GDUS-Modified Topp-Leone Distribution: A New Distribution with Increasing, Decreasing, and Bathtub Hazard Functions
Arun Kaushik and Unnati Nigam*
Department of Statistics, Banaras Hindu University, Varanasi, India
E-mail: unnatinigam2307@gmail.com
*Corresponding Author
Received 14 January 2022; Accepted 12 April 2022; Publication 29 April 2022
Abstract
In this paper, we propose an extension to the Topp-Leone distribution, as introduced by [20] using the Generalized-DUS transformation given by [8]. The Topp-Leone distribution is defined on interval (0,1) and has a characteristic J-shaped frequency curve. The newly extended version of Topp-Leone distribution accommodates a variety of shapes of hazard rate functions making it a versatile distribution. We have also derived explicit expressions for some properties like ordinary moments, conditional moments, distribution of order statistics, quantiles, mean deviation, and entropy. Further, we have also discussed results on identifiability, stress-strength reliability, and stochastic ordering that are concerned with two independent random variables. For inference regarding the unknown parameters of the distribution, we derive the equations which give their maximum likelihood estimators. We also present the asymptotic confidence intervals of the unknown parameters of the distribution, based on large sample property, using the Fisher information matrix. To facilitate further studies, a step-by-step algorithm is presented to produce a random sample from the distribution. Further, extensive simulation experiments are done to study the long-term behavior of the maximum likelihood estimators of the parameters through their mean squared error and mean absolute bias on the basis of large number of samples. The consistency of the MLEs is empirically proved. Lastly, the application of the proposed distribution is shown by fitting a real-life dataset over some existing distributions in the same range.
Keywords: Probability distribution, identifiability, stochastic ordering, entropy, stress-strength reliability, simulation study, real data fitting..
1 Introduction
With the increasing usage of statistics in diverse fields like medicine, engineering, social sciences, etc., various lifetime probability distributions and their extensions are introduced to ensure proper modeling of data. Such distributions are used to study and characterize various datasets. In recent years, various such distributions have been introduced from time to time with different ranges, like positive real line (), bounded range, () or unit range (0,1), etc. The distributions defined on the unit range are particularly used to model proportions data. A few of the most commonly used distributions to model proportions data are Beta, Johnson (see [5]), and Kumaraswamy distributions (see [6]). With the increasing demand for modeling proportions data, various lifetime distributions have been transformed to unitintervals. Some of these are, unit-Gamma or Log-Gamma (see [3]) by Gamma, unit-Weibull (see [10]) by Weibull, log-Lindley (see [4]) by Lindley, unit Gompertz (see [11]) by Gompertz, unit Birnbaum-Saunders (see [9]) by Birnbaum-Saunders, unit Burr-XII (see [7]) by Burr-XII distributions and Transmuted power function distribution (see [21, 22]) by a quadratic transmutation map, etc.
One of the extensively used distributions to model unit range data (i.e., defined on (0,1)) is the Topp-Leone distribution (given by [20]). It is a mixture of uniform and generalized triangular distributions and has a J-shaped frequency curve. [12] derived the closed-form expressions for this distribution. This distribution has also been welcoming to generate new families of distributions by using various transformations and modifications. These new families are very flexible in nature and can accommodate a variety of shapes of density and hazard functions. The Topp-Leone normal distribution (given by [17]) presented its possible application to three datasets. The Generalized Topp-Leone distribution (given by [19]) used a skewness parameter for the extension and showed the application on tissue damage proportions data. The Topp-Leone generalized distribution was proposed by [15], using the beta generated (BG) family of distributions. A special case of such a distribution is the Topp-Leone generalized exponential distribution. The Topp-Leone odd log-logistic distribution was proposed by [1] along with its usage on a regression model.
An important transformation, called as the DUS transformation (see [24]), was introduced to propose new distributions using a baseline distribution. It increased the flexibility in modelling of various datasets. On the basis of this transformation, various new distributions, like DUS-Kumarswamy distribution (see [23]) has been proposed.
In this paper, we propose an extension to the Topp-Leone distribution using the Generalized DUS transformation given by [8]. We use the Topp-Leone distribution as a baseline distribution due to its flexibility to capture hazard functions of variety of shapes. The probability density function and the cumulative density function are defined as,
| (1) |
and,
| (2) |
where is the transformation parameter, f(x) and F(x) denote the pdf and the cdf of the distribution respectively.
The baseline distribution for the given transformation is taken to be Topp-Leone distribution with single parameter having cdf ; and corresponding pdf as ; . Using the transformation introduced in Equations (1) and (2), the cdf and the pdf of the newly proposed distribution, which will now be referred as GDUS-Modified Topp-Leone (GMTL) Distribution is as follows:
| (3) | |
| (4) |
The newly proposed GDUS-Modified Topp-Leone (GMTL) distribution is very flexible as it can accommodate variety of shapes of hazard rates (see Figure 2), densities (see Figure 1) and survival functions (see Figure 2). We use GMTL to denote the distribution whose cdf and pdf are given by Equations (3) and (4), where and are the parameters. In this article, we present some attractive statistical properties of the proposed GMTL distribution and present its effective use for modeling proportion data of recovery rates of CD34 cells after peripheral blood stem cell (PBSC) transplants over some existing distributions defined on unit interval.
The shapes of density, distribution, reliability and hazard functions are visualised in Section 2. The Statistical Properties of the distribution are derived in Section 3. This include ordinary moments, conditional moments, quantile function, order statistics, mean deviation about mean and median, entropy, stress-strength reliability, identifiability, stochastic ordering and differential equations. We present the maximum likelihood estimators (MLEs) along with the asymptotic confidence intervals of the unknown parameters and in Section 4. An extensive set of simulation experimentsare carried out to study the behavior of mean squared error and mean absolute bias of the MLEs for different sample sizes in order to check their consistency. In Section 5, the proposed distribution is used to model a real dataset of recovery rates of CD34 cells over the existing unit-interval distributions like Beta, Kumaraswamy, unit-Gamma and unit-Weibull distributions. The findings of the paper are concluded in Section 6.
2 Shapes of the Distribution
Figure 1 visualises the probability density and cumulative distribution function plots for different values of parameters as per Equations (3) and (4). It is clear that the proposed distribution can accommodate variety of shapes of densities as shown in Figure 1. The associated reliability function is,
| (5) |
The associated hazard rate is,
| (6) |
Figure 2 visualises the reliability and hazard rate functions for different values of the parameter. The hazard rate of the proposed distribution accomodates variety of shapes, as shown in Figure 2.
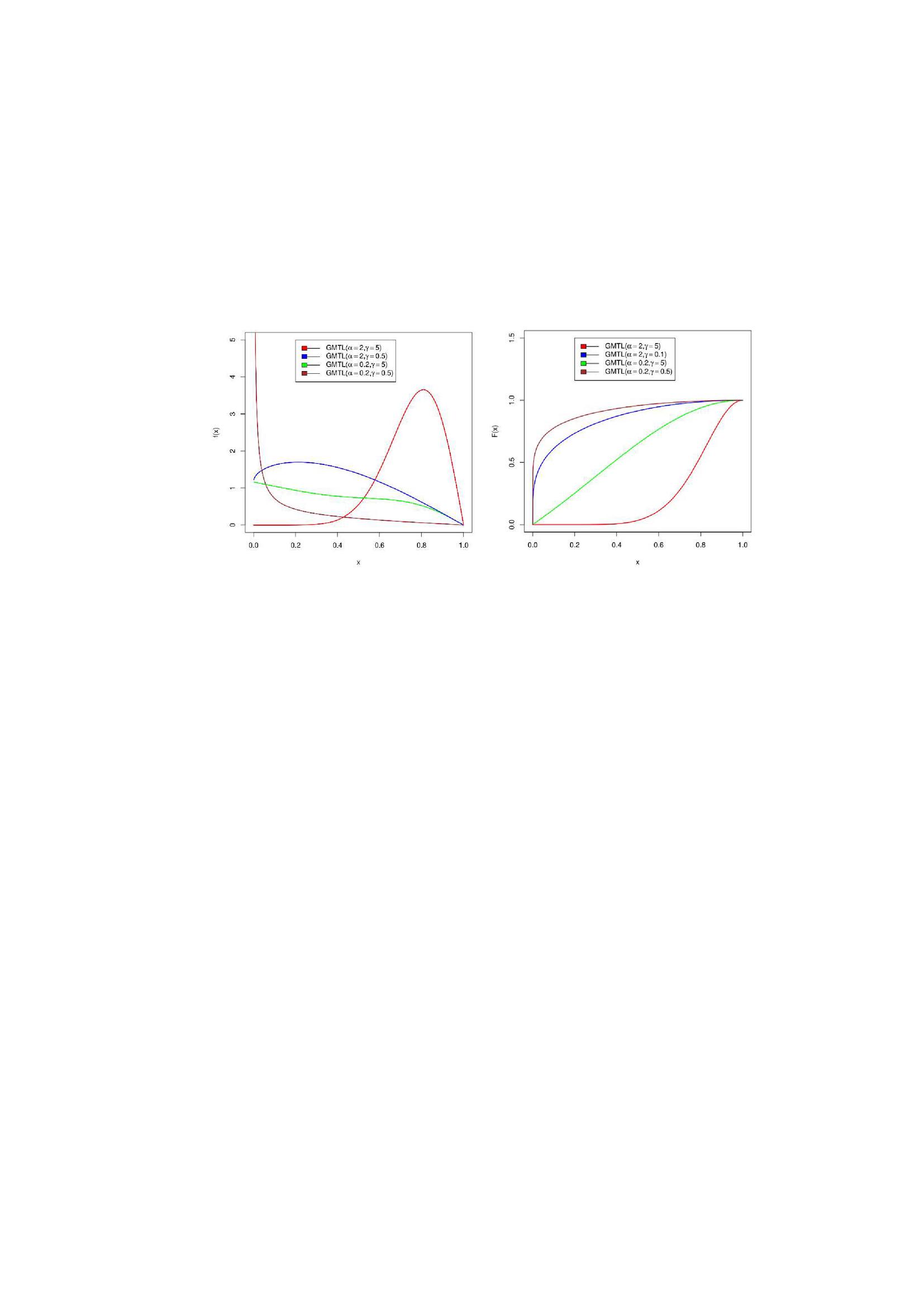
Figure 1 PDFs and CDFs of GMTL().
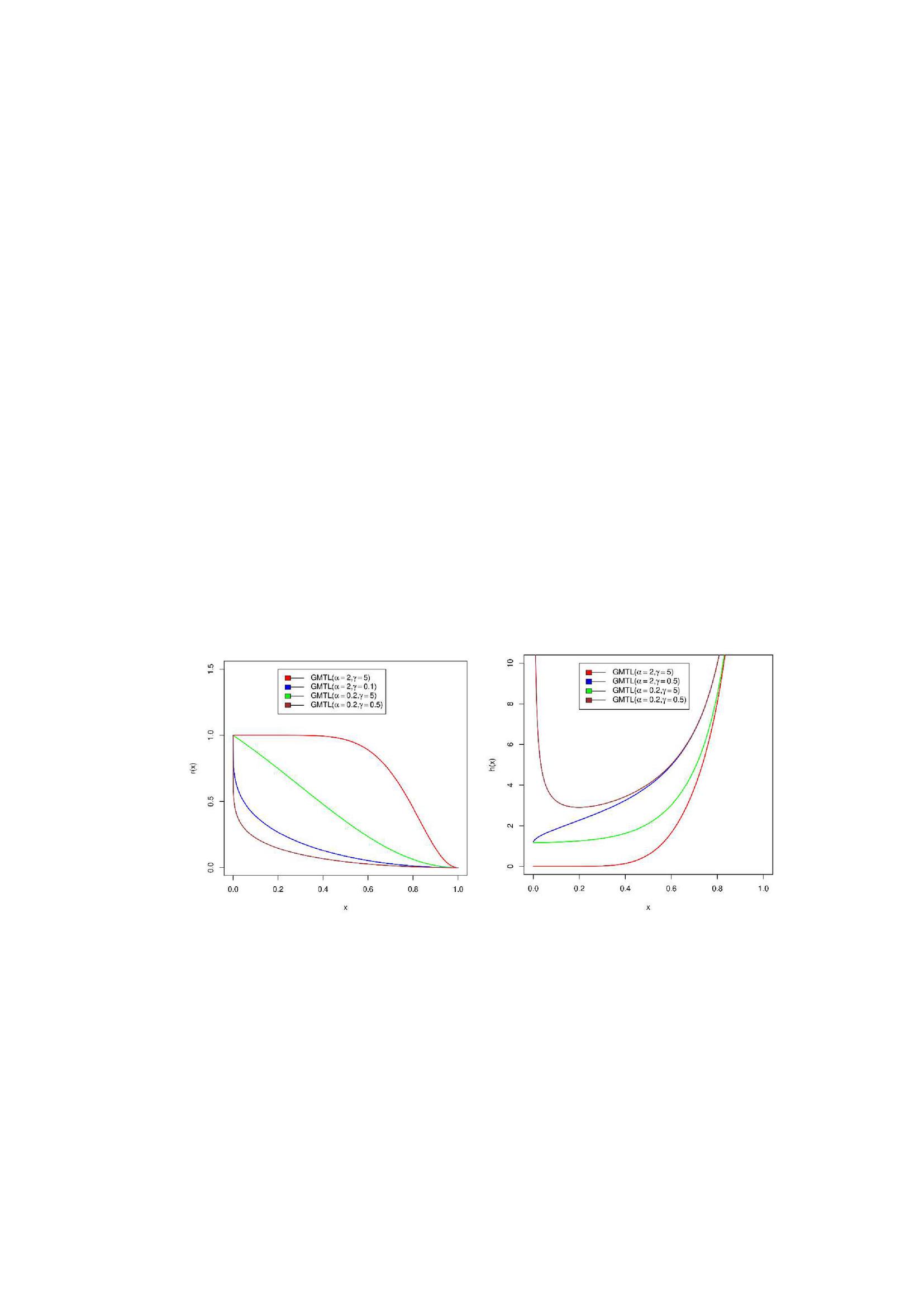
Figure 2 Reliability and hazard rate functions of GMTL().
3 Statistical Properties
3.1 Moments
The th ordinary moments of the proposed distribution can be derived using the given theorem.
Theorem 3.1
Proof.
Expanding the term as a convergent sum of infinite terms, we get
using the expansion of series,
where, (as per the situation) and then by further simplifying it, we get
Using Theorem 3.1, we can derive the expressions of mean, variance, skewness and kurtosis by putting the respective values of r.
3.2 Conditional Moments
The th conditional moments of the proposed distribution can be derived using the given theorem.
Theorem 3.2
Proof. To prove the above theorem, we proceed through the same way as mentioned in Theroem 3.1.
3.3 Quantile Function
To obtain the th quantile function (denoted by ), we solve the equation . Hence from Equation (3), we get
| (9) |
This equation can be further solved using the quadratic formula or by numerical methods. We have also explored the changing behavior of median with varying values of parameters and . Thus, we put in Equation (9), where denotes the median. We get,
The nature of median with respect to changing parameters is visualized in Figure 3.
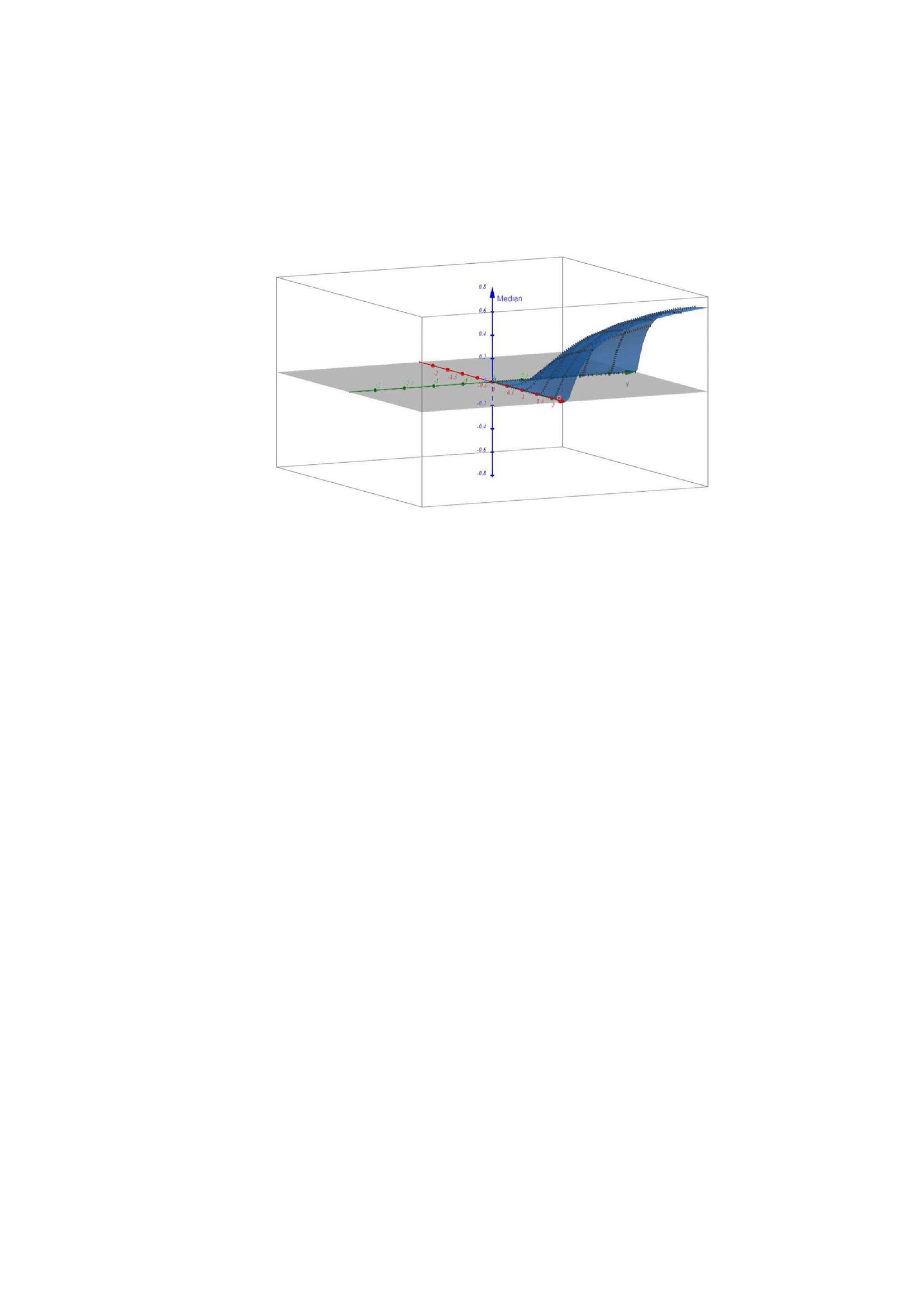
Figure 3 Variation in median with respect to changing parameters ().
3.4 Order Statistics
In this section, we obtain the probability density and cumulative distribution functions of the th order statistics, which refers to the th sample point in the sample of total n points, when arranged in ascending order.
Let be a random sample of size , from the proposed GMTL distribution where we re-arange all the sample points in ascending order. We denote, as the corresponding order statistics. The pdf of th (for ) order statistics is given as,
where, f(x) and F(x) denote the pdf and the cdf of the population.
And the cdf of th order statistics , , is given as
Thus, by using Equations (3) and (4) the pdf and cdf of the th order statistics based on a random sample of size from the proposed distribution is derived as follows –
| (10) |
and
| (11) |
3.5 Mean Deviation
The mean deviation about mean is defined by,
where refers to the mean.
The above expression can be simplified as follows
Using integral by parts and putting , it simplifies to
where denotes the proposed cdf.
By Theorem 3.2,
and thus,
| (12) |
The mean deviation about median is defined as
where refers to the median.
Ater simplying the above expression by putting , we get
By Theorem 3.2,
Thus,
| (13) |
3.6 Entropy
Entropy of a random variable measures the average level of information or uncertainty inherent in the variable’s possible outcomes in this section, we present the expression of Reńyi entropy (see [13]) which generalizes the Hartley and Shannon entropies. Let X has the pdf f(x) then Reńyi entropy is defined as,
From Equation (4) we get,
and after simplification
Hence we get
| (14) |
3.7 Stress-Strength Reliability
The stress-strength reliability is used in reliability theory as a measure of the performance of the system in consideration under stress. In terms of probability, the stress-strength reliability can be obtained as
where, refers to the strength of the system and refers to the stress applied on the system.
The probability can be used to compare two random variables that come across in various disciplines.
The stress-strength reliability, for GMTL random variables where and (where the parameters may or may not be equal) is given by
on simplifying, we have,
| (15) |
where, represents gamma integral and represents incomplete gamma integral.
3.8 Identifiability
A family of distributions is said to be identifiable in parameters if the distribution of two members of the family are equal, i.e. , then for all values of .
In order to prove our results based on identifiability, we use Theorem 1 given by [2]. It states that the density ratio, , of two distinct (unequal parameters) members of the family defined on the interval , either converges to 0 or diverges to , as . For the GMTL distribution, we have,
| (16) |
This limit can be equal to 1 if . It is possible that this limit is 1 even if the parametrs are not equal to each other.
Thus, the GMTL distribution is not indentifiable as the multiplication of the two parameters may be the same for the distinct parameter values. If we parameterise the distribution using and , the limiting cases of the ratio of density, from Equation (16) an be given as
| (17) |
Thus, the GMTL parameters, and are identified if two members of the GMTL family have same densities with same for different values of (i.e. ).
3.9 Stochastic Ordering
A random variable is said to be stochastically greater than if for all . In a similar manner, is said to be greater than Y in the
• hazard rate order if for all
• mean residual life order if for all
• likelihood ratio order if is an increasing function of
Theorem 3.3 Letus have two independent random variables X and Y, such that and . Then, we have the following conditions
1. For and , , , and for all .
2. For and , , , and for all .
Proof. The likelihood ratio of two independent random variables and is given by
We first consider Case I, and differentiate the above likelihood ratio with respect to . It gives
| (18) |
For , for all . Thus, the likelihood ratio increases as the value of x increases (increasing function of x). Hence, for , . Now, by the result provided by [16], and . Similarly, we consider the Case II, , and proceed in a similar way as above
| (19) |
For , for all . Thus, the likelihood ratio increases as the value of x increases (increasing function of x). Hence, for , . Now, by the result provided by [16], and .
3.10 Ordinary Differential Equations for Density and Survival Functions
We obtain the first order differential equations of density and survival functions of the proposed GMTL distribution. It is done by calculating the first derivatives of density and survival functions with respect to x.
The first order derivative of the pdf is
Thus, the first order ODE for density function, by re-arranging the above expression into a more meaningful form, is
| (20) |
Table 1 Ordinary differential equations of GMTL density
| First Order | ||
| First Order ODE | ||
| 1 | 1 | |
| 2 | 1 | |
| 3 | 1 | |
Table 2 Ordinary differential equations of GMTL survival function
| First Order | ||
| First Order ODE | ||
| 1 | 1 | |
| 2 | 1 | |
| 3 | 1 | |
where, and . We present the first order ODEs of the pdf, for some considered parameters, in Table 1.
The survival function of the GMTL distribution given by .
On differentiating it w.r.t. x, we have
Thus, on simplifying the above expression and re-arranging it we have,
| (21) |
where, and . For some considered values of the parameters, first order ODEs of the survival function are presented in Table 2.
4 Maximum Likelihood Estimation and Simulation
4.1 Point Estimation
We obtain the maximum likelihood estimators of the parameters and by maximising the likelihood or log-likelihood function with respect to x. The log-likelihood function from the proposed distribution usig a sample of size n is given by,
| (22) |
Differentiating it with respect to the both parameters separately we get,
and
In order to get the point estimates, we equate both the equations to zero. We get the MLEs and of parameters and respectively.
We obtain the MLEs and of the parameters and respectively by equating the above equations to zero and solving the two non-linear equations. These equations may not be solved by any analytical methods. Thus, use of numerical methods is required. We recommend the use of Newton Raphson method where the initial choice of roots might be obtained using the contour plots.
4.2 Asymptotic Confidence Intervals
In this section, we obtain the confidence intervals of the parameters on the basis of the asymptotic properties of the maximum likelihood estimators. We use the diagonal elements of the Fisher information matrix and use the estimators of its elements to obtain the estimated asymptotic variance for the parameters and respectively. As this is an asymptotic propery, it is only valid for large sample problems.
Thus, two sided confidence interval of and can be defined as and respectively. Where denotes the upper point of standard normal distribution. Fisher Information matrix can be estimated by,
| (23) |
where,
4.3 Random Number Generation
The steps to generate random numbers from the proposed distribution are –
1. Select and .
2. Generate a standard uniform random number, .
3. Using the quantile function, compute
4. Repeat the steps 2 and 3, times to get a sample of size , from .
Illustration:
1. We fix and
The random sample generated is: {0.7575, 0.7344, 0.9391, 0.7976, 0.6713, 0.8507, 0.4252, 0.7743, 0.7354, 0.7549}
2. We fix and
The random sample generated is: {0.5901, 0.6160, 0.8302, 0.7302, 0.7026, 0.3785, 0.4896, 0.6976, 0.4615, 0.7156, 0.5139, 0.8669, 0.8872, 0.7725, 0.5092, 0.7548294 0.5602, 0.5448, 0.8950, 0.3764}
4.4 Simulation Study
In order to prove the consistency of the maximum likelihood estimators, of the parameters, we conduct an extensive simulation study. In this study, we simulate 10000 samples for the given value of parameters for increasing values of n (i.e., n 20,40,…200). We then compute MSE and mean absolute bias of the MLEs on the basis of these samples and study the performance of mean squared error and mean absolute bias as a function of sample size. The MSE and mean absolute bias (AB) are computed using the following formulae,
We present the results of simulation study for parameters, ()= (0.5,1.5) in Table 3 and the results are visualized in Figure 4.
Table 3 Mean squared error and mean absolute bias for () for simulated samples
| Sample Size | MSE() | AB() | MSE() | AB() |
| 20 | 0.0165 | 0.0966 | 0.0013 | 0.0292 |
| 40 | 0.0071 | 0.0653 | 0.0006 | 0.0203 |
| 60 | 0.0045 | 0.0525 | 0.0004 | 0.0169 |
| 80 | 0.0034 | 0.0461 | 0.0003 | 0.0157 |
| 100 | 0.0026 | 0.0404 | 0.0002 | 0.0135 |
| 120 | 0.0021 | 0.0369 | 0.0002 | 0.0122 |
| 140 | 0.0019 | 0.0345 | 0.0002 | 0.0114 |
| 160 | 0.0016 | 0.0319 | 0.0001 | 0.0105 |
| 180 | 0.0014 | 0.0302 | 0.0001 | 0.0100 |
| 200 | 0.0012 | 0.0284 | 0.0001 | 0.0094 |
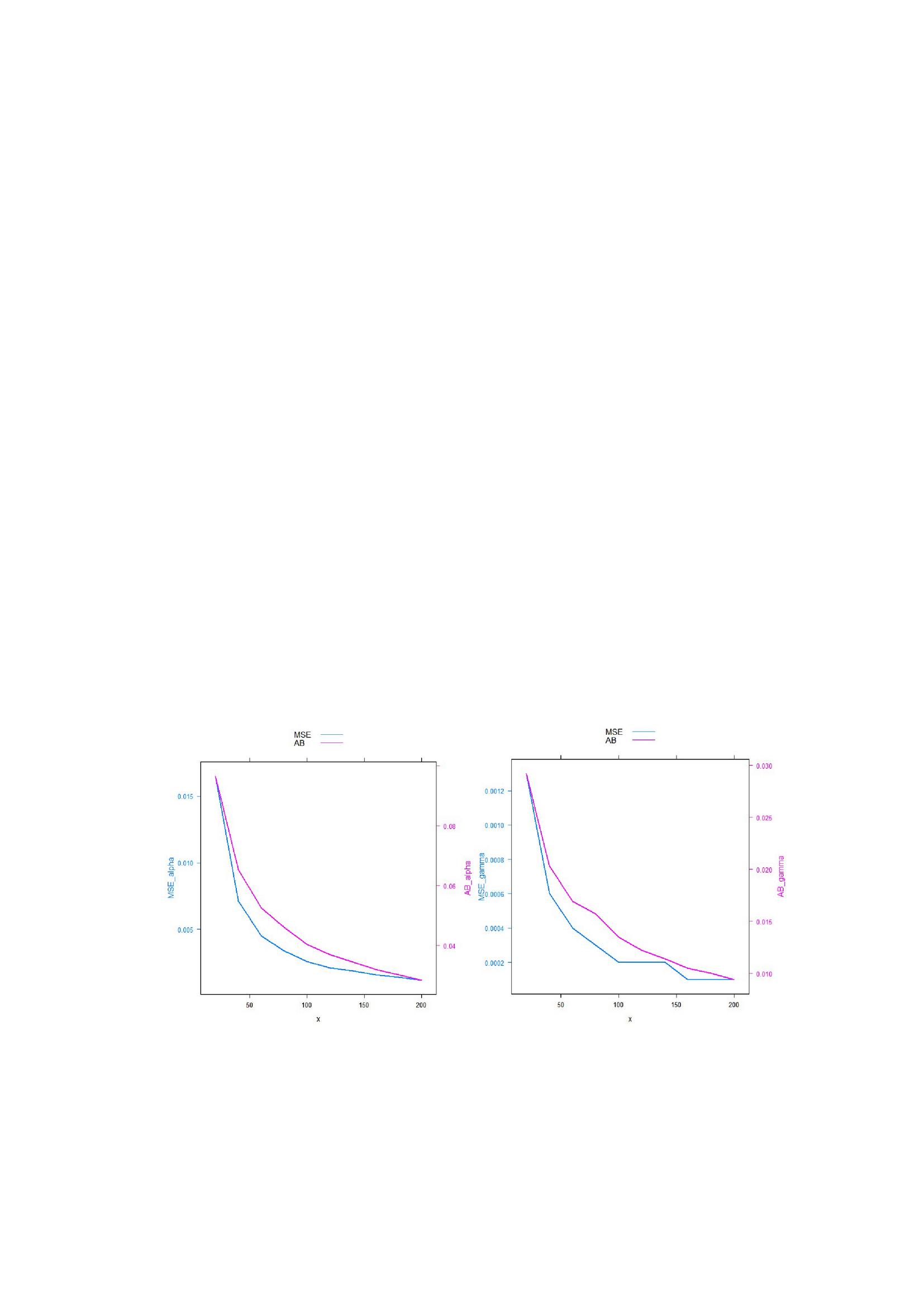
Figure 4 MSE and mean absolute bias of and for simulated samples with and .
From Figure 4, it can be concluded that the mean squared error and mean absolute bias decrease as the sample size (n) increases for 10000 simulated samples. This proves that the maximum likelihood estimators are consistent.
5 Real Data Fitting
In this section, we analyze a real dataset in order to illustrate the performance of the proposed GMTL() distribution. The GMTL distribution is fitted to the data of recovery rates of CD34 cells after peripheral blood stem cell (PBSC) transplants. The study was conducted with 239 patients between 2003 and 2008 at the Edmonton Hematopoietic Stem Cell Lab in Cross Cancer Institute-Alberta Health Services. The data is present in R package {simplexreg} (refer R Core Team (2013) [14]), by the title sdac. The recovery rates can be extracted using the command sdac$rcd. We have used and as initial values of the iterative algorithm. Thus, the obtained MLEs of the parameters of the GMTL distribution are: and .
Figure 5 gives the fitting of different models that are considered over the given data set (refer Sharma(2020) [18]). The K-S statistic for the fitting is 0.0544, with p-value 0.8713. It suggests that the proposed GMTL distribution is quite suitable for fitting of this data.
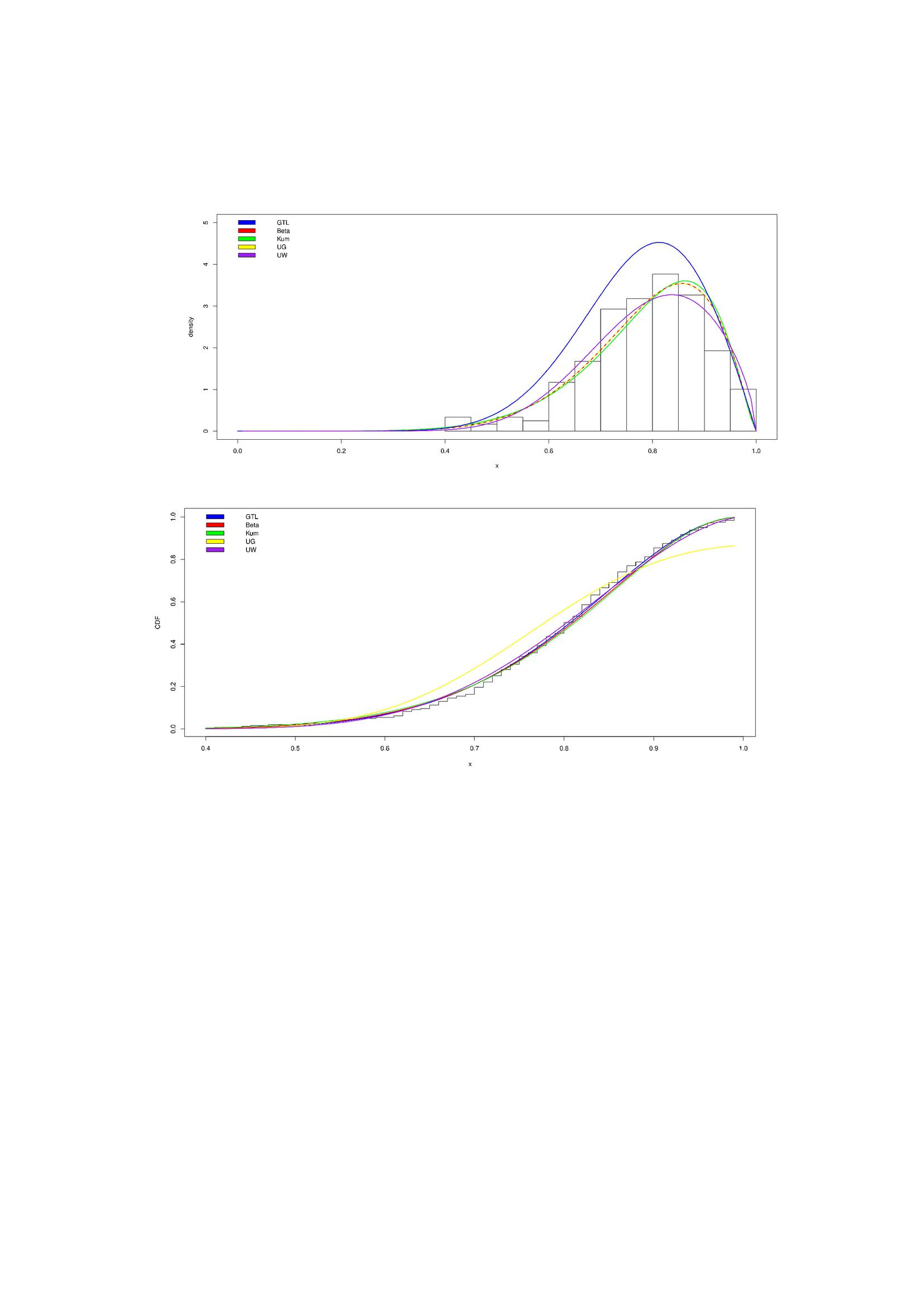
Figure 5 Fitting of different models on the given dataset.
Further, we compare the goodness-of-fit statistics with Beta, Kumaraswamy, unit-Gamma and unit-Weibull distributions which are also defined on the unit interval. We use some criteria like- Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) to compare the models under consideration and identify the best possible model for the given data set. The model with the smallest values of AIC and BIC statistics is considered to be the best possible model among the distributions under comparison. The statistics are computed by
where, is the number of estimated parameters, is the maximum value of likelihood function and is the number of observations. We also use the K-S statistics and their corresponding p-values for comparison of different models. The model having the smallest value of the K-S statistic is considered to be the best model amongst all the models under consideration.
Table 4 presents the MLEs, maximum values of log-likelihood functions, AIC and BIC criteria along with the K-S statistics and the p-values. From the table, we conclude that the proposed GDUS-Modified Topp Leone (GMTL) distribution has the highest log (L) value, smallest values of AIC, BIC and K-S- statistics among the all distributions under consideration. Therefore, we recommend the use of the proposed GMTL distribution for modelling the given dataset over the existing datat sets over the unit range which were considered.
Table 4 Maximum value of log(L), MLEs, AIC, BIC, K-S statistics and p-values for various fitted models
| Comparison of Distributions | ||||||
| Model | MLEs | AIC | BIC | K-S statistic | p-value | |
| GMTL() | 192.8600 | (5.1644,2.4269) | -381.7200 | -374.7671 | 0.0544 | 0.8713 |
| Beta() | 191.8672 | (8.6671,2.2859) | -379.7345 | -372.7816 | 0.0669 | 0.6578 |
| Kumaraswamy () | 190.7640 | (6.6942,2.4535) | -379.5280 | -370.5751 | 0.0753 | 0.5067 |
| Unit-Gamma() | 191.8867 | (2.2808,9.2516) | -379.7734 | -372.8205 | 0.1380 | 0.0210 |
| Unit-Weibull() | 192.0157 | (8.0559,1.6181) | -380.0314 | -373.0785 | 0.0585 | 0.8068 |
6 Conclusion
In this paper, a two-parameter extension of the J-shaped Topp-Leone distribution called as GDUS-Modified Topp-Leone (GMTL) distribution is introduced for a possible application of modeling of recovery rates of CD34+ cells after peripheral blood stem cell (PBSC) transplants. The proposed distribution has an interesting property to accommodate variety of density and hazard rate functions like increasing, decreasing, and bathtub shapes. The expressions of ordinary moments, conditional moments, quantile function, mean deviation, order statistics, and entropy are discussed. Other important properties of the proposed distribution like- identifiability, ordinary differential equations, stochastic orderings, and stress-strength reliability are also discussed (also refer [19]).
The estimation techniques for the parameters are also discussed. The simulation study that was conducted proved the consistency of the ML estimators of the parameters. Further, an algorithm for the generation of a random sample from the proposed distribution is also given to facilitate future studies.
According to the various goodness-of-fit criteria, like AIC, BIC, and K-S statistics, the proposed GMTL distribution is a better model for fitting the recovery rates of CD34 cells data over the Beta, Kumaraswamy, unit-Gamma, and unit-Weibull distributions (also refer [18]). Summing up, it can be concluded that the GMTL distribution can be effectively used for modeling real data defined on the unit interval.
References
[1] M. Alizadeh, F. Lak, M. Rasekhi, T. G. Ramires, H. M. Yousof, and E. Altun. The odd log-logistic topp-leone g family of distributions: heteroscedastic regression models and applications. Comput. Stat., 33, 3:1217–1244, 2018.
[2] A. P. Basu and J. K. Ghosh. Identifiability of distributions under competing risks and complementary risks model. Communications in Statistics – Theory and Methods, 9:1515–1525, 1980.
[3] P.C. Consul and G.C. Jain. On the log-gamma distribution and its properties. Stat Pap, 12:100–106, 1971.
[4] E. Gómez-Déniz, M.A. Sordo, and E. Calderín-Ojeda. The log-lindley distribution as an alternative to the beta regression model with applications in insurance. Insur Math Econ, 54:49–57, 2014.
[5] N.L. Johnson. Systems of frequency curves generated by methods of translation. Biometrika, 36(1/2):149–176, 1949.
[6] P. Kumaraswamy. A generalized probability density function for double-bounded random processes. J Hydrol, 46(1-2):79-88, 1980.
[7] M.Ç. Korkmaz and C. Chesneau. On the unit burr-xii distribution with the quantile regression modeling and applications. Comp. Appl. Math., 40(1), 2021.
[8] S.K. Maurya, A. Kaushik, S.K. Singh, and U. Singh. A new class of distribution having decreasing, increasing, and bathtub-shaped failure rate. Commun. Stat. Theory Methods, 46, 20:10359–10372, 2017.
[9] J. Mazucheli and S. Dey A.F. Menezes. The unit-birnbaum-saunders distribution with applications. Chile J Stat, 9(1):47–57, 2018.
[10] J. Mazucheli, A.F.B. Menezes, and M.E. Ghitany. The unit-weibull distribution and associated inference. J Appl Probab Stat, 13:1–22, 2018.
[11] J. Mazucheli, A.F. Menezes, and S. Dey. Unit-gompertz distribution with applications. Statistica, 79(1):25–43, 2019.
[12] S. Nadarajah and S. Kotz. Moments of some j-shaped distributions. J. Appl. Stat., 35, 10:1115–1129, 2003.
[13] A. Renyi. On measures of entropy and information. In Proceedings of the 4th Berkeley symposium on mathematical statistics and probability. Berkeley :University of California Press., 1:547–561, 1961.
[14] R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2013.
[15] Y. Sangsanit and W. Bodhisuwan. The topp-leone generator of distributions: properties and inferences. Songklanakarin. J. Sci. Technol., 38:537–548, 2016.
[16] M. Shaked and J. Shanthikumar. Stochastic orders and their applications. Academic Press, Boston, 1994.
[17] V.K. Sharma. Topp-leone normal distribution with application to increasing failure rate data. Journal of Statistical Computation and Simulation, 83, 2:326–339, 2018.
[18] V.K. Sharma. R for lifetime data modeling via probability distributions. Handbook of Probabilistic Models, Elsevier Inc., 2020.
[19] K. Shekhawat and V.K. Sharma. An extension of J-shaped distribution with application to tissue damage proportions in blood. Sankhya B, 83:543–574, 2021.
[20] C. W. Topp and F. C. Leone. A family of J-shaped frequency functions. J. Am. Stat. Assoc., 50:209–219, 1955.
[21] M. N. Shahzad, Z. Asghar, Transmuted Power Function Distribution: A More Flexible Distribution, Journal of Statistics and Management Systems 19(4) (2016) 519–539.
[22] Tanış, C. (2021) On Transmuted Power Function Distribution: Characterization, Risk Measures, and Estimation. Journal of New Theory, (34), 72–81.
[23] Karakaya, K., Kınacı, İ., Kuş, C., Akdoğan, Y. (2021). On the DUS-Kumaraswamy Distribution. Istatistik Journal of The Turkish Statistical Association, 13(1), 29–38.
[24] Kumar, D., Singh, U. and Singh, S.K. (2015). A Method of Proposing New Distribution and its Application to Bladder Cancer Patients Data. J. Stat. Appl. Pro. Lett., 2(2), 235–245.
Biographies

Arun Kaushik is currently working as an Assistant Professor in the Department of Statistics, Banaras Hindu University, Varanasi, India. He completed his PhD in Statistics in 2016. His research interests span the areas of Bayesian Inference, decision theory, MCMC, distribution theory, Bayesian econometrics, Python language, and STAN Software applications. He has been a recipient of CSIR JRF and CSIR SRF during PhD.

Unnati Nigam is currently a Masters’ degree student in the Department of Statistics, Banaras Hindu University, Varanasi, India. She completed her graduation from the same university in the year 2020 with a Gold Medal. She aspires to research and contribute in the areas of Statistical Inference, Bayesian Inference, Lifetime Data Analysis, Distribution Theory and R-software applications.
Journal of Reliability and Statistical Studies, Vol. 15, Issue 1 (2022), 299–324.
doi: 10.13052/jrss0974-8024.15112
© 2022 River Publishers