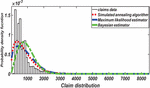
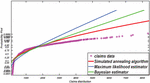
A Bayesian Approach to Weibull Distribution with Application to Insurance Claims Data
Hamza Abubakar1, 2,* and Shamsul Rijal Muhammad Sabri1
1School of Mathematical Sciences, University of Science Malaysia, Malaysia
2Department of Mathematics, Isa Kaita College of Education, Dutsin-Ma, Katsina, Nigeria
E-mail: zeeham4u2c@yahoo.com
*Corresponding Author
Received 07 March 2023; Accepted 12 April 2023; Publication 06 May 2023
Abstract
Statistical distributions are of great interest for actuaries in modelling and fitting the distribution of various data sets. It can be used to present a description of risk exposure on the investment, where the level of exposure to the risk can be determined by “key risk indicators” that usually are functions of the statistical model. Financial mathematicians and actuarial scientists often use such key risk indicators to determine the degree to which a particular company is subject to certain aspects of risk, which arise from changes in underlying variables such as prices of equity, interest rates fluctuations, or exchange rates. Weibull distribution is one of the most popular statistical distribution models employed by the actuarial and financial risk management problems in fitting and or in modelling the behaviours of financial data or lifetime event data to forecast stock pricing movement or uncertainly prediction. In this study, a Bayesian approach to the Weibull distribution model on the assumption of gamma prior to Weibull distribution parameters has been proposed. A computational study based on the actuarial measures is conducted, proving the proposed distribution of the claim amount. Along this line, in assessing the performance of the proposed method, the results of the simulations study have been conducted to explore the efficiency of the proposed estimators is compared to a maximum likelihood (MLE) and simulated annealing algorithm (SA). Finally, an actuarial real data set is analyzed, proving that the proposed model can be used effectively to model insurance claim data.
Keywords: Weibull distribution, Bayesian method, simulated annealing, maximum likelihood Insurance claim, actuarial measures.
Introduction
The effective and efficient modelling of uncertain events such as stock pricing movement, uncertainly prediction in market demand for a specific commodity and insurance claims has always been one of the most researched topics in business, finance and economics. As a result, determining the proper statistical distribution is a critical task for accurate data representation. In actuarial sciences, the selection of appropriate statistical distribution for modelling of uncertainty, forecasting, and prediction of insurance claims amount has been crucially significant to the actuarial scientist is to evaluate the exposure to market risk in a portfolio of instruments. As a result, the substantial size of the relevant studies on various statistical distribution for accurate forecasting has been conducted for many years. This includes some early work by (Ter Berg, 1980) on the Gamma and Poisson distribution models. Following the early work of (Ter Berg, 1980) was the study by (Willmot, 1987, 1988) on the distribution of insurance data based on the Poisson inverse Gaussian distribution framework, the Delaporte distribution (Willmot and Sundt, 1989), The generalized version of a Poisson distribution (Kumar and Nair, 2016), the Poisson-Goncharov distribution (Denuit, 1997) and on approximations for aggregate claim distributions (Dhaene and Sundt, 1997; Hipp, 1986). Recently, a lot of researches have conducted on the insurance claims distribution using various mathematical and statistical distribution models such as Aggregate Claims Amount Probability Distributions (Goffard et al., 2017), modelling of the Severity and Frequency of Auto Insurance Claims based on statistical distributions (Omari et al., 2018), claim distribution with some characterizations and applications to insurance claim amount estimation has been discussed in (Ahmad et al., 2020), insurance risk computation via Monte Carlo approach has been presented in (Bar-Lev and Ridder, 2019), a positive-valued insurance claim was modelled based on theoretical Bayesian approach data with outliers (Okhli and Jabbari Nooghabi, 2021), insurance claims data was modelled using new poisson mixed weighted Lindley distribution in (Atikankul et al., 2020). insurance and actuarial sciences, claims amount modelling has been heavily promoted via the Bayesian approach in the outstanding insurance claims amount (Fuzi et al., 2016; Hong and Martin, 2017; Katsis and Ntzoufras, 2005; Moumeesri et al., 2020; Ntzoufras et al., 2005; Peters et al., 2017; Zhang et al., 2012). Modified Weibull distribution for internal rate of return modelling (Abubakar, 2021; Abubakar and Sabri, 2021). Most of these studies have been predominantly limited to posterior parameter estimation utilizing primarily the distribution, rather than testing distribution hypotheses or estimating insurance claims uncertainties.
According to industrial statistics, insurance companies have grown significantly over the years, and the demand for insurance plans for their businesses and households is overwhelming (Boland, 2007; Kazemi et al., 2017; Wuthrich, 2013; Zhao et al., 2021). To that end, insurance companies are realigning themselves to meet changing their basic requirements such as insurance plans and requirements, risk reduction and investments, and claim payment demands. Given that every policyholder anticipates a cushion in the event of economic loss as specified in an insurance contract, the task of meeting the repayment schedule becomes a major concern for the insurer. The best estimate of the insurance expected claim allows decisions on the investment portfolio and claim reimbursement to be made without much error, thereby rising above the aforementioned challenges. The goal of this study is to investigate probability models based on the Weibull distribution for modelling a variety of insurance claims. The main objective of the study is to explore the Bayesian approach to Weibull distribution on the assumption of gamma prior to the shape parameter. The purpose is to model adequately the number of claims occurring under insurance policies to estimate the expected number of claims. To the best of the author’s knowledge, the insurance claim data has not been modeled on the assumption of Weibull distribution with shape parameters following gamma prior distribution. The specific objectives of the study are to (i) construct an insurance claims model on the assumption of Weibull distribution with shape parameter following a gamma distribution; (ii) apply Bayesian model framework to estimate the parameter of the model developed in (i); (iii) compare the performance of Bayesian estimator with maximum likelihood method and simulated annealing algorithm based on the number of insurance claims data.
The rest of this paper is structured as follows. In Section 2, materials and methods including the Weibull distribution model, likelihood function, Bayesian estimation method, prior assumptions on insurance claim amount data, and method of estimating expected future insurance claims amounts from the posterior distribution is presented. In Section 3, a simulation study on the Weibull distribution assuming a gamma prior for the shape parameter has been presented. In Section 4, performance evaluation metrics Bayesian model approach, the maximum likelihood and simulated annealing obtained via simulation study are conducted. result and discussion are presented in Section 5. This paper has finally concluded in Section 6.
Materials and Methods
Determining the Expected Return of Insurance Claims Amount
The researcher measured the expected return amounts of Insurance claims data using the Bayesian approach. To determine the Posterior Distribution, incorporate the likelihood function of the best fit model of the claims return amounts with the Gamma prior distribution. The expected insurance claims amount will be determined by the posterior distribution’s expectation.
Weibull Distribution Model
Let be the Insurance claims amounts. If a random variable based on the assumption of Weibull distribution denoted as XWeibull . The probability density function (PDF) is defined as
| (1) |
The Cumulative distribution function (CDF) of Equation (1) can be derived as follows.
where is defined as the shape representing the slope of the curve and is the Weibull distribution scale parameter representing the characteristic life.
In our study, is the Insurance claims data over investment period ; is the shape parameter (slope/threshold) that determine the basic shape of the Weibull distribution PDF; is the scale parameter (characteristic life) of the Weibull distribution (WD) showing the distribution Insurance claims data.
The expected value and the variance of the Insurance claims data following Weibull distribution are given,
| (3) | |
| (4) |
where is the shape, is the scale parameter and is the gamma function.
Determining Likelihood Function
The Maximum likelihood function is regarded as one of the most common methods for parameters estimation. Suppose that Let is the amounts of the claims, which are independent and identically distributed , random variables, where the distribution parameters are assumed to be unknown. The distribution parameters and can be estimated via the maximum likelihood method. The likelihood function can be built from Equation (1) as
| (5) |
The likelihood function in Equation (5) can be simplified as follows
| (6) |
The log-likelihood function can be obtained by taking the natural logarithm of Equation (6) written as
We obtained the following Equation by differentiating Equation (Determining Likelihood Function) concerning appropriate scale and shape parameters and equating the resulting Equation to zero as follows,
| (8) | |
| (9) |
The MLE of parameters is determined by solving the nonlinear systems of linear equations mentioned above. To numerically optimize (maximization) the log-likelihood function in Equation (Determining Likelihood Function), it is considerably simpler to apply nonlinear optimization such as powerful computer software packed or novel metaheuristics algorithms such as Simulated annealing algorithm. The estimator of scale parameters from Equation (8) is as follows
| (10) |
The estimator of shape parameter can be obtained by substituting Equation (9) in Equation (10) as follows,
| (11) |
Equation (11) can be solved numerically or using an excel spreadsheet package to obtain the estimate . The value of can is easily obtained if is obtained. In this study, we have applied a Simulated annealing approach to obtain an estimated value .
Bayesian Estimation Method
Recently, the Bayesian estimation approach has attracted a lot of attention from various disciplines for analyzing various lifetime data, and it has mostly been recommended as an alternative to the traditional maximum likelihood methods. Thomas Bayes proposed the Bayesian approach, which is based on Bayes’ theorem. The Bayesian approach offers a simple rule for adjusting probabilities when new information becomes available. The new information is regarded as observed data in the Bayesian modelling framework, allowing us to update our previous assumptions about parameters of interest, which are assumed to be random variables. It is preferable in the Bayesian method to estimate the parameter using the data for the statistical model defined by the probability (density) function . The parameter is considered as a random variable in the Bayesian approach and thus has its distribution. If prior knowledge about the parameter is not available, it is possible to make use of a non-informative prior distribution in Bayesian analysis. In this study, the Gamma prior for shape parameters are considered and no specific prior on the scale parameter is assumed.
Prior Assumptions on Insurance Claim Amount Data
It is worth noting that if the shape parameter of the distribution is known, the scale parameter will have a conjugate prior distribution, a gamma prior is assumed in this case. When both parameters of a given distribution are unknown, it is obvious that they lack conjugate priors. In this study, we first consider the known shape parameter of the Weibull distribution (Nassar et al., 2018). So we consider the following priors on and . has a gamma prior with the scale parameter and shape parameter, , i.e. it has the PDF in Equation (12). The posterior distribution was determined by multiplying the likelihood function of the Insurance claims amounts by the prior distribution under the Bayesian approach. In this case, the prior distribution of the scale parameter is assumed to come from Gamma distribution with PDF as follows
| (12) |
The hyper-parameters and are assumed to be known real numbers. If hyper-parameters of independent Gamma distribution priors, then an estimate of hyper-parameters and Equation (12) is presented in the next subsection.
Estimating Expected Future Insurance Claims Amounts From the Posterior Distribution
If the likelihood is based on Insurance claims amount , to obtain the Bayes estimator, we multiply the prior distributions with likelihood function as follows,
| (13) |
Substituting Equations (6) and (12) into Equation (13) we have,
Then, the marginal distribution of parameters given Insurance claim data is found by taking the integral of both parameters
Equation (Estimating Expected Future Insurance Claims Amounts From the Posterior Distribution) can be simplified as follows
| (16) |
where is defined as follows,
| (17) | ||
| (18) | ||
| (19) |
Then the likelihood function is proportioned to the marginal function and the joint posterior distribution of the two parameters is obtained as follows,
| (20) | ||
| (21) |
Equation (Estimating Expected Future Insurance Claims Amounts From the Posterior Distribution) is recognized as Gamma. Therefore, the Bayes estimate of under the squared error loss function becomes.
| (22) |
As can be seen, the distributions obtained in both parameters are not similar to the known distributions and their closed-form can not be obtained. The estimations of parameters under the quadratic loss function are the expected values of these distributions. Powerful optimization techniques are needed. There exist many techniques to produce such approximations. The focus of this study is on the maximum likelihood and simulated annealing algorithm in comparison with Bayes estimators in terms of RMSE and MAE as measuring criteria.
Simulation Study on Weibull Distribution with Shape Parameter Following a Gamma Distribution
In this section, we examine the behaviour of the Bayesians estimators for a finite sample of size n. The performances of the Bayesians estimators has been compared with the Simulated annealing algorithm and maximum likelihood estimators of the shape and the scale parameters of Weibull distribution in terms of errors accumulation criteria. We assume that shape parameters follow Gamma priors. The simulation studies have been conducted on the python programming language developed by the author. In a simulation study based on Insurance claim amount, for comparing the performances of the estimators, we have generated random Insurance claims data from Weibull distribution via Python programming. The simulation has been carried out according to the following steps:
Step 1.Generate sample of sizes from the Insurance claim distribution.
Step 2.Compute the maximum likelihood estimates (MLE) for the proposed model parameters.
Step 3.For each sample size, samples with , , 1.5, 2 and 2.5 values estimate Weibull parameters.
Step 4.Compute the RMSEs and MAE.
Performance Evaluation Metrics
The performance of the Bayesian approach has been evaluated and compared with the simulated annealing algorithm and maximum likelihood methods in terms of error accumulation via RMSE and MAE according to the following Equations. A method with lower error accumulation is considered as the best fit model to the Insurance claims data set
| (23) | ||
| (24) |
where , , and are the exact value of the shapes parameters, estimated values of the shape parameter, exact value of the scale parameter and the estimated values of scale parameter respectively.
Result and Discussion
Simulation results have been reported in Tables 1 and 2. Figures 1 until 4, displayed the RMSE of various estimation methods of Weibull distribution while Figures 6 until 8 displayed the MAE of various methods of Weibull distribution understudy for different values of shapes and scale parameters with different samples size n 10, 50, 100, 150, 200.
Table 1 The Various Estimators of , , 1.5, 2, and 2.5 parameters of Weibull distribution
| BE | MLE | SA | ||||||
| n | ||||||||
| 1 | 1 | 10 | 0.9571 | 1.1023 | 1.0101 | 1.0473 | 1.1001 | 1.0570 |
| 50 | 1.0019 | 1.0535 | 1.0087 | 1.0235 | 1.0061 | 1.0167 | ||
| 100 | 1.0035 | 1.0307 | 1.0034 | 1.0067 | 1.0026 | 1.0072 | ||
| 150 | 1.0069 | 1.0102 | 1.0019 | 1.0029 | 1.0011 | 1.0015 | ||
| 200 | 1.0101 | 1.0105 | 1.0011 | 1.0016 | 1.0009 | 1.0012 | ||
| 1 | 1.5 | 10 | 1.0072 | 1.5613 | 1.0301 | 1.5031 | 1.0142 | 1.5027 |
| 50 | 1.0025 | 1.5351 | 1.0078 | 1.5015 | 1.0061 | 1.5017 | ||
| 100 | 1.0014 | 1.5197 | 1.0054 | 1.5009 | 1.0016 | 1.5012 | ||
| 150 | 1.0011 | 1.5103 | 1.0016 | 1.5005 | 1.0009 | 1.5005 | ||
| 200 | 1.0002 | 1.5071 | 1.0010 | 1.0002 | 1.0003 | 1.5002 | ||
| 1 | 2 | 10 | 0.9961 | 2.1011 | 1.0501 | 2.0343 | 1.0510 | 2.0171 |
| 50 | 1.0027 | 2.0651 | 1.0187 | 2.0105 | 1.0081 | 2.0170 | ||
| 100 | 1.0012 | 2.0117 | 1.0033 | 2.0046 | 1.0034 | 2.0052 | ||
| 150 | 1.0005 | 2.0123 | 1.0013 | 2.0053 | 1.0012 | 2.0014 | ||
| 200 | 1.0001 | 2.0005 | 1.0007 | 2.0007 | 1.0007 | 2.0007 | ||
| 1 | 2.5 | 10 | 0.9917 | 2.5334 | 1.0108 | 2.5121 | 1.0210 | 2.5090 |
| 50 | 0.9909 | 2.5150 | 1.0097 | 2.5095 | 1.0053 | 2.5061 | ||
| 100 | 0.9935 | 2.5087 | 1.0061 | 2.5041 | 1.0031 | 2.5020 | ||
| 150 | 1.0008 | 2.5012 | 1.0014 | 2.5014 | 1.0016 | 2.5015 | ||
| 200 | 1.0002 | 2.5007 | 1.0012 | 2.5003 | 1.0003 | 2.5003 | ||
According to the simulation study results obtained in Tables 1 and 2, revealed that results obtained with the Bayesian methods are similar with Maximum likelihood and agreed with each other when the sample size is small. With a small sample size, the estimates using Bayesian methods were reported to have a better fit followed by Maximum likelihood while the simulated annealing algorithm reported poor performance. With an increase in sample size, SA reported having the best result with better fitting followed by the maximum likelihood method. When the sample size increases the accumulation of the error (RMSE and MAE) decrease in all cases. From the Table 2 results it can be seen that, for a small sample size, the estimates with Bayesian methods and maximum likelihood method are a better fit than Simulated annealing. But, for big sample size, the Simulated annealing algorithm outperforms the traditional Bayesian methods and maximum likelihood method in estimating Weibull distribution parameters based on the Insurance claims data set. However, because the Bayesian approach considers
Table 2 RMSE and MAE of the various estimation methods of Weibull distribution
| BE | MLE | SA | ||||||
| n | RMSE | MAE | RMSE | MAE | RMSE | MAE | ||
| 1 | 1 | 10 | 0.05373 | 0.00594 | 0.01805 | 0.00574 | 0.03643 | 0.01571 |
| 50 | 0.00780 | 0.00111 | 0.00931 | 0.00064 | 0.00251 | 0.00046 | ||
| 100 | 0.00466 | 0.00034 | 0.00347 | 0.0001 | 0.00077 | 0.0001 | ||
| 150 | 0.00302 | 0.00009 | 0.00211 | 0.00003 | 0.00015 | 0.00002 | ||
| 200 | 0.01013 | 0.0001 | 0.00111 | 0.00001 | 0.00011 | 0.00001 | ||
| 1 | 1.5 | 10 | 0.02068 | 0.00685 | 0.03012 | 0.00332 | 0.00457 | 0.00169 |
| 50 | 0.00556 | 0.00075 | 0.0078 | 0.00019 | 0.00029 | 0.00026 | ||
| 100 | 0.00242 | 0.00021 | 0.0054 | 0.00007 | 0.00021 | 0.00016 | ||
| 150 | 0.00138 | 0.00008 | 0.0016 | 0.00004 | 0.00008 | 0.00006 | ||
| 200 | 0.00054 | 0.00004 | 0.03536 | 0.00249 | 0.00006 | 0.00002 | ||
| 1 | 2 | 10 | 0.02068 | 0.00972 | 0.03012 | 0.00844 | 0.00457 | 0.00681 |
| 50 | 0.00556 | 0.00138 | 0.0078 | 0.00058 | 0.0009 | 0.0005 | ||
| 100 | 0.00242 | 0.00033 | 0.0054 | 0.00008 | 0.0002 | 0.00009 | ||
| 150 | 0.00138 | 0.00009 | 0.0016 | 0.00004 | 0.00008 | 0.00002 | ||
| 200 | 0.00054 | 0.00001 | 0.03536 | 0.00001 | 0.00003 | 0.00001 | ||
| 1 | 2.5 | 10 | 0.01343 | 0.00251 | 0.01146 | 0.00229 | 0.00722 | 0.0083 |
| 50 | 0.00976 | 0.00032 | 0.00979 | 0.00038 | 0.00114 | 0.00023 | ||
| 100 | 0.00666 | 0.00008 | 0.00611 | 0.0001 | 0.00124 | 0.00015 | ||
| 150 | 0.00095 | 0.00005 | 0.0014 | 0.00002 | 0.00021 | 0.00002 | ||
| 200 | 0.00042 | 0.00001 | 0.008 | 0.00006 | 0.00009 | 0.00001 | ||
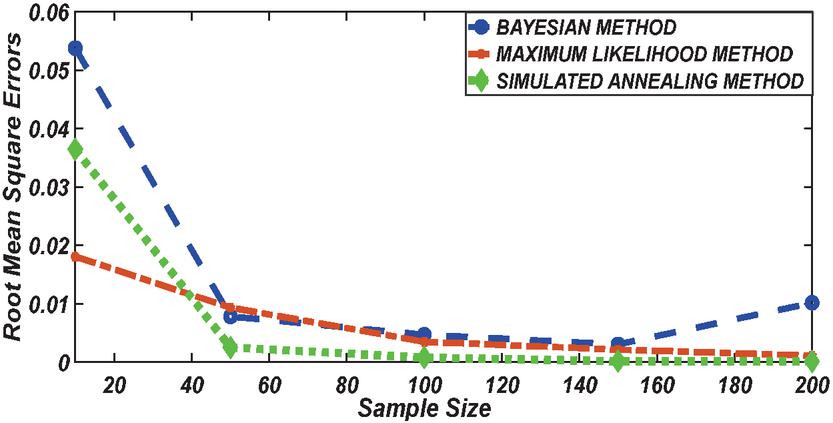
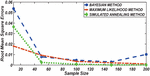
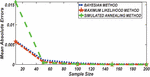
Figure 1 Comparing RMSE of Bayesian estimator with other methods when and .
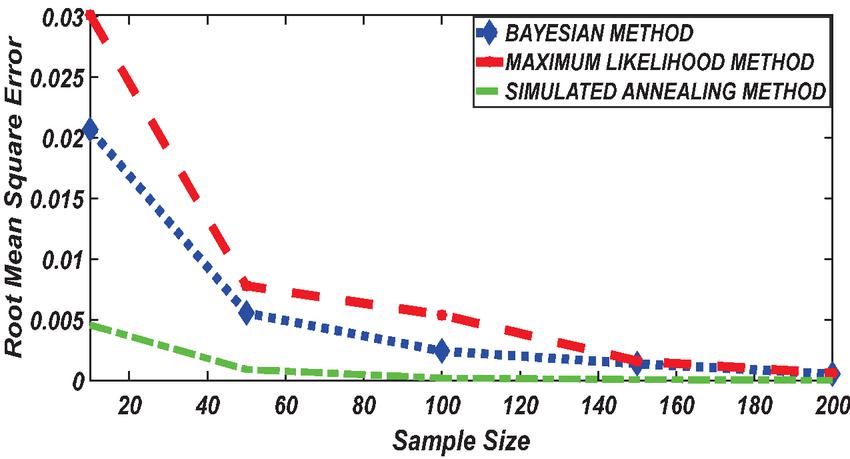
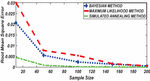
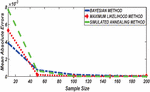
Figure 2 Comparing RMSE of Bayesian estimator with other methods when and .
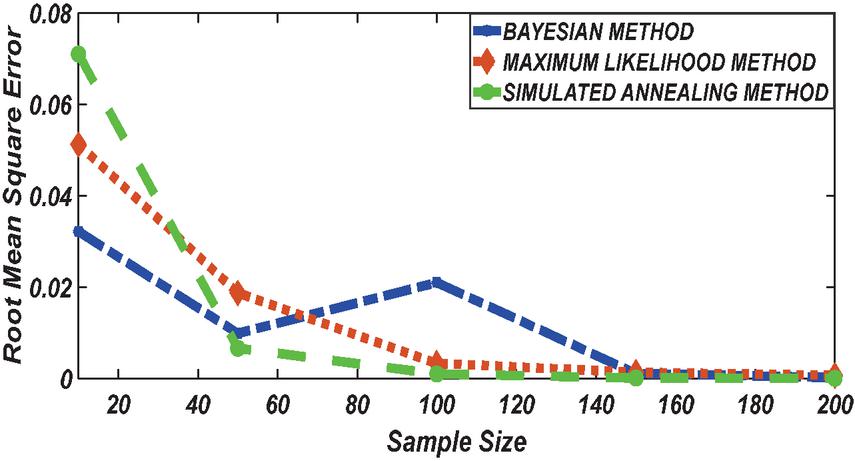
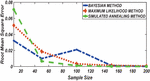
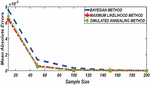
Figure 3 Comparing RMSE of Bayesian estimator with other methods when and .
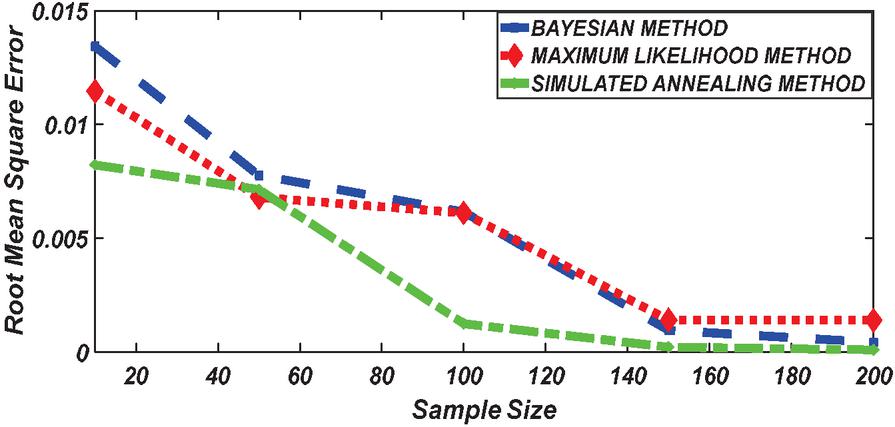
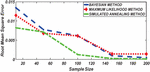
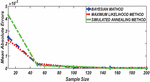
Figure 4 Comparing RMSE of Bayesian estimator with other methods when and .
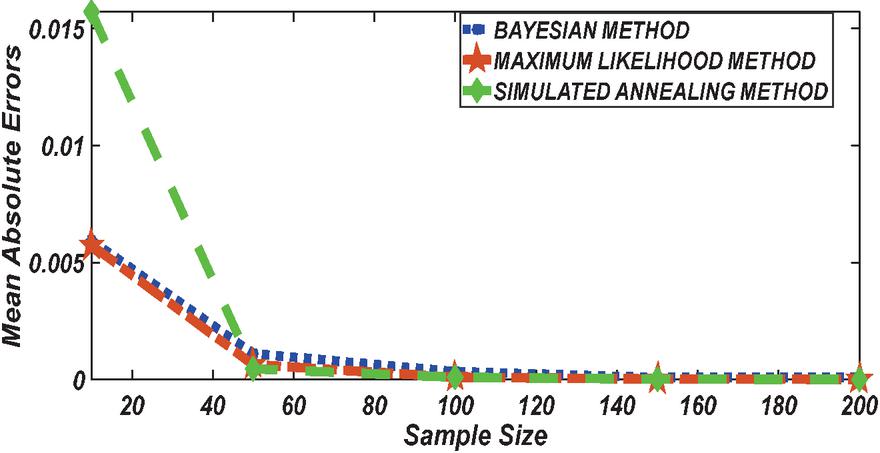
Figure 5 Comparing MAE of Bayesian estimator with other methods when and .
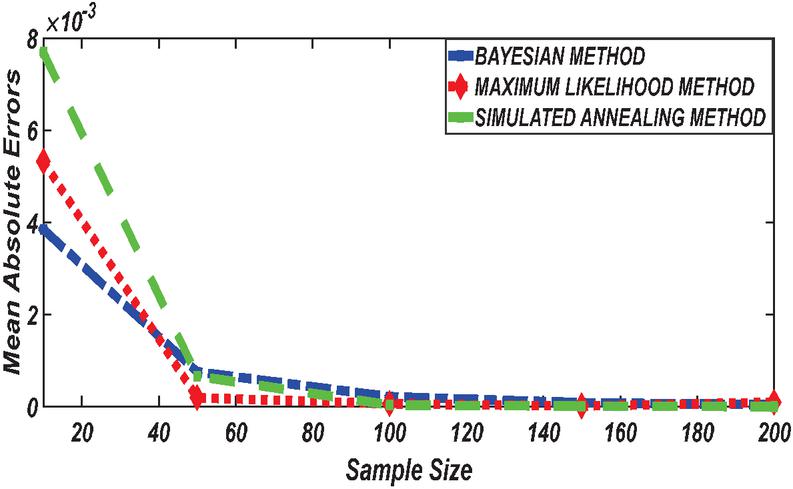
Figure 6 Comparing MAE of Bayesian estimator with other methods when and .
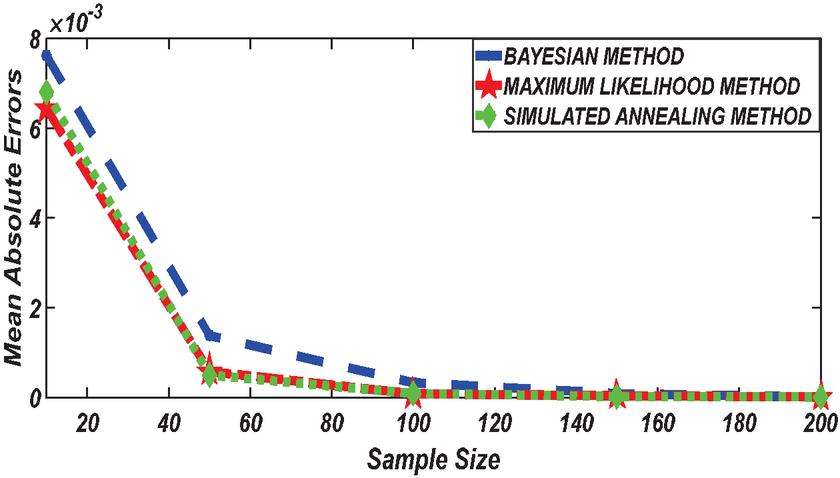
Figure 7 Comparing MAE of Bayesian estimator with other methods when and .
more levels of variability in the model, it is typically preferred over the Simulated annealing and maximum likelihood methods, which only estimate parameters as point estimates. The Bayesian methods also provide the entire posterior distributions for and, allowing us to perform additional analyses such as looking at predictive distributions of claims amount. These are the distributions that are used to estimate the likelihood of future claims.
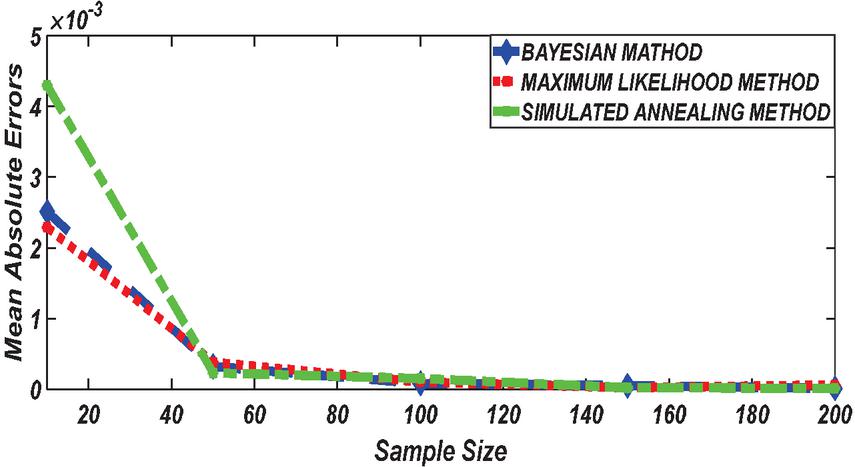
Figure 8 Comparing MAE of Bayesian estimator with other methods when and .
Figures 1 until 8 displayed the results of Root mean square errors (RMSE) and Mean absolute errors (MAE) reported in Table 2 respectively for various sample sizes. It can be observed that the RMSE and MAE accumulation in the Bayesian methods are going hand in hand with Maximum likelihood when the sample size is small. The error accumulation in the Simulated annealing algorithm reduced drastically with the increase in sample size. However, when the sample size increases the errors accumulation decrease in all cases. From Figures 1 to 8, it can be seen that, for small sample size, the estimates with Bayesian methods and Maximum likelihood are a better fit than SA. But, for a big sample size, Simulated annealing algorithm estimates are a good fit for the Insurance claim data set. This paper concluded that Bayesian methods agreed with the maximum likelihood method and Simulated the annealing algorithm when the two parameters of the Weibull distribution are estimated. The study revealed that, as sample size increases, both Bayes estimation, maximum likelihood estimation and Simulated annealing have a decrease in RMSE and MAE values. Especially, if the sample size is small the Bayesian estimation approach can be used as an alternative.
Actuarial Risk Measures
Value-at-Risk is defined as a statistical measure that indicates (in an explicit manner) the amount of a potential loss of market value of a financial asset, for which the probability of reaching or exceeding this value within a specified time horizon is equal to the tolerance level determined by the decision-maker (Bello et al., 2020; De Luca et al., 2020; Filippi et al., 2020; Molino and Sala, 2021). Another definition of VaR sees it as a measure of the maximum loss that an individual can incur within a certain time horizon for an investment realised under normal market conditions, within a predefined tolerance level (Majumder, 2018). Assuming random variable , the mathematical definition of VaR is as follows:
| (25) |
where is the quantile function of random variable , and is the level of the quantile of the probability distribution of this random variable. In particular, random variable may represent return of any financial asset at time . Risk exposure is one of the most important tasks of the actuarial and financial theory which has been described using probability distributions. Actuaries and financial risk managers are frequently using key risk indicators to assess the degree to which their businesses are exposed to specific types of risk posed by changes in underlying factors such as stock prices, prices of equity, interest rates, and currency exchange rates (Afify et al., 2020).
Value at Risk Measure of Claims Weibull Distribution
Value at Risk is basically a statistical tool to measure the expected loss at a particular period from particular Stock or Whole Portfolio with a given Confidence Level (Probability Level). The of random claims at the level, denoted by , is the percentile (or quantile) of the distribution of X. Hence, the of the Weibull claim model is defined by
| (26) | |
| (27) |
where and F is the CDF of the Weibull distribution given in Equation (Weibull Distribution Model).
Tail Value at Risk Measure
The Tail value at risk Measure is also called as Expected Shortfall (Le, 2020) and Conditional Value-at-Risk (Filippi et al., 2020) are two terms for tail value at risk. When an event occurs outside of a particular probability level, the TVaR is used to quantify the expected value of the loss. The TVaR is defined as follows:
| (28) |
An application to insurance data
In the study for this article, certain car accident data from 500 incidences recorded by one of Turkey’s largest insurance firms from January 2009 to December 2009 were used for real-life exemplary reasons. The numbers include the total number of claims in car accidents. Table 1 shows the estimations of the scale and form parameters for each estimation method.
Numerical study of the risk measures
The and for random variable X with the two-parameter Weibull distribution is defined in Equations (26) and (29) respectively. As said there too, in the attempt of estimating and , the efficiency of its estimators is to be determined as the joint efficiency of the estimators of the parameters of the Weibull distribution.
In this sub-section, we provide a numerical study of the risk measures such as and , for the Weibull distribution model for different sets of parameters. The process is described below:
A random sample of size n of 1000 of claims amount is generated according to Weibull distribution,
parameters have been estimated via BE, SA and MLE,
1000 repetitions are made for computation for Weibull distribution parameters.
Compute and , and SE for each estimators.
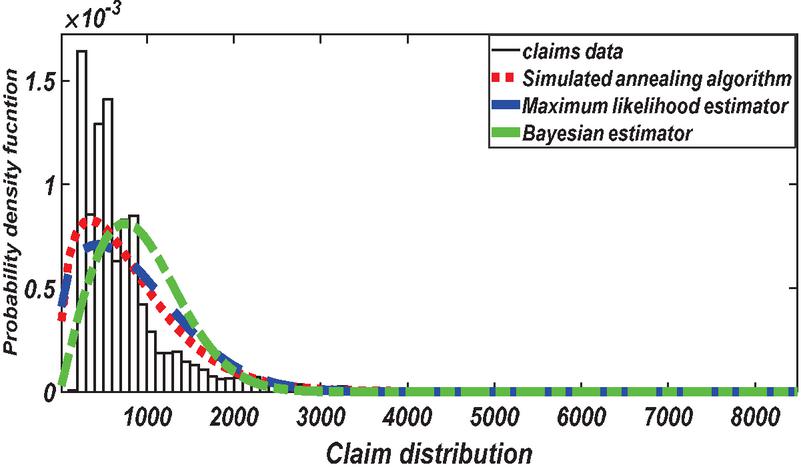
Figure 9 PDF for comparing estimation method based on insurance claims data set.
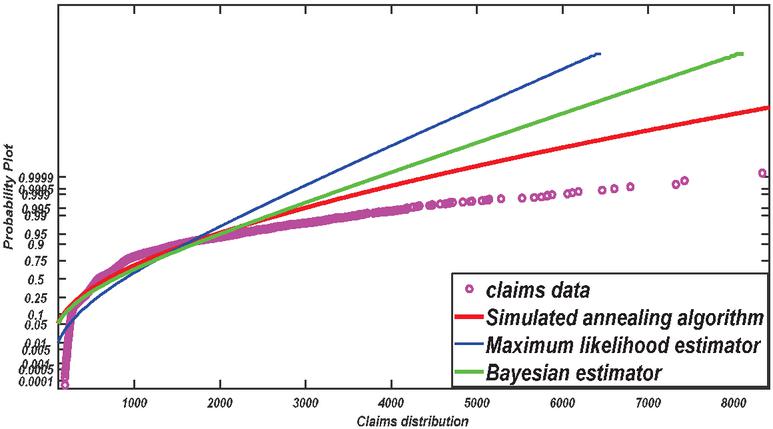
Figure 10 Probability plot for comparing various estimation methods based on insurance claims data set.
The numerical results of the risk measures are provided in Table 2. The numerical results are displayed graphically corresponding to each table in Figures 9–10. The simulation study of the risk measures is performed for the Weibull distribution for the estimated values of parameters. A model with higher values of the VaR is said to have a heavier tail. The simulation results provided in Tables 3 shows that the Bayesian estimator (BE) has higher values of the VaR than the Maximum likelihood estimator (MLE) and simulated annealing algorithm (SA). According to the simulation results given in Table 3 SA or BE are chosen as the best estimators.
Table 3 and , and SE for various estimation methods based on insurance claims data set
| Estimator | TVaR | SE | ||||
| BE | 817.2431 | 6. 358192 | 70111.1 | 7943.848 | 23831.544 | 0.00745097 |
| MLE | 825.7635 | 8.1895894 | 71092.7 | 7740.74 | 23222.22 | 0.00774074 |
| SA | 887/511 | 5.967336 | 69378.4 | 7132.48 | 21397.44 | 0.00694187 |
For the two-parameter Weibull distribution, compute the value at risk. The MLE approach is one of the most often utilized estimation methods in the literature. Nonetheless, in our work, we compared estimate approaches to find the optimum method, including the MLE method, for estimating for various sample sizes and known location parameter instances. It is demonstrated that MLE and BE estimation methods need the solution of nonlinear equations for the parameters, whereas SA has been demonstrated to be explicit functions of the sample observations and do not require any iterative computational procedures. In most circumstances, SA is strongly suggested for estimating the parameters of Weibull distribution and estimating or quantiles thereof for big samples. Because the MLEs and the BE are asymptotically identical, their performances are relatively close. With a high sample size, the SA approach appears to be the most recommendable estimator in general.
Conclusion
Statistical distributions are important in financial sciences in data modelling and analysis. The purpose of this article was to model claim sizes using the Weibull statistical distribution, with the shape parameter assuming the Gamma distribution. The parameters of the Weibull distributions were estimated using three methods: the Bayesian approach, the Maximum Likelihood approach, and the Simulated annealing algorithm. A simulation study was has been conducted to examine the performance of the Bayesian approach in comparison with maximum likelihood and Simulated annealing in estimating the parameters of the Weibull distribution for different sample sizes and parameter values.
Given the size of Insurance claim amounts and the general Insurance industries, Weibull distributions can be used to model Insurance claim distributions. These are useful when analyzing claims rather than using a lengthy schedule of raw claims data. Analysis can take the form of estimating the likelihood of claims falling into a specific range, as well as reinsurance agreements in place and other mathematical analyses. It also demonstrates that the Bayesian approach and the Maximum likelihood method are satisfactory and agreed at estimating the probabilities of lower claims, whereas the Simulated annealing algorithm is a good better fit at estimating the probabilities of larger claims. As a result, it is advisable to use Simulated annealing because it does not undervalue probabilities for large claims. This is especially useful when setting up reserves. Interestingly, all estimation methods can be used concurrently; for example, when the organization is interested in the probabilities of low claims, it employs the Bayesian approach or the Maximum likelihood distribution, whereas when it is interested in large claims, it employs a Simulated annealing algorithm. Further research on a Weibull distribution can be conducted when both parameters follow specific distributions. According to the findings, the Weibull distribution with shape following Gamma distribution fit the Insurance claims amount data better. This shows that no method is superior to another; it all depends on the distributions used (Henclová, 2006; Hersch, 2019). We concluded that the Simulated annealing algorithm necessitates more variables in parameter estimation than the Bayesian and Maximum likelihood methods. Priority setting is primarily subjective and relies on a guide provided by the classical method. In conclusion, we presume that the estimation methods work in conjunction to ensure that good conclusion are reached in this type of Insurance claims data analysis.
References
Ahmad, Z., Mahmoudi, E., and Hamedani, G. (2020). A class of claim distributions: Properties, characterizations and applications to insurance claim data. Communications in Statistics – Theory and Methods. https://doi.org/10.1080/03610926.2020.1772306.
Atikankul, Y., Thongteeraparp, A., and Bodhisuwan, W. (2020). The new poisson mixed weighted lindley distribution with applications to insurance claims data. Songklanakarin Journal of Science and Technology. https://doi.org/10.14456/sjst-psu.2020.21.
Bar-Lev, S. K., and Ridder, A. (2019). Monte Carlo Methods for Insurance Risk Computation. International Journal of Statistics and Probability. https://doi.org/10.5539/ijsp.v8n3p54.
Boland, P. J. (2007). Statistical and probabilistic methods in actuarial science. In Statistical and Probabilistic Methods in Actuarial Science. https://doi.org/10.1198/tas.2008.s269.
Denuit, M. (1997). A New Distribution of Poisson-Type for the Number of Claims. ASTIN Bulletin. https://doi.org/10.2143/ast.27.2.542049.
Dhaene, J., and Sundt, B. (1997). On Error Bounds for Approximations to Aggregate Claims Distributions. ASTIN Bulletin. https://doi.org/10.2143/ast.27.2.542050.
Fuzi, M. F. M., Jemain, A. A., and Ismail, N. (2016). Bayesian quantile regression model for claim count data. Insurance : Mathematics and Economics. https://doi.org/10.1016/j.insmatheco.2015.11.004.
Goffard, P. O., Loisel, S., and Pommeret, D. (2017). Polynomial Approximations for Bivariate Aggregate Claims Amount Probability Distributions. Methodology and Computing in Applied Probability. https://doi.org/10.1007/s11009-015-9470-7.
Henclová, A. (2006). Notes on free lunch in the limit and pricing by conjugate duality theory. Kybernetika. https://doi.org/10.18452/2963.
Hersch, G. (2019). No Theory-Free Lunches in Well-Being Policy. Review of Financial Studies. https://doi.org/10.1093/pq/pqz029.
Hipp, C. (1986). Improved Approximations for the Aggregate Claims Distribution in the Individual Model. ASTIN Bulletin. https://doi.org/10.2143/ast.16.2.2015001.
Hong, L., and Martin, R. (2017). A Flexible Bayesian Nonparametric Model for Predicting Future Insurance Claims. North American Actuarial Journal. https://doi.org/10.1080/10920277.2016.1247720.
Katsis, A., and Ntzoufras, I. (2005). Bayesian hypothesis testing for the distribution of insurance claim counts using the Gibbs sampler. Journal of Computational Methods in Sciences and Engineering. https://doi.org/10.3233/jcm-2005-5304.
Kazemi, R., Jalilian, A., and Kohansal, A. (2017). Fitting Skew Distributions to Iranian Auto Insurance Claim Data. Applications and Applied Mathematics: An International Journal.
Kumar, C. S., and Nair, B. U. (2016). On generalized hyper-Poisson distribution of order k and its application. Communications in Statistics – Theory and Methods. https://doi.org/10.1080/03610926.2014.966842.
Moumeesri, A., Klongdee, W., and Pongsart, T. (2020). Bayesian bonus-malus premium with Poisson-Lindley distributed claim frequency and Lognormal-Gamma distributed claim severity in automobile insurance. WSEAS Transactions on Mathematics. https://doi.org/10.37394/23206.2020.19.46.
Nassar, M., Afify, A. Z., Dey, S., and Kumar, D. (2018). A new extension of Weibull distribution: Properties and different methods of estimation. Journal of Computational and Applied Mathematics. https://doi.org/10.1016/j.cam.2017.12.001.
Ntzoufras, I., Katsis, A., and Karlis, D. (2005). Bayesian Assessment of the Distribution of Insurance Claim Counts Using Reversible Jump MCMC. North American Actuarial Journal. https://doi.org/10.1080/10920277.2005.10596213.
Okhli, K., and Jabbari Nooghabi, M. (2021). On the contaminated exponential distribution: A theoretical Bayesian approach for modeling positive-valued insurance claim data with outliers. Applied Mathematics and Computation. https://doi.org/10.1016/j.amc.2020.125712.
Omari, C. O., Nyambura, S. G., and Mwangi, J. M. W. (2018). Modeling the Frequency and Severity of Auto Insurance Claims Using Statistical Distributions. Journal of Mathematical Finance. https://doi.org/10.4236/jmf.2018.81012.
Peters, G. W., Targino, R. S., and Wüthrich, M. V. (2017). Full Bayesian analysis of claims reserving uncertainty. Insurance: Mathematics and Economics. https://doi.org/10.1016/j.insmatheco.2016.12.007.
Ter Berg, P. (1980). On the Loglinear Poisson and Gamma Model. ASTIN Bulletin. https://doi.org/10.1017/S0515036100006590.
Willmot, G. E. (1987). The Poisson-Inverse Gaussian Distribution as an Alternative to the Negative Binomial. Scandinavian Actuarial Journal. https://doi.org/10.1080/03461238.1987.10413823.
Willmot, G. E. (1988). Parameter orthogonality for a family of discrete distributions. Journal of the American Statistical Association. https://doi.org/10.1080/01621459.1988.10478626.
Willmot, G. E., and Sundt, B. (1989). On evaluation of the delaporte distribution and related distributions. Scandinavian Actuarial Journal. https://doi.org/10.1080/03461238.1989.10413859.
Wuthrich, M. V. (2013). Non-Life Insurance : Mathematics and Statistics. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.2319328.
Zhang, Y., Dukic, V., and Guszcza, J. (2012). A Bayesian non-linear model for forecasting insurance loss payments. Journal of the Royal Statistical Society. Series A: Statistics in Society. https://doi.org/10.1111/j.1467-985X.2011.01002.x.
Zhao, J., Faqiri, H., Ahmad, Z., Emam, W., Yusuf, M., and Sharawy, A. M. (2021). The Lomax-Claim Model: Bivariate Extension and Applications to Financial Data. Complexity. https://doi.org/10.1155/2021/9993611.
Biographies

Hamza Abubakar received both his B.Sc. in Mathematics and MSc in Financial Mathematics from the University of Abuja, Nigeria in 2006 and 2015 respectively. He holds a PhD degree in Financial Mathematics from the University of Sciences Malaysia. Hamza joined the service of Isa Kaita College of Education, Dutsin-ma, Katsina, Nigeria in 2008 and was promoted to the rank of Senior Lecturer. He is an active member of the Nigerian Mathematical Society, the Mathematical Association of Nigeria, the Science Teachers Association of Nigeria, and the International Association of Engineers (OR and AI). His research interests include Financial Mathematics, neural network modeling, and metaheuristics optimization.

Shamsul Rijal Muhammad Sabri received both his B.Sc. in Actuarial Science and MSc in Statistics from the National University of Malaysia in the year 1998 and 2001 respectively. He then received PhD degree in Applied Statistics from the University Malaya in the year 2009. Shamsul Rijal is currently serving with the School of Mathematical Sciences, University of Science, Malaysia. He is an active member of the Malaysian Mathematical Sciences Society (PERSAMA). His research interests include Financial Mathematics, Statistical Modelling and Simulation studies.
Journal of Reliability and Statistical Studies, Vol. 16, Issue 1 (2023), 1–24.
doi: 10.13052/jrss0974-8024.1611
© 2023 River Publishers