Hybrid Top Features Extraction Model for Detecting X Rumor Events Using an Ensemble Method
Taukir Alam1, †, Wei Chung Shia2, 3, *, †, Fang Rong Hsu1,*, Taimoor Hassan4, Pei-Chun Lin1, Eric Odle1 and Junzo Watada5
1Department of Information Engineering and Computer Science, Feng Chia University, Taichung 407, Taiwan
2Molecular Medicine Laboratory, Department of Research, Changhua Christian Hospital, Changhua 500, Taiwan
3School of Big Data and Artificial Intelligence, Fujian Polytechnic Normal University, Fuqing 350300, China
4Institute of Translational Medicine & New Drug Development, China Medical University, Taichung, 404333, Taiwan
5Waseda University, Tokyo, 169-8050, Japan
E-mail: taukir.alam007@gmail.com; weichung.shia@gmail.com; frhsu@o365.fcu.edu.tw; Taimoorhassan408.th@gmail.com; peiclin@o365.fcu.edu.tw; odle.eric1@gmail.com; watada@waseda.jp
*Corresponding Authors
†Equal contribution
Received 27 August 2024; Accepted 02 December 2024
Abstract
The paper describes a novel a hybrid ensemble algorithm (HEA) that combines ensemble learning, class imbalance handling, and feature extraction. To address class imbalance in the dataset, the suggested approach integrates SMOTE oversampling and random under sampling (RU) feature extraction. To begin, Pearson correlation analysis is used to detect highly associated features in a dataset. This analysis aids in the selection of the most relevant features, which are either substantially related to the target variable or have a strong association with other features. The method seeks to improve classification performance by focusing on these correlated features. Following that, the SMOTE oversampling and RU algorithms are used to balance the majority and minority categorization characteristics. The SMOTE (synthetic minority oversampling technique) develops synthetic cases for the minority class by interpolating between existing instances, enhancing minority class representation. RU, on the other hand, removes instances from the majority class at random to obtain a balanced distribution. Furthermore, the random forest classifier (RFC) model’s key features are input into an ensemble of decision tree (DT), k-nearest neighbor (KNN), adaptive boosting (AdaBoost), and convolutional neural network (CNN) approaches. This ensemble approach combines multiple models’ predictions, exploiting their particular strengths and catching varied patterns in the data. Popular machine learning algorithms include DT, KNN, AdaBoost, and CNN, which are notable for their capacity to handle many types of data and capture complicated relationships. The evaluation findings show that the suggested HEA approach is effective, with a maximum precision, recall, F-score, and accuracy of 90%. The proposed methodology produces encouraging results, proving its applicability to a variety of categorization problems.
Keywords: Deep learning, ensemble, machine learning, RFC, RU, SMOTE, rumor detection, natural language processing (NLP).
1 Introduction
The proliferation of social media such as X, Facebook, Weibo, etc. have revolutionized global communication, enabling millions of users to instantly share information and express opinions. While this spontaneous interconnectivity has enhanced information dissemination, it has also exposed users to the perilous spread of rumors and disinformation [1]. This vulnerability poses dire personal, social, political, and economic threats on a massive scale as it can even escalate to risks impacting nations states or even continents. However, to curtail this issue, the development of effective techniques for rumor detection in social media has become a prominent area of research in recent years. However, this pursuit is facing major challenges such as excessive noise in social media data, data complexity, the requirement for high detection accuracy, and the class imbalance problem.
The proposed hybrid ensemble algorithm (HEA) aims to tackle challenges in a novel manner for the detection of rumors in social media. The specific objectives of this research encompass the identification of strongly correlated features through Pearson correlation analysis, handling class imbalance using the synthetic minority over sampling technique (SMOTE) and random under-sampling (RU), and reducing data dimensionality by selecting key features from the random forest model. Moreover, the study seeks to capitalize on the advantages of various machine learning techniques by integrating them within the framework of HEA. The ultimate goal of this study is to devise a robust and dependable method for rumor detection in social media, with practical applicability in real-world scenarios.
Rumors, characterized as unverified information presented as factual [2], have the potential to evoke significant reactions from people. The swift and effortless circulation of such rumors on social media platforms adds to their impact. An illustrative instance occurred in 2015, when a rumor surfaced on X with the hashtag #100Days100Nights [3], suggesting a competition among gangs in LA to achieve 100 killings first. This rumor prompted people in the LA region to refrain from leaving their homes, even though it lacked authenticity. The lack of awareness in effectively dealing with rumors on social media can lead the masses to make misguided decisions or fall victim to propagandistic information. Numerous rumors of similar nature continued to appear on various social media platforms in subsequent years, influencing the wellbeing of the masses and necessitating the cessation of their propagation across extensive user networks [4]. However, the task of rumor detection has become challenging, especially in the context of national security, as it involves identifying credible online discourse [5].
The repercussions of rumors extend beyond the realm of social media, disrupting public peace in our society [6]. In the contemporary landscape, a rumor can reach millions of people within seconds on social media, regardless of the absence of supporting evidence [7]. The differentiation between reliable and unreliable information on the internet has emerged as a pressing modern challenge. Detecting rumors on X has garnered significant attention due to its widespread usage among those who initiate social unrest [8]. Research indicates that more than 30% of trending tweets on X carry false or unverified information, posing potential risks to a country’s society, financial stability, political system, and international reputation. Once rumors gain prevalence, halting their spread becomes challenging, underscoring the increasing demand for early detection methods among social media analysts [9, 10].
Various approaches to rumor detection in social media have been proposed. One such approach involves the use of artificial neural networks (ANNs) in machine learning (ML), inspired by the functioning of biological brains [11, 12]. ANNs establish mathematical interconnections between vector elements and have demonstrated effectiveness in various computer science tasks, especially with large training datasets [13].
Recurrent neural networks (RNNs) represent a different kind of ML approach that consider temporal dynamics of micro-blogging posts, leveraging diverse characteristics such as textual contents. Researchers have applied this method to detect rumors during the 2010 Gulf of Mexico oil spill, achieving an F-score of 0.775 [14].
Deep learning (DL) has demonstrated superior performance over conventional ML approaches in several research domains[15]. For instance, Deng et al. [16] found that DL methods may be classified by the degree of abstraction when interpreting relationships within a dataset. DL has been used in natural language processing [17], computer vision [18], speech recognition [19], audio signal interpretation [20], and social network analysis [21]. Another social network application described by Castilo et al. [22] involves supervised training of a ML model that checks the credibility of trending X topics.
Numerous studies in the field of rumor detection employ various machine learning (ML) techniques, including support vector machine (SVM) [23–25], the susceptible-exposed-infected-skeptic (SEIZ) model [26], decision tree (DT), random forest (RF), k-nearest neighbor (KNN) [24], and the naive Bayes (NB) classifier [27, 28]. Additionally, deep learning (DL) methods, specifically convolutional neural network (CNN) [29–32] and recurrent neural network (RNN) [33–35] approaches, have also been explored.
Yang et al. [25] proposed an SVM classifier for detecting rumors on the Chinese social media siteSina Weibo, yielding 77% accuracy. Jin et al. [26]. introduced a SEIZ epidemiology model for X rumor detection, capable of distinguishing skeptics on eight global events. Mendoza et al. [36] employed logistic regression, decision tree, and SVM for binary classification of retweets as reliable or not during crisis events on X, achieving an accuracy of 0.86. Kwon et al. Kwon et al. [24] utilized a hybrid DT, SVM, and RF classifier approach to identify temporal, structural, and linguistic characteristics of rumor propagation on X, achieving accuracy (87%) and recall (0.92).
Dayani et al. [27] proposed a supervised KNN and NB classifier with an accuracy of 86%. Cai et al. [23] used a supervised SVM trained on Weibo text for rumor detection with 84% precision. Takahashi et al. [37] took an unsupervised approach in identifying rumors following natural disasters, emphasizing the role of retweeting in propagating false rumors. Furthermore, DL methods, particularly CNN and RNN-based models, have shown promise in rumor detection tasks [9, 11]. Ma et al. [35] presented an RNN trained on non-sequential tweets and retweets able to classify multiple rumor types. When applied to a X dataset, this RNN offered superior detection accuracy compared to other models. Asghar et al. [31] proposed a novel bidirectional CNN that classifies tweets either as a rumor or credible with 86.12% accuracy. Similarly, Ajao et al. [29] proposed a hybrid LSTM-CNN for identifying rumors on X with 82% accuracy.
In this paper, we propose a novel hybrid ensemble algorithm (HEA) model for rumor detection, built on the foundations of the SMOTE-RU feature extraction model. The proposed approach utilizes the Pearson correlation method for extracting strongly correlated features from the dataset. Subsequently, the synthetic minority oversampling technique (SMOTE) and random under sampling (RU) are employed to balance minority and majority class data. The random forest method further enhances feature extraction. Following data extraction, the HEA model utilizes a sequence of methods including decision tree, k-nearest neighbor (KNN), AdaBoost, and aconvolutional neural network (CNN). The best sequence is determined by evaluating precision, recall, F-score, and accuracy during training and validation. The optimal sequence aims to improve performance metrics based on the characteristics of each model.
A summary of key studies that served as the basis for incorporating ML approaches into our proposed HEA model is provided in Table 1.
Table 1 Comparison of key rumor detection approaches
| Author | Model | Dataset |
| Castilo et al. [22] | SVM | X |
| Cai et al. [23] | SVM | |
| Kwon et al. [24] | DT/SVM/RF | X |
| Yang et al. [25] | SVM | |
| Jin et al. [26] | SEIZ | X |
| Dayani et al. [27] | KNN+Bayes | X |
| Ajao et al. [29] | LSTM+CNN | X |
| Alsaeedi et al. [30] | CNN | PHEME |
| Asghar et al. [31] | CNN | PHEME |
| Alkhodair et al. [33] | Word2Vec+LSTM | PHEME |
| Ma et al. [35] | RNN | X |
| Proposed method | HEA model | PHEME |
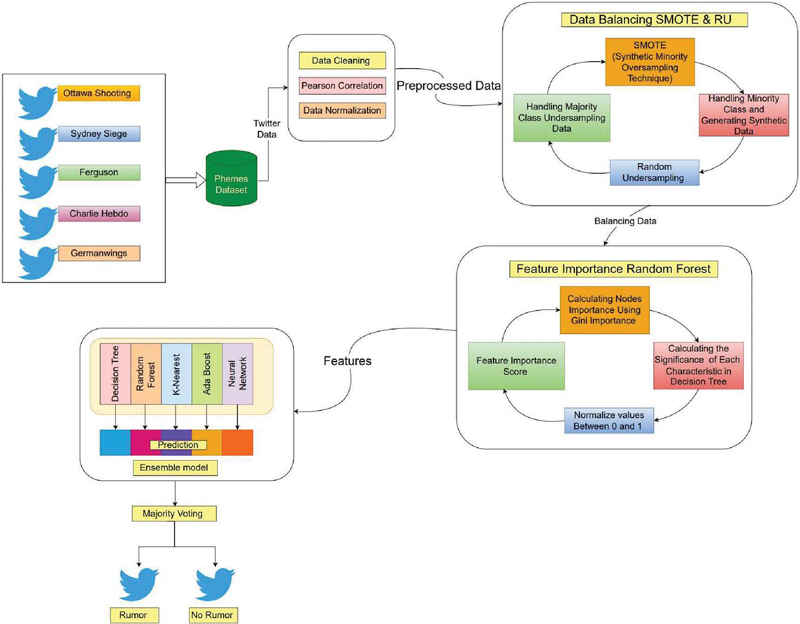
Figure 1 Flowchart of the proposed hybrid ensemble method. A comprehensive end to end depiction of the overall paper.
2 Materials and Methods
This paper presents the hybrid ensemble algorithm (HEA) which is shown in Figure 1. This paper employs the PHEME dataset [38] tweets threads, which includes 5802 posts on worldwide events. The events include Charlie Hebdo, the Ferguson, German Wings Crash, the Ottawa Shooting and the Sydney Siege. These are world events included in the dataset threads.
The Computational platform Google Collab’s GPU was used and an Adam optimizer with a default learning rate of 0.001 was used in the training protocol to train the model across 2000 epochs with a batch size of 20. To enable efficient model evaluation, the dataset was divided into training and test sets. Python and TensorFlow were used for reliable and effective deep learning procedures.
2.1 Preprocessing of Data
Tweets from the PHEME dataset were first split into independent and dependent variable columns. Then, we cleaned the data of redundancies and performed normalization using the min–max scalar method which scales features to within a given range, to ensure uniformity and to eliminate case-related differences, we converted all text to lowercase, and we removed text data noise such as special characters, punctuation, URLs, and HTML tags.
2.2 Data Balancing
In order to prevent model bias toward the majority class, which can result in poor generalization, data balancing is essential. Prediction accuracy is decreased, especially for the minority class, when models are biased toward the more prevalent class due to imbalanced data. Balancing the dataset in the context of rumor detection guarantees equitable representation and improved model performance.
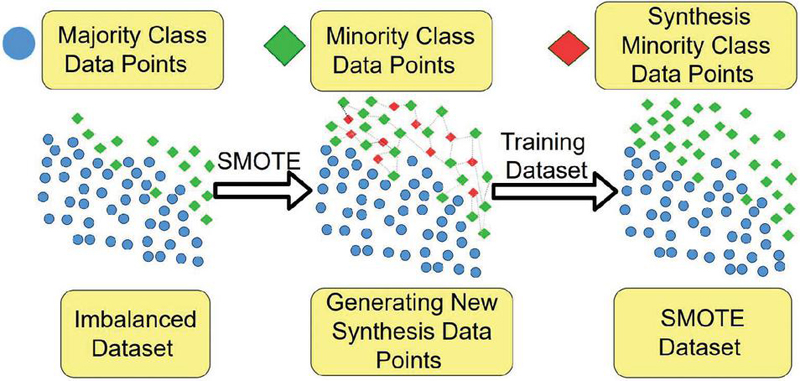
Figure 2 SMOTE. The synthetic minority over-sampling technique develops synthetic cases for the minority class by interpolating between existing instances.
The SMOTE algorithm mitigated the impact of model overfitting when random oversampling occurs. In the feature space, SMOTE produces new instances by interpolating adjacent positive instances from k-nearest minority class neighbors. The SMOTE algorithm generates synthetic samples in the feature space by interpolating between minority class instances. This process helps mitigate the impact of class imbalance but does not alter the original data distribution significantly. However, it may introduce slight variations, which could affect model behavior depending on the interpolation technique used. This process is illustrated in Figure 2; the mathematics of SMOTE are described by Equation (1) [40].
| (1) |
where
S = new instances synthesized by random interpolation between two instances,
X = minority instances of dataset,
W= random weight in 0 and 1,
Y = k-nearest minority neighbors of X instances of the dataset.
Note: “” and “” operators represent addition and subtraction of corresponding feature values, respectively.
Step 1: This algorithm selects minority instance X and randomly selects one Y from k-nearest minority class neighbors.
Step 2: A new instance is synthesized, which is calculated by Equation (1).
Step 3: Further SMOTE synthesize instances of the minority in the majority class dataset region, irrespective of location.
Further random undersampling is presumed by randomly selecting from the majority class followed by deletion from the training dataset [41]. Within the majority class, instances are discarded randomly until a balanced distribution is achieved. This process is illustrated in Figure 3.
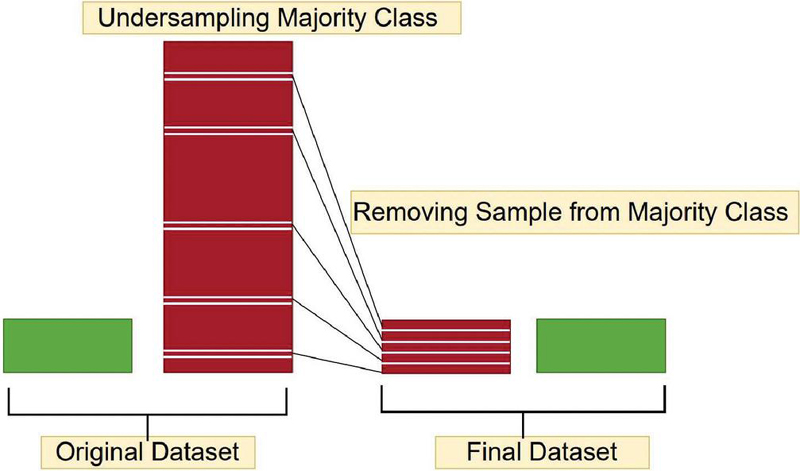
Figure 3 Random undersampling. This helps in the class imbalance of the dataset.
2.3 Feature Extraction
Pearson correlation analysis (PCA) was implemented in each column/feature of the dataset to determine correlation. Highly correlated variables tend to convey similar information, which can hinder model performance. As such, Pearson correlation was conducted as follows [42]:
Step 1: Correlation between each column/feature is calculated using the Pearson Correlation formula:
| (2) |
Note that: r Pearson coefficient, n number of pairs, sum of products, sum of x scores, sum of y scores, sum of squared x scores, sum of squared y scores.
From Figure 4, 1 indicates a strong positive relationship, 1 indicates a strong negative relationship. A result of zero indicates no relationship at all.
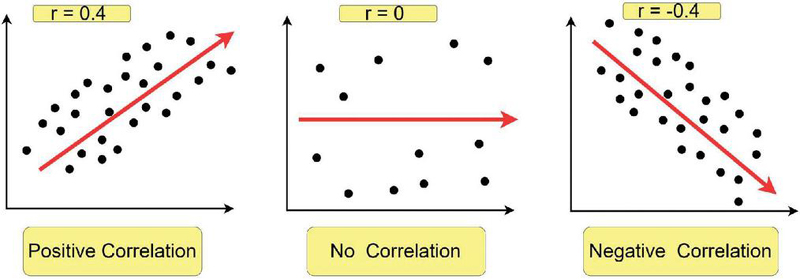
Figure 4 Pearson correlation analysis. This was implemented in each column/feature of the dataset to determine correlation.
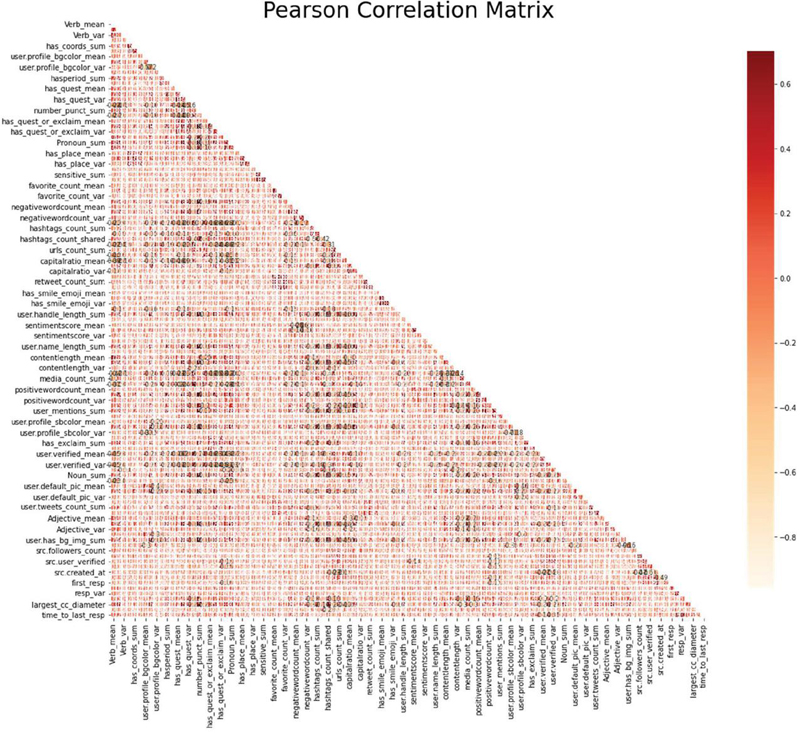
Figure 5 Correlation matrix. The positive values have correlation and negative values have lower correlation.
Step 2: Features with a correlation value of greater than 0.90 were excluded. Pearson correlation matrix results are shown in Figure 5 and Table 2.
Following Pearson correlation analysis, we apply a class balancing technique to avoid generalization bias in favor of the majority class during training. Furthermore, we apply a feature selection step using the RFC method to elucidate key data classification features. The RFC method is executed using the following four-step process [43]:
Table 2 A summary table of the correlation results from Figure 5, focusing on the most significant relationships ()
| Attribute 1 | Attribute 2 | Correlation Coefficient |
| user_profile_bgcolor_mean | user_profile_bgcolor_var | 0.72 |
| sentimentScore_mean | sentimentScore_var | 0.68 |
| retweet_count_mean | retweet_count_sum | 0.65 |
| user.default_pic_mean | user.default_pic_var | 0.63 |
| user_profile_trigram_mean | user_profile_trigram_var | 0.61 |
| hashtags_count_sum | hashtags_count_var | 0.59 |
| contentlength_mean | contentlength_var | 0.57 |
| capitalratio_mean | capitalratio_var | 0.55 |
| time_to_last_resp_mean | time_to_last_resp_var | -0.53 |
| user. verified_mean | user. verified_var | 0.51 |
Step 1: Use the Gini impurity method to determine node importance for each decision tree using the following equation (we assume a binary tree with only two child nodes):
| (3) |
where the importance of node weighted number of samples reaching node , the impurity value of node , child node from left split on node , child node from right split on node .
Step 2: Compute the influence of each character on the decision tree:
| (4) |
The parameter denotes the importance of feature i.
Step 3: Values are normalized to between 0 and 1 by using the following equation:
| (5) |
The parameter denotes the normalized importance of feature i.
Step 4: Evaluate the mean normalized importance value for features calculated by each RF tree as follows:
| (6) |
The parameter denotes the average importance of feature i. Parameter denotes the normalized importance of feature i on tree j. Parameter T represents the total number of trees. The balanced data is then used to train a random forest model, which we use to extract the top 50 key features from the dataset. At the conclusion of this process, the data was balanced and top features have been identified. Our top 50 key PHEME features are show in Figure 6.
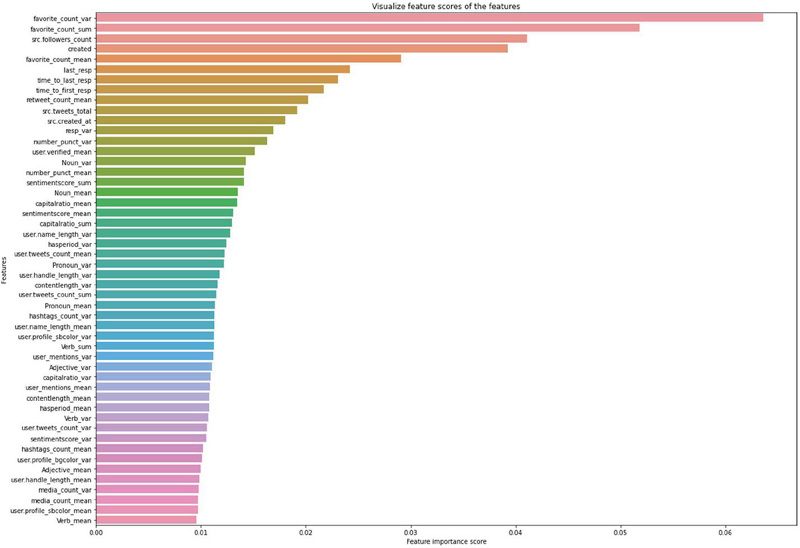
Figure 6 Top 50 key PHEME features extracted from the dataset.
2.4 Ensemble Method
The random forest approach constructs a decision tree using a different dataset or mean data subset. This process is illustrated graphically in Figure 7. By including multiple decision trees, the random forest approach provides a more accurate prediction given that decision tree agreements earn a stronger vote towards the final predicted output. The data has been split into 80% training and 20% for testing [44].
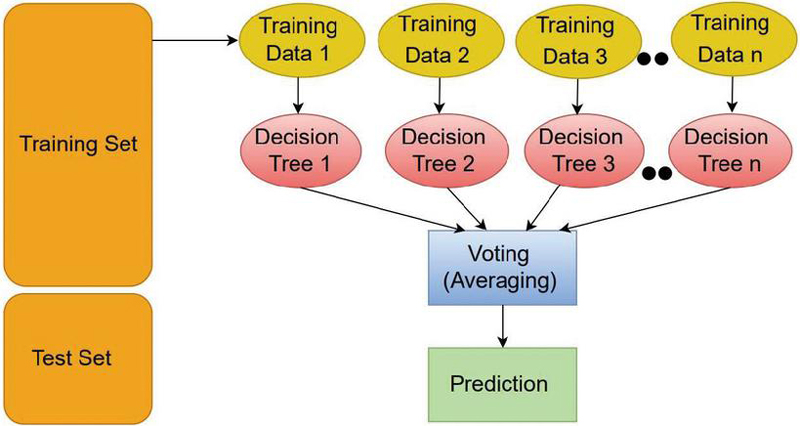
Figure 7 Random forest classification. This constructs a decision tree using a different dataset or mean data set.
The ensemble method is composed of decision tree (DT), k-nearest neighbor (KNN), adaptive boosting (AdaBoost), and convolutional neural network (CNN) methods [45].
The decision tree classifier constructs a model based on selected features from the dataset. To ensure reproducibility, a random state value of 7 is used during model initialization [46].
2.4.1 Decision tree
Given a set of instances S and attribute A, is a subset of S with A v, Ent(S) represents the entropy of S, and Val(A) represents the set of all possible values for A:
| (7) |
2.4.2 K-nearest neighbor
In the k-nearest neighbors (kNN) algorithm, choosing the best value for k plays a crucial role. The k-value is a key component of the method because it controls how many neighbors are taken into account for categorization [47].
2.4.3 Adaptive boosting (AdaBoost)
First, we select weights that aid in targeting difficult classes. This process is done sequentially such that two weights are adjusted for each step of the algorithm [48] for () with training samples from () to the th training sample such that where X is total set of the data and , the AdaBoost method is perforformed as follows:
Step 1: Initialize. for . Here, weights of samples and th training sample.
Step 2: Train weak learners using the distribution .
Step 3: Get weak hypothesis .
Step 4: Determine with minimal weighted error:
| (8) |
where is the probability.
Assume that:
| (9) |
For , and
| (10) |
where is a normalization factor (chosen such that is the distributed output of the final hypothesis):
| (11) |
where T is a classifier
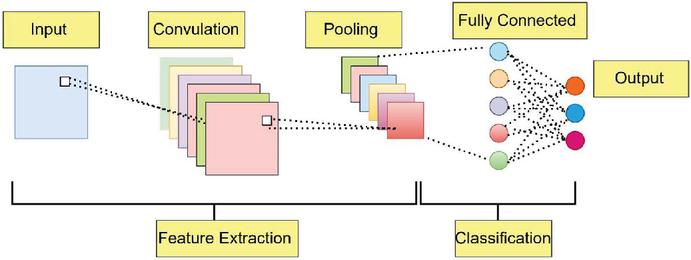
Figure 8 Convolutional neural network having different layers: input layer, middle layer and output layer.
2.4.4 Convolutional neural network
For the CNN, an input layer, four middle levels, and an output layer constitute the network’s total of six layers. The first dense layer contains an input dimensionality definition for the input layer. There are 128, 64, 32, and 16 neurons in each of the four main layers, respectively (Figure 8). The mathematics of our CNN are described by Equation (12) [49]:
| (12) |
where number of input features, number of output features, k convolution kernel size, convolution padding size, and convolution stride size.
3 Analysis and Evaluation of Results
The performance of the proposed HEA model is evaluated using an ROC (receiver operating characteristics) curve, confusion matrix, and a classification report. A classification report consists of accuracy, precision, recall, and F-score metrics. A classification prediction is simultaneously true (model agrees with ground truth) or false (model disagrees with ground truth) and positive (a given class is attributed by the model) or negative (a given class is not attributed by the model). Accuracy is simply the number of true positives divided by the total number of predictions. Precision is calculated by dividing the number of true positives by the total number of positives (true and false) for a given class. Recall is calculated as the proportion of true positives to true positives plus false negatives. Finally, the F-Score is calculated by taking the weighted mean of precision and recall.
Figures 9(a), (b), (c), and (d) compare accuracy, F-score, precision, and recall for the different rumor detection approaches shown. According to our results, the proposed hybrid ensemble method outperformed the other approaches with an achieved accuracy, F-score, precision, and recall of approximately 0.90, 0.90, 0.90, and 0.90, respectively.
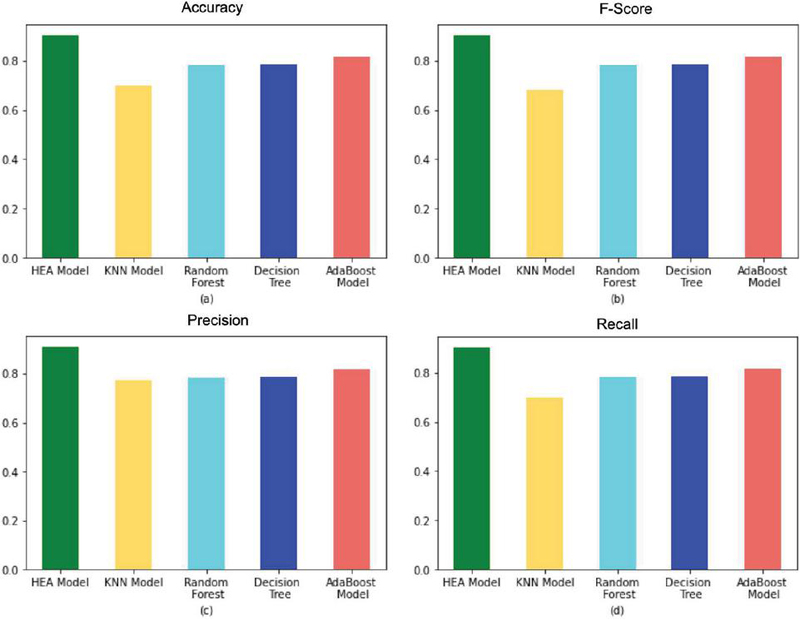
Figure 9 Comparison of rumor detection approaches. A comparison has been put forward in between HEA and the different approaches.
Table 3 provides performance metrics on the proposed HEA model along with other component approaches. The KNN method offered the lowest precision (0.77), recall (0.69), F-score (0.68), and accuracy (0.69) with respect to PCA and feature importance. AdaBoost provided better results than both the KNN and decision tree methods. Meanwhile, our proposed HEA model exhibited superior precision (0.90), recall (0.90), F-score (0.90), and accuracy (90%), illustrated in Figure 9.
Table 3 Comparison of key rumor detection approaches
| Models | Accuracy | F-score | Precision | Recall |
| KNN model | 0.699357 | 0.683262 | 0.775804 | 0.699357 |
| Random forest | 0.782958 | 0.783064 | 0.783369 | 0.782958 |
| Decision tree | 0.784566 | 0.784682 | 0.787542 | 0.784566 |
| AdaBoost model | 0.818328 | 0.818456 | 0.819299 | 0.818328 |
| HEA model | 0.903537 | 0.903519 | 0.909577 | 0.903537 |
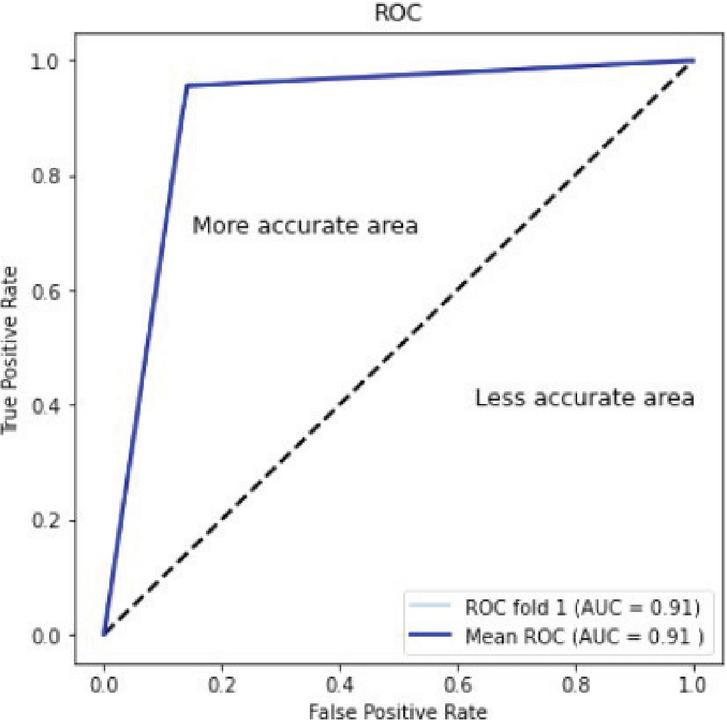
Figure 10 ROC curve of the proposed hybrid ensemble model.
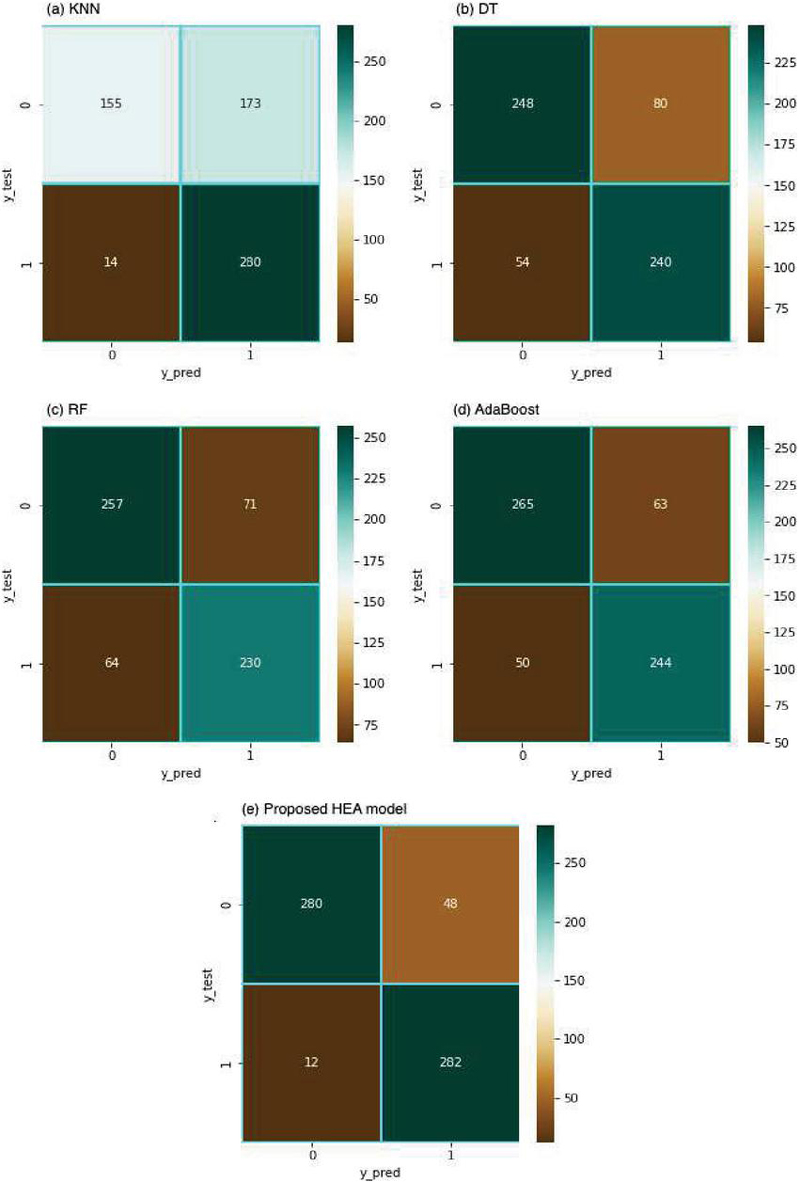
Figure 11 Confusion matrix (CM) of classification results generated by five approaches: (a) KNN, (b) decision tree, (c) random forrest, (d) AdaBoost, and (e) our proposed HEA model. The CM vertical axis represents ground truths of 0 (non-rumor) and 1 (rumor). Horizontal axis represents corresponding model predictions. Heat map coloration ranges from brown (few), to light green (moderate), to dark green (many).
4 Discussion
The objective of this research is to apply the hybrid ensemble method illustrated in Figure 1 to enhance classification tasks on the PHEME dataset. A total of 5802 posts about current events make up the dataset. Data cleaning, normalization, and feature selection using Pearson correlation analysis were among the data preprocessing approaches used. Data was split into 80% and 20% for training and testing respectively. The accuracy of rumor verification is significantly lower without the use of SMOTE for resampling, at about 69% with k-nearest neighbor (KNN) and somewhat higher with decision tree (about 78%), than the 90% accuracy attained when the data is balanced using the (SMOTE) synthetic minority oversampling method. As the model learns better from underrepresented samples, it adds synthetic examples rather than duplicating the existing data, reducing the risk of overfitting to specific samples in the minority class, which improves generalization.
SMOTE and random undersampling (RU) were applied to alleviate class imbalance. Decision tree (DT), k-nearest neighbor (KNN), adaptive boosting (AdaBoost), and convolutional neural network (CNN) models were all included in the ensemble technique. An input layer, four intermediate levels, and an output layer made up the six layers of the CNN model. The evaluation findings showed that the hybrid ensemble strategy was effective, with maximum precision, recall, F-score, and accuracy of 90%.
Figure 10 provides an ROC curve for our proposed HEA model. Values near 1 represent superior accuracy, and our curve considers the true positive vs. the true negative rate.
Figures 11(a)–(e) show classification confusion matrices obtained from five rumor detection approaches. Our proposed ensemble method (e) exhibits superior accuracy (562 correct out of 622 total predictions). The following is a detailed breakdown of performance metrics pertaining to Figure 11(e):
True positives (280): Number of rumors correctly identified as rumors by the model.
True negatives (282): Number of non-rumors correctly identified as non-rumors by the model.
False positives (48): Number of non-rumors erroneously identified as rumors by the model.
False negatives (12): Number of rumors erroneously identified as non-rumors by the model.
5 Conclusion
This paper presents the design of a hybrid ensemble algorithm rumor detection model that incorporates the synthetic minority oversampling technique (SMOTE) and random under sampling (RU) to balance the training dataset. Moreover, our proposed HEA model utilizes the random forest method to extract key classification features that are then used in a machine learning ensemble to obtain superior predictions. Performance results from testing the proposed model yielded 90% accuracy in the detection of rumors on social media, as well as values of 90% for precision, recall, and F-score. In future work we will focus on advance deep learning method for feature extraction to better stabilize loss during model training.
Patents
Not applicable.
Supplementary Materials
Specific scripts used to generate our results during this project are available at: https://github.com/taukiralam007/Rumor\_detection/blob/main/rumor-2.ipynb.
Author Contributions
T.A: Conceptualization, methodology, writing – original draft preparation, validation. W.C.S.: Conceptualization, Investigation, Methodology, Resources, writing – review and editing, Project administration, Supervision, Funding acquisition. F.-R.H.: Project administration, Investigation, Resources, Supervision and Review, Funding acquisition. H: Writing – review and editing. P.C.: Supervision, review E.O: writing and review J.W: Supervision, review.
Funding
This research is supported by the National Science and Technology Council, R.O.C., under Grant No. MOST 112-2221-E-035-057 and Changhua Christian Hospital Grant No. 112-CCH-IRP-117.
Data Availability Statement
Data used in this article “PHEME Dataset”, which is publicly available: https://figshare.com/articles/dataset/PHEME\_dataset\_of\_rumours\_and\_non-rumours/4010619.
Acknowledgments
Not Applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
[1] Li, J.; Bin, Y.; Peng, L.; Yang, Y.; Li, Y.; Jin, H.; Huang, Z. Focusing on Relevant Responses for Multi-modal Rumor Detection. IEEE Transactions on Knowledge and Data Engineering 2024.
[2] Tan, L.; Wang, G.; Jia, F.; Lian, X. Research status of deep learning methods for rumor detection. Multimedia Tools and Applications 2023, 82, 2941-2982.
[3] “Los angeles gangs in sick contest to kill 100 people in 100 days,” [Online] https://www.dailymail.co.uk/news/article-3178182/Los-Angeles-gangs-bet-kill-100-people-100-days-first.html. 2015.
[4] Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Systems with Applications 2020, 153, 112986.
[5] Allport, G.W.; Postman, L. An analysis of rumor. Public opinion quarterly 1946, 10, 501–517.
[6] Tan, Z.; Ning, J.; Liu, Y.; Wang, X.; Yang, G.; Yang, W. ECRModel: An elastic collision-based rumor-propagation model in online social networks. IEEE Access 2016, 4, 6105–6120.
[7] Wu, L.; Li, J.; Hu, X.; Liu, H. Gleaning wisdom from the past: Early detection of emerging rumors in social media. In Proceedings of the Proceedings of the 2017 SIAM international conference on data mining, 2017; pp. 99–107.
[8] Bondielli, A.; Marcelloni, F. A survey on fake news and rumour detection techniques. Information sciences 2019, 497, 38–55.
[9] Pathak, A.R.; Mahajan, A.; Singh, K.; Patil, A.; Nair, A. Analysis of techniques for rumor detection in social media. Procedia Computer Science 2020, 167, 2286–2296.
[10] Al-Sarem, M.; Boulila, W.; Al-Harby, M.; Qadir, J.; Alsaeedi, A. Deep learning-based rumor detection on microblogging platforms: a systematic review. IEEE access 2019, 7, 152788–152812.
[11] Eismann, K. Diffusion and persistence of false rumors in social media networks: implications of searchability on rumor self-correction on Twitter. Journal of Business Economics 2021, 91, 1299–1329.
[12] Alzanin, S.M.; Azmi, A.M. Detecting rumors in social media: A survey. Procedia computer science 2018, 142, 294–300.
[13] Grekousis, G. Artificial neural networks and deep learning in urban geography: A systematic review and meta-analysis. Computers, Environment and Urban Systems 2019, 74, 244–256.
[14] Ma, J.; Gao, W.; Mitra, P.; Kwon, S.; Jansen, B.J.; Wong, K.-F.; Cha, M. Detecting rumors from microblogs with recurrent neural networks. 2016.
[15] Schmidhuber, J. Deep learning in neural networks: An overview. Neural networks 2015, 61, 85–117.
[16] Deng, L.; Yu, D. Deep learning: methods and applications. Foundations and trends® in signal processing 2014, 7, 197–387.
[17] Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the Proceedings of the 25th international conference on Machine learning, 2008; pp. 160–167.
[18] Wehrmann, J.; Becker, W.; Cagnini, H.E.; Barros, R.C. A character-based convolutional neural network for language-agnostic Twitter sentiment analysis. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), 2017; pp. 2384–2391.
[19] Huang, P.-S.; Kim, M.; Hasegawa-Johnson, M.; Smaragdis, P. Deep learning for monaural speech separation. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014; pp. 1562–1566.
[20] Lee, H.; Pham, P.; Largman, Y.; Ng, A. Unsupervised feature learning for audio classification using convolutional deep belief networks. Advances in neural information processing systems 2009, 22.
[21] Deng, S.; Huang, L.; Xu, G.; Wu, X.; Wu, Z. On deep learning for trust-aware recommendations in social networks. IEEE transactions on neural networks and learning systems 2016, 28, 1164–1177.
[22] Castillo, C.; Mendoza, M.; Poblete, B. Information credibility on twitter. In Proceedings of the Proceedings of the 20th international conference on World wide web, 2011; pp. 675–684.
[23] Cai, G.; Wu, H.; Lv, R. Rumors detection in chinese via crowd responses. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2014), 2014; pp. 912–917.
[24] Kwon, S.; Cha, M.; Jung, K.; Chen, W.; Wang, Y. Prominent features of rumor propagation in online social media. In Proceedings of the 2013 IEEE 13th international conference on data mining, 2013; pp. 1103–1108.
[25] Yang, F.; Liu, Y.; Yu, X.; Yang, M. Automatic detection of rumor on sina weibo. In Proceedings of the Proceedings of the ACM SIGKDD workshop on mining data semantics, 2012; pp. 1–7.
[26] Jin, F.; Dougherty, E.; Saraf, P.; Cao, Y.; Ramakrishnan, N. Epidemiological modeling of news and rumors on twitter. In Proceedings of the Proceedings of the 7th workshop on social network mining and analysis, 2013; pp. 1–9.
[27] Dayani, R.; Chhabra, N.; Kadian, T.; Kaushal, R. Rumor detection in twitter: An analysis in retrospect. In Proceedings of the 2015 IEEE International Conference on Advanced Networks and Telecommuncations Systems (ANTS), 2015; pp. 1–3.
[28] Kumar, A.; Sangwan, S.R. Rumor detection using machine learning techniques on social media. In Proceedings of the International Conference on Innovative Computing and Communications: Proceedings of ICICC 2018, Volume 2, 2019; pp. 213–221.
[29] Ajao, O.; Bhowmik, D.; Zargari, S. Fake news identification on twitter with hybrid cnn and rnn models. In Proceedings of the Proceedings of the 9th international conference on social media and society, 2018; pp. 226–230.
[30] Alsaeedi, A.; Al-Sarem, M. Detecting rumors on social media based on a CNN deep learning technique. Arabian Journal for Science and Engineering 2020, 45, 10813–10844.
[31] Asghar, M.Z.; Habib, A.; Habib, A.; Khan, A.; Ali, R.; Khattak, A. Exploring deep neural networks for rumor detection. Journal of Ambient Intelligence and Humanized Computing 2021, 12, 4315–4333.
[32] Roy, A.; Basak, K.; Ekbal, A.; Bhattacharyya, P. A deep ensemble framework for fake news detection and classification. arXiv preprint arXiv:1811.04670 2018.
[33] Alkhodair, S.A.; Ding, S.H.; Fung, B.C.; Liu, J. Detecting breaking news rumors of emerging topics in social media. Information Processing & Management 2020, 57, 102018.
[34] Chen, T.; Li, X.; Yin, H.; Zhang, J. Call attention to rumors: Deep attention based recurrent neural networks for early rumor detection. In Proceedings of the Trends and Applications in Knowledge Discovery and Data Mining: PAKDD 2018 Workshops, BDASC, BDM, ML4Cyber, PAISI, DaMEMO, Melbourne, VIC, Australia, June 3, 2018, Revised Selected Papers 22, 2018; pp. 40–52.
[35] Ma, J.; Gao, W.; Wong, K.-F. Rumor detection on twitter with tree-structured recursive neural networks. 2018.
[36] Mendoza, M.; Poblete, B.; Castillo, C. Twitter under crisis: Can we trust what we RT? In Proceedings of the Proceedings of the first workshop on social media analytics, 2010; pp. 71–79.
[37] Takahashi, T.; Igata, N. Rumor detection on twitter. In Proceedings of the The 6th International Conference on Soft Computing and Intelligent Systems, and The 13th International Symposium on Advanced Intelligence Systems, 2012; pp. 452–457.
[38] Pheme Dataset https://figshare.com/articles/dataset/PHEME\_dataset\_of\_rumours\_and\_non-rumours/4010619?file=6453753.
[39] Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research 2002, 16, 321–357.
[40] Yi, X.; Xu, Y.; Hu, Q.; Krishnamoorthy, S.; Li, W.; Tang, Z. ASN-SMOTE: a synthetic minority oversampling method with adaptive qualified synthesizer selection. Complex & Intelligent Systems 2022, 8, 2247–2272.
[41] Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine learning with oversampling and undersampling techniques: overview study and experimental results. In Proceedings of the 2020 11th international conference on information and communication systems (ICICS), 2020; pp. 243–248.
[42] Obilor, E.I.; Amadi, E.C. Test for significance of Pearson’s correlation coefficient. International Journal of Innovative Mathematics, Statistics & Energy Policies 2018, 6, 11–23.
[43] Xiaolong, X.; Wen, C.; Xinheng, W. RFC: a feature selection algorithm for software defect prediction. Journal of Systems Engineering and Electronics 2021, 32, 389–398.
[44] Kaur, A.; Guleria, K.; Trivedi, N.K. Feature selection in machine learning: Methods and comparison. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), 2021; pp. 789–795.
[45] Bagheri, M.A.; Gao, Q.; Escalera, S. A framework towards the unification of ensemble classification methods. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications, 2013; pp. 351–355.
[46] Patel, H.H.; Prajapati, P. Study and analysis of decision tree based classification algorithms. International Journal of Computer Sciences and Engineering 2018, 6, 74–78.
[47] Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A brief review of nearest neighbor algorithm for learning and classification. In Proceedings of the 2019 international conference on intelligent computing and control systems (ICCS), 2019; pp. 1255–1260.
[48] Chengsheng, T.; Huacheng, L.; Bing, X. AdaBoost typical Algorithm and its application research. In Proceedings of the MATEC Web of Conferences, 2017; p. 00222.
[49] Indolia, S.; Goswami, A.K.; Mishra, S.P.; Asopa, P. Conceptual understanding of convolutional neural network-a deep learning approach. Procedia computer science 2018, 132, 679–688.
Biographies

Taukir Alam received his M.Sc. in electrical engineering from National Kaohsiung Normal University (Taiwan). He has worked as a senior engineer with Delta Taiwan and he is currently a Ph.D. candidate with the Faculty of Information Engineering and Computer Science, Feng Chia University (Taiwan). His research interests include machine learning, image processing, and GenAI where he explores the possibilities of generative models such as variational autoencoders (VAEs) and generative adversarial networks (GANs). His work in this field attempts to push the limits of data augmentation, simulation for AI system training, and creative content development.

Wei Chung Shia Ph.D. is the principal investigator of molecular medicine laboratory at Changhua Christian Hospital, Taiwan. He holds a Ph.D. in Information Engineering and Computer Science from Feng Chia University, Taiwan. He mainly specializes in breast cancer and related translational research, including molecular biology/genomics/clinical research. His recent research interests are in medical AI, include using machine-learning/deep-learning approaches for medical image analysis (breast ultrasound imaging and mammography) to predict the benign/malignant, prognosis and chemotherapy response.

Fang Rong Hsu received his Ph.D. degree in Computer Science from the National Chiao-Tung University, Hsinchu, Taiwan in 1992. He is a professor and was the chairperson in the Department of Information Engineering and Computer Science at Feng-Chia University, Taiwan. He was the Chairperson and a Professor of the Department of Bioinformatics, Asia University (2003–2004), Chairperson and a Professor of the Department of Information Technology, Asia University (2002–2003), and he was an associate professor and a professor of Providence University (1994–2002). His current research interests include machine learning, bioinformatics, cloud computing, man machine interaction, information security and graph algorithm.

Taimoor Hassan received his bachelor’s degree in medical sciences (Operation Theater Technology) from University of Health Sciences, Pakistan. He is currently enrolled as a Graduate student at Institute of Translational Medicine & New Drug Development, China Medical University (Taiwan). His research interests include bioinformatics, structural computational biology, protein engineering, antibody engineering, medical AI, machine learning, cancer biology, cancer therapeutics, translational medicine and new drug development.

Pei-Chun Lin received her Ph.D. degree from the Graduate School of Information, Production and Systems (IPS), Waseda University, Japan. During her Ph.D. work, Dr. Lin constructed a series of statistical models pertaining to fuzzy data. These models were then applied to decision- making systems with promising results. After obtaining her doctorate, Dr. Lin worked as a researcher at IPS in association with Waseda University while continuing to specialize in the application of fuzzy statistical models. One of her key accomplishments during this period was in the union of fuzzy statistical modeling and artificial intelligence. In addition to research, Dr. Lin serves as editor and reviewer for multiple top journals and is often invited as a keynote speaker. Her research interests include soft computing, artificial intelligence computing, robotics computing, statistical modeling, cloud computing, and big data analysis. Currently, Dr. Lin is Associate Professor in the Department of Information Engineering and Computer Science at Feng Chia University in Taichung City, Taiwan.

Eric Odle holds a B.Sc in biology from Saint Louis University (Missouri, USA), a B.A. in Japanese from the University of Alaska Anchorage (Alaska, USA), an M.A. in applied linguistics from Yuan Ze University (Taoyuan, Taiwan), and an M.Sc. in biology from National Taiwan Normal University (Taipei, Taiwan). His master’s thesis in linguistics focused on appraisal-based quality analysis of English–Japanese medical translation, while his master’s thesis in biology focused on AI-assisted behavioral tracking of mutant zebrafish undergoing drug treatment. In addition to rumor detection, Eric is passionate about artificial intelligence applications in Japanese text analysis, machine translation, second language education, music genre classification, sport biomechanics, and bioinformatics.

Junzo Watada received his B.Sc. and M.Sc. degrees in electrical engineering from Osaka City University (Osaka, Japan) as well as a Ph.D. from Osaka Prefecture University (Sakai, Japan). Dr. Watada served as Professor of Management Engineering, Knowledge Engineering, and Soft Computing with the Waseda University Graduate School of Information, Production, and Systems (Kitakyushu, Japan) until March of 2016. Now, he serves as Research Professor with the Zhejiang Gongshang University Research Institute of Quantitative Economics, Full Professor with the University Technology Petronas Department of Computer and Information Sciences (Malaysia), and Professor Emeritus at Waseda University (Japan). His research interests include big data analytics, soft computing, tracking systems, knowledge engineering, and management engineering. Moreover, Dr. Watada is a Life Fellow of both the Japan Society for Fuzzy Theory and Intelligent Informatics as well as the Biomedical Fuzzy Systems Association. Since 2019, he has served as President of the Forum of Inter-disciplinary Mathematics in India, as well as President of the International Society of Management Engineers since 2003. His awards include the Henri Coanda Medal Award from Inventico (Romania) in 2002 and the GH Asachi Medal from the Universitatea Tehnica GH Asachi, IASI (Romania) in 2006. Additionally, Dr. Watada serves as principal editor, co-chief editor, and associate editor for various international journals, including ICIC Express Letters, Information Sciences, Journal of Systems and Control Engineering (Proc. IMechE), International Journal of Innovative Computing, Information and Control, and Fuzzy Optimization and Decision Making.
Journal of Web Engineering, Vol. 24_1, 79–106.
doi: 10.13052/jwe1540-9589.2414
© 2025 River Publishers