A Study on One-Parameter Entropy-Transformed Exponential Distribution and Its Application
Mathew Stephen1,*, David Ikwuoche John2 and Yaska Mutah3
1Department of Mathematics, Statistics and Computer Science, Kwararafa University Wukari, Wukari Nigeria
2Department of Mathematics and Statistics, Federal University Wukari, 200, Katsina-Ala Road, Wukari, Wukari, Nigeria
3Department of Mathematics and Statistics, The Federal Polytechnic Mubi, Adamawa State
E-mail: matsteve231@gmail.com
*Corresponding Author
Received 23 November 2023; Accepted 12 April 2024
Abstract
This study presents the Entropy-Transformed Exponential Distribution (EnTrED), in an attempt to enhancing the flexibility and applicability of the traditional exponential distribution. The study explores the statistical properties of the EnTrED, including mode, quantile function, reliability, moments, and hazard function. The parameters of the distribution were estimated using maximum likelihood estimation, and the stability of these estimates was thoroughly evaluated through extensive Monte Carlo simulation. The simulation results demonstrated that the maximum likelihood estimates of the model parameters were well-behaved. Additionally, Empirical assessments against alternative distributions underscores the robustness of the EnTrED as a superior model for analyzing life data.
Keywords: Entropy-transformed exponential distribution (EnTrED), memoryless property, hazard rate, survival analysis, reliability analysis, time-dependent hazard.
1 Introduction
Modeling real life data is integral in many areas of applied studies such as life sciences, biochemistry, geosciences, cosmology, statistical mechanics, social sciences, linguistics, biology, information technology, and even science fiction films. Considerable efforts have been done to construct new distributions for survival data. However, there still remain many problems involving real data, which are not contemplated by existing probability models (Percontini, Gomes-Silva, da Silva and Handique, 2021). Suppose a random variable c follow an exponential distribution and its probability density function (P.D.F) and cumulative distribution function (C.D.F) are given by;
| (1) |
For this model, the probability of an event occurring is most likely independent of time i.e., which implies the memoryless property. This property may not hold in some practical scenarios. Also, for this model In (1), when dealing with systems that wear out or age over time, the exponential distribution may not accurately capture the increasing failure rate since (Nelsen, 1987). In addressing the above challenges to make the exponential distribution more flexible and applicable to a wide range of real-life scenarios, several researches have proposed different transformation techniques. (Owoloko, Oguntunde and Adejumo, 2015) studied the “transmuted exponential distribution”, (El-Damrawy, Teamah and El-Shiekh, 2022) derived the “Truncated bivariate Kumaraswamy exponential distribution”, (Chesneau, Kumar, Khetan and Arshad, 2022) derived the “modified weighted exponential distribution”, (Ozkan and Golbasi, 2023) proposed the “Generalized Marshall-Olkin exponentiated exponential distribution” amongst others.
Dragan and Isaic-Maniu (2019) described the pseudo-entropic transformation also called entropy transformation by (Aziz, Husain, and Ahmed, 2021) which has some unique features. The transformation can be summarized with the expression in (2) (for more details see (Aziz, Husain, and Ahmed, 2021)).
| (2) |
where is the survival function of a baseline probability distribution.
By incorporating both the rate of change of the reliability function and the logarithm of the reliability, which can be related to the hazard function, a more flexible exponential model that allow for time-varying hazard rates with memory effects can be created. This can lead to a more realistic and flexible exponential model for reliability analysis and survival data, especially when modeling systems or processes where the failure rate is not constant over time.
The aim of this research is to propose a novel distribution called the entropy transformed exponential distribution, to derive some of its properties, estimate its parameter using the method of maximum likelihood, validate through simulation the stability of the model and to demonstrate its applicability using real life data sets. The rest of this article is organized into sections as follows; In Section 2 the entropy transformed exponential distribution (EnTrED) is formally introduced, the statistical and reliability properties of the EnTrED and the maximum likelihood estimate (MLE) of the parameter of the parameter is derived and presented. In Section 3, the stability of the EnTrED was determined through a simulation study and the application of the EnTrED in modelling real-life data sets and the study concludes in Section 4.
2 Entropy Transformed Exponential Distribution
2.1 Exponential Distribution
The probability density function (PDF) and cumulative density function (CDF) of the exponential distribution is given by (1). By definition, the survival function is given by the equation
| (3) |
2.1.1 Entropy transform exponential distribution
According to (Dragan and Isaic-Maniu, 2019), if a random variable c has an exponential distribution, then the random variable will have an entropy transformed (or the pseudo-entropic) exponential distribution if its PDF satisfies the equation;
| (4) |
The survival function of the exponential distribution is given by;
and substituting the log of the survival function and its derivative into Equation (4) yields the following:
| (5) |
and .
To validate the that (5) satisfies the condition in (4), it has to be shown that the integral over the range of (5) is unity.
| (6) |
By using integration by parts, let
| (7) |
On substituting into (6), and simplifying, it can easily be shown that
satisfying the condition in (4) and validating the model.
Definition 1: a random variable c is said to have an entropy transformed exponential distribution if it satisfies (5) and .
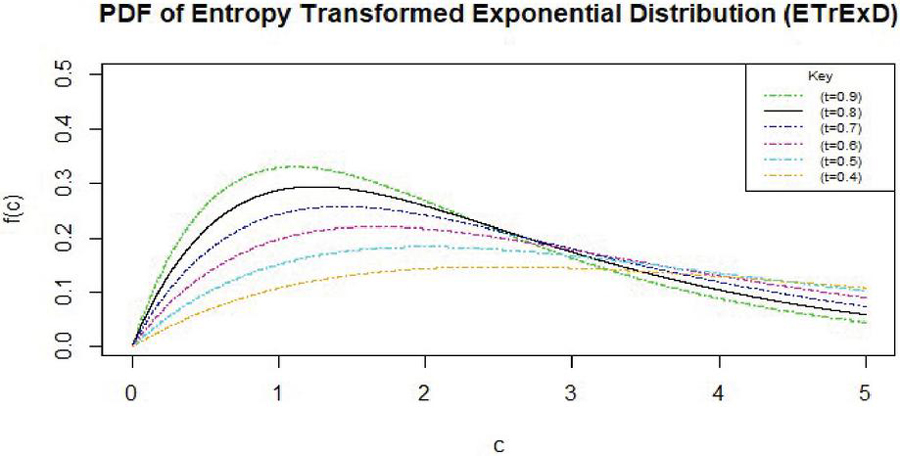
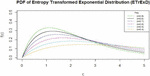
Figure 1 Plot (where ).
Figure 1 displays the of the EnTrED, revealing a right-skewed distribution.
By the fundamental theory of calculus the represents the CDF of the random variable and can be obtained by solving the following;
| (8) |
As it has been shown,
| (9) |
Since the definition the CDF is a function, whose output yields the , evaluating (9) will yield the CDF of . Thus,
| (10) |
Definition 2: for a random variable c, the expression in equation (10) defines the CDF of the Entropy Transformed Exponential Distribution , and .
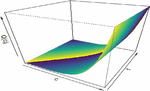
The CDF of the distribution is displayed in Figure 2, satisfying the condition that all and .
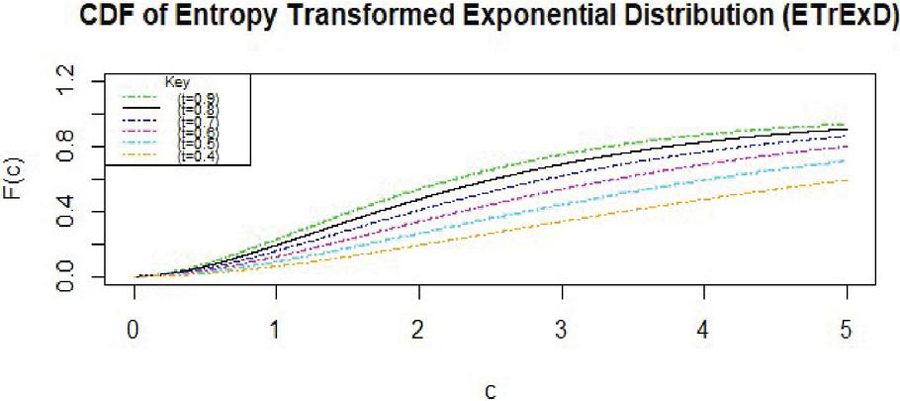
Figure 2 CDF plot (where ).
2.1.2 Asymptotic behaviour
The asymptotic behavior of the PDF provides insights into the tails or extreme values of the distribution. The limit of EnTrED as is 0.
| (11) |
The limit of EnTrED in the tails is 0. This indicates that the probability of observing values in those tails is infinitesimally in the regions. This is consistent with the condition that the total probability over the entire range of possible values for a random variable is unity.
2.1.3 Properties of EnTrED
Quantile function (Q(C))
The EnTrED has the ability to generate random variates or random samples that follow the distribution’s characteristics since its quantile function can be expressed in terms of the Lambert W () function (Further details on the can be found in Corless et al. 1996).
Theorem 1: Let c be a random variable distributed with EnTrED. Then for every fixed , and , the quantile function is given as follows;
| (12) |
Proof To obtain the quantile function, the CDF of the random variable c must be inverted.
| (13) |
Let ; , then, on substitution into (13), we have that
| (14) |
Using Lambert’s function, , Equation (2.1.3) can be written as
Therefore,
| (15) |
Which ends the proof.
The graphical plot for the quantile function is presented in Figure 3.
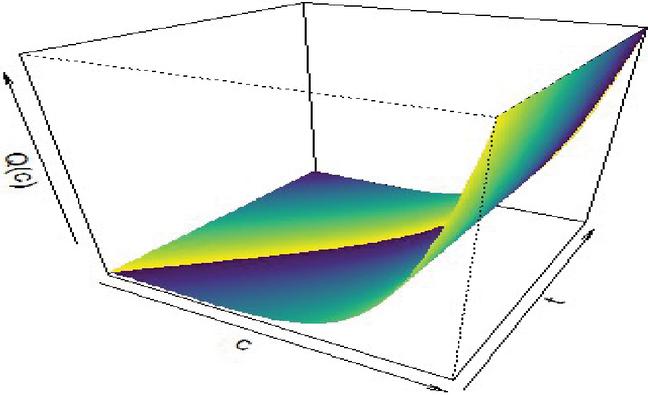
Figure 3 Quantile function plot (where ).
Raw moments
For a random variable c, the raw moment is a quantitative measure that characterizes various aspects of its probability distribution. The moment function of the random variable is used to study many important properties of distribution such as dispersion, tendency, skewness and kurtosis.
Theorem 2: Let a random variable , then, the raw moment is given by the equation;
| (16) |
Proof
For any continuous random variable with a valid PDF , the moment is given by:
| (17) |
By transformation, let
On substituting into Equation (2.1), the following is obtained;
| (18) |
Since gamma of z is expressed as , Equation (2.1) can be transformed into
| (19) |
Therefore, the of a random variable c with entropy transformed exponential distribution is expressed as shown in Equation (19), which completes the proof.
Probability weighted moments
Probability Weighted Moments are expressed as expectations of functions of a random variable, premise on the condition that the ordinary moments of the random variable exist. For a random variable C the probability weighted moments is defined by the expression;
| (20) |
Theorem 3: Let a random variable , then, the of EnTrED is given by;
| (21) |
Proof
To obtain the for EnTrED, we make the substitution of Equation (6) for and (10) for into (20). Thus;
| (22) | ||
| (23) |
Where;
| (24) |
Using the Binomial sum of a series presented in Equation (2.1), it can be shown that
| (25) |
Thus,
| (26) | ||
| (27) |
Also, by expanding using Binomial sum of a series in (2.1), it can be shown that,
| (28) |
Substitute (28) into (27). Then we have that;
Where;
| (29) | ||
| (30) |
By transformation, let;
| (31) |
| (33) | ||
| (34) | ||
| (35) | ||
| (36) | ||
| (37) |
Where;
Conditional moment
A useful tool for understanding the distributional properties of random variables is the conditional moments . Assume that C is a random variable, or an event, such that , then the expected value of given the condition is represented by the conditional moment of order , which is written as . For the random variable with EnTrED, the conditional moment is derived by;
| (38) |
Proof
The conditional moment of a random variable with continuous distribution is given by;
| (39) |
For , make the substitution of Equation (6) for the PDF of the EnTrED in Equation (39).
By using integration by parts, let
This implies that
| (40) |
Where is the survival function of EnTrED (as defined in Equation (48)), thus completing the proof.
Mean
Theorem 4: The mean of a random variable is expressed as follows.
| (41) |
Proof
The mean of a random variable c with EnTrED can be obtained as the first moment. This can be derived by substituting unity into the moment in (19).
| (42) |
Which completes the proof.
Harmonic mean (Har.M)
Theorem 5: the harmonic mean of a random variable is expressed as follows.
| (43) |
Proof
The harmonic mean of a random variable c with can be obtained by solving the expression given below.
| (44) | ||
| (45) |
Which ends the proof.
Mode (Md)
Theorem 6: the mode of a random variable is defined as follows.
| (46) |
Proof
The mode of a random variable
| (47) |
Which ends the proof.
Survival function (S(c))
Survival function can be defined as the probability that an event happened after time, . It models time to-an-event and takes note of the time it takes for an event to occur. Given the CDF of a probability function, the survival function is the probability of survival beyond time and is defined by;
| (48) |
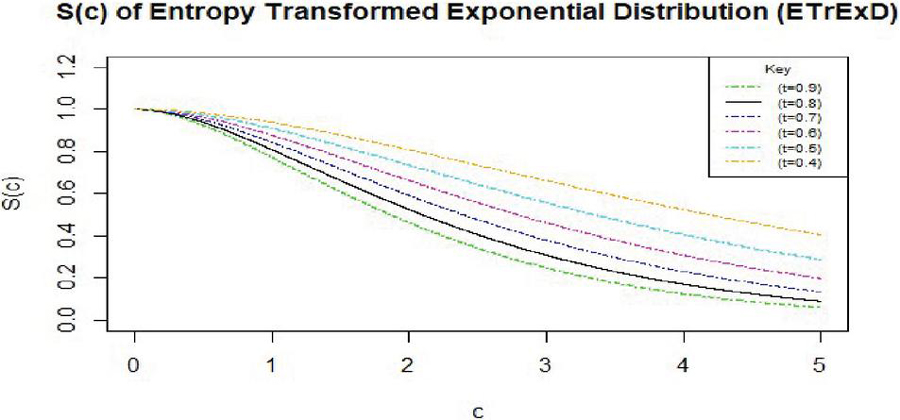
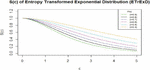
Figure 4 Survival function plot (where ).
The survival function of the EnTrED is presented in Figure 4. This depicts the probability that an event has not occurred by time (). The function is characterized by a gradual decrease from as increases, thus, signifying a diminishing likelihood of no event occurrence over time. Ultimately, as increases, the survival function value approaches 0, suggesting that the event is almost certain to occur after a sufficiently long time.
Hazzard function (H(c))
The hazard function is also known as the failure rate is defined as the conditional probability of failure of an item/device given that the item has survived to the time, t. The hazard rate function of a random variable is the ratio of the PDF, to the survival function, and is given by:
| (49) |
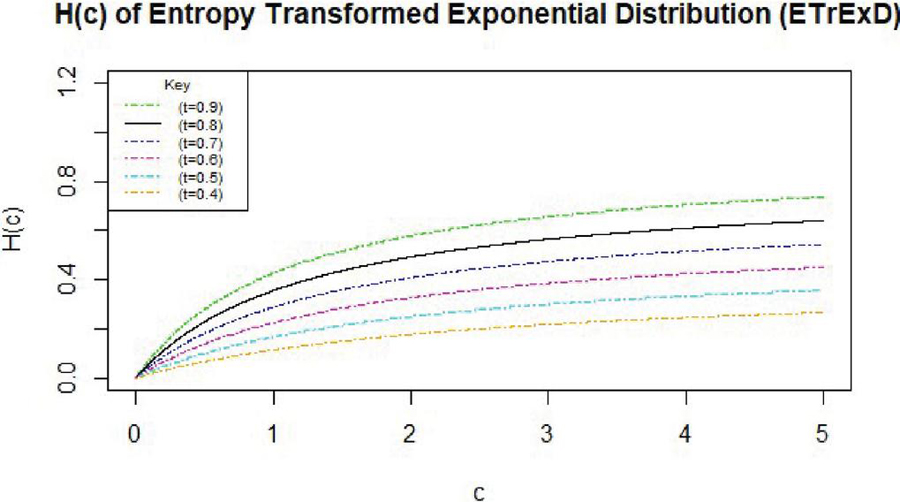
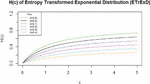
Figure 5 Hazzard function plot (where ).
The hazard function provided represents the instantaneous risk of event occurrence for model EnTrED as a function of with as a parameter. As shown in Figure 5, the function increases gradually with c, showing a linear-like behavior. However, as increases, the hazard function reaches a peak and becomes asymptotically constant. The behavior is influenced by the parameter , where higher values result in steeper increases in the hazard rate.
Characteristic function
This characteristics function is useful and has some properties which gives it a genuine role in mathematical statistics. It is used for generating moments, characterization of distributions and in analysis of linear combination of independent random variables.
Theorem 6: the characteristic function of a random variable is defined by the following equation.
| (50) |
Proof
The characteristics function of a random variable is given by;
| (51) |
Expressing in trigonometric form, we have that
| (52) |
Using the power series expansion, it can be shown that
| (53) |
This implies that
| (54) |
Where and are the moments of the random variable for and respectively.
As obtained in Equation (19), .
It follows that
| (55) |
Thus, completing the proof.
Order statistic
Order statistics are essential for describing the distribution and behavior of random variables because they provide the sorted values of observations taken from a sample. Given a random sample of size , the order statistics are denoted as , where represents the smallest observation, the second smallest, to , which denotes the largest observation. The order statistic of a random variable is given as;
Expanding using the Binomial theorem, we have
| (57) |
Therefore, equation (57) becomes;
| (58) |
Theorem 8: The order statistic of a random variable with EnTrED is given by;
| (59) |
Proof
To obtain the order statistic of the EnTrED, we make the substitution (6) for and (10) for in Equation (58). Therefore,
| (60) | ||
| (61) |
Where;
Information measures
In information theory, information measures are numbers that are used to quantify different characteristics of information, uncertainty, and entropy. These metrics have been applied in a variety of domains, such as statistics, machine learning, communication theory, and cryptography, where it is essential to comprehend and quantify uncertainty and information. This subsection will develop the Renyi entropy and associated Arimoto measure for the EnTrED.
1. Renyi entropy
The Rényi entropy measures bear the name of the mathematician Alfréd Rényi. It generalizes the concept of Shannon entropy, providing a parameterized family of entropy measures. This can be defined as follows;
| (62) |
Suppose a random variable , then the degree of uncertainty can be obtained by substituting (6) for in equation in Equation (62) as follows;
| (63) | ||
| (64) |
From (16), is equivalent to the moment of the density function. Thus, on substituting into (64), we obtain the following;
| (65) |
2. Arimoto measure of entropy
A means of comparing the uncertainty or disorder in probability distributions is the Arimoto measure of entropy, which is often referred to as the “information divergence entropy” or the “information radius entropy.” The following formula defines this:
| (66) |
If , then on substituting (6) into (66), the Arimoto measure of entropy is derived as follows;
| (67) | ||
| (68) |
On substituting the transformation in (7) into (68), we have that,
which can be transformed using the gamma function as;
| (69) |
Method of parameter estimation adopted
To estimate the parameter of the EnTrED, using the maximum likelihood method, let be independent identically distributed of size (n) with probability function EnTrED, then, the likelihood function for EnTrED is given below
| (70) | ||
The likelihood equation in (70) is partially differentiated with respect to phi and equating to zero, we have
Therefore, the MLE for the parameter of is given as;
| (71) |
3 Stability Analysis
3.1 Simulation
This part uses Monte-Carlo simulation to assess the stability of the EnTrED probability model’s MLE by increasing the sample size. A random sample of sizes 30, 100, 500 and 750 was generated and using the quantile function shown in Equation (10) with the parameter values fixed at 0.3, 0.4, 0.6, and 0.9. The bias (AvAB), variance (Var), standard deviation (SD), mean square error (MSE), root mean square error (RMSE) and coefficient of variation (CV) were the metrics utilized to evaluate the stability. The calculations were done using the following formula;
| (72) |
Table 1 Simulation results and measures of accuracy
| Sample | ||||||||
| Size | Parameter | MLE | Bias | Var | SD | MSE | RMSE | CoV |
| 30 | 0.3 | 2.7808 | 2.4808 | 22.0374 | 4.6944 | 28.1918 | 5.3096 | 168.8142 |
| 100 | 0.3 | 1.9742 | 1.6742 | 15.7767 | 3.9720 | 18.5795 | 4.3104 | 201.1996 |
| 500 | 0.3 | 0.5759 | 0.2759 | 0.6880 | 0.8294 | 0.7641 | 0.8741 | 144.0315 |
| 750 | 0.3 | 0.4604 | 0.1604 | 0.0755 | 0.2748 | 0.1012 | 0.3182 | 59.6916 |
| 30 | 0.4 | 0.4331 | 0.0331 | 0.1419 | 0.3766 | 0.1429 | 0.3781 | 86.9586 |
| 100 | 0.4 | 0.5137 | 0.1137 | 0.0094 | 0.0971 | 0.0224 | 0.1495 | 18.8955 |
| 500 | 0.4 | 0.5137 | 0.1137 | 0.0021 | 0.0455 | 0.0150 | 0.1225 | 8.8559 |
| 750 | 0.4 | 0.2728 | -0.1272 | 0.0030 | 0.0552 | 0.0192 | 0.1387 | 20.2369 |
| 30 | 0.8 | 0.6893 | -0.1107 | 0.0008 | 0.0279 | 0.0130 | 0.1142 | 4.0525 |
| 100 | 0.8 | 0.6506 | -0.1494 | 0.0867 | 0.2944 | 0.1090 | 0.3302 | 45.2557 |
| 500 | 0.8 | 0.7674 | -0.0326 | 0.0181 | 0.1346 | 0.0192 | 0.1385 | 17.5453 |
| 750 | 0.8 | 0.6873 | -0.1127 | 0.0000 | 0.0055 | 0.0127 | 0.1129 | 0.8032 |
| 30 | 0.9 | 0.6705 | -0.2295 | 0.0006 | 0.0248 | 0.0533 | 0.2308 | 3.7032 |
| 100 | 0.9 | 0.7790 | -0.1210 | 0.0001 | 0.0086 | 0.0147 | 0.1213 | 1.1077 |
| 500 | 0.9 | 0.7790 | -0.1210 | 0.0000 | 0.0040 | 0.0147 | 0.1211 | 0.5191 |
| 750 | 0.9 | 0.6687 | -0.2313 | 0.0000 | 0.0049 | 0.0535 | 0.2314 | 0.7338 |
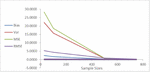
A simulation was performed and the results presented in Table 1 presents the sample size, true and MLE parameter estimates for the new model. Testing the behavior of the distribution with the aid of variance, standard deviation and standard error revealed as the sample sizes increases. The observed trend in the simulation results was as anticipated: as the sample sizes grew larger and larger, the values of the adequacy metrics (variance, standard deviation, and standard error) decreasing. This trend displayed in Figure 6 aligns with expectations for a well-fitting density model. In statistical modeling, an adequate model should ideally demonstrate reduced variability and increased precision as more data becomes available for estimation.
Therefore, the decreasing values of these adequacy metrics as the sample sizes increased can be interpreted as a positive sign. This result supports the conclusion that the EnTrED model behaves as a well-behaved density function, which is indicative of its suitability for modeling real-life data sets. In essence, the simulation results, as summarized in Table 1, indicate that the EnTrED model is a statistically sound and appropriate choice for modeling data in various applications.
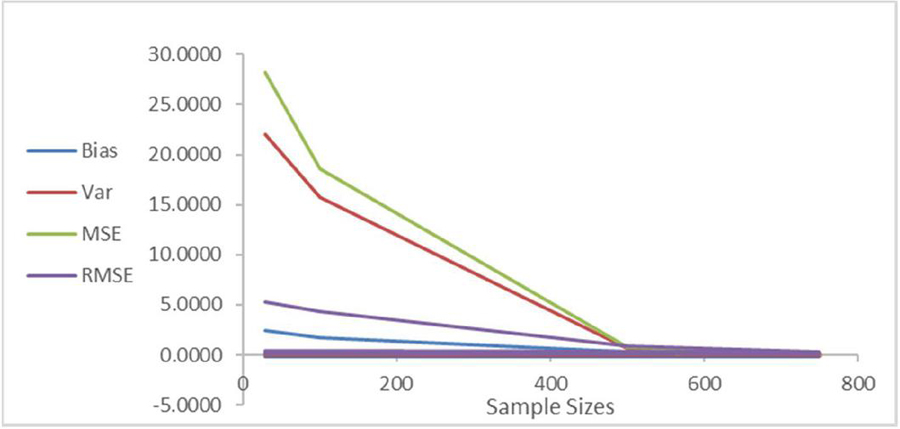
Figure 6 Measures of stability.
3.2 Empirical Application
This section uses three actual datasets to show the applicability and flexibility of the EnTrE distribution. Additionally, this part offers a comparison to other competing models and an assessment of the distribution’s goodness of fit. The models that were compared included the Sine Exponential distribution, Exponential distribution, Ram Awadh distribution and Prakaamy distribution respectively. The Kolmogrov Smirnov (KS), AIC, BIC, HQIC, and CAIC are among the adequacy metrics used. The better the model, the lower these measures’ values should be.
In this section, the empirical applicability and flexibility of the newly introduced entropy-transformed exponential distribution (EnTrED) are thoroughly examined using real-world datasets. This analysis aims to showcase the practical utility of the EnTrED model in handling diverse data scenarios. Moreover, it includes a comparative assessment of the EnTrED model against several alternative statistical distributions to assess the goodness of fit and overall performance. The datasets chosen for this evaluation are actual, real-world datasets, which adds an element of authenticity and relevance to the analysis. These datasets represent different domains or fields of study, making them suitable for assessing the versatility of the EnTrED model across various applications. To determine how well the EnTrED model performs in comparison to other statistical models, a comprehensive set of competing models is considered. These competing models include:
| Models | Domain | Sources | |
| Sine Exponential (SE) | For | (Isa, Bashiru, Ali, and Adepoju, 2022) | |
| Exponential (E) | For | ||
| Ram Awadh (RA) | For | (Shukla, 2018). | |
| Prakaamy (P) | For | (Shukla, 2018) |
The first dataset was based on (Tashkandy, Nagy, Akbar, Mahmood and Gemeay, 2023) and covered the intervals between 64 successive eruptions of the Kiama Blowhole. The following is the dataset’s content: 83, 51, 87, 60, 28, 95, 8, 27, 15, 10, 18, 16, 29, 54, 91, 8, 17, 55, 10, 35, 47, 77, 36, 17, 21, 36, 18, 40, 10, 7, 34, 27, 28, 56, 8, 25, 68, 146, 89, 18, 73, 69, 9, 37, 10, 82, 29, 8, 60, 61, 61, 18, 169, 25, 8, 26, 11, 83, 11, 42, 17, 14, 9, 12
Table 3 Adequacy measures for fits using first dataset
| Models | AIC | BIC | CAIC | HQIC | MLE | KS | P val | Rank |
| EnTrED | 595.594 | 597.753 | 595.659 | 596.445 | 0.050 | 0.162 | 0.070 | 1 |
| SE | 599.937 | 602.096 | 600.002 | 600.788 | 0.014 | 0.152 | 0.105 | 2 |
| E | 601.625 | 603.784 | 601.690 | 602.476 | 0.025 | 0.164 | 0.063 | 3 |
| RA | 1105.328 | 1108.149 | 1105.361 | 1106.474 | 0.150 | 109748 | 2.2e-16 | 5 |
| P | 695.421 | 697.580 | 695.486 | 696.272 | 0.151 | 109743 | 2.2e-16 | 4 |
Table 4 95% Confidence interval estimates for first dataset
| Models | MLE | SE_MLE | 95% Lower CI | 95% Upper CI |
| EnTrED | 0.050 | 0.000 | 0.050 | 0.051 |
| SE | 0.014 | 0.000 | 0.014 | 0.014 |
| E | 0.025 | 0.000 | 0.025 | 0.025 |
| RA | 0.151 | 0.000 | 0.150 | 0.151 |
| P | 0.151 | 0.000 | 0.150 | 0.151 |
The second dataset, which details the number of COVID-19 cases during the first wave in Nepal in December 2020, was published by (Dhungana and Kumar, 2022). The data is shown as follows: 2, 2, 2, 2, 2, 2, 3, 2, 3, 3, 4, 2, 5, 5, 3, 2, 4, 4, 8, 4, 4, 3, 2, 3, 7, 6, 6, 11, 9, 3, 8, 7, 11, 8, 12, 12, 14, 7, 11, 12, 6, 14, 9, 9, 11, 6, 6, 5, 5, 14, 9, 15, 11, 8, 4, 7, 11, 10, 16, 2, 7, 17, 6, 8, 10, 4, 10, 7, 11, 11, 8, 7, 19, 9, 15, 12, 10, 14, 22, 9, 18, 12, 19, 21, 12, 12, 18, 8, 26, 21, 17, 13, 5, 15, 14, 11, 17, 16, 17, 23, 24, 20, 30, 18, 18, 17, 21, 18, 22, 26, 15, 13, 13, 6, 9, 17, 12, 17, 22, 7, 16, 16, 24, 28, 23, 23,19, 25, 29, 21, 9, 13, 16, 10, 17, 20, 23, 14, 12, 11, 15, 9, 18, 14, 13, 6, 16, 12, 11, 7, 3, 5, 5.
Table 5 Adequacy measures for fits using second dataset
| Models | AIC | BIC | CAIC | HQIC | MLE | KS | P val | Ranks |
| EnTrED | 1004.982 | 1008.012 | 1005.009 | 1006.213 | 0.172 | 0.101 | 0.091 | 1 |
| SE | 1048.172 | 1051.202 | 1048.198 | 1049.403 | 0.047 | 0.161 | 0.001 | 2 |
| E | 1058.388 | 1061.419 | 1058.415 | 1059.619 | 0.086 | 0.188 | 4.1e-05 | 3 |
| RA | 1087.025 | 1090.055 | 1087.051 | 1088.256 | 0.516 | 10612 | 2.2e-16 | 4 |
| P | 1087.025 | 1090.055 | 1087.051 | 1088.256 | 0.516 | 10595 | 2.2e-16 | 5 |
Table 6 95% Confidence interval estimates for second dataset
| Models | Estimate | SE | 95% Lower CI | 95% Upper CI |
| EnTrED | 0.172 | 0.001 | 0.170 | 0.174 |
| SE | 0.049 | 0.000 | 0.048 | 0.049 |
| E | 0.086 | 0.001 | 0.085 | 0.087 |
| RA | 0.517 | 0.003 | 0.510 | 0.523 |
| P | 0.517 | 0.003 | 0.510 | 0.523 |
The third dataset can be found in (Banerjee and Bhunia, 2022), and it details the survival periods (in days) of guinea pigs that were given various amounts of tubercle bacilli. The dataset includes the following: 12, 15, 22, 24, 24, 32, 32, 33, 34, 38, 38, 43, 44, 48, 52, 53, 54, 54, 55, 56, 57, 58, 58, 59, 60, 60, 60, 60, 61, 62, 63, 65, 65, 67, 68, 70, 70, 72, 73, 75, 76, 76, 81, 83, 84, 85, 87, 91, 95, 96, 98, 99, 109, 110, 121, 127, 129, 131, 143, 146, 146, 175, 175, 211, 233, 258, 258, 263, 297, 341, 341, 376.
Table 7 Adequacy measures for fits using third dataset
| Models | AIC | BIC | CAIC | HQIC | MLE | KS | P val | Rank |
| EnTrED | 790.567 | 792.843 | 790.624 | 791.473 | 0.020 | 0.134 | 0.153 | 1 |
| SE | 805.941 | 808.217 | 805.998 | 806.847 | 0.006 | 0.193 | 0.009 | 2 |
| E | 808.884 | 811.161 | 808.941 | 809.791 | 0.010 | 0.211 | 0.003 | 3 |
| RA | 856.749 | 859.026 | 856.806 | 857.655 | 0.060 | 59703 | 2.2e-16 | 4 |
| P | 1752.437 | 1754.714 | 1752.494 | 1753.343 | 0. 060 | 3.05e+11 | 2.2e-16 | 5 |
Table 8 95% Confidence interval estimates for third dataset
| Models | Estimates | SE | 95% Lower CI | 95% Upper CI |
| EnTrED | 0.0200 | 0.0000 | 0.0200 | 0.0201 |
| SE | 0.0057 | 0.0000 | 0.0057 | 0.0057 |
| E | 0.0100 | 0.0000 | 0.0100 | 0.0100 |
| RA | 0.0601 | 0.0001 | 0.0600 | 0.0602 |
| P | 0.0601 | 0.0001 | 0.0600 | 0.0602 |
As presented in Tables 3, 5 and 7, the results on the application of the EnTrED to real dataset compared to six other models revealed the applicability of the new model. It can be observed that the EnTrED has the smallest of all the information criterions (i.e., AIC, BIC, CAIC and HQIC). The profound implication of these findings is the EnTrED model’s supremacy in terms of adequacy and goodness of fit. The exceptional performance of the model is expressed in the consistently lower AIC, BIC, CAIC, and HQIC values, irrespective of dataset characteristics and shows its versatility and adaptability. This remarkable ability to capture the underlying data generation mechanisms more effectively positions the EnTrED as a formidable tool for researchers across diverse scientific areas. Its statistical flexibility and adequacy are invaluable assets in modelling complex data structures, offering researchers an advanced and dependable distribution for intricate statistical modeling and analysis tasks.
Results in Tables 4, 6 and 8 summarizes the parameter estimates along with their, standard errors and 95% confidence intervals for the models across the three data sets. The results presented provides insights into the precision of the estimates and the range within which the true parameter values are likely to fall with a specified level of confidence. As observed, the parameter estimates all fell within the 95th percent confidence interval and the difference between the upper and lower CI showed that EnTrED, SE, and E had the smallest value, thus indicating that they provide a better fit for the data sets.
4 Conclusion
In this study, ErTrED is proposed. Various statistical and reliability attributes of EnTrED, including moments, moment generating function, quantile function, hazard rate function, and mean, as well as order statistics, were examined and derived. Additionally, a rigorous simulation study was executed to assess the stability of the Maximum Likelihood Estimates (MLE) for EnTrED’s parameters, revealing their robust behavior as sample sizes increased.
To demonstrate the flexibility and adequacy of the EnTrED distribution, an empirical data analysis was carried out. The goodness of fit of the EnTrED model was scrutinized using three distinct datasets as test cases. A comparative analysis ensued, fitting the EnTrED against competing distributions, including the Sine Exponential, Exponential, Ram Awadh and Prakaamy distributions. The results of this extensive empirical data analysis pointed to the EnTrED exhibiting better fitting capabilities across the datasets. This compelling outcome underscores the potential of EnTrED as the distribution with the most adequate fit, affirming its position as a valuable tool for researchers and practitioners alike. Parameter estimation methods influences parameter estimates of a density function. In this study, we utilized the Maximum Likelihood Estimation (MLE) method. As a suggestion for future research, we recommend exploring alternative estimation methods for the EnTrED. This exploration can provide valuable insights into the robustness and accuracy of parameter estimation in diverse modeling scenarios.
References
Aziz, A., Husain, Q., and Ahmed, M. (2021). The Entropy Transformed Rayleigh Distribution: Properties and Applications. In Journal of Physics, 1818(1), 1–12.
Banerjee, P., and Bhunia, S. (2022). Exponential Transformed Inverse Rayleigh Distribution: Statistical Properties and Different Methods of Estimation. Austrian Journal of Statistics., 51(14), 60–75.
Chesneau, C., Kumar, V., Khetan, M., and Arshad, M. (2022). On a modified weighted exponential distribution with applications. Mathematical and Computational Applications., 27(1), 17.
Dhungana, G. P., and Kumar, V. (2022). Exponentiated Odd Lomax Exponential distribution with application to COVID-19 death cases of Nepal. PloS one, 17(6), e0269450.
Dragan, I., and Isaic-Maniu, A. (2019). An innovative model of reliability—The pseudo-entropic model. Entropy, 21(9), 846.
El-Damrawy, H., Teamah, A., and El-Shiekh, B. (2022). Truncated bivariate Kumaraswamy exponential distribution. J. Stat. Appl. Pro., 11, 461–469.
Isa, A., Bashiru, S., Ali, B., and Adepoju, A. (2022). Sine-Exponential Distribution: Its Mathematical Properties and Application to Real Dataset. UMYU Scientifica., 1(1), 127–131.
Nelsen, B. R. (1987). Consequences of the memoryless property for random variables. The American Mathematical Monthly,, 94(10), 981–984.
Owoloko, E., Oguntunde, P., and Adejumo, A. (2015). Performance rating of the transmuted exponential distribution: an analytical approach. SpringerPlus., 4, 1–5.
Ozkan, E., and Golbasi, G. S. (2023). Generalized Marshall-Olkin exponentiated exponential distribution: Properties and applications. PLoS One., 18(1), e0280349.
Percontini, A., Gomes-Silva, F., da Silva, R., and Handique. (2021). The McDonald Lindley-Poisson Distribution. Pakistan Journal of Statistics and Operation Research., 3(1), 1095–1112.
Shukla, K. (2018). Prakaamy distribution with properties and applications. JAQM, 30–38.
Tashkandy, K., Nagy, M., Akbar, M., Mahmood, Z., and Gemeay, A. (2023). The Exponentiated Cotangent Generalized Distributions: Characteristics and Applications Patients of Chemotherapy Treatments Data. IEEE Access., 13.
Biographies

Mathew Stephen earned his Diploma and B.Sc. in Statistics from The Federal Polytechnic Mubi, Adamawa State, and Federal University Wukari, Taraba State, Nigeria, in 2014 and 2018, respectively. He later completed an MSc in Statistics at Federal University Wukari, Taraba State, Nigeria, and currently works as an Assistant Lecturer at Kwararafa University, Wukari, Taraba State, Nigeria.

David Ikwuoche John obtained his B.Sc. and M.Sc. in 2009 and 2012 respectively, from the Department of Mathematics, Ahmadu Bello University, Zaria-Nigeria. In 2021 he obtained his Ph.D in Statistics from the Department of Statistics, Ahmadu Bello University, Zaria-Nigeria. Currently he is a Senior Lecturer and Departmental Postgraduate Co-ordinator for Mathematics and Statistics programs in the Department of Mathematics and Statistics, Federal University Wukari, Nigeria.

Yaska Mutah is affiliated with The Federal Polytechnic Mubi and holds a Bachelor of Science degree in Statistics from the University of Maiduguri, a Master of Science degree in Statistics from Modibbo Adama University of Technology, Yola, and a Postgraduate Diploma in Education from Usman Danfodio University of Sokoto. He is currently pursuing a PhD in Statistics at Modibbo Adama University, Yola. Additionally, he is an active member of professional organizations such as the Nigerian Statistical Association (NSA), the Mathematical Association of Nigeria (MAN), and the Teachers Registration Council of Nigeria (TRCN). His contributions include numerous publications in reputable journals and conferences.
Journal of Reliability and Statistical Studies, Vol. 17, Issue 1 (2024), 17–44.
doi: 10.13052/jrss0974-8024.1712
© 2024 River Publishers