Research on Semantic Information Retrieval Based on Improved Fish Swarm Algorithm
Ming Hu
Wuhu Institute of Technology, China
E-mail: huming@whit.edu.com
Received 08 December 2021; Accepted 23 December 2021; Publication 08 March 2022
Abstract
In order to improve the effectiveness of semantic information retrieval, the improved fish swarm algorithm is proposed to carry out semantic information retrieval. Firstly, the system of semantic information retrieval is designed, and theory model of search engine is established. Secondly, the information retrieval model based on semantic similarity is constructed, and the mathematical model is deduced. Thirdly, the improved fish algorithm is established, and the analysis procedure of it is designed. Finally, the simulation analysis of semantic information retrieval is carried out, results show that the proposed model can obtain higher classification accuracy, precision rare and recall rate, therefore it has higher performance on semantic information retrieval.
Keywords: Semantic information retrieval; improved fish swarm algorithm, classification accuracy.
1 Introduction
With the rapid development of information technology, the scale and quantity of Web information are growing rapidly. At the same time, the development of network technology is also changing with each passing day. The Internet is gradually moving towards the next generation of knowledge network, and the organization and description of network information will show a new look. Therefore, the research on the new generation of information retrieval technology is very pioneering and challenging, It has attracted the participation of many organizations and individuals at home and abroad. Information retrieval system that is named as search engine is one of the most numerous and widely used applications on the Internet today. However, most users have not received professional training, and constructed low quality query is difficult to accurately reflect the information needs, it seriously affects the accuracy of retrieval results. How to obtain as high information retrieval performance as possible with as little computation in low quality query environment is a hot topic in the field of information retrieval [1].
Since the founder of the Internet T. Berners-Lee put forward the concept of semantic Web, a series of related studies have been carried out in an all-round way. Using ontology as a tool to describe information semantics on the web has become the consensus of many researchers, and various research and applications based on ontology have also emerged. At the same time, in the field of information retrieval, the research on semantic Web oriented and information semantic processing has also begun to attract people’s attention, For example, R. Navigli and P. Velardi believed that the semantic information expansion query using ontology is more effective than the traditional synonym or synonym based expansion after analyzing the ontology based query expansion strategy. A. Abdelali used bilingual ontology dictionary to replace the conventional bilingual dictionary in cross language information retrieval, and obtains equivalent results [2].
In the research of “How Net”, researchers also tried to solve the similarity and relevance of words and sentences from the perspective of semantic. In the field of digital library, professional librarians arrange the important terms in a professional field according to the semantic hierarchy and use the generated thesaurus for semantic retrieval. However, at present, semantic retrieval mainly realized concept level retrieval with the help of interactive term tips in the retrieval process, and did not consider other information such as concept attribute description, This concept based semantic retrieval method often could not meet the actual needs. Therefore, we use ontology to describe and characterize the semantics of user queries and documents, propose corresponding processing methods for the concepts and attributes in the retrieval, and realized the core algorithm of semantic retrieval by calculating the similarity of semantic vectors composed of concepts and attributes [3].
Semantic information retrieval based on relevance feedback understands the most interesting features of current users by analyzing the user’s feedback information, and dynamically adjusts the feature weight of the semantic information in the retrieval process, so that the retrieval gradually develops in the direction of user interest and finally meets the user’s requirements. This is a process of gradual refinement. in recent years, the intelligent algorithms have been applied in semantic information retrieval, such as particle swarm optimization algorithm, ant colony algorithm, cuckoo algorithm, and genetic algorithm, the existing algorithms have superior search performance and faster convergence speed, but they are easy to fall into local solutions. In this research, the improved fish swarm algorithm is establish to carry out semantic information retrieval. Artificial fish swarm algorithm is an optimization method based on animal autonomous body model according to the behavior characteristics of fish swarm. It is a new optimization strategy designed from bottom to top. The improved fish swarm optimization algorithm has superior search performance and faster convergence speed, but it is easy to fall into local solutions. AFSA belongs to intelligent bionics algorithm. Because the random initialization mechanism of population is introduced, improved fish swarm algorithm has less dependence on initial parameters than other algorithms. In this paper, the improved particle swarm optimization algorithm and relevance feedback are used to narrow the gap between low-level features and high-level semantic information, which changes the previous computer-centered retrieval process, and user-centered retrieval can better meet the needs of users. The improved fish swarm algorithm can effectively improve semantic information retrieval effect [4]. The improved fish swarm algorithm can improve the computing efficiency and accuracy of semantic information retrieval.
2 System of Semantic Information Retrieval
Semantic information retrieval actually applies the semantic relationship reflected in ontology to the annotation and retrieval of information resources. Specifically, it realizes information retrieval at the semantic level through the analysis and reasoning of relevant documents, and communicates with users in an appropriate form and friendly interface. Semantic information retrieval includes ontology document retrieval, instance retrieval and semantic relationship retrieval.
Ontology document retrieval is to find ontology document with specified classes and attributes in the constructed ontology. There are many different methods to realize ontology document retrieval. One method is to transform the ontology document to make it suitable for ordinary search engines, that is, through the processing of RDF or OWL documents, the matching ordinary search engines can index and retrieve it, and play the role of semantic information because of its description of information. Another method is to study ontology based search methods and technologies, such as building a specific searcher for a website or directly using jena2 searcher. The system uses the searcher to search specific semantic web documents, extracts the metadata and information in these documents, and stores them in the database. The database supports the query of a specific class or attribute [5].
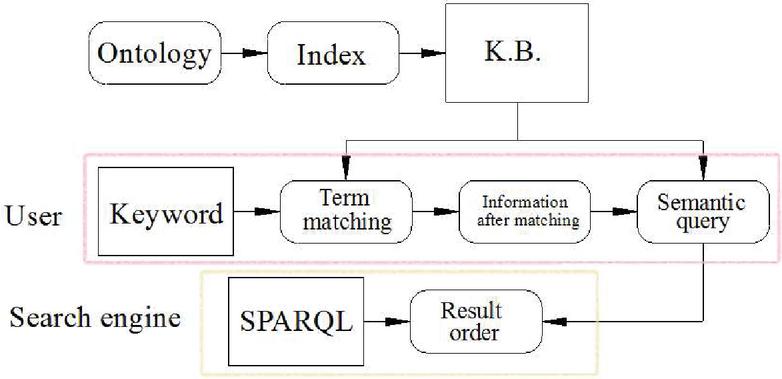
Figure 1 Diagram of semantic information retrieval system.
Case retrieval is to find and query the instance information of a specified class in the constructed ontology database. It mainly carries out structured query and reasoning based on RDF(S), OWL and other underlying knowledge models. Case retrieval is easier to combine with traditional retrieval. After the user enters the query request, the query request is transformed into the information represented by the semantic web. Combined with the semantic expansion algorithm, the query request is matched with the concepts in the ontology database. After matching, semantic reasoning is used to find relevant concepts and find the specified concepts, For the query concept, query all the instance information related to the concept through the graph in the RDF instance document, and these instance information is the final retrieval result. Now that there is the retrieval of ontology documents and instances, some studies begin to pay attention to the retrieval of semantic relations. Semantic relation retrieval is the retrieval of various complex relationships between concepts.
For example retrieval, a new semantic information retrieval system is proposed, as shown in Figure 1.
The framework mainly includes two parts: ontology processing module and formal query module. When the created ontology base is regarded as a knowledge base, the ontology processing module will automatically index the information resources. The formal query module takes keywords as input and the output is a SPARQL query record [6].
The purpose of term matching is to find the corresponding ontology information for the terms of each keyword, such as class, instance, attribute, etc. There are two matching methods for the name and tag of ontology information: the fist method is formal matching, which is to use string matching technology to find similar terms in the knowledge base; the second method is semantic matching, which mainly uses a general ontology library such as WordNet to query semantically related terms [7, 8].
After term matching, the terms in the knowledge base k.b. can find their matching terms through different matching methods. Various matching methods have selected predefined trusted values to determine the quality of matching. Generally, the trusted value of direct matching is higher than that of synonym based matching. Term matching connects the concepts in the knowledge base with the terms in the keyword query. In this way, after term matching, the terms are no longer a string of characters, but interpreted as a string of information resources needed by users.
Semantic retrieval mainly relies on ontology and query conditions. Jena performs semantic reasoning to obtain query results, and then outputs the results to the client. According to the designed semantic information retrieval framework, the knowledge base (K.B.) is the ontology file, and the query condition is the ontology information resource after term matching. Semantic retrieval is to perform semantic reasoning on the ontology where the ontology information resource is located, and query and match the RDF instance file of the ontology with SPARQL language provided by Jena for the query request, Finally, the matching results are sorted and output [9].
The purpose of query result ranking is to rank the results closest to the user’s needs, so as to ensure the efficiency and quality of query. The sorting of query results can be regarded as the probability of generating query F through the query condition C given by the user in knowledge base K, which is expressed by . In this way, the problem of sorting query results is transformed into a traditional probability problem. The key to sorting is to calculate this probability. Bayesian theorem can be used to calculate this probability, then:
| (1) |
where is the prior probability of query , and is the probability of generating knowledge base and keywords in formal query.
Assuming that both knowledge base K and query condition C are independent events, is divided into two parts, so the representation of is shown as follows
| (2) |
Expression (2) still can not intuitively judge which factors is related to. Therefore, Bayesian theorem is used again for and brought into expression (2), and the following is obtained:
| (3) |
It can be seen intuitively that is only related to and , while is the probability of generating in knowledge base K, and P (F C) is the probability of producing f under query condition C. Therefore, only by calculating these two probabilities can we solve the sorting problem of query results.
3 Information Retrieval Based on Semantic Similarity
In the information retrieval based on semantic similarity, after the “partial matching” strategy of vector space model is applied to obtain the semantic vector of user query and document, the concepts and attributes in the vector are processed respectively. Considering the correlation between different concept instances and comparable attributes of concepts, the similarity is calculated respectively as the basis for choosing documents to complete semantic retrieval [10].
When and are the same branch concepts as shown in Figure 2(a), the sub concept of consists of two parts: the sub concept of and the semantic related concepts of and . the larger the proportion of the latter, the smaller the correlation between and . When and are different branch concepts as shown in Figure 2(b), the sub concept of consists of three parts: the sub concept of , the sub concept of and the semantic related concepts of and . similarly, the larger the proportion of the latter indicates that , the smaller the correlation of .
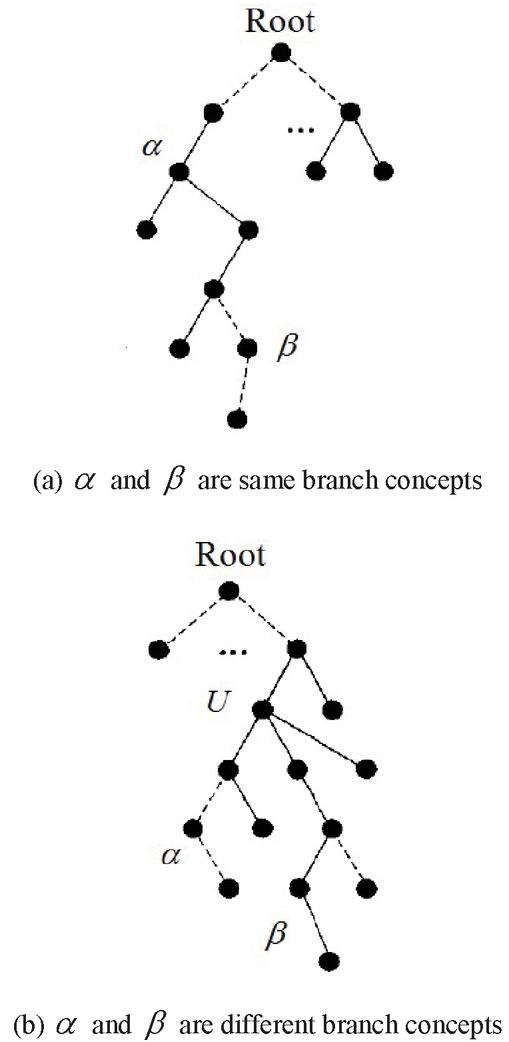
Figure 2 Structural diagram of same and different concepts.
The concept similarity between concepts A and B is defined as follows:
| (4) |
where is nearest root concept depth of and , is the distance between and , the values of them are non negative integers, the number of all nodes of the ontology concept sub trees with as the root, the number of all nodes of the ontology concept sub trees with as the root, the number of all nodes of the ontology concept sub trees with as the root,
Each ontology concept has multiple different instances, and their difference lies in the different attribute values. Instances of different concepts may also contain the same attributes. Therefore, when comparing the similarity between two instances, only the concept similarity is not enough, and the similarity between concept attributes must be considered [1].
The similarity between attribute vectors and is as follows:
| (5) |
where and are weights of attributes and in respective attribute vectors. which are pre set in ontology. is similarity of attribute values, which is confirmed according to expert knowledge in process of constructing ontology.
After calculating the concept similarity of semantic vectors and the attribute similarity of concept instances, the complete semantic similarity between semantic vectors can be obtained, and corresponding expression is listed as follows:
| (6) |
where is the user query semantic vector, is document feature semantic vector. denotes the feature weight of semantic.
4 Theoretical Model of Improved Fish Swarm Algorithm
The improved fish swarm algorithm is used to optimized the basic parameters of semantic information retrieval model.
4.1 Initialize Individual Position of Artificial Fish School
The initialization of the basic artificial fish swarm algorithm is generated randomly within the feasible region, and the possibility of uneven distribution cannot be ruled out. The uneven distribution of artificial fish swarm is not conducive to the global convergence of the algorithm. According to the characteristics of chaotic Transformation: randomness, ergodicity and regularity, chaotic transformation is used to initialize the individual position of artificial fish school, which makes the initialized artificial fish have diversity and is conducive to the global convergence of the algorithm. The typical formula of chaotic transformation is shown as follows [12]:
| (7) |
where denotes the controlling parameter.
4.2 Improvement of Foraging Behavior
Artificial fish swarm algorithm mainly involves three behaviors: foraging, clustering and tail chasing, and foraging behavior is the basis of algorithm convergence. Therefore, the improvement of foraging behavior is also one of the important factors to improve the performance of the algorithm. This paper mainly aims at the problem of finding the maximum value of the function (the same applies to the problem of finding the minimum value of the function). In the process of optimization, the larger the function value is, the closer it is to the optimal value, and the smaller the function value is, the farther it is from the optimal value.
Assuming that the state matrix of artificial fish at time is , firstly, the fitness values for all artificial fish swarm is solved, and then arrange them in descending order according to the fitness values (function values), then the better fitness values will be the first and the worst will be the last. Let the sequence number of the th individual at time be . if =1, it means that the position of the th individual at time is the best in the group, that is, it is closest to the optimal value; If , it means that the position of the th individual at time is the worst in the swarm, that is, it is the farthest from the optimal value.
is defined as the degree factor close to the optimal fish, which is calculated by [13]
| (8) |
where . The smaller the value of , the closer it is to the optimal fish, and the larger the value of , the farther it is from the optimal fish. When , execute the following expression:
| (9) |
where .
The strategy of reducing the visual field is adopted for the fish group close to the optimal individual, which can effectively avoid the fish group falling into the local optimization; when m (1/2, 1), execute the following expression:
| (10) |
where .
Only when the fish find food and their physical fitness is supplemented, the moving step of the fish will become larger.
Physical fitness transformation model is used to improved the fish swarm algorithm. Artificial fish swarm algorithm is an algorithm inspired by fish in nature, and the physical fitness transformation model is adapted according to the law between sports and physical fitness in nature. The consumption of physical fitness directly affects the moving step of fish swarm. Therefore, when improving the basic artificial fish swarm algorithm, the physical fitness of fish swarm has also become one of the factors we should consider. In the later stage of fish foraging, the physical energy is consumed to a certain extent, which will reduce the step length in the behavior of fish foraging, crowding and tail chasing. If the fish continue to move with the previous step size, it is easy to make the fish fall into local optimization. It is particularly important to reduce the step size of the fish in time [14].
Physical transformation model: is set as the threshold at which physical fitness begins to decay; S represents the motion unit of the working fish, and the initial value is 0. With the iteration of the algorithm, s will gradually increase. When the value of S is greater than or equal to It shows that the physical fitness of artificial fish begins to decline, which will affect the change of step size in the foraging, clustering and tail chasing behavior of artificial fish. Reduce the step size in each behavior according to the following expression:
| (11) |
where denotes the step size, denotes the physical attenuation factor, . in this research.
The basic procedure of improved fish swarm algorithm is listed as follows:
Step 1: Various parameters are set in the improved artificial fish swarm algorithm.
Step 2: The individual location of fish swarm is initialized based on expression (6).
Step 3: The aggregation and tail chasing behaviors of each artificial fish are carried out respectively. When the constraints are not met, the improved foraging behavior is implemented based on expressions (8) and (9).
Step 4: Judge the physical fitness of all fish groups if the conditions of physical fitness attenuation are met, the expression (10) is executed.
Step 5: Judge whether the termination conditions are met. If not, execute step 3; Otherwise, skip to step 6.
Step 6: The optimal value is returned.
5 Semantic Information Retrieval Simulation
The success rate is used as the evaluation standard of approximate sentence calculation of the evaluation model, and the recall rate and precision rate are used as the evaluation standards of information retrieval.
The success rate is calculated by [15]
| (12) |
where denotes the success rate of model, denotes the number of times the TopN contains the most approximate data in sum tests, denotes the total number of data on the test set.
Recall rate is calculated by
| (13) |
where denotes the number of relevant data retrieved, denotes the number of relevant data not retrieved
The precision rate is calculated by
| (14) |
where denotes the number of irrelevant data retrieved.
In order to solve the problem that sentences are not sensitive to sentence segment matching, that is, to prevent over fitting of sentences in model training, corpus segments are added for training. Cut sentences into segments:
| (15) |
Then the sentence with length can be segmented into segments. In order to make the training fragment contain the key information of the sentence, the fragment is filtered by the following formula
| (16) |
where is the function that convert words to TF-IDF values, if , The th segment is filtered out, otherwise it is used for corpus training.
The quality of classification directly affects the results of the model. In order to compare the short text classification effects of different models, 20000 short texts of finance, sports, entertainment and science and technology are used for training, and 200 short texts are used for testing. In order to analyze the effectiveness of the improved fish algorithm, the support vector machine and Rocchio method are also used to analyze the sample, and the simulation results are shown in Table 1.
Table 1 Classification accuracy based on different method
| Method | |||
| Number of | Rocchio | Support | Improved Fish |
| Classification | Method | Vector Machine | Swarm Algorithm |
| Two classifications | 0.84 | 0.90 | 0.95 |
| Three classifications | 0.82 | 0.88 | 0.96 |
| Four classifications | 0.81 | 0.87 | 0.94 |
| Five classifications | 0.83 | 0.90 | 0.97 |
It can be seen from Table 1 that the improved fish swarm algorithm based on word vector has higher accuracy than other classification methods. Therefore, it can be explained that taking word vector as training feature has stronger feature expression ability than taking word as feature unit, and overcomes the problem of sparse features when traditional methods are used for text classification.
Take 2000 short texts for model training, and use 200 approximate sentences for testing. Rocchio method, support vector machine and improved fish swarm algorithm are used for classification test simulation. The experimental results are shown in Table 2.
Table 2 Top 10 success rare based on different methods
| Rocchio Method | Support Vector Machine |
| Rocchio method | 0.81 |
| Support vector machine | 0.87 |
| Improved fish swarm algorithm | 0.92 |
As seen from Table 2, the improved fish swarm algorithm can obtain highest success rate, therefore the improved fish swarm algorithm has highest generalization ability.
In order to test the practicability of the model for information retrieval, this paper compares the traditional keyword matching retrieval with this model from two aspects: precision and recall. 200 retrieval tests were conducted out of 2000 retrieved information.
Table 3 Performance comparison among different methods
| Method | Precision Rate | Recall Rate |
| Rocchio method | 0.82 | 0.80 |
| Support vector machine | 0.85 | 0.83 |
| Improved fish swarm algorithm | 0.90 | 0.91 |
As seen from Table 3, the improved fish swarm algorithm can obtain highest precision rate and recall rate among three methods, the information retrieval method based on the improved fish swarm algorithm is not limited by the literal matching of information, so it has a higher recall rate than keyword retrieval.
6 Conclusions
An improved fish swarm algorithm is proposed for Web semantic information retrieval, and the word vector is used to classification of short text, and the invalid search domain can be shortened to improve the success rate of approximate sentence. The improved fish swarm algorithm can carry out approximate sentence computation. Simulation analysis show that the improved fish swarm algorithm has highest generalization ability, the proposed improved fish swarm algorithm has higher precision classification accuracy and success rate, and has higher recall rate and precision rate.
References
[1] Shivani Jain, K.R. Seeja, Rajni Jindal, A fuzzy ontology framework in information retrieval using semantic query expansion, International Journal of Information Management Data Insights, 2021, 1(1):100009.
[2] C.S. Saravana Kumar and R. Santhosh, Effective information retrieval and feature minimization technique for semantic web data, Computers & Electrical Engineering, 2020, 81(1):106518.
[3] Ibrahim Bounhas, Nadia Soudani, Yahya Slimani, Building a morpho-semantic knowledge graph for Arabic information retrieval, Information Processing & Management, 2020, 57(6):102124.
[4] Bandna Kumari, Rohit Kumar, Vijay Kumar Singh, Lokesh Pawar, Pankaj Pandey, Manish Sharma, An Efficient System for Color Image Retrieval Representing Semantic Information to Enhance Performance by Optimizing Feature Extraction, Procedia Computer Science, 2019, 152(1):102–110.
[5] Parastoo Jafarzadeh and Faezeh Ensan, A semantic approach to post-retrieval query performance prediction, Information Processing & Management, 2022, 59(1):102746.
[6] Mingying Xu, Junping Du, Zhe Xue, Feifei Kou, Xin Xu, A semi-supervised semantic-enhanced framework for scientific literature retrieval, Neurocomputing, 2021, 461(10):450–461.
[7] Xialin Zhang, Lingkun Lian, Fukang Zhu, Parameter fitting of variogram based on hybrid algorithm of particle swarm and artificial fish swarm, Future Generation Computer Systems, 2021, 116(3):265–274.
[8] Jiwei Huang, Jie Zeng, Yufang Bai, Zhuming Cheng, Zhenhui Feng, Lei Qi, Dakai Liang, Layout optimization of fiber Bragg grating strain sensor network based on modified artificial fish swarm algorithm, Optical Fiber Technology, 2021, 65(9):102583.
[9] Zhi-xin Zheng, Jun-qing Li, Pei-yong Duan, Optimal chiller loading by improved artificial fish swarm algorithm for energy saving, Mathematics and Computers in Simulation, 2019, 155(1):227–243.
[10] Han Xu, YouQun Zhao, Chao Ye, Fen Lin, Integrated optimization for mechanical elastic wheel and suspension based on an improved artificial fish swarm algorithm, Advances in Engineering Software, 2019, 137(11):102722.
[11] Yuguang Zhong, Zexiao Deng, Ke Xu, An effective artificial fish swarm optimization algorithm for two-sided assembly line balancing problems, Computers & Industrial Engineering, 2019, 138(12):106121.
[12] Ruishan Xin, Yidong Yuan, Jiaji He, Shuai Zhen, Yiqiang Zhao, Random active shield generation based on modified artificial fish-swarm algorithm, Computers & Security, 2020, 88(1):101552.
[13] Wei Yan, Meijing Li, Xin Pan, Guorong Wu, Liping Liu, Application of support vector regression cooperated with modified artificial fish swarm algorithm for wind tunnel performance prediction of automotive radiators, Computers & Security, Applied Thermal Engineering, 2020, 164(1):114543.
[14] Yean Zhu, Weiyi XU, Guoliang Luo, Haolun Wang, Jingjing Yang, Wei Lu, Random Forest enhancement using improved Artificial Fish Swarm for the medial knee contact force prediction, Artificial Intelligence in Medicine, 2020, 103(3):101811.
[15] Ying Xing, Xingde Wang, Qianpeng Shen, Test case prioritization based on Artificial Fish School Algorithm, Computer Communications, 2021, 180(18):295–302.
Biography

Hu Ming, Master of Engineering, associate professor of Wuhu Institute of Technology, member of the national curriculum ideological and political team. He has won the first prize of The Teachers’ Teaching Ability Competition of Anhui Province, the Gold Medal of “Internet ” Innovation and Entrepreneurship Competition, the first prize of the Teaching Achievement Award of Anhui Province for 3 times. He patended 7 inventions. He has taken many teaching and research projects such as “Research on domain name detection, classification and clustering algorithm based on deep learning”, “Research and practice of effective operation management based on online teaching Quality improvement” and so on.
Journal of Web Engineering, Vol. 21_3, 845–860.
doi: 10.13052/jwe1540-9589.21313
© 2022 River Publishers