Semantics-Aware Context-Based Learner Modelling Using Normalized PSO for Personalized E-learning
Hadi Ezaldeen*, Sukant Kishoro Bisoy, Rachita Misra and Rawaa Alatrash
Department of Computer Science and Engineering, C.V. Raman Global University, Bhubaneswar, Odisha-752054, India
E-mail: hadi.talal@gmail.com; sukantabisoyi@yahoo.com; rachita.dhunu.misra@gmail.com; rawaa.alatrash@gmail.com
*Corresponding Author
Received 24 November 2021; Accepted 15 February 2022; Publication 15 April 2022
Abstract
E-learning proves its importance in the diverse educational levels over traditional education. An adaptive e-learning system needs to deduce the learner model for adding personalization to instructional websites. The learner model is the perception repository about the e-content user, which can be inferred implicitly by employing meaningful semantic analysis of the text. In this research, a novel methodology is proposed to conceptually deduce the semantic learner model for personalized e-learning recommendations. Firstly, Conceptual Learner Model (CLM) is developed based on the learner’s behavior and context-based text semantic representation by exploiting concepts from the ConceptNet knowledge base, with a significant association of patterns and rules. Then, Expanded Contextual Learner Model (ECLM) is developed by exploring the latent semantics in graphs to add concepts with the common-sense meanings that exceeded the named entities. The learner’s knowledge graph is defined based on contextually associated concepts. Semantic relations in ConceptNet are exploited to extend learner models. The Normalized Particle Swarm Optimization (NPSO) algorithm is used to learn the importance of the relation types between the concepts. Thus, CLM and ECLM each are represented as a vector of weighted concepts in which updating is obtained automatically. The proposed recommendation system incorporates dynamic learner models to predict an appropriate e-content with the highest ranking, matching the true needs of a particular learner. Our simulation results show that the performance of ECLM is better Mean Reciprocal Rank (MRR) value 0.780 than other existing methods.
Keywords: Personalized E-learning recommendation, contextual learner model, semantic analysis, knowledge graph, normalized PSO, prefix tree.
1 Introduction
The content recommender system is considered one of the most prominent strategies to personalize the pace of e-learning according to the learners’ instructional preferences. Each learner can get a customized learning plan that should adapt to learner attributes in a personalized e-learning environment as Raj and Renumol have widely studied this effect [1]. The best way to apply the optimal learning paths and in what contexts could be through association methodologies in a conceptual framework as addressed by Mangaroska and Giannakos [2]. Recently, the focus is to exploit the semantic relations more meaningfully combining with machine learning (ML) techniques to improve the accuracy of recommendations [3, 4]. This can be used to improve an augmented methodology based on a semantic network like ConceptNet [5, 6], to build the context-based semantic learner model automatically for ranking learning objects in a personalized e-learning recommendation system that is reflected in this work.
ConceptNet is a knowledge base of multilingual semantical representation, which helps the machine to understand the text, especially regarding context-based inferring within text processing and mining tasks [7]. Automated methods are used by ConceptNet to extract concepts and relationships from many renewable sources like DBpedia, WordNet, OpenCyc, and Open-source common sense while preserving the original source of each relationship within it. Reliance on these renewable knowledge resources permits an increase in the number of concepts and relationships within ConceptNet continuously [8]. Each relationship between two concepts can be represented in the form of a tuple (concept1, relation, concept2), and it is considered one of the richest bases of knowledge in semantic terms.
The current study provides a personalised e-learning recommendation strategy that helps learners identify relevant e-learning resources that fit their interests taking the benefit of a rich semantic network with the semantic analysis of the text. To represent the learner’s interests, a conceptual learner modelling methodology is proposed which takes advantage of the semantic and contextual relationships between concepts. There is also a recommendation algorithm that connects the e-content representation to the learner model.
Several studies in this subject have been conducted; all earlier works that provided conceptual models of learners on e-learning platforms use named entities to represent users’ interests. While in this work, the named-entities have been exceeded to add concepts with more meaningful text phrases utilizing common-sense knowledge captured from ConceptNet [9]. The motivation is to provide a tailored representation strategy for textual e-learning content, in which the text is represented as a sequence of consequent concepts, including the representation of entities, words, and phrases, to more meaningfully reflect the learner’s interests.
The objective is to introduce the Conceptual Learner Model (CLM) where the learner’s interests are modeled with concepts, and the Expanded Contextual Learner Model (ECLM) where contextually related concepts represent the learner’s interests as a graph, on which the recommendation algorithm is predicated. Therefore, the learner’s interests are identified by extracting the weight of each concept (term) in CLM which has been then evolved towards ECLM by employing the semantic relations in the knowledge graph. To that end, the proposed machine-based optimization approach uses Normalized Particle Swarm Optimization (NPSO) [10] to learn the significance of each type of semantic relation based on the contextual information of concepts and the semantic knowledge from ConceptNet. This resulted in finding the optimal representation of the distribution of the available semantic relation types to expand the user’s concepts to develop ECLM, which the proposed recommendation methodology relies on to recommend personalized e-content. The learner model is getting updated according to continuous observations and navigations, which are linked to different browsing actions. Association rules are applied depending on the learner’s behavior by means of semantics. This tries to overcome the lack of building an adaptive learner model and bringing individualization by providing tailor-made services during the learning process. The experiments reported significantly improved performance and better results compared to other models presented in the literature.
In this work, the following contributions have been accomplished:
• Proposed a new methodology of context-based conceptual learner modelling by automatic manner utilizing tailored text semantic representation and significant assertions with ConceptNet.
• Developed conceptual learner model (CLM) as a generated vector of weighted concepts (terms) to represent the learner’s interests, which is getting updated dynamically based on user’s behaviors.
• CLM is used to develop a robust expanded contextual learner model (ECLM) relying on the suggested machine-based optimization approach using NPSO to learn the importance of semantic relation types, where a distinct expansion is made on leaner’s concepts.
• The two presented models are evaluated in different scenarios through the proposed content-based recommendation algorithm, wherein ECLM resulted in the best performance that is better than existing models.
This suitably affects the learners and is reflected in their outcomes. What matters in this work is, expanded model with semantics and contextual information of text representation, as well as practical advice, and has been derived from the extended experiment in getting the best empirical results.
Proposed work is compared with various existing methods developed recently, as concluded in Table 2.
Remaining sections are arranged as follows; a review of the existing methods to deduce the learner model and the various techniques used has been presented in Section 2. The proposed model is introduced in Section 3. Experiments, results, and discussion are given in Sections 4 and 5 respectively. Section 6 concludes the paper along with some future research directions.
2 Related Backgrounds
Personalization through different recommendation strategies within online educational platforms has attracted many studies in the last few years, which may need more enrichment [11]. Many techniques of user modelling are utilized in previous works for personalized recommendations based on historical user data. On the other, content-based recommendation is handled from a narrow perspective and more significant research is needed. There is a huge amount of implicit information in e-learning, like prepared knowledge, complexity, and knowledge point resources that can be difficult to acquire. Hence, addressing content-based recommendation strategies for e-learning resources is not easy and smooth.
Learner’s characteristics are conceptualized through the learning pattern as a harmonizing concept, in which the interrelationships among regulative, affective, cognitive learning activities [12]. Mostly, the learner model is inferred by investigating navigation and concluded information to align the recommendation targets. Such learner’s preferences, competence and knowledge level, individual factors, and other features and certain differences are included in the learner model. To make effective use of the ontology representation and adaptive architecture, Ouf et al. [13] proposed an ontology-based framework for learner modeling by introducing learners with convenient learning objects. Their focus didn’t meet for making an extremely intelligent learning environment according to different learner’s characteristics identified conceptual modelling.
Recently, the Top-N personalized course recommendation approach is proposed by Wang et al. [14] relies on a graph convolution network. General preferences of the users are formulated by incorporating the co-category relationship and co-learning relationship into the item embedding. User’s item representations are generated by aggregate functions to learn course latent factors, utilizing the associated learners in the interaction graph and the common category semantic information. Zou et al. [15] have presented a learner modelling method for building a personalized word learning system based on linguistic theories of vocabulary learning.
In the context of delivering the educational e-content in a personalized manner, an adaptive curriculum sequencing (ACS) approach is introduced by Martins et al. [16], utilizing learners’ educational targets and their extrinsic and intrinsic information. The search for an optimal sequence of the content in ACS used different algorithms: Particle Swarm Optimization (PSO), Genetic Algorithm, Prey–Predator Algorithm, and Differential Evolution.
Most of the existing web-based recommendation systems mainly fall into the following basic classifications; Collaborative Filtering Recommendation (CFR) [17], Content-Based Filtering Recommendation (CBFR) [3, 18], and Hybrid Recommendation that relies on a combination between the two methods, needing a complicated strategy and homogeneous components [19]. CBFR tries to overcome problems like “Cold-start” from which CFR suffers for achieving decent performance. Specifically, when the extensive historical data required by the e-learning system has not yet been gathered to draw any inferences for users or items based on sufficient information, resulting in the problem of cold-start. Also, when users’ feedback data is sparse and insufficient for identifying sufficient reliable similar users, the problem of Sparsity occurs. CBFR can be classified into two methods; such as (A) “statistical content-based method” [20], and (B) “semantics-aware content-based method” [21].
2.1 Statistical Content-based Methods
Statistical content-based methods have been extensively employed in information retrieval (IR) systems to undertake qualitative statistical analysis of the text. The user model is addressed based on his/her items, then finding the similarity between the user model and the content of the object that should be suggested. These methods are used widely to analyze the massive amount of textual data available online. A statistical user model is generated by processing the textual e-content. Keyword extraction can be designed by tokenizing the corpus into words, filtering out function words, commonly-used words, or unrelated words. Several models are built by applying statistical methods such as Latent Dirichlet Allocation (LDA) [18], Tf-idf pairs [22], Bag of Words [23], Sentimental Features [24], and Hashtag Frequency [25]. According to the e-content in which the user is already interested, a model for every user can be deduced. Thus, one of these methods that integrate with a convenient algorithm can be utilized to estimate the user’s interest in a new item.
Aiming to construct a personalized recommendation system based on a statistical method of text analysis, Benzarti and Faiz [20] utilized an information retrieval method depending on different social networks. The user model has been built out of user-related content by using Tf-idf methods. Pennacchiotti et al. [22] extended the Tf-idf method upon utilizing Tf-idf-based pairs of words to form a unit for modelling the users, besides the terms of the user’s friends. Shu et al. [18] designed LDA technique-based language model to train the topic model by a statistical framework in combination with deep learning. A diverse direction in the literature has been presented by utilizing tags, particularly hashtags for modelling the user’s interests, Ma et al. [25] developed a tag-user matrix to compute the similarities between users and microblogs inside an iterative updating schema.
Modeling the user by applying methodologies based on statistical analysis has limited existence because the semantics of the text cannot be caught. The recommender system can take into consideration only the user model’s vocabulary that was part of it. Thus, the system model is not able to recommend e-content with similar meanings. Such methods lack in utilizing the semantic relations that can be deduced from the knowledge base.
2.2 Semantics-aware Content-based Methods
Many semantics-aware methods have been used to analyze the content in recommendation systems depending on named entities, thus the user model can be deduced in platforms of e-learning and social media. Researchers have mostly used concepts from a knowledge base like DBpedia [26], which are corresponding to the entities extracted from the text to represent its semantics. In this study [3] an enhanced e-learning recommendation system has been designed leveraging semantic relations to expand the user’s terms. The semantic similarity between terms and content is found utilizing DBpedia and WordNet Synsets [27]. By applying a generative ML-based model, the user model is to be a vector of relative relation to a set of e-learning categories to provide personalized e-learning content.
Based on different techniques, a method of semantic recommendation has been presented by Karidi et al. [28], wherein users’ interests were represented by using a hierarchical knowledge graph (KG). They utilized the Steiner Tree algorithm to profile users, where the categories obtained from a known taxonomy are the tree’s nodes.
Zarrinkalam et al. [29] developed a semantics-enabled user interest detection approach, wherein the associated entities which have not been represented yet in the knowledge base are temporally grouped into semantic topics. The representation of user’s interests is carried out as a hierarchical graph of interest, where spreading activation theory was used to expand it.
Piao [30] demonstrated a personalised link recommendation method based on named entities. Entities, classes, and categories are three types of associated concepts from DBpedia that have been included in the proposed user model. The temporal dynamics of user interests have been explored. Furthermore, Piao and Breslin [31] adopted a named-entity model to reflect user needs by leveraging WordNet Synsets in conjunction with DBpedia entities, presenting improved results when compared to previous work that employed the entity model. Besides, there is a considerable amount of literature on this subject, and there still exist drawbacks which some researchers hanker to consider.
State-of-the-art research that has been presented, shows a series of works that suggest different recommendation approaches based on the user model. In these previous works, users’ interests have been represented employing the named entities. As a result, entities are unable to represent the context of text; also, using extracted named entities to describe textual content is insufficient for capturing the semantics inside the text, which is a crucial aspect in learner modeling. The current work presented here is e-learning-oriented and proposes a new method of text semantic representation using ConceptNet, which concentrates on a richer set of semantic relations between compound concepts. It contributes to modeling the learner’s interests using contextual relations between concepts where the textual content of a material is represented as a set of consequential concepts. By that, entire words and types of phrases within the text can be represented, not just entities, leveraging common-sense meanings, as discussed in Section 3. It can be considered as a distinct methodology when compared to other strategies used in the field of personalized e-learning recommendations.
3 The Proposed E-learning Recommendation System
A learning system can be made powerful with an effective recommender process, initiated by a learner model, and dependent on instructional requirements using semantic and conceptual methods. To distinguish the learner preferences, a methodology of semantics-aware context-based learner modelling is presented in this section. Contextual relations between the concepts are used to build the user graph. Then, semantically the weights of the relations among the concepts are computed, taking into account the type of the relation in ConceptNet, to expand the learner model. The recommendation algorithm links the learner model with the representation of content, leveraging the learner’s behaviour. A personalized recommender system has been proposed, which aids the learner in an e-learning environment to receive textual content that is more relevant to their needs. Semantic analysis of the text is used by exploiting a rich knowledge base to expand the learner model.
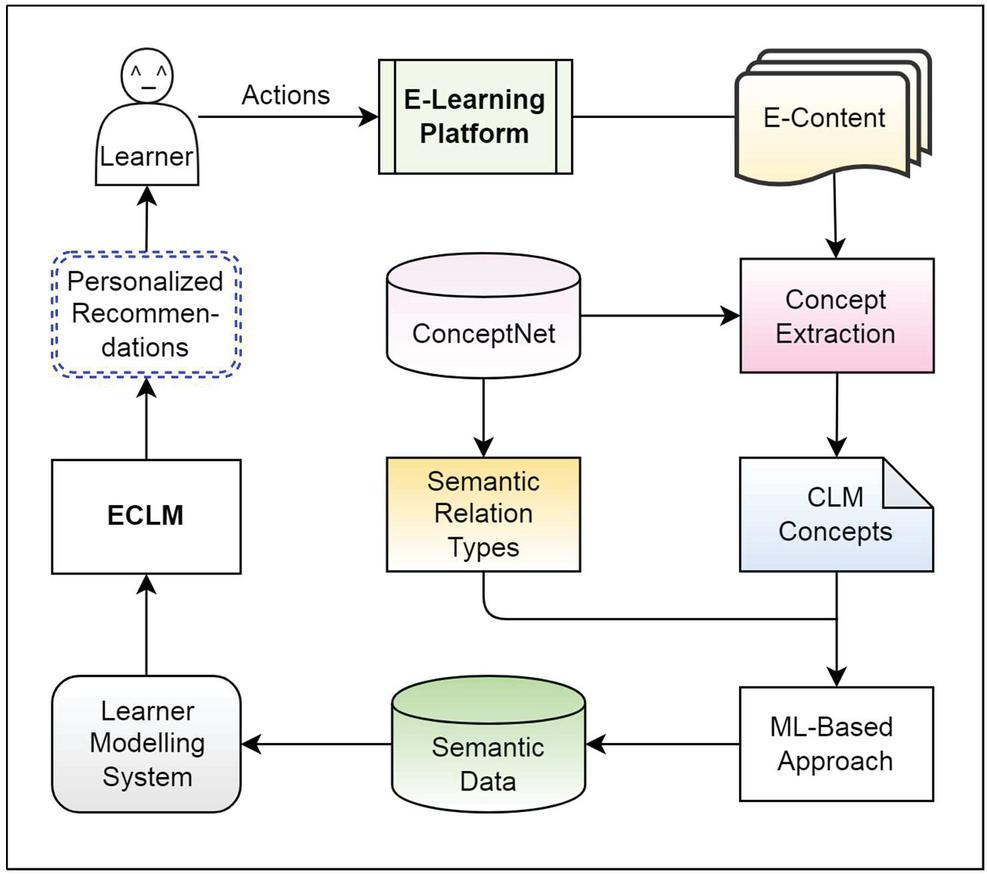
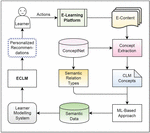
Figure 1 Personalized e-learning recommendation system framework.
The proposed recommender system (Figure 1) depends on semantic analysis of e-learning resources which is described in Section 3.1. This is to develop both proposed models CLM and ECLM as described in Sections 3.2 and 3.3 respectively. Furthermore, based on the learner behaviour, learner models are got updated automatically as suggested in Section 3.4. The proposed recommendation algorithm is presented in Section 3.5.
3.1 Context-based Text Semantic Representation
The proposed methodology of context-based conceptual learner modelling relies on generated semantic data, in which more contextual and textual knowledge are incorporated. The aim is to make use of the semantic analysis of processing the textual e-content more expressively.
Here the e-content is searched against the textual series of concepts. The English concepts of ConceptNet are taken into account since ConceptNet is regarded as a multilingual knowledge base. Extraction is done over the corresponding concepts from the ConceptNet English part. Further, the importance of semantic relation type over the concepts by using ConceptNet is computed using an evolutionary intelligence method based on NPSO.
Thus, the textual e-content is represented through extracting consequent concept series. Since the semantic knowledge base of ConceptNet is structured based on semantic assertions between the entities, so the part of the text can be converted to a concept, whenever the textual representation of this part can correspond with this concept.
As the semantics of words in Natural Language Processing (NLP) depend on associated words with predecessors, so whenever a better meaningful phrase emerges by adding more words, such words are recommended to be added.
Several tasks were conducted to preprocess the textual e-content, as follows:
– Filtering each symbol except the numbers and letters.
– Removing punctuations, stop words, special characters from the text.
– Unique words out of the textual e-content have been created (Tokenized).
The tokenized words have then been semantically represented with a set of consequent concepts which include the representation of entities along with words and textual phrases relying on common-sense meanings, by using a greedy algorithm (Algorithm 1).
Algorithm 1 is constructed to convert the textual e-content into a series of concepts. To discover whether a string denotes a prefix of some concept, Prefix Tree has been leveraged. The representation of all concepts is converted into a Prefix Tree, wherein the words are the edges of the tree. This algorithm performs well where the semantic accuracy will be more with longer phrases of words. The English concepts were extracted in the preprocessing stage, wherein the ConceptNet flat file that includes all assertions has been manipulated. In this context, we consider the assertions that link two English concepts.
Algorithm 1 Text representation series of tokenized words series of concepts
string empty array
string empty array of concepts
is an array of tokenized words; n is the length of in the input
{ if is a prefix of a concept
{
} if is an English concept extracted from ConceptNet
{
} else if is not empty
{
}
}
3.2 Building of CLM
Learner modelling is the process of identifying the learner to reach them by achieving more levels of diversity in the e-learning environment, and to know their target and why they browse a website. Learner model can be built in a way that helps to detect the essence of semantics based on learner selections with the learning objects, as well as depending on the navigation observations according to their study field. Therefore, the learner model can be considered as a vector of relative relation to a set of terms.
To assist learners in finding relevant materials, a method for implicitly building CLM is proposed. However, the principle of this model has been used in other related investigations where named entities have been used to represent the user model, whereas we propose using the concepts retrieved in a distinct manner contextually as described in Section 3.1.
The proposed methodology introduces the learner’s model as a set of weighted values corresponding to the interestingness of the learner, each value is considered as a perception percent that the learner is interested in a specific concept.
The building of CLM is based on the text semantic representation as a sequence of concepts that are extracted by Algorithm 1 (Section 3.1) using ConceptNet concepts. The learner model is to be a generated vector of weighted terms corresponding to those extracted concepts.
That means a conceptual learner model for a learner is formulated as follows:
| (1) |
As is considered a set of the available concepts of the learner, and it is needed to compute the weighted value of that reflects the interest of learner in the concept taking into consideration the selected learning objects, the following equation is given:
| (2) |
Where denotes the number of learning objects selected by the learner which include , out of the entire number of his selections , and denotes the popularity factor.
It is more desirable that the concept is not to be popular. In the recommendation process, more specific concepts are useful rather than common concepts. It is suggested that the popularity factor is to be computed from the inverse frequency with respect to the user as follows:
| (3) |
Here, indicates the all known users, indicates the number of learners having concept of interest to them.
3.3 Semantics Aware Optimization Approach for Developing ECLM
Generally, the concepts are linked to each other based on semantic relations in the knowledge graph. Thus, if a learner is concerned about a concept, this intuitively leads to the fact, the learner is concerned with other concepts that are related to this concept. To enhance the recommendations based on the learner model, the combination of semantic relations and learner modelling has been taken into account to develop ECLM.
3.3.1 Building the Learner’s Sub-knowledge Graph
It has been established that representing user interests as a set of weighted concepts is useful. It is needed to take into consideration the context where each concept is related to another so that the learner’s interests are modeled properly. A list of linked concepts in the context of each other in the learner’s set of concepts is to be obtained. The more the concepts occur in context to each other in the user’s list of concepts, the more interested that learner will be in the list of these concepts as a whole.
The context of the connected concepts of the learner are addressed by defining a sub-knowledge graph for a learner , where denotes the nodes while the edges are represented by . In , each learner’s concept is represented by node (where ), and there is an edge (where connecting two corresponding nodes ( and ), that appear in the same context among the learner’s data.
3.3.2 ECLM Design
In this context, many different semantic relation types connect concepts in the ConceptNet knowledge graph. Apart from that, appropriate semantic relations have to be concentrated for extending CLM while not all semantic relations are suitable for a more accurate recommendation.
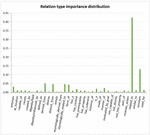
Here, thirty-four distinct types of semantic relations like “related_to,” “synonym,” and “derived_from,”…etc. (shown in Figure 7) that are retrieved from the corpus and considered knowledge dimensions1 [32]. A computational intelligence method has been presented to learn the significance of each type of semantic relation, wherein the textual and contextual information has been incorporated.
Formally, a distribution R is defined as a vector where its dimensions correspond to these types of relations; , where each dimension represents the relative importance of the semantic relation with the type .
To learn the importance of relation type, an extended training dataset for each learner is generated, which is formulated as follows:
| (4) |
Here, is a set of concepts, is the sub-knowledge graph constructed as in Section 3.3.1 that includes all user’s concepts in CLM, wherein there is an edge ending at that linked a concept belonging to .
Whenever a type of relation is significant for the recommendation process, it ought to show up frequently in for numerous learners. Consider, indicates the user interest in the concept where there is an edge linking such as in , and refers to the semantic relation type , thus:
| (5) |
For a concept that is a part of where its weight is already computed in CLM. Each concept in may link with another concept via multiple types of relations as multiple edges end at it. This leads to generalizing the Equation (5) that calculate the training weight of this concept by taking the summation of the relations type of all these edges between these two concepts:
| (6) |
Where is the semantic relation type of the edge in .
Now our objective is to obtain the best value of for enhancing the CLM, where corresponds to the importance of each type of semantic relation.
For this purpose the weight for every concept must converge to the target weight . The CLM is represented with a vector of the weighted user concepts, while the training user model includes the target weights as a vector . The concepts’ weights of both vectors must identical for perfect values of . Moreover, the dimensions of both vectors are equal to the overall concepts’ number from the user model. Aiming to measure the similarity of these two vectors, the cosine distance has been considered. Ultimately, the cosine function has to be maximized to get the better values of :
| (7) |
The above function (7) must be maximized by taking into account all learners U as follows:
| (8) |
The vector can be written in a form of multiplying the matrix with vector as given:
| (9) |
The dimensions of the matrix is ; where 34 refers to the semantic relations number captured in ConceptNet while indicates the user’s concepts number in the .
The values can be calculated by the following formula:
| (10) |
Where refers to the type of semantic relation of edge . Thus to maximize the previous function (8) considering the overall learners , the following objective function is given:
| (11) |
For and to be identical, the best values that form must be found, which will maximize the function in (11). In this context, a global search algorithm ‘NPSO’ has been utilized for this optimization problem.
3.3.3 Applying NPSO for Optimizing Relation Type Weights
The population of particles (individuals) has been formed with various instances of the vector represented types of semantic relations. Function (11) is represented as the cost function (fitness function) of the population. 1000-instances of have been created. Normalized PSO algorithm has been utilized, relying upon two conditions to get an adapted-problem PSO, as follow:
(1) The dimension values of particle in range .
(2) The summation of all dimension values must be equal to 1 for each particle.
For normalized weighted optimal attribute, NPSO is outlined as follow:
(a) Initializing: We choose one particle, every dimension is set same value to be precise , the remaining particles are assigned on a random value for each dimension random , and this n-dimensional random value quantity is one. For each particle, a random position and velocity are initialized.
Position: ; where denotes the current position of the individual , indicates the iteration step.
Velocity: , where indicates the velocity of the individual .
Best local position of the individual particles: , .
Best global position of the whole particles: , .
(b) Computing and : Every individual continues tracking its best position in search space. refers to the locally best-known solution among its neighbors. indicates the individual with the best fitness value among all individuals. Both of and have to be computed using fitness function , in (11).
(c) Updating the velocity and position: Here every particle modifies its value, based on its best-known position locally as well as others values ( and ). PSO’s goal is to accelerate every individual toward its ( and ). For every iteration, the velocity and position of entire particles are getting updated rate according to the following formulas (15) and (16) respectively:
| (12) | ||
| (13) |
Where, and are efficiency and control coefficients of NPSO. and are recognized constants as social learning ability coefficients to local and global best position respectively, each one is independent with another.
The existing coordinates have to be recorded by every particle. Sideways moves for particles are tuned by the velocity in the search space dimensions, along with and coordination, for which fitness values are calculated, then:
| (14) |
(d) Solving the normalized optimal weighted attribute: The key of our optimal weighted problem relies on finding the best solution from NPSO that represent the distribution of the relation types, under the constraint of a normalized depiction:
Otherwise do the following:
If , set , and update .
Else , set , and update .
For cross-border individuals, attractor is introduced as a spatial zoom center of NPSO. It conduces stability to search for optimizing position about population, by employing zoom mode to recall those particles to the distance of the original space of search becomes active.
To apply disturbance to global optimal individual, an attractor is used to set the particle, as follow:
| (15) |
For other particles depending on the stability of the process, using an attractor is tuned as follow:
| (16) |
Then a spatial zoom center is adjusted at time t, as follow:
| (17) |
Refresh the particle with a zoom scaling factor using the following formula:
| (18) |
(e) Repeating optimization while maximum iterations are not met; thus, has been outputted by NPSO, has the optimal solution that represents the vector ‘’ the values of all semantic relation types considered in the suggested approach.
Algorithm 2 (NPSO)
indicates the number of individuals in the swarm.
for each particle of the swarm do
initialize a uniformly distributed random vector n-dimension for each individual’s position restricted with upper bound and lower bound of the search space where; ,
Choose one particle and set each its dimension’s value
initialize the velocity of the individual where ,
Iteration t 1
Do
For each particle
Calculate fitness value using Function (11)
If is better than its best fitness value recorded until this time
Set the current value as the new ,
End If
End For
Choose the particle having the maximum as ,
For each particle
Find random numbers where:
Assign values efficiency and control coefficients ,
for each dimension do
Update the velocity of the individual
Update the position of the individual
If particle , where , Not Satisfied then
If
Set , and Update
Else
Set , and Update
Do disturbance to using an attractor
Do for other particles using an attractor
Set a spatial zoom center , at time t
Refresh particle with a zoom scaling factor for the particle
End If
End for
While maximum iterations are not met
Output as the optimal solution
3.3.4 ECLM Formularization
The vector of the relative semantic relation types has been resulted by the machine-based optimization approach utilizing NPSO, which is needed to develop ECLM. Here, an expansion is made by adding relevant concepts from the knowledge graph to the user’s model whose interest is converged to these new concepts, where comprises all learner concepts extracted in Section 3.1. Thus, ECLM is defined as follow:
| (19) |
Here relying on the best solution of NPSO to exploit the semantic relations as a computed vector vector, is to be computed concerning edge with the relation type :
| (20) |
Where denotes the popularity of concept as a penalty factor.
3.4 Automatically Updating the Learner Model
Learners’ navigations properly express the attributes online and reflect their interests. The interests of a learner are represented as a set of weighted values corresponding to a series of concepts; each value measures the learner’s interest in a specific concept, so let be a set of possible concepts of the learner model as follows:
Such as “semantic_analysis” and “ontology” would be represented by respectively, and so on.
Thus, the learner model of a learner is considered as a set of the original values as follows:
Where, signifies the certitude to which the learner model is related to the term with this given weighted value.
The learner model is defined here as semantic-based weighted concepts, and the behaviour is defined as surfing action of scientific content related to the learner’s concepts (terms). That is, should be automatically updated based on the behaviour. In CLM and ECLM, these weighted values of the learner’s concepts are within the range [0,1]. It suggested that the value zero denotes complete uncertainty whether the learner is interested in a concept or not, whereas, the value ‘1’ denotes outright certainty of the learner is interested in.
The updating of the learner model’s weighted values in is dependent on what the learner has done online, which is browsing (selecting) materials linked to certain terms, taking into account the semantic relationship between these terms and the learning material.
Formally, let be the set of actions that a learner can do:
So, let be the updated value of the original value , then this is the certitude of the learner acting linked to term .
Therefore, suppose is the current weighted value of the learner’s interest in the term “semantic_analysis,” and that learner has surfed a relevant material such as “ConceptNet knowledge graph” so that will be changed. Let this change be that is related to the current value , essentially the higher the probability the greater is the certitude ratio unless the original probability ratio is zero. Also, changes are related to the original value because the ratio of change must be related to the original coefficient of change that expresses the original weight of the learner’s interest in the concept. Besides, this value cannot exceed a certain value which is the sum of all the posts submitted by all actions associated with , taking into consideration that the max value is 1.
The increment must be proportional to the distance from the maximum value, so will also become proportional to the maximum value. That is, the further away we are from the maximum value, the greater the increment.
In this context for a learner , if the learner model has a concept with value , this value would be influenced and changed by doing any action associated to , as follows:
Initially, there is no action associated to , hence .
| (21) |
Here, the original value is obtained using Equation (2) when CLM is applied or is captured by Equation (20) when ECLM is used. indicates the change of value after the learner has acted , which is to be computed as follows:
| (22) |
Whenever a learner’s interest in a certain term increases dramatically, it would be accompanied by a reduction in interest in another concept. So, to keep the learner model dynamically updated corresponding to the recent interestingness, the oldest term with the certitude value for which the learner has not been surfing materials included it anymore, and has the same certitude value , needs to be adjusted. Thus for the correct tie-up of values for the term in which has been modified by adding value , and therefore must be decreased by the same amount of change. That is;
| (23) |
In this way; the weighted values of the terms from the learner model to which this material is linked are to be changed as explained above using Equations (21), (22), and (23).
3.5 Personalized Recommendation Algorithm
The goal of the proposed learner modelling methodology is to recommend the best learning objects that are more relevant to the learner. To accomplish this, integration is done on the learner models as part of the recommender system.
As per the learner model of a learner is automatically deduced and can be represented by:
So that, the values obtained by Equation (21) are to be tracked to server the recommendation algorithm.
The recommendation algorithm works to rank the learning objects according to the learner model, which is needed to assign a measured value for each learning object concerning the interests of the learner . The weighted values of the learner’s concepts are then used to rank the learning objects for providing a relevant recommendation list to the learner.
Each learning object is represented as a sequence of concepts , wherein is defined as a normalized summation of for each concept included in as given:
| (24) |
By running the algorithm using the testing data (Section 4) relying on each model CLM and ECLM, personalized Top- recommendations of e-learning objects depending on their ranked values are to be provided as a ranked list to the learner.
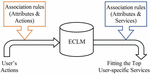
Our proposed recommendation algorithm can be used as a new recommender system, which can also be utilized to enhance existing recommendation approaches for e-learning systems. Figure 2 illustrates the process of the proposed service model. As shown in figure user actions are considered after applying association rules in the ECLM and then it provides user specific services.
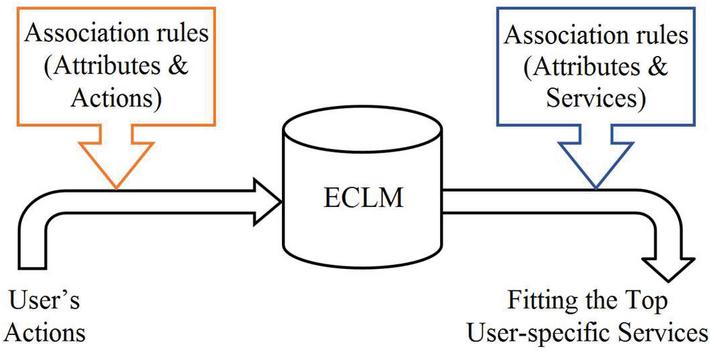
Figure 2 Process of the proposed service model.
4 Experiment Setup
To implement the proposed learner modeling methodology, it is needed to extract the semantic relations between the e-learning terms (concepts) and e-learning objects (scientific materials) based on the learner’s selections. The learner model is generated using knowledge base and the semantic and context-based text representation using ConceptNet English part [9].
4.1 Dataset
The methodology is assessed using data collected in an educational setting that reflects a true learning process of a group of students from our university.
First, educational e-content of materials were collected, which are linked to different terms. These data were adopted depending on the recommendation of experts in our university, which reflects the actual needs of a real learner.
These materials have been gathered from E-Library,2 Nptel.ac.in, and Coursera.org. This e-content is as a larger improved data volume of the recent publication dataset used in the state-of-the-art study that has been conducted by Ezaldeen et al. [3].
Second, a survey is carried out by using Google form in order to capture the user selections out of these materials. Data of 290 learners’ selections has been gathered which form the dataset. Where each learner would select 15 materials that are relevant to his interests. The interests of the learner have been formulated by the weighted user’s concepts extracted from his selections of materials. Some statistics about the collected Educational Data Sets (EDS) used in the experiments are listed in Table 1.
Table 1 Dataset perception
| Number of learners | 290 |
| Number of scientific materials | 150 |
| Learner’s selection of materials | 15 |
| Mean of Discrete words’ number in material approximately | 10593 |
| Mean of Discrete concepts’ number in material approximately | 1796 |
EDS is split into two sets: for the training process, 75% of the dataset has been taken that comprises of each user’s selection of materials. For the evaluation process, 25% is the testing set was disseminated evenly for all learners. For accomplishing this, the first 10 user’s selections are used for training the model, remaining selections are kept for testing.
The evaluation of our proposed recommendation methodology would require a public or large dataset, which is difficult due to API Rate limits of any reliable educational portal with respect to following the users’ usage data. EDS proves the merit of our method, in more real-life and less biased datasets. This manner is alike to the recent research carried out by Karidi et al. [28], where they evaluated their method and presented the experimental results using a small dataset for 100-user. The lack of suitable available public datasets led to the difficulty to appraise the contribution of some of the proposed methods.
4.2 Semantic Representation of the Textual Content
As it is elaborated earlier, for each e-content, the noise has been cleaned by utilizing various operations of preprocessing as mentioned in Section 3.1.
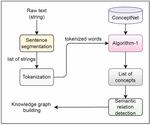
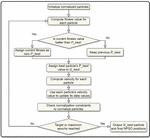
Then Algorithm 1 has been applied to these extracted words to obtain a list of concept representations and the contextual relations among them for building the knowledge graph. Figure 3 describes the information extraction architecture. The machine-based optimization approach is applied to detect the weighted semantic relation types of ConceptNet. The normalized weighted optimal solution is outputted by the NPSO algorithm as shown in Figure 4. To perform a comparison with others, the track of concept representation along with word representation has been recorded.
In our experiments, Python environment with the SpaCy package for NLP was used, along with the ConceptNet package (5.7)3 to work with the ConceptNet English part, which supports variant practical textual-reasoning tasks over documents.
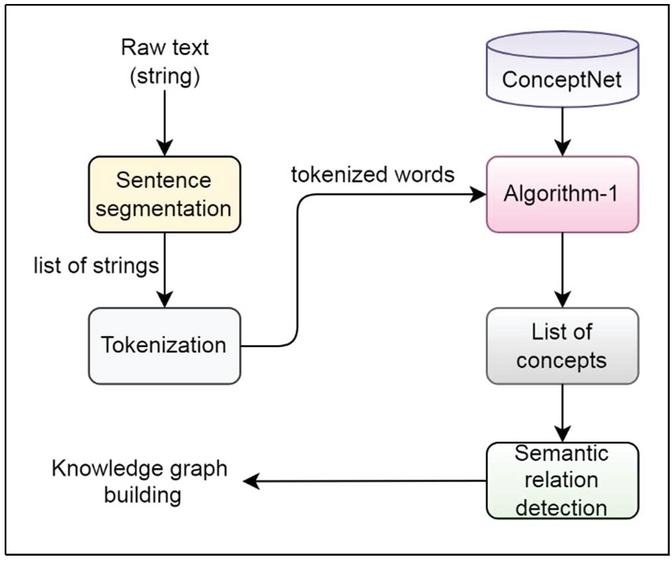
Figure 3 Text semantic representation.
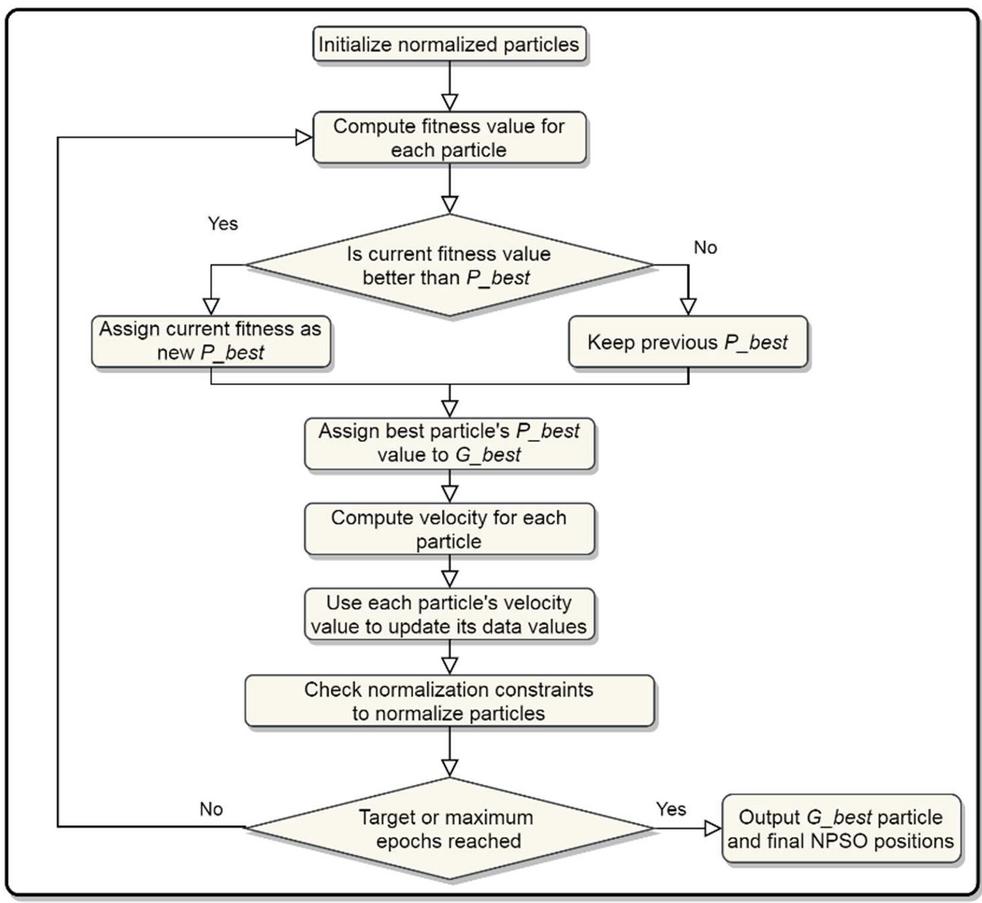
Figure 4 NPSO flowchart.
5 Evaluation and Discussion
The proposed methodology is suggested to deduce CLM automatically, along with the evolutionary model ECLM. The semantic relations with candidate concepts from the ConceptNet knowledge base have been utilized in expanding the primitive terms, to enrich the semantic linking between learners’ terms with the learning objects. Efficient results are reflected by building CLM integrated for developing the robust learner model ECLM relies on semantics aware optimization approach, in which more contextual and textual knowledge is incorporated. Where the proposed recommendation algorithm (Section 3.5) is based on the ranking of learning objects using the user concepts shared in each one.
The validation of the proposed recommender system performance has regarded the results of the recommendation methodology based on the two suggested models CLM and ECLM, along with applying other methods that are presented below:
– Tf-idf-Based Model (TFM): It is considered the baseline model utilizing information retrieval for user modelling based on Tf-idf [20], the unseen objects have then been ranked by employing this statistical method.
– Tf-idf Pairs-Based Model (TFPM): This model has been improved [22] depending on the statistical method Tf-idf. A joint of word pairs is used in this model rather than picking the word itself for user modelling.
– Entity-Based Model (ENTM): In this model, text’s parts that correspond to pages of Wikipedia are extracted in order to generate DBpedia named-entities, by which the users have been represented. It is utilized with variations in lots of current researches [31].
– LDA-based Model (LDAM): This model relies on the LDA method, the word is represented as the probability that belongs to the topics distribution generated by the training data. The statistics of the words in each document are examined. Besides the topics are detected along with discovering the document’s balance of topics [18]. Here the distribution of latent topics is obtained by which the user is represented.
Evaluation Metrics: Precision at a rank and Mean Reciprocal Rank (MRR) are used to evaluate the experiments; the greater precision and MRR become, the better the performance. They are commonly employed to validate recommendation systems [3], as well as information retrieval (IR) systems. In a comparable way of the behavior of IR, the recommendation algorithm is akin to the searching process for finding appropriate items for the user.
(a) : The proportion of recommended items in the first of the recommendation list whose are the learner is truly interested in. It is computed considering that describes the ratio of true recommended items, and which is relative to incorrect ones with regard to all learners. Top-K personalized recommendations resulting from the recommender system are to be investigated in our experiments as follows:
| (25) |
Where, is the recommended items for the th learners, and indicates the number of learners in the dataset. This means that the learning object has been selected by the th learners. denotes the actual learner’s selections of learning objects in the testing set. Here is selected to be 5.
(b) : is the mean of the inverse multiplicative of ranks of the first true recommended item of interest to the learner in relation to the number of user-recommendation lists .
| (26) |
Admittedly, every user is interested in whatever scientific material they chose. To appraise the effectiveness of our model, the findings of the recommender system are compared to the actual data choices. In the recommendations, the true items are the learner’s selection of materials, while the false items are the remaining materials of the recommendation list provided by the system to the learner, which has not been selected by this learner.
Here, a random recommendation of materials is almost assigned an equal probability for every learner. In the case of recommending a material randomly, P@5 would be about 0.033 for those materials that have been recommended randomly.
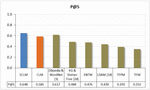
Table 2 shows a comparison between our model and others methods. As per the comparison, our models CLM and ECLM using semantic methods of user modelling show better performance over other methods, where the best results have been achieved by ECLM.
Table 2 A comparison between our models against other methods
| Dataset | Model | ||
| EDS | ECLM | 0.648 | 0.780 |
| CLM | 0.585 | 0.694 | |
| TFM | 0.336 | 0.411 | |
| TFPM | 0.393 | 0.466 | |
| ENTM | 0.452 | 0.573 | |
| LDAM [18] | 0.439 | 0.486 | |
| DBpedia & WordNet [3] | 0.617 | — | |
| Dataset [28] | KG & Steiner Tree [28] | 0.484 | — |
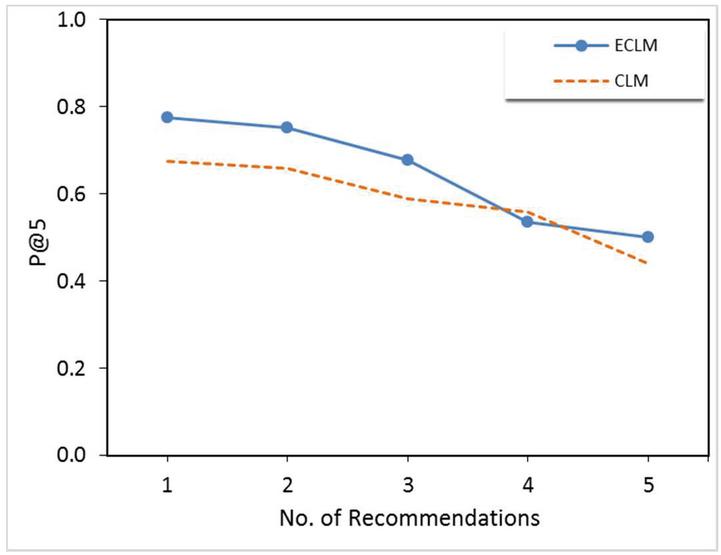
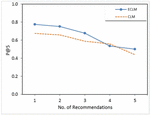
Figure 5 Results of the proposed recommendation algorithm based on CLM and ECLM.
Based on the findings of two proposed models CLM and ECLM, and the literature where other methods have been applied, the experimental results obtained by running the recommendation algorithm leveraging CLM and ECLM have exceeded other methods in terms of P@K. It is computed to evaluate the recommendation quality by comparing the items of the recommended list provided by the recommender system with the actual learner’s selections of learning objects for each learner.
Table 2 and Figure 5 show promising results in terms of with a value of (0.585) for CLM, while acquired for ECLM is the best result with a value of (0.648). So that, ECLM is the highest model among all other models, while KG & Steiner Tree model presented in the literature by Karidi et al. [28] has acquired 0.484 in terms of (Figure 6), where the evaluation results of their method are presented using a 100-user dataset.
Furthermore, the experiment aimed to highlight the best result achieved by the robust model ECLM compared with some recently suggested models. The enhancement of the current dataset using NPTEL and Coursera contents has improved the result from 0.608 in [3] to 0.617, which proves the efficiency of our introduced method.
A good value of (0.780) was obtained by ECLM, and (0.694) for CLM, which were the best results in comparison with other methods. It can be inferred from the demonstrated results, that exceeding the known entities with weighted terms resourced by various types of semantic relations captured using ConceptNet is quite promising. It would improve information extraction considerably that assist in understanding the learner’s interests well. Especially when e-learning content is to be recommended, it is more efficient to enrich the model by terms from the domain, which are lexically similar to the initial term. So semantic representations based on a rich ontology of textual e-content would help to obtain better identification of terms relevant to the learner.
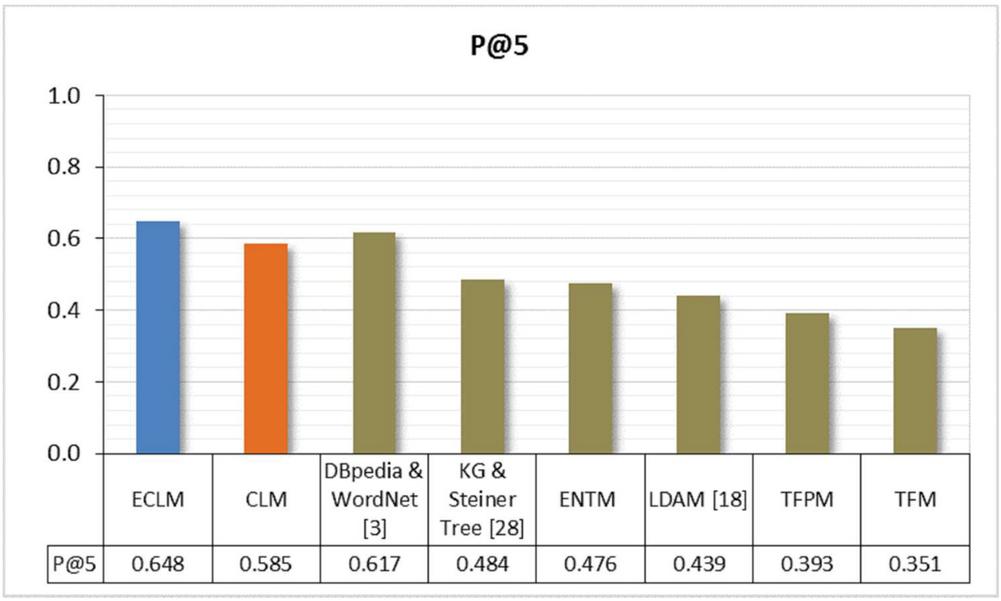
Figure 6 Results comparison of our models with others.
Moreover, the convergence of NPSO is shown to be a good solution for representing the relation types’ distribution ‘’, where each dimension value indicates the normalized weighted value of a semantic relation type (X-Axis), as illustrated in Figure 7.
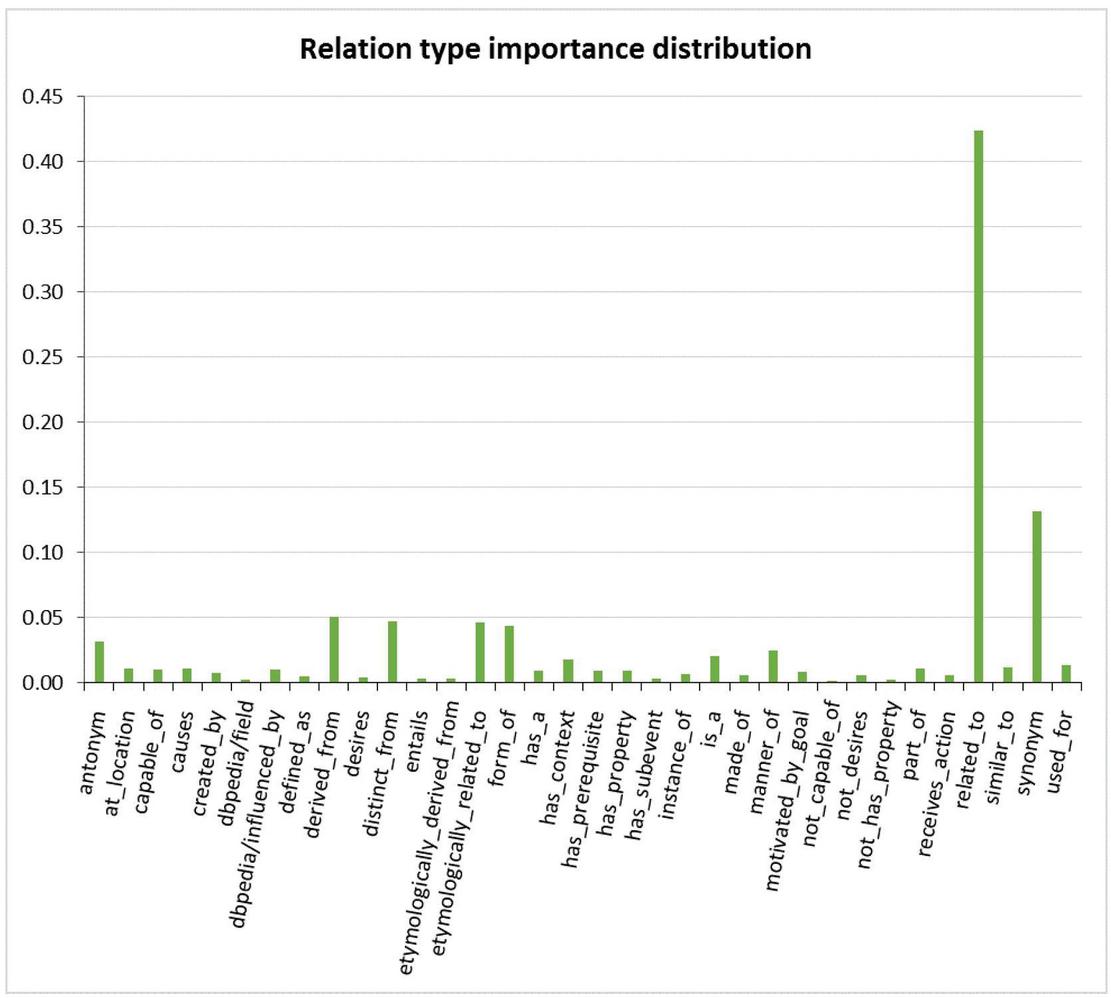
Figure 7 Relation type importance distribution.
Hyperparameters: Different settings of hyperparameters used for NPSO such as the weight and acceleration coefficients that have been experimented. The value refers to the factor of inertia weight, here is found suitable. The acceleration factors are also significant parameters to tune particle’s experiences along with the swarm experience that influences all particle trajectories. Values of are taken equal to 1.58667. The maximum number of iterations is set to 300, and are independent random numbers between 0 and 1.
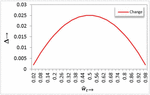
Learner model’s concepts with the weighted values is changing dynamically depending on the learner’s behaviors and text semantic representation of the current and new learning objects. Figure 8 shows the amount change with respect to a weighted value, achieves a Gaussian distribution, this is what makes the change when the ratio is very large or very small. While the closer the ratio is to the medium, the change is less. This helps to maintain the non-extreme mean values of the proposed learner model.
As the learners’ data changes over time, ECLM updating is obtained by using the retrieved data depending on semantic text representation of phrases with ConceptNet for new learning objects. Thus, the extracted interests would be used as input for a more accurate prediction of e-learning resources to the learner through the recommendation process in real-time. ECLM relies upon a semantically plentiful common-sense knowledge base to elicit connected concepts with an initial set of concepts.
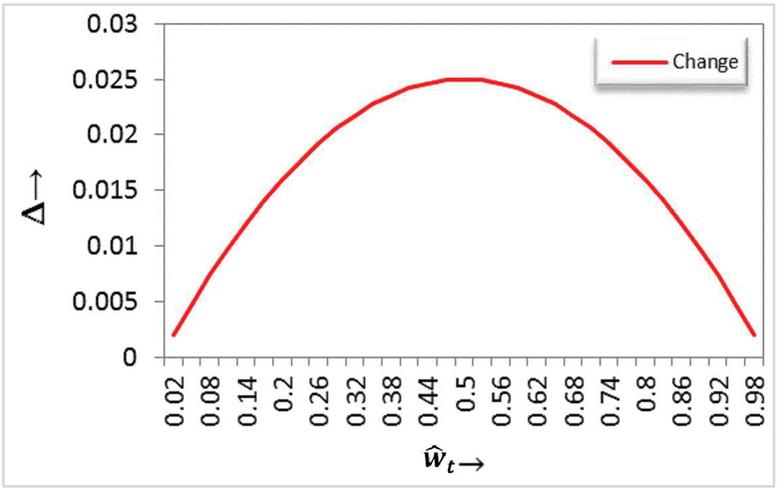
Figure 8 Amount of change with respect to the relative value .
In the view of finding the weighted value of semantic relation type, processing normalization constraints with NPSO in comparison to the traditional PSO algorithm has resulted in many merits. Although PSO worked well for ACS in [16], the virtue of using NPSO to satisfy the normalization constraints to compute normalized weighted attributes is better than using traditional PSO in terms of accuracy [10]. Whereas further alterations are required when applying traditional PSO, which may lead to weakening the optimization solution and not meeting the required normalization constraints, applying NPSO shrinks solution space concerning PSO, increasing the ability for converging to the optimal solution. Specifically, particles in NPSO can move spirally around the point by using the scaling center as an attractor, which aids to detect the optimal global point with less algorithm complexity.
Moreover, the possibility of adjustment to generalize the proposed user model, thereby producing it as a web service providing user profiling service as a model would suit many use cases on the web. Further, it may be reasonable to assume that the proposed methodology is cross-Multilanguage and ought to exploit for other languages, however, further experimentation and examination can be accomplished in future work.
6 Conclusion
A new personalized e-learning recommendation methodology has been proposed by integrating the semantics-aware conceptual learner modelling based on contextually related concepts to match learner models with the best e-content. The recommender system attempts at predicting appropriate e-learning resources with the highest-ranking linked to the learner’s interests. The two proposed learner models, CLM and ECLM have been built based on a tailored text semantic representation of e-content, and automatically are updated in an implicit way depending on the learner’s selection of materials. Semantic relation types from ConceptNet are leveraged to expand the learner models. The proposed methodology uses NPSO to explore the importance of the semantic relation types for developing the robust ECLM. This tries to overcome the absence of constructing a dynamic learner model in prevalent published work. The learner model takes the advantage of the contextual information of concepts and semantic knowledge to represent the learner’s interests. This has shown improved performance with better results in comparison with other models presented in the literature where the best was obtained with a value of for ECLM, and value of was resulted by CLM.
The proposed context-based semantic learner model is scalable involving more extending knowledge graphs within e-learning platforms integrating with social computing. In the future, deep learning techniques can be used for the proposed work to get more accurate predictions. Alternative methods of semantic representation can also be pursued and integrated suitably with contextual information.
Footnotes
1 https://github.com/commonsense/conceptnet5/wiki/Relations
2 https://library.cvrgi.edu.in/e-library.php
3 https://github.com/commonsense/conceptnet5/wiki/Downloads
References
[1] N. S. Raj, V. G. Renumol, ‘A systematic literature review on adaptive content recommenders in personalized learning environments from 2015 to 2020’, Journal of Computers in Education, 2021. https://doi.org/10.1007/s40692-021-00199-4
[2] K. Mangaroska and M. Giannakos, ‘Learning Analytics for Learning Design: A Systematic Literature Review of Analytics-Driven Design to Enhance Learning’, in IEEE Transactions on Learning Technologies, vol. 12, no. 4, pp. 516–534, 1 Oct.–Dec. 2019, https://doi.org/10.1109/TLT.2018.2868673.
[3] H. Ezaldeen, R. Misra, R. Alatrash, R. Priyadarshini, ‘Semantically enhanced machine learning approach to recommend e-learning content’, International Journal of Electronic Business, Vol. 15, No. 4, 2020, pp. 389–413. https://doi.org/10.1504/IJEB.2020.111095
[4] H. Ezaldeen, R. Misra, R. Alatrash, R. Priyadarshini, ‘Machine Learning Based Improved Recommendation Model for E-learning’, 2019 International Conference on Intelligent Computing and Remote Sensing (ICICRS), 2019, pp. 1–6. https://doi.org/10.1109/ICICRS46726.2019.9555866.
[5] H. Liu and P. Singh, ‘ConceptNet — A Practical Commonsense Reasoning Tool-Kit’, BT Technology Journal, Vol. 22, 2004, pp. 211–226. https://doi.org/10.1023/B:BTTJ.0000047600.45421.6d
[6] R. Speer and C. Havasi, ‘ConceptNet 5: A Large Semantic Network for Relational Knowledge’, In: Gurevych I., Kim J. (eds) The People’s Web Meets NLP. Theory and Applications of Natural Language Processing, 2013, pp. 161–176, Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-35085-6\_6
[7] C. Havasi, R. Speer, J. B. Alonso, ‘ConceptNet 3: a flexible, multilingual semantic network for common sense knowledge’, In proceedings of Recent Advances in Natural Language Processing, 2007, pp. 27–29.
[8] M. Keshavarz and Y.-H. Lee, ‘Ontology matching by using ConceptNet’, In: V. Kachitvichyanukul, H.T. Luong, and R. Pitakaso (eds) Proceedings of the Asia Pacific Industrial Engineering & Management Systems Conference, 2012, pp. 1917–1925, 2012.
[9] R. Speer, J. Chin, C. Havasi, ‘ConceptNet 5.5: an open multilingual graph of general knowledge’, In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, 2017, pp. 4444–4451.
[10] J. Guo, J. Gou, C. Wang and W. Luo, ‘The Normalized-PSO and Its Application in Attribute Weighted Optimal Problem’, 2016 Third International Conference on Trustworthy Systems and their Applications (TSA), Wuhan, China, 2016, pp. 48–53. https://doi.org/10.1109/TSA.2016.18.
[11] S. S. Kundu, D. Sarkar, P. Jana, D. K. Kole, ‘Personalization in Education Using Recommendation System: An Overview’, In: Deyasi A, Mukherjee S, Mukherjee A, Bhattacharjee AK, Mondal A (eds) Computational Intelligence in Digital Pedagogy. Intelligent Systems Reference Library, vol. 197, 2021. Springer, Singapore. https://doi.org/10.1007/978-981-15-8744-3\_5
[12] N. B. A. Normadhi, L. Shuib, H. N. M. Nasir, A. Bimba, N. Idris, V. Balakrishnan, ‘Identification of personal traits in adaptive learning environment: Systematic literature review’, Computers & Education, Vol. 130, 2019, pp. 168–190. https://doi.org/10.1016/j.compedu.2018.11.005
[13] S. Ouf, M. Abd Ellatif, S. E. Salama, Y. Helmy, A proposed paradigm for smart learning environment based on semantic web’, Computers in Human Behavior, Vol. 72, 2017, pp. 796–818. https://doi.org/10.1016/j.chb.2016.08.030
[14] J. Wang, H. Xie, F. L. Wang, L. K. Lee, O. T. S. Au, ‘Top-N personalized recommendation with graph neural networks in MOOCs’, Computers and Education: Artificial Intelligence, 2, 100010, 2021. https://doi.org/10.1016/j.caeai.2021.100010
[15] D. Zou, M. Wang, H. Xie, G. Cheng, F. L. Wang, L. K. Lee, ‘A comparative study on linguistic theories for modeling EFL learners: facilitating personalized vocabulary learning via task recommendations’, Interactive Learning Environments, 1–13, 2020. https://doi.org/10.1080/10494820.2020.1789178
[16] A. F. Martins, M. Machado, H. S. Bernardino, J. F. de Souza, ‘A comparative analysis of metaheuristics applied to adaptive curriculum sequencing’, Soft Computing, 25, 2021, 11019–11034. https://doi.org/10.1007/s00500-021-05836-9
[17] X. Liu. ‘A collaborative filtering recommendation algorithm based on the influence sets of e-learning group’s behavior’, Cluster Computing 22, no. 2 (2019): 2823–2833. https://doi.org/10.1007/s10586-017-1560-6
[18] J. Shu, X. Shen, H. Liu, B. Yi, Z. Zhang, ‘A content-based recommendation algorithm for learning resources’, Multimedia Systems, 24(2), 2018, pp. 163–173. https://doi.org/10.1007/s00530-017-0539-8
[19] H. Ezaldeen, R. Misra, S. K. Bisoy, R. Alatrash, R. Priyadarshini, ‘A hybrid E-learning recommendation integrating adaptive profiling and sentiment analysis’, Journal of Web Semantics 72 (2022): 100700. https://doi.org/10.1016/j.websem.2021.100700
[20] S. Benzarti, & R. Faiz, ‘EgoTR: Personalized Tweets Recommendation Approach’, In: Silhavy R., Senkerik R., Oplatkova Z., Prokopova Z., Silhavy P. (eds) Intelligent Systems in Cybernetics and Automation Theory. CSOC 2015. Advances in Intelligent Systems and Computing, vol. 348, 2015, pp. 227–238, Springer, Cham. https://doi.org/10.1007/978-3-319-18503-3\_23
[21] L. Boratto, S. Carta, G. Fenu, &R. Saia, ‘Semantics-aware content-based recommender systems: Design and architecture guidelines’, Neurocomputing 254 (2017): 79–85. https://doi.org/10.1016/j.neucom.2016.10.079
[22] M. Pennacchiotti, F. Silvestri, H. Vahabi, & R.Venturini, ‘Making your interests follow you on twitter’, In Proceedings of the 21st ACM international conference on Information and knowledge management, 2012, pp. 165–174. https://doi.org/10.1145/2396761.2396786
[23] H. Jiang, Y. Xiao, & W. Wang, ‘Explaining a bag of words with hierarchical conceptual labels’, World Wide Web 23, 1693–1713 (2020). https://doi.org/10.1007/s11280-019-00752-3
[24] W. Cui, Y. Du, Z. Shen, Y. Zhou,& J. Li, ‘Personalized microblog recommendation using sentimental features’, 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, 2017, pp. 455–456, doi: 10.1109/BIGCOMP.2017.7881756.
[25] H. Ma, M. Jia, D. Zhang, & X. Lin, ‘Combining tag correlation and user social relation for microblog recommendation’, Information Sciences 385 (2017): 325–337. https://doi.org/10.1016/j.ins.2016.12.047
[26] S. Auer, C. Bizer, G. Kobilarov, J. Lehmann, R. Cyganiak, & Z. Ives, ‘DBpedia: A Nucleus for a Web of Open Data’ In: Aberer K. et al. (eds) The Semantic Web. ISWC 2007, ASWC 2007. Lecture Notes in Computer Science, vol. 4825. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-76298-0\_52
[27] G. A. Miller, ‘WordNet: a lexical database for English’, Communications of the ACM 38, no. 11 (1995): 39–41. https://doi.org/10.1145/219717.219748
[28] D. Pla Karidi, Y. Stavrakas, & Y. Vassiliou, ‘Tweet and followee personalized recommendations based on knowledge graphs’, Journal of Ambient Intelligence and Humanized Computing 9, no. 6 (2018): 2035–2049. https://doi.org/10.1007/s12652-017-0491-7
[29] F. Zarrinkalam, H. Fani, E. Bagheri, M. Kahani and W. Du, ‘Semantics-Enabled User Interest Detection from Twitter’, 2015 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), Singapore, 2015, pp. 469–476, https://doi.org/10.1109/WI-IAT.2015.182.
[30] G. Piao, ‘Towards Comprehensive User Modeling on the Social Web for Personalized Link Recommendations’, In Proceedings of the 2016 Conference on User Modeling Adaptation and Personalization (UMAP ’16). Association for Computing Machinery, New York, NY, USA, (2016), pp. 333–336. https://doi.org/10.1145/2930238.2930367
[31] G. Piao, & J. G. Breslin, ‘User modeling on Twitter with WordNet Synsets and DBpedia concepts for personalized recommendations’, In proceedings of the 25th ACM international on conference on information and knowledge management, (2016), pp. 2057–2060. doi: 10.1145/2983323.2983908
[32] F. Ilievski, A. Oltramari, K.Ma, B. Zhang, D.L.McGuinness, &P. Szekely, ‘Dimensions of commonsense knowledge’, arXiv: 2101.04640 (2021).
Biographies

Hadi Ezaldeen is a Ph.D. in Computer Science and Engineering (CSE) from C.V. Raman Global University, India, in 2022. He received his Master’s degree in Web Science (MWS) from the Syrian Virtual University (SVU), Damascus, Syria. He has worked as a tutor (Assistant Professor), and an assistant supervisor of several graduation projects in the Faculty of Information Technology Engineering (ITE), at SVU. His research areas include Machine Learning, Semantic Analysis, Recommendation Systems, Natural Language Processing, and Text Mining. He has publications in reputed Journals and International Conferences indexed in SCI and Scopus. He has achieved interesting projects in the field of Web Intelligence and Knowledge Discovery.

Sukant Kishoro Bisoy received Ph.D., M.Tech, Bachelor’s degree in Computer Engineering in 2017, 2003 and 2000, respectively. He is working as Associate Professor in CSE, C. V. Raman Global University, India. His current research interests are on Neuro-robotics, Machine Learning, Cloud computing, Software Defined Network. He has been involved in organizing many conferences such IEEE ICICRS 2019, IEEE ANTS 2017, ICACIE-2016 (SPRINGER), ICHPCA-2014 (IEEE), many Workshop/FDP. He has several publications in Journals and Conferences indexed in SCI and Scopus. He has published patent. Reviewed papers in journals like ELSEVIER, SPRINGER, WILEY and INDERSCIENCE.

Rachita Misra, retired Professor and Head of Department of Computer Science and Information Technology at C.V. Raman Global University, is a Ph.D. from the IIT Kharagpur, India. She has more than 40 years of experience in teaching, research, and IT industry. She has more than 50 scholarly publications to her credit, in international journals, conference proceedings, and book chapters in the areas of digital image processing, computational intelligence, and parallel processing. She is a senior member of IEEE and a life member of CSI, OITS, AIPRUI, and ISCA.

Rawaa Alatrash is a Ph.D. scholar in Computer Science and Engineering at C.V. Raman Global University (CGU), India. She received her Master’s degree in Computer Science and Engineering from CGU. She is presently working as an Assistant Professor at CGU, teaching in the field of Computer Science and Information Technology. Her main research interests include Deep Learning, Knowledge-based Systems, Natural Language Processing, and Text Mining. She has publications in reputed Journals and International Conferences indexed in SCI and Scopus. She is a web developer. She has done many remarkable projects in Web Intelligence and Sentiment Analysis. Reviewed papers in journals like River Publishers and Science Publishing Group.
Journal of Web Engineering, Vol. 21_4, 1187–1224.
doi: 10.13052/jwe1540-9589.2148
© 2022 River Publishers