The Poisson Nadarajah-Haghighi Distribution: Different Methods of Estimation
Sajid Ali1,*, Sanku Dey2, M. H. Tahir3, and Muhammad Mansoor4
1Department of Statistics, Quaid-i-Azam University, Islamabad 45320, Pakistan
2Department of Statistics, St. Anthony’s College, Shillong 793001, India
3Department of Statistics, The Islamia University of Bahawalpur, Bahawalpur 63100, Pakistan
4Department of Statistics, Government Sadiq Egerton College, Bahawalpur, Pakistan
E-mail: sajidali.qau@hotmail.com
Corresponding Author
Received 15 March 2021; Accepted 05 July 2021; Publication 23 August 2021
Abstract
Estimation of parameters of Poisson Nadarajah-Haghighi (PNH) distribution from the frequentist and Bayesian point of view is discussed in this article. To this end, we briefly described ten different frequentist approaches, namely, the maximum likelihood estimators, percentile based estimators, least squares estimators, weighted least squares estimators, maximum product of spacings estimators, minimum spacing absolute distance estimators, minimum spacing absolute-log distance estimators, Cramér-von Mises estimators, Anderson-Darling estimators and right-tail Anderson-Darling estimators. To assess the performance of different estimators, Monte Carlo simulations are done for small and large samples. The performance of the estimators is compared in terms of their bias, root mean squares error, average absolute difference between the true and estimated distribution functions, and the maximum absolute difference between the true and estimated distribution functions of the estimates using simulated data. For the Bayesian inference of the unknown parameters, we use Metropolis–Hastings (MH) algorithm to calculate the Bayes estimates and the corresponding credible intervals. Results from the simulation study suggests that among the considered classical methods of estimation, weighted least squares and the maximum product spacing estimators uniformly produces the least biases of the estimates with least root mean square errors. However, Bayes estimates perform better than all other estimates. Finally, we discuss a practical data set to show the application of the distribution.
Keywords: Exponential distribution, hazard rate, lifetime data, maximum likelihood method, Bayesian estimation, Nadarajah-Haghighi distribution, Poisson distribution.
1 Introduction
Although there are many continuous and discrete distributions in statistics literature, the exponential distribution enjoys a special place due to its memory-less and constant hazard rate properties. Thus, it is used as a benchmark model in the reliability analysis. To overcome constant hazard rate, many extensions of the exponential distribution have been introduced in the literature, for example, exponentiated-exponential (EE) (Gupta and Kundu, 1999) and beta-exponential (BE) (Nadarajaha and Kotz, 2006), among many others. Nadarajah and Haghighi (2011) introduced a new extension of the exponential and to define it, let have the Nadarajah-Haghighi (NH for short) distribution, say . The cumulative distribution function (cdf) of NH distribution is given by
| (1) |
where is the scale parameter and is the shape parameter. The NH distribution reduces to exponential distribution assuming . The probability density function (pdf) corresponding to (1) is given by
| (2) |
Nadarajah and Haghighi (2011) pointed out that the density function (2) always has zero mode. Additionally, the hazard rate function (hrf) of the NH distribution can be increasing, decreasing, and constant. It is noted by Nadarajah and Haghighi (2011) that the NH density function can be monotonically decreasing and yet increasing hrf. Also, if is a Weibull random variable with the shape parameter and scale parameter , then the density (2) has the same as that of the random variable truncated at zero, i.e., the NH distribution can be interpreted as the truncated Weibull distribution.
Recently, Mansoor et al. (2020a) proposed the Poisson Nadarajah-Haghighi (PNH) model to model reliability systems. To this end, consider a company formed by systems functioning independently at a given time, where is a zero-truncated Poisson (ZTP) random variable (rv) with the probability mass function (pmf)
Next, suppose that each system consists of parallel units. The system will fail if all units fail and assume that the failure times of the units for the system, say , …, are independent and identically NH random variables with scale parameter and shape parameter . Let denote the failure time of the system and represents the time to failure of the first of the functioning systems. Then, one can write and the conditional cdf of given is
Hence, the unconditional cdf of is given by
For simplicity, let . Then,
| (3) |
and the pdf corresponding to (3) is given by
| (4) | ||
| (5) |
Hereafter, a random variable with cdf (3) is called the Poisson Nadarajah-Haghighi (PNH) distribution and denoted by . Clearly, if , the PNH distribution reduces to the Poisson-exponential (PE) distribution. This distribution is introduced by Mansoor et al. (2020a), however, many properties, especially a comparison of different estimation methods has not been considered in the literature. The survival function (sf) and hrf of are given by
| (6) |
and
| (7) |
respectively. Figures 1(a) and 1(b) display some plots of the density and hrf of for different values of , and . Figure 1(a) reveals that the PNH density has decreasing and unimodal (right-skewed) shape, whereas Figure 1(b) indicates that the PNH hazard rate is decreasing, increasing, bathtub (BT) and up-side bathtub (UBT).
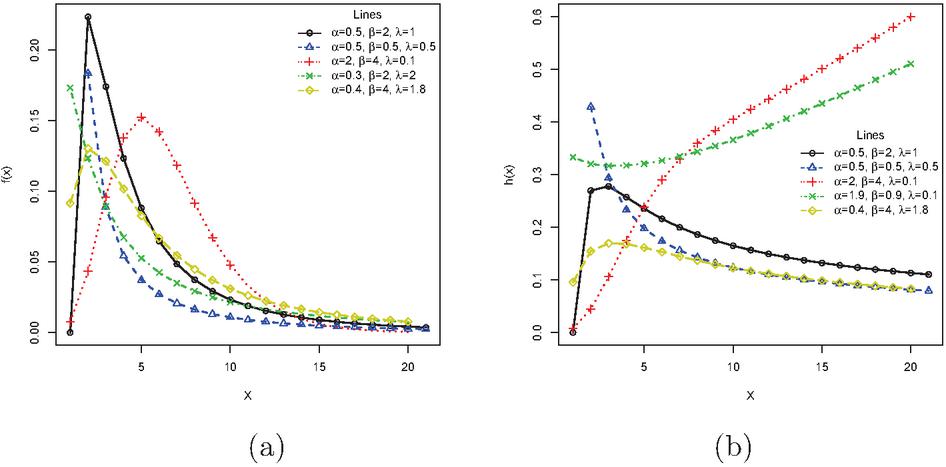
Figure 1 Plots of the PNH (a) density and (b) hazard rate for some selected parameter values.
Parameter estimation plays a vital role in statistics and the maximum likelihood estimation is generally a starting point to estimate parameters. The popularity of this method is due to its simple and intuitive formulation. For example, estimators obtained by this method are asymptotically consistent and normally distributed (Lehmann and Casella, 2003). However, there are other estimation methods in the literature, which are commonly used. For example, Kundu and Raqab (2005) for generalized Rayleigh distributions, Teimouri et al. (2013) for Weibull distribution, Ali et al. (2020b) for two-parameter logistic-exponential distribution, Dey et al. (2014, 2015, 2016, 2017b, 2017a, 2017c, 2017d) for the two-parameter Rayleigh, weighted exponential, two-parameter Maxwell, exponentiated-Chen, Dagum, transmuted-Rayleigh, two parameter exponentiated-Gumbel, new extension of generalized exponential and NH distributions. Recent literature in this direction may be seen in Alizadeh et al. (2020), Eliwa et al. (2020), Tahir et al. (2018), Ali et al. (2020c), Mansoor et al. (2020b), Ali et al. (2020a), Shafqat et al. (2020) and references cited therein. These methods are the method of moment estimation, method of L-moment estimation, method of probability weighted moment estimation, method of least-squares estimation, method of weighted least-square estimation, method of maximum product spacing estimation and method of minimum distance estimation and so on.
The aim of this study is to provide a comprehensive comparison of different frequentist methods of estimation for the PNH distribution. To this end, we assume different sample sizes and different combination of parameter values. We focus on the maximum likelihood estimators, percentile based estimators, maximum product of spacings estimators, least-squares estimators, weighted least-squares estimators, Cramér-von-Mises estimators, Anderson-Darling estimators and right-tail Anderson-Darling estimators. As it is difficult to compare the performances of different methods theoretically, extensive simulations are performed to compare the performances of the different estimators based on their relative bias, root mean squares error, the average absolute difference between the true and estimated distribution functions, and the maximum absolute difference between the true and estimated distribution functions of the estimates. The originality of this study comes from the fact that there has been no previous work comparing all of these estimation methods for the PNH distribution. Further, we also consider the Bayesian estimation of the unknown parameters under the assumptions of independent gamma priors on the scale and shape parameters, respectively. We present a Metropolis-Hastings (MH) algorithm to compute the Bayes estimates and the associated credible intervals. A real life data set is also analyzed for illustrative purposes. Thus, the study will be a guideline for choosing the best estimation method for the PNH distribution, which we think would be interesting for applied statisticians.
The rest of the paper is organized as follows. Section 2 presents the quantile function, moments and shapes of the pdf and hrf for the proposed model. Section 3 describes ten different frequentist methods of estimation. In Section 4, a simulation study is carried out to compare the performance of different methods of estimation for the proposed model. In Section 5, Bayesian analysis is conducted using the Metropolis-Hastings (MH) algorithm. In Section 6, the usefulness of the PNH distribution is illustrated using a real dataset. Finally, Section 7 offers some concluding remarks.
2 Basic Statistical Properties of PNH Distribution
This section discusses some basic statistical properties of the PNH distribution.
2.1 Quantile function
To generate random variables from the PNH distribution, we invert Equation (3) as , where . The explicit form of the PNH quantile is
| (8) |
Further, the quantile function can be used to investigate the skewness and kurtosis measures. For example, the Bowley skewness (Kenney and Keeping, 1962) based on quantiles is given by
Similarly, the Moors’ kurtosis (Moors, 1988) is
2.2 Moments
Many properties of a distribution can be studied using moments, e.g., tendency, dispersion, skewness, and kurtosis. The th moment expression of PNH is given by
where denotes the incomplete gamma function defined as .
The graphical depiction of the mean, variance, skewness, and kurtosis is given in Figure 2. It is noticed that the mean and variance decreased by increasing while increased by increasing . Similarly, the skewness and kurtosis decreased by decreasing , and is not significant as observed in the cases of mean and variance.
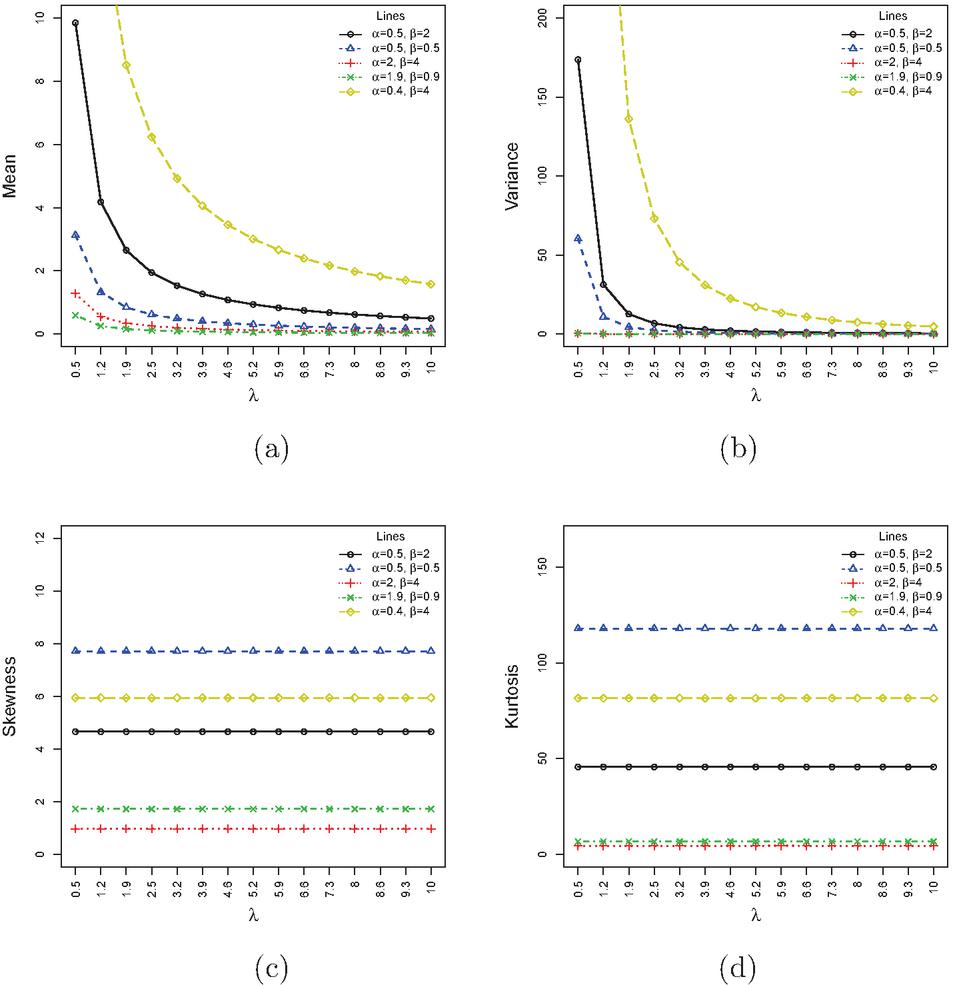
Figure 2 Plots of the PNH (a) Mean (b) Variance (c) Skewness, and (d) Kurtosis for some selected parameter values.
2.3 Shapes of the Density and Hazard Rate Functions of PNH Model
To study the shapes of the density and the hrf, we determine critical points of the PNH density by , which are the roots of the following equation.
| (9) |
The critical points of the PNH hrf can be obtained from the following equation
| (10) |
where . One can examine numerically the local maximum, minimum and inflexion points of Equations (9) and (2.3).
Another property to characterize the distribution is the log-concave, i.e., the density is log-concave if , otherwise convex. The hazard would be decreasing if the density is log-concave. For the PNH, it is observed that the density is log-concave for with a fixed . Moreover, for the density is also observed log-concave. Similarly, hazard rate average can be used to characterize the distribution whether it is increasing (decreasing) hazard rate IDHR (DIHR) if for . The PNH is DIHR for ,.
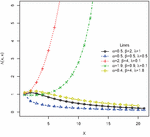
A density is said to be new-better-than-used (NBU) if , for , otherwise new-worse-than-used (NWU). From Figure 3, it is clear that the PNH is NBU for .
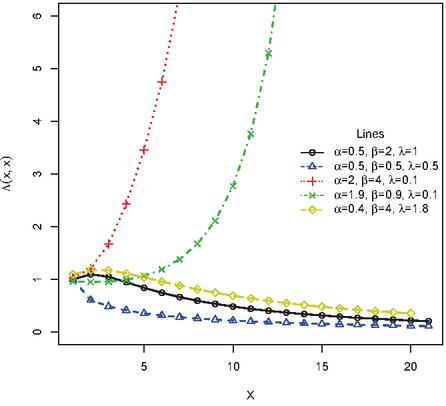
Figure 3 Plot to identify NBU and NWU of the PNH for some selected parameter values.
3 Methods of Estimation
This section describes ten classical methods for estimating the parameters, , and assuming a random sample of size from the distribution (4) with unknown parameters , and .
3.1 Method of Maximum Likelihood
It is well-known that the method of maximum likelihood is the most popular method in statistical inference, since it has several attractive properties (Lehmann and Casella, 2003). . The log-likelihood for based on a given sample is given by
| (11) |
The maximum likelihood estimators (MLEs) of the model parameters can be obtained
by maximizing the log-likelihood function with respect
to . There are several routines available for numerical
maximization of (3.1) given in the R program (optim
function), SAS (PROC NLMIXED), Ox (sub-routine
MaxBFGS). Alternatively, one can differentiate (3.1) and solve the
resulting nonlinear likelihood equations.
The partial derivatives of with respect to the parameters are given by
The MLE of can be obtained by solving simultaneously the following normal equations
There is no closed-form expressions for and and therefore numerical computations using nonlinear optimization algorithm, such as the Newton-Raphson iterative method, should be used.
3.2 Method of Maximum and Minimum Spacing Distance Estimators
Cheng and Amin (1979) introduced the maximum product of spacings (MPS) method as an alternative to MLE for the estimation of parameters of continuous univariate distributions. Ranneby (1984) independently developed the same method as an approximation to the Kullback-Leibler measure of information. Let denote the distribution function of the ordered random variables , where is a random sample of size from the cdf .
Let define the uniform spacings of a random sample from the PNH distribution distribution as
where and . Clearly,
Following Cheng and Amin (1983), the maximum product of spacings estimators , and of the parameters , and are obtained by maximizing the geometric mean of the spacings with respect to , and
| (12) |
or, equivalently, by maximizing the function
| (13) |
The estimators , and of the parameters , and can also be obtained by solving the nonlinear equations
| (14) | ||
| (15) | ||
| (16) |
where
| (17) | ||
| (18) |
and
| (19) |
Cheng and Amin (1983) showed that maximizing as a method of parameter estimation is as efficient as the MLE estimation. Further, the MPS estimators are also consistent under more general conditions than the MLE estimators.
Similarly, the minimum spacing distance estimators of , and of , and are obtained by minimizing
| (20) |
where is an appropriate distance. Some choices of are and , which are called absolute and absolute-log distance, respectively. These estimators are called the minimum spacing absolute distance estimator (MSADE) and the minimum spacing absolute-log distance estimator (MSALDE). This method was originally proposed by Torabi (2008). The MSADE and MSALDE of parameters , and can be obtained by minimizing
| (21) |
and
| (22) |
with respect to , and respectively.
The estimators , and of , and can be obtained by solving the following nonlinear equations
where
The estimators , and of , and can be obtained by solving the nonlinear equations
where
3.3 Methods of Ordinary and Weighted Least Squares
The least squares and weighted least squares estimators were proposed by Swain et al. (1988) to estimate the parameters of beta distribution (Swain et al., 1988). It is well known that
| (23) |
Using the same notations as subsection 3.2, the ordinary least squares estimators , and of the parameters , and are obtained by minimizing the function:
| (24) |
These estimators can also be obtained by solving the following non-linear equations:
where , and are given by Equations (17), (18) and (19), respectively.
The weighted least-squares estimators , and of the parameters , and are obtained by minimizing the function:
| (25) |
The WLSE can be obtained by solving the following non-linear equations:
| (26) | ||
| (27) | ||
| (28) |
3.4 Method of Percentiles
Since the PNH distribution has an explicit distribution function, the unknown parameters , and can be estimated by equating the sample percentile points with the population percentile points. This method is known as the percentile method (Kao, 1958, 1959). If denote the estimate of , then the percentile estimators and of the parameters , and can be obtained by minimizing the function with respect to , and :
where is the unbiased estimator of and is defined in (2.1).
3.5 Methods of the Minimum Distances
This section considers three estimation methods by minimization of the goodness-of-fit statistics, i.e., minimizing the distance between the theoretical and empirical cumulative distribution functions, with respect to , and .
3.5.1 Method of Cramér-von-Mises
To motivate our choice of Cramér-von Mises type minimum distance estimators, MacDonald (1971) provided empirical evidence that the bias of the estimator is smaller than the other minimum distance estimators. Thus, the Cramér-von Mises estimators , and of the parameters , and are obtained by minimizing with respect to , and :
| (29) |
The estimators can be obtained by solving the following non-linear equations:
where , and are given by , and , respectively.
3.5.2 Methods of Anderson-Darling and Right-tail Anderson-Darling
Anderson and Darling (1952) introduced a test as an alternative to statistical tests for detecting sample distributions departure from the normal distribution. This method is used here to obtain the Anderson-Darling estimators, , and of the parameters , and , by minimizing the function with respect to , and respectively.
| (30) |
The estimators can be obtained by solving the following non-linear equations:
The right-tail Anderson-Darling estimators , and of the parameters , and are obtained by minimizing with respect to , and . The right-tail Anderson-Darling is defined as
| (31) |
The estimators can also be obtained by solving the following non-linear equations.
where , and are given by Equations (17), (18) and (19), respectively.
4 Simulation Study
This section discusses Monte Carlo simulation studies to assess the performance of the frequentist estimators mentioned in the previous section. In particular, we used bias, root mean squared error, the average absolute difference between the theoretical and the empirical estimate of the distribution functions, and the maximum absolute difference between the theoretical and the empirical distribution functions as the performance assessment criteria. For comparison, we considered the following sample sizes: 40, 60, 80, 100. Ten thousand independent samples of the aforementioned sample sizes were generated from PNH distribution with parameters . It is observed that 10,000 repetitions are sufficiently large to have stable results. For all the methods considered in this study, first we have estimated the parameters using the method of maximum likelihood and used them as the initial values for the rest of the methods. Also, the same randomly generated samples are used to compute the simulation summaries of different estimation methods. The results of the simulation studies are tabulated in Tables 1–2.
For each estimate we calculate the bias, root mean-squares error (RMSE), the average absolute difference between the theoretical and the empirical estimate of the distribution functions (), and the maximum absolute difference between the theoretical and the empirical distribution functions (). The statistics are obtained using the following formulae:
| (32) | |
| (33) | |
| (34) | |
| (35) |
Simulated bias, RMSE, , for the estimates are listed in Tables 1–2. The row with label shows the partial sum of the ranks and superscript indicates the rank of each of the estimators among all the estimators for that metric. For example, Table 1 shows the bias of MLE() as for . This indicates, the bias of obtained using the method of maximum likelihood ranks 4th among all other estimators.
The following observations can be drawn from the Tables 1–2.
1. All the estimators show the property of consistency, i.e., the RMSE decreased as sample size increased.
2. The bias of decreased by increasing for all the method of estimations.
3. The bias of decreased by increasing for all the method of estimations.
4. The bias of decreased by increasing for all the method of estimations but for small sample size, the estimate of is highly biased.
5. The bias of MSALDE increased by increasing as compared to the other methods.
6. is smaller than for all the estimation techniques. Again, the statistics get smaller with the increase of sample size.
7. In terms of performance of the methods of estimation, it is observed that the WLS and MPS estimators uniformly produce the least biases of the estimates with least RMSE for most of the configurations considered in our studies.
Table 1 Simulation results for
| Est. | MLE | LSE | WLS | PCE | MPS | MSADE | MSALDE | CVM | AD | RAD | |
| 20 | Bias() | 0.414 | 0.228 | 1.314 | 43.300 | 0.174 | 1.641 | 5.560 | 0.338 | 1.381 | 1.186 |
| RMSE() | 0.864 | 0.751 | 3.416 | 99.946 | 0.578 | 3.610 | 8.457 | 0.901 | 3.899 | 3.098 | |
| Bias() | 0.408 | 0.223 | 0.147 | 30.437 | 0.047 | 2.762 | 6.531 | 0.212 | 0.172 | 0.320 | |
| RMSE() | 2.520 | 0.872 | 0.548 | 56.548 | 0.314 | 5.002 | 9.736 | 0.554 | 0.596 | 0.968 | |
| Bias() | 135.204 | 15.598 | 6.343 | 0.010 | 1.580 | 1.586 | 4.137 | 3.009 | 7.300 | 8.762 | |
| RMSE() | 1884.978 | 132.385 | 36.852 | 0.010 | 4.980 | 4.166 | 7.397 | 7.098 | 40.617 | 43.115 | |
| 0.059 | 0.062 | 0.061 | 0.182 | 0.059 | 0.421 | 0.399 | 0.062 | 0.310 | 0.062 | ||
| 0.102 | 0.106 | 0.104 | 0.299 | 0.098 | 0.819 | 0.788 | 0.109 | 0.547 | 0.109 | ||
| Ranks | 44.5 | 41 | 34 | 56 | 11.5 | 56 | 64 | 32.5 | 52 | 48.5 | |
| 40 | Bias() | 0.217 | 0.174 | 0.612 | 15.429 | 0.088 | 2.108 | 5.988 | 0.221 | 0.421 | 0.410 |
| RMSE() | 0.494 | 0.523 | 2.065 | 43.918 | 0.360 | 4.475 | 9.053 | 0.584 | 1.760 | 1.574 | |
| Bias() | 0.088 | 0.079 | 0.051 | 18.925 | 0.008 | 3.061 | 6.758 | 0.093 | 0.058 | 0.116 | |
| RMSE() | 0.518 | 0.342 | 0.247 | 51.891 | 0.161 | 5.661 | 10.056 | 0.273 | 0.237 | 0.411 | |
| Bias() | 9.389 | 4.579 | 1.662 | 0.010 | 0.536 | 1.884 | 4.098 | 1.322 | 1.478 | 1.855 | |
| RMSE() | 196.246 | 47.051 | 17.031 | 0.010 | 2.404 | 4.377 | 7.285 | 4.194 | 13.045 | 10.245 | |
| 0.042 | 0.044 | 0.043 | 0.129 | 0.042 | 0.437 | 0.404 | 0.044 | 0.246 | 0.044 | ||
| 0.073 | 0.077 | 0.075 | 0.213 | 0.071 | 0.851 | 0.794 | 0.079 | 0.408 | 0.078 | ||
| Ranks | 40.5 | 41 | 38 | 56 | 10.5 | 63 | 67 | 35 | 44 | 45 | |
| 60 | Bias() | 0.148 | 0.146 | 0.322 | 14.904 | 0.055 | 2.497 | 6.045 | 0.174 | 0.191 | 0.199 |
| RMSE() | 0.366 | 0.438 | 1.260 | 54.299 | 0.275 | 5.151 | 9.186 | 0.473 | 0.911 | 0.897 | |
| Bias() | 0.038 | 0.042 | 0.026 | 18.419 | -0.001 | 3.248 | 6.832 | 0.055 | 0.032 | 0.061 | |
| RMSE() | 0.233 | 0.216 | 0.156 | 60.180 | 0.113 | 6.011 | 10.120 | 0.187 | 0.143 | 0.229 | |
| Bias() | 2.411 | 1.559 | 0.577 | 0.010 | 0.272 | 2.084 | 4.152 | 0.715 | 0.491 | 0.707 | |
| RMSE() | 49.611 | 20.585 | 7.194 | 0.010 | 1.386 | 4.606 | 7.401 | 2.736 | 4.208 | 4.238 | |
| 0.034 | 0.036 | 0.035 | 0.117 | 0.035 | 0.443 | 0.406 | 0.036 | 0.212 | 0.036 | ||
| 0.059 | 0.064 | 0.061 | 0.192 | 0.058 | 0.861 | 0.797 | 0.065 | 0.340 | 0.064 | ||
| Ranks | 38 | 40.5 | 35.5 | 56 | 11.5 | 66 | 72 | 38 | 39 | 43.5 | |
| 80 | Bias() | 0.109 | 0.124 | 0.198 | 9.327 | 0.036 | 2.663 | 6.092 | 0.144 | 0.110 | 0.121 |
| RMSE() | 0.292 | 0.385 | 0.893 | 46.999 | 0.225 | 5.445 | 9.241 | 0.409 | 0.567 | 0.591 | |
| Bias() | 0.021 | 0.027 | 0.017 | 15.827 | -0.003 | 3.292 | 6.981 | 0.038 | 0.022 | 0.041 | |
| RMSE() | 0.143 | 0.150 | 0.112 | 61.087 | 0.090 | 6.079 | 10.321 | 0.143 | 0.108 | 0.157 | |
| Bias() | 0.680 | 0.696 | 0.263 | 0.010 | 0.171 | 2.291 | 4.283 | 0.444 | 0.263 | 0.391 | |
| RMSE() | 18.605 | 10.232 | 1.730 | 0.010 | 0.856 | 4.875 | 7.566 | 1.863 | 1.970 | 2.054 | |
| 0.030 | 0.032 | 0.030 | 0.101 | 0.030 | 0.449 | 0.405 | 0.032 | 0.191 | 0.031 | ||
| 0.051 | 0.055 | 0.053 | 0.163 | 0.051 | 0.869 | 0.791 | 0.056 | 0.298 | 0.055 | ||
| Ranks | 32 | 46 | 30.5 | 56 | 11.5 | 68 | 72 | 42 | 38.5 | 43.5 | |
| 100 | Bias() | 0.085 | 0.103 | 0.132 | 4.508 | 0.025 | 2.772 | 5.790 | 0.117 | 0.070 | 0.077 |
| RMSE() | 0.243 | 0.334 | 0.670 | 23.179 | 0.190 | 5.631 | 8.993 | 0.350 | 0.341 | 0.383 | |
| Bias() | 0.014 | 0.018 | 0.012 | 13.326 | -0.003 | 3.326 | 7.021 | 0.028 | 0.016 | 0.030 | |
| RMSE() | 0.103 | 0.110 | 0.089 | 60.285 | 0.078 | 6.125 | 10.333 | 0.115 | 0.089 | 0.121 | |
| Bias() | 0.262 | 0.287 | 0.161 | 0.010 | 0.124 | 2.396 | 4.095 | 0.289 | 0.170 | 0.247 | |
| RMSE() | 8.255 | 2.617 | 0.656 | 0.010 | 0.599 | 5.021 | 7.337 | 1.199 | 0.674 | 1.011 | |
| 0.027 | 0.028 | 0.027 | 0.088 | 0.027 | 0.452 | 0.406 | 0.028 | 0.173 | 0.028 | ||
| 0.046 | 0.049 | 0.047 | 0.141 | 0.045 | 0.874 | 0.788 | 0.050 | 0.266 | 0.049 | ||
| Ranks | 33 | 41.5 | 29.5 | 55 | 11 | 69 | 74 | 48 | 36.5 | 42.5 |
Table 2 Simulation results for
| Est. | MLE | LSE | WLS | PCE | MPS | MSADE | MSALDE | CVM | AD | RAD | |
| 20 | Bias() | 21.500 | 3.754 | 1.620 | 3.415 | 5.791 | 1.055 | 1.053 | 4.066 | 2.131 | 1.505 |
| RMSE() | 36.500 | 7.952 | 4.533 | 4.880 | 10.509 | 4.814 | 4.146 | 7.898 | 5.166 | 4.360 | |
| Bias() | 3.500 | 2.261 | 1.048 | -3.498 | 0.451 | 2.017 | 1.913 | 1.587 | 1.406 | 2.165 | |
| RMSE() | 18.500 | 5.733 | 3.045 | 4.131 | 2.135 | 5.680 | 4.210 | 3.353 | 3.467 | 6.983 | |
| Bias() | 14.500 | 16.193 | 6.280 | 0.010 | 4.287 | 0.517 | 0.759 | 4.620 | 6.839 | 7.728 | |
| RMSE() | 116.500 | 39.933 | 15.753 | 0.010 | 9.311 | 4.007 | 3.759 | 9.548 | 19.058 | 20.687 | |
| 0.049 | 0.062 | 0.059 | 0.512 | 0.058 | 0.467 | 0.455 | 0.061 | 0.410 | 0.061 | ||
| 0.85 | 0.101 | 0.097 | 0.961 | 0.093 | 0.925 | 0.908 | 0.103 | 0.750 | 0.102 | ||
| Ranks | 67 | 59 | 28 | 47 | 31 | 42 | 34 | 41.5 | 45 | 45.5 | |
| 40 | Bias() | 18.105 | 3.097 | 1.413 | 4.912 | 4.735 | 1.141 | 0.603 | 3.333 | 1.614 | 1.120 |
| RMSE() | 32.645 | 6.786 | 4.027 | 5.886 | 9.455 | 4.778 | 3.682 | 6.849 | 4.260 | 3.636 | |
| Bias() | 2.531 | 1.380 | 0.688 | -3.370 | 0.327 | 1.391 | 1.884 | 0.998 | 0.781 | 1.133 | |
| RMSE() | 16.122 | 3.351 | 1.821 | 3.874 | 1.552 | 5.193 | 4.281 | 2.212 | 1.953 | 2.427 | |
| Bias() | 13.578 | 9.325 | 4.098 | 0.010 | 3.317 | 0.831 | 0.386 | 4.020 | 3.970 | 4.492 | |
| RMSE() | 108.529 | 23.107 | 10.382 | 0.010 | 7.900 | 4.296 | 3.438 | 8.812 | 10.137 | 10.624 | |
| 0.041 | 0.044 | 0.042 | 0.512 | 0.041 | 0.475 | 0.465 | 0.043 | 0.396 | 0.043 | ||
| 0.070 | 0.073 | 0.069 | 0.983 | 0.067 | 0.956 | 0.929 | 0.073 | 0.708 | 0.073 | ||
| Ranks | 63.5 | 54 | 30 | 54 | 29.5 | 48 | 39 | 43.5 | 40 | 38.5 | |
| 60 | Bias() | 14.247 | 2.712 | 1.285 | 5.135 | 4.161 | 1.534 | 0.704 | 2.896 | 1.400 | 0.974 |
| RMSE() | 27.222 | 6.081 | 3.698 | 6.196 | 8.785 | 4.961 | 3.627 | 6.165 | 3.845 | 3.277 | |
| Bias() | 0.956 | 1.009 | 0.523 | -3.380 | 0.246 | 1.046 | 1.710 | 0.779 | 0.563 | 0.809 | |
| RMSE() | 5.850 | 2.592 | 1.464 | 3.864 | 1.279 | 4.954 | 4.114 | 1.810 | 1.506 | 1.807 | |
| Bias() | 4.585 | 6.574 | 3.050 | 0.010 | 2.629 | 1.185 | 0.482 | 3.522 | 2.923 | 3.310 | |
| RMSE() | 34.637 | 16.481 | 7.975 | 0.010 | 6.876 | 4.426 | 3.406 | 8.166 | 7.842 | 8.155 | |
| 0.034 | 0.035 | 0.034 | 0.505 | 0.034 | 0.477 | 0.468 | 0.036 | 0.384 | 0.035 | ||
| 0.056 | 0.060 | 0.057 | 0.986 | 0.055 | 0.965 | 0.932 | 0.060 | 0.674 | 0.060 | ||
| Ranks | 59 | 53.5 | 27 | 56 | 30 | 51 | 40 | 50 | 38 | 35.5 | |
| 80 | Bias() | 11.557 | 2.427 | 1.158 | 5.976 | 3.698 | 1.762 | 0.808 | 2.573 | 1.221 | 0.879 |
| RMSE() | 23.196 | 5.605 | 3.452 | 7.198 | 8.218 | 5.111 | 3.637 | 5.684 | 3.511 | 3.084 | |
| Bias() | 0.538 | 0.814 | 0.434 | -3.449 | 0.199 | 0.867 | 1.648 | 0.673 | 0.461 | 0.657 | |
| RMSE() | 2.768 | 2.155 | 1.252 | 3.917 | 1.129 | 4.934 | 4.085 | 1.613 | 1.295 | 1.527 | |
| Bias() | 2.375 | 5.245 | 2.502 | 0.010 | 2.162 | 1.479 | 0.632 | 3.250 | 2.403 | 2.725 | |
| RMSE() | 14.973 | 13.319 | 6.661 | 0.010 | 6.074 | 4.648 | 3.498 | 7.757 | 6.582 | 6.782 | |
| 0.029 | 0.031 | 0.030 | 0.503 | 0.029 | 0.479 | 0.470 | 0.031 | 0.373 | 0.031 | ||
| 0.049 | 0.052 | 0.049 | 0.991 | 0.048 | 0.970 | 0.932 | 0.052 | 0.646 | 0.052 | ||
| Ranks | 50 | 54 | 27.5 | 57 | 29.5 | 52 | 43 | 52 | 38 | 37 | |
| 100 | Bias() | 9.765 | 2.213 | 1.074 | 7.395 | 3.358 | 1.923 | 0.909 | 2.332 | 1.111 | 0.818 |
| RMSE() | 20.457 | 5.205 | 3.222 | 8.337 | 7.779 | 5.296 | 3.634 | 5.268 | 3.255 | 2.903 | |
| Bias() | 0.361 | 0.666 | 0.363 | -3.374 | 0.166 | 0.772 | 1.688 | 0.585 | 0.377 | 0.548 | |
| RMSE() | 1.505 | 1.842 | 1.112 | 3.741 | 1.018 | 4.805 | 4.090 | 1.471 | 1.117 | 1.324 | |
| Bias() | 1.509 | 4.234 | 2.083 | 0.010 | 1.839 | 1.639 | 0.764 | 2.915 | 1.988 | 2.307 | |
| RMSE() | 7.579 | 11.127 | 5.823 | 0.010 | 5.488 | 4.793 | 3.562 | 7.285 | 5.740 | 5.931 | |
| 0.026 | 0.028 | 0.026 | 0.502 | 0.026 | 0.481 | 0.472 | 0.028 | 0.362 | 0.027 | ||
| 0.043 | 0.047 | 0.044 | 0.992 | 0.043 | 0.973 | 0.934 | 0.047 | 0.620 | 0.046 | ||
| Ranks | 43.5 | 56 | 28 | 58 | 30.5 | 55 | 44 | 52 | 39 | 34 |
5 Bayesian Estimation
This section presents the Bayesian inference of the unknown parameters of the distribution. It is needless to mention that, if all the parameters of the model are unknown, a joint conjugate prior for the parameters does not exist. For this, we assume piecewise independent priors and the proposed priors for the parameters , and may be taken as and . The joint prior distribution of and can be written as . We assume , denote the joint posterior and is the likelihood function. For the , the likelihood function can be written as
| (36) |
Therefore, we write the joint posterior as
| (37) |
| (38) |
where and are the gamma densities, and . It is not difficult to show that is log-concave for and and thus, the idea of Devroye (1986) can be used. Here, we will implement the Metropolis Hastings (MH) (Metropolis et al., 1953) algorithm to compute the estimators. The MH algorithm is a powerful Markov Chain Monte Carlo algorithm. To this end, we assume gamma density as transition kernel for sampling value of . The choice of gamma distribution has been considered purely for illustration purpose, and other suitable distributions can be used. After generating the marginal densities, the next step is to calculate the posterior summaries, . The steps to calculate the Bayes estimates are as follow:
Step 1: Take some initial guess values of , and , say , and , respectively;
(a) To generate , evaluate the acceptance probability by , where has been defined above.
(b) Generate a random numbers from
(c) If , , otherwise .
Step 2: Suppose at the ith step, , and take the values and . Now we can generate , and ;
Step 3: Repeat the above step times;
Step 4: Calculate the Bayes estimator of by , where denote the number of burn-in sample.
For the Bayesian analysis, we generated samples for and , and the Bayes estimates with other posterior summaries, like MCMC error, median, Bayesian intervals have been tabulated in Table 3 for the above mentioned parameter combinations and sample sizes. To compute the posterior summaries, we selected the hyperparameters in such a way that mean of the priors equal to the nominal parameter values with large variances. Moreover, we have used as the burn-in period for our calculations. From Table 3, it is noticed that as the sample size increases, the Bayes estimates approaches to the nominal values and the Bayesian intervals become tighter for large sample sizes. Furthermore, the MCMC error decreases with the increase of sample sizes.
Table 3 Monte Carlo Markov Chain results for Bayesian analysis
| Parameter | Estimate | SD | MC error | CI | Median | |
| 20 | 0.5044 | 0.5101 | 0.0060 | (0.0128,1.88) | 0.3504 | |
| 40 | 0.5051 | 0.5085 | 0.0036 | (0.0127,1.855) | 0.3464 | |
| 60 | 0.4999 | 0.5005 | 0.0014 | (0.0128,1.833) | 0.3468 | |
| 80 | 0.501 | 0.5006 | 0.0012 | (0.0129,1.824) | 0.3464 | |
| 100 | 0.5001 | 0.5002 | 0.0004 | (0.0127,1.804) | 0.3468 | |
| 20 | 0.4974 | 0.5037 | 0.0048 | (0.0123,1.919) | 0.3402 | |
| 40 | 0.4997 | 0.5035 | 0.0033 | (0.0119,1.893) | 0.3447 | |
| 60 | 0.5008 | 0.5019 | 0.0014 | (0.0128,1.856) | 0.3467 | |
| 80 | 0.5011 | 0.5014 | 0.0010 | (0.0132,1.849) | 0.3475 | |
| 100 | 0.5001 | 0.5004 | 0.0004 | (0.0127,1.846) | 0.3469 | |
| 20 | 0.4986 | 0.4993 | 0.0045 | (0.0124,1.845) | 0.3458 | |
| 40 | 0.503 | 0.5119 | 0.0031 | (0.0116,1.897) | 0.3489 | |
| 60 | 0.4996 | 0.4989 | 0.0014 | (0.0129,1.836) | 0.3466 | |
| 80 | 0.4974 | 0.4942 | 0.0011 | (0.0131,1.811) | 0.346 | |
| 100 | 0.4991 | 0.4982 | 0.0004 | (0.0128,1.804) | 0.3467 | |
| 20 | 3.506 | 1.329 | 0.0057 | (1.426,6.574) | 3.332 | |
| 40 | 3.477 | 1.302 | 0.0054 | (1.429,6.445) | 3.31 | |
| 60 | 3.502 | 1.33 | 0.0034 | (1.402,6.541) | 3.326 | |
| 80 | 3.503 | 1.314 | 0.0032 | (1.42,6.477) | 3.316 | |
| 100 | 3.499 | 1.302 | 0.0029 | (1.405,6.541) | 3.328 | |
| 20 | 3.498 | 1.301 | 0.0059 | (1.432,6.529) | 3.347 | |
| 40 | 3.482 | 1.329 | 0.0059 | (1.396,6.477) | 3.317 | |
| 60 | 3.506 | 1.331 | 0.0036 | (1.404,6.595) | 3.347 | |
| 80 | 3.502 | 1.328 | 0.0035 | (1.407,6.536) | 3.333 | |
| 100 | 3.503 | 1.328 | 0.0032 | (1.411,6.578) | 3.342 | |
| 20 | 3.498 | 1.326 | 0.0063 | (1.403,6.532) | 3.323 | |
| 40 | 3.511 | 1.328 | 0.0059 | (1.404,6.582) | 3.348 | |
| 60 | 3.501 | 1.322 | 0.0038 | (1.411,6.514) | 3.337 | |
| 80 | 3.502 | 1.324 | 0.0032 | (1.408,6.555) | 3.334 | |
| 100 | 3.499 | 1.318 | 0.0029 | (1.41,6.512) | 3.337 |
Table 4 Bladder Cancer Data Set
| 0.08 | 2.09 | 3.48 | 4.87 | 6.94 | 8.66 | 13.11 | 23.63 | 0.20 | 2.23 | 3.52 | 4.98 | 6.97 | 9.02 | 13.29 |
| 0.40 | 2.26 | 3.57 | 5.06 | 7.09 | 9.22 | 13.80 | 25.74 | 0.50 | 2.46 | 3.64 | 5.09 | 7.26 | 9.47 | 14.24 |
| 25.82 | 0.51 | 2.54 | 3.70 | 5.17 | 7.28 | 9.74 | 14.76 | 26.31 | 0.81 | 2.62 | 3.82 | 5.32 | 7.32 | 10.06 |
| 14.77 | 32.15 | 2.64 | 3.88 | 5.32 | 7.39 | 10.34 | 14.83 | 34.26 | 0.90 | 2.69 | 4.18 | 5.34 | 7.59 | 10.66 |
| 15.96 | 36.66 | 1.05 | 2.69 | 4.23 | 5.41 | 7.62 | 10.75 | 16.62 | 43.01 | 1.19 | 2.75 | 4.26 | 5.41 | 7.63 |
| 17.12 | 46.12 | 1.26 | 2.83 | 4.33 | 5.49 | 7.66 | 11.25 | 17.14 | 79.05 | 1.35 | 2.87 | 5.62 | 7.87 | 11.64 |
| 17.36 | 1.40 | 3.02 | 4.34 | 5.71 | 7.93 | 11.79 | 18.10 | 1.46 | 4.40 | 5.85 | 8.26 | 11.98 | 19.13 | 1.76 |
| 3.25 | 4.50 | 6.25 | 8.37 | 12.02 | 2.02 | 3.31 | 4.51 | 6.54 | 8.53 | 12.03 | 20.28 | 2.02 | 3.36 | 6.76 |
| 12.07 | 21.73 | 2.07 | 3.36 | 6.93 | 8.65 | 12.63 | 22.69 |
6 Real Data Application
This section presents a real data set analysis using the PNH distribution and further compares it with competing models, like the exponentiated-NH (ENH) (Lemonte, 2013), exponentiated Weibull (EW) (Mudholkar and Srivastava, 1993), Marshall-Olkin Weibull (MOW) (Ghitany et al., 2005), BE, NH, EE and Weibull models. We estimate the model parameters by using the maximum likelihood method and compared the goodness-of-fit of the models using the Cramér–von Mises () and Anderson-Darling () statistics, which are described in detail by Chen and Balakrishnan (1995). In addition, we consider the Kolmogrov-Smirnov (K-S) statistic. In general, the smaller the values of these statistics, the better the fit to the data. The cdfs of the ENH, EW, MOW, BE and EE models are given by
where is the incomplete beta function ratio.
The data set has been taken from Lee and Wang (2013) and reproduced in Table 4, which represents the remission times (in months) of a random sample of 128 bladder cancer patients.
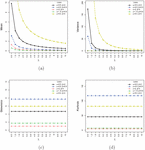
The box-plot of these observations is displayed in Figure 4(a), which indicates that the distribution is right-skewed. The TTT plot (Aarset, 1987) of these data is shown in Figure 4(b) and it is clear that it is first concave and then convex, which suggests an upside-down bathtub shaped failure rate. Accordingly, the PNH distribution could, in principle, be appropriate for modeling the current data set. The MLEs (with SEs in parentheses), , and K-S statistics are included in Table 6. All three goodness-of-fit statistics indicate that the PNH model provides the best fit. Further, the empirical and estimated survival curves and PP plot are shown in Figures 5(a) and 5(b) and also support this conclusion.
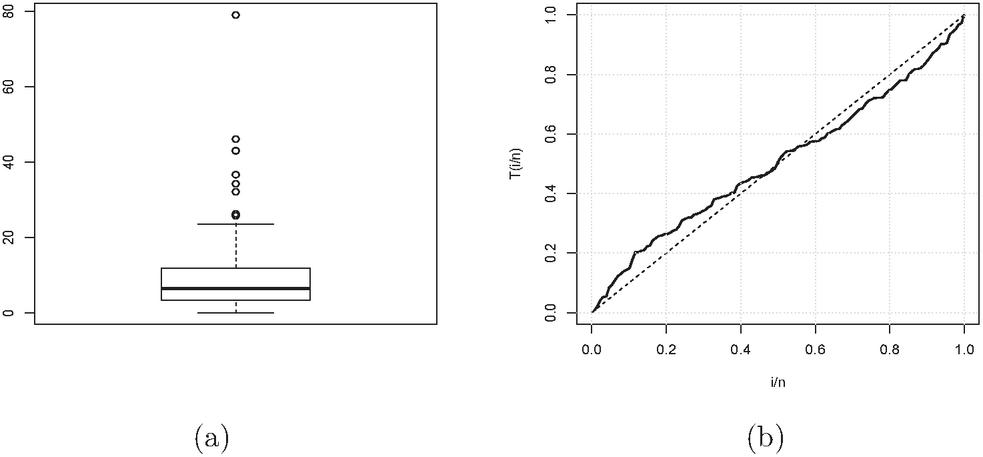
Figure 4 (a) Boxplot (b) TTT plot for the bladder cancer data.
Table 5 Monte Carlo Markov Chain results for the Bayesian analysis of the data set
| Parameter | Estimate | SD | MC error | CI | Median |
| 0.7721 | 0.7783 | 0.0036 | (0.0189,2.863) | 0.5339 | |
| 1.666 | 1.672 | 0.0078 | (0.0420,6.182) | 1.152 | |
| 0.2021 | 0.2017 | 0.0009 | (0.0052,0.7446) | 0.1409 |
Table 6 MLEs, their standard errors (in parentheses) and goodness-of-fit statistics for the bladder cancer data
| Distribution | Estimates | K-S | ||||
| PNH | 0.2422 | 0.0358 | 0.0405 | |||
| ENH | 0.2779 | 0.0421 | 0.0442 | |||
| EW | 0.2885 | 0.0436 | 0.0450 | |||
| MOW | 0.8311 | 0.1417 | 0.0791 | |||
| BE | 0.7154 | 0.1192 | 0.0738 | |||
| NH | 0.6741 | 0.11008 | 0.0919 | |||
| EE | 0.6033 | 0.1122 | 0.0725 | |||
| W | 0.7863 | 0.1313 | 0.0699 | |||
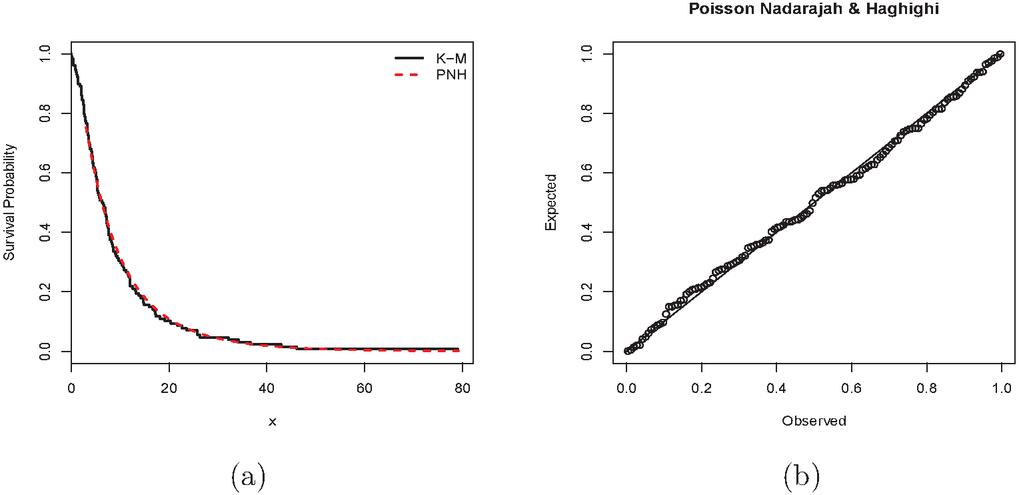
Figure 5 Bladder cancer data (a) empirical survival and estimated PNH survival function; (b) P-P plot.
7 Conclusion
In this article, we studied some basic statistical properties of the Poisson Nadarajah-Haghighi (PNH) distribution and estimated its parameters by eleven different methods of estimation, namely the maximum likelihood estimators, least squares and weighted least squares estimators, the maximum product of spacings estimators, the minimum spacing absolute distance estimators, the minimum spacing absolute-log distance estimators, Cramér-von-Mises estimators, Anderson-Darling and right-tail Anderson-Darling estimators and the Bayes estimators. Results of the simulation study showed that among frequentist estimators, WLS and MPS perform better than the other methods. However, the Bayesian is the best method. An application to a real data set is also presented as an illustration of the potentiality of the new model as compared to other existing models. It is expected the utility of the model in different fields, especially in survival analysis when hazard rate is decreasing, increasing, bathtub and upside-down bathtub shape. Further, it is also noticed that the performance of the MLEs is quite satisfactory. The use of the MLEs or Bayes estimators is recommended for practical purposes. In the future, record values can be analyzed assuming the PNH distribution.
Acknowledgments
The authors express their sincere thanks to the three reviewers and the editors for making some useful suggestions on an earlier version of this manuscript which resulted in this improved version.
References
Aarset (1987) Aarset, M. V. (1987). How to identify a bathtub hazard rate. IEEE Transactions on Reliability, R-36(1):106–108.
Ali et al. (2020a) Ali, S., Dey, S., Tahir, M. H., and Mansoor, M. (2020a). A comparison of different methods of estimation for the flexible Weibull distribution. Communications Faculty of Sciences University of Ankara Series A1 Mathematics and Statistics, 69:794–814.
Ali et al. (2020b) Ali, S., Dey, S., Tahir, M. H., and Mansoor, M. (2020b). Two-parameter logistic-exponential distribution: Some new properties and estimation methods. American Journal of Mathematical and Management Sciences, 39(3):270–298.
Ali et al. (2020c) Ali, S., Dey, S., Tahir, M. H., and Mansoor, M. (2020c). Two-Parameter Logistic-Exponential Distribution: Some New Properties and Estimation Methods. American Journal of Mathematical and Management Sciences, 39(3):270–298.
Alizadeh et al. (2020) Alizadeh, M., Afify, A. Z., Eliwa, M. S., and Ali, S. (2020). The odd log-logistic Lindley-G family of distributions: properties, Bayesian and non-Bayesian estimation with applications. Computational Statistics, 35:281–308.
Anderson and Darling (1952) Anderson, T. W. and Darling, D. A. (1952), Asymptotic Theory of Certain “Goodness of Fit” Criteria Based on Stochastic Processes, The Annals of Mathematical Statistics, 23(2):193–212. https://doi.org/10.1214/aoms/1177729437
Chen and Balakrishnan (1995) Chen, G. and Balakrishnan, N. (1995). A general purpose approximate goodness-of-fit test. Journal of Quality Technology, 27(2):154–161.
Cheng and Amin (1979) Cheng, R. C. H. and Amin, N. A. K. (1979). Maximum product of spacings estimation with application to the lognormal distribution, math.
Cheng and Amin (1983) Cheng, R. C. H. and Amin, N. A. K. (1983). Estimating parameters in continuous univariate distributions with a shifted origin. Journal of the Royal Statistical Society. Series B (Methodological), 45(3):394–403.
Devroye (1986) Devroye, L. (1986). Non-Uniform Random Variate Generation. Springer-Verlag.
Dey et al. (2017a) Dey, S., Al-Zahrani, B., and Basloom, S. (2017a). Dagum distribution: Properties and different methods of estimation. International Journal of Statistics and Probability, 6(2):74–92.
Dey et al. (2015) Dey, S., Ali, S., and Park, C. (2015). Weighted exponential distribution: properties and different methods of estimation. Journal of Statistical Computation and Simulation, 85(18):3641–3661.
Dey et al. (2016) Dey, S., Dey, T., Ali, S., and Mulekar, M. S. (2016). Two-parameter Maxwell distribution: Properties and different methods of estimation. Journal of Statistical Theory and Practice, 10(2):291–310.
Dey et al. (2014) Dey, S., Dey, T., and Kundu, D. (2014). Two-parameter Rayleigh distribution: Different methods of estimation. American Journal of Mathematical and Management Sciences, 33(1):55–74.
Dey et al. (2017b) Dey, S., Kumar, D., Ramos, P. L., and Louzada, F. (2017b). Exponentiated Chen distribution: Properties and estimation. Communications in Statistics – Simulation and Computation, 46(10):8118–8139.
Dey et al. (2017c) Dey, S., Raheem, E., and Mukherjee, S. (2017c). Statistical Properties and Different Methods of Estimation of Transmuted Rayleigh Distribution. Revista Colombiana de EstadÃstica, 40:165–203.
Dey et al. (2017d) Dey, S., Raheem, E., Mukherjee, S., and Ng, H. K. T. (2017d). Two parameter exponentiated Gumbel distribution: properties and estimation with flood data example. Journal of Statistics and Management Systems, 20(2):197–233.
Eliwa et al. (2020) Eliwa, M. S., El-Morshedy, M., and Ali, S. (2020). Exponentiated odd Chen-G family of distributions: statistical properties, Bayesian and non-Bayesian estimation with applications. Journal of Applied Statistics, 0(0):1–27.
Ghitany et al. (2005) Ghitany, M. E., Al-Hussaini, E. K., and Al-Jarallah, R. A. (2005). Marshall–Olkin extended Weibull distribution and its application to censored data. Journal of Applied Statistics, 32(10):1025–1034.
Gupta and Kundu (1999) Gupta, R. D. and Kundu, D. (1999). Theory & methods: Generalized exponential distributions. Australian & New Zealand Journal of Statistics, 41(2):173–188.
Kao (1958) Kao, J. H. K. (1958). Computer methods for estimating Weibull parameters in reliability studies. IRE Transactions on Reliability and Quality Control, PGRQC-13:15–22.
Kao (1959) Kao, J. H. K. (1959). A graphical estimation of mixed Weibull parameters in life-testing of electron tubes. Technometrics, 1(4):389–407.
Kenney and Keeping (1962) Kenney, J. and Keeping, E. (1962). Mathematics of statistics. Number v. 2 in Mathematics of Statistics. Princeton: Van Nostrand.
Kundu and Raqab (2005) Kundu, D. and Raqab, M. Z. (2005). Generalized Rayleigh distribution: different methods of estimations. Computational Statistics & Data Analysis, 49(1):187–200.
Lee and Wang (2013) Lee, E. T. and Wang, J. W. (2013). Statistical Methods for Survival Data Analysis. Wiley Publishing, 4th edition.
Lehmann and Casella (2003) Lehmann, E. and Casella, G. (2003). Theory of Point Estimation. Springer New York.
Lemonte (2013) Lemonte, A. J. (2013). A new exponential-type distribution with constant, decreasing, increasing, upside-down bathtub and bathtub-shaped failure rate function. Computational Statistics & Data Analysis, 62:149–170.
MacDonald (1971) MacDonald, P. D. M. (1971). Comment on “an estimation procedure for mixtures of distributions” by Choi and Bulgren. Journal of the Royal Statistical Society. Series B (Methodological), 33(2):326–329.
Mansoor et al. (2020a) Mansoor, M., Tahir, M. H., Alzaatreh, A., and Cordeiro, G. M. (2020a). The Poisson Nadarajah–Haghighi distribution: Properties and applications to lifetime data. International Journal of Reliability, Quality and Safety Engineering, 27(01):2050005.
Mansoor et al. (2020b) Mansoor, M., Tahir, M. H., Cordeiro, G. M., Ali, S., and Alzaatreh, A. (2020b). The Lindley negative-binomial distribution: Properties, estimation and applications to lifetime data. Mathematica Slovaca, 70(4):917–934.
Metropolis et al. (1953) Metropolis, N., Rosenbluth, A. W., Rosenbluth, M. N., Teller, A. H., and Teller, E. (1953). Equation of state calculations by fast computing machines. The Journal of Chemical Physics, 21(6):1087–1092.
Moors (1988) Moors, J. J. A. (1988). A quantile alternative for kurtosis. Journal of the Royal Statistical Society. Series D (The Statistician), 37(1):25–32.
Mudholkar and Srivastava (1993) Mudholkar, G. S. and Srivastava, D. K. (1993). Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Transactions on Reliability, 42(2):299–302.
Nadarajah and Haghighi (2011) Nadarajah, S. and Haghighi, F. (2011). An extension of the exponential distribution. Statistics, 45(6):543–558.
Nadarajaha and Kotz (2006) Nadarajaha, S. and Kotz, S. (2006). The beta exponential distribution. Reliability Engineering & System Safety, 91(6):689–697.
Ranneby (1984) Ranneby, B. (1984). The maximum spacing method. an estimation method related to the maximum likelihood method. Scandinavian Journal of Statistics, 11(2):93–112.
Shafqat et al. (2020) Shafqat, M., Ali, S., Shah, I., and Dey, S. (2020). Univariate discrete Nadarajah and Haghighi distribution: Properties and different methods of estimation. Statistica, 80(3):301–330.
Swain et al. (1988) Swain, J. J., Venkatraman, S., and Wilson, J. R. (1988). Least-squares estimation of distribution functions in Johnson’s translation system. Journal of Statistical Computation and Simulation, 29(4):271–297.
Tahir et al. (2018) Tahir, M. H., Cordeiro, G. M., Ali, S., Dey, S., and Manzoor, A. (2018). The inverted Nadarajah–Haghighi distribution: estimation methods and applications. Journal of Statistical Computation and Simulation, 88(14):2775–2798.
Teimouri et al. (2013) Teimouri, M., Hoseini, S. M., and Nadarajah, S. (2013). Comparison of estimation methods for the Weibull distribution. Statistics, 47(1):93–109.
Torabi (2008) Torabi, H. (2008). A general method for estimating and hypotheses testing using spacings. Journal of Statistical Theory and Practice, 8(2):163–168.
Biographies

Sajid Ali is currently Assistant Professor at the Department of Statistics, Quaid-i-Azam University (QAU), Islamabad, Pakistan. He graduated (PhD Statistics) from Bocconi University, Milan, Italy. His research interest is focused on Bayesian inference, construction of new flexible probability distributions, time series analysis, and process monitoring.

Sanku Dey, M.Sc., Ph.D.: An Associate Professor in the Department of Statistics, St. Anthony’s College, Shillong, Meghalaya, India. He has to his credit more than 220 research papers in journals of repute. He is a reviewer and associate editors of reputed international journals. He has a good number of contributions in almost all fields of Statistics viz., distribution theory, discretization of continuous distribution, reliability theory, multi-component stress-strength reliability, survival analysis, Bayesian inference, record statistics, statistical quality control, order statistics, lifetime performance index based on classical and Bayesian approach as well as different types of censoring schemes etc.

M. H. Tahir is currently Professor of Statistics, and Chair Department of Statistics at The University of Bahawalpur (IUB), Bahawalpur, Pakistan. He received BSc, MSc and PhD degree from IUB in 1988, 1990 and 2010, respectively. Dr Tahir has over 27 years of teaching experience to post-graduate classes, and has supervised 65 MPhil and 8 PhD students successfully. He has published more than 90 research papers in national and international journals, including Journal of Statistical Planning and Inference, Communications in Statistics-Theory and Methods, Communications in Statistics-Simulation and Computation, Journal of Statistical Computation and Simulation, Journal of Statistical Distributions and Applications, Journal of Statistical Theory and Applications. He is reviewer of more than 55 national and international statistical journals. Dr. Tahir’s research interests include distribution theory, generalized classes of distributions, survival and lifetime data analysis, methods of estimation, and construction of experimental designs.

Muhammad Mansoor is Assistant Professor of Statistics at the Department of Statistics, Government Sadiq Egerton Graduate College, Bahawalpur, Pakistan. His current research focuses on generalizing statistical distributions arising from the hazard function. Other research areas include statistical inference of probability models, computational statistics, and regression analysis.
Journal of Reliability and Statistical Studies, Vol. 14, Issue 2 (2021), 415–450.
doi: 10.13052/jrss0974-8024.1423
© 2021 River Publishers