Stochastic Evaluation of a Duplicate Standby System via Semi-Markov Processes
Parmender, Vikas Garg and Amit Kumar*
Department of Mathematics, Chandigarh University, Gharuan, Mohali, Punjab, India-140413
E-mail: booraparmender@gmail.com; gargvikas0314@gmail.com; amitk251@gmail.com
*Corresponding Author
Received 19 May 2025; Accepted 26 October 2025
Abstract
This paper presents a stochastic evaluation of a repairable system consisting of two identical operative units in parallel and one cold standby duplicate unit. The system is modeled using a Semi-Markov process framework combined with the regenerative point technique, which enables the treatment of general repair time distributions beyond the exponential assumption common in classical Markovian models. The novelty of the study lies in jointly analyzing reliability and economic measures-including Mean Time to System Failure (MTSF), steady-state availability, busy period of the repair facility, expected number of repairs, and long-run profit-under a unified framework. Instantaneous activation of the standby unit is incorporated without switchover delay, and its independence from the repair queue is explicitly considered. Numerical and graphical illustrations are provided to compare system performance across different redundancy strategies and to highlight the sensitivity of reliability indices to failure and repair rates. The results show that failures of original units exert a stronger impact on system reliability than those of the duplicate unit, while enhancing repair efficiency significantly improves both availability and profitability. The proposed modeling approach provides practical insights for the design of highly reliable and cost-effective systems in applications such as data centers, manufacturing, and safety-critical infrastructures.
Keywords: Stochastic modeling, MTSF, duplicate unit, reliability, regenerative point, probabilistic analysis.
1 Introduction
Reliability is a cornerstone of engineering and system design, ensuring that systems consistently perform their intended functions over time without unexpected failures. In safety-critical sectors such as healthcare, aerospace, industrial automation, and digital services, reliability directly influences operational continuity, cost efficiency, and user trust. Redundancy is a widely adopted technique to enhance reliability by allowing a system to remain operational even when one or more components fail. Among redundancy strategies, standby configurations particularly cold standby-are attractive because the standby unit remains inactive until required, thereby avoiding wear and degradation during idle periods and offering a cost-effective solution compared to continuously active redundancy.
A number of studies have investigated reliability modeling of repairable and redundant systems under varying conditions such as human error, switching failures, reboot delays, and preventive maintenance. These works provide valuable insights but are often constrained by simplifying assumptions, such as exponential repair distributions or a narrow focus on individual performance measures. Moreover, few studies simultaneously address both reliability and economic aspects under a unified stochastic framework. The present work addresses these limitations by analyzing a repairable system consisting of two operative units in parallel supported by a cold standby duplicate unit. The system is modeled using the Semi-Markov process framework in conjunction with the regenerative point technique, which enables the treatment of general repair time distributions beyond the exponential case. This approach allows for a realistic representation of repair processes and supports comprehensive evaluation of performance indices. Numerical and graphical illustrations are provided to demonstrate the sensitivity of system measures to variations in failure and repair rates, thereby offering practical insights into system design and management.
The novelty and contributions of this paper can be summarized as follows:
1. General repair modeling: Incorporation of general (non-exponential) repair time distributions using a Semi-Markov and regenerative approach.
2. Unified framework: Joint analysis of reliability and economic measures, including Mean Time to System Failure (MTSF), availability, busy period, number of repairs, and profit.
3. Explicit standby behavior: Consideration of instantaneous activation of the cold standby unit without switchover delay and clarification of its independence from the repair queue.
4. Comparative analysis: Discussion of differences between cold standby, active redundancy, and alternative standby strategies (e.g., warm standby).
5. Practical sensitivity insights: Identification of the stronger influence of original unit failures compared to standby failures, and the role of improved repair efficiency in enhancing availability and profitability.
One of the most effective techniques for enhancing system reliability is the incorporation of redundancy. In such configurations, systems remain operational even if one or more components fail, thereby ensuring continuous and uninterrupted service. The importance of reliability in industrial environments lies in its positive impact on customer satisfaction, productivity, brand reputation, and maintenance costs. Redundant designs also offer advantages such as backup capability and load sharing, which contribute to improved fault tolerance and resource utilization.
A system model with a standby duplicate unit subjected to random shocks during repair was analyzed by Mahmoud et al. [1]. Several other studies, including those by Cao et al. [2], Rander et al. [3], Mahmoud et al. [4], Kadyan et al. [5], Kumar et al. [6], Kumar et al. [7] have examined repairable systems under imperfect coverage. Kumar and Shekhar [8] investigated a two-unit repairable system within a Bayesian framework, incorporating imperfect coverage, detection delay, and reboot dynamics. Using exponential assumptions and Monte Carlo simulations, they derived posterior estimates for system performance measures, highlighting the effectiveness of Bayesian inference in addressing parameter uncertainty and reliability evaluation. In addition, numerous reliability studies have modeled redundant repairable systems to address challenges such as switching delays and reboot processes [9]. These investigations consistently underscore the significant impact of such factors on system availability and operational efficiency.
Jain et al. [10] analyzed the reliability characteristics of a system consisting of three identical units, where two units operate simultaneously while the third serves as a cold standby with delayed service initiation. In recent years, the matrix method has emerged as an effective tool for sensitivity analysis in reliability modeling, particularly for systems involving standby configurations, vacation policies, and common-cause failures in safety-critical applications (cf. [12, 13, 14]). Jadhav and Kumar [17] examined a coal feeding system using Markov modeling, evaluating reliability indices, sensitivity, and profit analysis. Kumar and Kumar [18] investigated IoT-based garbage data collection systems through Markov birth–death modeling, identifying the weakest sensors via sensitivity analysis. Kumar and Ram [19] modeled a decomposition unit under fail-back and degradation modes, deriving reliability indices through stochastic analysis. Kumar et al.[20] applied a continuous-time Markov process to wireless sensor networks, highlighting reliability, MTTF, and critical component identification.
Sharma and Rana [21] proposed a Bayesian-regularized NAR-ANN model to improve software reliability growth prediction, addressing overfitting issues in ANN-based SRGMs and demonstrating enhanced accuracy on real-world failure datasets. Thakur and Sharma [22] evaluated software reliability using Lindley, Beta-generalized Lindley, and a newly extended Lindley distribution, showing that the NLD model outperformed others across multiple datasets based on AIC and BIC criteria. Kavita and Sharma [23] studied software reliability under upgrade and preventive maintenance policies using regenerative point and semi-Markov approaches, deriving reliability measures such as MTTF, availability, and profit under Weibull failure distributions.
2 System Description
Assumptions:
• The system consists of two identical operative units functioning in parallel, with a third unit serving as a cold standby duplicate.
• Upon the failure of any operative unit, the standby unit is activated immediately and replaces the failed unit without switchover delay.
• The standby unit remains in cold standby mode until deployment, implying no degradation occurs while inactive.
• A single repair facility is available, and repair begins immediately upon detection of a failure.
• All units (original and standby) are restored to an “as-good-as-new” condition after repair, i.e., perfect repair is assumed.
• The system remains operational as long as at least one of the two original units is functional.
• The system enters a failed state (complete shutdown) when both original units fail simultaneously or sequentially before replacement is initiated.
Notations:
The notations used in the model are defined as follows:
: Probability of transition from state to state .
: Probability of reaching state from via intermediate states , , and .
: Mean time to exit regenerative state before entering from .
: Mean sojourn time corresponding to the state.
: Constant failure rate of an original unit.
: Constant failure rate of the duplicate unit.
: PDF of repair time for an original unit.
: PDF of repair time for the duplicate unit.
: CDF of repair time for an original unit.
: CDF of repair time for the duplicate unit.
: Original unit / duplicate unit is operative.
: Duplicate unit in cold standby mode.
Duplicate unit waiting for operation.
: Original unit under repair / waiting for repair.
: Duplicate unit under repair / waiting for repair.
: Failed original unit undergoing continuous repair from its prior state.
: Duplicate unit awaiting continuous repair from its prior state.
: Laplace-Stieltjes convolution / Laplace convolution.
Laplace / Laplace-Stieltjes transformation.

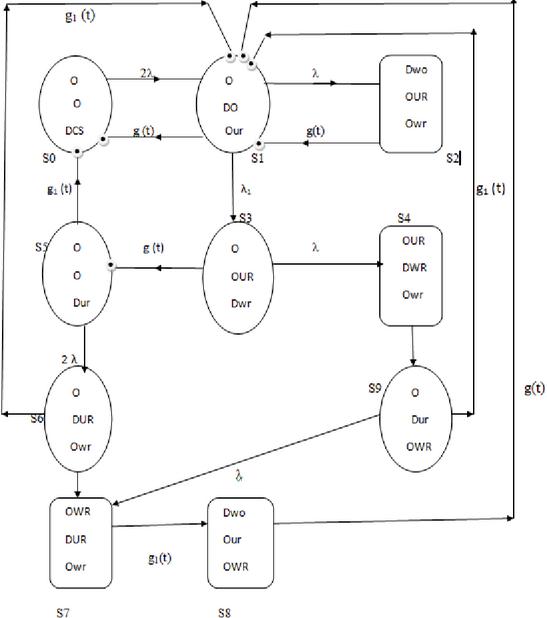
Figure 1 Transition diagram.
3 Transition Probabilities
The different probabilities of transitioning to a steady state are as follows:
| (1) |
Also, it can be verified very easily that
| (2) | ||
4 Mean Soujourn Time
The mean soujourn time () corresponding to various states () of the system are defined by following relation:
| (3) | ||
5 Mean Time to System Failure
Considering the failed state as an absorbing state and as the initial transition point from the regenerating state either to any other regenerative state or to any failed state, the following recursive relations for are given:
| (4) | ||
Using the Laplace-Stieltjes transform of the above expression and solving for ,
| (5) |
where
| (6) | ||
6 Availability Analysis
Let the system enter regeneration state at . Denote by the probability that the system is in the up state at any instant . The recursive relations for are given as follows:
| (7) | ||
where
| (8) |
with denoting the probability that the system remains in the up state, starting in , at time without visiting any other regenerative state. Applying the Laplace transformation to Eq. (7) and solving for , the steady-state availability is obtained as
| (9) |
where
| (10) |
7 Analysis of Busy Period of Server
Suppose the system enters regenerative state at . Let denote the probability that the server is busy at any instant . The recursive relations for are expressed as:
| (11) | ||
Here, represents the probability that the server remains in state during repair up to time , without transitioning to another regenerative state or returning to the original state through a non-regenerative state.
| (12) | ||
Taking LT of relations (11) and solving for using Cramer’s rule yields the long-run time for system repair as:
| (13) | |
| (14) |
and is already established in (6).
8 Expected Number of Visits by Server
Let represent the estimated number of server visits in (0,t).
| (15) | ||
Taking LST of above relations (15) and solving for ,using Cramer’s rule and calculating the expected number of visits per unit time as
| (16) |
where
| (17) |
and is already described in (6).
9 Profit Evaluation
The system profit function (profit per unit time) is defined as
| (18) |
where
(i) = fixed revenue per unit up time of the system,
(ii) = cost per unit time when the server is busy for repair,
(iii) = charge incurred by the server for each visit,
(iv) = steady-state availability (long-run fraction of time system is up),
(v) = steady-state fraction of time the server is busy,
(vi) = expected number of server visits per unit time in steady state.
10 Graphical Representation
Graphical analysis of the reliability measures has been performed to illustrate their variation with respect to system parameters. Figures 2, 3, and 4 show the behavior of the Mean Time to System Failure (MTSF), availability, and profit, respectively, as functions of various failure and repair rates. The results indicate that all three measures decrease noticeably as the failure rates of both the original and duplicate units increase. Moreover, the failure rate of the original unit has a more pronounced effect on system performance compared to that of the duplicate unit. Conversely, increasing the repair rates of both units leads to improvements in availability and profit, as depicted in Figures 3 and 4. These findings underscore the crucial importance of effective repair strategies in enhancing overall system reliability and economic outcomes.
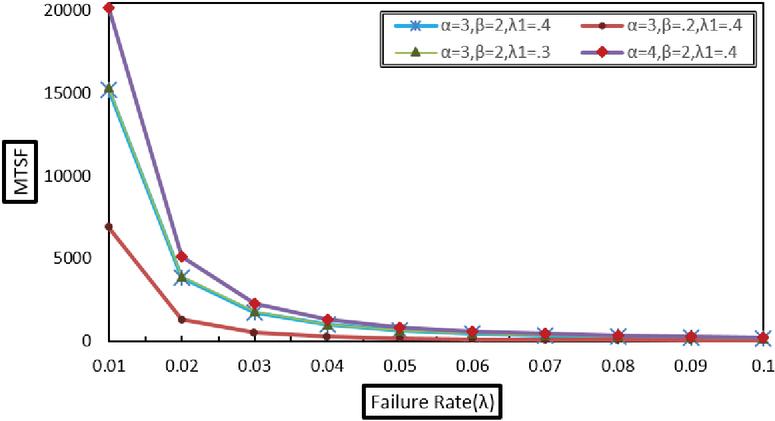
Figure 2 Variation of MTSF with failure rate ().
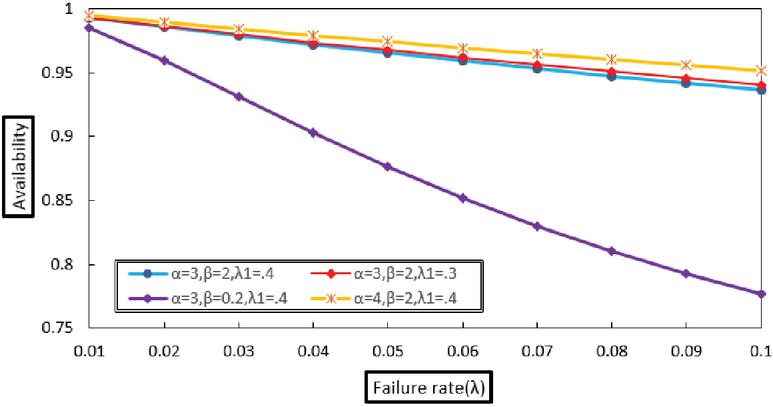
Figure 3 Variation of availability with failure rate ().
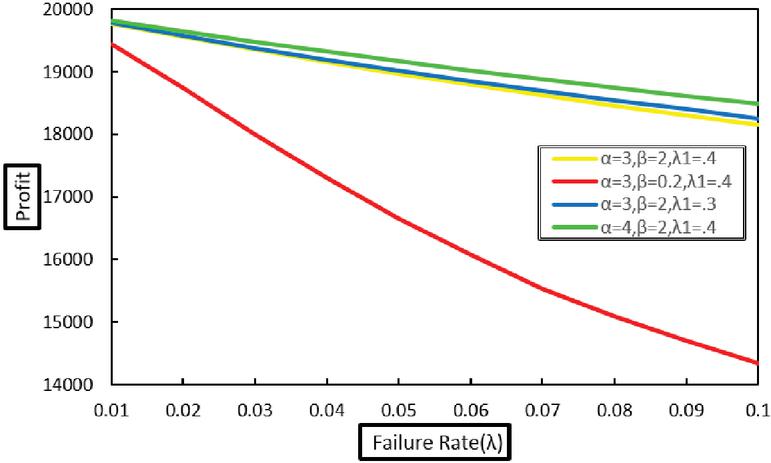
Figure 4 Variation of profit with failure rate ().
11 Illustrative Example and Technical Insights
The proposed model, stochastic evaluation of a duplicate standby system via Semi-Markov Processes, can be illustrated through a real-life example of a data center. In such an environment, two servers operate simultaneously to handle digital workloads, while a third server is maintained in cold standby mode. The standby server does not undergo degradation while idle and is activated immediately if one of the primary servers fails. The system continues to function as long as at least one of the two primary servers remains operational. A single technician is responsible for repairing failed units, with repairs assumed to restore servers to an “as-good-as-new” condition. Failures are modeled with exponential distributions, whereas repair times are represented by general distributions to capture real-world variability more accurately. The Semi-Markov process (SMP) combined with the regenerative point technique is employed to model the system’s behavior and to evaluate performance measures such as Mean Time to System Failure (MTSF), availability, and technician workload. This modeling framework is highly useful for analyzing system reliability and cost-effectiveness. For example, availability analysis provides insight into how consistently the system remains operational—an essential consideration in environments governed by strict uptime agreements. The model also accounts for the busy period of the repair technician and the expected number of repair interventions, offering valuable input for resource allocation and maintenance scheduling. Profit analysis further integrates operational revenue, repair costs, and service visit charges, enabling a holistic assessment of economic performance. The applicability of this approach extends beyond data centers to manufacturing systems with robotic machines, hospital settings with standby medical equipment, and transportation networks incorporating redundant safety mechanisms. Overall, the model provides decision-makers with a practical tool to optimize system design by balancing reliability, maintenance efficiency, and economic viability.
12 Real Life Applications
In real-life scenarios, this model is effectively applied in data centers, where two servers operate simultaneously to handle continuous workloads, and a third server is kept in cold standby mode. If one of the main servers fails, the standby is immediately activated without any delay, ensuring uninterrupted digital services. The failed unit is sent for repair while the system continues functioning with the available units. This setup not only enhances reliability but also optimizes cost-effectiveness by reducing downtime, which is critical for organizations bound by strict service-level agreements. Beyond data centers, the same principle applies to hospital life-support systems, manufacturing industries with robotic equipment, and transportation networks, where uninterrupted operation is vital.
13 Conclusion
This study analyzed a system consisting of two operative original units supported by one standby duplicate unit, focusing on key performance measures. The numerical and graphical results reveal that reliability indicators such as Mean Time to System Failure (MTSF), availability, and profit decline notably with increasing failure rates of both original and duplicate units. Among these, the failure rate of the original units exerts a stronger influence on system performance. Conversely, higher repair rates for both unit types significantly enhance system reliability and profitability. As illustrated in Figures 2–-4, increasing the repair rates, denoted by and for the original and duplicate units respectively, leads to improvements in MTSF, availability, and profit.
Overall, the findings highlight the importance of reducing the failure rate of the original units as a critical strategy for enhancing both system reliability and economic outcomes. As a direction for future work, prioritizing the maintenance and operational efficiency of original units relative to the duplicate unit could further improve long-term system performance and profitability.
References
[1] M. A. W. Mahmoud, M. Y. Haggag, and A. E. B. Abd Elghany, “Stochastic analysis of a duplicated standby system subject to shocks during repair,” Journal of the Egyptian Mathematical Society, vol. 25, no. 2, pp. 186–190, 2017.
[2] J. Cao and Y. Wu, “Reliability analysis of a two-unit cold standby system with a replaceable repair facility,” Microelectronics Reliability, vol. 29, no. 2, pp. 145–150, 1989.
[3] M. C. Rander, S. Kumar, and A. Kumar, “Cost analysis of a two dissimilar cold standby system with preventive maintenance and replacement of standby,” Microelectronics Reliability, vol. 3, no. 1, pp. 171–174, 1994.
[4] M. A. W. Mahmoud and M. E. Moshref, “On a two-unit cold standby system considering hardware, human error failures and preventive maintenance,” Mathematical and Computer Modelling, vol. 51, no. 5, pp. 736–745, 2010.
[5] M. S. Kadyan, “Reliability and cost-benefit analysis of a single unit system with degradation and inspection at different stages of failure subject to weather conditions,” International Journal of Computer Applications, vol. 55, no. 6, 2012.
[6] A. Kumar, S. C. Malik, and D. Pawar, “Profit analysis of a warm standby non-identical units system with single server subject to priority,” International Journal on Future Revolution in Computer Science and Communication Engineering, vol. 4, no. 10, pp. 108–112, 2018.
[7] A. Kumar, K. Garg and V. Garg, “Enhancing Reliability and Availability Analysis of Active Redundant Repairable Network with Imperfect Coverage,” in International Conference on Control, Computing, Communication and Materials (ICCCCM), IEEE, pp. 401–405, 2024.
[8] A. Kumar and C. Shekhar, “Bayesian modeling of repairable systems with imperfect coverage and delayed detection dynamics,” Quality and Reliability Engineering International, vol. 41, no. 4, pp. 1630–1641, 2025.
[9] C. Shekhar, A. Kumar, and S. Varshney, “Load sharing redundant repairable systems with switching and reboot delay,” Reliability Engineering and System Safety, vol. 193, pp. 106656, 2020.
[10] A. Kumar, M. Boualem, and A. A. Bouchentouf, “Optimal analysis of machine interference problem with standby, random switching failure, vacation interruption and synchronized reneging,” in Applications of Advanced Optimization Techniques in Industrial Engineering, CRC Press, pp. 155–168, 2022.
[11] C. Shekhar, N. Kumar, A. Gupta, A. Kumar, and S. Varshney, “Warm-spare provisioning computing network with switching failure, common cause failure, vacation interruption, and synchronized reneging,” Reliability Engineering and System Safety, vol. 199, p. 106910, 2020.
[12] P. Jain, D. Pawar, and S. C. Malik, “Reliability measures of a 1-out-of-2 system with standby and delayed service,” International Journal of Mechanical and Production Engineering Research and Development, vol. 10, no. 3, pp. 12725–12732, 2020.
[13] C. Shekhar, A. A. Raina, A. Kumar, and J. Iqbal, “A survey on queues in machining system: progress from 2010 to 2017,” Yugoslav Journal of Operations Research, vol. 27, no. 4, pp. 391–413, 2017.
[14] M. Ram, N. Goyal, and Shivani, “Standby system reliability modeling with cost and sensitivity analysis,” International Journal of Reliability, Quality and Safety Engineering, vol. 32, no. 2, pp. 2450030, 2025.
[15] A. Kumar, “Parametric optimization of repairable systems in IoT: addressing detection delays, imperfect coverage, and fuzzy parameters,” Life Cycle Reliability and Safety Engineering Vol. 14, pp. 329–-340, 2025. doi:\nolinkurl10.1007/s41872-025-00298-6.
[16] M. Ram, S. Kharola, and N. Goyal, “Reliability and sensitivity analysis of a maintainable energy system under priority repair,” OPSEARCH, 2024. doi:\nolinkurl10.1007/s12597-024-00868-9.
[17] S. Jadhav and A. Kumar, “Feeding system’s sensitivity and reliability analysis through Markov decision process,” International Journal of Mathematical, Engineering & Management Sciences, vol. 10, no. 2, 2025.
[18] P. Kumar and A. Kumar, “Quantifying reliability indices of garbage data collection IoT-based sensor systems using Markov birth-death process,” International Journal of Mathematical, Engineering and Management Sciences, vol. 8, no. 6, pp. 1255, 2023.
[19] A. Kumar and M. Ram, “Process modeling for decomposition unit of a UFP for reliability indices subject to fail-back mode and degradation,” Journal of Quality in Maintenance Engineering, vol. 29, no. 3, pp. 606–621, 2023.
[20] A. Kumar, S. Jadhav, and O. M. Alsalami, “Reliability and sensitivity analysis of wireless sensor network using a continuous-time Markov process,” Mathematics, vol. 12, no. 19, pp. 3057, 2024.
[21] S. K. Sharma and R. K. Rana, “Advancing software reliability with time series insight: a non-autoregressive ANN approach,” Quality and Reliability Engineering International, vol. 40, no. 8, pp. 4166–4186, 2024.
[22] P. Thakur and S. K. Sharma, “Software reliability prediction and regression analysis with family of Lindley distribution,” in International Conference on Computing and Machine Learning, Singapore: Springer Nature, pp. 35–49, 2024.
[23] Kavita and S. K. Sharma, “Performance analysis of software system subject to preventive maintenance and software up-gradation facility,” Reliability: Theory & Applications, vol. 20, no. 2, pp. 120–127, 2025.
Biographies
Parmender is a research scholar in the Department of Mathematics at Chandigarh University. He earned his M.Sc. degree from Maharshi Dayanand University, Rohtak (Haryana) in 2014. His primary research interests lie in the field of reliability theory and stochastic processes. He has actively participated in several national and international conferences.
Vikas Garg is an Assistant Professor in the Department of Mathematics at Chandigarh University, Mohali. He earned his Ph.D. in Statistics from Kurukshetra University. His research interests include Reliability Theory and Stochastic Processes.
Amit Kumar is an Assistant Professor at the University Institute of Sciences, Chandigarh University, India. He holds a Ph.D. from the Birla Institute of Technology and Science (BITS), Pilani Campus, Rajasthan. His research interests include queueing theory, the machine repair problem, optimal control, reliability and maintainability, stochastic modeling, sensitivity analysis, evolutionary computation, statistical analysis, and fuzzy sets and logic. Dr. Kumar has published numerous research articles in reputed journals such as Reliability Engineering & System Safety, the Journal of Computational and Applied Mathematics, Quality Technology and Quantitative Management, and the Arabian Journal for Science and Engineering. He actively participates in conferences, Faculty Development Programs (FDPs), workshops, and symposiums as both a presenter and invited speaker. In addition, Dr. Kumar serves as a reviewer for several prestigious journals and has professional experience with the Irrigation Department, Roorkee, India. (ORCID: 0000-0001-5347-1808)
Journal of Reliability and Statistical Studies, Vol. 18, Issue 2 (2025), 473–490.
doi: 10.13052/jrss0974-8024.18210
© 2025 River Publishers