A Study on Performance Improvement of Prompt Engineering for Generative AI with a Large Language Model
Daeseung Park1, Gi-taek An2, Chayapol Kamyod3 and Cheong Ghil Kim1,*
1Department of Computer Science, Namseoul University, Cheonan, Republic of Korea
2Korea Food Research Institute, Wanju-gun 55365, Republic of Korea
3Computer and Communication Engineering for Capacity Building Research Center, School of Information Technology, Mae Fah Luang University, Chiang Rai 57100, Thailand
E-mail: dspark@daeseungpark.com; gt@kfri.re.kr; chayapol.kam@mfu.ac.th; cgkim@nsu.ac.kr
*Corresponding Author
Received 04 December 2023; Accepted 02 February 2024; Publication 22 February 2024
Abstract
In the realm of Generative AI, where various models are introduced, prompt engineering emerges as a significant technique within natural language processing-based Generative AI. Its primary function lies in effectively enhancing the results of sentence generation by large language models (LLMs). Notably, prompt engineering has gained attention as a method capable of improving LLM performance by modifying the structure of input prompts alone. In this study, we apply prompt engineering to Korean-based LLMs, presenting an efficient approach for generating specific conversational responses with less data. We achieve this through the utilization of the query transformation module (QTM). Our proposed QTM transforms input prompt sentences into three distinct query methods, breaking them down into objectives and key points, making them more comprehensible for LLMs. For performance validation, we employ Korean versions of LLMs, specifically SKT GPT-2 and Kakaobrain KoGPT-3. We compare four different query methods, including the original unmodified query, using Google SSA to assess the naturalness and specificity of generated sentences. The results demonstrate an average improvement of 11.46% when compared to the unmodified query, underscoring the efficacy of the proposed QTM in achieving enhanced performance.
Keywords: AI, large language model, generative AI, few-shot learning, prompt engineering, AI Chatbot.
1 Introduction
Recent advancements in AI and NLP (natural language processing) have garnered attention, leading to active research in the field of LLM (large language models) related to chatbot technology. As chatbots and AI technologies continue to evolve, their performance has been steadily improving. With the evolution of them, which are trained on massive datasets using LLMs, they have reached a level where they can provide responses at a similar level to that of humans [1, 2].
Representatively, large-scale language models of the GPT (generative pre-trained transformer) series [3] have been introduced and are showing excellent performance in various NLP tasks. This is considered a key basic technology for Generative AI [4], which learns content patterns and creates new content with inference results. Many global tech giants, including OpenAI, Google, Deepmind, Meta, and other research institutes are conducting several large-scale projects based on different strategies and approaches [5].
Typically, models such as the GPT series are trained on large general corpus datasets such as web pages, books, papers, and articles. It can then be applied to a variety of natural language processing tasks using adaptive methods such as fine-tuning [6]. As a result, LLM has more than millions of parameters, allowing the model to learn a variety of language patterns and structures. This technological evolution of the LLM is having a significant impact on the AI community, revolutionizing the way AI algorithms are developed and used.
As for the LLM’s model capacity, it is improving by expanding the model size or data size in the pre-trained language model (PLM). As a recent example, much larger PLMs, GPT-3 with 175B parameters and PaLM with 540B parameters, were trained to explore performance limits. Although the expansion is mainly done at different model sizes using similar processes of architecture and pre-training operations, these large PLMs show superior performance compared to small PLMs represented by 330M parameter BERT and 1.5B parameter GPT-2. Generally, large-scale language models (LLMs) refer to language models containing hundreds of billions (or more) of parameters, such as GPT-3, PaLM, Galactica, and LLaMA which have been trained on large-scale text data [7].
ChatGPT, taking a closer look, is a model based on GPT-3.5, and is an advanced model through changes in the model and learning method from the existing GPT-1 to GPT-3. The main change from GPT-1 to GPT-3 is the change in model size, which improves performance by learning more information from various datasets. GPT-3 uses few-shot learning, a technique to effectively learn a model even in situations where very little data is given, and prompt learning, a method of utilizing domain knowledge for model learning through input in the form of human-readable text. Prompt based learning performs various functions such as random writing, translation, web coding, and conversation. Furthermore, it is fine-tuned based on GPT-3.5 and allows human intervention during the learning process. By applying RLHF (reinforcement learning from human feedback), a reinforcement learning algorithm, to GPT-3.5, bias and harmfulness are reduced. Currently, in RLHF, humans rank the model’s responses and reflect feedback through a reward function, so that human preferences are reflected in the model. The learning method consists of three stages, allowing additional learning of GPT-3.5 through prompt-based supervised learning and the RLHF algorithm. They consist of demo answer collection and a policy compliance verification stage, comparison data collection and a reward model training stage, and policy optimization stage with a reinforcement learning algorithm [7].
This paper applies prompt engineering to Korean-based LLMs, presenting an efficient approach for generating specific conversational responses with less data. For this purpose, we proposed a technique of utilizing the query transformation module (QTM). The proposed QTM transforms input prompt sentences into three distinct query methods, breaking them down into objectives and key points, making them more comprehensible for LLMs. This paper is composed as follows: Sections 2 overviews the GPT series; Section 3 introduces the proposed query transformation module; Section 4 includes the simulation environment, method, and results; finally, a conclusion and future works section follows.
2 Backgrounds
In general, LLM can be associated with the GPT series models. GPT stands for ‘generative pre-trained transformer’, representing AI models that are pre-trained on extensive data through machine learning to generate sentences. In particular, in the recent revolution of Generative AI, ChatGPT has gained prominence for its ability to engage in human-like conversations. ChatGPT can formulate responses to questions in a manner resembling human sentence construction [8–11].
2.1 GPT-1
Before the era of GPT, language models typically relied on labelled data and supervised learning. However, obtaining a large amount of labelled data is challenging due to the absolute necessity of human involvement in the labelling process. Naturally, unlabelled data is more easily accessible in significant quantities. Existing language models lacked effective methods to leverage unlabelled data. Therefore, GPT-1 focused on developing an efficient generative pre-training model using unlabelled data [12].
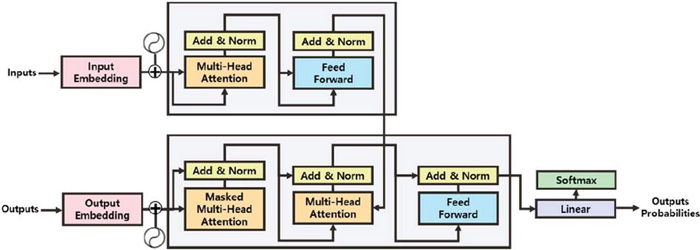
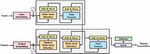
Figure 1 Transformer model.
In GPT-1, to simplify the model and reduce computational complexity, only the decoder component of the transformer in Figure 1 [8] is utilized. Figure 2 [12] illustrates the form with the cross self-attention portion removed from the transformer [8, 9].

Figure 2 GPT-1 model.
As training is conducted in an autoregressive manner, predicting the next word as illustrated in Formula (1), models in the GPT series demonstrate superior performance compared to conventional language models.
| (1) |
Autoregressive learning, by predicting the next word, enables the acquisition of the language’s structure and the understanding of contextual and linguistic patterns, resulting in superior performance. When employing pre-trained models, a crucial step involves fine-tuning for the specific end task. Autoregressive learning proves beneficial in fine-tuning by promoting a more generalized training approach that avoids being overly biased towards particular problems [8, 9, 12].
2.2 GPT-2 and GPT-3
The objective of the GPT-2 model was to create a general language model through unsupervised pre-training, allowing for zero-shot downstream task execution without the need for fine-tuning. At the time, GPT-2 achieved state-of-the-art (SOTA) performance in many domains as an unfine-tuned model. This accomplishment underscored the potential of unsupervised pre-training, signifying a significant achievement by surpassing task-specific models and reaching the SOTA [8, 9, 12, 13].
Conventional LLMs commonly suffer from the drawback of being unable to perform tasks without fine-tuning. When the model is trained to execute a specific task through fine-tuning, its generalization ability is compromised.
In GPT-3, to address these issues, in-context learning is employed. In-context learning enables the pre-trained model to perform specific tasks without fine-tuning by providing examples when solving problems. In in-context learning, various methods exist, such as those outlined in Table 1, including zero-shot, one-shot, and few-shot, depending on the number of examples provided.
Table 1 Method of in-context learning
| Method | Description |
| Zero-shot learning | The model cannot look at any examples from the target class |
| One-shot learning | The model observes only one example from the target class |
| Few-shot learning | The model observes few examples from the target class |
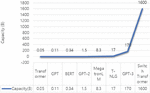
As another approach to enhance the model and address issues, increasing the model capacity, i.e., the number of parameters, is employed to enable the execution of more computations. As depicted in Figure 3 [1], recent high-performing LLMs exhibit a gradual expansion in model capacity, contributing to their superior performance [12–14].
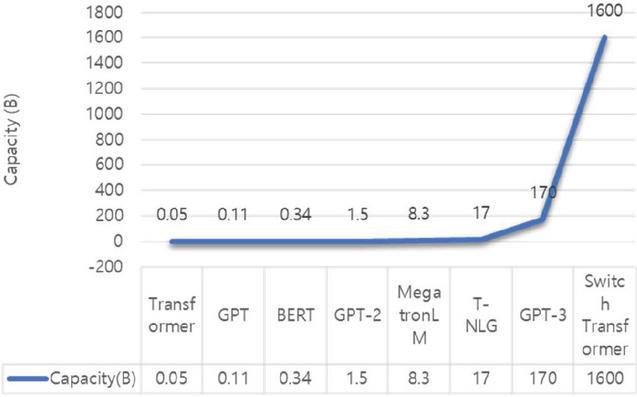
Figure 3 Model capacity of LLMs.
Even with an increased model capacity and the application of few-shot learning in pre-trained models, the model may fail to accurately comprehend the purpose and direction of the task it requires. In such instances, the model cannot generate the intended response as envisioned by the questioner.
In this paper, we propose a novel approach to enhance the response generation performance of the GPT series LLM by introducing a method for constructing prompt structures.
3 Proposed Method
In general, the ChatGPT series of LLM (large language models) exhibits significant variations in the quality of generated sentences depending on the training data or environment. Therefore, methods such as fine-tuning or few-shot learning are often employed to instruct the model on how to generate high-quality responses [15–19]. Fine-tuning involves training the LLM on a large amount of additional data to generate responses. In contrast, few-shot learning generates responses based on a few sample sentences. Typically, when building conversational models such as chatbots using LLM, fine-tuning is predominantly employed, which requires a substantial amount of training data. However, in cases where specialized knowledge is not required, few-shot learning can be leveraged for a quicker and more straightforward development of conversational models [16–19].
In order to create conversational models using few-shot learning, the data input into the prompts plays a crucial role. The process of finding combinations of input values that can yield high-quality desired responses from LLM using prompt input data is referred to as prompt engineering. However, research in utilizing this approach for building conversational models in Korean LLM has been lacking, and it remains underutilized in the context of conversational models [18, 19].
3.1 Prompt Engineering
In general, language generation models tend to have the nature of generating connected sentences and paragraphs based on the input query. Figure 4 illustrates a case applying prompt engineering. When a user’s query, which hasn’t been trained through methods like fine-tuning, is input into a language generation model, as shown in (a) of Figure 4, it extends the query rather than generating a response, resulting in additional queries instead.
To go beyond this characteristic of LLM and generate appropriate interactive responses without fine-tuning, users are encouraged to input their queries in a simplified and suitable form. This approach, as depicted in (b) of Figure 4, allows the model to generate responses to the queries effectively.
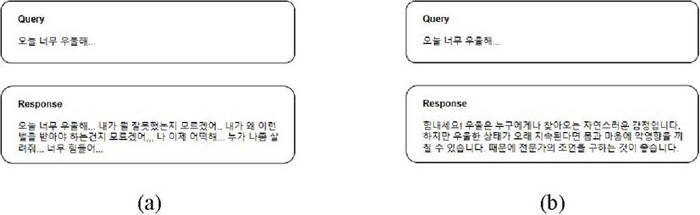
Figure 4 Response generation methods in LLM. (a) Conventional response generation method. (b) Few-shot learning-based interactive response generation method.
This process is referred to as prompt engineering, and it involves creating prompt queries used in language generation models to generate natural and appropriate responses to queries. Additionally, prompt engineering enables the generation of input data that allows LLM to produce the most suitable questions or answers based on user input, improving the conversational flow of chatbots and creating more natural interactions. This, in turn, enhances chatbot efficiency and user satisfaction. Therefore, by appropriately configuring a Korean prompt-based few-shot learner, one can anticipate performance improvements in LLM [20–23].
3.2 Proposed Query Transformation Module
The query transformation module (QTM) in Figure 5 transforms queries in a manner distinct from the conventional approach (a), opting instead for the method illustrated in (b). In this study, we explore and propose a methodology where queries, engineered through prompt engineering using the approach in (b), serve as prompt queries for LLM. This ensures the precise recognition of the user’s query intent by the LLM, effectively conveying the necessary objectives for proficient interactive response generation.

Figure 5 Application of the query transformation module. (a) Conventional approach. (b) Proposed method.
The original query technique involves presenting user-input queries directly to the language generation model without preprocessing or transformation for experimental purposes. In this work, the proposed technique utilizes four types of prompt queries: general query, preceding phrases query, cloze query, and purpose explicit query.
The preceding phrases query (PPQ) technique involves providing the initial sentence or words necessary for a relevant and appropriate response, allowing the subsequent sentence to be generated. As shown in the sample in Table 1, essential content required for the response, particularly the opening statement, is input into the language generation model. If there are no specific instructions in the input query, the language generation model can intentionally induce the required response by completing the subsequent sentence related to the preceding phrase.
The cloze query (CQ) technique involves presenting a sentence with certain parts left blank, accompanied by examples, and then completing the sentence by filling in the blanks. This method is commonly referred to as “fill in the blanks” and is frequently employed in language generation models. In other words, it entails providing a few question–answer pairs as examples and inducing similar responses based on them.
The purpose explicit query (PEQ) technique involves stating the purpose or objective and providing categorized examples accordingly in the query. The PEQ method goes beyond the cloze query technique by not only specifying the purpose behind the query but also presenting a variety of examples in different categories. This approach aims to guide language generation models to produce more natural responses by helping them understand the specific purpose behind the query and showcasing various forms of examples.
Each query technique is denoted as Query, PPQ, CQ, and PEQ. In accordance with Figure 6, experiments are conducted utilizing the appropriate responses for each method. The form and quality of the generated responses are then scrutinized and evaluated based on their respective query construction methods.

Figure 6 Query examples and query methods.
4 Experiment
In this section, we specify the settings for the models, and evaluation metrics for few-shot learning. We conduct our experiments and analyses based on the experimental settings specified in this section. More details about training environments and hyperparameters are described as follows.
4.1 Experiment Environment and Method
Google Colab, an open-source service offered by Google, is accessible to individuals with Gmail accounts. Google Colab is a valuable resource for researchers who may lack the necessary hardware resources or cannot financially afford GPU access. This service provides a substantial allocation of computing resources, including 12.72 GB of RAM and 358.27 GB of hard disk space for each runtime session. It’s important to note that each runtime session has a duration of 12 hours, after which it automatically resets, requiring users to establish a new connection [24–26].
In Google Colab, we executed SKT GPT-2 and Kakaobrain KoGPT-3 models and queried them using the four query methods outlined in Section 3.2 in response to the experimental 3 queries from Figure 6. The results were then processed to remove special characters such as Korean characters, English characters, numbers, and periods using LinQ [27].

Figure 7 Experiment results for SKT GPT-2.

Figure 8 Experiment results for Kakaobrain KoGPT.
4.2 Experiment Results and Evaluation
Based on the experimental models presented in Section 3, the results obtained from SKT GPT-2 were consistent with Figure 7, while the outcomes derived from Kakaobrain’s KoGPT-3 matched those in Figure 8. It was observed that as we progressed from a general query to PPQ, CQ, and PEQ, the responses gradually became more conversational in nature. Upon comparing Figure 7, which illustrates SKT GPT-2 (117M parameters), with Figure 8, which showcases Kakaobrain KoGPT-3 (6B parameters), it becomes evident that Kakaobrain KoGPT-3, with a higher number of parameters, exhibits superior overall response quality.
Google Brain introduced the sensibleness and specificity average (SSA) evaluation method to address the challenges of objectively assessing generative language models’ performance, considering the inherent complexities of understanding sentence ambiguity and meaning. Unlike traditional metrics like ROUGE and BLEU, which may not effectively evaluate models’ ability to engage in human-like conversations, SSA has become a preferred method for evaluating conversational models. SSA evaluates whether a model’s responses make sense “sensibleness” and provide specific, contextually relevant information “specificity” in a human-like manner, assigning binary scores of 0 or 1 for each aspect. This metric plays a crucial role in assessing the quality of natural language generation models, particularly in the context of conversational dialogue [28, 29].
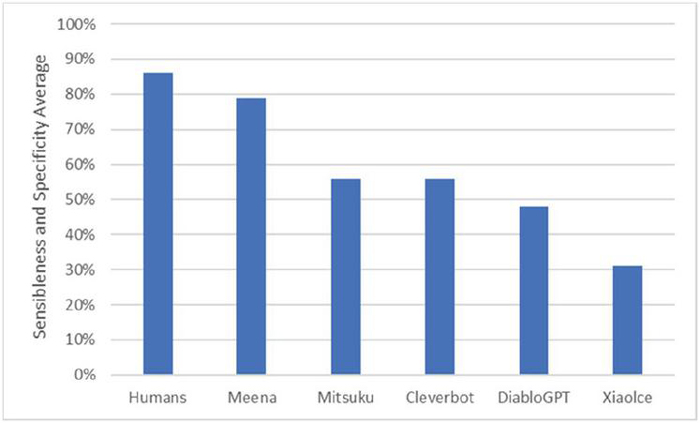
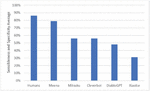
Figure 9 Evaluation metrics for Google SSA models [29].
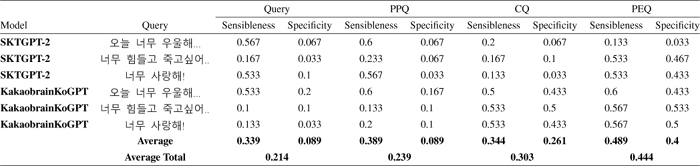
As observed in Figure 9, humans received an evaluation score of 86%, while other language generation models received an average score of 56%. Examining the evaluation results based on SSA in Table 2, we observe that the language generation model Kakaobrain KoGPT, which did not undergo fine-tuning, received a very low average score of 21.4% for Q1. However, it is worth noting that there was an improvement in performance, reaching 44.4%, for Q2–4 through preprocessing and query transformation.
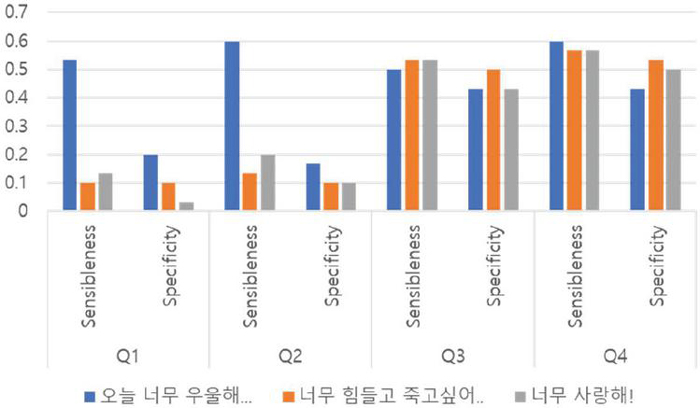
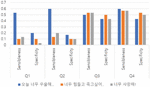
Figure 10 Comparison of experimental results.
Figure 10 illustrates that sensibleness and specificity consistently improved for Q1–4. These results indicate that, across various language generation models, it is possible to achieve a usable level of conversational response generation through prompt engineering.
5 Conclusion
In this research, we present an efficient approach for generating specific interactive responses with limited data, utilizing prompt engineering on Korean-based LLM. As a part of our methodology, we introduce the query transformation module (QTM), which refines input prompt sentences into three distinct query methods by deconstructing them into objectives and key points. The performance of each query method is assessed through Google SSA to evaluate sentence naturalness and specificity [9]. Our results demonstrate an average enhancement of 11.46% compared to unaltered queries that lack the objectives and intent of the input data. This paper only conducted evaluations for a total of 12 models using three example sentences and four query methods. Future research endeavours involve investigating techniques for improving prompts without relying on QTM.
Acknowledgement
This work was supported by the National Research Foundation of Korea Grant funded by the Korean Government (NRF-2021R1I1A4A01049755) and by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2020-0-01846) supervised by the IITP (Institute of Information and Communications Technology Planning and Evaluation).
References
[1] Zhao, Wayne Xin, et al. “A survey of large language models.” arXiv preprint arXiv:2303.18223 (2023).
[2] Hadi, Muhammad Usman; tashi, qasem al; Qureshi, Rizwan; Shah, Abbas; muneer, amgad; Irfan, Muhammad; et al. (2023). A Survey on Large Language Models: Applications, Challenges, Limitations, and Practical Usage. TechRxiv. Preprint. https://doi.org/10.36227/techrxiv.23589741.v1.
[3] T. Wu et al., “A Brief Overview of ChatGPT: The History, Status Quo and Potential Future Development,” in IEEE/CAA Journal of Automatica Sinica, vol. 10, no. 5, pp. 1122–1136, May 2023, doi: 10.1109/JAS.2023.123618.
[4] Gozalo-Brizuela, Roberto, and Eduardo C. Garrido-Merchan. “ChatGPT is not all you need. A State of the Art Review of large Generative AI models.” arXiv preprint arXiv:2301.04655 (2023).
[5] Sang-Woo Lee, Gichang Lee, and Jung-Woo Ha (2023). Recent Studies on Hyperscale Language Models from NAVER. Communications of the Korean Institute of Information Scientists and Engineers, 41(4), 91–97.
[6] Howard, J., and Ruder, S. (2018). Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Long Papers) (Vol. 1, pp. 328–339). https://doi.org/10.18653/v1/p18-1031.
[7] S. An, J. Ryu, W. Cho, J Noh, and H. Son, Rise of Hyper-scale LLM (Large Language Model) and issues, Software Policy & Research Institute Issue Report IS-158, v 1.2, 2023.02
[8] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, £., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 2017-Decem (Nips), 5999–6009.
[9] Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL HLT 2019 – 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies – Proceedings of the Conference, 1(Mlm), 4171–4186.
[10] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., …Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems, 2020-Decem.
[11] Qiu, X. P., Sun, T. X., Xu, Y. G., Shao, Y. F., Dai, N., and Huang, X. J. (2020). Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 63(10), 1872–1897. https://doi.org/10.1007/s11431-020-1647-3.
[12] Radford, A., Narasimhan, K., Salimans, T., and Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. Retrieved from https://openai.com/research/language-unsupervised.
[13] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. Retrieved from https://openai.com/research/better-language-models.
[14] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., …Amodei, D. (2020). Language models are few-shot learners. Advances in Neural Information Processing Systems (Vol. 33, pp. 1877–1901).
[15] Chang, Y., Wang, X., Wang, J., Wu, Y., Zhu, K., Chen, H., … and Xie, X. (2023). A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109. https://doi.org/10.48550/arXiv.2307.03109.
[16] Ziegler, D. M., Stiennon, N., Wu, J., Brown, T. B., Radford, A., Amodei, D., Christiano, P., and Irving, G. (2019). Fine-Tuning Language Models from Human Preferences. arXiv preprint arXiv:1909.08593.
[17] Liu, X., Ji, K., Fu, Y., Tam, W., Du, Z., Yang, Z., and Tang, J. (2022, May). P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (pp. 61–68). https://doi.org/10.18653/v1/2022.acl-short.8.
[18] Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., and Wierstra, D. (2016). Matching Networks for One Shot Learning. In Advances in Neural Information Processing Systems 29 (NIPS 2016). URL: https://papers.nips.cc/paper/6385-matching-networks-for-one-shot-learning.
[19] Ravi, S., and Larochelle, H. (2017). Optimization as a Model for Few-Shot Learning. In International Conference on Learning Representations (ICLR). URL: https://openreview.net/forum?id=rJY0-Kcll.
[20] White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., … and Schmidt, D. C. (2023). A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv preprint arXiv:2302.11382.
[21] Liu, V., and Chilton, L. B. (2022, April). Design guidelines for prompt engineering text-to-image generative models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (pp. 1–23). https://doi.org/10.1145/3491102.3501825.
[22] Zhou, Y., Muresanu, A. I., Han, Z., Paster, K., Pitis, S., Chan, H., and Ba, J. (2022). Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910.
[23] Oppenlaender, J. (2022). Prompt engineering for text-based generative art. arXiv preprint arXiv:2204.13988. https://doi.org/10.48550/arXiv.2204.13988.
[24] Bisong, E. (2019). Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners (pp. 59–64). Apress. https://doi.org/10.1007/978-1-4842-4470-8\_7.
[25] Sukhdeve, D. S. R., and Sukhdeve, S. S. (2023). Google Colaboratory. In Google Cloud Platform for Data Science: A Crash Course on Big Data, Machine Learning, and Data Analytics Services (pp. 11–34). Apress. https://doi.org/10.1007/978-1-4842-9688-2\_2
[26] Monteiro, T. (2023, March 10). Meet Google Colab: Developing AI on the Cloud. gHacks Tech News. Retrieved from https://www.ghacks.net/2023/03/10/what-is-google-colab/.
[27] Wikipedia contributors. (n.d.). Language Integrated Query. In Wikipedia, The Free Encyclopedia. Retrieved from https://en.wikipedia.org/wiki/Language\_Integrated\_Query.
[28] Adiwardana, D., Luong, M.-T., So, D. R., Hall, J., Fiedel, N., Thoppilan, R., Yang, Z., Kulshreshtha, A., Nemade, G., Lu, Y., and Le, Q. V. (n.d.). Towards a Human-like Open-Domain Chatbot. Retrieved from https://ar5iv.org/abs/2001.09977.
[29] Google Research Blog. (n.d.). Towards a Conversational Agent that Can Chat About…Anything. Retrieved from https://blog.research.google/2020/01/towards-conversational-agent-that-can.html.
Biographies

Daeseung Park received his B.Sc. and M.Sc. degrees in computer science from Namseoul University in 2015 and 2022, respectively. His research areas include embedded system, mobile security, deep learning, natural language processing and computer vision.

Gi-taek An received his B.Sc. in Computer Science from Namseoul University in 2011 and M.Sc. in Computer Science from Jeonbuk National University. Currently, he is a Senior Technical Researcher at the Korea Food Research Institute and a Ph.D. student at Jeonbuk National University. His research areas include information retrieval, artificial intelligence, and data platforms.

Chayapol Kamyod achieved his Ph.D. in Wireless Communication from the Center of TeleInFrastruktur at Aalborg University, Denmark, a significant milestone in his academic career. This was preceded by a Master of Engineering in Electrical Engineering from The City College of New York and, earlier, a Bachelor’s and Master’s in Telecommunication Engineering and Laser Technology and Photonics from Suranaree University of Technology, Thailand. Currently, he is a lecturer in the Computer Engineering program at Mae Fah Luang University, Thailand, where his research is focused on the resilience and reliability of computer networks, wireless sensor networks, and exploring the potentials of IoT applications.

Cheong-Ghil Kim received his B.Sc. in Computer Science from University of Redlands, CA, USA in 1987. He received his M.Sc. and Ph.D. degrees in Computer Science from Yonsei University, Korea, in 2003 and 2006, respectively. Currently, he is a professor at the Department of Computer Science, Namseoul University, Korea. His research areas include multimedia embedded systems, mobile AR and 3D contents, and AI chatbot. He is a member of IEEE.
Journal of Web Engineering, Vol. 22_8, 1187–1206.
doi: 10.13052/jwe1540-9589.2285
© 2024 River Publishers