (ICITBS). Vientiane, Laos. pp. 720–723. doi: 10.1109/ICITBS49701.2020.00159.
[35] Hu, X., Y. Wang, Q. B. Chen, Q. Liu, and X. Fan. 2021. Research on personalized learning based on collaborative filtering method. J. Phys. Conf. Ser. 1757(1): 012050. doi: 10.1088/1742-6596/1757/1/012050.
[36] Geetha, G., M. Safa, C. Fancy, and D. Saranya. 2018. A hybrid approach using collaborative filtering and content-based filtering for recommender system. J. Phys. Conf. Ser. 1000: 012101. doi: 10.1088/1742-6596/1000/1/012101.
[37] Cui, L.-Z., F. Guo, and Y. Liang. 2018. Research overview of educational recommender systems. In Proc. 2nd Int. Conf. Comput. Sci. Appl. Eng. doi: 10.1145/3207677.3278071.
[38] Joy, J., and R. V. G. Pillai. 2022. Review and classification of content recommenders in e-learning environment. J. King Saud Univ. Comput. Inf. Sci. 34(9): 7670–7685. doi: 10.1016/j.jksuci.2021.06.009.
[39] Zhong, L., Y. Wei, H. Yao, W. Deng, Z. Wang, and M. Tong. 2020. Review of deep learning-based personalized learning recommendation. In Proc. Int. Conf. E-Educ., E-Business, E-Manage., E-Learn. (IC4E). Assoc. Comput. Mach. pp. 145–149. doi: 10.1145/3377571.3377587.
[40] Zhang, S., L. Yao, A. Sun, and Y. Tay. 2019. Deep learning-based recommender system. ACM Comput. Surv. 52(1): 1–38. doi: 10.1145/3285029.
[41] Bubeck, S., et al. 2023. Sparks of artificial general intelligence: early experiments with GPT-4. arXiv (Cornell University). doi: 10.48550/arxiv.2303.12712.
[42] Dai, Z., Z. Yang, Y. Yang, J. G. Carbonell, Q. V. Le, and R. Salakhutdinov. 2019. Transformer-XL: attentive language models beyond a fixed-length context. arXiv (Cornell University). doi: 10.48550/arxiv.1901.02860.
[43] Lu, S., I. Bigoulaeva, R. Sachdeva, H. T. Madabushi, and I. Gurevych. 2023. Are emergent abilities in large language models just in-context learning? arXiv (Cornell University). doi: 10.48550/arxiv.2309.01809.
[44] Friedman, L. K., et al. 2023. Leveraging large language models in conversational recommender systems. arXiv (Cornell University). doi: 10.48550/arxiv.2305.07961.
[45] Zhao, W. X., et al. 2023. A survey of large language models. arXiv (Cornell University). doi: 10.48550/arxiv.2303.18223.
[46] Leiker, D., et al. 2023. Prototyping the use of large language models (LLMs) for adult learning content creation at scale. In Proc. AIED Workshop. Tokyo, Japan.
[47] Risang Baskara, F. X. 2023. Navigating the complexities and potentials of language learning machines in EFL contexts: a multidimensional analysis. EAI Endorsed Trans. Creative Technol. 14(3): 1–15.
[48] Gao, Y., et al. 2023. An investigation of applying large language models to spoken language learning. Appl. Sci. 14: 224.
[49] Lee, J., et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. arXiv (Cornell University). doi: 10.48550/arxiv.2201.11903.
[50] Diao, S., P. Wang, L. Ye, and T. Zhang. 2023. Active prompting with chain-of-thought for large language models. arXiv (Cornell University). doi: 10.48550/arxiv.2302.12246.
[51] Mishra, A. K., and K. N. Thakkar. 2023. Stress testing chain-of-thought prompting for large language models. arXiv (Cornell University). doi: 10.48550/arxiv.2309.16621.
[52] Chen, W., X. Ma, X. Wang, and W. W. Cohen. 2023. Program of thoughts prompting: disentangling computation from reasoning for numerical reasoning tasks. Trans. Mach. Learn. Res. 10: 1–16.
[53] Karnati, R. T., H. Kundra, and P. R. S. S. Naidu. 2025. Study Pilot: an AI-powered platform for personalized learning through retrieval-augmented generation on diverse user content. Int. J. Sci. Res. Eng. Manage. 9(6): 1–7. https://doi.org/10.55041/ijsrem.ncft007.
[54] Shan, R. 2024. OpenRAG: open-source retrieval-augmented generation architecture for personalized learning. In Proc. Int. Conf. Artif. Intell., Robot., Commun. (ICAIRC). pp. 212–216. https://doi.org/10.1109/ICAIRC64177.2024.10900069.
[55] Shan, R. 2025. LearnRAG: implementing retrieval-augmented generation for adaptive learning systems. In Proc. Int. Conf. Artif. Intell. Inf. Commun. (ICAIIC). pp. 224–229. https://doi.org/10.1109/ICAIIC64266.2025.10920869.
[56] Abdelmagied, M., M. A. Chatti, S. Joarder, Q. Ul Ain, and R. Alatrash. 2025. Leveraging graph retrieval-augmented generation to support learners’ understanding of knowledge concepts in MOOCs. arXiv preprint arXiv:2505.10074. https://arxiv.org/abs/2505.10074.
[57] Zerhoudi, S., and M. Granitzer. 2024. PersonaRAG: enhancing retrieval-augmented generation systems with user-centric agents. arXiv preprint arXiv:2407.09394. https://arxiv.org/abs/2407.09394.
[58] Spatioti, A., I. Kazanidis, and J. Pange. 2023. Educational design and evaluation models of the learning effectiveness in e-learning process: a systematic review. Turk. Online J. Distance Educ. 24(4): 318–347. https://doi.org/10.17718/tojde.1177297.
[59] Fleming, N. D., and C. Mills. 1992. Helping students understand how they learn. Teach. Professor 7(4).
[60] Wang, Y., M. Zuo, X. He, and Z. Wang. 2025. Exploring students’ online learning behavioural engagement in university: factors, academic performance and their relationship. Behav. Sci. 15(1): 78. https://doi.org/10.3390/bs15010078.
[61] Pricopie, V. 2020. Constructivism. In SAGE Int. Encycl. Mass Media Soc. Vol. 5, pp. 377–378. SAGE Publications, Inc. https://doi.org/10.4135/9781483375519.n148.
[62] Medina, M. S., A. N. Castleberry, and A. M. Persky. 2017. Strategies for improving learner metacognition in health professional education. Am. J. Pharm. Educ. 81(4): 78. https://doi.org/10.5688/ajpe81478.
[63] Abadi, D. P., M. Ramli, and F. Wahyuni. 2025. Analysis of behaviorism theory: classical conditioning and operant conditioning in changing students’ truancy behaviour. J. Pembelajaran Bimbingan Pengelolaan Pendidikan 5(2): 8. https://doi.org/10.17977/um065.v5.i2.2025.8.
Biographies

Tew Hongthong received his B.S.Tech.Ed. in Computer Engineering from Rajamangala University of Technology Lanna, Thailand, his M.Sc in Internet and Information Technology from Naresuan University, Thailand and his M.It in Software Development from Central Queensland University, Australia. His research areas include data classification, machine learning, and educational technology.

Nacha Chondamrongkul is an Associate Professor of Software Engineering with many years of experience in both industry and academia, specializing in software engineering and artificial intelligence. He earned a Ph.D. in Computer Science from the University of Auckland, New Zealand. Nacha’s research covers model-driven software engineering, linear temporal logic, model checking, semantic web, ontology reasoning, and machine learning.

Punnarumol Temdee received her B.Eng. in Electronics and Telecommunication Engineering, M. Eng in Electrical Engineering, and Ph.D. in Electrical and Computer Engineering from the King Mongkut’s University of Technology Thonburi. Currently, she is an Associate Professor at the School of Applied Digital Technology, Mae Fah Luang University, Chiang Rai, Thailand. She is also the head of Computer and Communication Engineering for the Capacity Building Research Center (CCC). Her research interests are artificial intelligence and its applications, data classification, personalized learning, and personalized healthcare.
Journal of Mobile Multimedia, Vol. 21_6, 1105–1134.
doi: 10.13052/jmm1550-4646.2165
© 2025 River Publishers