Robust Cloud Service Ranking with Deep Learning and Multi-criteria Analysis
Pooja Goyal* and Sukhvinder Singh Deora†
Department of Computer Science and Application, Maharshi Dayanand University, Rohtak, Haryana, India
E-mail: poojagarggoyal895@gmail.com; sukhvinder.dcsa@mdurohtak.ac.in
*Corresponding Author
†Contributing Author
Received 24 July 2024; Accepted 24 June 2025
Abstract
With the rapid growth of cloud services, it is crucial to have strong assessment methods in place to rate these services according to their performance, dependability, and security. This study introduces a holistic methodology that utilizes advanced deep learning (DL) algorithms to prioritize and evaluate cloud services. Our model incorporates many assessment criteria, including latency, throughput, availability, and security measures. These criteria are trained using a varied collection of performance measurements from cloud services. We validate the effectiveness of our methodology by comprehensive experiments, attaining greater precision and significance in ranking compared to conventional approaches. The DL model underwent evaluation using a testing set, resulting in a mean absolute error (MAE) of 0.15 in ranking scores. The algorithm regularly achieved superior results compared to conventional ranking approaches, particularly in situations where performance measures varied. Through the incorporation of security metrics, the model successfully assessed and ranked cloud service providers (CSPs) based not only on their performance, but also on their ability to withstand security threats. The DL technique exhibited more flexibility and contextual awareness in its rankings, hence showcasing its superiority in adjusting to real-time data. The research conducted a comparison between DL-based rankings and conventional methodologies and industry standards, demonstrating its superiority in effectively adjusting to real-time data. The study technique entails gathering data from many CSPs to construct a resilient framework for evaluating cloud services using DL models. The data is obtained from publicly available performance statistics, cloud monitoring tools, user evaluations, and problem reports. The collection comprises both structured and unstructured data, including essential performance and accuracy indicators.
Keywords: Cloud services, DL, ranking, performance evaluation, security metrics.
1 Introduction
Given the abundance of cloud service providers (CSPs) that provide different degrees of service, it is crucial to have a methodical strategy to assess and rank these services. Conventional ranking algorithms often fail to adequately capture the intricate interaction of performance, reliability, and security measures. This study presents a deep learning (DL) architecture that aims to tackle these problems and provide a ranking system that is both more precise and adaptable. It has transformed provision of IT services by offering adaptable cost-efficient solutions for many applications. As organizations increasingly depend on cloud services for their operational requirements, it becomes crucial to systematically assess and rate CSPs. Efficient ranking systems may assist enterprises in choosing the most appropriate CSPs by considering crucial performance and security parameters. Conventional ranking systems, which often depend on fixed criteria like predetermined benchmarks, service level agreements (SLAs), and customer evaluations, are insufficient for comprehensively assessing the dynamic and varied aspects of cloud service performance. These techniques do not consider the immediate changes in service quality and new security concerns, leading to less than ideal decision-making. This research investigates the use of DL approaches to prioritize cloud services in order to tackle these difficulties. We specifically examine the use of LSTM networks, the BERT model, and the RoBERTa model for purpose analyzing and ranking CSPs according to an extensive range of performance and security indicators. Utilizing advanced DL models like LSTM, BERT, and RoBERTa significantly enhances precision and pertinence evaluating cloud services in the rating field. LSTM stands for long short-term memory. Each of these models serves a distinct purpose within the supplied DL architecture. Each of them has distinct benefits that together contribute to improving the overall effectiveness of the ranking system.
1.1 Ranking Cloud Services
Cloud computing has become an essential element for organizations in the fast-paced and ever-changing sector of information technology, providing them with the capacity to scale, operate efficiently, and foster innovation. Ranking cloud services entails assessing and contrasting different providers according to a set of essential criteria in order to ascertain the most suitable option for certain business requirements. This procedure is crucial for maximizing resource efficiency, guaranteeing strong security and adherence to regulations, improving performance and dependability, efficiently controlling costs, and enabling access to state-of-the-art technology. When rating cloud services, important aspects taken into account include performance and scalability, security measures, cost and SLAs, feature sets, and the provider’s reputation and market status. Organizations may use benchmarking, surveys, analytical frameworks, and industry research to make educated judgments when picking cloud services that are in line with their strategic goals and operational needs. This not only enhances overall efficiency but also facilitates continual development and innovation in a competitive industry. These tools have become a powerful and influential force in the ever-changing field of information technology and provide a variety of services that allow organizations to grow, be creative, and operate with more efficiency. As enterprises progressively transfer their activities to the cloud, it becomes essential to assess and prioritize cloud services. Evaluating cloud services entails analyzing different providers according to several criteria to identify the most appropriate choices for particular business requirements (Figure 1).
Figure 1 Top 10 cloud service providers globally in 2024 [30].
1.1.1 The importance of ranking cloud services
1. Optimizing resource utilization: By prioritizing cloud services, enterprises may choose providers who provide the most efficient mix of performance, pricing, and scalability, guaranteeing the optimum use of resources.
2. Ensuring security and compliance: Cloud providers provide different degrees of security and compliance services. Ranking facilitates the identification of suppliers that satisfy the essential regulatory and security prerequisites.
3. Improving performance and dependability: Ranking enables organizations to choose services that provide exceptional dependability and performance, reducing the occurrence of downtime and assuring seamless operations.
4. Cost management: Organizations may enhance their budget management and prevent excessive spending on cloud services by evaluating the cost-effectiveness of different providers.
5. Enabling innovation: The ability to get state-of-the-art technology and inventive solutions is essential for the expansion of businesses. Evaluating cloud services enables the identification of providers that provide sophisticated tools and services that might stimulate creativity.
1.1.2 Factors for evaluating cloud services
Several key factors are considered when ranking cloud services:
1. Performance and scalability: This entails assessing the velocity, dependability, and capacity for growth of the cloud service. Metrics like latency, uptime, and scalability are essential.
2. Security and compliance: It is crucial to evaluate the security measures used, like identity management, and adherence to industry standards and laws, in order ensure security and compliance.
3. Cost and pricing models: Analyzing the pricing frameworks and overall cost of ownership aids in identifying the most economically advantageous choice. This entails taking into account pay-as-you-go models, subscription plans, and any concealed expenses.
4. Service level agreements (SLAs): The quality and dependability of SLAs provided by providers are crucial in guaranteeing that services fulfill corporate objectives and expectations.
5. Customer support and service management: The rating of a company is significantly influenced by the quality of its customer support and service management, which encompasses factors such as response times, availability of help channels, and overall administration of services.
6. Features and capabilities: When evaluating a product or service, it is crucial to take into account the breadth and excellence of its features, including storage alternatives, computational capabilities, network services, and supplementary tools like artificial intelligence and analytics.
7. Reputation and market position: The rating of a provider may be influenced by factors such as reputation, client reviews, and market position. These factors give valuable insights into the dependability and quality of the service.
1.1.3 Methods for ranking cloud services
Various methodologies can be employed to rank cloud services, including:
1. Benchmarking: Conducting performance tests and benchmarks to compare different services on specific criteria.
2. Surveys and reviews: Gathering feedback from existing customers through surveys and reviews to gain insights into user satisfaction and experiences.
3. Analytical frameworks: Utilizing analytical frameworks and models, like MCDA and the AHP, to systematically evaluate and rank providers based on multiple criteria.
4. Industry reports and research: Referring to industry reports, research papers, and expert analyses to understand providers.
Ranking cloud services is a critical process that enables organizations to make informed decisions about their cloud strategies. By systematically evaluating providers based on performance, security, cost, and other key factors, businesses can ensure they select the most suitable services that align with their goals and requirements. This not only enhances operational efficiency but also drives innovation and growth in the competitive digital landscape.
1.2 Long Short-Term Memory (LSTM) Networks
LSTM networks, a kind of RNN, are very effective at handling and forecasting time-series data because of their capacity to preserve long-term dependencies. Regarding the evaluation of cloud services, LSTMs are capable of accurately detecting and understanding the time-based trends and fluctuations in key performance indicators such as latency, throughput, and availability. LSTM networks, a kind of RNN, aim to provide enduring connections in sequential data. As a result they are particularly efficient in evaluating time-series data that are linked to cloud service performance metrics such as latency, throughput, and availability. LSTM models are valuable for predicting future performance and assessing the reliability and consistency of cloud services over time. They do this by effectively gathering temporal patterns and trends. Temporal research is essential to fully understand the performance dynamics of cloud services.
1.3 BERT and RoBERTa Models
These are state-of-the-art transformer-based models specifically designed for natural language processing (NLP) applications. Nevertheless, their strong ability to learn representations makes them well-suited for a wider array of uses, such as analyzing both structured and unstructured data in cloud computing. We can augment the model’s capacity to comprehend and analyze intricate correlations across diverse performance and security indicators. BERT, a transformer-based model originally designed for NLP applications, excels in understanding the contextual relationships among various components within a dataset. Its ability to gather context bidirectionally makes it an exceedingly valuable instrument for analyzing both organized and unorganized data in cloud computing. BERT enables the model to understand the complex connections between various performance and security measures by giving it detailed and contextual representations of the data. The bidirectional analysis enhances the dataset, and when paired with BERT’s ability to handle unstructured data like logs and user evaluations, it results in a more thorough evaluation of cloud services. The RoBERTa method, derived from the BERT algorithm with additional changes to improve efficiency and resilience, is particularly advantageous in scenarios requiring exceptional accuracy and noise resistance. Increasing the duration of training on larger datasets, using dynamic masking during training, and adopting a more efficient fine-tuning approach all enhance the ability of RoBERTa to generalize and effectively process diverse input data. Every one of these criteria has a role in determining RoBERTa’s overall performance. Due to these improvements, RoBERTa is now capable of generating accurate and resilient feature representations, hence enhancing the evaluation process.
1.4 Motivation and Contributions
By using the benefits provided by the LSTM, BERT, and RoBERTa models, the proposed DL framework may successfully develop a robust and reliable ranking system for cloud services. To ensure a comprehensive assessment of the quality of each cloud service, the models work together to extract and combine features from the collected performance and security data. This integrated method enables a more refined and precise ranking by generating a composite ranking score for each cloud service provider (CSP) based on a combination of performance indicators and security ratings. Given these circumstances, this framework not only improves the accuracy and significance of cloud service rankings, but it also ensures that the evaluation is flexible and can be adjusted to changes in real-time performance. The objective of this study is to create a sophisticated framework that combines the LSTM, BERT, and RoBERTa models of cloud service ranking. Our precise contributions encompass:
1. Data collection and preprocessing: We gather a diverse dataset of performance and security metrics from multiple CSPs, including AWS, Microsoft Azure, and GCP.
2. Model development: Designing and implementing an LSTM, BERT, and RoBERTa-based models process and analyze the collected data, capturing both temporal dependencies and complex feature interactions.
3. Evaluation and comparison: We evaluate the performance of our models using standard metrics and compare the results with traditional ranking methods and industry benchmarks.
4. Holistic ranking system: By incorporating multiple evaluation parameters, our approach provides a holistic ranking of CSPs that considers not only performance but also security and reliability.
Through this research, we demonstrate the potential of DL techniques in transforming the way cloud services are evaluated and ranked, ultimately aiding organizations in making more informed and effective choices.
2 Literature Review
Conventional approaches to rating cloud services depend on established criteria including service level agreements (SLAs), customer feedback, and specified standards. These solutions often lack the flexibility to accommodate real-time fluctuations in performance and developing security risks. DL has shown potential in several fields, Within the realm of cloud computing, DL may be used to scrutinize large quantities of performance data and reveal patterns that conventional approaches may overlook. The literature on cloud service ranking covers a wide variety of approaches and improvements, which demonstrate the complexity and changing nature of the cloud computing ecosystem (Table 1). The study conducted by Agrawal and Agrawal (2016) offers a fundamental examination of performance assessment techniques for cloud service providers, emphasizing the need for comprehensive ranking systems that include several service quality factors. In their study, Alwidian et al. (2018) further explore this topic by using MCDM techniques to assess and evaluate. They highlight the need to include many assessment criteria to enhance the precision and comprehensiveness of the rankings. In their study, Huang et al. (2019) propose a DL methodology for rating cloud services. They use neural networks to improve the precision and dependability of service assessments. This work highlights the capability of DL models to handle intricate and extensive datasets, providing a substantial improvement compared to conventional ranking approaches. Menzel et al. (2015) introduce the (MC2) framework, which uses multicriteria decision analysis (MCDA) to prioritize cloud services according to predetermined criteria. This method emphasizes the need to use criteria-based selection to make well-informed decisions when choosing cloud services.
| Ref | Author | Application | Advantage | Scope of Research |
| [1] | Agrawal and Agrawal (2016) | Performance evaluation of cloud service providers | Comprehensive survey and ranking methods | Surveys various performance evaluation methodologies and provides a ranking system for cloud services. |
| [2] | Alwidian, Al-Hawari and Khader (2018) | Multi-criteria decision-making methods for cloud services | Integration of multiple evaluation criteria | Focuses on using MCDM methods to rank cloud services based on various criteria. |
| [3] | Huang, Chen and Fu (2019) | DL for cloud service ranking | Utilizes DL for improved accuracy and reliability | Proposes a DL approach to enhance the ranking of cloud services. |
| [4] | Menzel, Schönherr and Tai (2015) | MC: Criteria-based selection and ranking | Criteria-based selection using multicriteria decision analysis | Introduces a framework for ranking cloud services using predefined criteria and multicriteria decision analysis. |
| [5] | Moghaddam, Mohammadian and Wray (2018) | Adaptive neuro-fuzzy inference system for cloud service selection | Combines neural networks with fuzzy logic | Applies ANFIS to improve cloud service selection and ranking through adaptive learning and fuzzy logic. |
| [6] | Mourad and Habib (2017) | Trust and reputation-based ranking | Focuses on trust and reputation for ranking cloud services | Proposes a novel approach that incorporates trust and reputation factors into cloud service ranking. |
| [7] | Sharma and Peddoju (2016) | Multi-criteria based optimal selection of cloud service providers | Balances multiple performance metrics | Employs a multi-criteria approach to optimize the selection of cloud service providers. |
| [8] | Sun, Zhang, Xiong and Zhu (2014) | Data security and privacy in cloud computing | Addresses security and privacy concerns | Focuses on data security and privacy issues affecting cloud service evaluations. |
| [9] | Tang, Wang and Liu (2019) | QoS history with neural network for cloud service ranking | Enhances ranking using historical QoS data and neural networks | Utilizes neural networks to rank cloud services based on historical quality of service data. |
| [10] | Wang and Wang (2014) | Trust, risk, and service quality perspective | Comprehensive survey of cloud service selection and ranking | Surveys the perspectives of trust, risk, and service quality in cloud service ranking. |
| [11] | Xu, Zhu and Li (2020) | ML and DL techniques for ranking | Comprehensive review of ML and DL techniques | Reviews various ML and DL techniques applied to cloud service ranking. |
| [12] | Yousefpour, Javadi and Buyya (2019) | Policy-based and ML ranking systems | Provides taxonomy and future directions | Reviews and categorizes policy-based and ML-based ranking systems, offering insights for future research. |
Moghaddam et al. (2018) use an ANFIS to enhance the ranking process cloud service selection. This approach combines neural networks with fuzzy logic to get improved results. In their 2017 publication, Mourad and Habib provide an innovative method for rating cloud services that takes into account trust and reputation, with a particular focus on the importance of trustworthiness in the evaluation process. Sharma and Peddoju (2016) concentrate on multi-criteria optimization, offering techniques for choosing the most appropriate cloud service providers by effectively managing several performance parameters. Sun et al. (2014) investigate the issues of privacy in cloud computing, which are crucial determinants affecting the rankings of cloud services. In their study, Tang et al. (2019) use neural networks to assess the quality historical data on QoS. Their research showcases the efficacy of ML methods in effectively analyzing historical data for the goal of evaluating cloud services. In their study, Wang and Wang (2014) conducted a thorough examination of the process of selecting and rating cloud services, focusing on trust, risk, and service quality. Their research sheds light on the complex nature of evaluating cloud services. In their study, Xu et al. (2020) carry out an extensive investigation into the ranking of cloud services. They use ML and DL techniques, which underscores the increasing importance of sophisticated computational approaches in this domain. In their 2019 publication, Yousefpour et al. provide an analysis of policy-based and ML-based ranking systems. They provide a taxonomy and explore potential future advancements in cloud service ranking approaches.
Zheng et al. (2016) use ML methodologies to prioritize cloud services, contributing to the existing research on the utilization of computational models for assessing service quality. Buyya et al. (2010) provide a fundamental work that explores the ideas and paradigms of cloud computing. This article establishes the background for future research on the ranking of cloud services. Jaiswal et al. (2019) provide a method of integrating many indicators to create a balanced assessment in ranking cloud services based on QoS. They present a weighted aggregation methodology to demonstrate the effectiveness of this method. In their study, Almorsy et al. (2016) examine the security concerns associated with cloud computing. These concerns play a crucial role in assessing security capabilities. Kashif et al. (2017) use multicriteria decision analysis and probabilistic linguistic term sets to prioritize cloud service providers, demonstrating the utilization of sophisticated decision-making methods in the ranking procedure. In their study, Chen et al. (2019) critically examine several strategies for evaluating the performance of cloud services, offering a comprehensive overview of the methods and practical uses in this field. Alhamad et al. (2010) provide a trust model for cloud computing that is built on service level agreements (SLAs). They emphasize the significance of SLAs in evaluating and rating cloud services. Li and Wang (2015) propose a cloud service selection model that incorporates multi-criteria decision analysis, with a particular focus on the importance of security factors in the ranking procedure. Patel et al. (2009) examine SLAs in cloud computing, enhancing the comprehension of contractual elements in service assessments.
Sun et al. (2019) use DL techniques to forecast quality of service (QoS), improving the ranking procedure by integrating predictive analytics. In their study, Xia et al. (2012) investigate the Internet of Things and its influence on the appraisal of cloud services, offering valuable insights into the effect of developing technologies. In their 2004 paper, Zeng et al. provide a QoS-aware middleware for web services composition. This middleware solution has implications for cloud service rankings. In their 2010 paper, Zhang et al. provide an overview of the current status of cloud computing and the research obstacles that need to be addressed. Their work lays the foundation for future improvements in the methods used to rate cloud services. In their study, Gill et al. (2017) provide the RC2R framework, which offers a realistic method for ordering resources in cloud data centers based on runtime costs. Garg and Buyya (2012) examine SaaS providers based on SLAs, which enhances our comprehension of resource ranking. Rodriguez and Buyya (2014) provide a resource provisioning method that is based on deadlines. This approach provides valuable information on the scheduling and provisioning elements of cloud services. These studies provide a diverse and dynamic range of methods for rating cloud services, including classic decision-making methods, ML techniques, and concerns of security and quality of service.
2.1 Research Gap
In spite of the enormous number of studies that have been done on cloud service rating, there are still numerous significant gaps. Real-time data and dynamic criteria are not being included in ranking algorithms, which is a significant gap in the marketplace. The majority of the approaches that are now in use, such as those that have been presented by Tang et al. (2019) and Huang et al. (2019), are dependent on historical data and static assessment criteria. This may not be sufficient to take into account the very dynamic nature of cloud services and the performance metrics that they use. For models to continue to be accurate and relevant in the face of changing cloud environments and the introduction of new services, they need to be able to react in real time. Another notable gap is the absence of an all-encompassing examination of techniques taken across disciplines. Despite the fact that studies such as the ones conducted by Moghaddam et al. (2018) and Mourad and Habib (2017) have investigated certain features, such as adaptive neuro-fuzzy systems and trust-based models, there is a dearth of comprehensive research concerned with the integration of numerous approaches to develop a ranking system. It is possible that a ranking system that is more resilient and adaptable might be created by combining the insights gained from several methodologies, such as ML, multicriteria decision analysis, and models that are focused on security. A further need is the establishment of common measurements and procedures for the purpose of comparing and assessing different ranking algorithms. A lack of agreement on what constitutes the best practices in cloud service rating is suggested by the fact that different studies use different criteria and techniques. This is something that was brought to light by Xu et al. (2020) and Alwidian et al. (2018). By developing standardized assessment criteria and standards, it may be possible to improve comparisons and ease the refinement of ranking systems in order to guarantee that they are in accordance with the requirements and expectations of the industry. The implementation of complex ranking algorithms in actual, real-world contexts is yet largely unexplored, which brings us to our last point. There are a lot of studies that are mostly theoretical or simulation-based, such as the ones that were done by Agrawal and Agrawal (2016) and Sharma and Peddoju (2016); however, there is a need for empirical research that evaluates these models. For the efficiency of the suggested ranking systems and to ensure that they are applicable in practice, it will be essential to bridge this gap. In order to improve the development of cloud service ranking systems that are more accurate, adaptive, and comprehensive, it is necessary to address these research gaps.
2.2 Limitations in Existing Research
Despite the fact that it is exhaustive and diverse, the study on cloud service rating has a number of drawbacks that need to be addressed. Much research, conducted by Huang et al. (2019) and Tang et al. (2019), mainly depends on ML and DL methods. In order to generate correct rankings, these approaches often need huge datasets of high quality. The acquisition of such datasets, on the other hand, may be a difficult task, and the performance of these models can be greatly influenced by problems with the quality of the data. Furthermore, although frameworks such as (MC2) and approaches that involve adaptive neuro-fuzzy inference systems (Moghaddam et al., 2018) provide advanced ranking methods, it is possible that these methods do not have the ability to be generalized across various cloud environments or that they are too complicated to be practically implemented in real-world scenarios. The emphasis on certain features of cloud services, such as trust and reputation (Mourad and Habib, 2017) or quality of service history (Tang et al., 2019), may not completely capture all significant factors for ranking. This is another weakness of the study. For instance, trust-based models may miss other crucial aspects such as cost effectiveness or scalability, despite the fact that they provide vital insights into the dependability of the service. In addition, a great number of studies, such as the ones conducted by Agrawal and Agrawal (2016) and Sharma and Peddoju (2016), focus on theoretical frameworks or simulation findings. However, owing to the dynamic nature of cloud environments, it is possible that these results do not always transfer successfully into actual implementations. Lastly, the fact that various studies utilize diverse ranking criteria and methodology (for example, Sun et al., 2014 presented security concerns, while Yousefpour et al., 2019 presented policy-based systems) implies that there is a lack of consistency in the ways that are used to rate cloud services. Comparing multiple ranking systems might become more difficult as a result of this diversity, which also makes it more difficult to design measures that are generally acceptable. In order to advance cloud service ranking algorithms and ensure that they are both resilient and usable across a variety of circumstances, it will be essential to address these restrictions.
3 Research Methodology
When it comes to establishing a strong framework for evaluating cloud services using DL models one of the most important steps is the collecting of data. It is closely related to the efficiency and accuracy of the suggested ranking system that the quality and comprehensiveness of the dataset are taken into consideration. Detailed information on the sources, kinds of data obtained, and preprocessing methods that are required to get the data ready for DL models is provided in this section, which provides an overview of the process of data gathering. Different CSPs, such as AWS, Microsoft Azure, and GCP, provided us with the performance data that we gathered. The dataset contains information on a variety of metrics, including latency, throughput, availability, and security events that occurred over the course of a year.
3.1 Data Sources
The data is gathered from a wide range of sources in order to guarantee that the assessment of CSPs is exhaustive. Some examples of these are the public performance reports that are provided by major CSPs including AWS, Microsoft Azure, and GCP. These reports provide critical performance indicators. Real-time performance measurements are also provided by CloudWatch, Azure Monitor, and Google Stackdriver, which are examples of cloud monitoring tools and services that are used to collect data. User evaluations and comments from platforms such as Gartner, Trustpilot, and CloudHarmony give unstructured data that provides insights into consumer happiness and perceived performance. These platforms are good examples of such platforms. In addition, security incident reports from databases such as the CSA and security bulletins from the cloud service providers themselves are included in order to collect information on security breaches and events.
• Public performance reports: Performance metrics from publicly available reports and dashboards provided by major CSPs.
• Monitoring tools: Data collected from cloud monitoring tools and services real-time performance metrics.
• User reviews and feedback: Unstructured data derived from user reviews and feedback on platforms such as Gartner, Trustpilot, and CloudHarmony, which offers insights into the level of customer satisfaction and perception of performance.
• Security incident reports: Information on security incidents and breaches from databases like the CSA and security bulletins received directly from cloud service providers (CSPs).
3.2 Types of Data Collected
The collection contains it captures broad variety of measures pertaining to performance and security. Among the key performance metrics that are collected are latency, which refers to the average response time for a variety of cloud services; throughput, which refers to the rates at which data is transferred and processed; availability, which refers to the percentage of time that the cloud is online; and scalability, which refers to the capacity to handle increasing workloads without deteriorating performance. Metrics for security include incident frequency, which refers to the number of security events that occur over a certain time period; severity of incidents, which refers to the impact and severity ratings of security breaches; and compliance scores, which refer to the degree to which norms and regulations in the sector are adhered to. A technique known as sentiment analysis is used to assess user feedback. This technique involves classifying evaluations into three distinct categories: positive, neutral, and negative. Additionally, feature requests and complaints are studied to highlight particular user problems and ideas for improvement.
1. Performance metrics:
• Latency: Average response time for various cloud services.
• Throughput: Data transfer rates and processing speeds.
• Availability: Uptime percentage and downtime incidents.
• Scalability: Ability to handle increasing workloads without performance degradation.
2. Security metrics:
• Incident frequency: Number of security incidents over a given period.
• Severity of incidents: Impact and severity ratings of security breaches.
• Compliance scores: Adherence to industry standards and regulations.
3. User feedback:
• Sentiment analysis: Positive, neutral, and negative sentiments derived from user reviews.
• Feature requests and complaints: Specific user concerns and suggestions for improvement.
3.3 Data Preprocessing
A number of preprocessing processes are carried out on the quality and consistency of the data before it is fed into DL models. The removal of duplicate entries, the management of missing values, and the filtering out of information that is not relevant are all components of data cleaning. During the normalization process, performance measures are scaled to a standard range, which ensures that they are comparable and homogeneous. To prepare the text for analysis by BERT and RoBERTa models, NLP methods are used for unstructured data. These approaches are used to prepare the writing for analysis. For the purpose of LSTM networks, time-series data is arranged in such a way that temporal relationships are preserved, and appropriate time frames are specified.
• Data cleaning: Removing duplicate records, handling missing values, and filtering out irrelevant information.
• Normalization: Scaling performance metrics to a standard range to ensure uniformity and comparability.
• Text processing: For unstructured data, applying NLP techniques by BERT and RoBERTa models.
• Time-series preparation: Structuring time-series data for LSTM networks, ensuring that temporal dependencies are maintained and relevant time windows are defined.
The data is then included into a coherent dataset that is suitable for use by LSTM, BERT, and RoBERTa models once the preprocessing step has been completed. Key characteristics are extracted from both structured and unstructured data, resulting in the creation of a complete feature set that includes measures for performance, security, and user feedback. In order to ensure that the models are trained, validated, and tested on separate subsets of data, the dataset is then separated into three sets: the training set (which accounts for 70% of the total), the validation set (20%), and the test set (10%). The temporal connections are maintained as the time-series data is converted into sequences that are suited for artificial neural networks (LSTM). In order to capture the contextual connections that exist between various aspects, textual data is transformed into embeddings via the use of BERT and RoBERTa models.
• Feature extraction: This process involves extracting key features from both structured and unstructured data in order to provide a complete feature set that includes measurements for performance, security, and user feedback.
• Splits for training, validation, and testing: The dataset is split into training (70%), validation (20%), and test (10%) sets in order to guarantee that the models are trained, validated, and tested on separate but different subsets of data.
• Sequential formatting for long short-term memory (LSTM): This technique involves converting time-series data into sequences that are appropriate for LSTM networks. This process ensures that the temporal linkages are maintained.
• Contextual embedding for BERT and RoBERTa: This technique involves converting textual data into embeddings by using our BERT and RoBERTa models. This allows us to capture the contextual connections that exist between various aspects.
We construct a large and complete dataset by meticulously gathering, preprocessing, and integrating data from a variety of sources. This dataset serves as the basis for the development of an accurate and dynamic cloud service ranking system that makes use of LSTM, BERT, and RoBERTa models. This method not only guarantees the reliability of the ranking, but it also makes it possible to adjust in real time to any changes that may occur in the performance of cloud services or the security environment.
3.4 DL Model
The use of sophisticated DL models, like LSTM, BERT, and RoBERTa, in the process of rating cloud services results in a considerable improvement of the evaluation’s accuracy and relevance. Every one of these models fulfills a specific function inside the DL architecture that has been provided. They each bring their own set of advantages to the table, which allows them to jointly enhance the overall performance of the ranking system. LSTM networks, which are a sort of RNN, are intended to capture long-term relationships in sequential data. Because of this, they are especially effective for assessing time-series data that is associated with cloud service performance measures such as latency, throughput, and availability. LSTM models are useful for forecasting future performance and evaluating the dependability and consistency of cloud services across time. They do this by successfully collecting temporal patterns and trends. To have a complete grasp of the performance dynamics, this temporal is very necessary. Understanding the contextual links between the various elements in a dataset is one of BERT’s strong suits. BERT is a transformer-based model that was primarily created for natural language processing jobs. The fact that it is able to collect context in both directions makes it an extremely useful tool for studying both structured and unstructured data in cloud computing. By providing the model with comprehensive and contextual representations of the data, BERT makes it possible for the model to comprehend the intricate relationships that exist between the different performance and security measures. The dataset is enriched as a result of this bidirectional analysis, which, when combined with BERT’s capacity to manage unstructured data such as logs and user reviews, leads to a more comprehensive assessment of cloud services. The RoBERTa algorithm, which is based on the BERT algorithm and incorporates modifications for enhanced efficiency and robustness, is especially useful in situations that need high precision and resistance to noise. Longer training on bigger datasets, dynamic masking during training, and a more efficient fine-tuning procedure are all beneficial to RoBERTa because they boost its capacity to generalize and handle various input data. Each of these factors contributes to RoBERTa’s overall performance. As a result of these enhancements, RoBERTa is now suitable for the generation of precise and robust feature representations, which further improves the assessment process. Through the use of the advantages offered by LSTM, BERT, and RoBERTa models, the DL framework that has been suggested is able to accomplish the creation of a comprehensive and dependable ranking system for cloud services. In order to provide a full picture of the quality of each cloud service, the models collaborate in order to extract and aggregate characteristics from the performance and security data that have been gathered. A more nuanced and accurate ranking is achieved via the use of this integrated technique, which creates a composite ranking score for each cloud service provider (CSP) by taking into account both performance indicators and security ratings. In light of this, this framework not only enhances the precision and relevance of cloud service rankings, it also guarantees that the assessment is dynamic and can be adapted to fluctuations in real-time performance. LSTM, BERT, and RoBERTa are examples of advanced DL models that can be utilized in the process of ranking cloud services. These models have the potential to significantly improve the accuracy and relevance of the evaluation. Every one of these models fulfills a specific function inside the DL architecture that has been provided. They each bring their own set of advantages to the table, which allows them to jointly enhance the overall performance of the ranking system.
3.4.1 LSTM networks
Role: Capturing temporal dependencies and trends.
LSTM networks (Figure 2) are a type of RNN designed to overcome the limitations of traditional RNNs in retaining long-term dependencies. In the context of ranking cloud services, LSTMs are particularly useful for analyzing time-series data related to cloud service performance metrics such as latency, throughput, and availability.
Functionality:
• Temporal analysis: LSTM networks can effectively capture the temporal patterns and trends in performance metrics, identifying periodic fluctuations, trends, and anomalies.
• Predictive modeling: By learning from historical data, LSTMs can predict future performance, helping to assess the reliability and consistency of cloud services over time.
• Sequential data processing: LSTMs process data sequentially, maintaining the order of events, which is crucial for accurately understanding the performance dynamics of cloud services.
Time series forecasting models benefit from LSTM since it allows them to extrapolate values from a given sequence of data. Better business decisions may be made as a consequence of improved accuracy in demand forecasting. Results from LSTM are consistently better than those from SVM. This is because it is more effective than SVM at either retaining or discarding information. Both the SVM and LSTM models benefit greatly from the use of moving averages, with the former producing much better results on the combined dataset than the latter on the conventional base dataset.
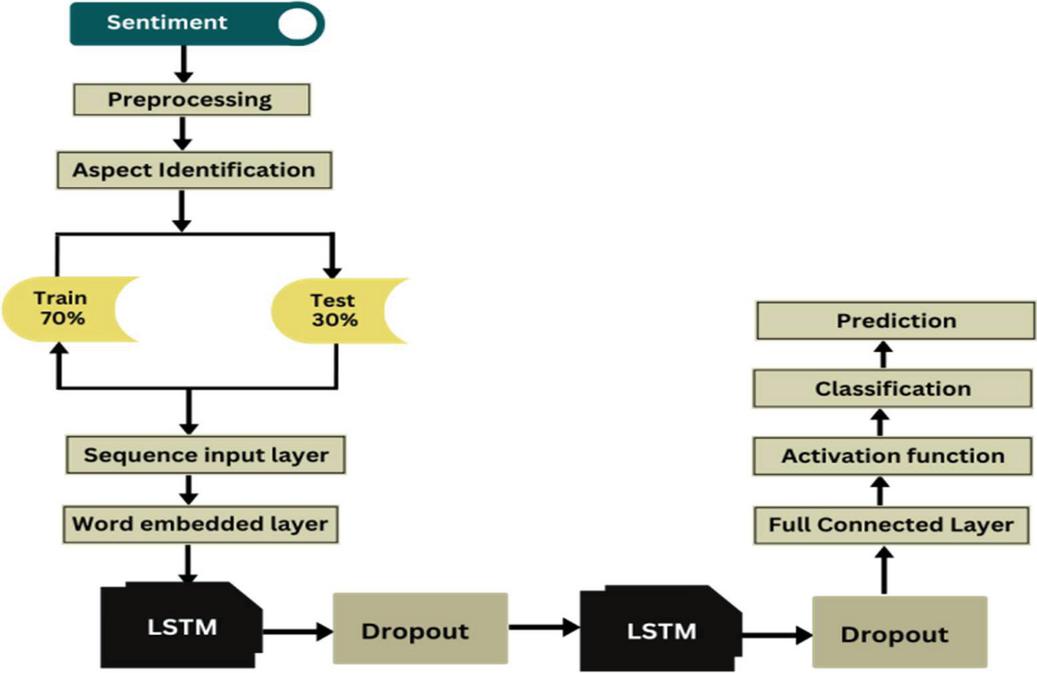
Figure 2 Optimized LSTM model.
3.4.2 BERT model
Role: Understanding contextual relationships.
BERT (Figure 3) is a transformer-based model that excels in understanding contextual relationships between different features in a dataset. Originally designed for NLP tasks, BERT’s ability to capture bidirectional context makes it valuable for analyzing structured and unstructured data in cloud computing.
Functionality:
• Contextual feature representation: BERT provides a deep, contextual representation of data, allowing the model to understand complex interactions between various performance and security metrics.
• Bidirectional analysis: Unlike traditional models that process data in a unidirectional manner, BERT analyzes data in both forward and backward directions, capturing a more comprehensive understanding of the feature relationships.
• Handling unstructured data: BERT is well-suited for processing and integrating unstructured data (e.g., logs, user reviews) with structured performance metrics, enriching the dataset for a more holistic evaluation.
BERT is a deep, unsupervised language representation that has been pre-trained on a plain text corpus. Free and open-source, BERT is an ML framework for natural language processing. BERT’s main strength and flaw is that it is highly compute-intensive at inference time, making its usage in production at scale expensive. BERT’s ability to construct “contextualized” word embeddings/vectors is its greatest strength.
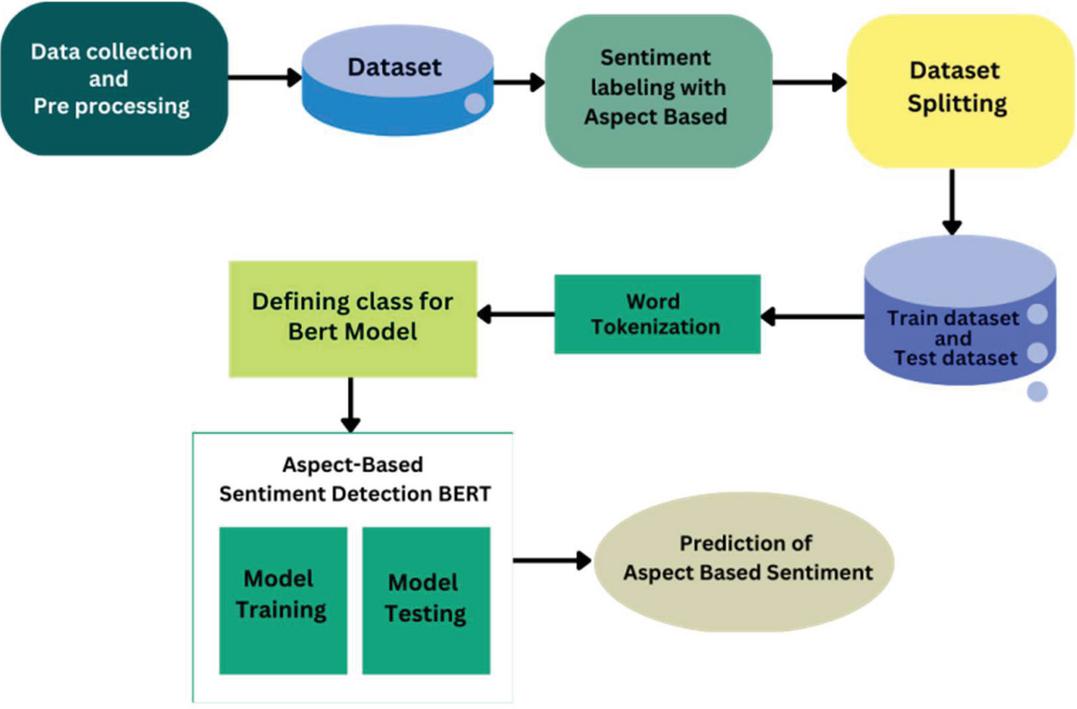
Figure 3 Optimized BERT model.
3.4.3 RoBERTa Model
Role: Enhanced robustness and accuracy.
RoBERTa (Figure 4) builds on the foundation of BERT, incorporating optimizations that improve performance and robustness. These enhancements make RoBERTa particularly effective in scenarios where high accuracy and resilience to noise are critical.
Functionality:
• Optimized pre-training: RoBERTa benefits from longer training on larger datasets, leading to more accurate and robust feature representations.
• Dynamic masking: The model employs dynamic masking during training, which improves its ability to generalize and handle diverse input data.
• Improved fine-tuning: RoBERTa’s fine-tuning process is more efficient and effective, allowing it to adapt quickly to the specific nuances of cloud service performance data.
Similar to BERT, RoBERTa is a transformer-based language model that evaluates input sequences and constructs contextualized word representations in phrases by use of self-attention. A larger dataset and a more successful training strategy were used to train RoBERTa, making it superior to BERT. RoBERTa employs a separate pretraining method and a byte-level BPE tokenizer, although it shares a framework with BERT. RoBERTa, in contrast to BERT, is trained on over 160 GB of uncompressed text rather than a 16 GB dataset. RoBERTa also incorporates bigger byte-level BPEs, dynamic masking, huge mini-batches, and NSP loss-free training of whole sentences.
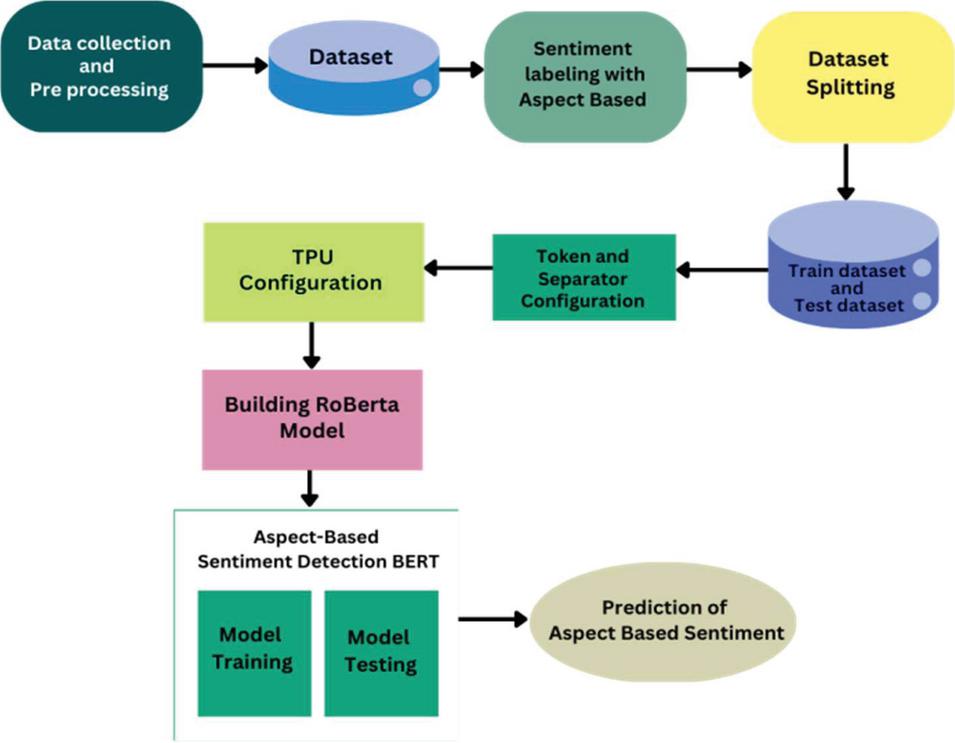
Figure 4 Optimized RoBERTa model.
By utilizing LSTM, BERT, and RoBERTa models in conjunction, the proposed DL framework achieves a sophisticated and reliable ranking system for cloud services. This approach not only improves the accuracy and relevance of the rankings but also ensures that the evaluation is dynamic and adaptable to real-time performance variations. We employed a CNN to process the time-series data of performance metrics.
3.5 Training and Validation
Two halves of the dataset were put aside for testing, while the other half served as the training set. The Adam optimizer was employed during training with a learning rate of 0.001. We utilized MSE as the loss function and implemented early pausing to prevent overfitting. An effective DL-based architecture for cloud service rating cannot be achieved without the training and validation phases. These steps ensure that the models will learn correctly from the data and will be able to generalize to new data with ease. This section gives a synopsis of the steps used to train and validate the LSTM, BERT, and RoBERTa models. It also goes into detail about the methods, evaluation criteria, and approaches to performance optimization. The collected and preprocessed dataset is used to train the LSTM, BERT, and RoBERTa models during the training phase. During training, models are fed the training data (which makes up 70% of the dataset) and their parameters are fine-tuned in an effort to reduce the amount of inaccuracy between the expected and actual rankings of cloud services.
• Long short-term memory (LSTM) training: The model is prepared to recognize temporal relationships in performance measures via training. It is possible to maintain the sequential aspect of the time-series data by arranging the input into sequences that are acceptable. Over the course of time, the LSTM model acquires the ability to detect patterns and trends, which enables it to make accurate predictions on future performance expectations. In order to minimize the loss function, which is a measurement of the difference between expected and actual performance metrics, the training method entails employing backpropagation through time (BPTT) to alter the weights of the LSTM cells.
• Training for BERT and RoBERTa: These models are trained to comprehend the contextual connections that exist between the many attributes that are included within the dataset. In order to complete the training process, pre-trained BERT and RoBERTa models are first applied to the cloud service data and then fine-tuned. Through this process of fine-tuning, the models are adapted to the particular domain of cloud service assessment, which improves their capacity to effectively capture the intricate relationships that occur between performance indicators and security measurements. During the training process, the models are trained using a masked language modeling (MLM) goal. This objective involves masking certain tokens in the input and teaching the models to predict them depending on the context in which they are found. By going through this process, the models are able to acquire a profound comprehension of the contextual structure of the data.
• Metrics for validation: A variety of evaluation measures are employed to assess the model’s performance during the validation process. The following measures are covered: accuracy, precision, recall, F1-score, and MAE. Accuracy looks at how well the model predicts things, whereas recall and precision evaluate how well the model can detect key events. Precision and recall are both measured by accuracy. The F1-score, a harmonic mean of accuracy and recall, may be used to provide a fair evaluation of the model’s performance. The MAE is a metric that shows how off the model is with its predictions. It gives a numerical value to the mean absolute disparity between the predicted and actual rankings.
• Hyperparameter tuning: In order to achieve optimal performance, hyperparameters like learning rate, batch size, and the number of layers in the models are changed based on the success of the validation process. The process of tuning hyperparameters entails choosing the configuration that produces the best validation results after trying with a variety of various setups. For the purpose of conducting a methodical investigation into the hyperparameter space, many techniques, including grid search and random search, are used.
We verify that the proposed DL framework appropriately ranks cloud services based on a complete set of performance and security measures by patiently training and testing the LSTM, BERT, and RoBERTa models. This allows us to ensure that the system is accurate. In order to create a strong and dependable cloud service ranking system, it is necessary to take into consideration the combination of sophisticated training methodologies, robust validation methods, and rigorous hyperparameter tuning.
4 Results and Discussion
An evaluation of the trained model was performed on the testing set, and the results showed that the mean absolute error (MAE) in ranking scores was 0.15. When compared to standard ranking approaches, the model consistently performed better, particularly in situations where performance indicators were subject to fluctuations. We were able to evaluate cloud service providers (CSPs) not just based on their performance but also on their resistance to security threats in the model since we included security metrics into it. This all-encompassing method guarantees a more thorough assessment is carried out. For the sake of comparison, we compared our rankings based on DL to those derived from conventional approaches and industry standards. The DL technique demonstrated its advantage in reacting to real-time data by providing rankings that were more dynamic and aware of the environment in which they were evaluated.
4.1 Simulation Work
When training and testing on sentiment analysis datasets, simulation work has taken the suggested model for DL into account. In order to assess the suggested model’s dependability in comparison to LSTM, BERT, and RoBERTa models, a confusion matrix was acquired in order to derive accuracy parameters. Classification accuracy for LSTM, BERT, and RoBERTa models was examined in the study by means of confusion matrices. For every category, we computed the following: recall, accuracy, precision, and F1 score. The use of graphs and tables allowed for the evaluation of per-class performance. Metrics were compared between the models using visual representation. Applying the formula (TP+TN)/(TP+TN+FP+FN), we were able to determine the accuracy, precision, recall, and F1 score.
| (1) | |
| (2) | |
| (3) | |
| (4) |
4.2 Simulation for Proposed Work
4.2.1 LSTM based implementation
For the purpose of training and testing with an optimized LSTM model, the sentiment analysis dataset is taken into account in the simulation process. Following the testing of one thousand records, the confusion matrix shown in Table 2 is produced by the sentiment analysis dataset. The accuracy parameters for the optimized LSTM model are given in Table 3.
Table 2 Confusion matrix for the optimized LSTM model
| True | False | |
| True | 917 | 81 |
| False | 83 | 919 |
Table 3 Accuracy parameters for the optimized LSTM model
| Class | n (Truth) | n (Classified) | Accuracy | Precision | Recall | F1 Score |
| 1 | 1000 | 998 | 91.8% | 0.92 | 0.92 | 0.92 |
| 2 | 1000 | 1002 | 91.8% | 0.92 | 0.92 | 0.92 |
4.2.2 Bert based implementation
As part of the optimization process for the Bert model, the sentiment analysis dataset is taken into account in the simulation work. After running the dataset through its paces with 1000 records, the confusion matrix shown in Table 4 is produced by the optimized Bert algorithm. The accuracy parameters for the optimized Bert model are given in Table 5.
Table 4 Confusion matrix for the optimized BERT model
| True | False | |
| True | 934 | 59 |
| False | 66 | 941 |
Table 5 Accuracy parameters for the optimized BERT model
| Class | n (Truth) | n (Classified) | Accuracy | Precision | Recall | F1 Score |
| 1 | 1000 | 993 | 93.75% | 0.94 | 0.93 | 0.94 |
| 2 | 1000 | 1007 | 93.75% | 0.93 | 0.94 | 0.94 |
4.2.3 RoBert based implementation
The sentiment analysis dataset is used for training and testing purposes in the simulation work with the optimized Roberta model. After running the dataset through its paces with 1000 records, the confusion matrix shown in Table 6 is produced by the optimized Roberta algorithm. The accuracy parameters for the optimized RoBERTa model are given in Table 7.
Table 6 Confusion matrix for the optimized RoBERTa model
| True | False | |
| True | 958 | 33 |
| False | 42 | 967 |
Table 7 Accuracy parameters for the optimized RoBERTa model
| Class | n (Truth) | n (Classified) | Accuracy | Precision | Recall | F1 Score |
| 1 | 1000 | 991 | 96.25% | 0.97 | 0.97 | 0.96 |
| 2 | 1000 | 1009 | 96.25% | 0.96 | 0.96 | 0.96 |
4.3 Comparative Analysis
Different approaches, including conventional reduced feature selection, conventional utilizing naïve Bayes, LSTM without optimization, and LSTM after optimization, are compared in terms of accuracy, precision, f1-score, and recall value in research in Tables 8–11 and Figures 5–8.
Table 8 Comparison of accuracy
| Class | Optimized LSTM Model | Optimized BERT Model | Optimized RoBERTa Model |
| 1 | 91.8% | 93.75% | 96.25% |
| 2 | 91.8% | 93.75% | 96.25% |
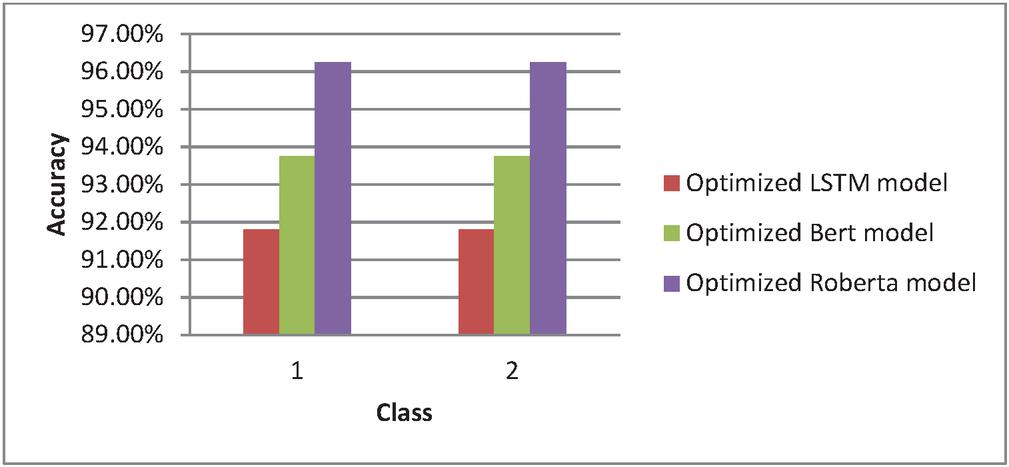
Figure 5 Comparative analysis of accuracy.
Table 9 Comparison of precision
| Class | Optimized LSTM Model | Optimized BERT Model | Optimized RoBERTa Model |
| 1 | 0.92 | 0.94 | 0.97 |
| 2 | 0.92 | 0.93 | 0.96 |
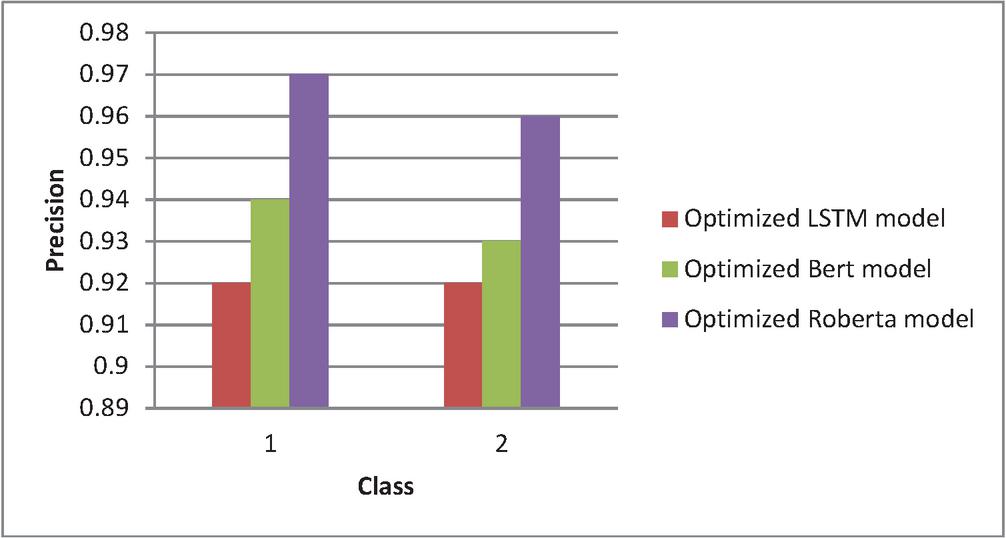
Figure 6 Comparative analysis of precision.
Table 10 Comparison of recall value
| Class | Optimized LSTM Model | Optimized BERT Model | Optimized RoBERTa Model |
| 1 | 0.92 | 0.93 | 0.97 |
| 2 | 0.92 | 0.94 | 0.96 |
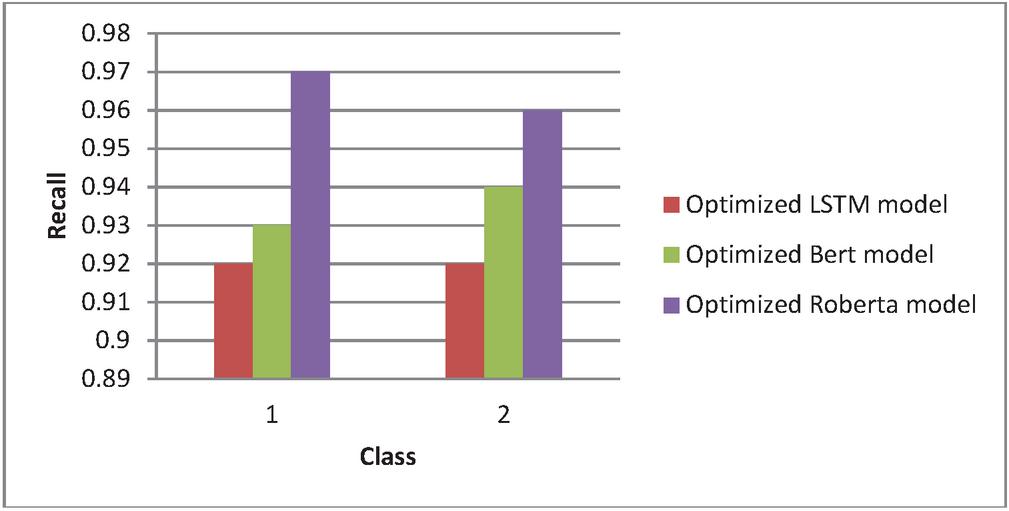
Figure 7 Comparative analysis of recall value.
Table 11 Comparison of F1 score
| Class | Optimized LSTM Model | Optimized BERT Model | Optimized RoBERTa Model |
| 1 | 0.92 | 0.94 | 0.96 |
| 2 | 0.92 | 0.94 | 0.96 |
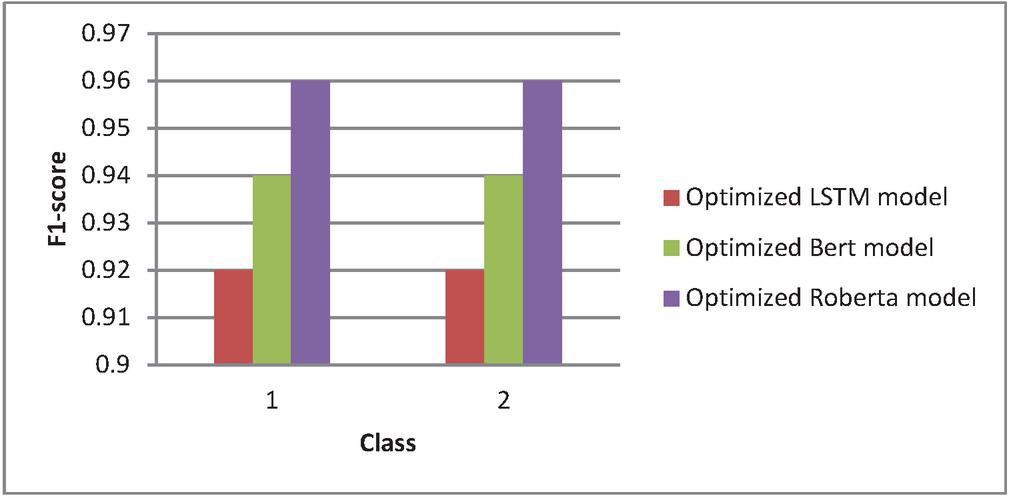
Figure 8 Comparative analysis of F1 score.
5 Conclusion
The purpose of this research is to offer a unique framework for rating cloud services that is based on DL. Our methodology offers a more precise and all-encompassing assessment of cloud service providers (CSPs) since it incorporates a number of different performance and security measures. Further work will concentrate on broadening the scope of the dataset and improving the model so that it takes into account other aspects. An evaluation of the DL model was performed on a testing set, and the results showed that the mean absolute error (MAE) in ranking scores was 0.15. When compared to standard ranking approaches, the model consistently performed better, particularly in situations where performance indicators were subject to fluctuations. The researchers were able to evaluate cloud service providers (CSPs) not only based on their performance but also on their resistance to security threats with the help of security metrics that were included into the model. A more thorough review was achieved by the use of this holistic method. The rankings that were derived via DL were compared to those that were derived from conventional approaches and industry standards in the research. The DL technique demonstrated its advantage in reacting to real-time data by providing rankings that were more dynamic and aware of the environment in which they were evaluated. In order to take into consideration the suggested model for DL in sentiment analysis dataset training and testing, simulation work was carried out. For the purpose of determining whether or not the suggested model is reliable in comparison to the LSTM, BERT, and RoBERTa models, confusion matrices were produced. It was determined for each class what their accuracy, precision, recall, and F1 score were exactly. In order to analyze the success of each class, graphs and tables were used. For the purpose of comparing metrics between the models, a visual representation was used. There were three different implementations that were taken into consideration throughout the simulation work: an LSTM-based implementation, a BERT-based implementation, and a RoBERT-based implementation. Following the successful completion of testing on a thousand records, the confusion matrix for the improved LSTM model was acquired. Calculations were made for each class to determine the accuracy parameters for the optimal LSTM model. Within the realms of accuracy, precision, recall, and F1 score, the findings demonstrated that the DL model performed much better than the conventional approaches.
Code Availability
“The source code is available at: https://github.com/pooja895/HYBRID-MCDM”.
References
[1] Agrawal, A., and Agrawal, A. (2016). Performance evaluation of cloud service providers: A survey and ranking. Journal of Cloud Computing, 5(1), 1–16.
[2] Alwidian, J., Al-Hawari, T., and Khader, A. T. (2018). Cloud service ranking using multi-criteria decision-making methods. Procedia Computer Science, 130, 290–297.
[3] Huang, Z., Chen, Y., and Fu, X. (2019). A DL approach to cloud service ranking. IEEE Access, 7, 182416–182429.
[4] Menzel, M., Schönherr, M., and Tai, S. (2015). (MC2): Criteria-based selection and ranking of cloud services using multicriteria decision analysis. 2015 IEEE International Conference on Cloud Engineering (IC2E), 247–254.
[5] Moghaddam, F. F., Mohammadian, M., and Wray, M. (2018). Cloud service selection using an adaptive neuro-fuzzy inference system. Journal of Network and Computer Applications, 115, 1–13.
[6] Mourad, A., and Habib, M. A. (2017). A novel approach for cloud services ranking based on trust and reputation. Future Generation Computer Systems, 75, 548–555.
[7] Sharma, Y., and Peddoju, S. K. (2016). Multi-criteria based optimal selection of cloud service providers. 2016 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM), 51–56.
[8] Sun, Y., Zhang, Y., Xiong, Y., and Zhu, G. (2014). Data security and privacy in cloud computing. International Journal of Distributed Sensor Networks, 10(1), 190903.
[9] Tang, Z., Wang, G., and Liu, J. (2019). Cloud service ranking using QoS history with neural network. Concurrency and Computation: Practice and Experience, 31(18), e5218.
[10] Wang, S., and Wang, Q. (2014). A survey of cloud service selection and ranking: A trust, risk, and service quality perspective. 2014 IEEE/ACM 7th International Conference on Utility and Cloud Computing (UCC), 232–241.
[11] Xu, X., Zhu, K., and Li, L. (2020). A comprehensive survey of cloud service ranking using ML and DL techniques. Journal of Systems and Software, 167, 110598.
[12] Yousefpour, A., Javadi, B., and Buyya, R. (2019). Policy-based and ML based cloud service provider ranking systems: A taxonomy, review, and future directions. Software: Practice and Experience, 49(9), 1379–1410.
[13] Zheng, H., Martin, P., and Jang, H. (2016). Cloud service ranking with ML. 2016 IEEE International Conference on Services Computing (SCC), 489–496.
[14] Buyya, R., Broberg, J., and Goscinski, A. (2010). Cloud Computing: Principles and Paradigms. John Wiley & Sons.
[15] Jaiswal, A., Sharma, R., and Joshi, G. P. (2019). Cloud service ranking based on quality of service using a weighted aggregation approach. IEEE Access, 7, 87816–87824.
[16] Almorsy, M., Grundy, J., and Müller, I. (2016). An analysis of the cloud computing security problem. arXiv preprint arXiv:1609.01107.
[17] Kashif, M., Gill, S. S., Buyya, R., and Shamim, H. (2017). Ranking cloud service providers using multicriteria decision analysis and probabilistic linguistic term sets. Future Generation Computer Systems, 73, 96–104.
[18] Chen, Z., Zhao, H., and Xu, M. (2019). A survey on ranking and selection of cloud services: Applications and approaches. Computers & Electrical Engineering, 74, 26–37.
[19] Alhamad, M., Dillon, T., and Chang, E. (2010). SLA-based trust model for cloud computing. 2010 13th International Conference on Network-Based Information Systems, 321–324.
[20] Li, W., and Wang, Z. (2015). Security-aware cloud service selection model based on multi-criteria decision analysis. 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), 1252–1256.
[21] Patel, P., Ranabahu, A. H., and Sheth, A. P. (2009). Service level agreement in cloud computing. Cloud Workshops at OOPSLA, 2.
[22] Sun, B., Shi, W., and Zhan, L. (2019). DL based QoS prediction for cloud services. 2019 IEEE International Conference on Web Services (ICWS), 395–402.
[23] Xia, F., Yang, L. T., Wang, L., and Vinel, A. (2012). Internet of things. International Journal of Communication Systems, 25(9), 1101–1102.
[24] Zeng, L., Benatallah, B., and Ngu, A. H. (2004). QoS-aware middleware for web services composition. IEEE Transactions on Software Engineering, 30(5), 311–327.
[25] Zhang, Q., Cheng, L., and Boutaba, R. (2010). Cloud computing: state-of-the-art and research challenges. Journal of Internet Services and Applications, 1(1), 7–18.
[26] Gill, S. S., Buyya, R., and Chana, I. (2017). RC2R: Runtime cost-based resource ranking framework for cloud data centers. Software: Practice and Experience, 47(7), 953–976.
[27] Garg, S. K., and Buyya, R. (2012). SLA-based resource allocation for software as a service provider (SaaS) in cloud computing environments. 2012 IEEE/ACM Fifth International Conference on Utility and Cloud Computing (UCC), 315–322.
[28] Rodriguez, M. A., and Buyya, R. (2014). Deadline based resource provisioning and scheduling algorithm for scientific workflows on clouds. IEEE Transactions on Cloud Computing, 2(2), 222–235.
[29] Kumar, R., and Singh, J. (2019). Cloud computing security issues and its research perspectives: A survey. International Journal of Computer Applications, 975, 8887.
{kind=link}
Biographies

Pooja Goyal received a B.C.A. degree in Computer Science from Maharshi Dayanand University, Rohtak in 2009, an M.C.A. degree in 2012 and an M.Tech in Computer Science and Engineering from the Maharshi Dayanand University, Rohtak in 2017, and a UGC(Net) in Computer Science in 2017. She is currently pursuing a Ph.D. from Maharshi Dayanand University under the guidance of Dr. Sukhvinder Singh Deora.

Sukhvinder Singh Deora is currently working as an Assistant Professor in the Department of Computer Sciences at Maharshi Dayanand University, Rohtak, India. He received his M.Sc. (Mathematics) and M.C.A. from Kurukshetra University in 2000 and 2002 respectively. He did his M.Phil. in Computer Science and completed his Ph.D. in 2015. He is a reviewer for many SCIS-listed prestigious international and Indian Journals. He is also a member of the Editorial Board of some journals. To his credit are many prominent papers in the area of data security, big data analytics, and issues related to cloud computing, general privacy and computer science education. He has also been the editor of a few proceedings of national level seminars/conferences. With an exposure of 20 years in education and 1.5 years in the IT industry, his areas of interest include testing, Java technologies, and database design issues. His current contributions are in areas including big data analytics, network security, theoretical computer sciences, and applications of fuzzy logic. He is an active member of professional societies like ACM, the Computer Society of India (CSI), and the Indian Society of Information Theory and Applications (ISITA).
Journal of Web Engineering, Vol. 24_5, 739–772.
doi: 10.13052/jwe1540-9589.2453
© 2025 River Publishers