Algebraic and Geometric Basis of Principal Components: An Overview
Pramit Pandit*, K. N. Krishnamurthy and K. B. Murthy
Department of Agricultural Statistics, Applied Mathematics and Computer Science, University of Agricultural Sciences, Bengaluru, Karnataka, India
E-mail: pramitpandit@gmail.com; kkmurthy13@gmail.com; kbmurthy2005@gmail.com
*Corresponding Author
Received 21 May 2019; Accepted 10 June 2020; Publication 13 October 2020
Abstract
Principal Component Analysis is considered as a dimension-reduction tool which may be used to reduce a large set of possibly correlated variables to hopefully a smaller set of uncorrelated variables that still accounts for most of the variation of the original large set. To understand the inner constructs of principal components, concepts of algebraic as well as geometric basis of principal components are prerequisites. Hence, in the current study, an attempt has been made to provide a step by step and vivid discussion of the basis of principle components and its various important properties.
Keywords: Algebraic basis, basis of principal components, geometric basis, principal components, properties of principal components.
1 Introduction
Principal component analysis (PCA) is a statistical method in which an orthogonal transformation is used to convert a set of observations of possibly correlated variables into a (hopefully, smaller) set of observations of linearly uncorrelated variables, called principal components (Jackson, 1991; Harris, 2001). The method of principal components was given by Karl Pearson in the year of 1901 (Pearson, 1901), however the general procedure being used nowadays is due to Harold Hotelling, whose pioneering paper showed up later in 1933 (Hotelling, 1933). This transformation is defined such that the first principal component has the largest possible variance and accounts for as much of the variability present in the original data as possible (Anderson, 2003; Johnson and Wichern, 2007). Each succeeding principal component in turn has the next highest possible variance under the constraint that it is orthogonal to the preceding principal component(s) so that the resulting vectors become an uncorrelated orthogonal basis set (Hardle and Simar, 2014). In regression analysis, a test without principal component analysis may be ineffective or even impossible if the number of independent variables is large compared to the number of observations (Timm, 2002). Besides, substantially higher correlations among the independent variables may lead to unstable estimates of regression coefficients (Gujarati et al., 2011). In such cases, these variables can be reduced to a smaller number of principal components resulting in a better test or more stable estimates of regression coefficients (Rencher, 2012). In case of MANOVA, if p (number of dimensions) is close to (error degrees of freedom) so that a test has a low power, or that, , making the determinants of Wilks’ negative, the dependent variables should be substituted with a smaller number of principal components in order to carry out the analysis (Rencher, 2012). In addition to these applications, depending on the fields, it is analogous to the discrete Karhunen–Loève transform in signal processing (Ahmed et al., 1974), proper orthogonal decomposition in mechanical engineering (Chatterjee, 2000), singular value decomposition in linear algebra (Bunch and Nielsen, 1978), Eckart–Young theorem in psychometrics (Johnson, 1963), empirical orthogonal functions in meteorological sciences (Hannachi et al., 2007) and so on. It should be noted that in the term principal components, the adjective ‘principal’ is used to describe the kind of components – main, primary, fundamental, major, and so on. The noun ‘principal’ as a modifier for components, is not used (Rencher, 2012). To understand the inner constructs of principal components, concepts of algebraic as well as geometric basis of principal components are prerequisites. Hence, in the current study, an attempt has been made to provide a step by step and vivid discussion of the basis of principle components and its various importantproperties.
2 Algebraic Basis of Principal Components
Let be an n-dimensional vector of variables and n is assumed to be very large. Now the interest is emphasized on reducing this n number of variables (may be correlated) into m () number of uncorrelated variables (Rencher, 2012).
In other words, (n-m) number of variables have to be deleted in order to decrease redundancy. Now, if the first m number of variables are kept by eliminating the last (n-m) number of variables, it will contribute sufficient increase in error sum of squares, as here, the condition is not ascertained. So, to ensure the condition transformation of vector is obvious. Now, a way of transformation of the vector has to be thought of in such a way that the aforesaid variability condition is ascertained to ensure minimum increase in error sum of squares if the last (n-m) variables are eliminated. In other words, the objective of this transformation is to maximise the decrease of variance so that the last (n-m) number of variables can be easily chopped off.
First of all, let be an n-dimensional unit vector. So, by definition, Euclidian norm of vector, .
Now, a projection of vector onto the n-dimensional unit vector has been made.
Projection of onto , (Stark and Yang, 1998), which is subjected to .
Again, , where S is the sample variance-covariance matrix of variables of vector. This matrix S is beyond researchers’ control. So what can be done is that this n-dimensional unit vector can be utilised as a search to get the desired form.
Let variance probe,
| (1) |
Now, as a corollary to Rolle’s Mean Value theorem (Riedel and Sahoo, 1998), for a very small change , can be approximated to , i.e.
| (2) |
From (1),
| (3) | |||
(As the quantity is infinitely small)
Putting the value of (1) and (3) in (2),
Or,
| (4) |
Now, as is an unit vector, even after perturbation, also remains as an unit vector.
Squaring both sides, it can be obtained that
Or,
Or,
Or,
| (5) |
(As the quantity is infinitely small and for being an unit vector).
Now, using Lagrangian multiplier (Bertsekas, 2014), from (4) and (5),
Or,
As this is certainly a non-zero quantity, so
Or,
| (6) |
where I is nxn identity matrix.
Now, this Equation (6) is a well-known form in linear algebra (Zhang, 2011), more specifically in matrix theory, where is the eigen value of S matrix and is the corresponding eigen vector (Searle and Khuri, 2017). As S is a square matrix of order n, there will be n number of eigen values and n corresponding eigen vectors. Arranging eigen values in the decreasing order (i.e. , it can be obtained (Johnstone, 2001),
| (7) |
Now, two matrices Q and are defined as and , respectively. Compacting the n number of Equations (7) in a single equation, it can be obtained,
| (8) |
Again, are eigen vectors of S matrix. As variance-covariance matrix S is a symmetric matrix, its eigen vectors are orthogonal to each other. Hence, matrix Q, consisting of n-orthogonal eigen vectors, is an orthogonal matrix, satisfying
and
Pre-multiplying to both the sides of (8),
| (9) |
and an expanded form of this Equation (9) will be
| (10) | ||
As the left hand side of the Equation (9) is similar to the Equation (1) as mentioned earlier, Variance-Covariance matrix of transformed vector C will be,
| (11) |
From equality property of matrices (Aitken, 2016), the following properties can be obtained,
| (12) |
| (13) |
and
| (14) |
3 Geometric Basis of Principal Component
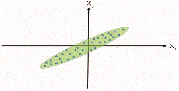
Suppose for 2 variables and , the following scatterplot has been obtained (Figure 1).
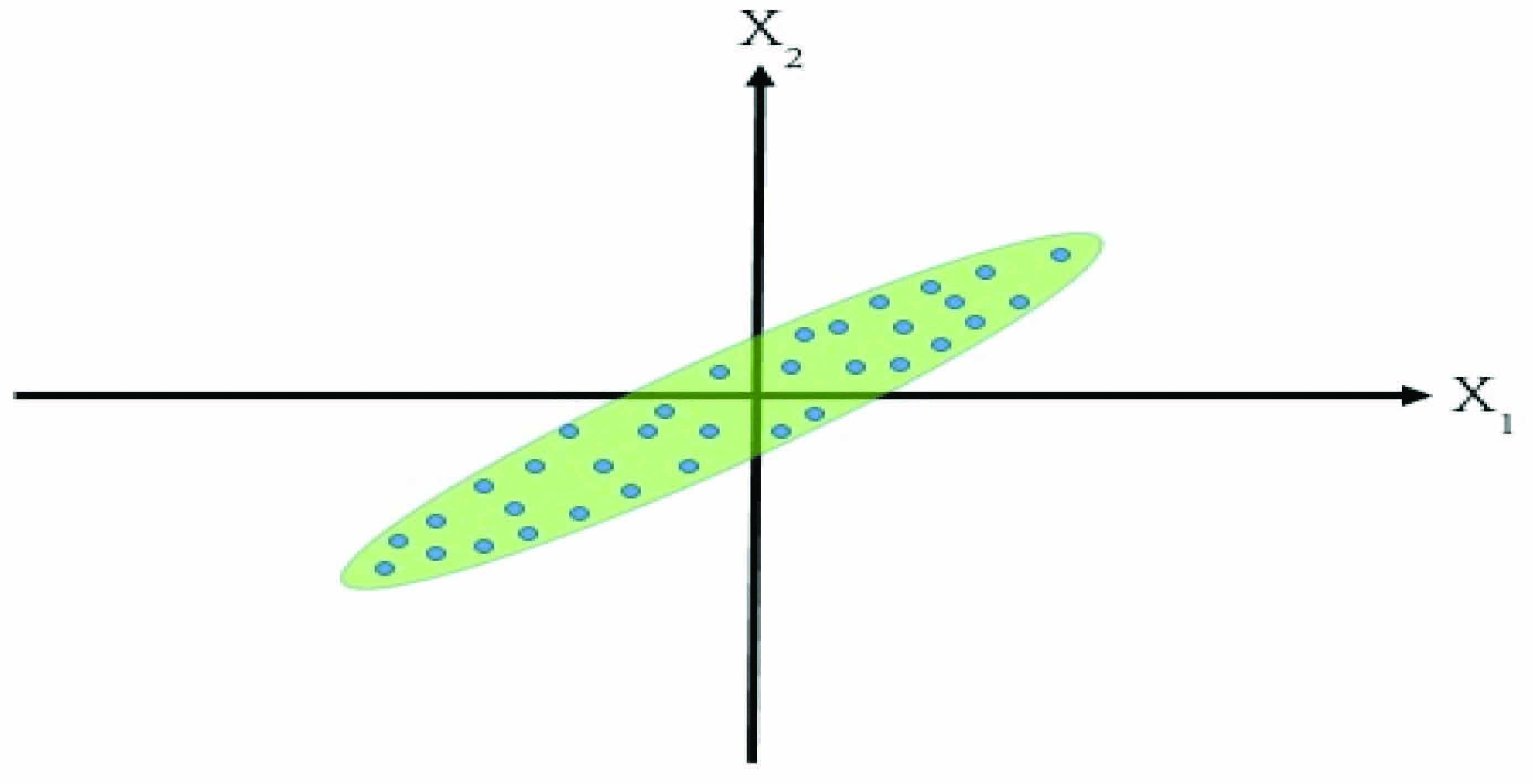
Figure 1 Scatterplot of X and X variable.
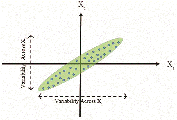
Now, from the scatterplot (Figure 1), it can be clearly understood that and are highly correlated. It can also be observed that variability across is higher than variability across , however both are substantial values (Figure 2).
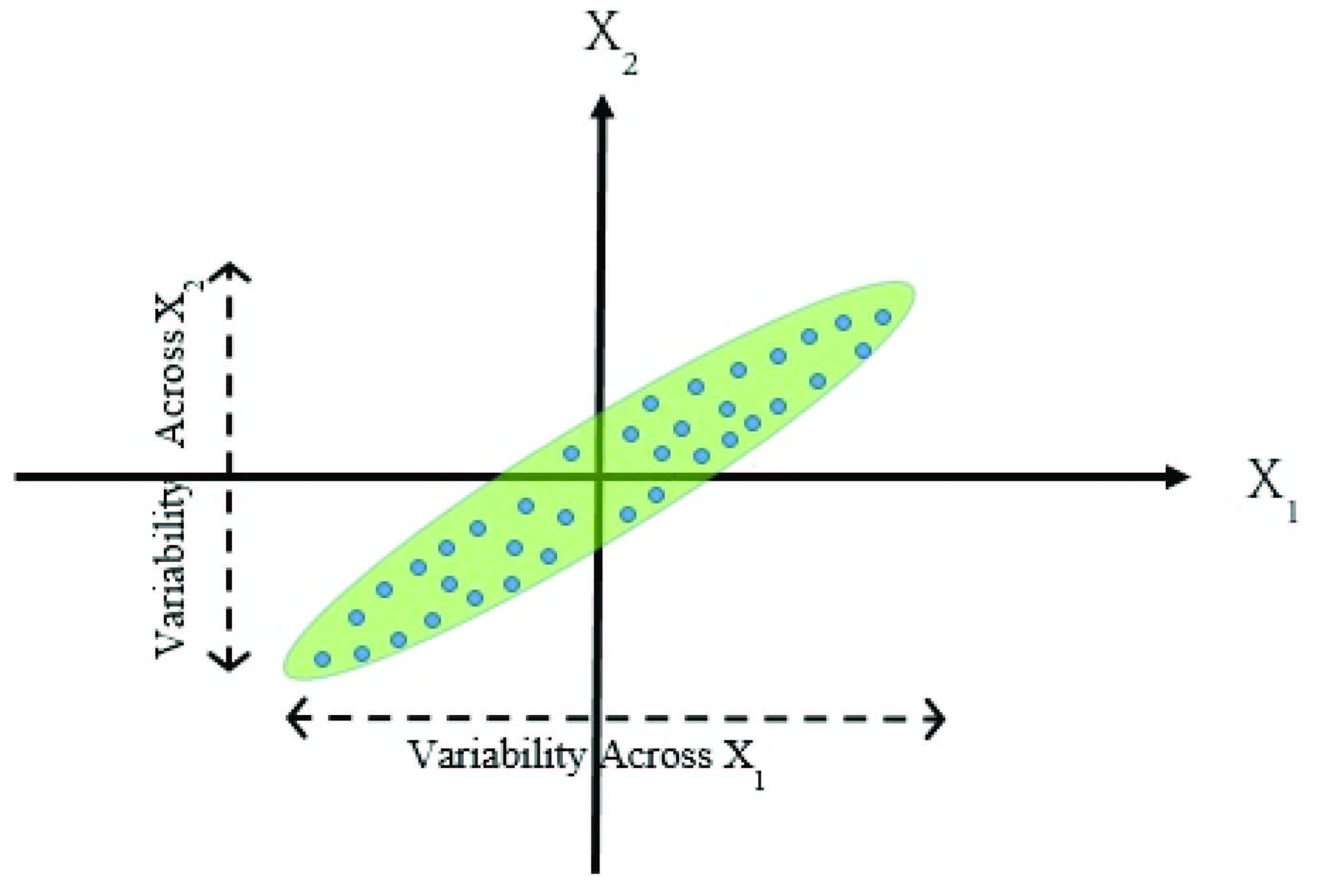
Figure 2 Variability across X and X axis in the scatterplot.
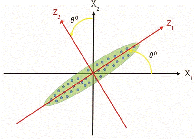
Keeping the origin rigid, if the axes are rotated anti-clockwise (Figure 3), the rotation will yield , as new axes (Eisenhart, 2005).
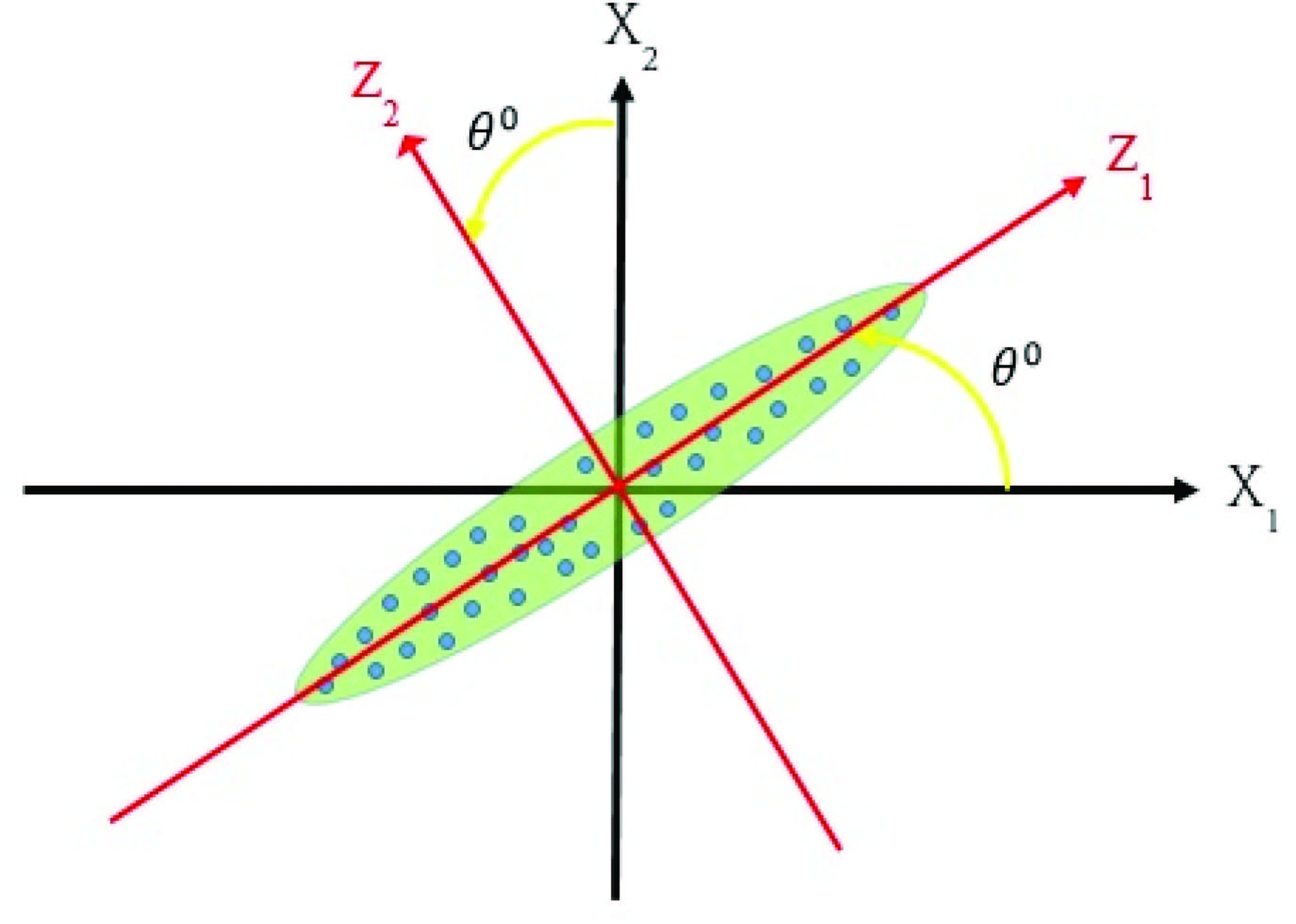
Figure 3 Rotated scatterplot of X and X variable.
After rotation, it can be seen that variability across is much higher than . In addition to that, and are observed to be almost independent. Now, if , then dimension alone will be able to provide sufficient information as much as available in the original data set.
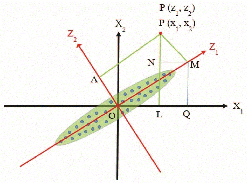
Now, a particular point P is considered, whose coordinate is (, ) in plane and (, ) in plane (Figure 4). From P, perpendicular lines PM and PA have been drawn on axis and axis respectively. From P, another perpendicular line PL has been drawn on axis. From the point M, two perpendicular line MQ and MN have been drawn on axis and PL line, respectively.
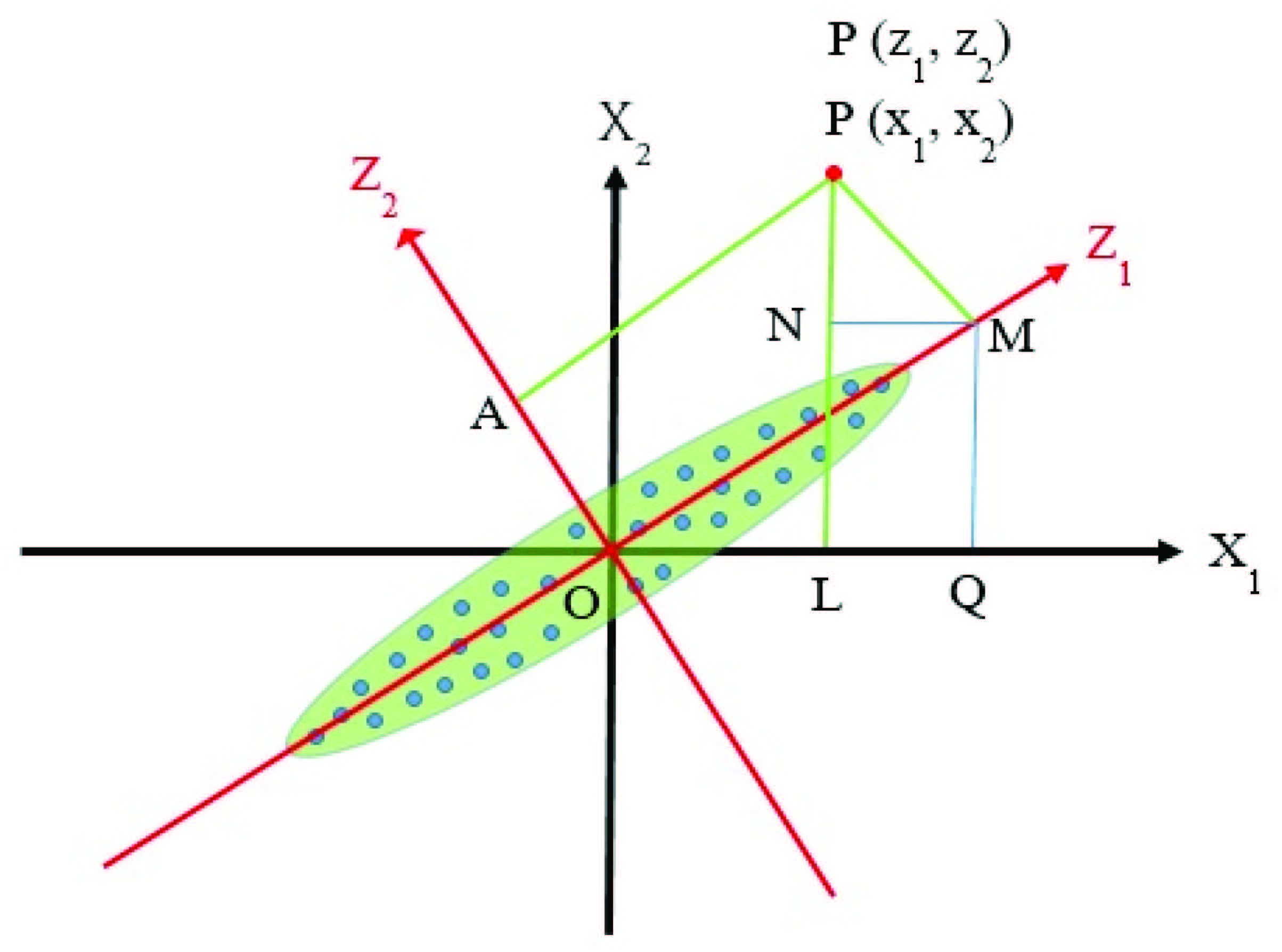
Figure 4 Coordinates of point P with respect to unrotated and rotated axes.
Now,
Again,
| (15) | |||
(From OMQ and PMN respectively)
and
| (16) | |||
(From PMN and OMQ respectively)
Solving Equation no. (15) and (16), it can be obtained,
In matrix form, which can be rewritten as (Aitken, 2016),
Or,
Or,
Where,
So, it can be observed that ’s are unit vectors and i.e. transformation matrix A is an orthogonal matrix. Similarly, for n number of variables also, this can be generalised as,
, subjected to the condition .
As the ultimate objective of this transformation is to maximise the decrease of variance in such a manner that the last few number of variables can be easily chopped off, maximisation of is required subjected to the condition, .
Now,
here, S is the sample dispersion matrix of variables.
In other words, maximisation of is needed to be subjected to the condition,
Using Lagrangian multiplier, a function has been defined as,
Partially differentiating L with respect to and equating it to zero, it can be obtained,
Or,
Or,
| (17) |
Equation (17) is similar to the Equation (6) mentioned earlier, from which in the same fashion, the same results can be obtained,
(i) ,
(ii)
(iii)
and
(iv) proportion of variability explained by .
4 Conclusion
In this study, both algebraic and geometric basis of principal components have been discussed thoroughly, which may considerably help in understanding the inner constructs of principal components. From both the approaches, it has been found that eigen values and elements of the corresponding eigen vectors of sample dispersion matrix are the variances and the coefficients of the original variables, respectively, of the corresponding newly formed principal components.
References
Ahmed, N., Natarajan, T. and Rao, K.R. (1974). Discrete cosine transform, IEEE Transactions on Computers, 23(1), pp. 90–93.
Aitken, A.C. (2016). Determinants and Matrices, Brousson, Read BooksLtd.
Anderson, T.W. (2003). An Introduction to Multivariate Statistical Analysis (3 Edition), New Jersey, John Wiley & Sons.
Bertsekas, D.P. (2014). Constrained Optimization and Lagrange Multiplier Methods, New York, Academic Press Inc.
Bunch, J.R. and Nielsen, C.P. (1978). Updating the singular value decomposition, Numerische Mathematik, 31(2), pp. 111–129.
Chatterjee, A. (2000). An introduction to the proper orthogonal decomposition, Current Science, 78(7), pp. 808–817.
Eisenhart, L.P. (2005). Coordinate Geometry, USA, Dover Publications Inc.
Gujarati, D.N., Porter, D.C. and Gunasekar, S. (2011). Basic Econometrics, New York, McGraw-Hill.
Hannachi, A., Jolliffe, I.T. and Stephenson, D.B. (2007). Empirical orthogonal functions and related techniques in atmospheric science: a review, International Journal of Climatology, 27, pp. 1119–1152.
Hardle, W.K. and Simar L. (2014). Applied Multivariate Statistical Analysis (4th Edition), New York, Springer-Verlag New York, Inc.
Harris, R.J. (2001). A Primer of Multivariate Statistics (3 Edition). Mahwah, Lawrence Erlbaum Associates, Inc., Publishers.
Hotelling, H. (1933). Analysis of a complex of statistical variables into principal components, Journal of Educational Psychology, 24,pp. 417–441.
Jackson, J.E. (1991). A User’s Guide to Principal Components, New Jersey, John Wiley & Sons, Inc.
Johnson, R.A. and Wichern, D.W. (2007). Applied Multivariate Statistical Analysis. Upper Saddle River, New Jersey, Pearson Education, Inc.
Johnson, R.M. (1963). On a theorem stated by Eckart and Young, Psychometrika, 28(3), pp. 259–263.
Johnstone, I.M. (2001). On the distribution of the largest eigenvalue in principal components analysis, The Annals of Statistics, 29(2),pp. 295–327.
Pearson, K. (1901). On lines and planes of closest fit to systems of points in space, Philosophical Magazines, 2, pp. 559–572.
Rencher, A.C. (2012). Methods of Multivariate Analysis (3 Edition), New Jersey, John Wiley & Sons.
Riedel, T. and Sahoo, P.K. (1998). Mean Value Theorems and Functional Equations, Singapore, World Scientific Publishing Co. Pte. Ltd.
Searle, S.R. and Khuri, A.I. (2017). Matrix Algebra Useful for Statistics (2 Edition), New Jersey, John Wiley & Sons, Inc.
Stark, H. and Yang, Y. (1998). Vector Space Projections: A Numerical Approach to Signal and Image Processing, Neural Nets, and optics, New York, John Wiley & Sons, Inc.
Timm, N.H. (2002). Applied Multivariate Analysis. New York, Springer-Verlag New York, Inc.
Zhang, F. (2011). Matrix Theory: Basic Results and Techniques (2nd Edition), New York, Springer Science & Business Media.
Biographies

Pramit Pandit obtained his Bachelor’s degree (Hons.) in Agriculture from Uttar Banga Krishi Viswavidyalaya and Master’s (Ag.) majoring in Agricultural Statistics from University of Agricultural Sciences, Bengaluru. He was the recipient of ICAR-Junior Research Fellowship during his Master’s degree programme for securing All India basis 2nd rank in AIEEA-UG-2016 examination in Statistical Sciences. He also secured All India basis 1st rank in AICE-JRF/SRF(PGS)-2018 in Agricultural Statistics and qualified ICAR-NET-2018. He was awarded with the prestigious UAS Gold Medal 2019 along with the Professor G. Gurumurthy Memorial Gold Medal, Sri Godabanahal Thuppamma Basappa Mallikarjuna Gold Medal and Sri Nijalingappa’s 77th Birthday Commemoration Gold Medal for his exemplary academic excellence. He was also the recipient of best ‘Best M.Sc. Thesis Award’ for his research work on, ‘Statistical Models for Insect Count Data On Rice’, conducted under the supervision of Prof. K. N. Krishnamurthy.

K. N. Krishnamurthy received his B.Sc., M.Sc. and M.Phil. degrees in Statistics from Bangalore University and Ph.D. degree in Statistics from Himalayan University. Prof. Krishnamurthy is a recipient of the Best Teacher award from the National Institute for Education & Research, New Delhi during 2017. He is currently working as Head of the department as well as University Head of the Department of Agricultural Statistics, Applied Mathematics & Computer Science, University of Agricultural Sciences, GKVK, Bengaluru. He has 38 years of experience in teaching at the University.

K. B. Murthy received his B.Sc. and M.Sc. degrees in Mathematics from Mysore University and Ph.D. degree in Mathematics from Himalayan University. He has specialised in graph theory and applied sciences and has a teaching experience of over 25 years. He has published many papers in National and International Journals and also participated in many International conferences. He is a member of Board of Studies of University of Agricultural Sciences, GKVK, Bengaluru. Dr. K. B. Murthy is the recipient of the GAURAVACHARYA-2017 award for the significant contribution in the field of graph theory and education from National Institute for Education and Research, New Delhi.
Journal of Reliability and Statistical Studies, Vol. 13_1, 73–86.
doi: 10.13052/jrss0974-8024.1314
© 2020 River Publishers