Enhancing Collaborative Filtering with Game Theory for Educational Recommendations: The Edu–CF–GT Approach
Rezoug Nachida*, Selma Benkessirat and Fatima Boumahdi
LRDSI Laboratory, Department of Computer Science, Faculty of Sciences, University of Blida 1, Blida, Algeria
E-mail: n_rezoug@esi.dz
*Corresponding Author
Received 24 August 2024; Accepted 08 January 2025
Abstract
In the field of education, the proliferation of e-learning platforms has considerably increased access to teaching material. However, this abundance of resources poses a serious challenge to learners in the form of information overload that hinders the learning process. To meet this challenge, effective mechanisms need to be put in place to guide learners towards resources that are tailored to their individual needs and preferences. Recommendation systems appear to be essential tools in this context, aiming to personalise the learning experience by offering targeted suggestions based on the user’s preferences.
This article presents EDU–CF–GT, a new educational recommendation model, as a solution to this challenge. Based on our generic CF–GT model, EDU–CF–GT is adapted to the complexities of the educational domain, improving learning efficiency by simplifying access to resources. Through evaluation on an educational dataset, EDU–CF–GT demonstrates significant improvements in recommendation relevance and learner satisfaction compared to existing models.
Keywords: Collaborative filtering, game theory, Shapley value, educational recommender system.
1 Introduction
The past few years have seen a significant increase in the number of online learning platforms. Although this has increased user access to various educational resources, it can lead to information overload. The primary issue was that learners find it difficult to explore different resources, like videos, educational courses, and documents, since they cannot find personalized resources that cater to their needs. The diversity in learning styles exacerbates this problem, which further makes it irritating and time-consuming to identify important resources. Recommendation systems play an important role as they customise educational resources based on user preferences, which can optimise their learning experience.
Even with abundant information, learning platforms need efficient systems to direct learners to the resources that are most appropriate for their individual needs. In this particular context, recommendation systems play an essential role. Their operation is based on the provision of personalised recommendations, tailored to the individual needs and interests of each learner, with the aim of personalising the educational experience. They aim to optimise the time spent searching for resources, thereby improving the efficiency and quality of learning by addressing the challenge of information overload.
The main objective of this research is to cope with the specific challenges of the education field by proposing an appropriate solution. Although the CF–GT model is recognised for its superior performance in terms of quality recommendation, offering personalised suggestions based on user preferences, its direct adaptation to the education domain requires adjustments due to the complexity of the characteristics specific to this sector. In order to solve the problem of inefficient learner searches, this article presents an evolution of the CF–GT model, called EDU–CF–GT.
This new approach, which is centred on the diversity of educational characteristics, seeks to improve learning efficiency and increase accessibility to education for all by streamlining resource access. To put it briefly, EDU–CF–GT creates a recommendation system that is adapted to the requirements of students, thereby directly addressing the difficulties brought about by the wealth of educational materials.This technique seeks to optimise the use of educational platforms by offering more accurate and tailored recommendations, thereby decreasing the amount of time spent seeking relevant resources.
2 Related Work
In the specialist literature on education, various recommendation models have been put forward with the aim of enriching the student learning process. One such model is EduRecomSys [5], which combines collaborative filtering (CF) with emotion detection techniques to suggest educational resources to users. The model is based on the preferences and interests of other users, as well as the user’s previously detected needs. EduRecomSys was evaluated in both qualitative and quantitative terms, with promising results. However, the work has one limitation: the test method is unreliable and the work has not been validated.
Another notable educational recommendation model is presented in [17], which proposes a multidimensional information model and genetic algorithm-based RS for learning resources. The system includes two key recommendation modules: a module that accounts for explicitly collected attributes and a preference matrix to control the learner’s interests regarding the explicit characteristics of learning resources in a multidimensional space, and a module that focuses on the attributes gathered tacitly and uses a genetic algorithm to mine these embedded attributes. The CF recommendation technique is used to derive both modules. Each module suggests a list of resources, and then a linear combination is used pertaining to CF by considering explicit characteristics and CF by considering implicit attributes, which are employed for the final recommendation. This system was evaluated, and the results showed that the proposed approach surpasses the precision pertaining to conventional algorithms, as well as moderate cold start and sparsity issues. However, the proposed recommendation procedure lacks the integration of knowledge of the learners in order to offer a customized recommendation as well as adequateness in terms of their educational level.
Another work was conducted in [15], where the authors built a framework to help students select appropriate courses based on their previously taken subjects and grades. The idea is to calculate the similarity between previously studied courses and current elective courses using course titles and descriptions. The work was manually evaluated, which does not prove its effectiveness.
Table 1 compares the work cited above [5, 17, 15] with our CF–GT model [1].
Table 1 Comparative analysis of recommendation models in educational and related contexts
| Criteria | Type of Model | Input Data | Evaluation | Key Strengths | Key Weaknesses |
| [5] | CF with emotion detection | User preferences, interests, and emotions | Qualitative and quantitative evaluation with promising results, but unreliable test method | Considers user emotions | Unreliable test method and lack of validation |
| [17] | Hybrid (CF and genetic algorithm) | User preferences, interests, and explicitly collected attributes | Quantitative evaluation with good results, but lack of integration of knowledge of learners | Combines multidimensional model with genetic algorithm | Does not consider learners’ educational level |
| [15] | CF | User previously taken subjects and grades | Manual evaluation, which does not prove its effectiveness | Simple and easy to implement | Manual evaluation |
| CF–GT [1] | CF with based user pre-selection using game theory) | generic data | Quantitative evaluation with good results, outperforming traditional CF and the comparison model | Improves accuracy and precision of recommendations through user clustering | The similarity function considers only one criterion, therefore it is not directly applicable to the educational domain |
Table 1 highlights the published studies that were conducted on educational recommendation systems and presented important limitations, such as inadequate validation, dependence on simple similarity functions, and an absence of personalization depending on the user preferences. The CF–GT model performs significantly during the task recommendation step; however, its design cannot be directly used for educational purposes, because it cannot handle multidimensional user data, like resource data, level, and learning preferences. For addressing these issues, the researchers have proposed the use of Edu–CF–GT, which is an adapted version of CF–GT. This model incorporates the complex and different characteristics of the educational environment.
The below-mentioned sections present an overview of the CF–GT model and describe how the Edu–CF–GT model improves personalized learning.
3 Overview of the CF–GT Algorithm
Many works [20, 25, 12] have adopted clustering as a similar user pre-selection step in the CF process. The CF–GT model extends this idea by using a novel clustering technique based on the Shapley value [6]. This clustering technique groups users together based on both their similarity to each other and their similarity to the cluster centre, resulting in more cohesive clusters than those produced by conventional clustering algorithms.
The CF–GT model has two steps:
• Create user communities: This step consists of grouping users into communities on the basis of their similarity, managed by the “SimilarUser” module. To do this, the algorithm iteratively assigns each user to the community with the highest Shapley value.
• Generate“Top-N” recommendations: The module responsible for this step is called “CFProcess”. It uses a CF algorithm to generate Top-N recommendations for each user. The CF algorithm is applied within each community of users, allowing the algorithm to take advantage of the fact that users in the same community are more likely to have similar preferences.
Figure 1 is a summary diagram of the CF–GT model.
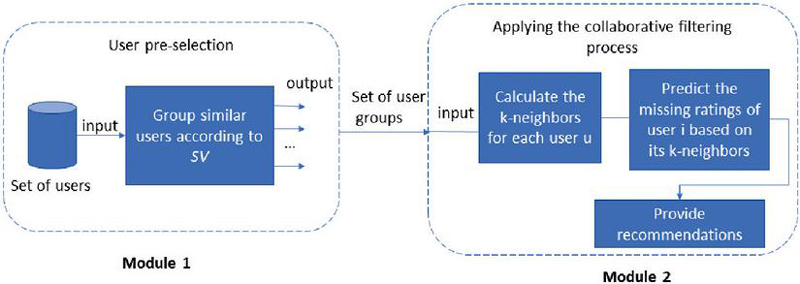
Figure 1 Overall diagram of the CF–GT model.
The input of the first module is a set of users }. Its output is a set G of similar user groups }.
The output of the first module would be the input of the second. The output of the latter is a set of recommendations for each user.
Indeed, CF–GT builds on the weaknesses of existing related work and has some remarkable features: unlike work that takes clustering as a pre-selection step, our approach takes into account the intrinsic notion of a cluster. The CF–GT model is designed as a generic approach and has been implemented as a prototype, which can be used in many application domains, including education.
For additional insights, please refer to our initial research endeavour [1]. All details and comprehensive information can be found in our inaugural work.
3.1 Validation of the CF–GT Model
In evaluating the CF–GT algorithm, we utilized the MovieLens100k dataset [13] and benchmarked its performance against conventional CF and k-means-based CF (). The rationale for selecting these algorithms lies in their fundamental nature and their historical effectiveness with the MovieLens dataset.
For accuracy assessment, we employed the mean absolute error (MAE) to measure the disparity between predicted and actual ratings. The CF–GT model was compared with other methods by varying neighbourhood sizes () and evaluated for precision and recall for different values of Top-N. Regardless of or , our CF–GT model consistently performed better than the other models in terms of MAE, precision, and recall. This steady performance highlights our model’s exceptional predictive power and suggestion quality.
3.2 Synthesis
In the field of education, recommending resources for learning is a significant difficulty. Even with the abundance of resources provided by educational platforms, students may find it difficult to identify content that specifically caters to their requirements and may become overwhelmed by the variety available. Since recommender systems can match learners with the most relevant materials based on their interests and learning needs, they present a viable solution to this challenge.
In a generic recommendation setting, our CF–GT model has demonstrated its efficacy by offering accurate and tailored recommendations that satisfy users’ requirements. Building on this achievement, we decided to investigate its particular application to the field of education. Our objective is not limited to testing the CF–GT model in this context, but rather to provide an adapted solution, called Edu-CF–GT.
Our contribution resides in enriching the CF–GT model to satisfy the specific requirements of recommending educational content through the development of the Edu-CF–GT algorithm. This adaptation represents a significant advance in the field of educational recommendation systems, exploiting the advantages of our CF–GT model and adapting it to better meet the requirements of the educational context.
In the following, we will describe the details of the Edu-CF–Gt model.
4 Implementation of the Extended Method Edu-CF–GT
The efficiency and success of the CF–GT [1] model in a generic setting motivates us to exploit its potential to address the challenges of educational recommender systems.
The CF–GT model considers a single feature to measure the similarity between users and predict recommendations. However, the educational domain requires multiple features (learner profile, learning preference, resources consulted, etc.). An adaptation at the level of the similarity function is essential to exploit it in an educational context. The adapted model is named Edu-CF–GT.
The Edu-CF–GT model comprises two modules: “InfoCollect” and “CF-GTProcess”. The “InfoCollect” module collects student data. The “CF-GTProcess” module is responsible for making recommendations based on the CF–GT model and input data. Figure 2 illustrates the architecture of the model.
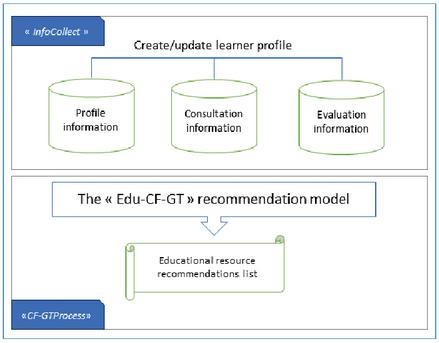
Figure 2 Overall diagram of the Edu-CF–GT model.
4.1 “InfoCollect” Module Details
The first module is used to collect information about the learners. Each user of the learning system is described by information that characterises their profile. Users can consult the learning resources and give each resource a rating to assess its quality.
The recommendation system uses this information to generate personalised recommendations for each learner in the learning environment.
Once logged into the learning environment, learners prefer to get appropriate recommendations for their learning needs without having to spend hours consulting the thousands of resources loaded into the system.
The learning environment retrieves this information each time a learner performs a new action (consults a new resource or assigns a grade to a resource) and updates their profile.
4.2 “CF-GTProcess” Module Details
The second module is used for recommendations, from the selection of similar users to the generation of learning resources. The first module prepares the data required for the second module to carry out its task, which is based on the CF–GT model [1]. This module goes through the following steps:
• Retrieve the output data from the “InfoCollect” module.
• Calculate the distance between the current user and the other users following .
• Application of the FC process on the group obtained:
Calculates the similarity between pairs of users such that .
Prediction of the missing evaluations of the current user.
Generation of Top-N recommendations.
5 Adaptation of the CF–GT Model for Education
The adaptation of the CF–GT model for education consists primarily of adapting the similarity function used.
For the CF–GT model, we relied solely on the votes assigned by users to items. To select similar users, the Edu-CF–GT model uses several criteria, namely: the learner’s profile, information about the consultation of a pedagogical resource, and the evaluation of pedagogical resources.
In what follows, we will detail the similarity function used as well as the dataset used.
5.1 Formal Basis of the Edu-CF–GT Model
The purpose of this section is to define the basic concepts that allow the calculation of missing ratings for the recommendation of educational resources. These concepts, presented in Table 2, are related to the user profile, the consultation and evaluation information (visit and evaluation of educational resources).
Table 2 Formal basis of the model
| Element | Description |
| All users of the virtual learning environment. | |
| All resources consulted by . | |
| All resources evaluated by . | |
| All the educational fields present in the system. | |
| Used to find out which resources have been consulted by user . This function is equal to 1 if user has consulted resource and 0 otherwise. | |
| Represents the rating assigned by user to resource . | |
| : represents the set of resources co-assessed by users and . | |
| The user profile. | |
| val is the value of the characteristic of the user It represents the set of characteristic/value pairs which define the user profile . |
5.2 Similarity Function Adaptation
In the literature, most CF recommendation models use the Pearson correlation coefficient to measure user similarity. This coefficient measures the linear correlation between two variables. In recommendation systems, this coefficient is used to measure the dependency between two vectors of resource ratings belonging to two users. These works focus primarily on the rating of resources to calculate user similarity. This was the case for our generic model, we only used the ratings of items to calculate user similarity.
The Edu-CF–GT model is based on three criteria to measure user similarity: user profile, information on the consultation and evaluation of educational resources. User similarity includes:
• the similarity between the user profiles of and .
• the similarity between and in terms of resources consulted.
• the similarity between u and v in terms of educational resources evaluated.
From the three similarities, we calculate the similarity between users and , denoted by . is given by:
| (1) |
For each similarity calculated, we used:
• Jaccard [21] to measure , as follows:
| (2) |
• Jaccard [21] to measure the similarity in terms of resources consulted by two users and . Equation (3) formalizes . This measure is relative to the number of resources co-consulted by the two users and the total number of resources visited by the two users.
| (3) |
When the two users and have not yet consulted any resources, this formula is not applied, as the union is null. In this case, is equal to zero.
• Pearson correlation [19] coefficient to calculate the similarity in terms of evaluation SimEval(u,v).
In the execution of the Edu-CF–GT model, the similarity function of the CF–GT model is as follows:
| (4) |
6 Validation of the Edu-CF–GT Model
To validate the Edu-CF–GT model, we carried out an offline analysis using an dataset that we created. This simulation helped us to test our proposal and evaluate its effectiveness.
6.1 Dataset Generation
Due to the lack of publicly available datasets in the field of education [8] and the absence of computerized learning systems in our universities, many researchers in the field of education create their own datasets to meet their specific needs. To address the lack of data, we drew inspiration from previous work [4] to generate a synthetic dataset called “EduTest”.
In this study, the researchers ensured the significance of their designed synthetic dataset by carefully designing the dataset so that it highlighted the important characteristics of the standard educational environment, like resource types, different learner profiles, and interaction patterns. The above characteristics were derived based on the results presented in the published studies and the general trends related to user behaviour studies and educational systems. After that, the researchers established a synthetic dataset closer to the actual conditions.
This dataset provides information primarily on (1) the learner’s profiles such as age, preferences, etc., (2) the information on the consultation of a resource or not and (3) the values of evaluation that users assign to educational resources.
Table 3 summarises the learner characteristics.
Table 3 Learner profile composition
| Information | Value |
| Profile information | Name |
| Level: licence or master | |
| Specialization: ISIL, SIQ, IL, SIR, SSI or TAL | |
| Preferred language (Java, C++, C#, Python) | |
| Programming experience (1-5) | |
| Learning style (book, video) | |
| Evaluation information | Scale of 1 to 5 |
| Consultation information | 1 indicates that the learner has already consulted the resource, while 0 indicates otherwise |
EduTest consists of learners and educational resources. The educational resources were accessed times. The database contains ratings.
6.2 Evaluation Protocol
We detail here the evaluation process used to assess the recommendations of our Edu-CF–GT model compared to two basic algorithms: conventional (CF) [23] and -means-based CF (-means-CF) [9]. The choice of these algorithms is based on their established relevance in the field of recommendation systems. The CF is a widely used reference [10], while -means-CF shares conceptual similarities with our approach, utilizing clustering as a fundamental component. By integrating these approaches into our evaluation, we obtain a comprehensive overview of the performance of our Edu-CF–GT model compared to established and sophisticated recommendation methods.
We evaluated our model based on predicted ratings, measuring the mean absolute error (MAE) [3] (which is the most commonly used measure to evaluate recommendation model predictions, being effective and easy to interpret), and the relevance of the provided recommendations by calculating precision [11] (to determine the probability that a recommended item is relevant) and recall [11] (to determine the probability that a relevant item is recommended); these measures assess the frequency with which a recommendation system makes correct or incorrect decisions regarding the relevance of an item.
First, the recommendation dataset was split into training and test sets. Recommendation models are learned on the training set and evaluated on the test set. For example, we can use 80 of the data for training, while the remaining 20 is used for evaluation. The most commonly used evaluation protocols is five-fold cross-validation [24]. We adopted this protocol for evaluating our model, where four folds are used for training and the fifth is used for testing.
As a final step, the rating predictions provided by the system are evaluated in terms of accuracy and relevance. Finally, we sort the predicted ratings of the candidate items and recommend the Top-N items to the target user (the best items).
6.3 Experiments and Results
In this section, the results of the evaluation of our Edu-CF–GT approach are presented by carrying out various experiments. For each experiment carried out, we consider three values of the similarity threshold and which gives two, three and four groups of similar users respectively.
We recall that, as detailed in [1], the threshold is used to support the preselection of similar users, ensuring that: (1) Close users, who tend to have almost equal SVs, are assigned to the same group. (2)The starting point of each group is reasonably distant.
After various executions, we obtained thresholds that allowed us to produce two, three, and four groups of similar users, which constitutes a relevant and appropriate preselection step for our approach.
Below, we present the model experiments based on predicted ratings and the relevance of the provided recommendations.
1. Predicted ratings For the accuracy evaluation metrics, we measure the value of the MAE between the predicted and actual evaluations and compare it with the previously cited approaches. As in previous studies [16, 14, 1], we consider different numbers of neighbours for this evaluation and .
Figures 3, 4 and 5 show the prediction accuracy for different neighborhood sizes on the EduTest dataset.
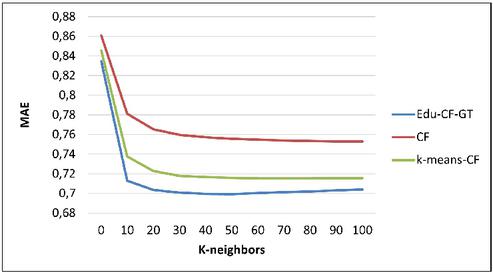
Figure 3 MAE for .
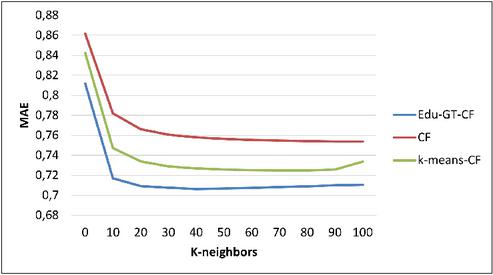
Figure 4 MAE for .
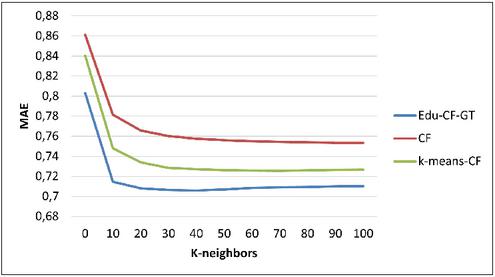
Figure 5 MAE for .
It can be seen that for the neighbourhood sizes considered, Edu-CF–GT achieves a remarkable improvement in prediction accuracy compared with the FC and k-means-CF algorithms. All methods give the most accurate predictions when the number of neighbours is around .
Without exception, Edu-CF–GT outperforms the test algorithms regardless of the number of neighbours.
The superiority of the proposed method can be explained by the fact that CF–GT exploits the SV solution concept to form a group of similar users as a preselection for the FC algorithm.
2. Relevance of recommendations
To determine the effectiveness of the system, we calculated precision (to determine the probability that a recommended item is relevant) and recall (to determine the probability that a relevant item is recommended).
With regard to the relevance of the recommendations provided, precision and recall were calculated on different numbers of Top-N. In our study, we consider and which means that we evaluate the method during the recommendation of Top-N items by the proposed recommendation system. Tables 4, 5 and 6 show the precision and recall values for the different Top-N with the EduTest dataset.
Table 4 Precision and recall for
| Edu-CF–GT | FC | K-means | ||||
| Top | Precision | Recall | Precision | Recall | Precision | Recall |
Table 5 Precision and recall for EduTest
| Edu-CF–GT | FC | K-means | ||||
| Top | Precision | Recall | Precision | Recall | Precision | Recall |
Table 6 Precision and recall for EduTest
| Edu-CF–GT | FC | K-means | ||||
| Top | Precision | Recall | Precision | Recall | Precision | Recall |
From these tables, we can see that for different Top-N, the precision and recall obtained by our Edu-CF–GT method are better than the evaluation methods considered.
7 Discussion
The proposed Edu-CF–GT approach is a promising solution for educational resource recommendation, outperforming baseline models on all evaluation metrics. The preselection steps of Edu-CF–GT offer a novel approach that takes into account intrinsic relationships within the group, thereby improving recommendation accuracy. Furthermore, evaluation of the approach using an educational dataset demonstrates its superiority over baseline models across all evaluation metrics. Detailed analysis of the approach reveals that integrating multiple learner characteristics enhances the selection of similar users, leading to more precise rating predictions and relevant recommendations.
By computing the average percentage improvement, we measured the performance of our Edu-CF–GT solution in terms of the MAE measure, as well as in comparison to the reference methods CF and K-means-CF. The outcomes demonstrate that Edu-CF–GT greatly enhances recall and precision. To be more exact, Edu-CF–GT performs 11.25 better than CF and 6.50 better than K-means-CF. Regarding recall, the corresponding gains are in comparison to CF and in comparison to K-means-CF. Moreover, Edu-CF–GT beats CF by and K-means-CF by in terms of MAE. These results confirm the effectiveness of Edu-CF–GT in recommending educational resources, underlining its ability to outperform traditional CF methods and their variants.
7.1 Potential Applications
For ensuring that the learners enjoy a more personalized learning experience, the Edu-CF–GT model could be incorporated into MOOCs and e-learning platforms. This integration would be implemented in 2 steps: The “InfoCollect” module and the “CF-GTProcess” module. The “InfoCollect” module collects user data, including their interaction with different learning resources (e.g., reading articles, viewing videos, or solving quizzes) and their correlation with these resources. This data is used as a basis for the recommendation procedure. On the other hand, the “CF-GTProcess” module implements the Edu-CF–GT model for examining the collected user data and making personalized recommendations depending on their preferences, profiles, and learning direction. The platforms that include these modules can adapt to the users’ needs, which, in turn, increases their engagement and improves their learning outcomes.
In summary, Edu-CF–GT is an effective solution to the problem of resource overload encountered by learners in e-learning and computer-based learning systems and, also, the proposed model is an optimisation of the generic CF–GT model by integrating several features with the user profile.
8 Conclusion and Future Work
The advent of online learning platforms has created a major challenge: information overload for learners. The diversity of educational resources and learning styles makes searching a tedious task. Recommender systems are crucial for guiding learners to suitable resources, optimising learning efficiency and reducing search frustration. Several recommender systems have been proposed in an educational context, however, there are still challenges regarding the relevance of the recommendations provided. The aim of this article was to propose an effective recommendation solution for the educational domain.
We began by giving a brief overview of existing work in the literature. The works discussed were synthesised and compared with the CF–GT model that we proposed in a generic framework [1].
After reviewing the state of the art, we briefly presented our generic CF–GT model. This recommendation model is based on the pre-selection of similar users according to a cooperative game model. The very satisfactory experimental results of our model, and the problems of relevance of recommendations experienced by educational systems, motivated us to exploit our CF–GT model for the benefit of education in order to propose a relevant solution. Although it is generic, proposing it in an educational context required additional effort. Its adaptation for the educational domain consists, in particular, in the adaptation of the similarity function used. The CF–GT model is based solely on a single feature to calculate the similarity between users, unlike the education domain, which is characterised by the diversity of features.
We then presented details of the proposed Edu-CF–GT solution and an experimental protocol. The Edu-CF–GT model is an adaptation of the CF–GT [1] model to the education domain. CF–GT [1] is a hybrid model that combines CF and a pre-selection step based on game theory. Edu-CF–GT extends CF–GT by integrating multiple learner characteristics into the similarity function.
We evaluated our model Edu-CF–GT on an educational dataset, Edu-Test. The experimental results significantly confirmed the improvement brought by our model compared to existing work. This improvement was particularly evident in the prediction of evaluations and the relevance of recommendations, thus meeting the requirements of the educational domain. The relevant recommendations suggested by our model help to optimise learners’ search time, thus having a positive impact on their learning process. These results constitute a significant and enriching contribution to a scientific article.
By proposing both a solution adapted to the educational domain and an improvement on the original CF–GT model through the integration of multiple features, our approach offers a relevant response to the challenges of recommending educational resources.
In the future, the researchers aim to design an educational platform called EduLearn that implements the proposed Edu-CF–GT model. This platform presents a real-world environment that would allow them to explore and test their approach. This platform would include several learning resources, like videos, books, and supporting materials offered by the instructors. The learners would have to make personalised accounts that would allow them to interact with the above resources (e.g., ratings, feedback). After logging into the platform, the Edu-CF–GT module analyses the learner’s profile and activities, and then recommends educational resources that would be specific to their interests and needs. This platform helps in validating the proposed model and offers an adaptive learning solution.
Although our approach shows promising results in recommending educational resources, there are interesting prospects for improving its robustness and applicability in various educational contexts. To this end, it would be wise to explore the use of a dataset more representative of the diversity of educational resources, enabling a broader generalization of the results. In addition, incorporating diversity into the recommendation process would help to ensure balanced exposure of learners to a varied range of resources, thus promoting their learning opportunities. Finally, to solve the cold-start challenge, further efforts could be made to develop adaptive mechanisms that provide accurate recommendations even for new users or items, taking advantage of techniques such as content based filtering and active learning.
Recognising that all work deserves to be perfected, we plan to explore further the application of deep learning to enhance the performance of educational recommendation systems. The proven success of deep learning in areas such as natural language processing and computer vision leads us to believe in its potential to significantly improve the accuracy and relevance of educational recommendations. This approach, which is geared towards continuous improvement, is a crucial prospect that could shape the future development of our research.
References
[1] Selma Benkessirat, Narhimene Boustia, and Rezoug Nachida. A new collaborative filtering approach based on game theory for recommendation systems. Journal of web engineering, 20(2):303–326, 2021.
[2] Selma Benkessirat, Narhimène Boustia, and Nachida Rezoug. Overview of recommendation systems. In Smart Education and e-Learning 2019, pages 357–372. Springer, 2019.
[3] FJOLLA Berisha. Quality of the predictions: mean absolute error, accuracy and coverage. Preprint (Sept. 2017). doi, 10, 2017.
[4] Lamia Berkani, Omar Nouali, and Azeddine Chikh. Recommandation personnalisée des ressources dans une communauté de pratique de e-learning. Une approche à base de filtrage hybride. INFORSID, pages 131–138, 2013.
[5] Maritza Bustos López, Giner Alor-Hernández, José Luis Sánchez-Cervantes, Mario Andrés Paredes-Valverde, and María del Pilar Salas-Zárate. Edurecomsys: an educational resource recommender system based on collaborative filtering and emotion detection. Interacting with Computers, 32(4):407–432, 2020.
[6] Georgios Chalkiadakis, Edith Elkind, and Michael Wooldridge. Computational aspects of cooperative game theory. Springer Nature, 2022.
[7] Felipe Leite da Silva, Bruna Kin Slodkowski, Ketia Kellen Araújo da Silva, and Sílvio César Cazella. A systematic literature review on educational recommender systems for teaching and learning: research trends, limitations and opportunities. Education and Information Technologies, 28(3):3289–3328, 2023.
[8] Hendrik Drachsler, Toine Bogers, Riina Vuorikari, Katrien Verbert, Erik Duval, Nikos Manouselis, Guenter Beham, Stephanie Lindstaedt, Hermann Stern, Martin Friedrich, et al. Issues and considerations regarding sharable data sets for recommender systems in technology enhanced learning. Procedia Computer Science, 1(2):2849–2858, 2010.
[9] Hendrik Drachsler, Toine Bogers, Riina Vuorikari, Katrien Verbert, Erik Duval, Nikos Manouselis, Guenter Beham, Stephanie Lindstaedt, Hermann Stern, Martin Friedrich, et al. Issues and considerations regarding sharable data sets for recommender systems in technology enhanced learning. Procedia Computer Science, 1(2):2849–2858, 2010.
[10] Michael D Ekstrand, John T Riedl, Joseph A Konstan, et al. Collaborative filtering recommender systems. Foundations and Trends® in Human–Computer Interaction, 4(2):81–173, 2011.
[11] Zeshan Fayyaz, Mahsa Ebrahimian, Dina Nawara, Ahmed Ibrahim, and Rasha Kashef. Recommendation systems: Algorithms, challenges, metrics, and business opportunities. applied sciences, 10(21):7748, 2020.
[12] Utkarsh Gupta and Nagamma Patil. Recommender system based on hierarchical clustering algorithm chameleon. In 2015 IEEE International advance computing conference (IACC), pages 1006–1010. IEEE, 2015.
[13] F Maxwell Harper and Joseph A Konstan. The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis), 5(4):1–19, 2015.
[14] Haifeng Liu, Zheng Hu, Ahmad Mian, Hui Tian, and Xuzhen Zhu. A new user similarity model to improve the accuracy of collaborative filtering. Knowledge-based systems, 56:156–166, 2014.
[15] J Naren, M Zarina Banu, and S Lohavani. Recommendation system for students’ course selection. In Smart Systems and IoT: Innovations in Computing: Proceeding of SSIC 2019, pages 825–834. Springer, 2020.
[16] Mehrbakhsh Nilashi, Othman Ibrahim, and Karamollah Bagherifard. A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques. Expert Systems with Applications, 92:507–520, 2018.
[17] Mojtaba Salehi, Mohammad Pourzaferani, and Seyed Amir Razavi. Hybrid attribute-based recommender system for learning material using genetic algorithm and a multidimensional information model. Egyptian Informatics Journal, 14(1):67–78, 2013.
[18] Benkessirat Selma, Boustia Narhimène, and Rezoug Nachida. Deep learning for recommender systems: Literature review and perspectives. In 2021 International Conference on Recent Advances in Mathematics and Informatics (ICRAMI), pages 1–7. IEEE, 2021.
[19] Leily Sheugh and Sasan H Alizadeh. A note on pearson correlation coefficient as a metric of similarity in recommender system. In 2015 AI & Robotics (IRANOPEN), pages 1–6. IEEE, 2015.
[20] Ngo Tung Son, Dao Huy Dat, Nguyen Quang Trung, and Bui Ngoc Anh. Combination of dimensionality reduction and user clustering for collaborative-filtering. In Proceedings of the 2017 International Conference on Computer Science and Artificial Intelligence, pages 125–130, 2017.
[21] Shalini Christabel Stephen, Hong Xie, and Shri Rai. Measures of similarity in memory-based collaborative filtering recommender system: A comparison. In Proceedings of the 4th multidisciplinary international social networks conference, pages 1–8, 2017.
[22] Xiaoyuan Su and Taghi M Khoshgoftaar. A survey of collaborative filtering techniques. Advances in artificial intelligence, 2009, 2009.
[23] Andreas Toscher and Michael Jahrer. Collaborative filtering applied to educational data mining. KDD cup, 2010.
[24] Fajie Yuan, Guibing Guo, Joemon M Jose, Long Chen, Haitao Yu, and Weinan Zhang. Lambdafm: Learning optimal ranking with factorization machines using lambda surrogates. In Proceedings of the 25th ACM international on conference on information and knowledge management, pages 227–236, 2016.
[25] Hafed Zarzour, Ziad Al-Sharif, Mahmoud Al-Ayyoub, and Yaser Jararweh. A new collaborative filtering recommendation algorithm based on dimensionality reduction and clustering techniques. In 2018 9th international conference on information and communication systems (ICICS), pages 102–106. IEEE, 2018.
Biographies

Rezoug Nachida is a senior lecturer in the Computer Science Department at Saad Dahlab University in Algeria. Her research interests primarily focus on data warehousing solutions, data mining and OLAP systems, decision support systems, decision-making, context-aware recommender systems, deep learning, and educational recommender systems. Dr. Rezoug has co-authored numerous papers presented at international conferences and published in journals. She completed her Ph.D. in Computer Science at the Superior School of Computer Science in Algeria in 2016.

Selma Benkessirat holds a Ph.D. in Computer Science from the Computer Sciences Department at Saad Dahlab University, Blida, Algeria. Her research focuses on machine learning, deep learning, recommender systems, and game theory.

Fatima Boumahdi obtained her B.Sc. and Master’s degrees in computer science from Saad Dahlab University, Blida1, Algeria in 2006. She earned her Ph.D. in computer science from the National School of Computer Science (ESI), Algiers, Algeria in 2015. Since 2021 she has served as an associate professor in the Faculty of Sciences at Blida1 University, Algeria. She has published numerous works in the areas of decision support systems, web information systems, and service-oriented architecture. Her current research interests include natural language processing, sentiment analysis, deep learning, artificial intelligence, cyber security, and social networks.
Journal of Web Engineering, Vol. 24_1, 57–78.
doi: 10.13052/jwe1540-9589.2413
© 2025 River Publishers