Profit Analysis of a Standby Repairable System with Priority to Preventive Maintenance and Rest of Server Between Repairs
Chhama Aggarwal, Nitika Ahlawat and S. C. Malik*
Department of Statistics, M.D. University, Rohtak-124001, India
E-mail: aggarwalshama11@gmail.com; ahlawatnitika386@gmail.com; sc_malik@rediffmail.com
Corresponding Author
Received 25 September 2020; Accepted 11 January 2021; Publication 15 March 2021
Abstract
The paper aims to bring out the profit analysis of a system with cold standby redundancy of two identical units. In the system, we keep one unit in working and the other is to back up the operation. The system requires preventive maintenance after a specific time. The server has the dual role to carry out repair activities in terms of preventive maintenance and repair of the failed unit. In addition to that, the server is allowed to take rest after each repair. There is no need of rest of the server after preventive maintenance. The provision of priority has been made for the preventive maintenance over repairs. The repairs are done to increase the efficiency and productivity level of the system. The failure rate follows exponential distribution while repair time, rest time of the server and preventive maintenance rate follow arbitrary distributions. The significant reliability characteristics including MTSF, long run availability, server busy time due to repair & preventive maintenance, expected number of repairs, expected number of preventive maintenances per unit time and profit function are obtained using the usual stochastic processes approach. For particular values of the parameters, the revenue per unit up-time and cost functions related to repair activities are considered to carry out the profit analysis of the system model. The results are shown graphically and numerically to highlight the effect of different parameters on some significant reliability characteristics
Keywords: Cold standby redundancy, stochastic process, rest of the server, preventive maintenance, priority, reliability characteristics and profit analysis.
1 Introduction
In the fast-growing technological age, it has become reasonable to put a spare unit(s) during operation of repairable systems in order to cover the risk or any emergency requirement. Over the years, cold standby redundancy has been probably one of the finest ways to make the use of such systems more effective. As a result, researchers have focused more on stochastic analysis of standby systems. It is well-known that most units operating in a useful life period, and complex systems that consist of many kinds of components, fail normally due to random causes independently over the time interval. A stochastic process is a set of outcomes of a random experiment indexed by time, and is one of the key tools needed to analyse the future behaviour quantitatively. The models have been developed by considering different failure assumptions and repair mechanisms. Goel and Shrivastava [1], Gupta et al. [2], Wu and Wu [4] and Wang et al. [5] have thoroughly discussed the reliability models of cold standby systems. Goel and Kumar [8] analysed a quick approximation method for profit analysis of a cold standby system. Over the years, researchers have suggested several repair and configuration policies for improving the system reliability. Kumar and Gupta [3] discussed the reliability analyses of a single unit M/G/1 system model with helping unit. Kumar and Singh [6] studied the reliability and sensitivity measures of a repairable system incorporating deliberate failure and reboot delay. Lado et al. [7] developed a model of a complex repairable system having two subsystems A and B which is connected in a series configuration. The system is studied using a supplementary variable technique and varies measures of system performance such as availability, reliability, (mean time to failure) MTTF and sensitivity & cost analysis have been made for particular values of the failure and repair rates. Shinde et al. [11] estimated repair rate under performance-based logistics (PBL) technique. Lado and Singh [12] and Raghav et al. [15] focused on the cost assessment of a system consisting two subsystem series configurations. In their research work, explicit expressions for reliability, availability, mean time to failure (MTTF) and cost analysis functions have been obtained. Poonia and Singh [14] presented the study of reliability measures of a complex system consisting of two subsystems, subsystem-1, and subsystem-2, in a series configuration with switching device. The repair operations are carried out continuously by the servers in most of these studies without taking any relaxation in between the repairs. It is a real fact that if server does repairs of the failed system continuously without having any break then it could have a bad impact on his health and as a result of which the efficiency of his work may be reduced.
Aggarwal and Malik [13] analysed a standby repairable system with rest of server between repairs. The idea of the rest of the server in between repairs has been proposed in that study so that the repair person can do his task more effectively. In the present study, one additional repair activity (called preventive maintenance) has been introduced in order to enhance the performance and thus efficiency of the system. By performing a regular preventive maintenance, we are assured that our system remains to operate under safe conditions and possible issues can be removed before they have a chance to cause harm to the system. A regular preventive maintenance may cause small hindrance for operation, but that is nothing compared to actual downtime caused by a breakdown. Preventive maintenance procedures take less time than emergency repairs and replacements. There is no doubt that preventive maintenance of the system after a particular running period of operation helps in minimizing the occurrence of faults. However, on the other hand, the accuracy of the system can be further enhanced by giving priority in the field of repair. In view of these observations in mind, several studies have been carried out by the researchers on stochastic study of repairable devices with the concepts of preventive maintenance and priority in repair disciplines. Barak et al. [9] obtained reliability characteristics of a redundant system by prioritizing inspection over repair. Kumar et al. [10] also introduced the concept of preventive maintenance of the system model while experimenting on a system of non-identical units.
A cold standby repair system with two similar units was therefore stochastically explored in detail by taking into account the principle of the rest of the server after each repair. After a specific duration of service, preventive maintenance of the system is carried out. However, server does not need any rest after preventive maintenance. The unit either remains in operation or in the failed state. The parameters of server’s repair and rest time obey arbitrary distributions while the unit’s failure rate is assumed constant. Stochastic process techniques (SMP & RPT) are used to extract mean time to system failure (MTSF) expressions, availability, server busy period due to repair, server busy period due to preventive maintenance, expected number of repairs, expected number of unit’s preventive maintenances and finally the profit of the system. For particular values of the parameters, the revenue per unit up-time and cost functions related to repair activities are calculated to carry out the profit analysis of the system model, the results of some significant reliability measures are obtained. The statistics are presented to demonstrate the effect of the failure rate, server rest completion rate, unit repair rate and unit preventive maintenance rate on MTSF, system model availability and profit of the system, as shown in Figures 2–4, respectively. In Figure 1, the state transition diagram of the system model is shown.
2 Notations
| SMP | Semi-Markov Process. |
| RPT | Regenerative Point Technique. |
| O/Cs | The unit is in operative/cold standby mode. |
| The unit’s constant failure rate. | |
| The unit’s preventive maintenance rate. | |
| g(t)/G(t) | Probability density function (pdf)/Cumulative distribution function (cdf) of repair rate of the units. |
| r(t)/R(t) | Probability density function (pdf)/Cumulative distribution function (cdf) of rest completion rate of the Server. |
| f(t)/F(t) | Probability density function (pdf)/Cumulative distribution function (cdf) of preventive maintenance rate of the unit. |
| FUr/FWr | The failed unit undergoes for repair/failed unit is waiting for repair. |
| Pm/WPm | The unit undergoes for preventive maintenance/waiting for preventive maintenance. |
| FUR/FWR | The failed unit undergoes for repair/waiting for repair nonstop from previous state. |
| PM/WPM | The unit undergoes for preventive maintenance/waiting for preventive maintenance nonstop from previous state. |
| SUr/SUR | The technician is taking rest/taking rest nonstop from the previous state |
| Character for Laplace Convolution | |
| Character for Laplace Steiltjes Convolution | |
| Contribution to mean sojourn time () in state when system transits directly to state . |
3 System Description
Here, a system of a complex structure having two units in which one is in the operative mode, and other is in cold standby is analysed. All the activities like failure, repair, preventive maintenance and rest completion of the server are random in nature with respect to time. So, this system is analysed stochastically. One server is only being considered for repair activities, which attends the system instantly whenever needed. Preventive maintenance has been performed after a fixed duration of operation. And, the server does not need to take rest after preventive maintenance. There is a principle of priority to preventive maintenance over repair.
The states of the system are described as:
: The original state in which operation of one unit is going on and the another is in cold standby mode
: The one unit is failed and is under repair while the other unit is working
: The one unit stops working and continuously being repaired from the earlier state, and the second unit is still fails and is awaiting repair
: The one unit is working, another unit fails and waiting for repair continuously from previous state and the server is under rest
: The one unit is operative; other is in the process of preventive maintenance
: The one unit is failed and is waiting for repair and other unit is in the process of preventive maintenance.
: The one unit is under continuous preventive maintenance from the previous state, and the other is awaiting preventive maintenance
: The one unit fails and is waiting for repair, and the other is in the process of preventive maintenance from the earlier state.
: The one unit is failed and waiting for repair and the other is also failed and continuously waiting for repair from the previous state, and the server is in repose
: The one unit fails and undergoes for repair, and the other is continuously waiting for repair from the previous state.
: The one unit fails and is continuously expecting repair from the previous state, other is waiting for preventive maintenance and the server is in repose continuously from the earlier state.
: The one unitis in the process of preventive maintenance and the other is continually waiting for repair from the previous state.
, , , and , are regenerating states while all remaining states are non-regenerative states.
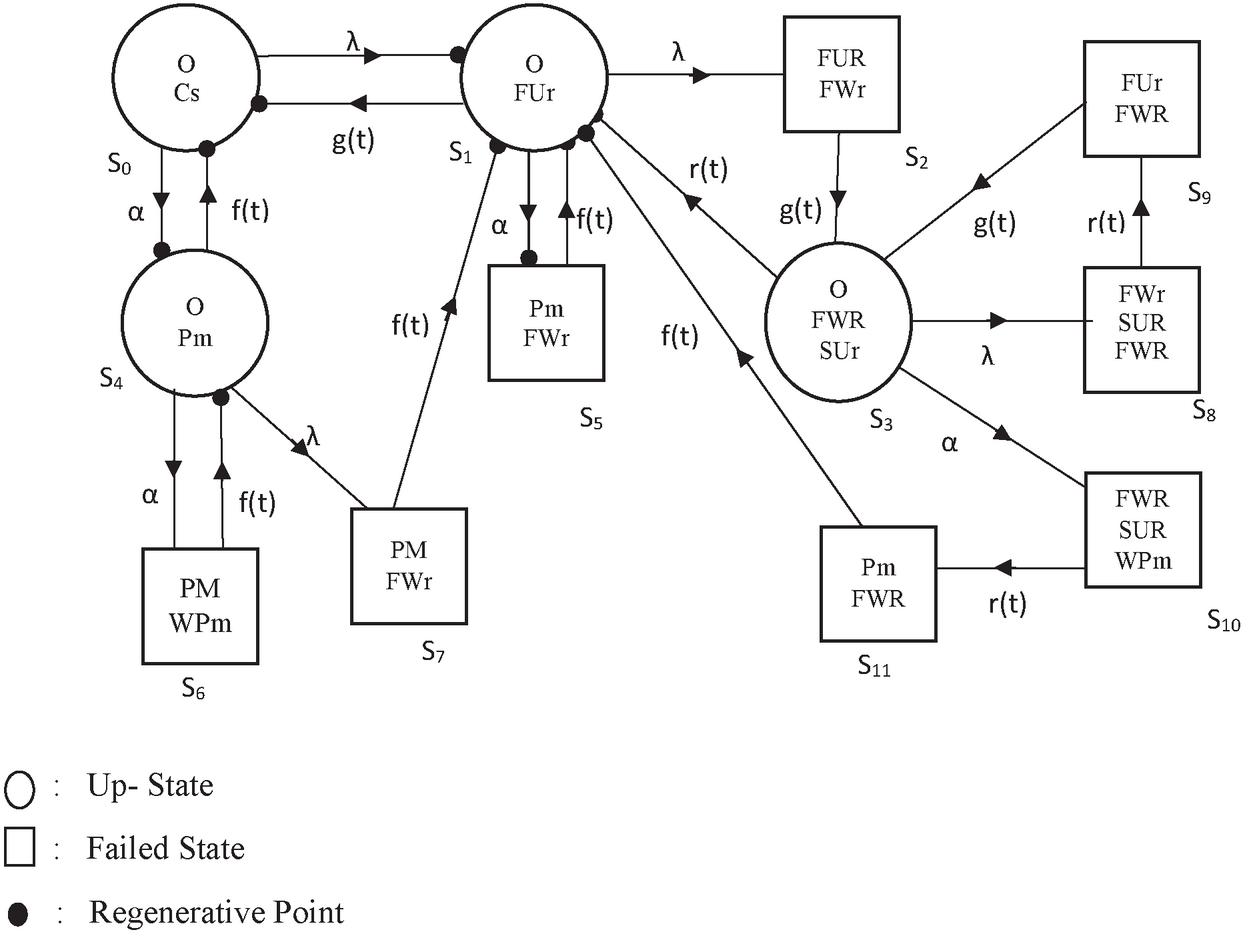
Figure 1 State transition diagram.
4 Transition Probabilities
The transition probabilities can be determined as
| (1) |
where, is the transition probability from state to . let us consider , then we can have or . The transition probability from state to state consists of two possibilities either there is a transition from state 0 to 1 or there is no transition from state 0 to 4 i.e. System remains at state .
Probability from state to is given by and probability of no transition from state to state is given by . Thus we have
The remaining transition probabilities are derived in similar way as follow as:
It can be verified that .
5 Mean Sojourn Time
The MST in state is derived by the following relations
| (2) |
where is Laplace Stieltj Transform of and the expression for can be obtained using Equation (1). Thus, we have
Hence using the values of above expressions in Equation (2), we obtain
| (3) |
6 Mean Time to System Failure (MTSF)
“Let be the first passage time from regenerating state to a failed state regarding the failed state as absorbing state. We have the following recursive relations for [13]:”
| (4) | ||
| (5) | ||
| (6) |
Taking Laplace Stieltjes transform of Equations (4)–(6) and solving for , we have
| (7) |
where and .
7 Availability Analysis
“Let be the probability that the system is in upstate at instant ‘’ given that system entered regenerative state at . The recursive relations for are given as [13]:”
| (8) | ||
| (9) | ||
| (10) | ||
| (11) |
where is the probability that the system is up initially in state is up at time without visiting to any other regenerative state, we have
| (12) |
Taking Laplace transform (LT) of Equations (8)–(11) and solving for by cramer’s rule.
The steady state availability is given as
| (13) |
where, &
8 Busy Period Analysis of the Server Due to Repair
Let be the probability that the server is busy in repair of the unit at an instant ‘’ given that the system entered regenerative state at . The recursive relations for are as follows:
| (14) | ||
| (15) | ||
| (16) | ||
| (17) |
“Where is the probability that the server is busy in state due to repair up to time ‘’ without making any transition to any other regenerative state or returning to the same via one or more non regenerative state [13].”
Therefore,
| (18) |
Take the Laplace transform (LT) of Equations (14)–(17) then solve for by cramer’s rule.
The time for which server is busy in repair is given by
| (19) |
Where
9 Busy Period Analysis of The Server Due to Preventive Maintenance
Let be the probability that the server is busy in preventive maintenance of the unit at aninstant ‘’ given that the system entered regenerative state at . The recursive relations for are as follows:
| (20) | ||
| (21) | ||
| (22) | ||
| (23) |
“Where is the probability that the server is busy in state due to repair up to time ‘’ without making any transition to any other regenerative state or returning to the same via one or more non regenerative state [13].”
Therefore,
| (24) |
Taking Laplace transform of Equations (20)–(23) and solving for by cramer’s rule.
The time for which server is busy due to Preventive Maintenance is given by
| (25) |
Where
10 Expected Number of Repairs
Let be the expected number of repairs by the server in given that the system entered the regenerative state at . The recursive relations for are given as:
| (26) | ||
| (27) | ||
| (28) | ||
| (29) |
Taking Laplace transformation of Equations (26)–(29) and solving for .
The expected number of repairs per unit time is given by
| (30) |
Where
11 Expected Number of Preventive Maintenances
Let be the expected number of preventive maintenances by the server in given that the system entered the regenerative state at . The recursive relations for are given as:
| (31) | ||
| (32) | ||
| (33) | ||
| (34) |
Taking Laplace transformation of Equations (31)–(34) and solving for .
The expected number of Preventive Maintenance per unit time is given by
| (35) |
Where
12 Profit Analysis
The profit incurred to the system model is given by
| (36) |
Where
“ Revenue per unit up-time of the system
Cost per unit time for which server is busy due to repair
Cost per unit time for which server is busy due to Preventive Maintenance
Cost per unit time repair
Cost per unit time Preventive Maintenance done by the server [13]”
13 Particular Case
Let take
| (37) | ||
| (38) | ||
| (39) | ||
| (40) | ||
| (41) | ||
| (42) | ||
| (43) | ||
| (44) | ||
| (45) | ||
| (46) |
Using the above equations in (7), (13), (19), (25), (30) and (35), The expressions for MTSF, availability, busy period analysis of the server due to repair, busy period analysis of the server due to preventive maintenance, expected number of repairs, expected number of preventive maintenances and finally the profit function is obtained by taking particular values of the parameters.
14 Numerical and Graphical Representation Of Different Reliability Measures
To study the behaviour of considered system, Numerical and graphical representations of MTSF, Availability and Profit Function for some particular values of the parameters are given below:
The reliability measures are presented in the following tables and graphs:
Table 1 MTSF vs constant failure rate (, repair rate (), constant maintenance rate (), preventive maintenance rate (), rest completion rate ()
| 0.1 | 0.963764 | 0.963764 | 0.973705 | 1.00671 | 0.96467339 |
| 0.2 | 0.920564 | 0.920564 | 0.929497 | 0.959836 | 0.92219172 |
| 0.3 | 0.880995 | 0.880995 | 0.889056 | 0.917041 | 0.88319088 |
| 0.4 | 0.844626 | 0.844626 | 0.851927 | 0.877823 | 0.84726784 |
| 0.5 | 0.811087 | 0.811087 | 0.817724 | 0.841759 | 0.81407867 |
| 0.6 | 0.780066 | 0.780066 | 0.786119 | 0.808487 | 0.78332822 |
| 0.7 | 0.751293 | 0.751293 | 0.75683 | 0.777699 | 0.75476179 |
| 0.8 | 0.724534 | 0.724534 | 0.729614 | 0.749132 | 0.72815856 |
| 0.9 | 0.699588 | 0.699588 | 0.704261 | 0.722556 | 0.70332613 |
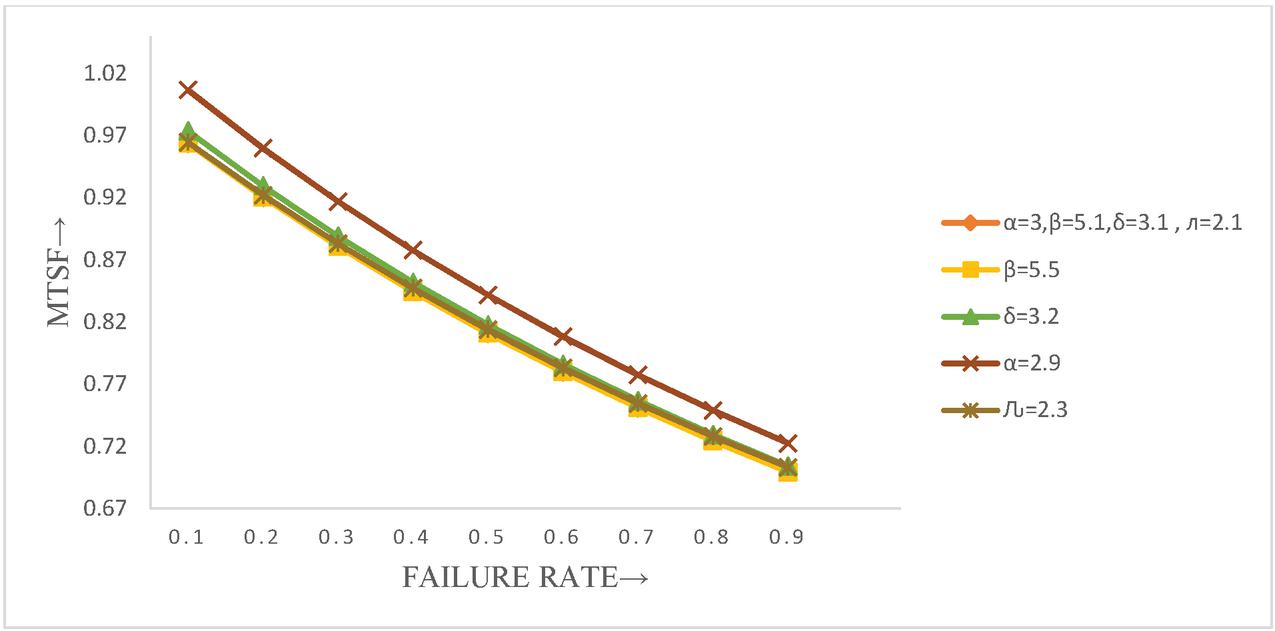
Figure 2 MTSF vs constant failure rate (, repair rate (), constant maintenance rate (), preventive maintenance rate (), rest completion rate ().
Table 2 Availability vs constant failure rate (, repair rate , constant maintenance rate (), preventive maintenance rate (), rest completion rate ()
| 0.1 | 0.662463 | 0.662532 | 0.67267985 | 0.67326055 | 0.66346589 |
| 0.2 | 0.646351 | 0.646608 | 0.65632614 | 0.65681518 | 0.64845399 |
| 0.3 | 0.629478 | 0.630011 | 0.63916289 | 0.6395808 | 0.63272461 |
| 0.4 | 0.612086 | 0.612959 | 0.62144541 | 0.62180687 | 0.61647982 |
| 0.5 | 0.594385 | 0.595642 | 0.60339453 | 0.60370975 | 0.59989823 |
| 0.6 | 0.576555 | 0.578221 | 0.58519833 | 0.58547418 | 0.58313542 |
| 0.7 | 0.558746 | 0.560832 | 0.56701458 | 0.56725556 | 0.56632515 |
| 0.8 | 0.541082 | 0.543588 | 0.54897357 | 0.54918247 | 0.54958074 |
| 0.9 | 0.523664 | 0.52658 | 0.53118107 | 0.53135957 | 0.53299689 |
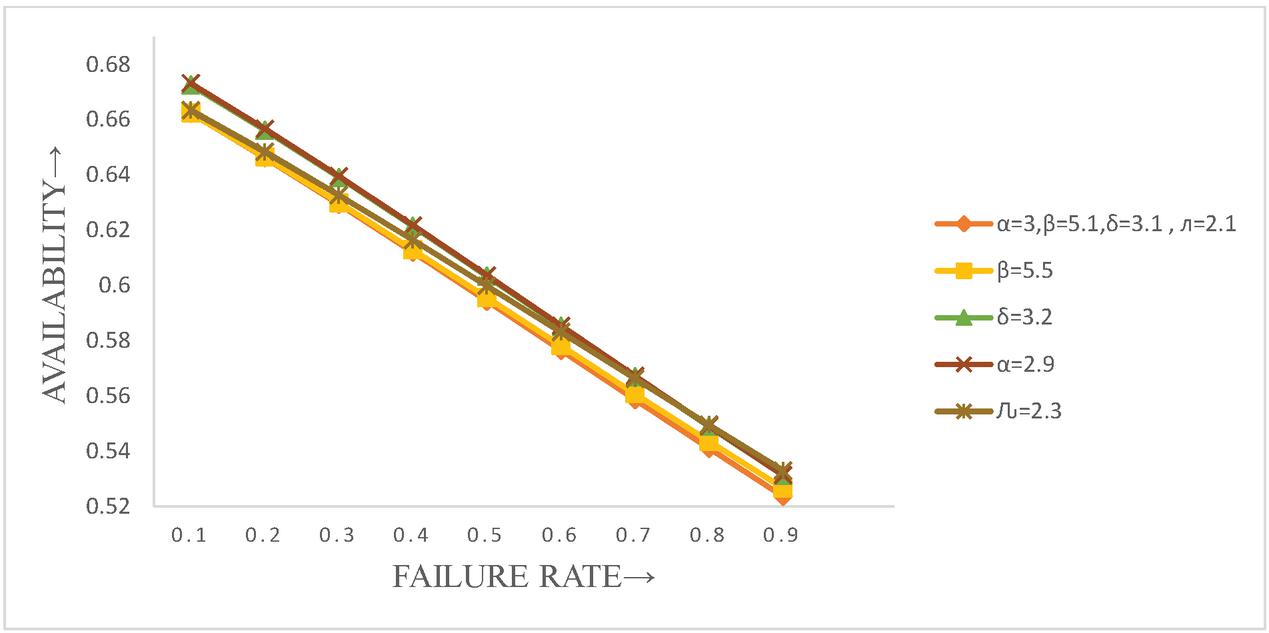
Figure 3 Availability MTSF vs constant failure rate (, repair rate , constant maintenance rate (), preventive maintenance rate (), rest completion rate ().
Table 3 Profit analysis vs constant failure rate (, repair rate , constant maintenance rate (), preventive maintenance rate (), rest completion rate ()
| Let and | |||||
| 0.1 | 7411.316 | 7408.477 | 7531.168 | 7608.732 | 7456.974 |
| 0.2 | 6590.387 | 6579.506 | 6702.449 | 6786.38 | 6686.794 |
| 0.3 | 5695.93 | 5672.399 | 5798.063 | 5893.162 | 5844.286 |
| 0.4 | 4751.857 | 4711.563 | 4842.563 | 4952.539 | 4950.468 |
| 0.5 | 3778.124 | 3717.388 | 3856.448 | 3984.092 | 4023.238 |
| 0.6 | 2791.163 | 2706.715 | 2856.604 | 3003.941 | 3077.652 |
| 0.7 | 1804.313 | 1693.277 | 1856.737 | 2025.163 | 2126.224 |
| 0.8 | 828.2337 | 688.1128 | 867.7929 | 1058.193 | 1179.211 |
| 0.9 | -128.713 | -300.041 | -101.645 | 111.1986 | 244.8994 |
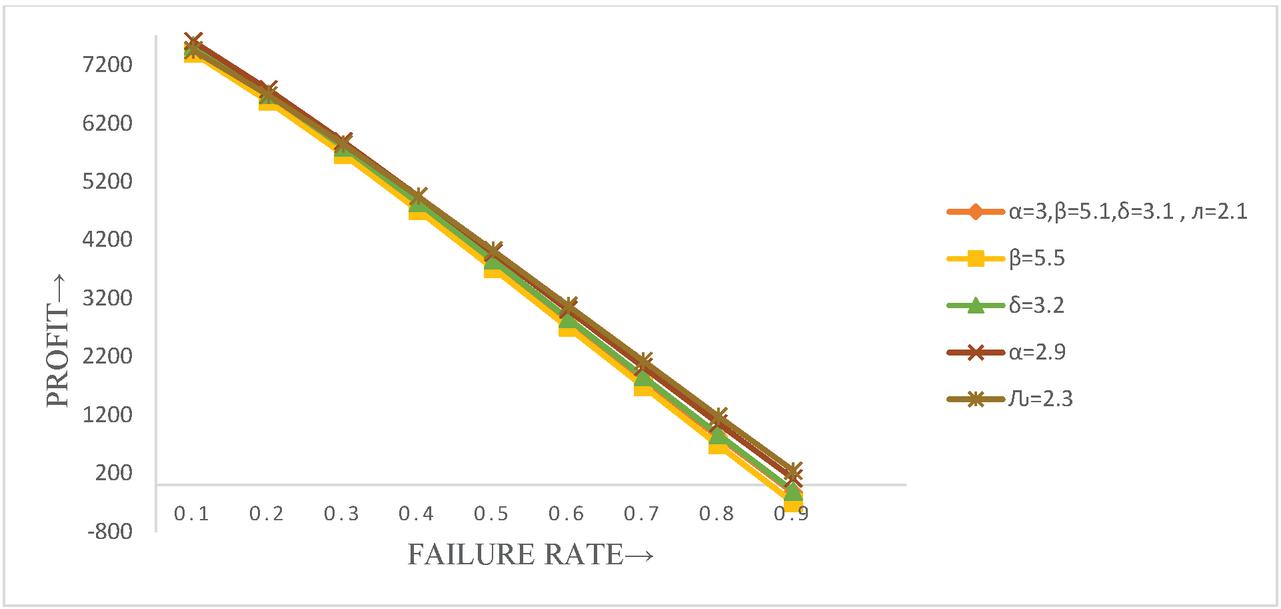
Figure 4 Profit analysis vs constant failure rate (, repair rate , constant maintenance rate (), preventive maintenance rate (), rest completion rate () .
15 Real Life Application
The computer system can be considered as an example of the present work. In any workstation, suppose there is a full time need of computer system. Then we can have two computer systems, one is operative and other is kept as spare in cold standby in order to cover the risk or any emergency requirement. It is a matter of fact that every electronic system needs preventive maintenance after some specific period of operation. And, system will get repaired only when it completely fails. If, there is only a single server who immediately visits the workstation whenever needed, then if both operations preventive maintenance and repair of the computer system required at a time. Then server can give priority to preventive maintenance over repair. As maintenance requires less time and energy of the server and the computer system can be used again after maintenance. And, server does not need any rest after preventive maintenance. If both the computer systems fail, then after repairing one system, the server needs a rest to regain his energy for repairing the other unit of the system. After taking some rest, the server can do the assigned job of repairing the other system continuously with same enthusiasm.
16 Discussion and Conclusion
Here, in a two-unit cold standby system, the concept of rest of the server after each repair is implemented. The concept of preventive maintenance is also considered after specific period of operation. There is a single server who visits the system immediately whenever needed. Priority is given to preventive maintenances over repairs. The reliability traits MTSF, availability and eventually the profit function are obtained for arbitrary parameter values. It is noted that the mean time to system failure and system model availability continue to decrease with the increase in the unit’s failure rate, although their values continue to increase with the increase in the repair rate and the rate at which the server accomplishes the rest. The profit function of the system model also follows the same pattern for . Consequently, a system which provides the rest to the server between repair works can only make the system consistent and financially beneficial to use by increasing the rest completion rate of the server (may be called a technician). In Tables 1–3 and Figures 2–4, the findings of these measures are described numerically and graphically.
References
[1] Goel, L.R. and Shrivastava, P. (1991): A Two Unit Cold Standby System with Three Modes and Correlated Failures and Repairs, Microelectronics Reliability, Vol. 31(5), pp. 835–840.
[2] Gupta, R., Chaudhary, P. and Kumar D. (2007): Stochastic Analysis of a Two Unit Cold Standby System with Different Operative Modes and Different Repair Policies, International Journal of Agriculture Statistics Sciences, Vol. 3(2), pp. 387–394.
[3] Kumar, P. and Gupta, R. (2007). Reliability Analysis of a Single Unit M|G|1 System Model with Helping Unit. Journal of Combinatorics Information& System Sciences, Vol. 32, No. 1–4, pp. 209–219.
[4] Wu, Q. and Wu, S. (2011): Reliability Analysis of Two Unit Cold Standby Repairable Systems under Poisson Shocks, Applied Mathematics and Computation, Vol. 218(1), pp. 171–182.
[5] Wang, C., Xing, L. and Amari, S.V. (2012): A Fast Approximation Method for Reliability Analysis of Cold Standby Systems, Reliability Engineering & System Safety, Vol. 106, pp. 119–126.
[6] Kumar, D. and Singh, S.B. (2016): Stochastic Analysis of Complex Repairable System with Deliberate Failure Emphasizing Reboot Delay, Communications in Statistics – Simulation and Computation, Vol. 45(2), pp. 583–602.
[7] Lado, A.K., Singh, V.V., Ismail, K.H. and Ibrahim, Y. (2018): Performance and Cost Assessment of Repairable Complex System with Two Subsystems Connected in Series Configuration, International Journal of Reliability and Applications, Vol. 19(1), pp. 27–42.
[8] Goel, M. and Kumar, J. (2018): Stochastic Analysis of a Two Unit Cold Standby System with Preventive Maintenance and General Distribution of all Random Variables, International Journal of Statistics and Reliability Engineering, Vol. 5(1), pp. 10–21.
[9] Barak, M.S., Yadav D. and Barak S. (2018): Stochastic Analysis of two-unit Redundant System with Priority to Inspection over Repair, Life Cycle Reliability and Safety Engineering, Vol. 7, pp. 71–79.
[10] Kumar, A., Pawar, D. and Malik, S.C. (2019): Profit Analysis of a Warm Standby Non-Identical Units System with Single Server Subject to Preventive Maintenance. International Journal of Agricultural and Statistical Sciences, Vol. 15(1), pp. 261–269.
[11] Shinde, V., Biniwale, D. and Bharadwaj, S.K. (2019): Availability Analysis for Estimation of Repair Rate of Performance based Logistics under Operating Conditions, Journal of Reliability and Statistical Studies, Vol. 12(1), pp. 65–78.
[12] Lado, A.K. and Singh, V.V. (2019): Cost Assessment of Complex Repairable System consisting Two Subsystems in Series Configuration using Gumbel Hougaard family copula, International Journal of Quality Reliability and Management, Vol. 36(10), pp. 1683–1698.
[13] Aggarwal, C. and Malik, S.C. (2020): A Standby Repairable System with Rest of Server between Repairs, Journal of Statistics and Management Systems (online).
[14] Singh, V.V., Poonia, P.K. and Adbullahi, A.H. (2020): Performance Analysis of a Complex Repairable System with Two Subsystems in Series Configuration with an Imperfect Switch, Journal of Mathematical and Computational Science, Vol. 10(2), pp. 359–383.
[15] Raghav, D., Pooni, P.K., Gahlot, M., Singh, V.V., Ayagi, H.I. and Abdullahi, A.H. (2020): Probabilistic Analysis of a System Consisting of Two Subsystems in the Series Configuration under Copula Repair Approach, Journal of Korean Society of Mathematical Educational. Ser. B: The Pure and Applied Mathematics, Vol. 27(3), pp. 137–155.
Biographies

Chhama Aggarwal is a Ph.D. student at the Department of Statistics in Maharshi Dayanand University since October, 2018. She received her B.Sc. (H) Mathematics and M.Sc. in Mathematics degrees from University of Delhi, Delhi.

Nitika Ahlawat is a Ph.D. student at the Department of Statistics in Maharshi Dayanand University since December, 2019. She received her B.A. in Mathematics and Statistics and M.Sc. in Statistics degrees from M.D. University, Rohtak (Haryana).

S. C. Malik is presently working as Professor & Head, Department of Statistics, M.D. University, Rohtak (Haryana). His field of research specialization are Reliability Theory, Sampling and Applied Statistics. He has a long research and teaching experience in subject of Statistics. He has supervised 40 Ph.D. students in the fields of reliability theory, sampling theory and applied statistics. Dr. Malik has been invited by various academic institutions to deliver talks and to present research papers at conferences/seminars/symposiums/workshops held in India and abroad including USA, UK, Portugal, Singapore, Germany, Hong-Kong, France, Spain, Netherland, Belgium, Austria, Italy, Japan, Switzerland and Nepal. He is reviewer of various journals specifically for the journals in the areas of Reliability, Operations Research and Statistics. Prof. Malik has been a member/life member of various academic/professional bodies. He is a founder President of Indian Association for Reliability and Statistics (IARS) and also Chief Editor of the UGC listed journal IJSRE being published by IARS.
Journal of Reliability and Statistical Studies, Vol. 14, Issue 1 (2021), 57–80.
doi: 10.13052/jrss0974-8024.1414
© 2021 River Publishers