Music Curriculum Research Using a Large Language Model, Cloud Computing and Data Mining Technologies
Yuting Shang
Nanchong Vocational and Technical College, Nanchong 637131, China
E-mail: 15298227288@163.com
Received 27 July 2023; Accepted 25 November 2023; Publication 08 April 2024
Abstract
This paper presents a method to enhance the scientific nature of the music curriculum model by integrating a large language model, cloud computing and data mining technology for the analysis of the music teaching curriculum model. To maintain the integrity of the mixing matrix while employing the frequency hopping frequency, the paper suggests dividing the mixing matrix into a series of sub-matrices along the vertical time axis. This approach transforms wideband music signal processing into a narrowband processing problem. Additionally, two hybrid matrix estimation algorithms are proposed in this paper using underdetermined conditions. Furthermore, utilizing the estimated mixing matrix and the detected time-frequency support domain, the paper employs the subspace projection algorithm for underdetermined blind separation of music signals in the time-frequency domain. This procedure, along with the integration of the estimated direction of arrival (DoA), enables the completion of frequency-hopping network station music signal sorting. Extensive simulation teaching demonstrates that the music curriculum model proposed in this paper, based on a large language model, cloud computing and data mining technologies, significantly enhances the quality of modern music teaching.
Keywords: Large language model, cloud computing, data mining, music, curriculum model.
1 Introduction
Teaching evaluations in music classrooms typically occur following students’ singing, answering, or other activities. However, many descriptive evaluations provided by teachers lack a clear purpose and merely serve as encouragement for students without referring back to the learning objectives. Consequently, this results in a loosely structured course content, poor interaction between the various elements, and an inability to conduct objective and accurate student evaluations [1].
“Expected goal determination” refers to adopting problem-solving as the foundation of teaching and imparting purpose to the instructional process. Music classes differ from other subjects in that they are non-semantic, with each individual experiencing and interpreting the same piece of music differently [2]. Hence, during course design, students’ prior knowledge and existing abilities must be taken into account, along with the intended understanding to be achieved in the course. By making precise judgments and selecting suitable teaching content based on these considerations, three-dimensional goals are identified, core content is defined, and teaching time is allocated rationally. This enables students to perceive the main objective of the course logically and purposefully, while focusing their attention on crucial elements that stimulate thinking and cultivate interest [3].
To determine whether students have attained the expected course objectives, standards and methods need to be developed for demonstration purposes. For instance, students should be able to establish rhythm after listening to music, proficiently read sheet music, and discern the underlying meaning behind the music. Music teachers should establish a series of criteria and methodologies based on the backward design approach, to evaluate the quality and effectiveness of the curriculum [4]. These evaluations serve the purpose of ensuring the desired learning outcomes. Therefore, the design of evaluation methods holds great significance as it influences teachers’ objective assessment of students’ mastery and provides effective feedback to aid in instructional adjustments and promote student learning.
Following the completion of the initial two steps, teachers can then design courses and learning methods within this framework. At this stage, music teachers should develop a clear plan encompassing the course content structure, teaching activities, choice of instructional methods, and preparation of teaching aids or musical instruments, aligning them with the learning outcomes and assessment criteria [5]. A comprehensive backward design necessitates the establishment of clear teaching goals that prompt students to examine their motivations for acquiring the knowledge and the desired outcomes. Students should also self-assess their learning progress and address any potential misunderstandings. Subsequently, teachers need to ignite students’ curiosity and stimulate their inclination to explore, facilitating both comprehension and practical application of knowledge. Key concepts or topics should be emphasized to foster experiential accumulation and enduring comprehension. Ultimately, self-reflection on teaching practices becomes crucial, encompassing the entire process and evaluating the outcomes of students’ understanding [6].
Music teachers should approach teaching design from a comprehensive perspective, making rational arrangements and ensuring a structured operation. Consequently, the components of teaching objectives, activities, evaluations, and situational factors become interconnected, forming an interactive instructional system through backward design. As a whole, these components complement and influence one another. Each segment of singing and dancing performances impacts the entire system, resulting in a more compact teaching structure, clearer instructional objectives, and targeted content [7]. When all elements of the teaching process revolve around the instructional goals, evaluation also becomes an integral part of the entire teaching process, facilitating effective goal implementation and optimizing the structure of the instructional system.
The philosophy of backward design advocates placing evaluation design at the forefront, prioritizing it over teaching activities. This approach entails establishing teaching goals first, followed by pre-determining evaluation methods and standards based on these goals, and finally designing the instruction. This organic relationship between expected learning outcomes, academic performance, teaching and learning behavior aims to enhance students’ comprehension and performance [8].
Music curriculum standards serve as the primary foundation for designing teaching goals. Music educators must thoroughly study the Music Curriculum Standards in relation to specific teaching scenarios and consider how to translate these standards into adaptable teaching objectives that cater to diverse student populations. In the process of reverse design, prioritizing evaluation enhances the comprehensiveness and relevance of teaching objectives [9]. Consequently, evaluations in music courses primarily indicate the actions students should undertake upon accomplishing predetermined teaching objectives, as well as the desired level of proficiency. Meanwhile, teachers can employ appropriate teaching methods to aid students in fulfilling the evaluation criteria, thus fostering sustainability and effectiveness in evaluations. This approach not only facilitates the attainment of teaching objectives but also contributes to the realization of curriculum standards [10].
Reverse design necessitates the creation of practical tasks that allow students to apply their knowledge in real-life contexts, granting them opportunities for exploration and discovery. Generally, subjects that demand deep and enduring comprehension tend to be abstract and non-intuitive, requiring exploration to uncover their underlying meanings [11]. Traditional teaching often revolves around the passive transfer of knowledge from textbooks, similar to a continuous stream of singing in a music class, where students merely accept information without actively engaging or cultivating the desire to explore, resulting in short-lived understanding. Consequently, the teaching activities associated with reverse design provide avenues for students to explore and discover, enabling them to develop independent learning capabilities and a genuine interest in uncovering the deeper significance of music [12].
The fragmentation of students’ individual knowledge acquisition and spiritual development has resulted in the disintegration of students as a unified whole. This disintegration, brought about by modern education, has given rise to numerous issues in the field of education. It is imperative for education to address and contemplate this problem from the perspective of the “whole person.” The integrity of individual existence does not arise from a mere accumulation of disparate knowledge across various disciplines, nor is it a result of the reduction of rational thinking through analysis [13]. Rather, it necessitates individuals to enrich the meaning and quality of their lives through diverse and vibrant personal experiences, as well as individualized creative expressions. Additionally, it requires dialogue and exchange. The reform of the school music curriculum has departed from its previous emphasis on imparting music knowledge and skills, and now considers the integration of students’ music learning and spiritual development as one of its overarching objectives [14].
The learning of music knowledge and skills entails more than acquiring theoretical and notational knowledge, as well as vocal abilities. It also encompasses an understanding of music and its related culture, such as comprehending the social function of music based on one’s own life experiences and acquired knowledge. This inclusive approach allows for the inclusion of students’ individual musical experiences in the classroom [15]. Only when the learning of music knowledge is integrated with students’ personal musical experiences can the acquired knowledge establish a meaningful connection with students and contribute to their personal growth. When music knowledge remains external to students, merely transmitted to them without any interaction, it fails to permeate their lives and does not foster their spiritual growth. In such a scenario, music knowledge becomes nothing more than an academic exercise for students [16].
The aspect of “process and method” within the course objectives also holds significance for students’ spiritual development. Music learning is not solely about the accumulation of music knowledge and skills; it is about shaping students’ cognition of musical perspectives, values, and cultural outlooks through their engagement with music. Although this process may entail confusion, setbacks, failures, and a considerable amount of time, it plays a crucial role in students’ learning, growth, development, and creativity. It is through this process that knowledge becomes integrated into individuals’ own experiences, continually transforming into spiritual strength and wisdom for life.
Furthermore, the development of the “whole person” is demonstrated through the harmonious relationship among individuals, nature, and society [17]. This curriculum reform, utilizing a holistic approach, requires a careful examination and construction of the relationships between individuals and themselves, individuals and nature, and individuals and society. Concerning the relationship between individuals and themselves, the curriculum emphasizes the use of music studies to cultivate a positive and optimistic outlook on life, as well as a yearning and pursuit of a better future. Through an emotional connection and understanding of the mood, style, ideological tendencies, and humanistic meanings within musical works, students develop the ability to appreciate and evaluate music. They cultivate a healthy and elevated aesthetic sensibility, allowing themselves to be nurtured by profound sentiments present in the world of music and the art of truth, goodness, and beauty [18].
This study combines large language model, cloud computing and data mining technologies to analyze the music teaching curriculum model, addressing the limitations of traditional music instruction and aiming to enhance the quality of modern music education.
2 Proposed Approach
2.1 Large Language Model
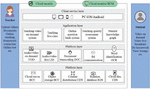
A large language model is a deep learning system that is advanced and built for various natural language processing (NLP) tasks. These models use transformer architecture and are trained on large datasets, which adds to their large size. As a result, they can detect, translate, predict, and synthesize text and other sorts of content.
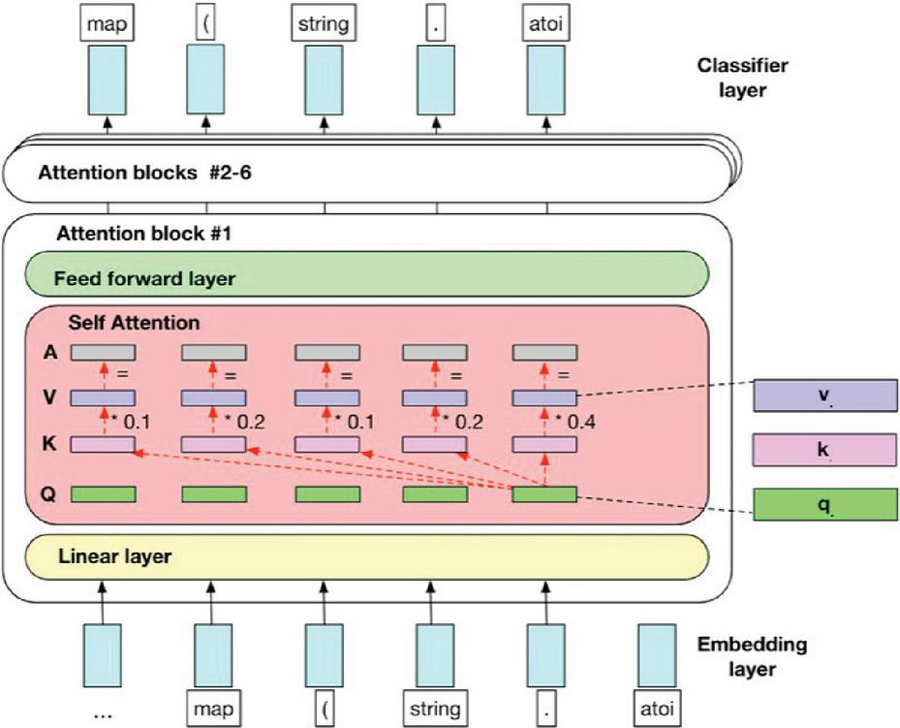
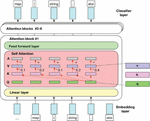
Figure 1 Large language model architecture.
Additionally, these models, often known as neural networks (NNs), are computational systems that draw inspiration from the human brain. These neural networks, like neurons, are made up of a layered network of nodes. Large language models can be trained to perform a variety of tasks, including recognizing protein structures and creating software code, in addition to imparting human languages to artificial intelligence (AI) applications. These models are pre-trained and then fine-tuned to tackle text categorization, question answering, document summarizing, and text production difficulties. Its problem-solving abilities are used in industries such as healthcare, banking, and entertainment, where they support numerous NLP applications such as translation, chatbots, and AI assistants.
The number of parameters in large language models is proportional to the model’s complexity. These models also include numerous neural network layers, such as recurrent layers, feedforward layers, embedding layers, and attention layers. These layers collaborate to process input text and produce output content. The embedding layer extracts the semantic and syntactic meaning of the input text, generating embeddings that allow the model to grasp context. The feedforward layer is made up of several completely connected layers that alter the embedded inputs. These layers make it easier to extract higher-level abstractions, allowing the model to understand the user’s purpose behind the text input. The recurrent layer examines the words in the incoming text sequentially, generating connections between them within a phrase.
Large language models are pre-trained during the training phase using vast textual datasets collected from platforms such as Wikipedia, GitHub, and others. These datasets contain a massive number of words, and the quality of these datasets determines the language model’s performance. At this point, the big language model does unsupervised learning, which involves processing the provided datasets without explicit instructions. Throughout this process, the artificial intelligence algorithm in the language model grasps the meaning of words and comprehends the relationships that exist between them. It also learns to differentiate between words depending on contextual clues. For example, it learns to recognize whether “right” means “correct” or the inverse of “left.” But fine-tuning is required to enable the huge language.
2.2 Music Signal Propagation Model
In the cloud music teaching platform, for the frequency hopping radio stations with asynchronous networking, the parameter association and network station sorting are carried out according to the difference between the characteristic parameters of each frequency hopping music signal, such as arrival time, hopping period, and hopping time. Since the above characteristic differences do not exist between the synchronous networking frequency hopping network stations, the sorting is difficult.
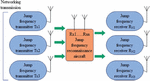
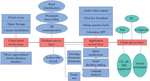
Blind source separation is a method to separate each source music signal from the mixture of multiple source music signals. At present, many scholars have applied blind source separation to the sorting and separation of frequency hopping music signals. The network station sorting based on blind source separation does not require, or requires little, prior information about the source music signal, and the array error has less influence on the algorithm. Moreover, compared with the traditional sorting method based on the characteristic difference of the music signal, it has great advantages. Therefore, the research on the sorting algorithm of an underdetermined frequency hopping network has more practical significance. In each subsection, the SCA algorithm in the underdetermined blind source separation theory is used to realize the frequency hopping network station sorting. Two hybrid matrix estimation algorithms and an underdetermined recovery algorithm for sparse music signals based on subspace projection are mainly studied. Furthermore, the frequency hopping network station music signal sorting is realized, and the frequency hopping reconnaissance structure is shown in Figure 2.
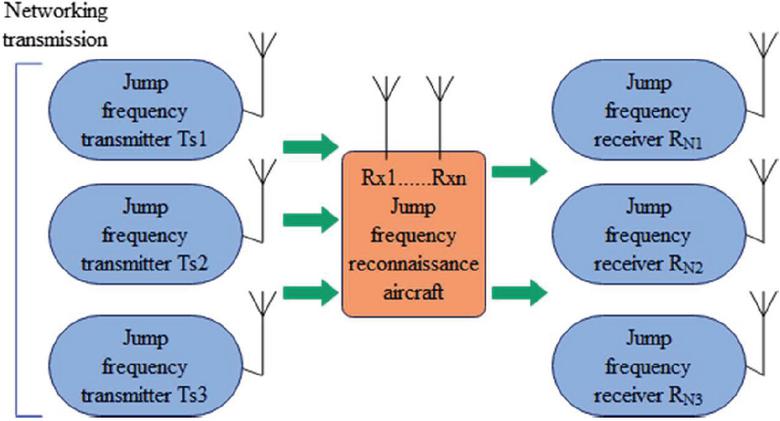
Figure 2 Schematic diagram of frequency hopping detection scene.
We assume that there are frequency hopping music signals , located in the far field (which can be regarded as parallel incidence) and radiate to array sensors from different directions respectively.
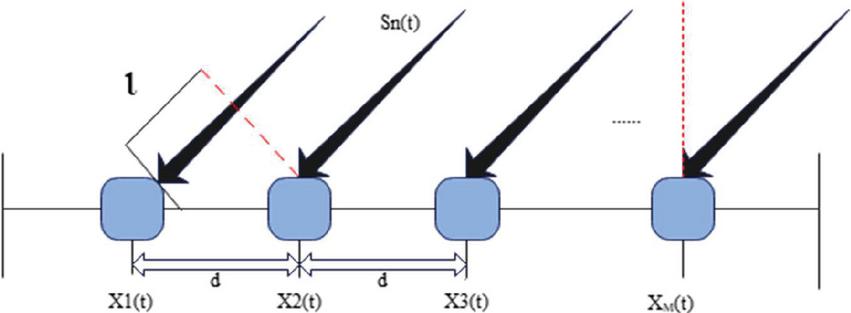
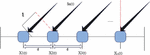
Figure 3 Schematic diagram of M-element array distribution.
Then, the steering vector of the array is expressed as:
| (1) |
In the actual environment, the source is usually located in the far field, then the analytical expression of the th source music signal is:
| (2) |
Due to the different positions of the array elements, the time for the same source music signal to arrive at each array element is different. It can be found from Figure 3 that the receiving delay of the mth array element to the source music signal is:
| (3) |
The observed music signal of array element to is:
| (4) |
Within the receiving delay of the array element, the modulation information of the source music signal and the carrier frequency of the music signal remain unchanged, and we can obtain:
| (5) |
Then, formula (2.2) can be simplified as:
| (6) |
The matrix form represents the music signal observed by array elements at time as:
| (7) |
That is:
| (8) |
However, for the frequency-hopping communication music signal studied in this paper, the frequency hopping of the carrier frequency of the frequency-hopping music signal occurs every certain time. Only when the frequency range of the music signal is relatively narrow and satisfies the relative bandwidth ( represents the frequency hopping bandwidth, and represents the center frequency of the frequency hopping music signal), it can be considered that the mixing matrix basically remains unchanged. The blind source separation of multi-frequency hopping music signals is to separate the intertwined frequency hopping music signals on the basis of checking the existence of frequency hopping music signals in the mixed music signal. The actual frequency range of frequency hopping communication is generally very large, so when using the SCA blind separation algorithm, it is necessary to pay attention to the time-varying of the mixing matrix.
2.3 Joint Estimation of Source Number and Mixture Matrix Based on a Clustering Algorithm
The frequency-hopping music signal is a typical broadband non-stationary music signal. Different from the blind separation and DOA estimation of the narrowband array music signal, the manifold matrix in the wideband array model changes with the frequency, which cannot be equivalent to the complex instantaneous mixture model of blind separation. The algorithm proposed in this section cuts the time-frequency matrix along the vertical time axis to obtain a series of sub-time-frequency matrices according to the hopping moment of the frequency music signal. They keep the hopping frequency constant in each sub-matrix, which can be treated as a narrowband music signal.
In order to complete the estimation of the number and mixture of frequency-hopping music signals, the sparse characteristics of frequency-hopping music signals in the time-frequency domain are used. Usually, formula (9) is used to calculate the normalized kurtosis of music signal, and kurl is the normalized kurtosis function. The larger the function value, the better the sparsity of the music signal.
| (9) |
The frequency-hopping music signal does not have the sparse characteristic in the time domain, but it is sparse in the time-frequency domain. Therefore, the observed music signal is transformed into the time-frequency sparse domain through the STFT time-frequency transform. When the source music signal is a sparse music signal, generally only one source music signal has a larger value at the same time, and the other source music signals have a relatively small value or zero, then the music signal can be considered to be sufficiently sparse at this time. We assume that only acts alone at time , that is:
| (10) |
When the influence of noise is ignored, the real and imaginary parts of the observed music signal are gathered on two straight lines passing through the origin in the -dimensional music signal space, and the direction of the straight lines corresponds to the column vector .
| (11) |
The music signal in the time-frequency domain is sparse, and the spatial sampling data of the mixed music signal in the time-frequency domain are distributed near several straight lines. Therefore, in this paper, the mixture matrix estimation and DOA estimation are completed by estimating the clustering line direction of the observed music signal. In this paper, STFT transform is performed on the mixed music signal observed by each array element, and the music signal is transformed into the time-frequency sparse domain. Moreover, this paper takes the real part and imaginary part of each time-frequency value of the time-frequency matrix obtained by the first three array elements. According to the principle of the same position, the three real parts are formed into a three-dimensional coordinate , where , , and the real part coordinate data set is obtained, and the imaginary part data set is constructed according to the same method.
| (12) |
The complex time-frequency representation of the music signal is used. Specifically, the real part (Re) and imaginary part (Im) of each time-frequency value are considered separately.
First, the coordinate dataset is projected onto the unit hypersphere by formula (13).
| (13) |
The data set to be clustered is , and the radius of the data neighborhood is defined as:
| (14) | |
| (15) |
Firstly, the projection to the unit hypersphere dataset is screened, and the low-energy points with less information are removed. That is, for any time-frequency point , if is satisfied, it is retained, otherwise, it is deleted. Then, for the remaining points, the neighborhood radius of each data point in the dataset is calculated according to formula (14), and then r is arranged in descending order. By setting the threshold of , the data points whose neighborhood radius is greater than are all deleted, and the data points smaller than are retained. Finally, the density value of each data is calculated according to formula (15), and the low-density points in the data set are removed according to the density value, and the high-density data set is obtained.
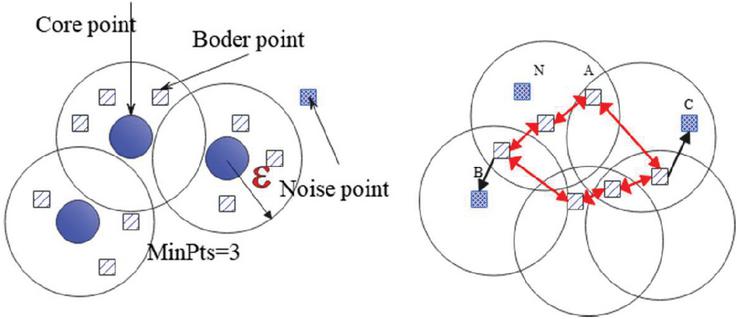
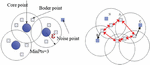
Figure 4 Data point classification.
Compared with the traditional clustering algorithm K-means, FCM, etc., the density-based spatial clustering (DBSCAN) of application with noise algorithm does not need to set the number of classifications in advance, and can automatically determine the number of classifications according to the data set. However, most of the traditional clustering algorithms cluster the circularly distributed data into one category, and the clustering effect is particularly poor for the linearly distributed data. Since the real and imaginary data sets of time-frequency values in this paper are mainly linearly distributed, the DBSCAN algorithm is selected. First, some basic concepts in the algorithm are defined as follows. The schematic diagram of the classification is shown in Figure 4.
(1) neighborhood: For , its neighborhood is the sample set in the sample set whose distance from is not greater than , so the neighborhood is a set, and this set is recorded as .
(2) Core object: For sample , the number of data points in is counted. If , then is the core point;
(3) Direct density reachable: If is satisfied and is the core object, then point is said to be directly density reachable from point ;
(4) Density reachable: In dataset , there are data columns and . If it is assumed that to is directly density reachable, then data points to are density reachable.
Figure 4 (left) shows the distribution of core points, boundary points, and noise points when MinPts 3. In the right figure, MinPts 4, point A and other red points are core points. Because their neighborhoods (red circles in the figure) contain at least four points (including themselves), and they are mutually reachable, they form a cluster. Point B and point C are not core points, but they can be reached by A through other core points, so A, B, and C belong to the same class. Point N is neither the core point nor reachable by other points, so it is recorded as a noise point.
At the detected frequency hopping moment, the time-frequency matrix of the observed music signal transformed by STFT is divided into a series of sub-matrices according to the hopping moment. Each sub-matrix is constructed with a sample data set , and the neighborhood parameter is set, and then the number of frequency-hopping music signals and the estimation of the mixing matrix are completed according to the following steps.
Step 1: For the sample data set, the algorithm first sets the neighborhood radius and the minimum number of neighborhood data points MinPts;
Step 2: First, the algorithm randomly selects a point from the data set . After that, the algorithm judges whether is a core object according to definition 2. If it is, then all directly density-reachable points in the neighborhood of the search are classified into one class. On the contrary, is not a core object, it is temporarily marked as an interference point, and the next data point is searched until all data are judged.
Step 3: For all the directly density-reachable points in the neighborhood of all core objects , the algorithm finds the data set connected with the maximum density, and merges some density-reachable data points.
Step 4: Until all the neighborhoods of all core objects are traversed, the algorithm obtains the number of clusters and the center of each cluster. The number of clusters is the estimated value of the number of frequency hopping network stations, and the cluster center is the estimated value of the real part/imaginary part of the mixture matrix.
According to formula (16), the mixing matrix of the sub-time-frequency matrix can be estimated.
| (16) |
If it is assumed that different radio stations have different azimuths, the incoming wave direction of the th source music signal can be obtained according to formula (2.2).
| (17) |
Among them, is the distance between the array elements. According to formula (17), the carrier frequency and the mixing matrix elements are needed to determine the value of DOA together, and how to associate the music signal carrier frequency value with the estimated mixing matrix elements one-to-one. It can be seen from formula (11) that if the point has only alone, then:
| (18) |
According to formula (18), the estimated value of the mixture matrix can be obtained as:
| (19) |
Comparing the estimated in this paper with the elements in formula (19), according to the degree of proximity, the corresponding is determined and is estimated.
3 Music Curriculum Model Based on Cloud Computing and Data Mining Technology
Education Cloud is an in-depth application of cloud computing in the field of education. Through the service mode of providing on-demand services and dynamic deployment, it provides the required application services such as information-based teaching management for education providers and recipients of educational institutions. This paper combines cloud computing and mining technology to build a music curriculum teaching model, as shown in Figure 5.
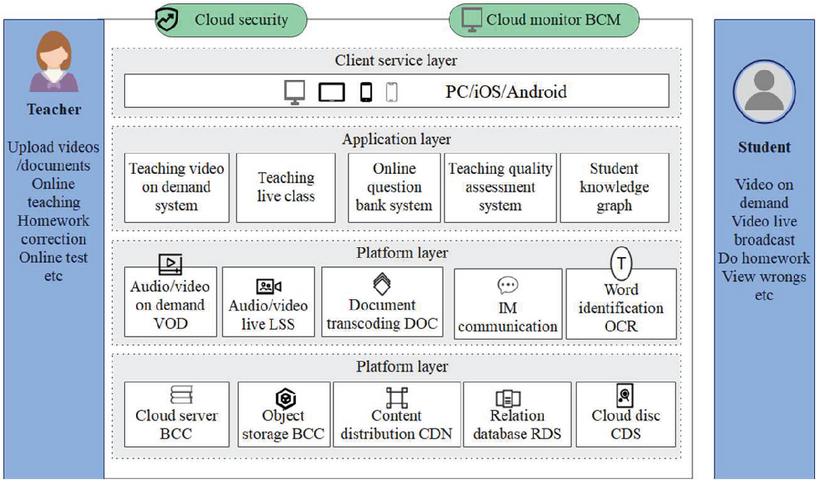
Figure 5 Scheme diagram of music teaching mode on cloud platform.
Based on the support of the second part of the algorithm, the intelligent education cloud platform framework is constructed, as shown in Figure 6.
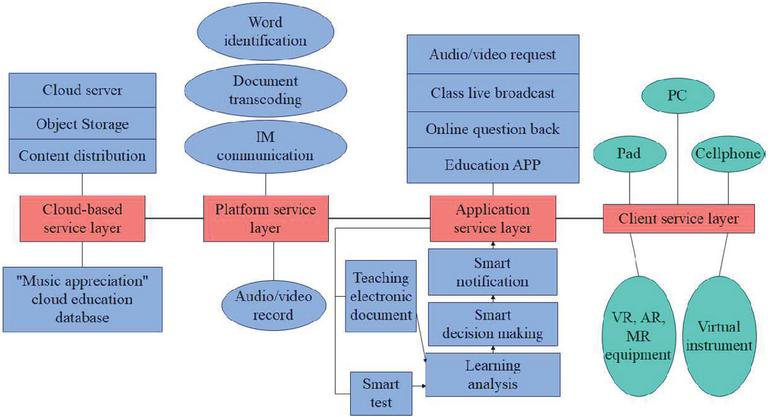
Figure 6 The understanding diagram of the smart education cloud platform architecture.
This paper proposes that the intelligent push module is based on the principle of on-demand push. It mainly pushes five aspects of content. The first is to push resources on demand, that is, push resources according to users’ learning preferences and learning needs. The second is to push activities on demand, that is, push learning activities according to the user’s existing foundation, learning preferences and learning purposes. The third is an on-demand push service, that is, a learning service is pushed according to the user’s current learning status and needs. The fourth is on-demand push tools, that is, according to the user’s learning process records, adaptively push various cognitive tools, The fifth is to push interpersonal resources on demand, that is, push interpersonal resources such as schoolmates, teachers, and subject experts according to the user’s interests, preferences, and learning content. The above push can not only help teachers carry out precise teaching, but also help students master and consolidate the knowledge points that are not mastered in classroom teaching. The smart education cloud platform is mainly composed of three functional areas, as shown in Figure 7.
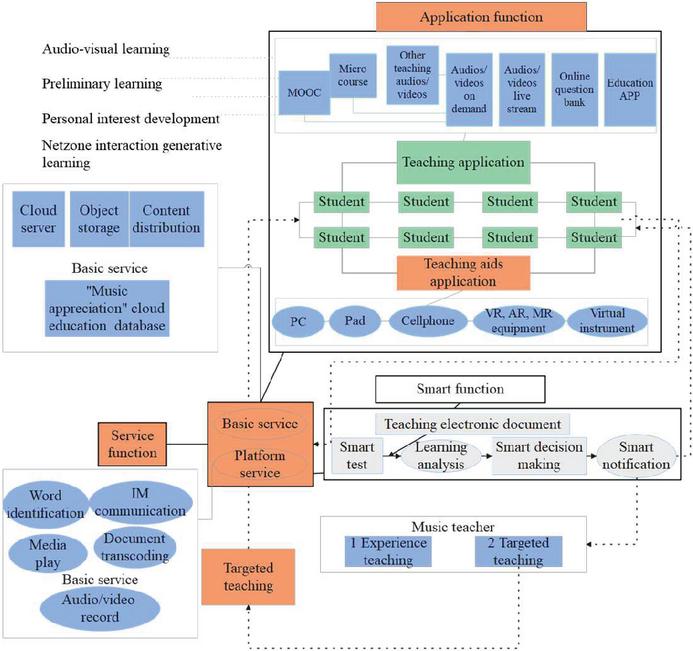
Figure 7 The understanding diagram of the teaching application and implementation of the smart education cloud platform.
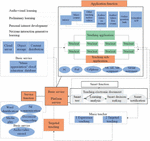
The distance music education platform based on the public cloud is based on service-oriented architecture (SOA), and the main features of the platform architecture are proposed to provide theoretical support for platform design and implementation, as shown in Figure 8.
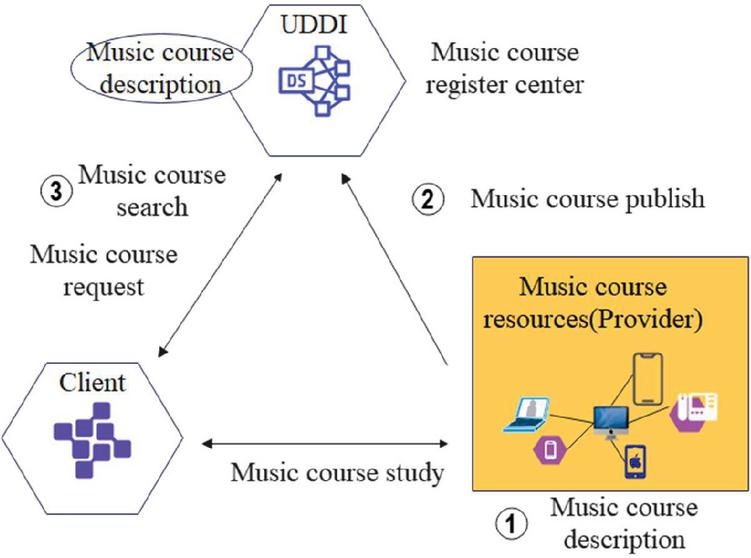
Figure 8 The structure of the distance music education platform.
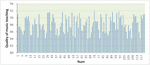
The effect of the music course model under the cloud computing and data mining technology proposed in this paper is verified, and the quality improvement effect of modern music course teaching is verified by statistics, and the results shown in Figure 9 are obtained.
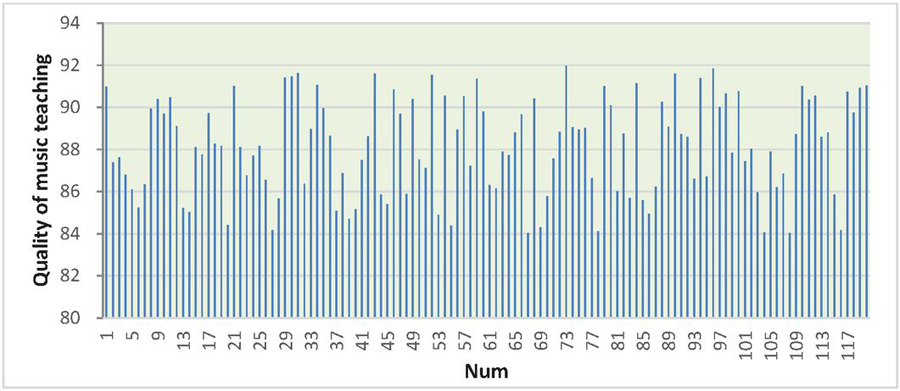
Figure 9 Verification of the effect of music course mode based on cloud computing and data mining technology.
Figure 9 represents the verification of the effect of the music course model based on cloud computing and data mining technology, where the x-axis represents different data points (different scenarios and conditions), and the y-axis represents the quality of music teaching.
The bars in the graph indicate the quality of music teaching for each corresponding data point on the -axis. The height of each bar represents the measured quality, with taller bars indicating higher quality and shorter bars indicating lower quality.
4 Scenario: Improving Music Curriculum with Extensive Simulation Teaching
Here is a scenario that demonstrates how extensive simulation teaching can be used to evaluate the effectiveness of the music curriculum model proposed in this research paper, leveraging a large language model (LLM).
A group of music educators and researchers has developed a novel music curriculum model that leverages the capabilities of an LLM, such as GPT-3, to enhance the teaching and learning of music. This model integrates AI-driven content generation, personalized learning paths, and real-time feedback. The researchers want to assess its impact on music education quality. The researchers begin by designing a music curriculum that incorporates the LLM-based model. They create lessons, assignments, and learning objectives, making use of the LLM’s text generation abilities to provide rich and dynamic learning materials. To evaluate the curriculum model’s effectiveness, the researchers set up a simulated learning environment. This environment includes a virtual classroom with a diverse group of students. Students in the virtual classroom engage with the LLM-powered curriculum. As they progress through the lessons and assignments, the system collects various data points:
1. Student interaction with course materials.
2. Responses to AI-generated content.
3. Progress in achieving learning objectives.
4. Time spent on different topics.
5. Frequency of interaction with the LLM-powered virtual instructor.
The LLM continuously analyzes student data to personalize the learning experience. It adapts the curriculum based on each student’s strengths, weaknesses, and learning pace. For example, if a student struggles with music theory, the LLM generates tailored explanations and exercises. The simulated learning environment includes assessments and quizzes, with questions generated by the LLM. The system provides instant feedback to students, pointing out areas for improvement and suggesting further study materials or practice. Researchers closely monitor student progress through the simulation. They examine how effectively the LLM’s content generation and personalization features support student learning and mastery of musical concepts. After a predefined period of extensive simulation teaching, the researchers evaluate the students’ performance. They analyze factors such as:
1. Learning outcomes.
2. Retention of musical knowledge.
3. Engagement and motivation levels.
4. Satisfaction with the LLM-powered curriculum.
Utilizing the data collected throughout the simulation, the researchers perform an in-depth data analysis. They assess whether the LLM-powered music curriculum model has led to significant improvements in learning outcomes, engagement, and overall quality of music education. Based on the extensive simulation teaching, the researchers discover that the music curriculum model, enriched by the capabilities of the LLM, has indeed shown a significant improvement in music education quality. Learning outcomes are more positive, engagement is higher, and students report greater satisfaction with the personalized learning experience. However, the researchers acknowledge that further real-world validation and long-term studies are needed to fully understand the model’s impact on music education. Future research could also explore how this model can be adapted for various musical genres, levels of expertise, and cultural contexts.
5 Conclusion
In the traditional approach to music curriculum design, educators often prioritize textbooks, their own expertise, and established teaching methods. This approach has led to a disconnect between teaching objectives and the actual content and activities in music education. Teaching goals are often treated as a mere formality, included in lesson plans without a profound impact on instructional design. Consequently, the focus tends to shift towards diversifying teaching content and incorporating flashy classroom activities. This disconnect has significant implications for students who find themselves navigating a curriculum without a clear sense of purpose or direction. Consequently, they struggle to comprehend and master the intended learning outcomes.
The primary objective of this study is to address the shortcomings of traditional music curriculum design and enhance the quality of modern music teaching through the integration of cloud computing and data mining technology. This study pioneers an innovative approach by emphasizing the alignment of curriculum content and teaching activities with well-defined teaching objectives and standards. By bridging this gap, educators can ensure that every element of their curriculum serves a purpose and contributes to the students’ understanding and mastery of the learning content.
Moreover, by incorporating cloud computing and data mining technology, this research introduces a data-driven dimension to music curriculum design. This allows for the systematic analysis of student progress, learning patterns, and areas of improvement. Educators can make informed decisions and tailor their teaching methods to address specific student needs, ultimately enhancing the overall quality of music education.
The integration of cloud computing and data mining technology enables the creation of personalized learning experiences for students. This individualized approach empowers students to set clear learning goals and track their progress, resulting in improved learning outcomes and a deeper appreciation of music.
Furthermore, through rigorous simulation teaching, this study provides concrete evidence of the effectiveness of the proposed music curriculum model. The empirical results demonstrate that the use of cloud computing and data mining technology can lead to a tangible improvement in the quality of modern music teaching.
While this study represents a significant step towards modernizing music education, several avenues for future research are worth exploring. These include investigating the long-term effects of the proposed curriculum model on students’ musical proficiency and their continued engagement with music. Additionally, exploring the potential of cloud computing and data mining in enhancing interdisciplinary approaches to music education, such as music technology, composition, and ethnomusicology. Also, examining how technology-enhanced music education can be made more inclusive and accessible to a diverse range of students, including those with disabilities. Lastly, considering the adaptation of this approach to music education in different cultural and geographical contexts, taking into account regional musical traditions and preferences.
Data Availability Statement
The dataset used to support this study are available from the corresponding author upon request.
Conflict of interest
The author declares no competing interests.
Funding Statement
This research received no specific grant from any funding agency.
References
[1] A. Amendola, G. Gabbriellini, P. Dell’Aversana, and A. J. Marini, “Seismic facies analysis through musical attributes,” Geophys. Prospect., vol. 65, no. S1, pp. 49–58, 2017.
[2] J. A. Anaya Amarillas, “Marketing musical: música, industria y promoción en la era digital,” INTERdisciplina, vol. 9, no. 25, pp. 333–335.
[3] E. Cano, D. FitzGerald, A. Liutkus, M. D. Plumbley, and F. R. Stöter, “Musical source separation: An introduction,” IEEE Signal Process. Mag., vol. 36, no. 1, pp. 31–40, 2018.
[4] E. Costa-Giomi and L. Benetti, “Through a baby’s ears: Musical interactions in a family community,” Int. J. Community Music, vol. 10, no. 3, pp. 289–303, 2017.
[5] A. Dickens, C. Greenhalgh, and B. Koleva, “Facilitating Accessibility in Performance: Participatory Design for Digital Musical Instruments,” J. Audio Eng. Soc., vol. 66, no. 4, pp. 211–219, 2018.
[6] L. L. Gonçalves and F. L. Schiavoni, “Creating Digital Musical Instruments with libmosaic-sound and Mosaicode,” Rev. Informática Teórica E Apl., vol. 27, no. 4, pp. 95–107, 2020.
[7] I. B. Gorbunova, “Music computer technologies in the perspective of digital humanities, arts, and researches,” Opcion, vol. 35, no. SpecialEdition24, pp. 360–375, 2019.
[8] I. B. Gorbunova and N. N. Petrova, “Music computer technologies, supply chain strategy and transformation processes in socio-cultural paradigm of performing art: Using digital button accordion,” Int. J. Supply Chain Manag., vol. 8, no. 6, pp. 436–445, 2019.
[9] R. Khulusi, J. Kusnick, C. Meinecke, C. Gillmann, J. Focht, and S. Jänicke, “A survey on visualizations for musical data,” Comput. Graph. Forum, vol. 39, no. 6, pp. 82–110, Sep. 2020.
[10] T. Magnusson, “The migration of musical instruments: On the socio-technological conditions of musical evolution,” J. New Music Res., vol. 50, no. 2, pp. 175–183, 2021.
[11] C. Michalakos, “Designing musical games for electroacoustic improvisation,” Organised Sound, vol. 26, no. 1, pp. 78–88, 2021.
[12] G. Scavone and J. O. Smith, “A landmark article on nonlinear time-domain modeling in musical acoustics,” J. Acoust. Soc. Am., vol. 150, no. 2, pp. 3–4, 2021.
[13] K. Stensæth, “Music therapy and interactive musical media in the future: Reflections on the subject-object interaction,” Nord. J. Music Ther., vol. 27, no. 4, pp. 312–327, 2018.
[14] A. C. Tabuena, “Chord-Interval, Direct-Familiarization, Musical Instrument Digital Interface, Circle of Fifths, and Functions as Basic Piano Accompaniment Transposition Techniques,” Int. J. Res. Publ., vol. 66, no. 1, pp. 1–11, 2020.
[15] L. Turchet and M. Barthet, “An ubiquitous smart guitar system for collaborative musical practice,” J. New Music Res., vol. 48, no. 4, pp. 352–365, 2019.
[16] L. Turchet, T. West, and M. M. Wanderley, “Touching the audience: musical haptic wearables for augmented and participatory live music performances,” Pers. Ubiquitous Comput., vol. 25, no. 4, pp. 749–769, 2021.
[17] O. Y. Vereshchahina-Biliavska, O. V. Cherkashyna, Y. O. Moskvichova, O. M. Yakymchuk, and O. V. Lys, “Anthropological view on the history of musical art,” Linguist. Cult. Rev., vol. 5, no. S2, pp. 108–120, 2021.
[18] L. C. Way, “Populism in musical mash ups: recontextualising Brexit,” Soc. Semiot., vol. 31, no. 3, pp. 489–506, 2021.
Biography

Yuting Shang has successfully completed the requirements for and been awarded a Master’s degree. Currently, she is employed in Nanchong Vocational and Technical College. Her research interests lie in the application of computer science within the domain of music education..
Journal of Web Engineering, Vol. 23_2, 251–274.
doi: 10.13052/jwe1540-9589.2323
© 2024 River Publishers