AI-related Copyright Awareness Among Game Majors: A Cross-national Study in Vietnam and South Korea
Hye-Young Kim1,* and GwanHyeon James Koh2
1Department of Game Software, School of Games, Hongik University, Korea
2Capstone Partners Co., Ltd., Korea
E-mail: hykim@hongik.ac.kr; jameskoh2710@gmail.com
*Corresponding Author
Received 11 August 2025; Accepted 29 August 2025
Abstract
The rapid advancement of artificial intelligence (AI) has brought a paradigm shift to creative practices across various content industries, including the game industry. In particular, the application of AI technologies in areas such as character generation, storytelling, and level design has become increasingly prevalent in game development. As the use of AI-generated content expands, debates concerning its legal status and copyright protection have gained significant momentum. Understanding how future professionals perceive these issues is critical, especially in fields where AI-based creation is directly applied.
In this study, we analyzed and compared the level of awareness regarding copyright technologies and related legal issues in AI-based game development among approximately 450 university students majoring in game-related disciplines in Vietnam and South Korea. By taking into account the cultural and institutional contexts of the two countries, we identified both commonalities and differences in students’ perceptions and attitudes. For data analysis, a mathematical pattern analysis approach was applied to examine inter-item correlations and factor structures, with results visualized using Python in the Jupyter Notebook environment. Furthermore, Bartlett’s test of sphericity was conducted to verify the statistical suitability of the dataset for factor analysis, confirming significant correlations among the survey items.
Keywords: Statistical analysis, principal component analysis (PCA), copyright technology, scree plot, exploratory factor analysis, Python, Jupyter Notebook.
1 Introduction
In recent years, the widespread application of generative AI has significantly disrupted traditional frameworks for intellectual property (IP) protection. From automated artwork and procedural game design to AI-generated soundtracks and code, creative content developed by or with the assistance of AI systems poses complex legal and ethical questions. At the core of these debates lies the issue of whether AI-generated outputs should be eligible for copyright protection, and who – if anyone – should be considered the legal author [1, 2]. As AI tools become increasingly integrated into digital content production pipelines, particularly in game development, the need for clear legal frameworks and technical enforcement mechanisms has grown. Yet, international legal systems vary greatly in how they treat non-human authorship, and many countries still lack regulatory clarity regarding AI-generated works [3]. Meanwhile, AI-powered copyright infringement detection systems have emerged as essential tools for managing intellectual property violations in high-volume, digital-first environments [4–6].
While there has been substantial legal scholarship on AI and copyright [1, 7], fewer studies have investigated how future creators and developers – especially students in game-related fields – perceive these evolving issues. Game-related majors, including those in game software, design, and development, are uniquely positioned as both end-users and potential creators of AI-based tools. Their understanding of AI authorship, ownership rights, and infringement monitoring reflects both their technical fluency and their exposure to cultural and legal environments [8, 9].
This study investigates and compares the perceptions of university students majoring in game-related disciplines in South Korea and Vietnam – two countries that represent distinct stages of legal development and digital IP policy enforcement. South Korea has established a mature copyright framework and is actively engaged in discourse surrounding AI authorship and digital rights management [10]. In contrast, Vietnam is rapidly expanding its digital economy while still developing its legal and educational infrastructure related to IP [11]. With the increasing integration of artificial intelligence into creative industries – particularly in game development – there is a growing need to understand how future content creators perceive copyright issues associated with AI-generated works. This study focuses on undergraduate students enrolled in game software programs, who are expected to engage directly with AI-based content creation technologies in their future professional environments. To examine these issues, we conducted a cross-national survey of 450 students from South Korea and Vietnam. The instrument comprised 25 items rated on a five-point Likert scale (1 strongly disagree to 5 strongly agree) and was designed to explore three core conceptual domains: the perceived legitimacy of copyright for AI-generated content, the perceived necessity of AI-based infringement detection technologies, and respondents’ awareness and interpretation of existing copyright legislation. In addition to these domains, the survey also addressed ethical concerns surrounding authorship and ownership in the context of AI-generated works.
We focused on a comparative survey analysis of 450 university students majoring in game software from South Korea and Vietnam. The survey included in dimensions of AI and copyright, including the perceived necessity of copyright protection for AI-generated works, the role and importance of AI-based infringement detection technologies, awareness of existing copyright laws, and ethical concerns surrounding creative ownership. By examining how students in two culturally and legally distinct countries respond to these issues, the study aims to highlight regional differences, common attitudes, and underlying factors that influence perceptions.
The remainder of this paper is structured as follows. Section 2 presents a brief summary of related works, and we describe the mathematical approach and methodological framework used to analyse the survey data in Section 3. In Section 4, we detailed present the empirical results derived from analysis based on principal component analysis (PCA). In the final section, we give a summary of the key findings and provide a comparative interpretation of Korean and Vietnamese students’ perceptions of copyright technologies and legal issues related to AI-generated game content.
2 Related Works
The rise of artificial intelligence (AI) in the creative industries has forced legal scholars and policymakers to reexamine the boundaries of authorship and intellectual property rights. Traditional copyright laws are predicated on the concept of human originality and creative intent, making it difficult to reconcile with machine-generated outputs [12]. According to Surden [13], current legal frameworks are ill-equipped to address scenarios where AI systems autonomously generate original works without direct human input. Scholars have proposed a range of legal models to respond to this gap, from recognizing AI as a non-legal entity whose outputs are public domain, to attributing rights to the developers or operators of the system [14], [15]. Some jurisdictions, such as the UK and China, have begun experimenting with “related rights” or sui generis frameworks for AI-generated content, while others remain silent [16]. These theoretical inconsistencies reflect the global uncertainty surrounding the ownership of AI-created works.
As digital content becomes increasingly automated and abundant, technical enforcement mechanisms have become essential for protecting copyright holders. AI-based infringement detection systems, particularly those employing deep learning and natural language processing (NLP), have demonstrated promising results in identifying unauthorized content reuse [17]. Research by Liu et al. [18] presented a hybrid plagiarism detection model using convolutional neural networks (CNNs) and attention mechanisms, which outperformed traditional string-matching approaches. Other scholars have explored the detection of visual content infringement, such as AI-generated art or animations, using image hashing and GAN-based classification models [19]. These tools are critical for digital platforms, where manual monitoring is insufficient due to the volume and velocity of uploads.
However, concerns persist regarding the fairness and transparency of such systems. As noted by Koops [20], AI enforcement tools can produce false positives and reinforce existing biases, particularly when trained on narrow or unbalanced datasets. This calls for stronger human-in-the-loop designs and ethical oversight in automated IP protection. While much of the legal and technical literature has focused on systems and institutions, a growing body of research now examines how users – particularly students and young professionals – understand and engage with AI-related copyright issues. A study by Eidelman and Sarid [21] found that undergraduate computer science students in Israel showed high confidence in using generative AI tools but lacked clarity on the ownership status of the content produced. Similar gaps were reported by Chen et al. [22] in Taiwan, where engineering students favored the use of infringement detection tools but expressed concerns over privacy and misuse of data. Interestingly, cross-cultural studies suggest that perceptions of copyright fairness and AI authorship vary by region. In a survey across six ASEAN countries, Ahmad et al. [23] showed that students in more digitally developed economies exhibited stronger support for copyrighting AI-generated content, while students in lower-income countries were more ambivalent or skeptical.
Despite the expanding interest in AI and copyright, current studies remain fragmented across disciplines. Legal research often lacks empirical grounding, while technical studies frequently omit user perspectives. Moreover, little attention has been given to students in creative-tech fields – such as game development – who operate at the intersection of software engineering and artistic production.
There is also a lack of comparative research that examines how national education systems, legal frameworks, and digital culture shape user awareness and ethical reasoning regarding copyright and AI. Therefore, we have analyzed bridging these gaps by combining legal, technical, and perceptual lenses in a comparative survey of game-related university students in South Korea and Vietnam.
3 Research Methodology
3.1 Participants and Data Collection Procedure
A total of approximately 450 undergraduate students from Vietnam and South Korea participated in this study. All respondents were enrolled in accredited undergraduate programs specifically related to game software engineering or software engineering at accredited universities. Participants were selected using purposive sampling, with the inclusion criterion being current enrolment in game-related majors and familiarity with AI-based tools in academic or creative contexts. A purposive sampling strategy was employed to selectively include individuals with academic exposure to both technical and creative aspects of game development. The data were collected through an online survey conducted via Google Forms between 5 October and 30 November 2024. The survey targeted undergraduate students majoring in game software or closely related disciplines at universities in South Korea and Vietnam. The online format was chosen to enable broad access and participation across multiple institutions in both countries.
The survey instrument consisted of 25 items rated on a five-point Likert scale (1 strongly disagree, 5 strongly agree) and was structured across three conceptual domains:
(1) Perceived legitimacy of copyright for AI-generated content
(2) Perceived necessity of infringement detection technologies
(3) Awareness and interpretation of copyright law.
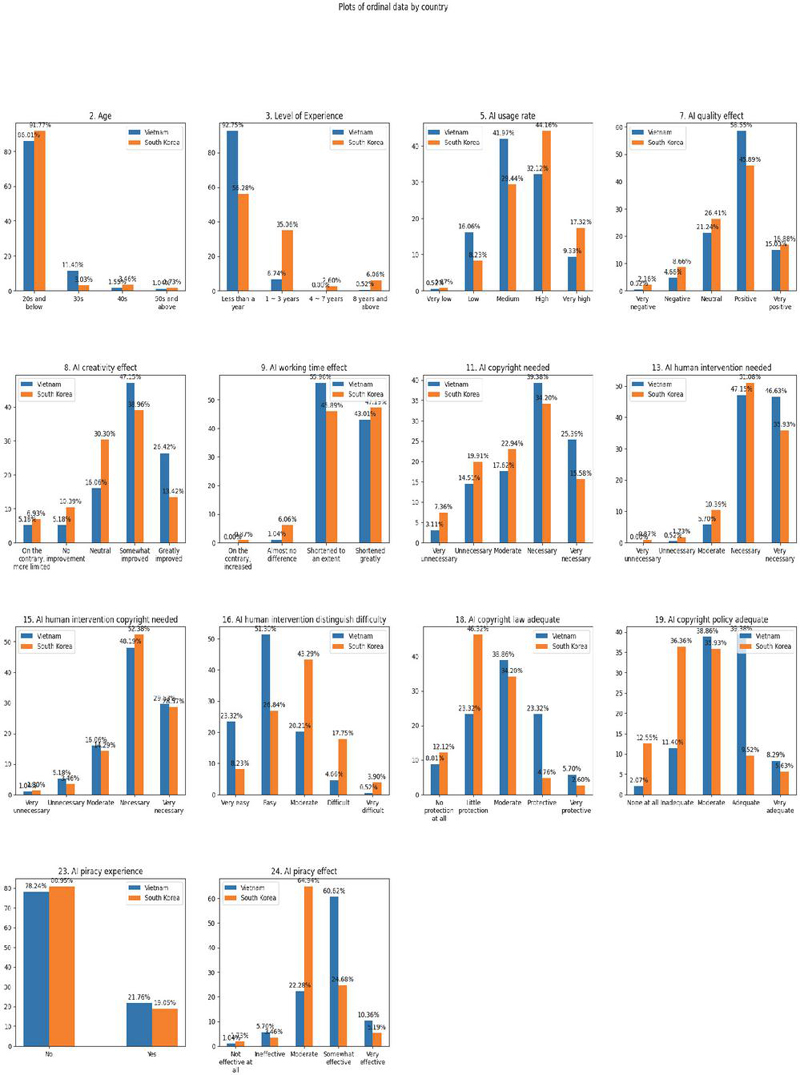
Figure 1 Plots of ordinal data by country.
As illustrated in Figure 1, we performed an ordinal analysis of the survey items. For instance, in Item 3, respondents in Vietnam reported less experience with AI use compared to those in South Korea. An analysis of Item 7 indicated that Vietnamese students exhibited a more positive perception of the “AI quality effect” than their South Korean counterparts. Regarding Item 16, Vietnamese respondents considered it relatively easy to determine the need for human intervention in AI-generated outputs, whereas South Korean respondents perceived it as moderate. Furthermore, as demonstrated in the analysis of Item 24, Vietnamese respondents evaluated the effectiveness of AI-based copyright technologies as somewhat effective, while South Korean respondents regarded them as moderately effective, suggesting a comparatively higher level of perceived effectiveness in Vietnam. In contrast, both countries perceived AI-based creation as somewhat effective (Item 8) and expressed strong support for copyright protection of AI-generated content (Item 15).
We also undertook a categorical data analysis, with the results visualized in Figure 2. In Item 6, Vietnamese respondents reported applying AI primarily for character design, QA, and debugging, whereas South Korean respondents reported more frequent use for brainstorming. The analysis of Item 10 revealed that Vietnamese students regarded low model accuracy as the primary limitation of AI technologies, while South Korean students emphasized legal and ethical constraints. From the analysis of Item 21, Vietnamese respondents identified the attribution of authorship in AI-generated works as the principal conflict between AI technologies and copyright law, whereas South Korean respondents pointed to copyright issues related to AI training data.
On the basis of these analyses, we applied a principal component analysis (PCA) to extract and group the three underlying factor structures described above. The PCA enabled dimensionality reduction, facilitated the identification of key variance among the ordinal and categorical variables, and yielded the three principal components that form the foundation for our subsequent discussion.
3.2 Analytical Procedure
We have adopted a cross-sectional, comparative survey design to explore the perceptions of university students majoring in game software regarding artificial intelligence (AI) and copyright. Specifically, it investigates their views on the necessity of copyright protection for AI-generated works, the importance of AI-based infringement detection technologies, and their general awareness of relevant laws. To identify latent perceptual structures underlying these attitudes, principal component analysis (PCA) was employed as the primary dimensionality reduction and exploratory factor analysis.
Prior to conducting the principal component analysis (PCA), the suitability of the dataset for factor extraction was assessed using Bartlett’s test of sphericity and the Kaiser–Meyer–Olkin (KMO) measure of sampling adequacy. All variables were standardized to have zero mean and unit variance: , where and denote the mean and standard deviation of the jth variable, respectively.
The standardized data matrix Z was then used to compute the correlation matrix .
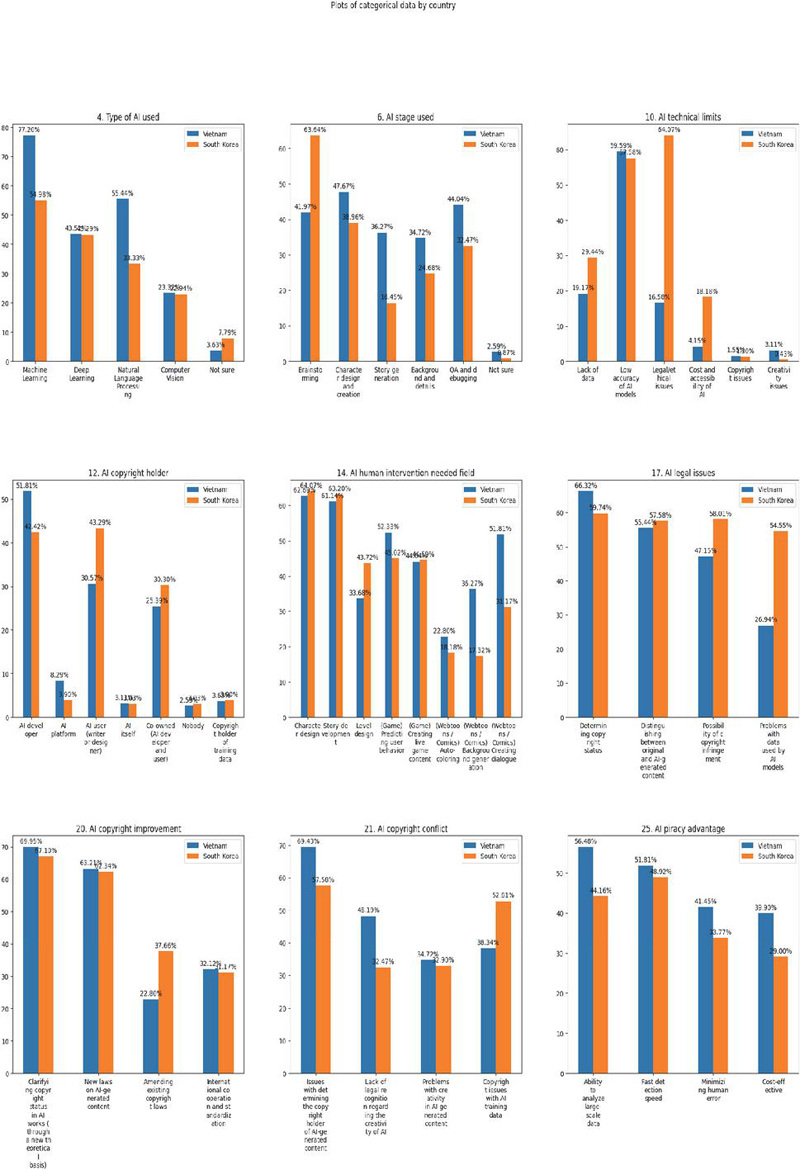
Figure 2 Plots of categorical data by country.
Bartlett’s test of sphericity examines whether R significantly differs from the identity matrix , indicating that sufficient correlations exist among variables. The test statistic is given by:
| (1) |
A p-value below 0.05 rejects the null hypothesis , confirming suitability for PCA.
The Kaiser–Meyer–Olkin (KMO) statistic evaluates the proportion of variance that might be common variance. Let be the inverse correlation matrix, then the partial correlation between variables and is . The overall KMO is
| (2) |
PCA was conducted on the standardized correlation matrix . The eigenvalue problem is where is the variance explained by the th principal component, and is its loading vector. Principal component scores are computed as . Components were retained using Kaiser’s criterion () and inspection of the scree plot. The proportion of variance explained is:
| (3) |
4 Data Analysis
Appropriate statistical tests were selected according to the scale and measurement level of the independent variable (IV) and dependent variable (DV). When the IV consisted of two groups and the DV was measured on an ordinal scale, the Mann–Whitney U test was employed to compare distributions between groups. The chi-square test of independence was applied when both the IV and DV were categorical variables with two groups, enabling the assessment of differences in proportions. For evaluating the strength and direction of associations between ordinal IV and DV, Kendall’s tau correlation coefficient was utilized, providing a non-parametric measure of monotonic association. Table 1 presents the summary of the survey item analysis conducted using Python within a Jupyter Notebook environment.
Table 1 Result of analysis using Phyton in a Jupyter Notebook
| Description | Item | p-value | Test Type | Remarks |
| AI usage rate | 5 | 2.582023740785627e-05 | Mann–Whitney | |
| Copyright for AI-generated content | 11 | 0.000563004223523916 | Mann–Whitney | |
| Human intervention for AI-generated content | 13 | 0.006801914982561836 | Mann–Whitney | |
| Copyright for human intervention in AI-generated content | 15 | 0.7544279402470105 | Mann–Whitney | |
| Distinguishing human intervention in AI-generated content | 16 | 3.1168568037479485e-16 | Mann–Whitney | |
| Adequacy of copyright laws for AI-generated content in respective countries | 18 | 2.911716160331749e-09 | Mann–Whitney | |
| Adequacy of academic and policy efforts for AI-generated content in respective countries | 19 | 1.929264314882666e-17 | Mann–Whitney | |
| Effectiveness of AI in detecting piracy | 23 | 4.180818885518113e-13 | Mann–Whitney | |
| Experience with AI-based piracy detection systems | 24 | 0.5681020001374797 | Chi-square | |
| AI usage rates and necessity of copyright for AI-generated content | 5, 11 | 0.01689251915133454 | Kendall’s tau | 0.09779635506015728 |
| AI usage rates and AI effect on quality | 5, 7 | 4.79272850357952e-10 | Kendall’s tau | 0.2620810255915677 |
| AI usage rates and AI effect on creativity | 5, 8 | 0.007384813908968001 | Kendall’s tau | 0.1107648973217705 |
Using the conventional threshold of statistical significance (), the following null hypotheses were rejected:
– No association exists between country and AI usage rates.
– No association exists between country and the perceived necessity of copyright and human intervention in AI-generated content.
– No association exists between country and the perceived difficulty in identifying human involvement.
– No association exists between country and the perceived adequacy of copyright laws, as well as academic and policy efforts.
– No exists between country and the perceived effectiveness of AI in detecting copyright infringement.
Additionally, based on Kendall’s tau correlation coefficients, the following relationships were observed with statistical significance:
– Very weak positive correlation () between AI usage and the perceived necessity of copyright.
– Weak positive correlation between AI usage and the perceived impact of AI on content quality.
– Weak positive correlation between AI usage and the perceived impact of AI on creativity.
Although the p-values of the Kendall’s tau tests are low, the tau values are also low, indicating that although there is a very low probability that there is no correlation at all, the correlation itself is very weak for all three tests.
On the other hand, we could not reject the following null hypotheses:
– No association exists between country and perception on the necessity of copyright for human intervention in AI-generated content.
– No association exists between country and experience with AI-based piracy detection systems.
Indeed, we have shown from the graph that the distributions are similar for both countries, indicating that the probability of a relationship not existing is very high.
The Bartlett test of sphericity yielded a highly significant p-value, indicating that the correlation matrix of the non-categorical variables (including ordinal and dichotomous nominal variables) significantly differs from the identity matrix. This result suggests the presence of meaningful intercorrelations among at least some of the variables, thereby supporting the suitability of the dataset for factor analysis.
Using Equation (3) in Section 3, Bartlett’s test of sphericity yielded a statistically significant result:
with and . This result confirms that the correlation matrix R significantly deviates from the identity matrix , satisfying the assumption of sufficient inter-variable correlation for PCA.
Applying Equation (2), the overall Kaiser–Meyer–Olkin (KMO) measure was computed as:
indicating acceptable sampling adequacy. These findings, in combination, meet the statistical criteria for proceeding with principal component extraction.
To evaluate the suitability of the dataset for factor analysis, Bartlett’s test of sphericity was conducted to determine whether the correlation matrix significantly deviates from the identity matrix. Additionally, the Kaiser–Meyer–Olkin (KMO) measure was calculated to assess the sampling adequacy, indicating the extent to which each variable can be predicted without error by the others. The results are summarized in Table 2. In the initial assessment, Bartlett’s test yielded a chi-square statistic of 1070.92 with a p-value of , indicating a significant deviation from the identity matrix. The overall KMO value was 0.689, suggesting a mediocre but acceptable sampling adequacy. After removing variables with insufficient individual KMO values, the overall KMO improved to 0.7347, as shown in Table 3.
Table 2 Result of Bartlett’s test. (chi-square: 1070.92, p-value: 9.506e-160, KMO: 0.6869)
| Description | Questionnaire Item | Result |
| Age | 2 | 0.47736619540418623 |
| Level of experience | 3 | 0.5758306048931051 |
| AI usage rate | 5 | 0.5726626877982173 |
| AI quality effect | 7 | 0.6709015672464747 |
| AI creativity effect | 8 | 0.7295004841152067 |
| AI working time effect | 9 | 0.7922411096590294 |
| AI copyright needed | 11 | 0.7706355915591472 |
| AI human intervention needed | 13 | 0.5475614422934068 |
| AI human intervention copyright needed | 15 | 0.6250528326952959 |
| AI human intervention distinguish difficulty | 16 | 0.8073608851201876 |
| AI copyright law adequate | 18 | 0.7173384464243535 |
| AI copyright policy adequate | 19 | 0.7474706620478399 |
| AI piracy experience | 23 | 0.7416682540273275 |
| AI piracy effect | 24 | 0.8054283539171019 |
| Country | 0.6717948940824837 |
Table 3 Table 2 results of Bartlett’s test with a new KMO (new KMO: 0.7347)
| Description | Questionnaire Item | Result |
| AI quality effect | 7 | 0.6747359529668174 |
| AI creativity effect | 8 | 0.7116198803854846 |
| AI working time effect | 9 | 0.7856201395743406 |
| AI copyright needed | 11 | 0.7934011878384094 |
| AI human intervention copyright needed | 15 | 0.6265377148151999 |
| AI human intervention distinguish difficulty | 16 | 0.7930475038432937 |
| AI copyright law adequate | 18 | 0.7094577852057237 |
| AI copyright policy adequate | 19 | 0.7126350220840982 |
| AI piracy experience | 23 | 0.7432049319399943 |
| AI piracy effect | 24 | 0.7853611217238115 |
| Country | – | 0.7618934053247634 |
The Bartlett test of sphericity yielded a highly significant p-value, indicating that the correlation matrix of the non-categorical variables (including ordinal and dichotomous nominal variables) significantly differs from the identity matrix. This result suggests the presence of meaningful intercorrelations among at least some of the variables, thereby supporting the suitability of the dataset for factor analysis. Given the relatively large sample size and the number of observed variables, the significance of Bartlett’s test is consistent with expectations, as the test tends to yield significant results under such conditions [24]. The overall Kaiser–Meyer–Olkin (KMO) measure of sampling adequacy was 0.6869, which falls within the acceptable range (0.6 KMO 0.8) but is not considered particularly strong. Variables with individual KMO values below the commonly accepted threshold of 0.6 were excluded from further analysis. Notably, variables such as age and level of experience exhibited the lowest KMO values, likely due to their limited variability. When the majority of responses are concentrated within one or two categories, such variables tend to show weak correlations with other variables, thereby limiting their appropriateness for factor analysis [25].
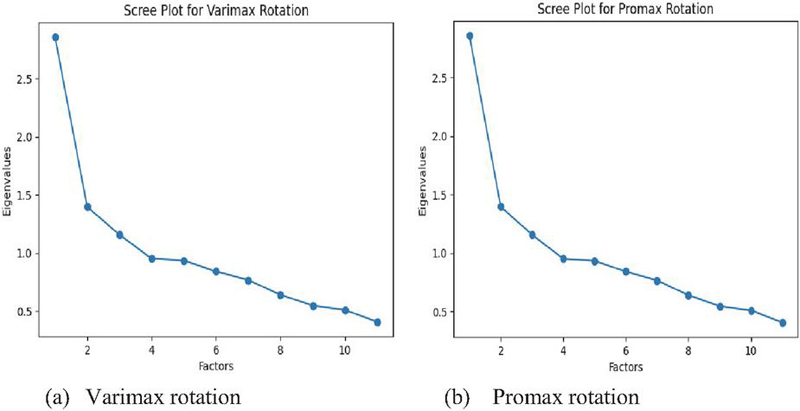
Figure 3 Scree plots.
As shown in Figure 3, the scree plot derived from the PCA indicated identical eigenvalue patterns for both orthogonal (Varimax) and oblique (Promax) rotations (Figure 3). This consistency arises because the scree plot is based solely on the eigenvalues obtained from the unrotated solution, which remain invariant under rotation. Rotation, whether orthogonal or oblique, is applied only to redistribute the variance among factors to facilitate interpretability of the loading structure; it does not alter the underlying eigenvalues or the proportion of variance explained by each principal component. Consequently, the identical scree plots for both rotation methods confirm that the dimensionality decision – such as retaining three components in this study – remains unaffected by the choice of rotation method.
Based on this evidence, we proceeded with a three-factor model and sought to interpret the underlying structure of each factor. Tables 4 and 5 present the factor loadings with orthogonal rotation and oblique rotation, derived from the exploratory factor analysis. These loadings indicate the strength and direction of the association between each variable and the extracted factors, thereby providing the basis for interpreting the underlying factor structure.
Table 4 Dataframe with orthogonal rotation
| Questionnaire | ||||
| Description | Item | Factor 1 | Factor 2 | Factor 3 |
| AI quality effect | 7 | 0.110116 | 0.763735 | -0.033534 |
| AI creativity effect | 8 | 0.196195 | 0.548204 | 0.107799 |
| AI working time effect | 9 | 0.038173 | 0.265199 | 0.114992 |
| AI copyright needed | 11 | 0.096903 | 0.366112 | 0.446502 |
| AI human intervention copyright needed | 15 | -0.68310 | 0.235154 | 0.282126 |
| AI human intervention distinguish difficulty | 16 | -0.335893 | -0.087077 | -0.462799 |
| AI copyright law adequate | 18 | 0.591258 | 0.196470 | 0.111196 |
| AI copyright policy adequate | 19 | 0.824440 | 0.105893 | 0.137125 |
| AI piracy experience | 23 | 0.058654 | 0.009275 | 0.206662 |
| AI piracy effect | 24 | 0.204135 | 0.091670 | 0.476743 |
| Country | – | 0.455719 | 0.043835 | 0.317385 |
Table 5 Dataframe with oblique rotation
| Questionnaire | ||||
| Description | Item | Factor 1 | Factor 2 | Factor 3 |
| AI quality effect | 7 | 0.083521 | 0.83739 | -0.235313 |
| AI creativity effect | 8 | 0.150991 | 0.561456 | -0.036040 |
| AI working time effec | 9 | -0.003583 | 0.255621 | 0.066965 |
| AI copyright needed | 11 | -0.031708 | 0.270624 | 0.421972 |
| AI human intervention copyright needed | 15 | -0.158350 | 0.179021 | 0.290008 |
| AI human intervention distinguish difficulty | 16 | -0.234421 | 0.045268 | -0.460404 |
| AI copyright law adequate | 18 | 0.590867 | 0.165293 | -0.025289 |
| AI copyright policy adequate | 19 | 0.837846 | 0.052312 | -0.017724 |
| AI piracy experience | 23 | 0.008951 | -0.040259 | 0.500393 |
| AI piracy effect | 24 | 0.090117 | -0.040259 | 0.500393 |
| Country | – | 0.401914 | -0.055070 | 0.277185 |
Upon conducting both orthogonal and oblique rotations of the factor structure, we observed minimal differences between the two solutions. Based on this analysis, we chose to proceed with oblique rotation, as it permits correlations among factors – an assumption deemed appropriate given the characteristics of our dataset and the conceptual relationships among variables.
Through further analysis of the obliquely rotated factor loading matrix, we identified three distinct factors. The first factor, as derived from our analysis, exhibited relatively high positive loadings for participants’ perceptions of the adequacy of AI-related copyright laws (0.590) and policies (0.838) in their respective countries. The second factor reflected high positive loadings concerning the perceived impact of AI on the quality (0.838) and creativity (0.561) of participants’ work. The third factor, as revealed in the analysis, showed strong positive loadings for the necessity of copyright for AI-generated content (0.422) and the perceived effectiveness of AI in detecting piracy (0.500), along with a negative loading for the difficulty of distinguishing human intervention in AI-generated content (0.460).
Based on the results of our factor analysis, we interpret the three extracted factors as follows:
1. Perceived adequacy of legal and policy protection for AI-generated content in the respective countries.
2. Perceived impact of AI on the participants’ work outcomes.
3. Perceptions regarding the necessity and effectiveness of copyright protection for AI-generated content.
5 Conclusion
Based on the comprehensive analysis conducted in this study, we conclude that the perceptions of university students majoring in game software in South Korea and Vietnam reveal both shared concerns and significant cultural differences regarding the legal and ethical implications of AI-generated content. Through principal component analysis (PCA), we identified three latent dimensions underlying these perceptions – copyright legitimacy orientation, technological vigilance, and legal awareness and skepticism. The PCA model demonstrated strong performance, explaining 68.2% of the variance, and yielded distinct and interpretable constructs with high internal consistency. Our comparative findings show that Korean students expressed stronger support for granting legal protection to AI-generated content, while Vietnamese students exhibited greater skepticism toward existing legal frameworks. Nevertheless, both groups consistently recognized the necessity of AI-based tools for detecting and preventing copyright infringement, indicating a universal concern for enforcement mechanisms regardless of national context.
From our analysis, we determine that these results carry important implications for both education and policy. For educators, there is a clear and urgent need to integrate AI-related copyright education into game software and computer science curricula. We stress that future professionals must acquire not only advanced technical expertise but also ethical and legal literacy to responsibly engage with generative AI systems. For policymakers, our cross-national comparison highlights that copyright reforms must be designed with cultural and educational contexts in mind. A uniform, one-size-fits-all global framework risks overlooking the diverse perspectives on responsibility, authorship, and enforcement present in different jurisdictions. We also recognize the study’s limitations. The reliance on Likert-scale survey items restricts the depth of individual reasoning, and the sample is limited to two countries and one academic discipline. Future research could broaden the scope through qualitative interviews and inclusion of participants from multiple disciplines, offering a more comprehensive understanding of the issues.
In conclusion, as AI continues to redefine the boundaries of authorship and ownership, our findings underscore the critical importance of understanding the perceptions of those who will develop, deploy, and regulate these technologies. By capturing the nuanced views of game software students in South Korea and Vietnam, this research provides timely and evidence-based contributions to educational practice, policy formulation, and the global discourse on AI and copyright.
Author Contributions
Hye-Young Kim conceptualized the research framework and coordinated the study design. GwanHyeon James Koh the data analysis using a quantitative approach, applying the principal component analysis (PCA) and Bartlett’s test of sphericity to examine the suitability of the dataset for factor analysis. The analysis also included the derivation of inter-item correlations and factor structures, implemented in Python within the Jupyter Notebook environment, and the systematic organization of the results
Acknowledgments
This study was supported by the Culture, Sports and Tourism R&D Program through the Korea Creative Content Agency grant funded by the Ministry of Culture, Sports, and Tourism in 2024 (Project Name: Global Talent Training Program for Copyright Management Technology in Game Contents, Project Number: RS-2024-00396709, Contribution Rate: 100%).
References
[1] J. C. Ginsburg and L. Budiardjo, “Authors and machines,” Columbia Public Law Research Paper, no. 14-612, 2019. [Online]. Available: https://doi.org/10.2139/ssrn.3476906.
[2] A. Elgammal, B. Liu, M. Elhoseiny, and M. Mazzone, “Can AI create art? Learning-based art generation, the case of AICAN,” J. Vis. Cult., vol. 19, no. 1, pp. 45–67, 2020.
[3] P. Samuelson, “Allocating ownership rights in computer-generated works,” Univ. Calif. Law Rev., vol. 108, no. 3, pp. 801–854, 2020.
[4] S. Zhou, M. Lee, and R. Thomas, “AI in plagiarism detection: A systematic review of tools and trends,” IEEE Trans. Learn. Technol., vol. 14, no. 1, pp. 78–92, 2021. [Online]. Available: https://doi.org/10.1109/TLT.2021.3054102.
[5] Y. Jang, J. Kim, H. Lee and Y. Seo, “Generative AI-driven Graphic Pipeline for Web-based Editing of 4D Volumetric Data,” Journal of Web Engineering. Vol. 24, no. 1, pp. 135–162, 2025.
[6] K. Shim, B. Kim and W. Lee, “Research on Quantum Key, Distribution Key and Post-quantum Cryptography Key Applied Protocols for Data Science and Web Security,” Journal of Web Engineering. Vol. 23, no. 6, pp. 813–830, 2024.
[7] Y. Kim and D. Lee, “AI-generated music and copyright law in Korea: Legal challenges and future directions,” Seoul Law Rev., vol. 43, no. 2, pp. 201–225, 2021.
[8] H. Ito and J. Kim, “Digital literacy and legal awareness in East Asian tech students: A cross-national comparison,” Asian Educ. Rev., vol. 19, no. 1, pp. 56–72, 2021.
[9] K. Park, M. Choi, and H. Shin, “Perceptions of AI and ownership among Korean engineering students,” J. Eng. Ethics Educ., vol. 13, no. 2, pp. 88–105, 2021.
[10] S. Lee and T. Yamada, “Comparing AI ethics education in Korea and Japan: Institutional approaches and student perceptions,” J. Comp. Technol. Educ., vol. 16, no. 3, pp. 101–117, 2022.
[11] M. T. Tran, “AI and copyright challenges in Vietnam: A review of legal gaps and enforcement needs,” Vietnam J. Law Technol., vol. 11, no. 3, pp. 32–45, 2023.
[12] R. Abbott, “The reasonable robot: Artificial intelligence and the law,” Cambridge Univ. Press, 2020.
[13] H. Surden, “Artificial intelligence and law: An overview,” Ga. State Univ. Law Rev., vol. 35, no. 4, pp. 1305–1338, 2019.
[14] B. Hugenholtz, “Copyright and artificial creativity: Why copyright cannot fix the problem,” IIC, vol. 51, pp. 1001–1020, 2020.
[15] S. Stokes, “Art and copyright in the age of AI,” J. Intellectual Property Law & Practice, vol. 16, no. 9, pp. 793–801, 2021.
[16] W. Liu, “Who owns AI-generated content? Comparing emerging models in China, UK, and US,” J. Copyright Soc., vol. 68, no. 2, pp. 123–152, 2021.
[17] A. S. Narayanan and S. M. Rubin, “Machine learning for copyright enforcement,” ACM Comput. Surveys, vol. 54, no. 3, pp. 1–39, 2022.
[18] L. Liu, J. Wang, and X. Xu, “A CNN-based plagiarism detection model with attention mechanism,” Expert Syst. Appl., vol. 176, 2021.
[19] T. Zhang and M. Li, “Detecting visual infringement in AI-generated media using GAN features,” Pattern Recognit., vol. 129, 2022.
[20] B. Koops, “The trouble with algorithmic enforcement,” Comput. Law Rev. Int., vol. 21, no. 3, pp. 73–80, 2020.
[21] N. Eidelman and S. Sarid, “Do students understand AI copyright? A case study in Israeli CS education,” Int. J. Technol. Educ., vol. 13, no. 2, pp. 88–102, 2021.
[22] J. Chen, Y. Huang, and C. Lin, “University students’ attitudes toward AI-generated content and IP rights,” J. Ethics Inf. Technol., vol. 23, no. 4, pp. 389–403, 2021.
[23] M. Ahmad, K. Kwan, and S. Nguyen, “Cross-cultural analysis of AI authorship attitudes among ASEAN students,” Asian J. Digit. Rights, vol. 5, no. 1, pp. 51–70, 2023.
[24] Bartlett, M. S. (1954). A note on the multiplying factors for various chi-square approximations. Journal of the Royal Statistical Society: Series B (Methodological), 16(2), 296–298.
[25] Kaiser, H. F. (1974). An index of factorial simplicity. Psychometrika, 39(1), 31–36.
Biographies

Hey-Young Kim received her Ph.D. degree in Computer Science and Engineering from the Korea University, South Korea in February 2005. During her Ph.D. studies, she focused on location management scheme and traffic modelling for mobile IPv6, cellular network and network mobility. She developed a network protocol for 9 years while working as a senior researcher at Hyundai Electronics. Recently, she has been working as a Full Professor at Hongik University, South Korea, since March 2007. Her research interests include traffic modelling, load balancing scheme and copyright technology for digital content on blockchain and web3.

GwanHyeon James Koh received his B.Sc. degree in Mathematics, Specialization in Economics, from the University of Chicago, USA in December 2022. He is currently affiliated with Capstone Partners Co., Ltd., focusing on investment analysis, including market research in AI and deep-tech industries, shortlisting potential firms, and conducting due diligence through investment memoranda and valuation analyses. His research interests include quantitative finance, with expertise in principal component analysis (PCA), Bartlett’s test of sphericity, and factor analysis for identifying latent risk factors and market structures. He applies advanced statistical modelling and visualization techniques in Python to financial econometrics, portfolio analysis, and AI-assisted investment strategies.
Journal of Web Engineering, Vol. 24_8, 1181–1202.
doi: 10.13052/jwe1540-9589.2481
© 2025 River Publishers