On Some Improved Classes of Estimators Under Stratified Sampling Using Attribute
Shashi Bhushan1, Anoop Kumar2,*, Dushyant Tyagi and Saurabh Singh2
1Department of Statistics, Lucknow University, Lucknow, India
2Department of Mathematics and Statistics, Dr. Shakuntala Misra National Rehabilitation University, Lucknow, U.P., India
E-mail: anoop.asy@gmail.com
*Corresponding Author
Received 23 February 2022; Accepted 14 March 2022; Publication 16 April 2022
Abstract
This article establishes some improved classes of difference and ratio type estimators of population mean of study variable using information on auxiliary attribute under stratified simple random sampling. The usual mean estimator, classical ratio estimator, classical product estimator and classical regression estimator are identified as particular cases of the proposed classes of estimators for different values of the characterising scalars. The expression of mean square error of the suggested classes of estimators has been studied up to first order of approximation and their effective performances are likened with respect to the conventional as well as lately existing estimators. Subsequently, an empirical study has been carried out using a real data set in support of theoretical results. The empirical results justify the proposition of the proposed classes of estimators in terms of percent relative efficiency over all discussed work till date. Suitable suggestions are forwarded to the survey practitioners.
Keywords: Auxiliary attribute, efficiency, mean square error, stratified simple random sampling.
1 Introduction
In sample surveys, the use of auxiliary information is a well-known fact to enhance the efficiency of the estimators. Several improved and modified ratio, regression, product and logarithmic type estimators have been suggested using auxiliary information under different sampling schemes by various authors including Nazir et al. (2018), Lone et al. (2021), Bhushan et al. (2020a, b, c, 2021a, b), Bhushan and Kumar (2021, 2022), etc. Many times, in real life situations, the variable of interest may not be associated with a quantitative auxiliary variable and some qualitative auxiliary characteristic might be easily available which is significantly associated with the variable of interest. For example:
• The height of person (y) may depend on sex i.e, the person is male or female.
• The amount of yield of paddy crop (y) may rely on a certain variety of paddy ().
• The amount of milk produce (y) may depend on a certain breed of buffalo ().
• The use of drugs (y) may depend on the sex ().
Thus, taking advantage of bi-serial correlation () into consideration, several authors proposed various class of estimators using attribute under different sampling framework. Naik and Gupta (1996) suggested classical ratio, product and regression estimators under simple random sampling (SRS). Singh et al. (2007) introduced attribute based exponential ratio and product type estimators in SRS. Abd-Elfattah et al. (2010) used information on attribute and investigated different exponential type estimators of population mean under SRS. Zaman and Kadilar (2019) addressed a novel family of exponential estimators using information of auxiliary attribute whereas Zaman and Kadilar (2021a) considered a new class of exponential estimators for finite population mean in two-phase sampling. Zaman (2019a) proffered an improved estimators using coefficient of skewness of auxiliary attribute under SRS. Zaman (2020) developed a generalized exponential estimator for the finite population mean based on attribute. Bhushan and Gupta (2020) envisaged an improved log-type family of estimators using attribute in SRS.
When the nature of population is heterogeneous then a well-known stratified simple random sampling (SSRS) is to be used to estimate the population parameters. It is based on dividing the whole population into homogeneous sub-populations known as “strata” and selecting a simple random sample independently from different strata. Sharma and Singh (2013) introduced exponential type estimators under SSRS using known population proportion. Zaman (2019b) evoked an efficient estimators of population mean using auxiliary attribute in SSRS. Zaman and Kadilar (2020) and Zaman (2021) proposed various exponential type estimators for population mean using auxiliary attribute under SSRS. Zaman and Kadilar (2021b) suggested exponential ratio and product type estimators of the mean in stratified two-phase sampling. It has been observed empirically that the efficiency of the above estimators introduced by different authors is at most equal to the classical regression estimator defined on the lines of Naik and Gupta (1996) under SSRS. The above discussion put a question: “Is there any procedure of obtaining better estimator than the classical regression estimator?” In this paper, we have made an effort to answer this question by suggesting some improved classes of difference and ratio type estimators using known population proportions.
The article is organized in following sections. Section 2 considers prominent estimators suggested till date in SSRS using attribute with their properties. In Section 3, we suggested some improved classes of estimators and studied their properties. The efficiency conditions are obtained in Section 4 which are further verified in Section 5 by an empirical study and discussion of empirical results. The conclusion of the study is given in Section 6.
2 Existing Estimators
Consider a finite population consist of N identifiable units which is divided into L homogeneous strata and a simple random sample s of size n is measured from stratum h using simple random sampling without replacement scheme. Let and be the study variable y and auxiliary attribute for unit i in the stratum h of population U. It is noted that if the unit i possess attribute and , otherwise. Let A = and a be the total number of units in the population U and sample s respectively possessing attribute whereas P ( be the population proportion, be the population proportion in stratum h and be the sample proportion of stratum h having attribute . The sample mean of study variable y is , where , the population mean of study variable is , where and the weight of stratum is /N. The population mean square of study variable in stratum h is and population mean square of auxiliary attribute in stratum h is . To obtain the mean square error (MSE) of different estimators, let us assume that and such that E, E, E and E.
Where = ().
Now, we consider a review of some prominent attribute-based estimators under SSRS along with their properties.
The usual mean estimator under SSRS is defined as
| (1) |
The variance of the above estimator is given by
| (2) |
Following Naik and Gupta (1996), the classical combined ratio, product and regression estimators for population mean using auxiliary attribute can be defined under SSRS as
| (3) | |
| (4) | |
| (5) |
where is the regression coefficient of y on and is the sample proportion. The MSE of the above estimators is respectively given by
| (6) | ||
| (7) | ||
| (8) |
where R is the population ratio. Now, minimizing the MSE with respect to (w.r.t.) , we get
Putting in the MSE, we get
| (9) |
The exponential functions model a relationship in which a constant change in the independent variable gives the equal proportional change in the dependent variable. Therefore, motivated by Singh et al. (2007), Sharma and Singh (2013) investigated ratio and product exponential type estimators under SSRS as
| (10) | ||
| (11) |
The MSE of the above estimators is given by
| (12) | ||
| (13) |
Sharma and Singh (2013) introduced another exponential type estimator under SSRS as
| (14) |
where is a suitably chosen scalar.
The MSE of the above estimator is given by
| (15) |
Minimizing the MSE w.r.t. , we get
Putting in the MSE, we get
| (16) |
which is the minimum MSE of the classical regression estimator .
Zaman and Kadilar (2020) envisaged a family of ratio exponential estimator under SSRS as
| (17) |
The MSE of the above estimator is given by
| (18) |
where .
On the lines of Koyuncu and Kadilar (2009), Zaman and Kadilar (2020) suggested an improved form of the above estimator under SSRS as
| (19) |
where is a suitably chosen scalar.
The MSE of the estimator is given by
| (20) |
Minimizing the MSE w.r.t. , we get
Putting in the MSE, we get
| (21) |
On the lines of Zaman (2020), one may define an exponential ratio type estimator using auxiliary attribute under SSRS as
| (22) |
where is a suitably chosen scalar.
The MSE of the estimator is given by
Minimizing the MSE w.r.t. , we get
Putting in the MSE, we get
| (24) |
which is the minimum MSE of classical regression estimator .
Following Abd-Elfattah et al. (2010), Zaman (2021) envisaged following class of estimator under SSRS as
| (25) | ||
| (26) | ||
| (27) | ||
| (28) | ||
| (29) |
where ), ), ), , ), ), , ), . Here, and are respectively the coefficient of variation and coefficient of kurtosis of auxiliary attribute and is the bi-serial correlation coefficient between study variable and auxiliary attribute in stratum h.
The MSE of the above estimators is given by
| (30) |
where , , .
Zaman (2021) suggested another improved estimator under SSRS given as
| (31) |
where is a suitably chosen scalar, such that m and n are either real values or the function of known parameters associated with the auxiliary attribute namely, standard deviation , coefficient of correlation , coefficient of kurtosis , coefficient of variation , etc in stratum h.
The MSE of the above estimator is given by
where .
Minimizing the MSE w.r.t. , we get
Putting in the MSE, we get
| (33) |
which is the minimum MSE of classical regression estimator .
3 Proposed Classes of Estimators
Motivated by Bhushan and Kumar (2020) and Bhushan et al. (2021c), we have proposed some improved classes of difference and ratio type estimators for population mean using attribute under SSRS as
| (34) | ||
| (35) | ||
| (36) | ||
| (37) | ||
| (38) | ||
| (39) |
where , , i 1,2,…,6 are suitably chosen scalars, , , m and n are either real values or function of parameters of auxiliary attribute .
Theorem 3.1. The minimum MES of the proposed class of estimators is given by
| (40) |
Proof: Consider the estimator
Express the above estimator in terms of e’s, we get
| (41) |
Squaring both sides of (41) and taking expectation, we will get the MSE of the estimator up to first order of approximation as
| (42) |
The above MSE is minimized for and as
and
Putting and in the MSE(, we get the minimum MSE as
| (43) |
The minimum MSE of the other estimator can be found in similar lines.
Theorem 3.2. The minimum MSE of the proposed classes of estimators is given by
| (44) |
Proof: Using the notations discussed earlier, the MSE of estimator is given by
| (45) |
which can further be written as
| (46) |
Minimizing the MSE( w.r.t. the scalar , we get
Putting in the MSE(), we get
| (47) |
The MSE of other estimators can be obtained in similar lines. In general, we can write
It is to be noted that the simultaneous minimization of and of the above MSE expression is not possible so we utilize the optimum values of when and use this within to obtain the MSE expressions. The optimum values of the scalars are given by
where
Here, and are used as an optimum values when = 1 is considered in the corresponding estimators.
4 Efficiency Conditions
We compare the minimum MSE of the proposed estimators , with the minimum MSE of the existing estimators and get the following efficiency conditions.
(i). On comparing minimum MSE of the proposed estimators with mean per unit estimator from (40) and (44) with (2), we get
| (48) |
(ii). On comparing minimum MSE of proposed estimators with classical ratio estimator from (40) and (44) with (6), we get
| (49) |
(iii). On comparing minimum MSE of proposed estimators with classical product estimator from (40) and (44) with (7), we get
| (50) |
(iv). On comparing minimum MSE of proposed estimators and classical regression estimator , Sharma and Singh (2013) estimator , Zaman (2020) estimator T and Zaman (2021) estimator from (40) and (44) with (9), (16), (24), (33) respectively, we get
| (51) |
(v). On comparing minimum MSE of proposed estimator with Sharma and Singh (2013) estimator from (40) and (44) with (12), we get
| (52) |
(vi). On comparing minimum MSE of proposed estimators with Sharma and Singh (2013) estimator from (40) and (44) with (13), we get
| (53) |
(vii). On comparing minimum MSE of proposed estimators with Zaman (2021) estimators , from (40) and (44) with (30), we get
| (54) |
(viii). On comparing minimum MSE of proposed estimator with Zaman and Kadilar (2020) estimator from (40) and (44) with (18), we get
| (55) |
(ix). On comparing minimum MSE of proposed estimators with Zaman and Kadilar (2020) estimator from (40) and (44) with (21), we get
| (56) |
It is to be noted that only under above conditions, the proposed classes of estimators , become superior than the usual mean estimator, classical ratio, product and regression estimators, Sharma and Singh (2013) estimator, Zaman and Kadilar (2020) estimator, Zaman (2020) type estimator and Zaman (2021) estimators. Subsequently, these conditions are verified through an empirical study using real data set.
5 Empirical Study
In order to verify the theoretical results of the proposed classes of estimators, we have performed an empirical study over the data set of Kadilar and Cingi (2003). The data set is based on the production of apples as study variable and number of apple trees as auxiliary variable in six regions of Turkey namely, Marmara, Agean, Mediterranean, central Anatolia, Black Sea and East and Southeast Anatolia in 1999. These six regions of Turkey are considered as sub-population/strata. Taking Neyman allocation (Cochran, 1977) into consideration, we have randomly drawn the districts from each strata using given formula:
| (57) |
Neyman allocation (Neyman, 1934) is a method to allocate samples into strata based on the strata variance and corresponding sampling cost in the strata which gives an unbiased estimator of population mean provided the total sample size. The different strata may not differ much from each other w.r.t. costs. We consider equal costs for all strata. However, the sample can often be divided into subsamples using SSRS such that for L subsamples, each of them has a sample size , h 1,2,…,L, with . A sample of size n 200 units is drawn with the help of Neyman allocation defined in (57) and summarized in Table 1. The percent relative efficiency (PRE) of the class of estimators with respect to mean per unit estimator are computed using the following formula:
where T= i 1,2,3, , , and , i 1,2,…,6. The empirical results are displayed in Table 2 in terms of MSE and PRE. These results of Table 2 are further displayed through line diagrams given in Figures 1 and 2 by MSE and PRE respectively.
Table 1 Descriptive statistics of the population
| Known | Symbol for | |||||||
| Parameters | Total | Stratum h | 1 | 2 | 3 | 4 | 5 | 6 |
| Population size | N 854 | 106 | 106 | 94 | 171 | 204 | 173 | |
| Sample size | n 200 | 13 | 24 | 55 | 95 | 10 | 3 | |
| Population mean | 1536 | 2212 | 9384 | 5588 | 966 | 404 | ||
| Population proportion | P 0.334 | 0.24 | 0.29 | 0.46 | 0.48 | 0.36 | 0.11 | |
| Standard deviation | 17105 | 6425 | 11551 | 29907 | 28643 | 2389 | 945 | |
| Standard deviation | 0.466 | 0.43 | 0.45 | 0.50 | 0.50 | 0.48 | 0.32 | |
| Kurtosis coefficient | 0.56 | 1.16 | -2.03 | 2.02 | 1.68 | 3.93 | ||
| Variation coefficient | 1.46 | 1.76 | 1.56 | 1.07 | 1.03 | 1.33 | 2.77 | |
| Covariance coefficient | 904.7 | 996 | 1404 | 48674 | 2743 | 449 | 204 | |
| Weight | 0.12 | 0.12 | 0.11 | 0.20 | 0.24 | 0.32 |
Table 2 MSE and PRE of different estimator with respect to
| Estimators | MSE | PRE |
| 387786.7 | 100.0000 | |
| 276560.1 | 140.2179 | |
| 970347.4 | 39.9637 | |
| 260132.8 | 149.0726 | |
| 273256.6 | 141.9130 | |
| 620150.3 | 62.5310 | |
| 357499.9 | 108.4718 | |
| 357160.8 | 108.5748 | |
| 358365.0 | 108.2100 | |
| 358812.8 | 108.0749 | |
| 347115.3 | 111.717 | |
| 360353.6 | 107.6128 | |
| 333791.4 | 116.5447 | |
| , i 1,3,4,6 | 253704.6 | 152.8497 |
| , i 2,5 | 252556.1 | 153.5447 |
| where . | ||
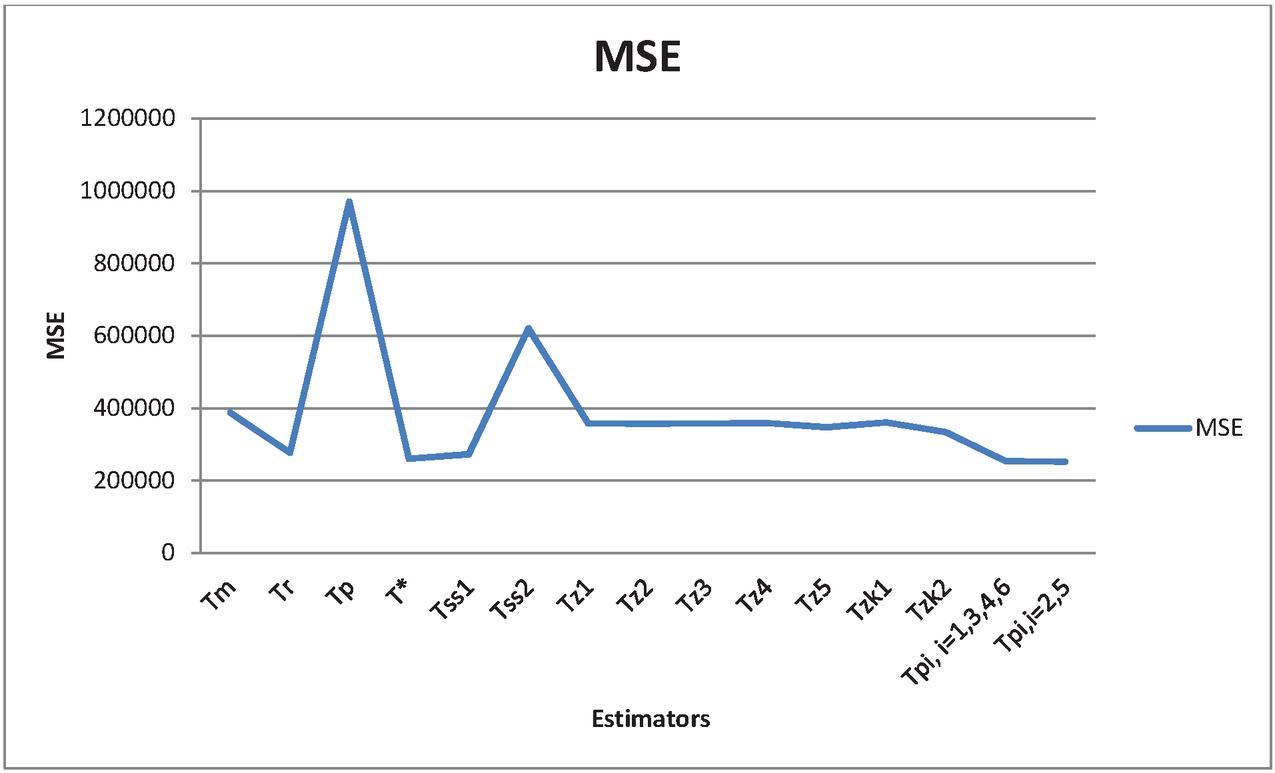
Figure 1 MSE of existing and proposed estimators.
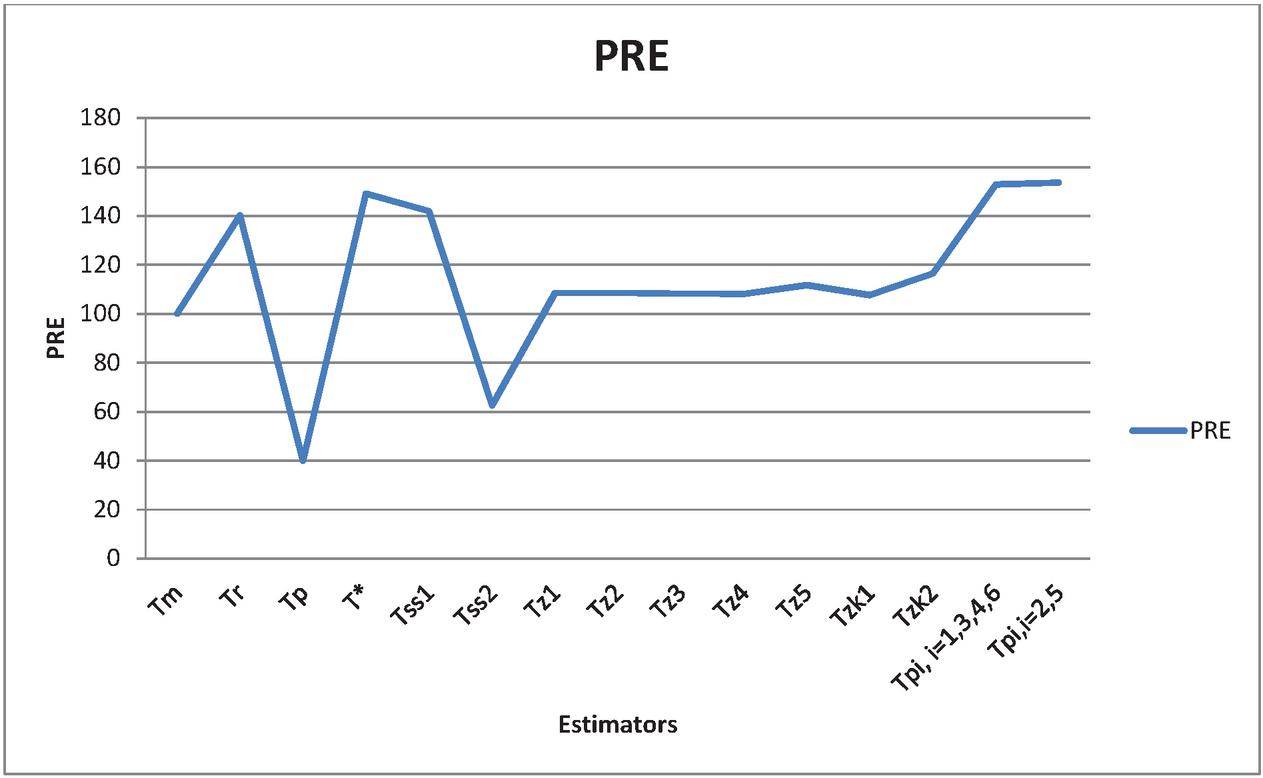
Figure 2 PRE of existing and proposed estimators.
5.1 Results and Discussion
On comparing the outcomes of Table 2, it has been observed that:
1. the proposed classes of estimators , are highly rewarding in terms of minimum MSE than the existing estimators such as usual mean estimator , classical ratio estimator , classical product estimator , classical regression estimator , Sharma and Singh (2013) estimator , Zaman and Kadilar (2020) estimators , Zaman (2020) type estimator and Zaman (2021) estimators . This can be easily observed from line diagram displayed in Figure 1.
2. the proposed classes of estimators , are found to be efficient in terms of maximum PRE providing better improvement over the existing estimators such as usual mean estimator , classical ratio estimator , classical product estimator , classical regression estimator , Sharma and Singh (2013) estimator , Zaman and Kadilar (2020) type estimators , Zaman (2020) type estimator and Zaman (2021) estimators . This can be easily observed from line diagram displayed in Figure 2.
3. Moreover, the proposed class of estimator , i 2,5 performed better than the other proposed classes of estimators in terms of minimum MSE and maximum PRE which can be also observed from line diagrams displayed in Figures 1 and 2 for MSE and PRE respectively.
6 Conclusion
This paper proposes some improved classes of estimators under stratified simple random sampling to estimate population mean with their properties. The usual mean estimator, classical ratio, product and regression estimators are special cases of the suggested classes of estimators for suitably chosen values of characterizing scalars. The proposed classes of estimators are turned out to be remunerating in terms of MSE and PRE when applied in real life scenario. These estimators are also showing their supremacy in terms of lesser MSE and greater PRE over conventional estimators such as mean estimator , ratio estimator , product estimator , regression estimator , Sharma and Singh (2013) estimator , Zaman and Kadilar (2020) estimators , Zaman (2020) type estimator and Zaman (2021) estimators when empirical study has been performed over real data. The performances of different estimators can also be observed from the Figures 1 and 2 displayed for MSE and PRE respectively. The empirical results support that the proposed classes of estimators are appreciatively favorable in abating the MSE to a greater extend as compare to the conventional estimators. Hence, looking on the assured behavior of the proposed classes of estimators, survey practitioners may be encouraged to utilize the proposed classes of estimators for their practical applications.
Acknowledgement
Authors are extremely thankful to the learned referees for their valuable suggestions regarding improvement of the paper and to the editor-in-chief Prof. Dr. Mangey Ram.
References
[1] Abd-Elfattah A.M., El-Sherpiency, E.A., Mohamed, S.M. and Abdou, O.F (2010). Improvement in estimating the population mean in simple random sampling using information on auxiliary attribute. Applied Mathematics and Computation, 215, 4198–4202. DOI: https://doi.org/10.1016/j.amc.2009.12.041
[2] Bhushan, S. and Gupta, R. (2020). An improved log-type family of estimators using attribute. Journal of Statistics and Management Systems, 23(3), 593–602.
[3] Bhushan S., Gupta R., Singh S. and Kumar A. (2020a). A new efficient log type class of estimators using auxiliary variable. International Journal of Statistics and Systems, 15(1), 19–28.
[4] Bhushan S., Gupta R., Singh S. and Kumar A. (2020b). A modified class of log type estimators for population mean using auxiliary information on variables. International Journal of Applied Engineering Research, 15(6), 612–627.
[5] Bhushan S., Gupta R., Singh S. and Kumar A. (2020c). Some improved classes of estimators using auxiliary information. International Journal for Research in Applied Science & Engineering Technology, 8(6), 1088–1098. DOI: http://doi.org/10.22214/ijraset.2020.6176
[6] Bhushan, S., Kumar, A. and Lone, S.A. (2021a). On some novel classes of estimators under ranked set sampling. AEJ-Alexandria Engineering Journal, 61, 5465–5474. https://doi.org/10.1016/j.aej.2021.11.001.
[7] Bhushan, S., Kumar, A., Pandey, A.P. and Singh, S. (2021b). Estimation of population mean in presence of missing data under simple random sampling. Communications in Statistics – Simulation and computation. https://doi.org/10.1080/03610918.2021.2006713.
[8] Bhushan, S., Kumar, A. and Singh, S. (2021c). Some efficient classes of estimators under stratified sampling. Communications in Statistics – Theory and Methods, 1-30. DOI: 10.1080/03610926.2021.1939052.
[9] Bhushan, S. and Kumar, A. (2020). On optimal classes of estimators under ranked set sampling. Communications in Statistics – Theory and Methods, 1–30. DOI: 10.1080/03610926.2020.1777431
[10] Bhushan, S. and Kumar, A. (2021). Novel log type class of estimators under ranked set sampling. Sankhya B, 1–27. https://doi.org/10.1007/s13571-021-00265-y
[11] Bhushan, S. and Kumar, A. (2022). An efficient class of estimators based on ranked set sampling. Life Cycle Reliability and Safety Engineering. https://doi.org/10.1007/s41872-021-00183-y
[12] Cochran, W.G. (1977). Sampling Techniques (3rd Edition). John Wiley, New York.
[13] Kadilar, C. and Cingi, H. (2003). Ratio estimators in stratified random sampling. Biometrical Journal, 45(2), 218–225. DOI: 10.1002/bimj.200390007
[14] Koyuncu, N. and Kadilar, C. (2009). Ratio and product estimators in stratified random sampling. Journal of Statistical planning and Inference, 139(8), 2552–2558. DOI: 10.1016/j.jspi.2008.11.009
[15] Lone, S.A., Subzar, M. and Sharma, A. (2021). Enhanced estimators of population variance with the use of supplementary information in survey sampling. Mathematical Problems in Engineering, 1–8. https://doi.org/10.1155/2021/9931217
[16] Nazir, A., Maqbool, S. and Ahmad, S. (2018). Modified Linear Regression Estimators Using quartiles and Standard Deviation. Journal of Statistics Application & Probability, 7(2), 379–388.
[17] Naik, V.D. and Gupta, P.C (1996). A note on estimation of mean with known population proportion of an auxiliary character. Journal of Indian Society for Agricultural Statistics, 48(2), 151–158.
[18] Neyman, J. (1934). On the two different aspects of the representative method: the method of stratified sampling and the method of purposive selection. Journal of the Royal Statistical Society, 97(4), 558–625. DOI: 10.2307/2342192
[19] Sharma, P. and Singh, R. (2013). Efficient estimator of population mean in stratified random sampling using auxiliary attribute. World Applied Science Journal, 27(12), 1786–1791. DOI: 10.5829/idosi.wasj.2013.27.12.1551
[20] Singh R., Chouhan P., Sawan, N. and Smarandache, F. (2007). Ratio-product type exponential estimator for estimating finite population mean using using information on auxiliary attribute. Renaissance High Press, USA, 18–32.
[21] Zaman, T. and Kadilar, C. (2019). Novel family of exponential estimators using information of auxiliary attribute. Journal of Statistics and Management Systems, 22(8), 1499–1509.
[22] Zaman, T. and Kadilar, C. (2020). On estimating the population mean using auxiliary character in stratified random sampling. Journal of Statistics and Management Systems, 23(8), 1415–1426.
[23] Zaman, T. and Kadilar, C. (2021a). New class of exponential estimators for finite population mean in two-phase sampling. Communications in Statistics-Theory and Methods, 50(4), 874–889.
[24] Zaman, T. and Kadilar, C. (2021b). Exponential ratio and product type estimators of the mean in stratified two-phase sampling. AIMS Mathematics, 6(5), 4265–4279.
[25] Zaman, T. (2019a). Improved estimators using coefficient of skewness of auxiliary attribute. Journal Of Reliability and Statistical Studies, 177–186.
[26] Zaman, T. (2019b). Efficient estimators of population mean using auxiliary attribute in stratified random sampling. Advances and Applications in Statistics, 56(2), 153–171.
[27] Zaman T. (2020). Generalized exponential estimators for the finite population mean. Statistics in Transition new series, 21(1), 159–168.
[28] Zaman, T. (2021). An efficient exponential estimator of the mean under stratified random sampling. Mathematical Population Studies, 28(2), 104–121.
Biographies

Shashi Bhushan received his Ph.D. degree in statistics from Lucknow University, Lucknow, India. He is currently working as a Professor in the Department of Statistics, Lucknow University, Lucknow, India. He has more than 15 years of teaching experience and 20 years of research experience. He has supervised six Ph.D till date. His research interests include Sample survey, missing data, non-response, measurement errors, etc. He has various publications in National and International journals of repute.

Anoop Kumar is pursuing his Ph.D. in Applied Statistics from the Department of Mathematics and Statistics, Dr. Shakuntala Misra National Rehabilitation University, Lucknow, India. He received his M.Sc. degree from Babasaheb Bhimrao Ambedkar University, Lucknow, India. He also qualified UGC NET twice in population studies. His research area is sampling survey, missing data, measurement errors. He has publications in various National and International journals of repute.

Dushyant Tyagi has done his M.Sc., M.Phil. and Ph.D. (Statistics) from Department of Statistics, Ch. Charan Singh University, Meerut and possess Eleven years of experience of educating in various institutions of repute like G. B. Pant University of Agriculture and Technology, Institute of Technology and Science Ghaziabad, International College of Financial Planning, New Delhi and Lady Shri Ram College for Women, New Delhi. He is currently working as an Assistant Professor at the Department of Mathematics and Statistics, Faculty of Science and Technology, Dr. Shakuntala Misra National Rehabilitation University, Lucknow. His research area is Statistical Quality Control and Computational Statistics. He held the responsibility of Convener and resource person for three AICTE sponsored Faculty Development Program on Advance Data Analysis through Data Analysis Software’s. He delivered lectures in more than 25 research methodology workshops. He has six research paper publication in reputed International journals and one book. He has presented his research work in various National and International Conferences and attended several seminars and FDP’s of statistics and related areas.

Saurabh Singh is currently pursuing Ph.D. in Applied Statistics from the Department of Mathematics and Statistics, Dr. Shakuntala Misra National Rehabilitation University, Lucknow, India. He received his M.Phil. degree from Babasaheb Bhimrao Ambedkar University, Lucknow, India. His research area is sampling survey, missing data. He has 10 publications in various National and International journals.
Journal of Reliability and Statistical Studies, Vol. 15, Issue 1 (2022), 187–210.
doi: 10.13052/jrss0974-8024.1518
© 2022 River Publishers