The Unit Folded Normal Distribution: A New Unit Probability Distribution with the Estimation Procedures, Quantile Regression Modeling and Educational Attainment Applications
Mustafa Ç. Korkmaz1, Christophe Chesneau2,* and Zehra Sedef Korkmaz3
1Department of Measurement and Evaluation, Artvin Çoruh University, City Campus, Artvin, 08000, Turkey
2LMNO, University of Caen Normandie, Caen, 14032, France
3Department of Curriculum and Instruction Program, Artvin Çoruh University, City Campus, Artvin, 08000, Turkey
E-mail: mustafacagataykorkmaz@gmail.com; christophe.chesneau@gmail.com; zehrasedefcoskun@gmail.com
*Corresponding Author
Received 09 September 2021; Accepted 04 April 2022; Publication 25 April 2022
Abstract
In this paper, we develop a continuous distribution on the unit interval characterized by the distribution of the absolute hyperbolic tangent transformation of a random variable following the normal distribution. The lack of research on the prospect of hyperbolic transformations providing flexible distributions on the unit interval is a motivation for the study. First, we study it theoretically and discuss its properties of interest from a modeling point of view. In particular, it is shown that the proposed distribution accommodates various levels of skewness and kurtosis. Then, some statistical work is performed. We investigate diverse estimation methods for the involved parameters and evaluate their performance through two simulation studies. Subsequently, the quantile regression model derived from the proposed distribution is developed. Two real-world data applications of interest are provided. The first application is about the univariate modeling of the percentage of the educational attainment of some countries, which is one indicator of the education topic of the Better Life Index (BLI) of the Organization for Economic Co-operation and Development (OECD) countries. The second application is to explain the relationship between the percentage of educational attainment of some countries with one indicator of the work-life balance, safety, and health topics of BLI via median quantile regression modeling. For the considered data sets, the proposed distribution and quantile regression models show that they have better modeling abilities than competitive models under some comparison criteria. The results also indicate that covariates are (statistically) significant at any ordinary level of significance for the median response.
Keywords: Better life index, educational attainment, hyperbolic tangent function, normal distribution, point estimates, OECD data sets, quantile regression, unit distribution.
1 Introduction
BLI has been proposed by the OECD to define the measure of well-being of different countries. It includes many metrics, such as social, economic, and environmental performance. By empowering citizens in the policy-making process, BLI aims to educate citizens on measuring the well-being of societies by empowering citizens in the policy-making process.
The BLIs of the countries consist of 11 topics such as income, jobs, housing, community, safety, education, environment, civil engagement, life satisfaction, health, and work-life balance. Each of the 11 variables of the index is currently based on one to three indicators. For example, the education variable consists of the educational attainment, student skills, and years of education indicators of the related countries. Further, the subject of these indicators has been used to relate to other indicators in the literature. In particular, the educational attainment indicator has been the subject of many studies.
According to the BLI variable of the OECD, educational attainment is specified as the highest score obtained at the most advanced level attended in the education system of the country where the education was received. The level of education takes into account the number of adults aged 25 to 64 with at least an upper secondary school diploma in the population of the same age. The unit of this measurement is given as the percentage of the adult population (aged 25 to 64) in the BLI. Adams [3] has found an education-health relationship in older people, even after taking into account individual and family characteristics, and he has examined to what extent this relationship represents an independent effect of education on health. Abel and Kruger [2] have examined the relationship between educational attainment and the suicide rate in the United States for the year 2001. Hill and Needham [22] have tested whether the self-rated health indicator improved over time (from 1972 to 2002) for women and men, and they also examined the extent to which historical gains in health were maintained. The educational attainment indicator helps explain any trends observed using ordered logistic regression. Gyekye and Salminen [20] have examined the relationship between educational attainment and perceptions of safety, job satisfaction, adherence to safety management policies, and the frequency of accidents via various statistical test procedures. Borgonovi and Pokropek [8] have examined the contribution of human capital to health in 23 countries around the world using the OECD Survey of Adult Skills, a unique large-scale international assessment of 1-65 year olds that contains information on self-reported health status, cognitive skills, education, and indicators of interpersonal confidence. This represents the cognitive dimension of social capital. Hazekamp et al. [21] have conducted a temporal trend analysis examining the educational attainment of male homicide victims aged 18 to 24 in the city of Chicago from 2006 to 2015 to describe the educational attainment of young victims of homicide in Chicago. Schellekens and Ziv [41] have tried to explain long-term trends in self-rated (reported) health with gender, age, race, and education covariates using regression analysis in the United States. Using the BLI topics, Altun [4] has given two applications via the regression approach. The first concerns the relationship between educational attainment values in OECD countries and indicators of the homicide rate and labor market insecurity. The other concerns the relationship between self-reported health status and indicators of water quality, air pollution, and homicide rate via regression modeling of the unit mean response. In general, these articles were motivated by the link between education level and other variables (indicators).
On the other hand, modeling real-world phenomena with probability models is very important for the statistical inference based on these phenomena. This issue has been studied by many statisticians and it continues to be studied. In particular, unit interval modeling approaches have increased recently as they are related to certain issues such as recovery and mortality rates, and the proportion of educational attainment, etc. based on the different world countries. When researchers want inferences about these important questions, the beta distribution comes to mind directly. Although the beta distribution has a probability density function (PDF) that is flexible in nature, it is sometimes not sufficient to model and explain all the informative characteristics of unit data sets. For this reason, in order to assess whether there are better results than the beta distribution based on statistical inference, new alternative models have been defined on the unit interval. Current literature on this topic includes [25], Topp-Leone [44], Kumaraswamy [30], generalized beta [36], standard two-sided power distribution [45], log-Lindley [18], log-xgamma [7], unit Birnbaum-Saunders [33], unit Lindley [31], unit inverse Gaussian [17], unit Gompertz [32], log-weighted exponential [4], degree unit Lindley [5], logit slash [26], unit generalized half normal [27], unit Johnson [19], unit Burr-XII [28] and trapezoidal beta [14] distributions. Many of the above distributions were obtained via transforming a parent distribution, and most of them gave better results than the beta distribution from a modeling point of view. In addition, for some of the distributions introduced above, alternative regression models have been derived. It is well-known that the beta regression has been proposed by [12], the Kumaraswamy quantile regression model has been introduced by [37], the unit-Lindley regression model has been studied by [31]. Also, Reference [4] proposed a regression model alternative to the beta regression model based on the weighted-exponential distribution. A flexible alternative regression model has been elaborated by [5] for the beta and simplex regression models. The unit-Weibull quantile regression (QR) model has been introduced by [35] as an alternative model to the beta and Kumaraswamy QR models. Last but not least, the log-extended exponential-geometric QR model developed by [24] also appears to be a serious competitor.
The objective of this study is to propose an original unit competitive distribution and its QR modeling to deal with percentages and proportions with their applications based on the proportion of the educational attainments’ OECD countries. We are also motivated to relate educational attainments’ OECD countries with covariates, which are some indicators of BLI topics such as work-life balance, safety, and health. To obtain a new ‘unit distribution’, we use a novel transformation of the normal distribution. This transformation is based on the absolute version of the hyperbolic tangent function. To our knowledge, this direction of research remains almost unexplored in the literature on unit distributions, despite the interest of hyperbolic functions in various branches of probability and statistical modeling (see [13]). “Almost” because, to our knowledge, in this framework, only the arcsecant normal distribution by [29] uses such an approach. Here, we motivate the fact that the considered transformation is able to carry the applicability of the normal distribution to the unit interval. It can be also noted that although a lot of distributions are proposed in order to analyze data on the unit interval, using the same models for every problem is not useful. In this sense, proposing new distributions is welcome and is applied.
The frame of the paper is as follows: The new distribution is described in Section 2. Some of its characteristics are specified by Section 3. Section 4 is dedicated to the estimation of the related model parameters, including simulation work. The new QR model based on the newly defined distribution, as well as its residual analysis, are explored in Section 5. Section 6 discusses univariate data modeling and QR modeling applications. Finally, the article ends with some comments in Section 7.
2 The ‘ distribution’
We start with a normal random variable (RV): , where denotes the mean of and its standard deviation. We define , where , . We denote the distribution of by the expression for ‘unif folded normal’ or where the mention of the two related parameters and has an interest. Consequently, because of the transformation considered, the distribution is a unit distribution. To our knowledge, it is new in the literature, and the underlying motivations are developed in several parts of the remainder of the study. As the first elements, the next result presents the related cumulative distribution function (CDF) and PDF, respectively.
Proposition 1.
First, for , the CDF of the distribution is determined as
| (1) |
where is the CDF of the standard normal () distribution and is the inverse function of . Also, for , the related PDF is
where is the PDF of the distribution. For , we complete the functions and as usual.
Proof.
Owing to the representation with , the CDF of can be developed as
The desired expression for is obtained. The expression of follows by differentiating according to , ending the proof. ∎
Based on Proposition 1, for , the following relations hold:
Also, another expression for the PDF is
| (3) |
where . When tends to , we get , which is a decreasing function with respect to . Also, from Equation (1), for , we notice that
This implies that the and distributions coincide. On another plan, the distribution can be unimodal, with a mode into . It can be determined by solving the following nonlinear equation according to :
The complexity of this equation is certain; a numerical treatment is required to determine the solution.
Among the important survival functions, the hazard rate function (HRF) of the distribution is expressed as
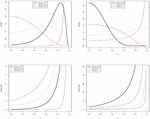
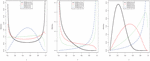
for . For , standard completions on are applied. When tends to , we have , which is a decreasing function with respect to . Figure 1 displays some curves of and for some chosen values of the parameters.
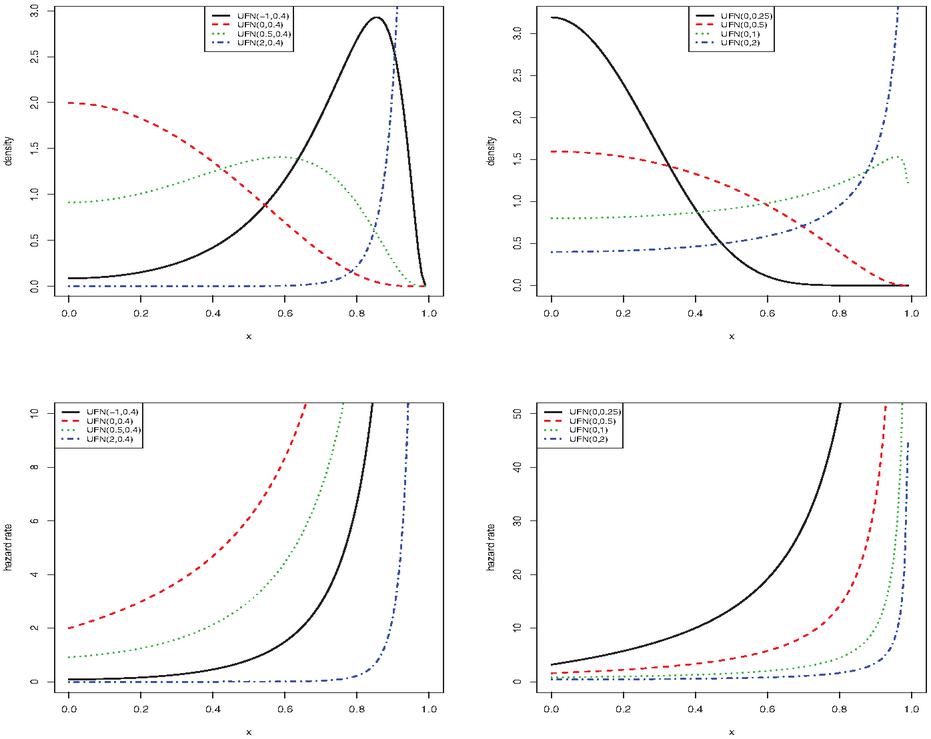
Figure 1 Samples of PDF and HRF shapes of the distribution.
Figure 1 shows that the distribution is very flexible; its PDF possesses a large panel of forms, including increasing, decreasing, bell-reversed bathtubs, and almost constant shapes. Also, we observe that the HRF is exclusively J shaped. This flexibility demonstrates that the distribution is able to model various phenomena with values in , and should be considered a serious option in this regard. Some of these modeling aspects are examined in the next parts of the study.
3 Notable Properties
The distribution is deeply related to the normal distribution, which makes it easier to study some of these important properties. Some of them are covered in this section.
3.1 Stochastic ordering
As a first approach, the distribution satisfies some stochastic ordering properties as described in full generality in [42]. As an immediate fact, the following stochastic dominance holds. For any , based on Equation (1), since the CDF is increasing, we have . We now discuss a monotone likelihood ratio property of the distribution. Let , , and be the ratio function defined by the respective PDFs, that is, by using Equation (3),
Then, we have
and
If we focus on the two main terms of this difference, one can notice that the function is decreasing with respect to , contrary to , implying that there is no immediate result on the sign of according to or . However, when tends to , the following equivalence holds:
and this last function is nonnegative for . This establishes the existence of a constant such that, if and , is nondecreasing, implying that the distribution satisfies the monotone likelihood ratio property in this setting; the higher the observed value, the more likely it is to come from rather than .
3.2 Generation of the Random Numbers
Generating values from the distribution is straightforward thanks to its mathematical structure. Indeed, since , where , it is enough to generate values from the classic distribution, say , then values from the distribution are given by , where for .
3.3 Quantile Function
The quantile function (QF) of a distribution completely identifies the distribution. It is the main ingredient of various probabilistic objects and statistical tools. The QF of the distribution is defined by the inverse of as presented in Equation (1). That is, it is the function such that for , or equivalently,
In the special case , the QF has the following closed form:
where is the inverse function of (corresponding to the QF of the distribution). From this expression, the quartiles of the distribution follow:
with , and . In addition, thanks to the QF, one can introduce various measures of asymmetry and kurtosis, such as those proposed in [16] and [38].
3.4 Moments
Since the distribution is unit-support, the moments of any order exist automatically. Since no closed form expression exists for them, a manageable series expansion is provided in the next proposition.
Proposition 2.
Firstly, let be a RV following the distribution. We define the truncated moment generating function of as , , and if is realized, and otherwise. Now, let be a positive integer and . Then, the -th moment of can be expressed as
Proof.
From the representation , where , we can write . Now, let us show that
| (5) |
The formula is straightforward for . For , the binomial formula yields
Also, for , by the same argument, we get
The desired formula follows by putting the two equalities together. Therefore, by Equation (3.4) and the dominated convergence theorem, we can write
Now, since , we have where , in the distribution sense. Therefore, we have
The desired result is obtained. ∎
The mean and variance of the distribution are given by and . Also, by using standard relations, we can determine the -th moment about the mean given as . The moments skewness and kurtosis coefficients of the distribution are given by and , respectively.
Three-dimensional plots of and are displayed in Figure 2 for wide ranges of values of the parameters.
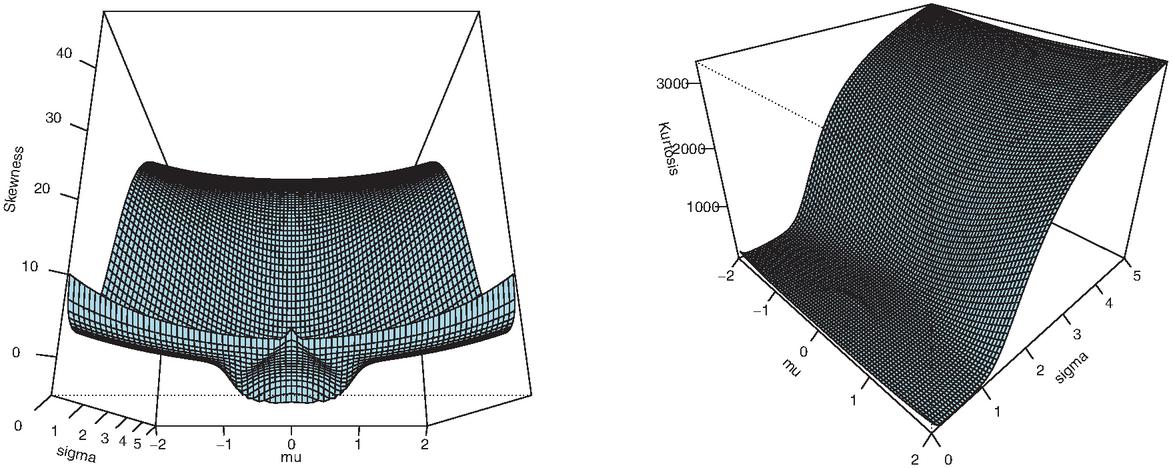
Figure 2 Three-dimensional plots of and for some ranges of parameter values.
From Figure 2, a great numerical versatility is observed for the considered skewness and kurtosis measures, depending on the values of and . This is another modeling benefit to the credit of the distribution.
The incomplete moments of the distribution can be expressed in a similar manner. The corresponding result is formulated in the new proposition.
Proposition 3.
Firstly, let be a RV following the distribution. Then, we define the double truncated moment generating function of as , and . Now, let be a positive integer and . Then, the -th incomplete moment of depending on can be expressed as
The proof of Proposition 3 is similar to the proof of Proposition 2, we thus omit it. When tends to , Proposition 3 becomes Proposition 2.
Taking yields the first incomplete moment, . It is especially useful for calculating the Bonferroni and Lorenz curves, moments of the standard and reversed residual life, and mean deviations for the distribution. All of them can be evaluated numerically.
3.5 Order Statistics
The minimal theory on the distributions of order statistics is described below. First, let be a -random sample from the distribution. Then, by placing them in ascending order, we define the order statistics denoted by . Then, for , the PDF of is specified by
| (6) |
where .
Explicitly, by using Equations (1) and (1), for , we get
For , we apply the standard completions on this function. In particular, by taking , for , the maximum RV has the following PDF:
Also, by taking , for , the minimum RV has the following PDF:
Order statistics are the main ingredients of useful estimation methods. Some of them will be described in the next estimation study.
4 Estimation Methods
Here, we present six different methods that are useful to estimate the parameters of the distribution. The methods are supported by simulation studies.
4.1 Maximum Likelihood Method
Here, the estimation of the parameters is examined via the well-established method of maximum likelihood (ML) method. Let be a -random sample from the distribution. The observed values are classically denoted by , referring to generic data, and the model parameter vector is specified as . Then, the log-likelihood function is given as
| (7) |
Following normal routine, the ML estimates (MLEs) and of and , respectively, can be derived by maximizing with respect to , also being the solutions of the following equations:
| (8) |
and
| (9) |
From Equation (4.1), we have
Based on Equations (4.1) and (4.1), the following equation is obtained:
| (11) |
Then, putting Equation (4.1) into Equation (4.1), the profile log-likelihood with respect to is specified as
It satisfies
Hence, we need to solve the following equation: ; numerical techniques are needed to get the . After obtaining the , the is determined by taking the square root of as defined in Equation (4.1) with .
For the interval estimations of the parameters and , the observed information matrix is required. Here, this matrix is defined by
Under mild conditions identified as ‘regularity conditions’, one can use the two-dimensional normal distribution with mean vector and covariance matrix for interval estimations. The formulas for the components of are available upon author request. Several alternative methods to the ML method have been proposed. Some of them are briefly presented below.
4.2 Some Other Estimation Methods
- Maximum product spacing (MPS) method
-
First, the MPS method was developed by [9] and [40]. It can be described as follows. Let be put in an ascending order. Let us set
with the conventions: and . The MPS estimates (MPSEs) and of and , respectively, are determined by maximizing with respect to .
- Least square (LS) method
-
The LS estimates (LSEs) and of the parameters and , respectively, are given by minimizing
with respect to .
- Weighted least square (WLS) method
-
In a similar way, the WLS estimates (WLSEs) and of the parameters and , respectively, are determined by minimizing
with respect to , where for .
- Anderson-Darling (AD) method
-
The AD estimates (ADEs) and of the parameters and , respectively, are got by minimizing
with respect to .
- Cramér-von Mises (CVM) method
-
The CVM estimates (CVMEs) and of the parameters and , respectively, are acquired by minimizing
with respect to .
4.3 Simulation Experiments
We now perform a simulation work based on -random samples to evaluate the performance of the estimates presented above with respect to varying . First, we generate samples of size with from the distribution. More precisely, we conducted two simulation studies where
• we take , and , for the first and second ones, respectively,
• the generated values are given by the formula , where the is the random number from the distribution.
The constrOptim routine available in the R program is employed. Further, we compute the average of the estimates (AEs), biases and mean square errors (MSE). Mathematically, for and , the AEs, biases and MSEs are calculated by
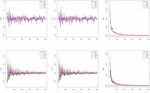
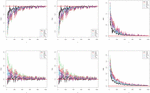
respectively, where the index refers to the -th sample. We anticipate that the AEs are close to true values, especially when the biases and MSEs are almost zero. Figures 3 and 4 display the results of these two simulation studies.
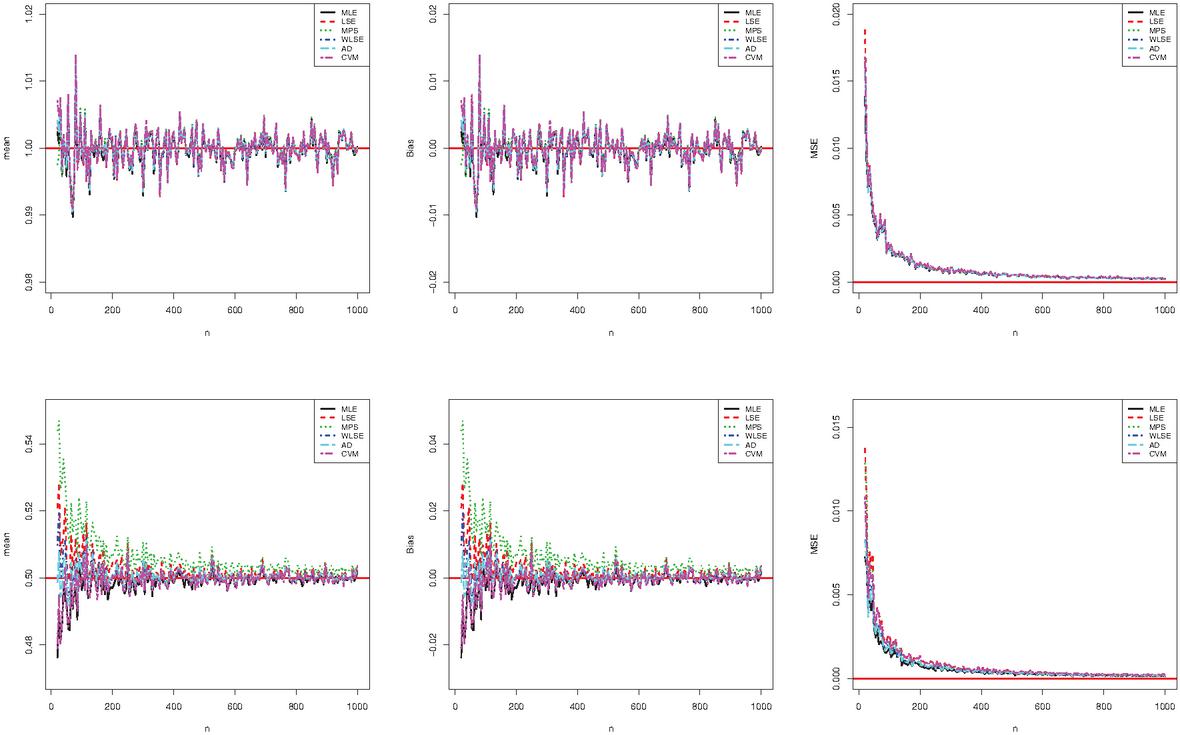
Figure 3 Graphical results of the (top) and (bottom) parameters for the first simulation study.
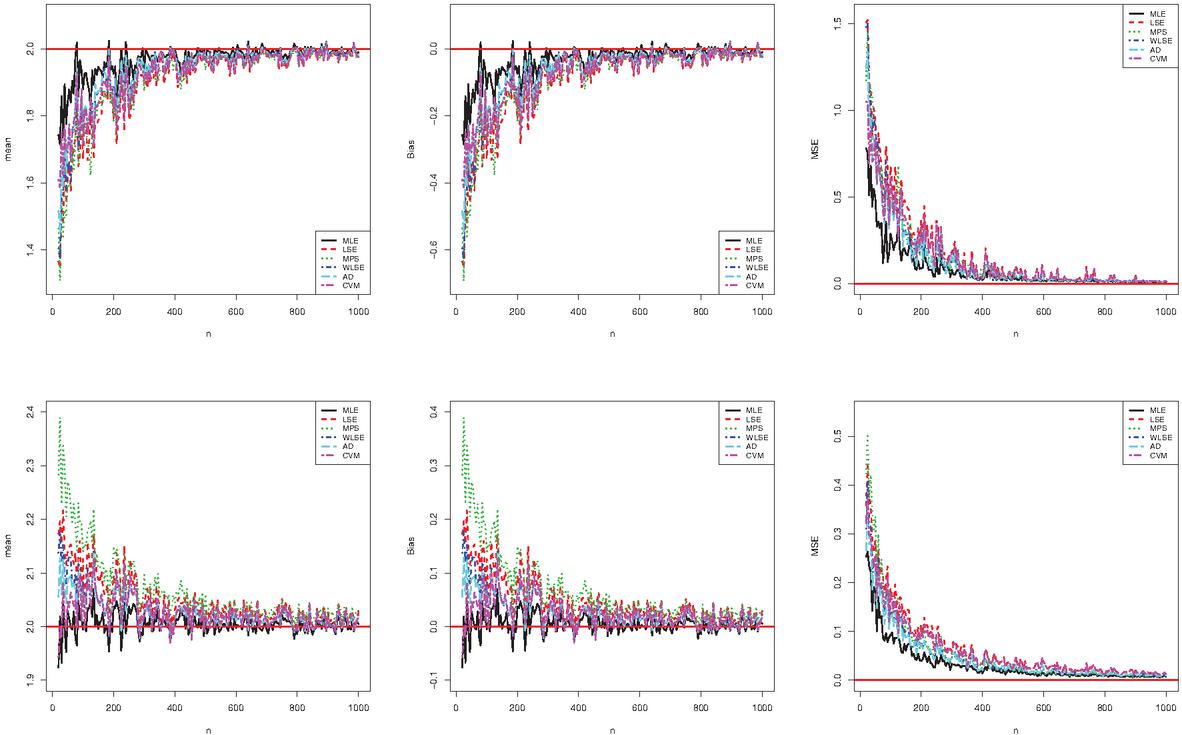
Figure 4 Graphical results of the (top) and (bottom) parameters for the second simulation study.
Figures 3 and 4 illustrate the consistency of the estimates. In particular, the biases and MSEs decrease to zero when increases, as expected. Also, their unbiasedness is observed. The amount of biases and MSEs on changing sample size is very close to the parameter , according to the first simulation study. In addition, the amount of the biases and MSEs of the MPS and LSE methods is the greatest initially for the parameter according to changes in the sample size. However, when the sample size increases, these amounts are close together. According to the second simulation study, when changing sample size, the amount of bias and MSEs introduced by the ML method is the smallest for both parameters. However, when the sample size increases, these amounts are close together. Generally, the performance of all estimates is close. Similar simulation results can also be obtained for arbitrary parameter settings.
5 The Derived Quantile Regression Model
5.1 Description
If the response variable support is set to a unit interval, the use of a unit regression model based on the unit distribution is suitable to model the conditional mean of the response variable via independent variables (covariates). In this regard, Reference [12] proposed the beta regression model. For accurate model inference, when the response variable has outliers in the measures, robust estimation results based on the regression model are required. For this aim, the QR model is a solid alternative model to the ordinary LSE and beta regression models. Whereas the method of least squares and beta regression models estimate the conditional mean of the response variable, the QR estimates the conditional median or other quantiles of the response variable.
With this approach, [37] and [35] have introduced the Kumaraswamy and unit Weibull QR models by re-parametrization of the Kumaraswamy and unit Weibull models, respectively.
Now, we introduce an alternative QR model based on a special distribution. In order to simplify the expression of the QF of the distribution, an exponentiated distribution version based on a special distribution is prefered. We call it as exponentiated () distribution. Its CDF and PDF are listed by
| (12) |
and
respectively, where and .
The QF of the distribution is obtained by
where . Then, the PDF of the distribution can be modified by putting . Thus, by setting , the PDF of the modified distribution is given by
| (13) |
where is the quantile parameter. In this context, is a tuning parameter which is assumed to be known. We denote the distribution associated to Equation (13) with . Samples of the shapes of are presented in Figure 5.
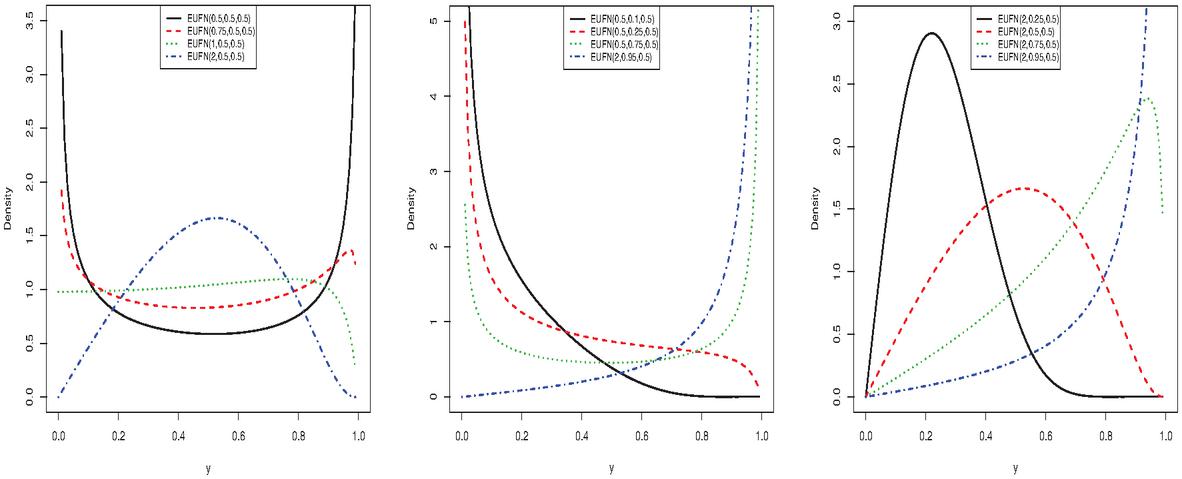
Figure 5 Samples of the PDF shapes of the modified distribution.
We see that the distribution has the skewed shapes as well as bathtub shaped, inverse N-shaped, decreasing, increasing and unimodal. The modelling of the conditional median follows by taking .
We now present the QR model based on the distribution with the PDF in Equation (13). In this regard, we consider observations from the re-parameterized distribution such that is a realization of , with unknown parameters and . Note that the parameter is known. The QR model is defined as
where and are the unknown regression parameter vector and -th vector known to covariates. Thus defined, is the link function which is used to relate the covariates at the conditional quantile of the response variable. For example, when , the covariates are related to the conditional median of the response variable. Since the distribution is set to the unit interval, we adopt the logit-link function such that
5.2 Parameter Estimation via the ML Method
Classically, the unknown parameters involved in the QR model are estimated by the ML method. Consider the link function below:
| (14) |
From Equation (14), it comes
| (15) |
Let be the unknown parameter vector. Then, inserting Equation (15) in Equation (13), the log-likelihood function of the QR model is
| (16) |
Since Equation (16) is composed of nonlinear functions according to the parameters of the model, this log-likelihood function can be maximized automatically by software such as R, Python, Matlab and Mathematica. We thus obtain the MLE denoted by . Here, we employ the maxLik function [23] of the R software to maximize Equation (16). This function also gives the components of the observed information matrix, including the standard errors (SEs). Recent advances in QR modelling with the ML method can be found in [24, 15, 31, 35] and [29].
5.3 Analysis of the Residuals for the Model Checking
Residual analysis may be necessary to verify if the regression model is appropriate. To see this, a residual analysis can be performed. Here, we indicate the randomized quantile and the Cox-Snell residuals.
- Randomized quantile residuals
-
The randomized quantile residuals have been introduced by [11]. The -th randomized quantile residual is determined as
for , where is the CDF of the modified distribution and is defined by Equation (15) with estimated by . If the fitted model successfully processes the data set, the underlying distribution of a randomized quantile residual corresponds to the distribution.
- Cox-Snell residuals
-
Alternatively, one can consider the Cox and Snell residuals developed by [10]. The -th Cox-Snell residual is given by
for . If the model fits to data suitably, the distribution of a Cox-Snell residual corresponds to the standard exponential distribution.
6 Data Analysis
In this section, two data applications have been given to see applicability of the proposed distribution model.
6.1 Description
We obtain all the data sets from OECD.Stat with the following uniform resource locator: https://stats.oecd.org/. It includes data and metadata for the OECD countries and selected non-member economies. The OECD.Stat consists of crucial themes such as Agriculture and Fisheries, Demography, Education and Training, Labour, Health, Social Protection, Finance, and Well-being, etc. Each theme is divided into various areas. Here, we consider the BLI of both OECD countries and some non-economy OECD countries in the Social Protection and Well-being theme. For the analysis of the two data, the educational attainment values are used as an indicator in the education theme of the BLI. The dataset used covers educational attainment values for OECD countries as well as for Brazil, Russia and South Africa. The percentage is the unit of measurement. The first application is about univariate modeling of educational attainment for the distribution. The second application is about the QR modeling for the distribution to relate educational attainment of the above countries with some indicators of topics of BLIs such as work-life balance, safety, and health. The reference year of the indicators is 2017. The data set can be directly found in https://stats.oecd.org/index.aspx?DataSetCode=BLI.
6.2 Univariate Data Modeling
Here, a real data set is analyzed to prove the empirical importance and modeling ability of the proposed model. This data set has been examined by [4] for another unit distribution, which is called the log-weighted exponential distribution. The author has obtained the estimated log-likelihood, denoted by , value of for his model.
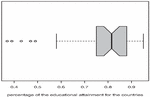
Figure 6 displays the boxplot of the data set.
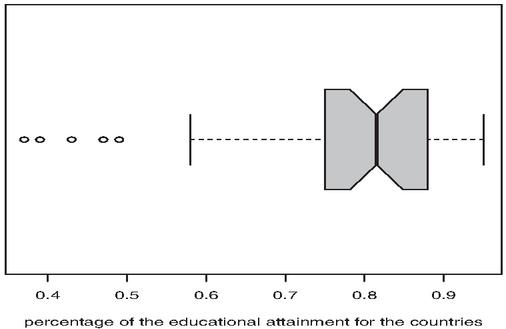
Figure 6 Boxplot of the considered data set.
From Figure 6, it appears that the data set is left skewed and it has some outliers.
We compare the performance of the real data fitting of the distribution through the ML method with the following well-established unit distributions:
• Beta distribution:
where , , , and is the beta function.
• Johnson distribution:
where , and . We note that the density is known as the PDF of the logit normal distribution.
• Exponentiated Topp Leone (ETL) distribution (see [39]:
where , and .
• Kumaraswamy (Kw) distribution:
where , and .
• Unit generalized half normal (UGHN) distribution (see [27]):
where , and .
The values, Akaike information criterion (AIC), Bayesian information criterion (BIC), Kolmogorov-Smirnov (), Cramér-von Mises () and Anderson-Darling () goodness of-fit statistics are obtained based on all distribution models to determine the optimum model. In general, one can choose as the optimal model the one indicating the smallest values of AIC, BIC, KS, and statistics, and the largest values of and p-value.
Firstly, we fit the folded normal () distribution, which has the following PDF: , , and , to this data set. For this model, we obtained the value and statistics as and 0.2309 (with p-value ), respectively. It is clear that the model is inadequate for explaining to this data set. We give the data analysis results belong to other competitor models in Table 1.
Table 1 MLEs, SEs (in parentheses), and goodness-of-fits statistics (the p-values of the KS test are given in )
| Model | ||||||||
| UFN | 1.1302 | 0.3678 | 26.8429 | 49.6858 | 46.4106 | 0.4850 | 0.0736 | 0.1195 |
| (0.0597) | (0.0424) | [0.6502] | ||||||
| UGHN | 0.9558 | 0.3698 | 20.2884 | 36.5769 | 33.3018 | 1.8384 | 0.3276 | 0.2097 |
| (0.1208) | (0.0498) | [0.0706] | ||||||
| Beta | 5.9874 | 1.8157 | 23.8684 | 43.7369 | 40.4616 | 1.2732 | 0.2233 | 0.1826 |
| (1.7258) | (0.4566) | [0.1588] | ||||||
| Kw | 5.4450 | 2.0847 | 24.3538 | 44.7076 | 41.4324 | 1.2057 | 0.2057 | 0.1740 |
| (1.0292) | 0.5383 | [0.2001] | ||||||
| ETL | 8.5134 | 0.6642 | 22.0160 | 40.0320 | 36.7568 | 1.8182 | 0.3524 | 0.2198 |
| (2.0971) | (0.1354) | [0.0508] | ||||||
| Johnson | 1.6045 | 1.1403 | 26.2280 | 48.4560 | 45.1809 | 0.7540 | 0.1229 | 0.1472 |
| (0.2455) | (0.1308) | [0.3828] |
Table 1 reveals that the distribution has the lowest values of AIC and BIC statistics. Also, the distribution has the lowest values of the and and KS statistics with higher p-value. Hence, the distribution is the best choice for the modeling.
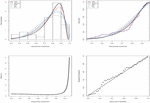
Figure 7 shows some important estimated functions of the distribution to graphically prove the fit of the model.
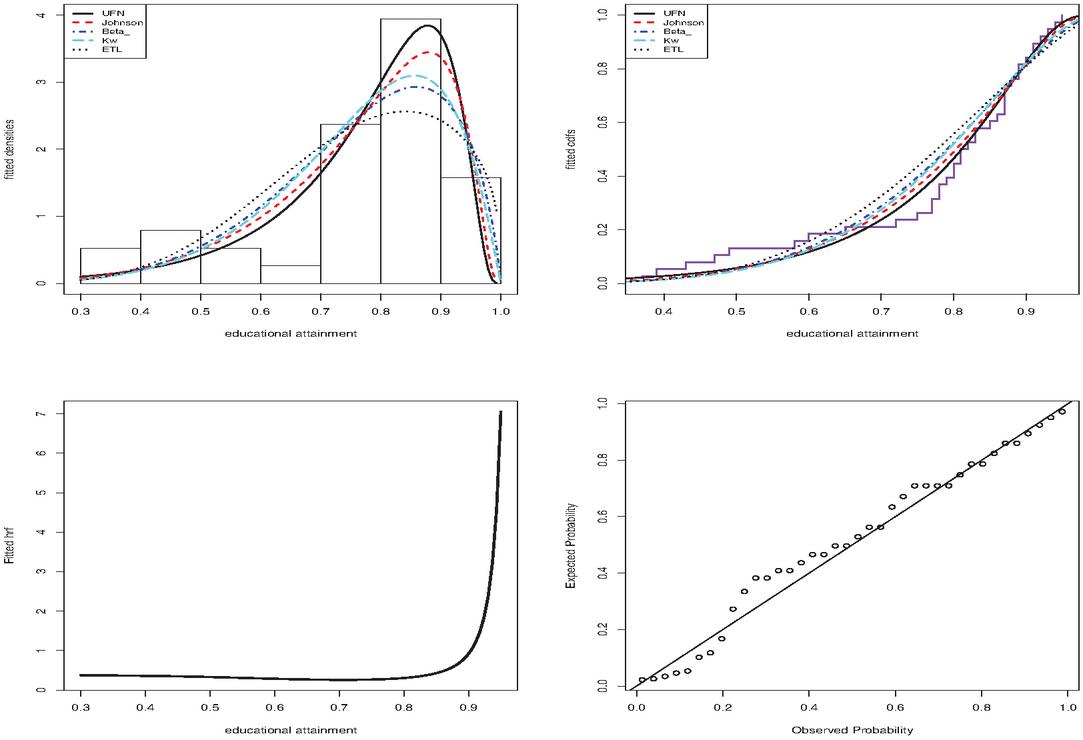
Figure 7 Some fitted functions for the used data.
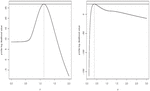
Clearly, the proposed model has successfully captured the skewness and kurtosis of the data set. The plotted lines of the probability-probability (PP) plot is very closer the diagonal line which indicates that the performance of the distribution is acceptable for the modeled data. In order to show that the likelihood equations have a unique solution, we display the profile log-likelihood (PLL) functions of the parameters and for the data set in Figure 8.
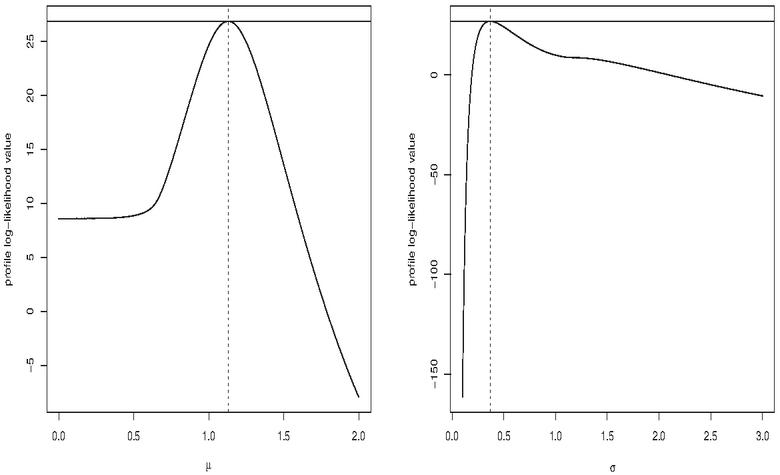
Figure 8 Plots of the PLL functions for the considered data set.
The maxima of the curves indicate that the likelihood equations have unique solutions for the MLEs.
6.3 QR Modeling for the Educational Attainment Data Set
In this section, a real application is provided in order to highlight the applicability of the newly defined QR model. Two important competitor regression models are considered. They are beta regression [12] model as well as Kumaraswamy QR [37] model. Their PDFs are
where is the mean and and
where is the median and for the beta regression and Kumaraswamy QR, respectively.
Here, we want to relate the level of education of the countries with the variables of some BLIs such as work-life balance, safety, and health. In this context, the aim of this application is to linearly explain the educational attainment values with the percentage of the employees working very long hours , homicide rate , and self-reported health covariates. The values of these indicators belong to the OECD countries as well as Brazil, Russia, and South Africa. Specifically, is the proportion of dependent employees whose usual working hours per week are 50 hours or more, is the ratio of deaths due to assault as a standardized rate according to age per 100,000 population, and is the percentage of the population aged 15 and over who report good or better health. One may see the data set and detailed information about all covariates via the link which has been given in Section 6. The following linear regression equation is used for all the regression models:
where the is the mean for the beta model whereas it denotes the median for the Kumaraswamy and models.
From Figure 6, we see that the data are skewed and have some outliers. For these reasons, relating the unit response variable with covariates via the median QR will be more useful for the inferences, since the mean is perturbed by skewed data with the outliers precisely. Thus, it can be obtained as a more illustrative and more robust inference than the mean response regression.
We use the betareg function of the R software for the results of the beta regression model. The maxLik function [23] of the R software has been used for the results of the , Kumaraswamy, and unit-Weibull QR models. The details are given as follows.
Firstly, we assume that for the three QR models for the median modeling. The obtained results are contained in Table 2.
Table 2 Results of the fitted regression models with the considered model selection criteria
| Parameters | Beta | Kumaraswamy | EUFN | ||||||
| Estimate | SE | p-value | Estimate | SE | p-value | Estimate | SE | p-value | |
| 2.5107 | 0.5606 | 2.7648 | 0.4293 | 2.9713 | 0.6000 | ||||
| 4.1441 | 1.2998 | 4.8408 | 1.1903 | 5.5763 | 1.4511 | ||||
| 0.0512 | 0.0176 | 0.0642 | 0.0105 | 0.0578 | 0.0173 | ||||
| 1.0869 | 0.7605 | 1.1092 | 0.5034 | 1.3746 | 0.7799 | ||||
| 12.2220 | 2.7550 | 6.8593 | 1.1576 | 6.6951 | 1.7689 | ||||
| 31.8600 | 31.8542 | 32.5631 | |||||||
| AIC | 53.7200 | 53.7083 | 55.1263 | ||||||
| BIC | 45.5321 | 45.5204 | 46.9384 | ||||||
From this table, the parameters and are seen as significant at any usual level, as well as the parameter is seen to be significant at an 8% level for the regression model. For the Kumaraswamy regression model, all parameters are significant at any usual level.
According to our regression model, the unit median response variable is negatively affected by all the covariates. Hence, it can be concluded that in the related countries, when the percentage of employees working very long hours, the homicide rate, and the percentage of the population who report their health as good or better increase, the percentage of educational attainment decreases. The result of self-reported health according to educational attainment turns out out to be surprisingly surprising. It is obvious that all covariates affect educational attainment negatively. Moreover, in view of the AIC and BIC values, it can be concluded that the proposed regression model is the best.
To complete this work, the Quantile-Quantile (QQ) plots of the randomized quantile residuals and the PP plots of the Cox-Snell residuals for all the models are displayed in Figures 9 and 10, respectively.
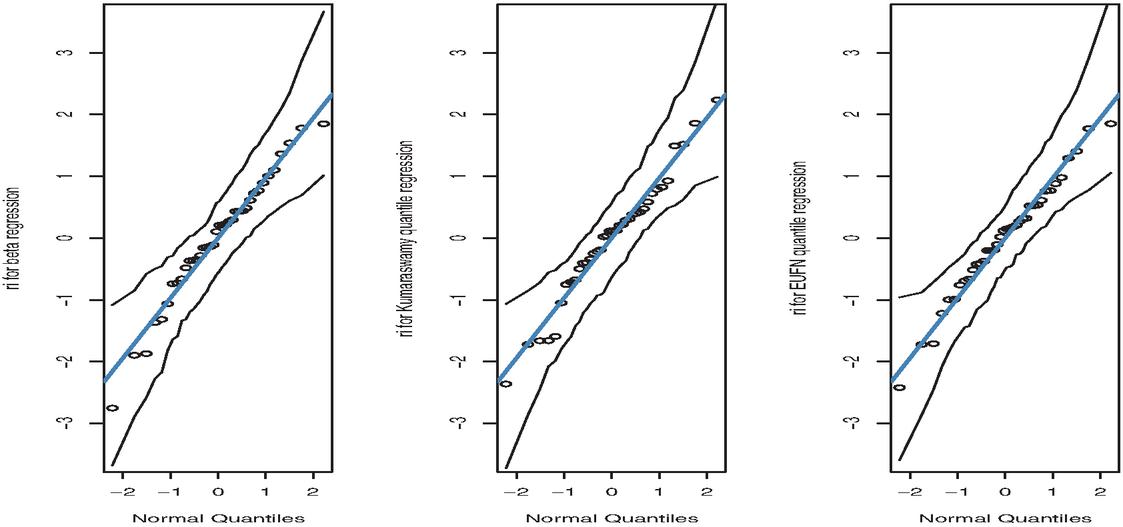
Figure 9 QQ plots of the randomized quantile residuals for the regression models.
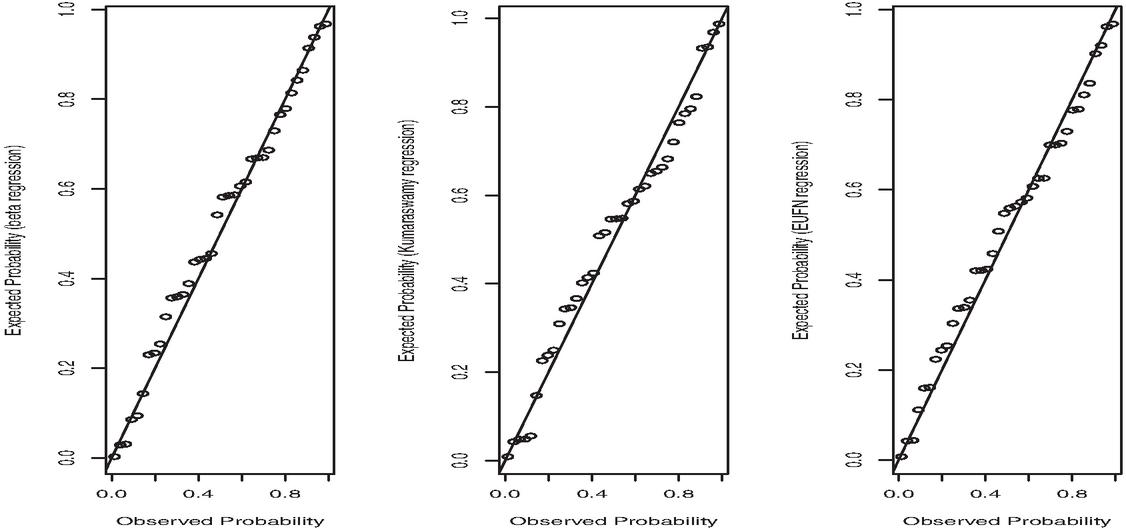
Figure 10 PP plots of the Cox-Snell residuals for the regression models.
The plots of the regression model are close to the diagonal line, as shown in Figures 9 and 10. Hence, the randomized quantile and Cox-Snell residuals based regression model have the and exponential distributions, respectively. Finally, we can say that the data set is modeled by the regression model more successfully than the other models.
7 Conclusion
We motivate and study a new unit distribution, called the unit folded normal () distribution, to model the proportion of educational attainment and other data sets defined over the unit interval. We study the characteristics and properties of the new distribution. Six methods are used to estimate the model parameters. Two simulation studies were conducted to illustrate the performance of these estimates. The percentage of educational attainment data set of both OECD countries and some non-economy OECD countries is considered to point out the applicability of the distribution. The findings, which are about the modeling of educational attainment, show that the proposed model provides better fits than referenced unit models. According to its regression modeling, it also aimed to relate the educational attainment in the countries with their employees working very long hours, homicide rate, and self-reported health via median QR modeling. The results indicate important findings on how these covariates affect the unit response variable titled ”Country Educational Attainment.”
Most surprising is the finding that, according to the estimated regression coefficients, there is an inverse relationship between education level and self-reported health status, statistically significant at an 8% significance level. That is, the percentages of educational attainment in countries are influenced negatively by those of self-reported health.Hence, the result of self-reported health according to educational attainment turns out surprisingly. Based on the dataset from 69 countries, [43] have shown that adults with lower levels of education are consistently more likely to self-report poor health than those with higher levels of education.
In addition, at any usual significance level, when a country’ percentage of employees working very long hours and rate of homicide increase, the country’ percentage of educational attainment decreases, as expected. The references [4] and [6] have concluded that homicide rate effects the educational attainment negatively.
In summary, the following findings have been obtained by this paper.
i. A new distribution and its quantile regression model for the modeling of measurements of proportions and percentages have been introduced.
ii. The percentages of educational attainment in the countries of the OECD and some other countries have been modeled by a proposed new probability distribution as well as related to covariates, which are some indicators of BLI topics such as work-life balance, safety, and health. It has been concluded that in related countries, when the percentage of employees working very long hours, the homicide rate, and the percentage of the population who report their health as good or better increase, the percentage of educational attainment decreases. All covariates have been considered significant at the 8% level for the unit median response.
iii. The results for the unit median response modeling of the data have shown that the proposed model has ensured better results than the well-known beta and Kumaraswamy regression models under some comparison criteria.
The distribution is expected to gain attention both in education and in many other disciplines in demand for unit models.
Data Availability Statement
The corresponding author can provide the data sets utilized in this work upon reasonable request.
Conflict of Interest
The authors declare no conflict of interest.
References
[1] Aarset, M. V. (1987). How to identify a bathtub hazard rate. IEEE Transactions on Reliability, 36(1), 106–108.
[2] Abel, E. L. andKruger, M. L. (2005). Educational attainment and suicide rates in the United States. Psychological Reports, 97(1), 25–28.
[3] Adams, S. J. (2002). Educational attainment and health: Evidence from a sample of older adults. Education Economics, 10(1), 97–109.
[4] Altun, E. (2020). The log-weighted exponential regression model: alternative to the beta regression model, Communications in Statistics-Theory and Methods, DOI: 10.1080/03610926.2019.1664586.
[5] Altun, E. and Cordeiro, G. M. (2020). The unit-improved second-degree Lindley distribution: inference and regression modeling. Computational Statistics, 35(1), 259–279.
[6] Altun, E., El-Morshedy, M. and Eliwa, M. S. (2021). A new regression model for bounded response variable: An alternative to the beta and unit–Lindley regression models. Plos one, 16(1), e0245627.
[7] Altun, E. and Hamedani, G. G. (2018). The log-xgamma distribution with inference and application. Journal de la Société Française de Statistique, 159(3), 40–55.
[8] Borgonovi, F. and Pokropek, A. (2016). Education and self-reported health: Evidence from 23 countries on the role of years of schooling, cognitive skills and social capital. PloS one, 11(2), e0149716.
[9] Cheng, R. C. H. and Amin, N. A. K. (1979). Maximum product of spacings estimation with application to the lognormal distribution. Math Report, 791.
[10] Cox, D. R. and Snell, E. J. (1968). A general definition of residuals. Journal of the Royal Statistical Society: Series B (Methodological), 30(2), 248–265.
[11] Dunn, P. K. and Smyth, G. K. (1996). Randomized quantile residuals. Journal of Computational and Graphical Statistics, 5(3), 236–244.
[12] Ferrari, S. and Cribari-Neto, F. (2004). Beta regression for modelling rates and proportions. Journal of applied statistics, 31(7), 799–815.
[13] Fischer, M. J. (2013). Generalized Hyperbolic Secant Distributions: With Applications to Finance, Springer Science & Business Media, Springer.
[14] Figueroa-Zu, J. I., Niklitschek-Soto, S. A., Leiva, V. and Liu, S. (2020). Modeling heavy-tailed bounded data by the trapezoidal beta distribution with applications. Revstat, to appear.
[15] Gallardo, D.I., Gómez-Déniz, E. and Gómez, H.W. (2020). Discrete generalized half-normal distribution and its applications in quantile regression. SORT-Statistics and Operations Research Transactions, 265–284.
[16] Galton, F. (1883). Inquiries into human faculty and its development. Macmillan and Company, London, Macmillan.
[17] Ghitany, M. E., Mazucheli, J., Menezes, A. F. B. and Alqallaf, F. (2019). The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Communications in Statistics-Theory and Methods, 48(14), 3423–3438.
[18] Gómez-Déniz, E., Sordo, M. A. and Calderín-Ojeda, E. (2014). The log–Lindley distribution as an alternative to the beta regression model with applications in insurance. Insurance: Mathematics and Economics, 54, 49–57.
[19] Gündüz, S. and Korkmaz, M. Ç. (2020). A New Unit Distribution Based On The Unbounded Johnson Distribution Rule: The Unit Johnson SU Distribution. Pakistan Journal of Statistics and Operation Research, 16(3), 471–490.
[20] Gyekye, S. A. and Salminen, S. (2009). Educational status and organizational safety climate: Does educational attainment influence workers’ perceptions of workplace safety?. Safety science, 47(1), 20–28.
[21] Hazekamp, C., McLone, S., Yousuf, S., Mason, M. and Sheehan, K. (2018). Educational attainment of male homicide victims aged 18 to 24 years in Chicago: 2006 to 2015. Journal of interpersonal violence, DOI: 10.1177/0886260518807216.
[22] Hill, T. D. and Needham, B. L. (2006). Gender-specific trends in educational attainment and self-rated health, 1972–2002. American journal of public health, 96(7), 1288–1292.
[23] Henningsen, A. and Toomet, O. (2011). maxLik: A package for maximum likelihood estimation in R. Computational Statistics, 26(3), 443–458.
[24] Jodra, P. and Jiménez-Gamero, M. D. (2020). A quantile regression model for bounded responses based on the exponential-geometric distribution. REVSTAT-Statistical Journal, 18(4), 415–436.
[25] Johnson, N. L. (1949). Systems of frequency curves generated by methods of translation. Biometrika, 36(1/2), 149–176.
[26] Korkmaz, M. Ç. (2020a). A new heavy-tailed distribution defined on the bounded interval: the logit slash distribution and its application. Journal of Applied Statistics, 47(12), 2097–2119.
[27] Korkmaz, M. Ç. (2020b). The unit generalized half normal distribution: A new bounded distribution with inference and application. University Politehnica of Bucharest Scientific Bulletin-Series A-Applied Mathematics and Physics, 82(2), 133–140.
[28] Korkmaz, M.Ç. and Chesneau, C. (2021). On the unit Burr-XII distribution with the quantile regression modeling and applications, Computational and Applied Mathematics, 40, Article number: 29, 1–26.
[29] Korkmaz, M. Ç., Chesneau, C. and Korkmaz, Z. S. (2021). On the arcsecant hyperbolic normal distribution. Properties, quantile regression modeling and applications, Symmetry, 13(1), 117, 1–24.
[30] Kumaraswamy, P. (1980). A generalized probability density function for double-bounded random processes. Journal of Hydrology, 46(1–2), 79–88.
[31] Mazucheli, J., Menezes, A. F. B. and Chakraborty, S. (2019a). On the one parameter unit-Lindley distribution and its associated regression model for proportion data. Journal of Applied Statistics, 46(4), 700–714.
[32] Mazucheli, J., Menezes, A. F. and Dey, S. (2019b). Unit-Gompertz distribution with applications. Statistica, 79(1), 25–43.
[33] Mazucheli, J., Menezes, A. F. and Dey, S. (2018). The unit-Birnbaum-Saunders distribution with applications. Chilean Journal of Statistics, 9(1), 47–57.
[34] Mazucheli, J., Menezes, A. F. B. and Ghitany, M. E. (2018). The unit-Weibull distribution and associated inference. J. Appl. Probability Stat, 13, 1–22.
[35] Mazucheli, J., Menezes, A. F. B., Fernandes, L. B., de Oliveira, R. P., and Ghitany, M. E. (2020). The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. Journal of Applied Statistics, 47(6), 954–974.
[36] McDonald, J. B. (1984). Some generalized functions for the size distribution of income. Econometrica, 52, 647–663.
[37] Mitnik, P. A. and Baek, S. (2013). The Kumaraswamy distribution: median-dispersion re-parameterizations for regression modeling and simulation-based estimation. Statistical Papers, 54(1), 177–192.
[38] Moors, J. J. A. (1988). A quantile alternative for Kurtosis, J. Roy. Statist. Soc. Ser. D, 37, 25–32.
[39] Pourdarvish, A., Mirmostafaee, S. M. T. K. and Naderi, K. (2015). The exponentiated Topp-Leone distribution: Properties and application. Journal of Applied Environmental and Biological Sciences, 5(7), 251–256.
[40] Ranneby, B. (1984). The maximum spacing method. An estimation method related to the maximum likelihood method. Scandinavian Journal of Statistics, 93–112.
[41] Schellekens, J.and Ziv, A. (2020). The role of education in explaining trends in self-rated health in the United States, 1972-2018. Demographic Research, 42, 383–398.
[42] Shaked, M. and Shanthikumar, J.G. (2007). Stochastic Orders, Wiley, New York, NY, USA.
[43] Subramanian, S. V., Huijts, T. and Avendano, M. (2010). Self-reported health assessments in the 2002 World Health Survey: how do they correlate with education?. Bulletin of the World Health Organization, 88, 131–138.
[44] Topp, C. W. and Leone, F. C. (1955). A family of J-shaped frequency functions. Journal of the American Statistical Association, 50(269), 209–219.
[45] van Dorp, J. R. and Kotz, S. (2002). The standard two-sided power distribution and its properties: with applications in financial engineering. The American Statistician, 56(2), 90–99.
Biographies

Mustafa Ç. Korkmaz is an Associate Professor in Statistics at Department of Measurement and Evaluation, Education Faculty, Artvin Çoruh University, Artvin, TURKEY. He received his bachelor’s (2008) and master’s (2010) degrees in Statistics from the Selçuk University, TURKEY. He has also received the PhD degree in Statistics from Çukurova University, Adana, TURKEY. His main research interest in the field of two-sided generalized distributions, generalized distribution theory, compound distributions, statistical analysis, regression modeling and quantile regression modeling. He has more than 75 publications in his credit.

Christophe Chesneau received the Ph.D. degree in Applied Mathematics from the University of Paris VI in 2006. He has been an Assistant Professor in the Department of Mathematics (LMNO) at the University of Caen-Normandie since 2007. His research activities are focused on applied mathematics, statistics, and probability with applications. Dr. Chesneau has more than 300 international publications to his credit.

Zehra Sedef Korkmaz is an Assistance Professor in Curriculum Instructions at Department of Educational Sciences, Education Faculty, Artvin Çoruh University, Artvin, TURKEY. She received her bachelor’s (2009), master’s (2012), and PhD (2018) degrees from the Ataturk University, TURKEY. Her main research interest in the field of teacher education, educational statistics, instroctional design, professional development, and statistical analysis.
Journal of Reliability and Statistical Studies, Vol. 15, Issue 1 (2022), 261–298.
doi: 10.13052/jrss0974-8024.15111
© 2022 River Publishers