Fine-grained Sentiment-enhanced Collaborative Filtering-based Hybrid Recommender System
Rawaa Alatrash* and Rojalina Priyadarshini
Department of Computer Science and Engineering, C.V. Raman Global University, Bhubaneswar – 752054, Odisha, India
E-mail: rawaa.alatrash@gmail.com; rojalinapriyadarshini@cgu-odisha.ac.in
*Corresponding Author
Received 23 October 2022; Accepted 23 November 2023; Publication 03 February 2024
Abstract
Developing online educational platforms necessitates the incorporation of new intelligent procedures in order to improve long-term student experience. Presently, e-learning recommender systems rely on deep learning methods to recommend appropriate e-learning materials to the students based on their learner profiles. Fine-grained sentiment analysis (FSA) can be leveraged to enrich the recommender system. User-posted reviews and rating data are vital in accurately directing the student to the appropriate e-learning resources based on posted comments by comparable learners. In this work, a new e-learning recommendation system is proposed based on individualization and FSA. A hybrid framework is provided by integrating alternating least square (ALS) based collaborative filtering (CF) with FSA to generate an effective e-content recommendation named HCFSAR. ALS attempts to capture the learner’s latent factors based on their selections of interest to build the learner profile. Three FSA models based on attention mechanisms and bidirectional long short-term memory (bi-LSTM) are suggested and used to train twelve models in order to predict new ratings from learner-posted book reviews based on the extracted learner profile. HCFSAR used multiplication word embeddings for stronger corpus representation that were trained on a dataset generated for an educational context and showed a better accuracy of 93.39% for the best model entitled MHAM based ABHR-2 with multiplication (MHAAM), which performed better than other models. A tailored dataset that has been created by scraping reviews of different e-learning resources is leveraged to train different proposed models and validate against public datasets.
Keywords: E-learning adaptation, recommender system, fine-grained sentiment analysis, collaborative filtering, natural language processing.
1 Introduction
Presently, the internet provides consumers with a lot more information, making it difficult for them to select the most relevant. The user may be confronted with a huge amount of information, but this will not assist them in making appropriate decisions. This problem is known as information overload. A recommender system is a form of data filtering system that is specifically designed to detect user preferences/interests depending on their requirements. The recommendation system generates a range of items for users based on prior preferences and requirements, as well as demographic information (Bhanuse and Mal, 2021; Kudori, 2021). Recommender systems grounded in collaborative filtering (CF) undertake the task of forecasting user interactions towards products or services. This is achieved through the acquisition of insights from past user-item associations within a category of users who demonstrate the same behaviour (Hameed et al., 2012; Ekstrand et al., 2011). An alternating least squares (ALS) algorithm, a form of CF, is used to address overfitting challenges inherent in sparse data sets. This utilization not only mitigates overfitting but also enhances prediction precision. It employs the matrix factorization approach to forecast the explicit preferences of users for various items (Aljunid, et al., 2019). The primary goal of gaining knowledge from educational backgrounds is to identify the performance of students and classify them depending on characteristics. It is useful to identify a student’s problematic attitude and make recommendations based on it (Ezaldeen et al., 2019; 2020). To enrich the recommender system, sentiment analysis is taken into account. It serves to acquire insights concerning the emotional content conveyed within a provided body of text. Operating as a fundamental component of natural language processing (NLP), it serves the purpose of identifying the prevailing sentiment within the text, often categorized as positive or negative. Furthermore, the fine-grained sentiment analysis (FSA) classified by remarks and opinion provides a constructive measurement for a variety of goals. These feelings are often classed as beneficial or unhelpful, or into a variety of categories ranging from very poor to very best. This analysis is a guide for analysing the public’s reception of e-content. The primary purpose of doing FSA is to increase the depth of study at the automatic development of the user’s viewpoint from their comments. The necessity to detect hidden information in textual data that exists in social networks has increased the demand for FSA (Alatrash et al., 2021; Mounika, 2021). Deep learning-driven sentiment analysis techniques have gained substantial traction in the evaluation of product/service reviews. These methodologies encompass a combined collection of features, employ embedded methodologies for feature creation, and subsequently execute sentiment classification through the integration of bidirectional long short-term memory (bi-LSTM) networks. Additionally, these approaches have extended their scope to fine-grained sentiment analysis. In this regard, a natural language processing (NLP) model has been developed, utilizing bi-LSTM architecture, to interpret item reviews presented as sentences (Garg et al., 2023). The output of this model quantifies the expressed sentiment numerically, representing distinct sentiment categories. The input is handled using word embeddings models such as word2vec (Mikolov et al., 2013a; 2013b). Moreover, the attention mechanism has found widespread application in various NLP endeavours, including machine translation and text summarization. This mechanism, known for its effectiveness, has also found application in fine-grained sentiment polarity classification tasks (Xie et al., 2019).
The present study provides a hybrid recommender system to generate individualized and effective e-learning recommendations that are triggered by combining collaborative filtering (CF) to deduce the learner profile and fine-grained sentiment analysis (FSA) model to guess the e-content rating to be used further in the recommendation process. The ALS CF model is leveraged based on a matrix decomposition method for hybrid recommendation. This is used in combination with the user-item matrix utility to determine the learner’s latent factors and create the learner profile, where the learner profile is represented as a dense vector of relative relations. In addition, by using the FSA model, the system proposes books which achieved the highest rating based on the learner profile captured by ALS. To forecast the ratings of five discrete classes strictly positive, positive, fair, negative, strictly negative, the FSA method mines feelings based on text comments of books. Three FSA models based on attention mechanisms and bi-LSTM are proposed here and used to train twelve models in order to predict new ratings from learner-posted book reviews.
The system can appropriately offer suitable e-learning materials to the student based on the extracted learner’s latent factors and the outputs of FSA models. The obtained findings outperform the previous approaches.
The following are the significant contributions to the current research:
• Proposed a novel framework of hybrid e-learning recommending a system based on a combination of ALS and FSA, in which higher-rated e-learning materials are suggested based on the captured learner profile.
• The improvement was performed by extracting the learner’s latent interest based on ALS to construct the user model as a dense vector of relative relations that are integrated to boost the suggested proposed model.
• FSA models rely on attention based models and NLP techniques are employed to classify the learning resources.
• A personalized recommendation system is introduced to deliver e-content with the highest ranked ratings related to the learner’s area and interests based on the dynamic user model.
• The HCFSAR recommendation system is enhanced with multiplication word embeddings for better corpus representation, which were trained on a dataset created for an educational environment, leveraging the goodness attention mechanism and bi-LSTM network, which predicted an accuracy of 93.39% for (MHAM Based ABHR-2 with Multiplication) MHAAM. In turn, the system produces individualized suggestions/recommendation in terms of fuzzified comments which are sorted into five types unlike binary categorization.
• For the education domain, a tailored dataset entitled “Amazon Book Hybrid Recommendation (ABHR-2)” was gathered and utilized to train twelve models. These models were trained and assessed on ABHR-2 and compared to several public datasets of precomputed vectors as well as the textual public dataset “SST-1” (Socher et al., 2013) and Hotel Reviews (Kumar et al., 2020).
The proposed approaches were examined using various scenarios, which led to the best showing of performance, as shown in Table 4.
The related work is depicted in Section 2. The proposed models HCFSAR approach and recommended methods have been developed and presented in Section 3. The experimental work is described in Section 4. Section 5 discusses the findings. Section 6 illustrates how to summarize the research.
2 Literature Review
E-learning systems adapt to the ever-changing environment by providing learners with remote learning opportunities and an abundance of learning resources. With huge online resources available, users may want assistance in picking which course to take. Consequently, recommender systems are used in e-learning to provide learners with individualized services by automatically recognizing their preferences (Zhang et al., 2021). The majority of current web-based recommender fits into different fundamental types; content-based filtering recommendation (CBFR) (Shu et al., 2018), collaborative filtering recommendation (CF) (Liu, 2019), and hybrid recommendation (Bourkoukou, and El Bachari, 2018). The recommender systems face a problem in recommending items to users in case there is very little data available related to the user or item. This is called the cold-start problem. Sparsity arises when learner feedback is limited and insufficient for determining sufficient credible similar users.
2.1 Collaborative Filtering-based User Modelling
Collaborative filtering-based modelling systems depend on the similarity among users for e-content recommendation. The user preference data utilized by collaborative filtering recommendation systems include explicit evaluations (e.g., scores 1–5) as well as implicit feedback (e.g., seeing and clicking) on items (Bobadilla et al., 2009). The early development of collaborative filtering-based recommendation algorithms is memory-based, with a heuristic search for similarities between users and things. Model-based collaborative filtering approaches for rating prediction and item ranking are being developed by utilizing machine learning and advanced artificial intelligence techniques.
Zapata et al. (2015) used CF-based approaches within the e-learning system, considering the well-established and quite good learning infrastructures. The “voting functionality” is added, to acquire the user’s scores and items.
An approach is used to implement collaborative tagging techniques within a methodology to achieve an online tutoring model [14] (Klašnja-Milićević et al., 2018). Sequential patterns mining and social tagging are combined into the applied approach for providing customized recommendations of learning resources to learners.
Also, Liu (2019), in front of traditional recommendation systems that suffer from poor quality recommendations through low scalability and lack of stability, proposed a solution. The CF suggestion method is utilised, which relies on the impact of the e-learning learners’ behaviours. A modern e-learning group enhances resources based on computation, evaluation density, the ring approach, and prediction. In comparison to other current strategies, the suggested solution will tackle the sparse problem well. The proposed method generates a more accurate recommendation than traditional recommendation algorithms.
Mondal et al. (2020) suggested the use of machine learning algorithms as part of an online education courses recommendation system. In particular, the authors employed the K-means approach to categorize learners relying on achievements in former courses. Following that, CF was used to propose additional appropriate courses. According to the outcomes, the suggested model presented low values for root mean squared error and mean absolute error. In addition, the model obtained good precision and recall, showing it can produce correct answers while retaining the bulk of true positives.
Jeevamol and Renumol (2021) used an ontology combined with collaborative filtering and content-based filtering techniques was used in the recommendation model. The learner and learning objects with their characteristics were modelled using ontology to generate the top-N recommendations based on learner ratings.
Koffi et al. (2021) used learner performance predictions and collaborative recommendation were used with CNN and KNN algorithms for material recommendation. Suitable learning items were determined by the profile of a selected learner. Also, they incorporated other learning elements in the learner’s profile.
Alternating least square (ALS) based CF needs sufficient historical learner data in the learner profile for solving the inherent problems of cold-start and sparsity arising in the recommender systems. Furthermore, it is difficult for collaborative filtering-based approaches to handle new items, and it is tough to integrate other features for a query/item. Using collaborative filtering, the prediction for a given (user, item) pair is the dot product of their associated embeddings. If an item is not observed during training, the system is unable to generate an embedding for the given pair (Ni et al., 2020; Awan et al., 2021).
2.2 Hybrid Recommendation Techniques
A real-world e-learning system typically integrates the key aspects of multiple recommendation techniques into a hybrid approach to overcome the shortcomings of collaborative filtering and content-based filtering. There are seven primary hybridization processes of recommendation technique: cascade, feature augmentation, feature combination, meta-level, mixed, switching, and weighted (Burke, 2007). The A hybrid recommendation system is a synergy of numerous strategies that use distinct range of inputs for the purpose of recommendation service, with one strategy complementing the others.
Hybrid recommendation attempts to beat the issue of sparsity and cold-start, and is used to address the new user/item problem. The hybrid techniques have a profound positive impact on the precision of the personalized e-learning recommendation. A hybrid recommendation system using collaborative filtering and a content-based approach with good learners’ ratings is proposed to improve the accuracy of recommendation (Turnip et al., 2017).
Vaishali et al. (2016) proposed a hybrid recommendation supported by “Pearson correlation” and “content-based recommendation” based on CF to recommend critical resources for the user. The proposed system uses an approach of “fuzzy tree matching” depending on “ontology, Pearson’s correlation, fuzzy logic, and M-tree creation” to examine the learner’s needs. Because a huge quantity of resources causes difficulty for the varied system’s existing in the learning patterns, it needs to accommodate the desired learning path by employing more semantic information to define the state of the entity.
In e-learning recommender systems, another specialized hybridization is context-aware recommendation and sequential pattern mining (Bourkoukou, and El Bachari, 2018). Tarus et al. (2018) developed an e-learning hybrid recommendation system that relies on integration of the context awareness of the learner, mining sequential patterns with CF to enhance the accuracy of the personalized recommendation over traditional recommender systems. Wan and Niu (2019) proposed a hybrid recommendation approach to personalize learning experiences. Different e-learning recommendations have been applied for enhancing the satisfaction of learners utilizing an influence-based user profile that is independent of “rating information”. “Self-organization theory” has been leveraged to produce the groups of learners. The model is optimized using intuitionistic fuzzy logic.
CF and social filtering based on the sentimental aspects have been integrated into the hybrid recommender approach to recommend better social content and learning courses relevant to learner profiles (Madani et al., 2020). The system uses a reinforcement learning technique to deduce the optimal learning path. However, the authors have not considered similarity between the learners’ profiles to deduce the optimal learning path.
2.3 Sentiment Analysis
Sentiment analysis or opinion mining (Guner et al., 2019) is one of the most active areas of research in natural language processing (NLP). It has received a lot of attention for mining and summarizing social media comments on the web and attracts different positive and negative people’s opinions, feelings, ideas, and behaviours to leverage them later in the education field (Qamar and Alassaf, 2020). These opinions and feelings have implicit and explicit features to be extracted, wherein Cai et al. (2021) constructed a model to capture the implicit and explicit quadruples aspects of the sentence review. In order to categorize the sentiment of the reviews more accurately, Bu et al. (2021) built an integrated model of both fine-grained aspect categories with the prediction of the sentiment review. To obtain an effective representation of the language model, Ke et al. (2019) constructed a pre-trained language model by integrating the sentence level representation with the word level linguistic knowledge representation for sentiment analysis.
Many researchers have attempted to address the problem of ambiguity and subjectivity (Sindhu et al., 2021; Das and Sagnika, 2020). A comprehensive view of the models, resources, algorithms, and applications evolved in the context of sentiment analysis and affective computing has been introduced by the authors (Susanto et al., 2021).
All the resources of Sentic computing in the field of sentiment analysis and affective computing are publicly available and used in different domains such as utilizing aspect-based affective computing and sentiment analysis for summarizing opinion (Kumar et al., 2021), recommender systems-based sentiment analysis (Pasquier et al., 2020) and e-learning for measuring the learner sentiment (Alencar and Netto, 2020).
A suggested hybrid architecture for several viewpoint attention rely on bi-LSTM and alleviates the buildup of mistakes in the pipeline technique. This employs a novel combined technique for extracting aspect and emotion pairs (Fu et al., 2021). Another hybrid model is built established on aspect-self-attention for aspect-based sentiment analysis to solve concerns such as data lost in recurrent neural networks (Lin et al., 2021). The presented model attempts to enhance sentence representation by focusing on two auxiliary features: word position and part-of-speech.
A set of researchers focused on leveraging ensemble models to enhance the accuracy of the sentiment analysis models for domain adaption (López et al., 2019; El Mekki et al., 2021) towards sentiment analysis for aspect-based (Gong et al., 2020) and other for analysing the sentiment of the review (Tiwari and Nagpal, 2021). While Cambria et al. (2020) reported a combination of top-down and bottom-up based on an ensemble of symbolic and subsymbolic AI tools, wherein the knowledge base for sentiment analysis is created by integrating logical reasoning and deep learning to infer the polarity of text.
Additionally, word embedding is utilized to generate a probabilistic model of either words or characters in a feature space that captures the semantic relationships between them. Researchers recently documented the effectiveness of employing word vectorization models to vectorize e-content comments, such as word2vec (Mikolov et al., 2013a; 2013b) and FastText (Bojanowski et al., 2017).
Kim (2014) created several model-based CNNs for FSA at the sentence level, leveraging word2vec pre-trained vectors to vectorize various public existing datasets. However, several experiments have reported, in polarity sentiment analysis, good results comparing to the outcome of FSA, which is considered the grand challenge of current research works to classify the rating of the posted reviews precisely. CNNs have been constructed with two channels and used to enhance outcomes in a variety of domains, including natural language processing (NLP) with the emerging trend of FSA of e-content comments (Alatrash et al., 2021). Dess et al. (2020) developed a deep learning-based technique for sentiment analysis to determine the sentiments of binary classification of student comments after finishing different online courses. On smaller private materials of e-learning, different deep learning architectures with word embedding representations were integrated and trained. These models demonstrate how particular word vectorization outperform the models trained on a common-purpose corpus (Ezaldeen et al., 2022). It is now important to fully realize the capability of different models of sentiment analysis developed in the adaptive e-learning framework, consider the specific domain the training data is obtained, as well as the over-sensitivity of notable models where the personalized e-learning methodologies are employed.
There are no significant works utilizing sentiment analysis in recommendation systems as most of the research focuses on sentiment analysis polarity classification, where it becomes difficult to handle many cases for meaningful recommendations on the web. Learners must have a more in-depth understanding of the instructional materials available online, which necessitates the multi-classification of e-learning resources. Thus, a powerful recommender system is needed to provide e-learning recommendations in terms of fuzzified reviews categorized into multiple classes unlike polarity classification, which is reflected in the existing work. The findings of this work can positively help learners with the goodness of effect on their opinions and attitudes being enriched by a convenient recommendation process.
Focusing on polarity cannot provide further mining of the user’s opinion, whereas multi-level classification gives us a perception on how a specific scientific material is suitable to be recommended to the learner, depending on the feedback of a similar learner taking many factors under consideration such as study level.
Moreover, the prevalent practice among researchers involves the utilization of publicly available datasets that have been designed with general terms and purposes “SST-1” (Socher et al., 2013) and Hotel Reviews (Kumar et al., 2020). In this context, a comprehensive analysis of the existing research demonstrates varied approaches in utilizing sentiment analysis for recommendation systems. Studies such as the one conducted by SST focused on movie reviews sourced from Rotten Tomatoes and employed a scraping technique to curate a dataset of 10,662 sentences, equally balanced between positive and negative sentiments. Conversely, booking.com’s dataset was pre-divided into positive and negative categories, facilitating the identification of distinct viewpoints across 1521 titles, 775 positive reviews, and 435 negative reviews. Our notable contribution, the ABHR-2 dataset, employed a unique strategy by scraping different pages on Amazon.com to compile customer reviews for books, accompanied by corresponding ratings spanning from “1” to “5”. This approach, which aimed at encoding the sentiment spectrum from very negative to very positive, yielded an extensive dataset of 80,000 records specifically tailored for fine-grained sentiment classification.
The diverse methodologies adopted for dataset curation underscore the complexity of sentiment analysis within recommendation systems. The varying sizes, sources, and preparation methods highlight the significance of selecting an appropriate dataset aligned with the specific research goals and domain context. Such considerations are paramount to achieving reliable and accurate outcomes in the domain of fine-grained sentiment classification and recommendation systems in the e-learning domain.
However, the application of such datasets “SST-1” (Socher et al., 2013) and Hotel Reviews (Kumar et al., 2020) does not yield advancements in the efficacy of language models when integrated into the recommendation process within e-learning contexts. The underlying reason for this inadequacy lies in the specialized nature of the education domain. In this domain, the precise representation of vectors in Euclidean space holds greater significance compared to their representation in general contexts. For instance, the term “machine learning”, within the education domain, is perceived as a unified phrase, differing significantly from its general representation as two separate words, “machine” and “learning.” The divergence in these representations bears substantial importance. To address this, my research endeavours to create a bespoke dataset that promises improved results. The usage of a dataset not tailored to the education domain would lack content pertinent to educational settings, resulting in a misalignment of content manipulation. Consequently, this misalignment would lead to inaccuracies in embeddings and ultimately introduce flawed recommendations.
These studies are focused on deriving practical advice to carry out the current system model for personalized recommendations to the learner in an e-learning environment where our motivation is derived from Kudori (2021), Kim (2014), Kumar et al. (2020), and Ni et al. (2020). Thus, our objective is to achieve the most benefit of tailored integration of ALS for the task of building the learner profile and attention based models for FSA to extract the sentiment behind the review in real-world settings. That reflects the main aim to categorize the e-learning resources in fuzzified sets of five classes, which is one of the core challenges of the recent studies that are being conducted nowadays rather than the polarity of FSA. The results of our investigations in this paper are based on predicting the ratings of the e-content to be utilized in the recommendation process of our suggested HCFSAR.
3 The Proposed Recommender System Framework
This section describes the proposed hybrid framework based on collaborative filtering and fine-grained sentiment analysis for e-content recommendation named (HCFSAR) depending on the learner’s feedback. HCFSAR incorporates two models: the CF model and the FSA model for hybrid recommendation, as explained in detail along with the used datasets in Sections 3.1, 3.2, 3.3 respectively. The hybrid recommendation uses the collaborative filtering model based on ALS which relies on a matrix factorization algorithm. This is applied to the user-item matrix utility to deduce the learner interests and build the learner profile. Moreover, by employing the FSA model, the books acquired with the highest predicted ranked rating is going to be recommended by the system based on the learner profile. The FSA model mines the sentiment depending on text reviews of the books to predict the ratings of discrete five classes. Here, three FSA models are proposed based on attention mechanism and bidirectional LATM to predict the new ratings of book reviews posted by learners. The implementation of the proposed model can be found on the following links: https://colab.research.google.com/drive/1yc5YRbBQUUgmOWWioNH3TLm0BNGRat--, https://colab.research.google.com/drive/16D3nwsbzylJcbd1cQvvUdr3k3exZ\_ZMq.
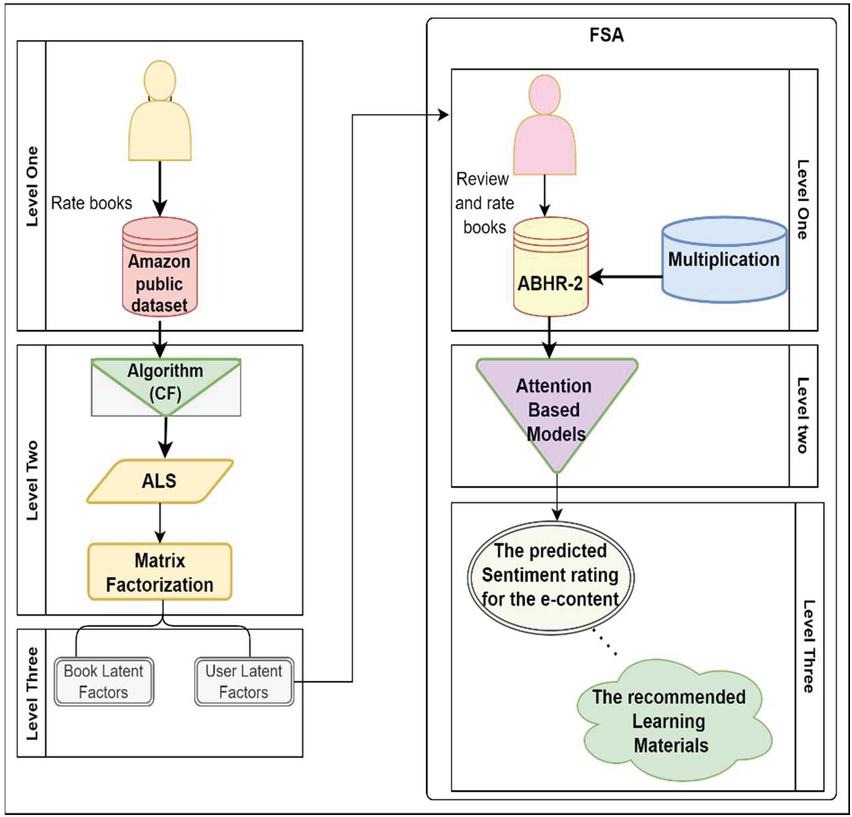
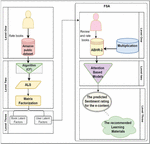
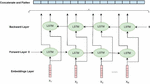
Figure 1 Structure for the proposed model.
In this work, the learning resource with the highest rating obtained from SA is used for the hybrid recommendation of e-content based on the learner interests deduced by ALS.
Figure 1 shows the procedure for both models FSA and ALS. The system is divided into two parts: the main part is ALS, and the second is the FSA, each of which is divided into several levels. In the main part are the books rated by the learner, which is the first level. The second level is ALS decomposed based on matrix factorization. The third level is the latent factors of books and users. In the second part, the first level is the books reviewed and rated by the learner, where the reviews are mapped into “multiplication” word embeddings to vectorize the corpus. The second level is the FSA based on attention mechanisms and the bi-LSTM model, while the third level is the predicted sentiment rating for the e-content that is used in the recommendation process.
3.1 Dataset
This research work presents an innovative approach to enhancing personalized e-content recommendations for learners by leveraging the combined BX-Book-Ratings and BX-Book datasets. The BX-Book-Ratings dataset contains explicit book ratings given by users, while the BX-Book dataset comprises critical book attributes such as titles, authors, and categories. The integration of these datasets results in a comprehensive dataset that is well-suited for training an ALS model, allowing efficient capture of user preferences through collaborative filtering.
Notably, the combined dataset includes valuable information about the learning category associated with each book. This categorization enables the system to effectively group similar books together, facilitating the delivery of relevant content recommendations to learners based on their specific interests in particular learning categories.
To achieve personalized recommendations, ABHR-2 is used to train FSA models and recommend new books to the learner based on the number of books available in each learning category. This personalization approach significantly enhances the user experience, increasing the likelihood of users discovering e-content that aligns with their unique preferences and educational needs.
Moreover, the utilization of the two datasets (the combined dataset and ABHR-2) results in a larger and more diverse collection of books and user ratings. This enriched dataset contributes to better generalization and scalability of the proposed model, making it capable of handling a larger user base and accommodating a wider range of e-content preferences.
More clearly, the Amazon public dataset serves a specific purpose within the research framework. It is employed in the initial part of the study to train the collaborative filtering algorithm, specifically the ALS approach. This dataset is particularly suited for collaborative filtering as it comprises a utility matrix wherein each user has rated books. Notably, this dataset focuses solely on ratings, omitting explicit reviews associated with the user’s ratings. In contrast, the ABHR-2 dataset is utilized in the subsequent phase to train sentiment analysis models. This dataset contains book reviews alongside their corresponding ratings. This data is instrumental in exploring the proposed sentiment analysis model’s effectiveness in extracting sentiment from reviews to predict ratings for new books relevant to the learner domain, building upon the outcomes of the collaborative filtering process mentioned in Section 3.2.1. The predicted ratings generated through sentiment analysis further contribute to the CF investigation. Therefore, the Amazon public dataset aids in the collaborative filtering phase, while the ABHR-2 dataset plays a pivotal role in the sentiment analysis and subsequent recommendation process.
ABHR-2
Textual data were collected from the e-content of 120 materials that belong to 50 primitive terms such as {“Image Processing”, “Deep learning”, “Cyber Security”, etc.}, based on the recommendations of 75 experts in our university as mentioned in Table A1. These gathered materials and the linked term reflect the actual learner’s needs in real classes.
The experts contributing to the dataset’s creation consisted of esteemed academic advisors, professors, lecturers, and scholars affiliated with the computer science and engineering as well as information technology departments at C.V. Raman Global University in India. Their areas of specialization spanned diverse domains such as image processing, natural language processing, cyber security, mobile computing, recommendation systems, digital signal processing, internet of things, software engineering, virtual reality, cloud computing, and more. This expert panel encompassed a wealth of knowledge, experience, and expertise, lending credibility and richness to the dataset’s composition.
The collected data is used to investigate the proposed approach of sentiment analysis model to extract the sentiment behind the reviews to predict the rating for the new book. This rating will be used further for the CF investigation.
Our own dataset named Amazon Book Hybrid Recommendation ABHR-1 (Alatrash and Ezaldeen, 2021) has been created based on primitive terms by scraping different pages of Amazon.com in order to get books reviews by utilizing Python Script. It comprises customers’ reviews for books with its corresponding rating wherein, these corresponding ratings have taken an encoding from “1” to “5” where each one is mapping from very negative to very positive.
The dataset mentioned earlier underwent augmentation and formulation, resulting in ABHR-2. It comprises approximately 80,000 records crafted for the purpose of fine-grained sentiment classification. The most challenging task is fine-grained to classify the sentiment of the review rather than to use binary classification, where the collected dataset is created to gain more precise results in automated opinion mining. The fine-grained opinion analysis is based on five discrete classes.
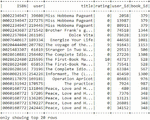
For example: the review text is “[‘particularly’, ‘strangely’, ‘present’, ‘math’, ‘machine’, ‘learning’, ‘dumbed’, ‘way’, ‘using’]”, whereas the rating corresponds to this sentence is “2” as given in ABHR-2. In the above example, the review1 text represents a sentence in ABHR-2 with its corresponding rating.
Thus, resulted in ABHR-2 consists of various sentences/users’ reviews with their corresponding rating out of 5, as presented in Figure 2.
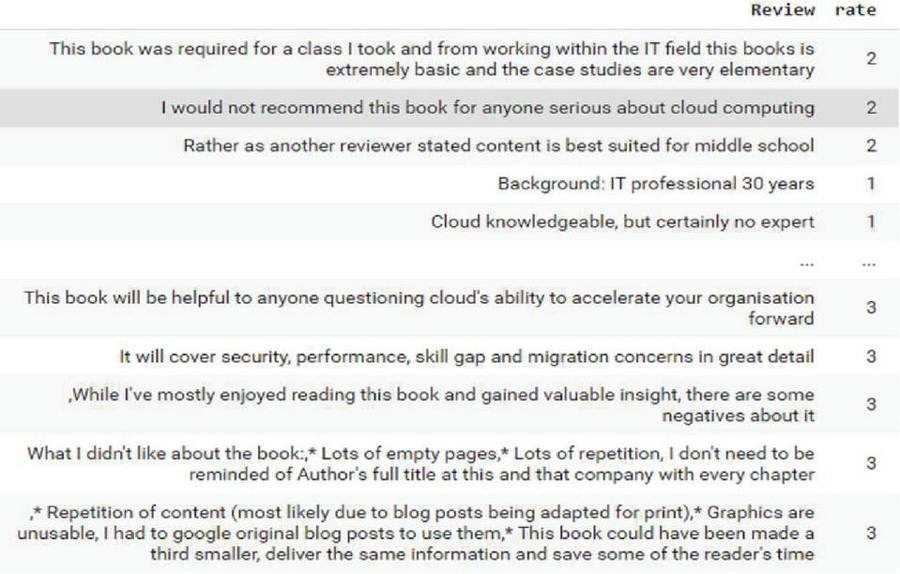
Figure 2 Sample of ABHR-2 dataset.
BX-Book-Ratings
This is a public dataset collected by Ziegler et al., (2005). Each book is identified using the respective ISBN. Invalid ones are removed. It comprises 1,149,780 ratings scaled between 1 to 10 for 271,379 books rated by 278,858 learners, but for research purposes, the scores were rescaled to between 1 and 5. It is formed by three columns; “Rating”, “UserId”, and “bookId”.
BX-Book
This dataset consists of eight columns (“ISBN”, “Book-Title”, “Book-Author”, “Year-Of-Publication”, “Publisher”, “Image-URL”, “Image-URL”, “Image-URL”). The information such as “ISBN” and “Book-Title” are considered while that irrelevant to the experiment are ignored. This dataset is combined with BX-Book-Ratings based on “ISBN” to get the book title of each book to be utilized in the recommendation process.
The link for both datasets BX-Book-Ratings and BX-Book is available on the following link (Kaggle.com).1
Figure 3 shows a combination of both dataset BX-Book-Ratings and BX-Book that have been merged where BX-Book-Ratings.ISBN == BX-Book.ISBN.
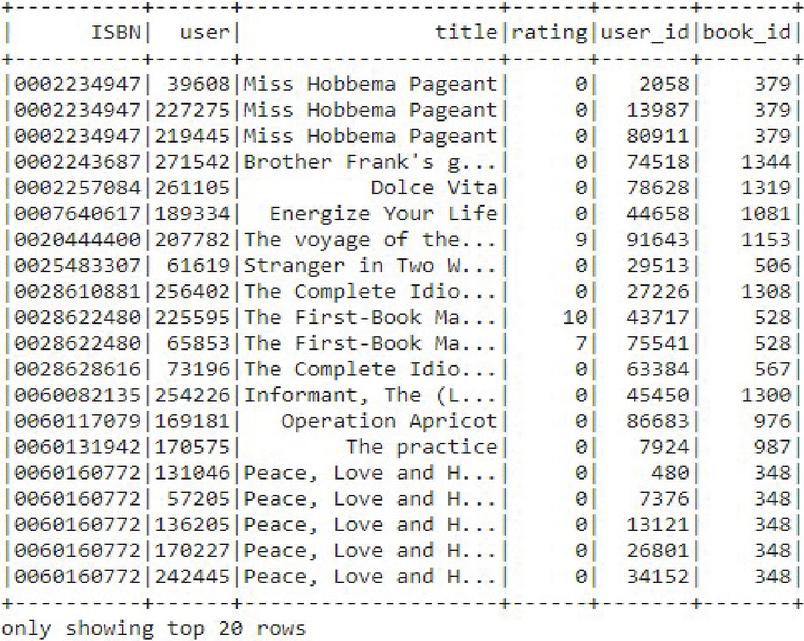
Figure 3 Combination of both dataset BX-Book-Ratings and BX-Book.
Then, the rating has been normalized for the investigation purpose and DATAFRAM is used as given in Figure 4.
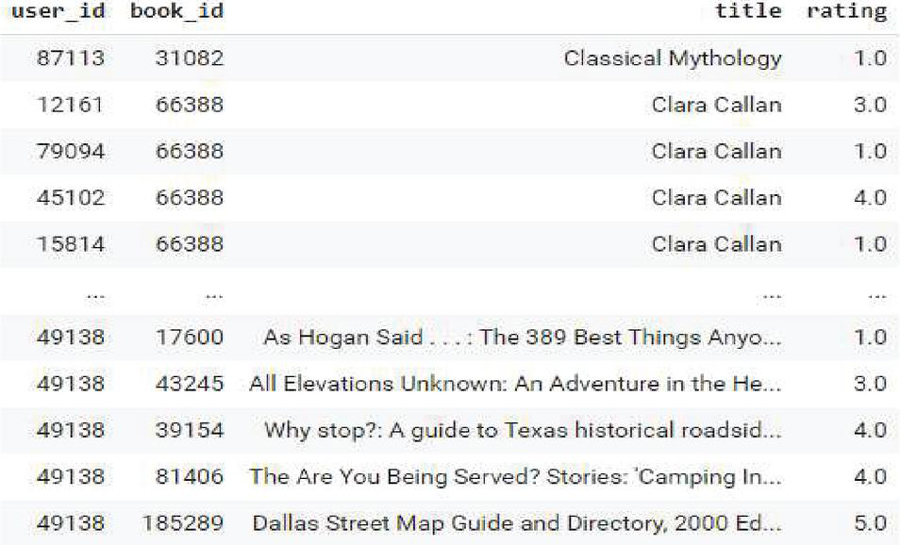
Figure 4 DATAFRAM for rating normalization.
Pre-trained vectors
A tie-up relation exists between the performance of ALS and FSA models to build a hybrid recommender system.
The effectiveness of the proposed FSA models is based on analysis of sentiments have been proved by applying diverse experiments on ABHR-2 for FSA.
In order to build the proposed model and investigate the system efficiency, the input must be handled first, since it treats data with the numerical format that is to be obtained by applying the language models to ABHR-2 to extract vectors out of vocabulary.
Multiplication (Alatrash and Ezaldeen, 2021) is a dataset for pre-computed word embedding representations on NLP techniques. It contains pre-trained word vectors and trained on ABHR-2 based on Continuous Bag of Words and Skip Gram methods by taking the multiplication of the output of two techniques, which are trained on around 80,000 records created for fine-grained sentiment classification in an education environment. It is used to extract vectors out of the corpus. The dimensionality of pre-trained vectors is 300.
Those pre-trained vectors are leveraged to be fed in the input to FSA as described in Section 3.3. The words that are not seen in the pretrained set are randomly initialized.
3.2 Collaborative Filtering Model
A collaborative filtering-based recommendation system depends on the behaviour of a group of users for the recommendation. It tries to predict the user needs based on the rating given by other users. The matrix factorization is utilized where the missing values are predicted from user ratings in the utility matrix, wherein users and items matrices are to be modelled by the latent factors.
3.2.1 Matrix factorization
The interaction user-item utility matrix is a sparse one because the primary active users will only rate a few items. Thus, matrix factorization can factorize this utility matrix into smaller matrices by discovering the latent factors underlying the interactions between users and items. Matrix factorization is used to learn these latent factors for users and items simultaneously to be represented in a lower-dimensional latent space. Those are used later for the approximation of the predicted entries. The following algorithms are used to learn these latent factors of the learners and books based on the rating given from learners to books. Then each learner and book are represented by its respective latent factors that are to be used later for the recommendation process. In the current study, Spark-ML and ML-libraries are used to predict the e-learning resources’ rating utilized in the recommendation.
3.2.2 Alternating least square (ALS)
ALS depends on matrix factorization algorithm that is used to link the learner with his interests. The subtle concept is to decompose the utility matrix into two smaller representations utilizing alternating least squares. The user-item matrix is factored into two low-rank matrices by this algorithm, learner matrix and book matrix. Here, the learners and books are depicted by a small number of latent factors that used to predict the missing entries (Awan et al., 2021). ALS learns to discover the -dimensional of the low order matrices where the original matrix is decomposed into two matrices and where ).
| (1) |
The two matrices describe the characteristics of the books and learners. In fact, learners can’t read and rate all the books, thus the utility matrix is quite sparse. ALS works very well with such sparsity by leveraging the rating of similar learners. ALS fills the blank cells with rating that the learner would give to the books if they were to read by them, thus the books with the highest rating are used to be recommended to the learner, as mentioned in Figure 5.
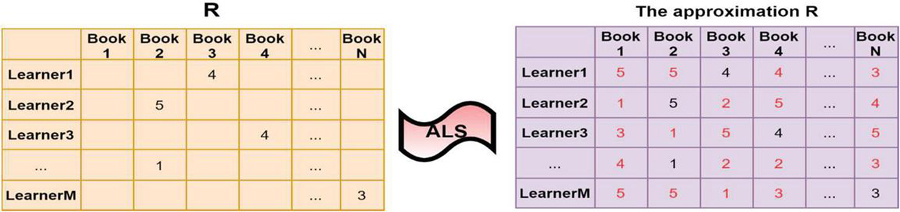
Figure 5 ALS simulation.
The two matrices are the factorization matrices that are multiplied to obtain the estimated rating for each book and learner. The goal of ALS is to discover these latent factors. The estimated rating is computed as follows:
| (2) |
where refers to the ith book and indicates the learner , the preference of book and learner . The Frobenius Norm is utilized to quantify the objective function in Equation (3) by minimizing the error of reconstructing the generated two matrixes and .
| (3) |
By taking the dot product of and , the blank cells in the user-item matrix are filled (Yu et al., 2012), which is the most prominent benefit of ALS.
3.2.3 Recommendation for the new user
1. A new user enters a book, the system generates new user-book interaction for the model.
2. ALS is retrained for the new user data.
3. Book data is created by ALS for inference.
4. ALS predicts the ratings for the entire books for this new user.
5. The output of ALS is the top 10 books that are recommended for the new user based on the predictions of ranked books, as shown in Figure 6.
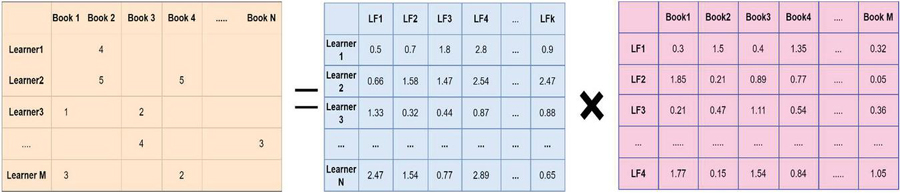
Figure 6 Recommendation for the new user.
The top 10 predicted books form the predicted set of the learner interest, which is considered the learner profile, wherein each book belongs to a specific e-learning category.
Thus, learner interests are derived from the learner profile as a relative vector of e-learning categories based on ALS output.
The predicted set for a learner is as given:
{b b b b, b, b, b, b, b, b}.
For example: (b, b, b, b ) belong to machine learning and (b b) belong to semantic web and so on.
To extract the ratio of each e-learning category such as machine learning, the number of books that belongs to this learning category are picked form the learner profile and to be normalized as follows:
| (4) |
Here is a number of items in the learner profile and is equal to 10.
Equation (5) is applied to compute the ratio of machine learning in the learner profile for a learner , as follows:
| (5) |
Thus, using the FSA models, the system will propose four books obtained the highest suggested rating for the similar e-learning category, and so on for further e-learning categories based on the user model.
That is, the system will provide a top-N personalized recommendation list of e-content based on the user profile.
3.3 Distinct Sentiment Analysis models for Review Data
FSA is a technique to analyse the text to identify sentiment and opinion that exists in this text. FSA can meet the true needs of the learner in an actual application or platforms (Mostafa, 2018). It is divided into five classes from very negative to very positive based on the review’s sentiment corresponding to the encode from ‘1’ to ‘5’. For this purpose, ABHR-2 dataset is used. The most important part is the dataset collected from learner reviews as mentioned in dataset Section 3.1. These reviews and their rating are critical to the researcher and stakeholders such as Amazon, Netflix, etc, to improve the recommendation process by analysing the users’ reviews about books, movies, etc.
Various pre-processing tasks apply to the ABHR-2 corpus to clean it of noise as mentioned in Section 4.1. The input of various deep learning models must be handled first, since they treat data with the numerical format obtained by applying the language models to ABHR-2 to extract vectors out of vocabulary. Each piece of ABHR-2 text is vectorized with pre-trained vectors “Multiplication”.
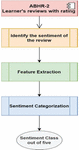
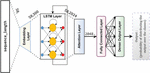
This work will provide a combination of sentiment analysis and deep learning algorithms to obtain a better solution for sentiment classification based on attention mechanism. The process of applying FSA to categorize the learners’ reviews is shown in Figure 7.
The FSA model is built based on the attention mechanism and bi-LSTM. Three models have been constructed: classical attention model, self-attention model and multi head attention model.
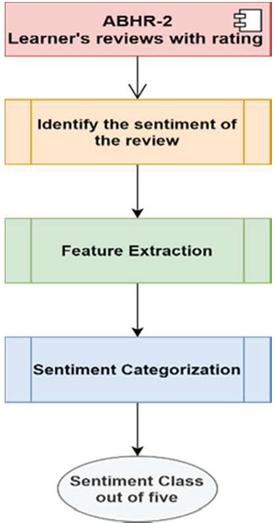
Figure 7 Process of applying FSA to categorize the learners’ reviews.
3.3.1 Attention-based models
The attention mechanism has revolutionized the way we create NLP models and is currently a standard fixture in most state-of-the-art NLP models. All reviews are available as a string representation. Strings cannot be understood by the deep neural network models and, thus, we are required to encode them in a numerical format.
The attention mechanism has emerged as a major global enhancement, particularly in NLP. By default, the attention mechanism uses additive attention and considers the whole context while calculating the relevance. Three attention-based models have been built: classical attention model, self-attention model and multi head attention model.
Attention-based classical attention model (CAM)
In the baseline model, the relative importance of each word must be taken into consideration in the context vector along with input words themselves. Bahdanau et al. (2014) place a special importance on embeddings for the entire words in the input while calculating the context vector. This is accomplished by basically adding the weighted sums of the input vectors. These weights are the position of each word in the sentence and learned utilizing the network of feed-forward neural. Let’s call the input vectors (taken from pre-trained vectors “Multiplication”) and the corresponding output vectors .
To produce output vector , the weighted sum of the input vectors is used in the self-attention process as presented in Equation (6).
| (6) |
indicates the number of words in the sequence. The weight is calculated through a softmax function, as shown in Equation (7).
| (7) |
is calculated as given in Equation (8):
| (8) |
is the length of the sentence and refers to the score of the output of a feedforward neural network depicted via the function that tries to extract the relative relation among output at and input at . To obtain the normalized alignment values for output , the softmax is applied after TAN hyperbolic function.
Attention-based self-attention model (SAM)
One of the major contributions in the field of attention is the self-attention mechanism. It has been revised by offering a highly fundamental and generalized definition of attention that is focused on three vectors: key, query, and values (Vaswani et al., 2017).
Thus, self-attention is the process that connects diverse positions of a sequence to create a precise representation (Cheng et al., 2016). Machine reader technology is the process to interpret the provided textual data automatically. Based to the broad definition, each word embedding should have three distinct matrices: key, query, and value.
These three matrices are created by multiplying the embedding vectors of the input (taken from pre-trained vectors “Multiplication”) by three matrices: key, query, and value () that are trained throughout the training phase to get the three matrices respectively as follows:
| (9) |
The score of every word in the input sentence is calculated with respect to the current word. As we encode a word at a specific location, this score indicates how much emphasis to put on other portions of the input text. This is done by computing the dot product between the query matrix and the key matrix of this specific word as given below:
| (10) |
After that, this score is divided by the square root of the dimension of the used. This leads to having more stable gradients than pass the result through a softmax operation as reported in the Equation (11):
| (11) |
Softmax normalizes the scores so they’re all positive and add up to 1. This softmax score determines how much each word will be expressed at a specific position. Then, multiply each by the softmax score and finally sum up the weighted . This produces the output of the self-attention layer at a certain position as given in Equation (12).
| (12) |
Attention-based multi head attention model (MHAM)
We can give self-attention greater power of discrimination by combining several self-attention mechanisms. This is used to improve the performance of the attention layer by expanding the model’s ability to focus on different positions and giving the attention layer multiple “representation subspaces”.
With multi-headed attention (Li et al., 2018; Cordonnier et al., 2020) we have not only one, but multiple sets of the three weight matrices query, key and value. Each set is initialized randomly. The embedding (taken from pre-trained vectors “Multiplication”) is multiplied by each set to obtain distinct matrices Q, K and V separately. Eventually, we got the output of various matrices.
Every word in the sequence’s word embedding is projected into various “representation subspaces”. The input embeddings are then projected onto a distinct representation subspace using each set after training.
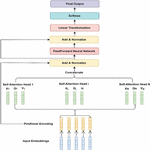
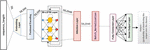
For this aim, the WQ, WK and WV have been split into N matrices and then multiplied with embedding (taken from pre-trained vectors “Multiplication”) to get Q, K and V prior to implementing self-attention. Then the split matrices go via the process of self-attention individually. Every set after applying the self-attention procedure is named a head. Every head generates an output matrix, which is then concatenated into a single weight matrix and passes them to feed forward neural network and then sent through a linear transformation to reduce the dimension back to k. Every head should discover something useful, providing the model additional representational capacity as presented in Figure 8.
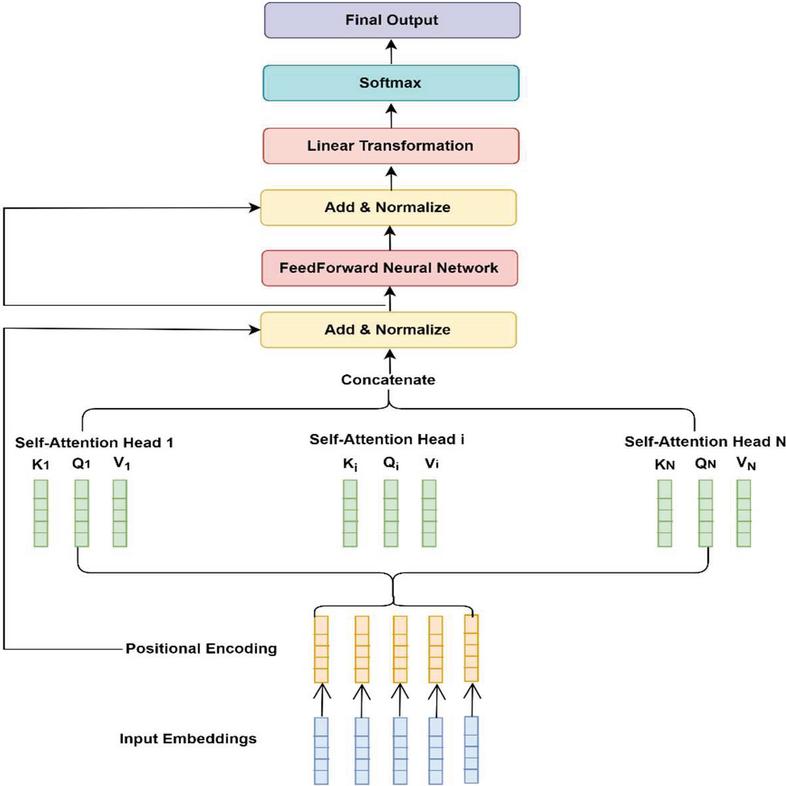
Figure 8 Attention-based multi head attention model architecture.
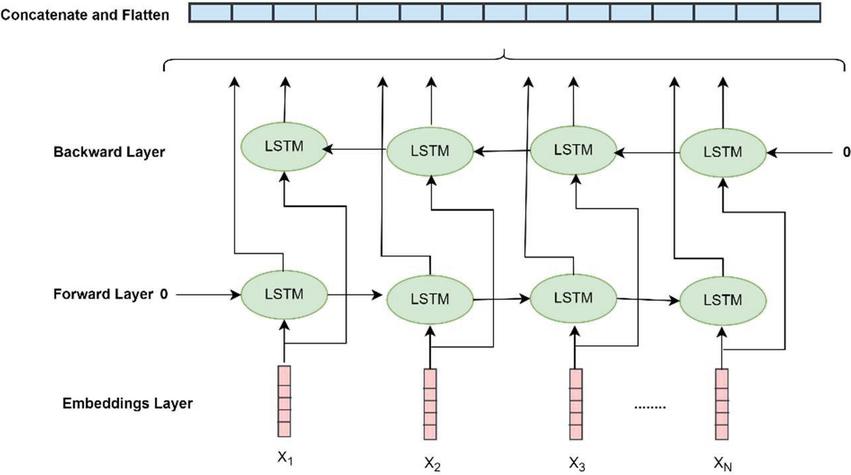
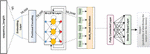
Figure 9 Bi-directional LSTM construction.
3.3.2 Bi-directional LSTM construction
Bi-directional long short-term memory (bi-LSTM) is a type of LSTM model that processes the data in both forward and backward direction, as shown in Figure 9. This feature of flow of data in both directions makes the bi-LSTM understand data better than other algorithms (Xu et al., 2019). Bi-LSTM is really just putting two independent LSTMs together. This structure allows the networks to have both direction information about the sequence at every time step to preserve the future and the past information using the two hidden states combined . indicates the number of words in the sequence.
4 Experiment
4.1 Processing of the Reviews’ Text
The preprocessing phase for the ABHR-2 dataset involved a series of essential tasks aimed at optimizing its quality and suitability for subsequent analysis. To begin, noise reduction procedures were employed to eliminate extraneous and disruptive elements, ensuring the dataset’s cohesiveness and clarity. Following this, a tokenization process was applied to extract a comprehensive vocabulary from the textual corpus. This involved segmenting the text into distinct tokens, such as words or subwords, to facilitate subsequent computational handling. The most crucial step involved the transformation of sentences into numerical representations through vectorization. This entailed mapping tokenized words to unique numerical values or embeddings, resulting in vectors that encapsulate the semantic essence of each sentence. These rigorous preprocessing steps collectively enhance the dataset’s readiness for fine-grained sentiment analysis and recommendation tasks within the education domain.
4.2 Experiments of ALS
The dataset is split into training and testing with proportion and 20% respectively. The root mean square error (RMSE) is utilized for the evaluation process. The smaller value of RMSE is getting more accurate prediction value. The missing items are considered to be those disliked by the learner. So, these items are rated with 1.
The utility matrix was acquired by utilizing Pyspark machine learning library. The number of unique learners and books are computed along with the matrix sparsity.
The parameters that have been chosen for the experiments for each algorithm are briefly described below:
A. Learning rate is fixed 0.01.
B. Regularization parameters is fixed 0.1
C. Latent factors 100
D. Fold cross-validation CV 5, 10, 15 respectively.
E. Times to repeat process 10
F. For ALS: pyspark.ml.recommendation library is used to train the algorithm.
G. All the mentioned algorithms are trained for matrix completion to give a rating for each learner and each book.
H. After training we acquire a new matrix.
I. Sort the rating of the new matrix for each learner.
J. Take the top to be recommended to the learner which form the learner profile to be used further to recommend e-content to the learner based on FSA.
4.3 Experiments of FSA
AHRS-2 is used for fine-grained sentiment classification. The AHRS-2 vocabulary is used as the input for different fine-grained SA models based on the attention mechanism and bi-LSTM. The input of these models is handled by leveraging multiplication pretrained vectors. The text reviews of ABHR-2 are mapped onto multiplication pretrained vectors. In order to extract the word embeddings, each word maps to a pre-trained vector with floating numbers. Hence each word is associated with a respective vector. Those pre-computed vectors serve as input to the models for the purpose of classification. The words which are not seen in the pre-trained set are randomly initialized.
In other words, the input of the models is the text reviews of ABHR-2 with their corresponding rating. The text reviews are represented through the multiplication pretrained vectors, as well as GloVe (Pennington et al., 2014) and word2vec (Mikolove et al., 2013b) which are further utilized to train FSA models. Eventually, the models’ input is the respective pre-computed vectors of the corpus vocabulary along with their rating scores (1 to 5) that are to be fed to bi-LSTM networks.
The output of these models is to categorize the e-learning resource into five classes to be used further in recommendation process. Three attention-based models have been built: classical attention model, self-attention model and multi head attention model as given below.
4.3.1 FSA based classical attention model (CAM)
The attention mechanism is a component of the neural construction which allows dynamic highlighting of significant characteristics of the input data, which are used in NLP as a series of textual components. It is implemented immediately to the input words or its representation in the higher-level. This is the baseline model; all the words of the sequence should be considered in the context vector, in addition to their relative importance.
Model architecture: The first layer is the embedding layer which maps each input word to a pre-trained 300-dimensional multiplication embedding vector.
The second layer is a bi-LSTM layer on both sides which outputs vectors of length 300 with dropout to prevent overfitting. LSTM layer with 1024 number of neurons and return sequence is true.
The third layer is an attention layer to calculating the relevance. This layer outputs vectors of the same length as the previous layer. It produces an encoded representation for each word in the target sequence that captures the meaning and position of each word, as mentioned in Section 3.3.1.1.
The fourth layer is a fully-connected layer. This increases the network’s representational capacity.
The fifth layer is a dropout layer which is used during the training to prevent overfitting.
The sixth layer is an output fully-connected layer. This yields a probability for each word in the vocabulary over the output neurons corresponding to each category using softmax activation.
The model utilized Adam optimizer for training with categorical_crossentropy. Figure 10 shows the model structure.
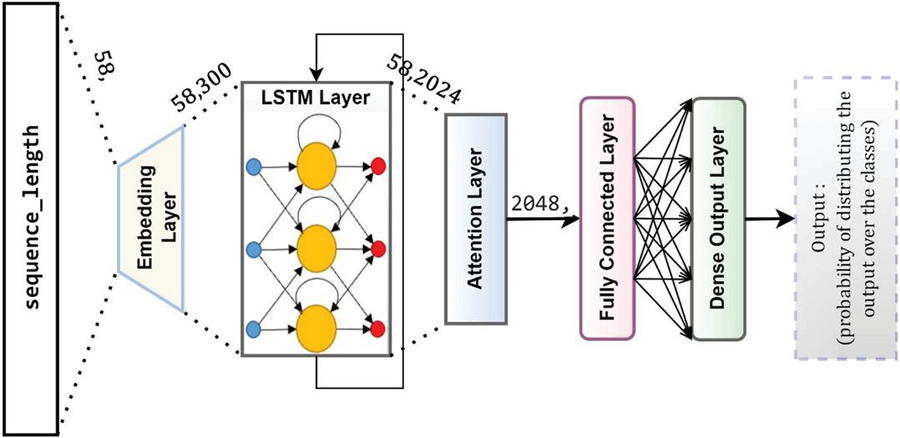
Figure 10 FSA based classical attention model (CAM).
4.3.2 FSA based self-attention model (SAM)
Self-attention, also called intra attention, is an attention mechanism relating different positions of a single sequence in order to compute a representation of the same sequence by allowing the inputs to interact with each other.
Model architecture: In order to construct the model, the first layer is the input embeddings layer where every individual word is mapped to a vector with floating continuous values of pre-trained 300-dimensional multiplication embedding vector.
The second layer is Positional Encoding to inject the information regarding the position to the embeddings by adding the relative information regarding the positions of each word in the sequence into the embeddings by utilizing sin and cosine functions. Then those vectors are added to the input corresponding to the embeddings. This effectively feeds the network about the position of every vector.
The third layer is a bi-LSTM layer on both sides which outputs vectors of length 300 with dropout to prevent overfitting. LSTM layer with 1024 number of neurons and return sequence is true.
The fourth layer is the self-attention layer. This layer is constructed as mentioned in Section 3.3.1.2.
The fifth layer is a fully-connected layer.
The sixth layer is a dropout layer to avoid overfitting.
The seventh layer is output fully-connected layer. This gives the probability for each word in the vocabulary over the output neurons corresponding to each category using softmax activation.
The model utilized Adam optimizer for training with categorical_crossentropy. Figure 11 shows the model architecture.
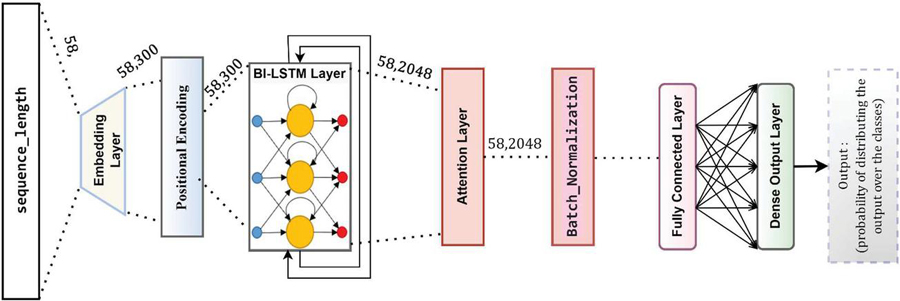
Figure 11 FSA based self-attention model (SAM).
4.3.3 FSA based multi head attention model (MHAM)
This is the most robust model among other models. The multi head attention model is a module for attention mechanisms which runs through an attention mechanism several times in parallel. The independent attention outputs are then concatenated and linearly transformed into the expected dimension.
Model architecture: This model has been built in similar construction to the earlier model barring the fourth layer (attention layer) which has been created based on the multi head attention model as reported in Section 3.3.1.3. The model architecture is presented in Figure 12.
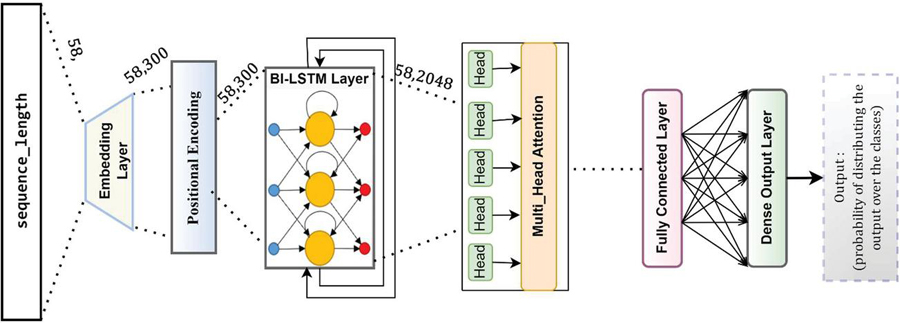
Figure 12 FSA based multi head attention model (MHAM).
4.4 Implementation of Attention-based Models
HCFSAR incorporates two models: the CF model and the FSA model for hybrid recommendation. Based on the learner profile deduced by CF, HCFSAR recommends the books with the highest rating by employing the FSA model. To forecast the ratings of discrete five classes, the FSA model mines sentiment based on text reviews of books. Three FSA models based on attention mechanisms and bi-LSTM are proposed here to predict new ratings from learner-posted book reviews.
On the basis of HCFSAR, 12 models with the restructuring listed below are proposed:
CAM based ABHR-2 with multiplication (CAMAM): in this model, the ABHR-2 corpus is mapped to multiplication pre-trained vectors for text vectorization. Then, these vectors are fed to train CAM. The architecture of CAM is detailed in Section 3.3.1.1.
SAM based ABHR-2 with multiplication (SAMAM): The ABHR-2 corpus is vectorized using Multiplication pre-trained that is used to train SAM. Section 3.3.1.2. describes the architecture of SAM.
MHAM based ABHR-2 with multiplication (MHAAM): The ABHR-2 text is converted utilizing multiplication pre-trained model, which is then leveraged to train MHAM. The MHAM structure is defined in Section 3.3.1.3.
CAM based ABHR-2 with GloVe (CAMAG): it is alike in construction to the CAMAM barring the ABHR-2 vocabulary is mapped to GloVe public dataset of pre-computed vectors.
SAM based ABHR-2 with GloVe (SAMAG): It is built similarly to SAMAM, with the exception that the ABHR-2 vocabulary is mapped to the GloVe public collection of pre-computed vectors.
MHAM based ABHR-2 with GloVe (MHAAG): It is developed in the same way as MHAAM, except that the ABHR-2 word is transferred to the GloVe public dataset of pre-computed vectors.
CAM based ABHR-2 with Mikolove (CAMAMI): The designer of this model is identical to CAMAM, but ABHR-2 corpus is mapped to the pre-computed vectors Mikolov.
SAM based ABHR-2 with Mikolove (SAMAMI): This model has the same construction as SAMAM, but the ABHR-2 corpus is projected to the publicly existed pre-trained vectors Mikolov.
MHAM based ABHR-2 with Mikolove (MHAAMI): This model is built in the same style as MHAAM, except that the ABHR-2 text is transferred to the publicly available dataset of pre-trained vectors Mikolov.
MHAM based SST-1 with multiplication (MHASM): The construction of this model is to vectorize the public dataset SST-1 using our language model multiplication pre-trained vector to train MHAM.
MHAM based hotel reviews with multiplication (MHAHM): The aim of this model is to vectorize the available dataset hotel reviews from booking.com (Kumar et al., 2020) by employing our language model multiplication pre-trained vector in order to train MHAM.
MHAM based hotel reviews with Mikolove (MHAHMI): The same architecture as the earlier model while the hotel reviews dataset is mapped to the publicly available dataset Mikolove of pre-trained vectors to train MHAM.
4.5 Dataset of Pre-computed Vectors Mapping with ABHR-2 and Public Dataset
This experiment was carried out for evaluating the strength of ABHR-2 against other public datasets “SST-1” (Socher et al., 2013) and hotel reviews from booking.com (Kumar et al., 2020). The ABHR-2, SST-1 and hotel reviews corpus vocabulary has been mapped to pre-trained vectors from “multiplication”, “GloVe” or “Mikolov”, and then fed into the input for training FSA models as elaborated in Figure 13.
It involves two levels:
Level 1, the system uses the pre-computed vectors of above datasets for corpus representation.
Level 2, these pre-computed vectors are utilized to vectorize ABHR-2, SST-1 and hotel reviews vocabulary. Each word is mapped to a particular pre-trained vector. Thus, the input of attention based models is the respective pre-computed vectors along with their rating scores (1–5) for FSA. Words that do not appear in the pre-trained language model are randomly initialized.
Moreover, the hotel review public dataset is utilized to appraise the robustness of the suggested FSA models against another model (Kumar et al., 2020) as well as the powerful “multiplication” pretrained vectors.
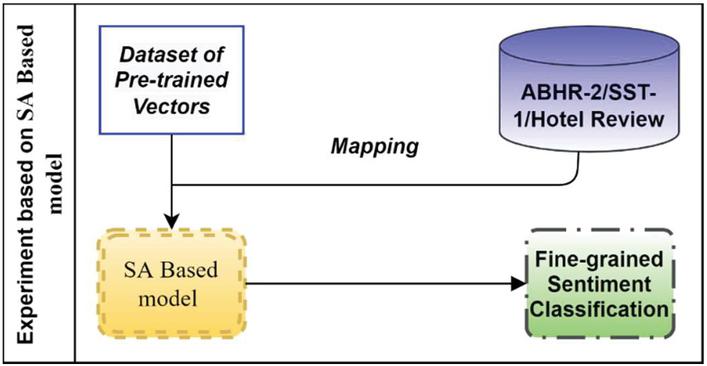
Figure 13 Dataset of pre-computed vectors mapping with ABHR-2 and public dataset.
4.6 Hyperparameter of Deep Learning
Table 1 shows the different parameters that bi-LSTM have been tested and trained on, where the used hyperparameters are reported to rely on the experiments.
Table 1 Hyperparameter of deep learning
| No. of LSTM layers | 2 |
| Units of each layer | 1024 |
| Dropout ratio | 0.5 |
| Batch size | 32 |
| Validation_split | 0.1 |
| No. of classes | 5 |
| Epochs | 30 |
| Return_sequences | True |
| “Dev set” size | Select 10% of the entire training set randomly |
| Optimizer | “Adam optimization” (Kingma and Ba, 2014) |
5 Results and Discussion
This section shows the simulation results of implementing a hybrid recommendation algorithm by integration collaborative filtering and sentiment analysis to develop a new framework. The algorithm recommends books based on learner preferences gleaned from user activity such as book selection and rating, as well as comparable learner behaviour. To create an effective recommender system that takes into consideration instant recommendation, we implemented ALS collaborative algorithms based on matrix factorization for matrix completion to fill up the missing rating. For a hybrid recommendation, SA based attention models are combined with the ALS.
The recommendation process relies on ALS to capture the learner profile. Using the FSA based attention models, the system will then propose the books achieved the highest rank from the same e-learning category based on these predicted set based attention models.
Table 2 displays the findings of recommending two different books “Dallas Street Map Guide and Directory, 2000 Ed…” and “Life’s Little Instruction Book Life’s Little…” for the learner with ID “49138”, and shows the predicted rating compared to the actual rating given by the learner with three Cross-Validation (CV) 5/10/15.
Table 2 Findings of recommending two different books for the same user
| Algorithm | CV | UserId | BookId | Predicted Rating | Actual Rating | Book Title | |
| 1 | ALS | 5/10/15 | 49138 | 185289 | 4.33 /4.56/ 4.58 | 5 | Dallas Street Map Guide and Directory, 2000 Ed… |
| 2 | ALS | 5/10/15 | 49138 | 264625 | 2.66/ 2.81/3.89 | 4 | Life’s Little Instruction Book (Life’s Little… |
Table 2 presents the difference between the actual rating and the rating predicted by ALS for two books and same user based on three CV 5/10/15. The actual rating for the first book is 5 and the predicted rating is 4.58 with CV 15 which is better than CV 5,10 which shows 4.33, 4.56 respectively. In the same direction, the second book ALS with CV 15 reported 3.89 better predicted rating out of 4 actual rating compared to CV 5,10 which displays 2.66, 2.81 respectively.
Table 3 reports the performance of ALS across multiple assessment measurements root mean square error (RMSE), mean square error (MSE), and Mean absolute error (MAE) based on CV equal to 5,10,15 to evaluate and train the methods’ outcomes. ALS has been trained based on tuning different parameters. The dataset is split into 80/20 for training and testing respectively. The accuracy is assessed based on the predicted ratings of the matrices RMSE, MSE and MAE. The lower the RMSE, the more precise the prediction. From the given outcomes it can be seen that CV 15 shows the best findings among all measurements. It is observed for CV 15 RMSE is 0.9715, and MSE 0.9265, while MAE is equal to 1.1485, which is better than CV 5,10 which acquires fewer results. In order to conduct a comparative analysis, the ALS algorithm was pitted against alternative methods. Notably, Anwar et al. (2021) observed a notably unfavourable RMSE of 2.6215, along with a CV value of 15 for the SVD++ model. In a separate context, Priyati et al. (2022) recorded an elevated RMSE value of 2.4672 for ALS under distinct experimental conditions. These findings underscore the effectiveness of our proposed model, showcasing its superior performance.
Table 3 The performance of ALS across multiple assessment measurements
| RMSE | MAE | MSE | |||||||
| Algorithm | CV 5 | CV 10 | CV 15 | CV 5 | CV 10 | CV 15 | CV 5 | CV 10 | CV 15 |
| ALS | 0.9898 | 0.9947 | 0.9715 | 1.3284 | 1.4781 | 1.1485 | 0.9874 | 0.9747 | 0.9265 |
| SVD++ (Anwar et al., 2021) | 2.6215 | 2.6227 | 2.6236 | 1.5778 | 1.557 | 1.563 | – | – | – |
| ALS (Priyati et al., 2022 ) | 2.4672 | ||||||||
Based on the ALS output, the learner interests are captured from the learner profile that are used to recommend the books that obtained the highest predicted rating from a similar e-learning category by leveraging the SA based attention models.
Thus, several experiments have been conducted to compare the achievements of variant models and estimate the findings of different SA based attention models. The classical attention model is the simplest one that computes the relative importance of each word. It has less computation time but also has lower accuracy with higher overfitting in the loss function accuracy when compared to other models.
The self-attention model connects multiple positions of a sentence to obtain a more precise representation by having for every word embedding three separate matrices corresponding to it. It introduced better accuracy with lower overfitting, but it needs more computation.
The outperformed model is the multi head attention model that brings the best accuracy with lowest overfitting in this experiment with more computation. This model is then used for further experiments with public datasets.
In order to prove the effectiveness of the proposed models along with strengthening of the multiplication for word embedding and the powerful of the ABHR-2 created for an education domain, the above models are trained and tested on ABHR-2 along with another public datasets and compared with other models.
Table 4 The results comparison of our models against others based on Four evaluation measures
| Word | |||||||
| Trained on | Embeddings | The Model | |||||
| Mapped to | Dataset | Techniques | Name | Accuracy | Precision | Recall | F1 Score |
| ABHR-2 | ABHR-2 | Multiplication | CAMAM | 89.43% | 90.42% | 89.50% | 90.45% |
| SAMAM | 90.43% | 90.42% | 90.31% | 90.30% | |||
| MHAAM | 93.39% | 93.49% | 93.38% | 93.78% | |||
| Stanford | GloVe | CAMAG | 65.60% | 65.61% | 65.50% | 65.39% | |
| dataset | SAMAG | 77.60% | 77.68% | 77.50% | 77.59% | ||
| MHAAG | 81.04% | 81.07% | 81.09% | 81.65% | |||
| Mikolove | CAMAMI | 73.86% | 73.92% | 73.81% | 73.78% | ||
| dataset | SAMAMI | 84.91% | 85.04% | 84.86% | 84.88% | ||
| MHAAMI | 88.65% | 88.44% | 88.40% | 88.59% | |||
| SST-1 | ABHR-2 | Multiplication | MHASM | 74.72% | 75.04% | 74.65% | 74.79% |
| Google dataset | Mikolove | CNN-multichannel (Kim, 2014) | 47.4% | – | – | – | |
| Hotel reviews from booking.com | Google dataset | Mikolove | MHAHMI | 89.40% | 89.43% | 89.42% | 89.39% |
| (Kumar et al., 2020) | ABHR-2 | Multiplication | MHAHM | 90.31% | 91.52% | 90.97% | 89.21% |
| Google Dataset | Mikolove | CNN based (Kumar et al., 2020) | 88.52% | 94.30% | 85.63% | 86.03% |
Table 4 describes four evaluation measures.
A. Experimental results of training ABHR-2 depending on attention-based models using various word embeddings
The effectiveness of the proposed model HCFSAR is assessed in terms of attention-based model performance for FSA to estimate the sentiment categorization.
This section presents the results of vectorizing ABHR-2 vocabulary using three different pre-trained word embedding models; “multiplication”, “Mikolove” and “GloVe”. The output of these models is fed to three attention-based models relying on the bi-LSTM network and the output of these models is the score of the sentiment of the sequence.
Utilizing Mikolove and GloVe public datasets of pre-computed vectors to vectorize ABHR-2 vocabulary is then used to train CAM results in an accuracy of 73.86% and 65.60%, respectively, which is lower than mapping the ABHR-2 corpus to the pre-computed vectors multiplication to train the same model that yields an accuracy of 89.43%.
This highlights the efficiency of multiplication pre-computed vectors trained on datasets for an education environment when compared to openly accessible pre-trained vectors trained on datasets for general objectives.
B. Experimental results of training SST-1 depend on MHAM using multiplication word embeddings
To verify the robustness of the ABHR-2 dataset generated for a given domain is better than the general-purpose generated domain, MHASM is trained by mapping SST-1 vocabulary to pre-computed multiplication vectors that are fed to train the MHAM and acquires 74.72% better accuracy compared to other models implemented by Kim (2014) that gained 47.0% lower accuracy using the same “SST-1” dataset.
Also, this proves the power of our pre-trained vectors multiplication that trained on a dataset created for a specific domain against the one trained on the “Mikolove” generic domain.
Moreover, this experiment leads to our proposed attention based models being better than those proposed by Kim (2014).
C. Experimental results of using various word embeddings datasets to vectorize the hotel review dataset depend on MHAM.
This experiment was also carried out to ensure the reliability of the word embeddings trained on dataset produced for a particular domain is superior to those trained on dataset general-purpose generated domain.
MHAHM leveraged pre-computed multiplication vectors to vectorize hotel reviews from the booking.com (Kumar et al., 2020) corpus, which is used to train MHAM and achieves 90.31% more accuracy than other models. MHAHMI maps the hotel reviews corpus into pre-trained Mikolove vectors for text representation, which are further used to train MHAM, and obtains lower accuracy of 89.40%.
Furthermore, the findings of this experiment reveal that our proposed attention based model significantly outperforms those offered by a CNN-based model (Kumar et al., 2020). MHAHMI trained on MHAM for FSA performed better and gained 89.40% better accuracy compared to the model suggested by Kumar et al. (2020) which yields 88.52% lower accuracy while training both models on the same dataset.
This proves the effectiveness of our proposed attention based models which for FSA outperformed other models, as mentioned in Table 4.
As far as our understanding goes, there has been no prior endeavour to amalgamate FSA with collaborative filtering within the realm of the education domain. The performance of the system results from the synergy between the correlated collaborative filtering model and FSA models. The collaborative filtering model plays a pivotal role, influencing the introduction of an appropriate learner profile. In addition, the FSA model acts as an augmentation tool for hybrid recommendations, aiding in the prediction of optimal content. In comparison with state-of-the-art approaches, these two system models outperformed the others. This distinctive fusion of the two system models greatly enhances the overall performance of the proposed hybrid recommender system.
6 Discussion
The proposed system HCFSAR has been evaluated based on CF model and attention based models in order to develop a hybrid framework e-content recommendation depending on the learner’s feedback. For a hybrid recommendation, SA based attention models are combined with the ALS to create an efficient recommendation. The ALS applied to the user-item matrix utility relies on a matrix factorization algorithm for matrix completion to fill up the missing rating to deduce the learner interests and build the learner profile. The learner profile is constructed based on learner preferences gleaned from user activity such as book selection and rating, as well as comparable learner behaviour. Then, based on the results of ALS, HCFSAR recommends the books that obtained the highest rank predicted for similar e-learning category by leveraging various FSA based attention models and bi-LSTM to forecast the new ratings from the book comments posted by learners for FSA. In the simulation results, ALS performed better when CV 15 for all measurements; RMSE is 0.9715, and MSE 0.9265, while MAE is equal to 1.1485 which is less than training ALS with CV 5,10.
Furthermore, the experimental results of attention based models reveal that MHAM outperformed CAM, SAM and other models. Vectorizing ABHR-2 using pre-trained multiplication vectors resulted in MHAAM 93.39%, outperforming CAMAM 89.43% and SAMAM 90.43%. These models outstand the rest models where ABHR-2 corpus is mapped to public pre-trained vectors word2vec that presents for CAMAMI 73.86%, SAMAMI 84.91% and MHAAMI 88.65%. While representing the text corpus based on ‘GloVe’ yielded for CAMAG, SAMAG and MHAAG lower accuracy with values of 65.60%, 77.60% and 81.04% respectively.
Moreover, MHASM trained by associating SST-1 vocabulary with pre-computed multiplication vectors acquires better accuracy of 74.72% compared to other models implemented by Kim (2014) gained 47.0% lower accuracy using the same “SST-1” dataset.
Additionally, training MHAHM based on transfer hotel reviews from the booking.com (Kumar et al., 2020) corpus into pre-computed multiplication vectors achieves 90.31% more accuracy than other models MHAHMI where pre-trained word2vec vectors are leveraged to vectorize the same dataset which obtain lower accuracy 89.40%. MHAHMI is further compared to the model proposed by Kumar et al. (2020) which results in a lower accuracy of 88.52%.
The results prove the validity and robustness of the pre-computed multiplication vectors that have been trained using a dataset developed for a specialized domain rather than a public purpose and provides evidence of ABHR’s epistemic efficacy 2 as well as the effectiveness of our proposed attention based models.
In this research, the process of generating personalized e-content recommendations is explained in detail. The initial step involves predicting the top 10 books that constitute the learner’s profile, each aligned with a specific e-learning category. These learner interests are established as a relative vector of e-learning categories, determined by the ALS output. This results in a set of top 10 books for a given learner.
For instance, a subset of four books may belong to the “machine learning” category, while another subset of two books aligns with the “semantic web” category. To quantify the learner’s affinity for each e-learning category, the ratio of books within that category is calculated using Equation (4), where the number of books belonging to a specific learning category is normalized by the total number of items in the learner profile, which is 10 in this context. For example, if there are four machine learning books within the learner profile, Equation (5) computes the ratio as 0.4. Utilizing FSA models, the system then suggests the top-rated books within each e-learning category based on these calculated ratios. For instance, if the machine learning ratio is 0.4, the system will recommend the highest-rated four books in that category. This process extends to other e-learning categories, ultimately leading to the provision of a personalized recommendation list of e-content, tailored to the learner’s profile.
Moreover, the research work centres on the analysis of educational books, predominantly within the realm of computer science. Given the nature of educational materials, it is anticipated that reviews associated with these books would ideally exhibit lower levels of subjectivity and emotional affect. Instead, the focus of the analysis is expected to shift towards more objective assessments and comments concerning the books. This approach aligns with the educational context, where the primary objective is to glean insights about the book’s content, utility, and applicability in a structured and informative manner.
In such a scenario, the research strives to foster a rigorous analytical environment where the emphasis is placed on extracting valuable and actionable insights for educational purposes. The intent is to offer an objective evaluation of the educational resources, catering to the needs of learners, educators, and academic institutions. By prioritizing objective commentary, the research aims to provide a balanced and comprehensive view of the quality and effectiveness of these educational books, facilitating informed decision-making and enhancing the educational experience within the computer science domain.
Figures 14 to 22 elaborate the accuracy against epoch, and loss against epoch, for the attention based models relying on ABHR-2 and pre-trained vectors multiplication, GloVe, and Mikolove (word2vec).
Attention based models integrated with ABHR-2 and multiplication figures:
Figure 14 CAMAM with ABHR-2 and multiplication.
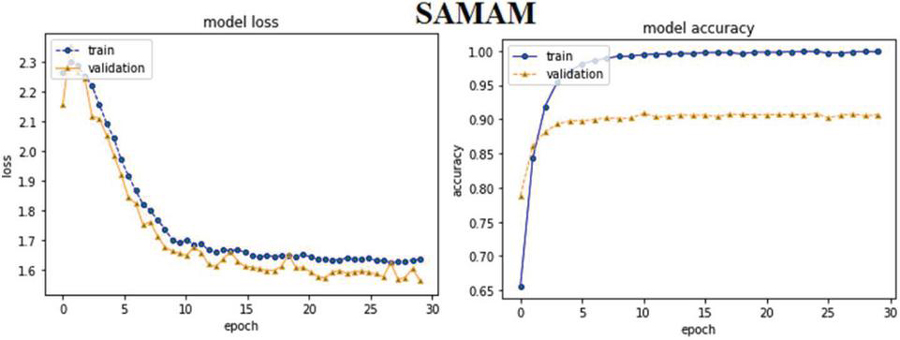
Figure 15 SAMAM with ABHR-2 and multiplication.
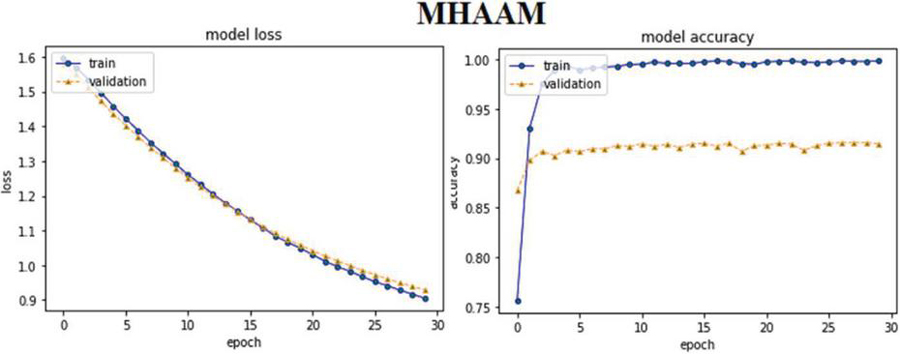
Figure 16 MHAAM with ABHR-2 and multiplication.
Attention based models integrated with ABHR-2 and GloVe figures:
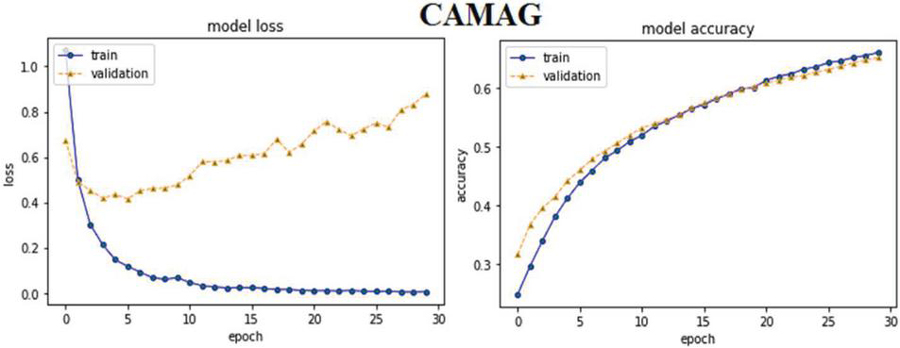
Figure 17 CAMAG with ABHR-2 and GloVe.
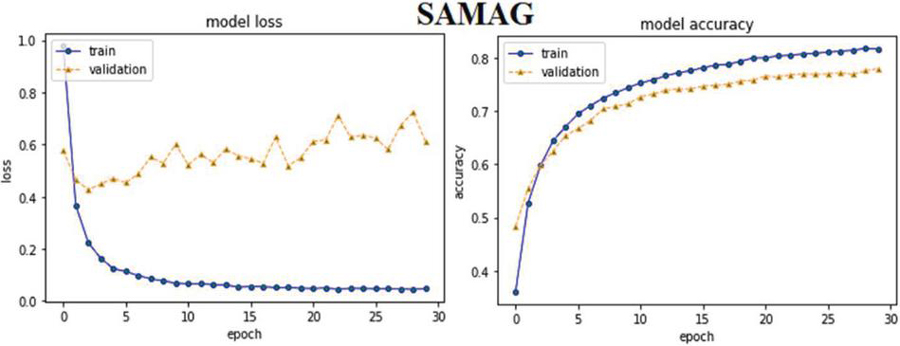
Figure 18 SAMAG with ABHR-2 and GloVe.
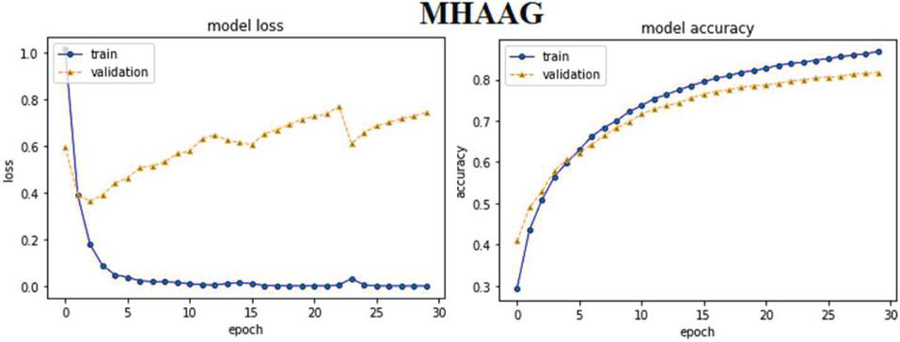
Figure 19 MHAAG with ABHR-2 and GloVe.
Attention based models integrated with ABHR-2 and Mikolove figures:
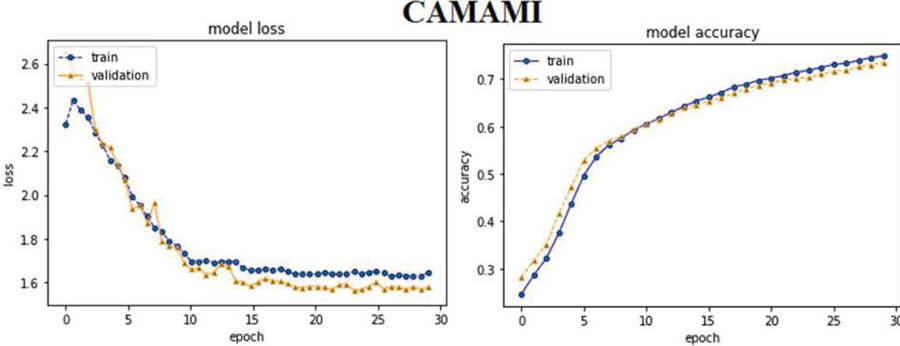
Figure 20 CAMAMI with ABHR-2 and Mikolove.
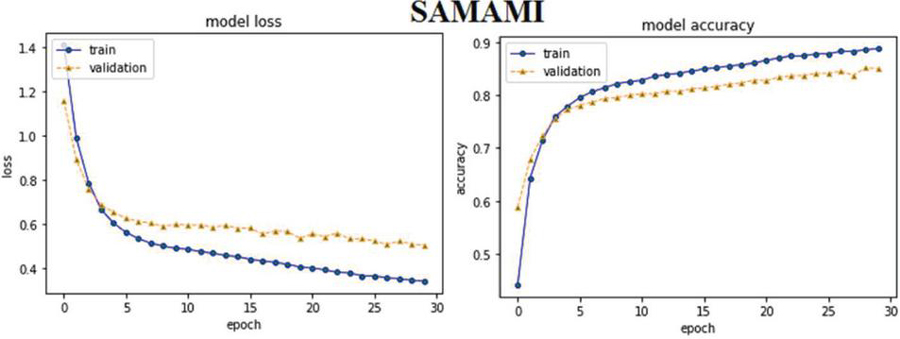
Figure 21 SAMAMI with ABHR-2 and Mikolove.
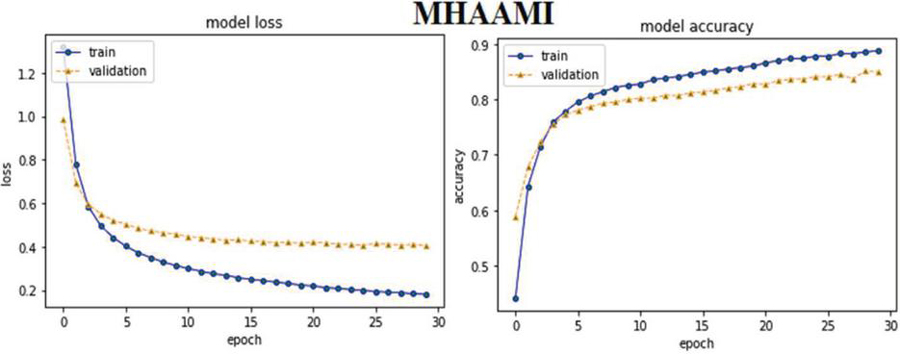
Figure 22 MHAAMI with ABHR-2 and Mikolove.
The best model MHAM integrated with multiplication and Mikolove to vectorize hotel reviews that is shown in Figure 23.
MHAM combined with hotel reviews and multiplication figure:
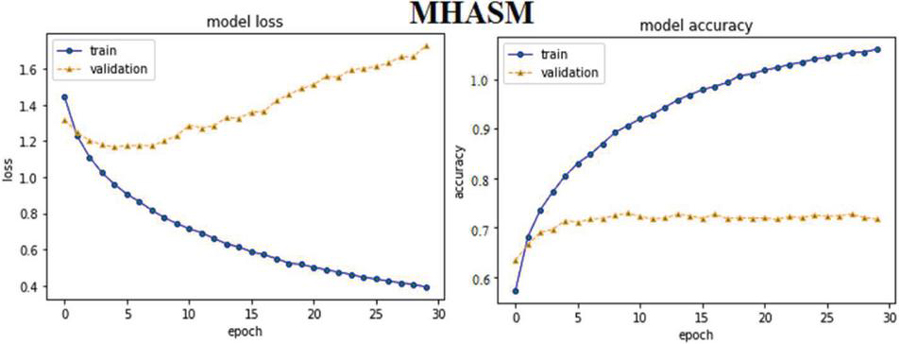
Figure 23 MHAM combined with hotel reviews and multiplication.
MHAM combined with hotel reviews and Mikolove Figure 24:
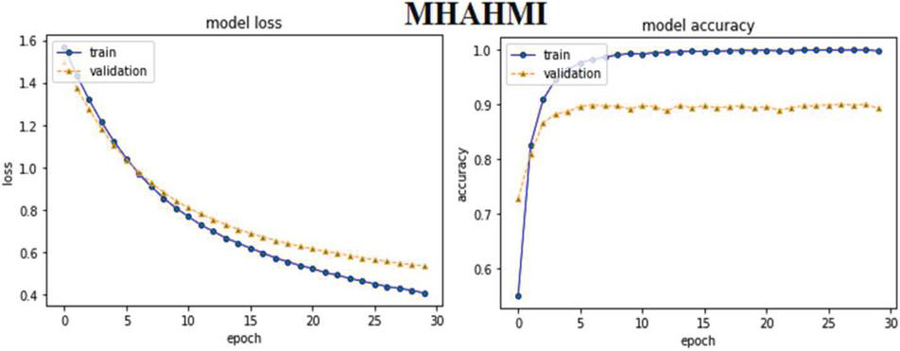
Figure 24 MHAM combined with hotel reviews and Mikolove.
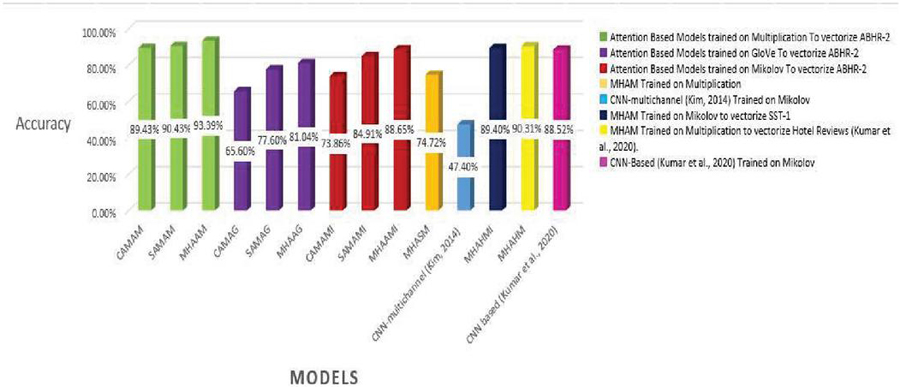
Figure 25 Comparison of the proposed attention based models trained on ABHR-2 against other models and datasets.
When we applied FSA to the ABHR-2 built for the education domain, we noticed remarkable results with improved capability. It is labelled with five classifications, in contrast to most academics nowadays who perform their study utilizing FSA with polarity to categorize reviews as positive or negative. This results in a more forward-thinking and strengthened operation, making the sentiment analysis process more complicated and impactful.
Figure 25 presents the comparison of the proposed attention based models trained on ABHR-2 integrated with multiplication pre-computed vectors against other Mikolove and GloVe pre-trained generic vectors along with general purpose-generated textual generic dataset, in addition to other models (Kim, 2014; Kumar et al., 2020).
The real-world usefulness of the proposed HCFSAR framework will depend on its ability to provide accurate, relevant, and personalized recommendations to learners, considering different factors. Personalization where the hybrid approach combines collaborative filtering and sentiment analysis to provide more personalized recommendations. Recommendation quality where the recommendations align with learners’ preferences and needs will determine the effectiveness of the framework. If the predictions from both CF and FSA models are accurate, learners are more likely to engage with the recommended content and the recommendations will be more relevant. Scalability can be achieved by handling a large number of users, items, and interactions. If the system can scale to accommodate a diverse user base, it can be more useful in real-world scenarios. In addition to many other factors such as usability, adaptability, sentiment analysis accuracy, integration, and feedback incorporation. Further research and testing are needed to assess its practical effectiveness in diverse eLearning settings.
7 Conclusion
Improving e-learning environments necessitates the use of an efficient recommender system in order to achieve a successful learner recommendation process. The system HCFSAR demonstrated in this paper is proposed by incorporating two models, the CF model and FSA model, for hybrid recommendation. Much research has approached this subject from a limited perspective, ignoring key significant aspects and other critical components.
The CF based on ALS, which relies on a matrix factorization method, is being used to infer the learner profile. This is leveraged in conjunction with the user-item matrix utility to determine the learner’s preferences and construct the learner profile. In addition, by using the FSA model, the system suggests books with the highest predicted score based on the learner profile. The FSA approach mines sentiment based on text reviews of books to infer ratings of five discrete classes that is used further in the hybrid recommendation.
The ABHR-2 dataset is used in order to improve the recommendation, which comprises of user reviews classified with five categories and is leveraged further to train various attention based models.
Compared to former models reported in the literature, our models performed substantially better and produced relevant results.
Our findings back up the well-established evidence, which uses pre-computed multiplication trained on ABHR-2 generated for an education environment rather than the one created for a general purpose to provide a superior representation of the corpus. As a result, the recommendation process moves in the appropriate direction.
Future work will be conducted to infer the user model by observing other methods and approaches, making use of knowledge graphs (KGs) for recommendation, investigation of the most efficient FSA models based on attention mechanism and deep learning models, and constructing a model-based transformer structure for embedding learning.
Appendix
Table A1: Terms used in this paper
| Natural language processing | Cyber-physical systems |
| Human–computer interaction | Data analytics |
| Parallel computing | Wearable technology |
| Mobile computing | Bioinformatics |
| Software development | Semantic web |
| Information systems | Knowledge discovery |
| Digital signal processing | Multimedia systems |
| Data science | Operating systems |
| Virtual reality | Compiler design |
| Computer graphics | Algorithm optimization |
| Embedded systems | Simulation and modelling |
| Cloud computing | Image processing’, |
| Distributed systems | Deep learning |
| Computer networks | Cyber security |
| Internet of Things (iot) | Natural language processing |
| Robotics | Human–computer interaction |
| Neural networks | Parallel computing |
| Cryptography | Mobile computing |
| Data warehousing | Software development |
| Web development | Information systems |
| Bioinformatics | Digital signal processing |
| Quantum computing | Data science |
| Wireless communication | Virtual reality |
| Machine vision | Computer graphics |
| Pattern recognition | Software engineering |
References
Ahmed, Z., and Wang, J. (2023). A fine-grained deep learning model using embedded-CNN with BiLSTM for exploiting product sentiments. Alexandria Engineering Journal, 65, 731–747. DOI: https://doi.org/10.1016/j.aej.2022.10.037.
Alatrash R, Ezaldeen H, Misra R, Priyadarshini R, 2021. Sentiment Analysis Using Deep Learning for Recommendation in E-Learning Domain. InProgress in Advanced Computing and Intelligent Engineeringpp. 123–133. Springer, Singapore. https://doi.org/10.1007/978-981-33-4299-6\_10.
Alatrash R., Ezaldeen H., 2021. rawaa123/Dataset GitHub Retrieved from https://github.com/rawaa123/Dataset/.
Alencar, M., and Netto, J, 2020. Measuring student emotions in an online learning environment. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence (Vol. 10, p. 0008956505630569).
Aljunid, M. F., and Manjaiah, D. H. (2019). Movie recommender system based on collaborative filtering using apache spark. In Data Management, Analytics and Innovation: Proceedings of ICDMAI 2018, Volume 2 (pp. 283–295). Springer Singapore.
Anwar, T., Uma, V., and Srivastava, G. (2021) Rec-cfsvd++: Implementing recommendation system using collaborative filtering and singular value decomposition (svd)++. International Journal of Information Technology & Decision Making, 20(04), 1075–1093.
Anwar, T., Uma, V., and Srivastava, G. (2021) Rec-cfsvd++: Implementing recommendation system using collaborative filtering and singular value decomposition (svd)++. International Journal of Information Technology & Decision Making, 20(04), 1075–1093
Awan MJ, Khan RA, Nobanee H, Yasin A, Anwar SM, Naseem U, Singh VP, 2021 Jan. A Recommendation engine for predicting movie ratings using a big data approach. Electronics.;10(10):1215. https://doi.org/10.3390/electronics10101215.
Bahdanau D, Cho K, Bengio Y, 2014 Sep 1. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
Bhanuse R, Mal S, 2021 Mar 25. A Systematic Review: Deep Learning based E-Learning Recommendation System. In2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS) pp. 190–197. IEEE.
Bobadilla, J. E. S. U. S., Serradilla, F., and Hernando, A, 2009. Collaborative filtering adapted to recommender systems of e-learning. Knowledge-Based Systems, 22(4), 261–265.
Bourkoukou, O., and El Bachari, E, 2018. Toward a hybrid recommender system for e-learning personnalization based on data mining techniques. JOIV: International Journal on Informatics Visualization, 2(4), 271–278.
Bourkoukou, O., and El Bachari, E, 2018. Toward a hybrid recommender system for e-learning personnalization based on data mining techniques. JOIV: International Journal on Informatics Visualization, 2(4), 271–278,.
Bu, J., Ren, L., Zheng, S., Yang, Y., Wang, J., Zhang, F., and Wu, W, 2021. ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction. arXiv preprint arXiv:2103.06605.
Burke R, 2007. Hybrid Web Recommender Systems. In: Brusilovsky P., Kobsa A., Nejdl W. (eds) The Adaptive Web. Lecture Notes in Computer Science, vol 4321. Springer, Berlin, Heidelberg,. https://doi.org/10.1007/978-3-540-72079-9\_12.
Cai, H., Xia, R., and Yu, J, (2021, August). Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (pp. 340–350).
Cambria, E., Li, Y., Xing, F. Z., Poria, S., and Kwok, K, (2020, October). SenticNet 6: Ensemble application of symbolic and subsymbolic AI for sentiment analysis. In Proceedings of the 29th ACM international conference on information & knowledge management (pp. 105–114).
Cheng J, Dong L, Lapata M, 2016 Jan 25. Long short-term memory-networks for machine reading. arXiv preprint arXiv:1601.06733.
Cordonnier JB, Loukas A, Jaggi M, 2020 Jun 29. Multi-head attention: Collaborate instead of concatenate. arXiv preprint arXiv:2006.16362.
Das, N., and Sagnika, S, 2020. A Subjectivity Detection-Based Approach to Sentiment Analysis. In Machine Learning and Information Processing (pp. 149–160). Springer, Singapore.
Dessí, D., Dragoni, M., Fenu, G., Marras, M., and Recupero, D. R, 2020. Deep learning adaptation with word embeddings for sentiment analysis on online course reviews. In Deep Learning-Based Approaches for Sentiment Analysis (pp. 57–83). Springer, Singapore. https://doi.org/10.1007/978-981-15-1216-2\_3.
Ekstrand, M. D., Riedl, J. T., and Konstan, J. A. (2011). Collaborative filtering recommender systems. Foundations and Trends in Human–Computer Interaction, 4(2), 81–173.
El Mekki, A., El Mahdaouy, A., Berrada, I., and Khoumsi, A, (2021, June). Domain Adaptation for Arabic Cross-Domain and Cross-Dialect Sentiment Analysis from Contextualized Word Embedding. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 2824–2837).
Ezaldeen H, Misra R, Bisoy SK, Alatrash R, Priyadarshini R, 2022. A hybrid E-learning recommendation integrating adaptive profiling and sentiment analysis. Journal of Web Semantics. 1;72:100700. https://doi.org/10.1016/j.websem.2021.100700.
Ezaldeen, H., Misra, R., Alatrash, R, 2019. and Priyadarshini, R, “Machine Learning Based Improved Recommendation Model for E-learning,” International Conference on Intelligent Computing and Remote Sensing (ICICRS), 2019, pp. 1–6, doi: 10.1109/ICICRS46726.2019.9555866.
Ezaldeen, H., Misra, R., Alatrash, R, 2020. and Priyadarshini, R., semantically enhanced machine learning approach to recommend e-learning content. International Journal of Electronic Business. 15(4):389–413. doi: 10.1504/IJEB.2020.111095.
Fu, Y., Liao, J., Li, Y., Wang, S., Li, D., and Li, X. (2021). Multiple perspective attention based on double BiLSTM for aspect and sentiment pair extract. Neurocomputing, 438, 302–311. https://doi.org/10.1016/j.neucom.2021.01.079.
Garg, R., Singhal, M., Singh, P., Nagrath, P. (2023). Sentiment Analysis of Reviews Using Bi-LSTM Using a Fine-Grained Approach. In: Khanna, A., Gupta, D., Kansal, V., Fortino, G., Hassanien, A.E. (eds) Proceedings of Third Doctoral Symposium on Computational Intelligence. Lecture Notes in Networks and Systems, vol 479. Springer, Singapore. https://doi.org/10.1007/978-981-19-3148-2\_71.
Gong, C., Yu, J., and Xia, R, (2020, November). Unified Feature and Instance Based Domain Adaptation for End-to-End Aspect-based Sentiment Analysis. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 7035–7045).
Guner L., Coyne E., Smit J, March, 2019. Sentiment analysis for Amazon.com reviews. https://www.researchgate.net/publication/332622380.
Hameed, M. A., Al Jadaan, O., and Ramachandram, S. (2012). Collaborative filtering based recommendation system: A survey. International Journal on Computer Science and Engineering, 4(5), 859.
Jeevamol, J., and Renumol, V. G, 2021. An ontology-based hybrid e-learning content recommender system for alleviating the cold-start problem. Education and Information Technologies, 1-30.
Ke, P., Ji, H., Liu, S., Zhu, X., and Huang, M, 2019. SentiLARE: Sentiment-aware language representation learning with linguistic knowledge,. arXiv preprint arXiv:1911.02493.
Kim, Y. (2014). Convolutional neural networks for sentence classification. arXiv:1408.5882.
Kingma, D. P., and Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Klašnja-Milićević, A., Ivanović, M., Vesin, B., and Budimac, Z, 2018. Enhancing e-learning systems with personalized recommendation based on collaborative tagging techniques. Applied Intelligence, 48(6), 1519–1535.
Koffi, D. D. A. S. L., Ouattara, N., Mambe, D. M., Oumtanaga, S., and ADJE, A., 2021. Courses Recommendation Algorithm Based On Performance Prediction In E-Learning. IJCSNS, 21(2), 148.
Kudori DS, 2021 Jun. Event Recommendation System using Hybrid Method Based on Mobile Device. Journal of Information Technology and Computer Science. 15;6(1):107–16. https://doi.org/10.25126/jitecs.202161221.
Kumar, A., Seth, S., Gupta, S., and Maini, S, 2021. Sentic computing for aspect-based opinion summarization using multi-head attention with feature pooled pointer generator network. Cognitive Computation, 1–19.
Kumar, R., Pannu, H. S., and Malhi, A. K. (2020). Aspect-based sentiment analysis using deep networks and stochastic optimization. Neural Computing and Applications, 32(8), 3221–3235. https://doi.org/10.1007/s00521-019-04105-z.
Li J, Tu Z, Yang B, Lyu MR, Zhang T, 2018 Oct 24. Multi-head attention with disagreement regularization. arXiv preprint arXiv:1810.10183.
Lin, Y., Fu, Y., Li, Y., Cai, G., and Zhou, A. (2021). Aspect-based sentiment analysis for online reviews with hybrid attention networks. World Wide Web, 24(4), 1215–1233. https://doi.org/10.1007/s11280-021-00898-z.
Liu, X. (2019). A collaborative filtering recommendation algorithm based on the influence sets of e-learning group’s behavior. Cluster Computing 22, no. 2, 2823–2833. https://doi.org/10.1007/s10586-017-1560-6.
López, M., Valdivia, A., Martínez-Cámara, E., Luzón, M. V., and Herrera, F, 2019. E2SAM: Evolutionary ensemble of sentiment analysis methods for domain adaptation. Information Sciences, 480, 273–286.
Madani, Y., Ezzikouri, H., Erritali, M., and Hssina, B, 2020. Finding optimal pedagogical content in an adaptive e-learning platform using a new recommendation approach and reinforcement learning. Journal of Ambient Intelligence and Humanized Computing, 11(10), 3921–3936.
Mikolov, T., Chen, K., Corrado, G., and Dean, J, 2013a. estimation of word representations in vector space. Efficient. arXiv preprint arXiv: 1301.3781.
Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv:1301.3781.
Mikolov, T., I., Chen, K., Corrado, G. S., and Dean, J, 2013b. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111–3119).
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., and Dean, J. (2013b). Distributed representations of words and phrases and their compositionality. arXiv:1310.4546.
Mondal, B., Patra, O., Mishra, S., and Patra, P, (2020, March). A course recommendation system based on grades. In 2020 international conference on computer science, engineering and applications (ICCSEA) (pp. 1–5). IEEE.
Mostafa MM, 2018. Mining and mapping halal food consumers: A geo-located Twitter opinion polarity analysis. Journal of food products marketing. Oct 3;24(7):858–79. doi: 10.1080/10454446.2017.1418695.
Mounika A, Saraswathi S, 2021. Design of Book Recommendation System Using Sentiment Analysis. InEvolutionary Computing and Mobile Sustainable Networks (pp. 95–101). Springer, Singapore.
Ni P, Li Y, Chang V, 2020 Jul. Recommendation and Sentiment Analysis Based on Consumer Review and Rating. International Journal of Business Intelligence Research (IJBIR). 1;11(2):11–27. DOI: 10.4018/ IJBIR.2020070102
P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, 2017. Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135–146. https://doi.org/10.1162/tacl\_a\_00051.
Pasquier, C., da Costa Pereira, C., and Tettamanzi, A. G, (2020, August). Extending a fuzzy polarity propagation method for multi-domain sentiment analysis with word embedding and pos tagging. In ECAI 2020: 24th European Conference on Artificial Intelligence, August 29–September 8, Santiago de Compostela, Spain (Vol. 325, pp. 2140–2147). IOS Press.
Pennington, J., Socher, R., and Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532–1543).
Priyati, A., Laksito, A.D. and Sismoro, H., 2022, August. The Comparison Study of Matrix Factorization on Collaborative Filtering Recommender System. In 2022 5th International Conference on Information and Communications Technology (ICOIACT) (pp. 177–182). IEEE.
Qamar, A. M., and Alassaf, M, 2020. Improving Sentiment Analysis of Arabic Tweets by One-Way ANOVA. Journal of King Saud University-Computer and Information Sciences. https://doi.org/10.1016/j.jksuci.2020.10.023.
Shu, J., Shen, X., Liu, H., Yi, B., Zhang, Z, 2018. A content-based recommendation algorithm for learning resources. Multimedia Systems, 24(2), 163–173,. https://doi.org/10.1007/s00530-017-0539-8.
Sindhu, C., Sasmal, B., Gupta, R., and Prathipa, J, 2021. Subjectivity detection for sentiment analysis on Twitter data. In Artificial Intelligence Techniques for Advanced Computing Applications (pp. 467–476). Springer, Singapore.
Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A. Y., and Potts, C. (2013, October). Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing (pp. 1631–1642).
Susanto, Y., Cambria, E., Ng, B. C., and Hussain, A, 2021. Ten Years of Sentic Computing. Cognitive Computation, 1–19.
Tarus, J. K., Niu, Z., and Kalui, D, 2018. A hybrid recommender system for e-learning based on context awareness and sequential pattern mining. Soft Computing, 22(8), 2449–2461.
Tiwari, D., and Nagpal, B, (2021, March). Ensemble Sentiment Model: Bagging with Linear Discriminant Analysis (BLDA). In 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom) (pp. 474–480). IEEE.
Turnip, R., Nurjanah, D., and Kusumo, D. S., 2017, November. Hybrid recommender system for learning material using content-based filtering and collaborative filtering with good learners’ rating. In 2017 IEEE Conference on e-Learning, e-Management and e-Services (IC3e) (pp. 61–66). IEEE.
Vaishali, F., Archana, G., Monika, G., Vidya, G., and Sanap, M, 2016. E-learning recommendation system using fuzzy logic and ontology. Int. J. Adv. Res. Comput. Eng. Technol.(Ijarcet), 5(1), 165.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser £, Polosukhin I, 2017. Attention is all you need. Advances in neural information processing systems.
Wan, S., and Niu, Z, 2019. A hybrid e-learning recommendation approach based on learners’ influence propagation. IEEE Transactions on Knowledge and Data Engineering, 32(5), 827–840.
Xie, J., Chen, B., Gu, X., Liang, F., and Xu, X. (2019). Self-attention-based BiLSTM model for short text fine-grained sentiment classification. IEEE Access, 7, 180558–180570. doi: 10.1109/ACCESS.2019.2957510.
Xu, G., Meng, Y., Qiu, X., Yu, Z., and Wu, X. (2019). Sentiment analysis of comment texts based on BiLSTM. Ieee Access, 7, 51522-51532. doi: 10.1109/ACCESS.2019.2909919.
Yu HF, Hsieh CJ, Si S, Dhillon I, 2012 Dec 10. Scalable coordinate descent approaches to parallel matrix factorization for recommender systems. In2012 IEEE 12th international conference on data mining (pp. 765–774). IEEE.
Zapata, A., Menéndez, V. H., Prieto, M. E., and Romero, C, 2015. Evaluation and selection of group recommendation strategies for collaborative searching of learning objects. International Journal of Human-Computer Studies, 76, 22–39.
Zhang, Q., Lu, J., and Zhang, G, 2021. Recommender Systems in E-learning. Journal of Smart Environments and Green Computing, 1, 76–89. https://doi.org/10.20517/jsegc.2020.06.
Ziegler, C. N., McNee, S. M., Konstan, J. A., and Lausen, G. (2005, May). Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web (pp. 22–32). DOI: https://doi.org/10.1145/1060745.1060754.
Biographies

Rawaa Alatrash is a Ph.D. scholar in Computer Science and Engineering at the C.V. Raman Global University (CGU), India. She received her Master’s degree in Computer Science and Engineering from CGU, India. She has more than four years of industrial experience and has worked on different Java based projects. Her main research interests include deep learning, knowledge-based systems, and natural language processing, sentiment analysis, and recommendation systems. She has publications in reputed journals and international conferences indexed in SCI and Scopus. She is a web developer, and has been involved in several remarkable projects in web intelligence and sentiment analysis. She has reviewed papers in journals published by River Publishers and Science Publishing Group.

Rojalina Priyadarshini completed her Ph.D. in 2020 and currently is working as an Assistant Professor in the C.V. Raman Global University, Odisha. She obtained a Gold medal for her Master’s degree. She has more than a decade of teaching and research experience, and is an accredited AWS cloud educator and a certified Java faculty member. Dr. Priyadarshini has published more than 50 research papers in peer-reviewed international journals and conferences. Her areas of specialization are cloud and fog computing, machine learning and cyber security.
Journal of Web Engineering, Vol. 22_7, 983–1036.
doi: 10.13052/jwe1540-9589.2273
© 2024 River Publishers