A Hyper-personalized, Context-aware Café Recommendation Mobile Application Integrating Real-time Environmental Sensing and Augmented Reality
Haekyung Chung1 and Janghyok Ko2,*
1Department of Visual Communication and Media Design, Konkuk University, Chungcheongbuk-do, 27478, Republic of Korea
2Division of Artificial Intelligence Convergence, Sahmyook University, Seoul, 01811, Republic of Korea
E-mail: jangmi44@gmail.com; janghyokko@syu.ac.kr
*Corresponding Author
Received 09 September 2025; Accepted 05 November 2025
Abstract
This study aims to develop an innovative recommendation system that provides a tailored café experience by integrating users’ nuanced preferences with a real-time environmental context. With the recent surge in domestic coffee consumption, the café market has reached a saturation point, leading consumers to seek spaces that match a specific atmosphere or purpose beyond merely consuming beverages. Existing recommendation systems, which primarily rely on past ratings or static information, have shown limitations in meeting these dynamic and multidimensional demands. To overcome these limitations, this paper proposes a novel framework that fuses hyper-personalization, context-aware recommendation, acoustic scene classification (ASC), passive crowd density estimation, and location-based augmented reality (AR). The proposed system utilizes a large language model (LLM) to extract abstract atmospheric characteristics such as “cozy,” “vibrant,” or “suitable for work” from unstructured text data collected from social media and review platforms. Simultaneously, it quantifies the actual environment of a space by analyzing real-time data collected through in-store sensors (or user devices). Specifically, ASC technology identifies the qualitative characteristics of sound – such as conversations, background music, and machine noise – going beyond simple noise levels. Passive detection of smartphone Wi-Fi probe signals accurately estimates indoor crowd density without infringing on personal privacy. This multi-modal data is combined with user profiles to generate a list of recommendations optimized for each individual. Finally, users can have an immersive exploration experience through a location-based AR interface, visually confirming recommended cafés, friends’ reviews, and personalized notes overlaid on their real-world surroundings. Through the synergistic combination of these advanced technologies, this research presents the design and implementation potential of a system that shifts the paradigm of physical space recommendation and provides a truly experience-centric service.
Keywords: Artificial intelligence, Machine learning, Experience service design, UX design, Large language model, Café recommendation.
1 Introduction
1.1 The Rise of the Experience Economy and Hyper-personalization
As of 2025, in the digitally native economic environment, consumer selection criteria have shifted from the mere utility of products to the quality of the experience. This deepening of the “experience economy” demands a new paradigm in the mobile application market, creating a competitive landscape where providing a generic experience is no longer sufficient to acquire and retain users. The core strategy of this new era is “hyper-personalization,” which involves using real-time data, artificial intelligence, and machine learning to instantly provide experiences tailored to each user’s unique preferences, behavioral patterns, and current needs. Hyper-personalization transcends traditional personalization, which might involve addressing a user by name or recommending products based on past purchases. It takes a proactive approach, analyzing user behavior to predict future needs and respond pre-emptively. The key features of hyper-personalization can be summarized as dynamic content delivery, deep behavioral insights, and real-time adjustment capabilities. This approach fosters a deep connection between the user and the application, increases loyalty, and ultimately acts as a decisive factor in ensuring the service’s sustainability. This trend is particularly prominent in the context of choosing a café. For modern consumers, a café is no longer just a place to drink coffee. It can be a quiet workspace, a social venue for conversations with friends, or a place of rest that provides aesthetic satisfaction. A user’s need for a “quiet café to focus on work” is a real-time, context-dependent requirement that cannot be met by past visit records alone. Therefore, there is a pressing need for a hyper-personalized recommendation system that understands dynamic environmental factors like the current atmosphere, crowd density, and type of noise, and connects them with the user’s immediate purpose.
1.2 Limitations of Traditional Recommendation Paradigms
The problem is that existing recommendation systems have structural limitations in handling these complex demands. Traditional paradigms such as collaborative filtering and content-based filtering have shown excellent performance in recommending standardized “items” like products, movies, or music. However, they face clear difficulties in recommending amorphous and multidimensional concepts like “atmosphere” or “environment.”
These systems not only face issues like data sparsity or the cold-start problem but, more fundamentally, lack the capability to process the rich, unstructured contextual data that defines the atmosphere of a physical space.
Characteristics like a café’s “vintage vibe” or “environment suitable for conversation” exist implicitly within the text of user reviews, social media photos, and complex signals like the actual noise and crowd density of the space. Existing models based on rating matrices or static item attributes cannot understand and model this high-dimensional semantic information.
At this juncture, the emergence of large language models (LLMs) signals a significant turning point. LLMs have the potential to bridge the gap between structured and unstructured data by understanding the subtle meanings embedded in users’ preferences expressed in natural language and review texts. This opens the door for recommendation systems to move beyond simply recommending “what” to suggesting “what kind of experience.”
1.3 Research Gaps and Proposed Contributions
To date, research has shown a clear gap in the form of a lack of a holistic system that integrates real-time environmental sensing technology with a deep semantic understanding of user preferences to provide location-based recommendations. While individual technologies (e.g., crowd density detection, location-based recommendations) exist, attempts to organically combine them to address the user’s complex “experiential needs” have been insufficient. To bridge this gap, this paper proposes a new system with the following three core contributions:
Hyper-personalization engine: An advanced machine learning-based hyper-personalization engine, particularly one based on LLMs, to understand the user’s subtle intentions. This goes beyond filtered preferences to extract users’ latent tastes from unstructured data like review texts.
Real-time environmental data integration: Collection and analysis of real-time environmental data through specialized technologies such as crowd density estimation and acoustic scene analysis. This maximizes the contextual accuracy of recommendations, providing information that most closely resembles the actual environment at the time of the user’s visit.
Immersive user interface: A user-centric, highly immersive interface provided through location-based augmented reality (AR) and gamification. This not only enhances the efficiency of information delivery but also encourages active user participation, creating a virtuous cycle that continuously improves the system’s data quality.
Through this integrated approach, this study aims to present a blueprint for a next-generation intelligent service that goes beyond simple information provision to recommend an optimized “experience” for the user.
2 Related Work
2.1 Analysis of Commercial and Patented Prior Art
To understand the distinctiveness of the system proposed in this study, it is necessary to first analyze related technologies that have been commercialized or registered as patents. These technologies demonstrate gradual, function-centric innovations that reflect market demands.
Prior Art 1 (Patent Publication 10-2021-0037206) focuses on in-store crowd density detection (Figure 1). This technology determines the level of congestion by identifying the number of customers in a store by comparing their location information with the store’s map information and further correcting for errors by considering order reception locations. While it relates to one aspect of our study – providing real-time congestion information – it is limited in that its measurement method relies solely on location data and does not consider other environmental factors.
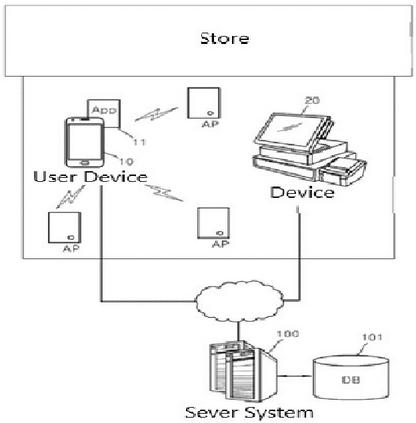
Figure 1 Prior Art 1 (Patent Publication 10-2021-0037206).
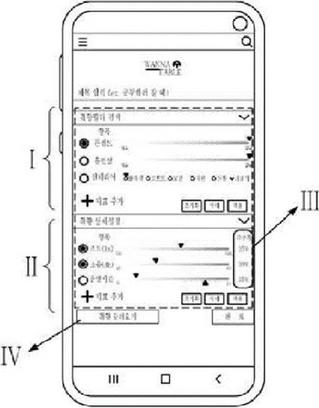
Figure 2 Prior Art 2 (Registered Patent No. 10-2104517).
Prior Art 2 (Registered Patent 10-2104517) deals with recommending café tables that reflect individual detailed preferences (Figure 2). Users can input micro-level spatial information such as interior concept, lighting, noise, congestion, and table shape. The system then matches this with table information collected via indoor positioning technology and sensors. Although it shares similarities with our study in receiving detailed user preferences, its recommendation scope is limited to the table level and fails to integrate dynamic data sources like external reviews or real-time acoustic analysis.
Prior Art 3 (Patent Publication 10-2022-0096234) concerns an integrated café information provision system (Figure 3). This technology offers various categories such as radius based on current location, operating hours, menu, price, and interior theme, with a particular emphasis on filtering for convenience services like “No Kids Zone,” “Pets Allowed,” and “Parking Available.” It also supports communication between users and operators through a community feature. While it aligns with our study in providing comprehensive information, the information is mostly static and lacks dynamic recommendation features that reflect real-time environmental changes or deep user preferences.

Figure 3 Prior Art 3 (Patent Publication 10-2022-0096234).
These prior patented technologies offer engineering solutions at a functional level for specific problems like congestion, detailed preferences, and convenience information. However, they operate within the existing “filter-then-rank” recommendation model framework and do not fundamentally change the paradigm of the recommendation system itself.
2.2 Advancements in Academic Recommender Systems
In academia, research has been actively conducted to advance the fundamental performance and concepts of recommender systems. This includes not just adding functions but transforming the very way recommendations are made.
2.2.1 From collaborative filtering to context-aware systems
Early research in recommender systems focused on “collaborative filtering.” This method generates recommendations by analyzing a user-item rating matrix based on the assumption that “I will also like items that other users with similar tastes to mine prefer”. While highly effective, this method faced cold-start problems and data sparsity issues, where recommendation performance degraded due to a lack of data for new users or items.
To overcome these limitations, context-aware recommender systems (CARSs) emerged. CARSs consider the “context” in which a recommendation is made as an additional dimension, alongside user and item information. For example, contextual information such as time, day of the week, and the user’s current activity can significantly improve recommendation accuracy. Particularly relevant to this study, location-aware recommender systems (LARSs) are a subfield of CARSs that use the user’s geographical location as key contextual information. LARSs are based on the intuition that users prefer restaurants, museums, and shops that are physically close, laying the academic foundation for location-based service recommendations.
2.2.2 Paradigm shift: Large language models (LLMs) in recommender systems
In recent years, the most innovative change in the field of recommender systems has been triggered by the advent of large language models (LLMs). LLMs are leading a fundamental paradigm shift by expanding the concept of recommendation from numerical rating prediction to semantic understanding and generation.
LLMs for semantic understanding: One of the biggest challenges in traditional recommender systems was utilizing unstructured text data such as user reviews or item descriptions. LLMs provide a powerful tool to solve this problem. They eliminate the need for manual feature engineering and representation learning, automatically converting raw text into semantically rich embeddings.
For example, from a review like “This café was quiet and cosy, great for reading a book,” latent atmospheric features such as “quietness,” “cosiness,” and “suitability for reading” can be extracted and used as input for the recommendation model. This allows for the modelling of subtle user preferences that existing models could not capture.
LLMs as recommendation engines: Beyond being mere feature extractors, LLMs can function directly as the core engine of the recommendation pipeline. Recent research has proposed two main paradigms: “LLM-as-retriever” and “LLM-as-ranker”. “LLM-as-retriever” uses an LLM to efficiently search for a candidate group of items highly relevant to a user’s history or query from the entire item pool. “LLM-as-ranker” then has the LLM deeply infer the user’s preferences for this retrieved candidate group to determine the final ranking. These two paradigms transform the recommendation process into an end-to-end, language-based reasoning process.
Generative recommendation (genre): At the forefront of LLM-based recommendation is generative recommendation (genre). In this paradigm, the LLM goes beyond simply ranking existing items to “generating” the recommendation itself as natural language text.
For instance, the system could generate a personalized and explainable recommendation sentence like, “Since you prefer vintage furniture and spacious tables, we recommend you visit the newly opened ‘Piece of Time’ café. It has a similar atmosphere to ‘The Old Library,’ which you enjoyed.” This has the potential to increase the transparency of recommendations and dramatically improve the user experience.
Thus, academic research is evolving recommender systems from simple filtering tools into intelligent agents that can deeply understand user intent and context and even make creative suggestions (Table 1).
Table 1 Compares the system proposed in this study with prior patented technologies and academic approaches, clearly highlighting its originality and contributions.
| Approach | Data Sources | Personalization Method | Context-Awareness Level | Key Innovations and Limitations |
| Prior Art 1 | User location, store map | None (batch information) | Low (only congestion) | Innovation: Real-time congestion measurement. Limitation: No personalization, single-dimension info. |
| Prior Art 2 | User input (filters), sensors | Explicit filtering | Medium (static info like noise, lighting) | Innovation: Micro-spatial unit recommendation. Limitation: Lacks dynamic/real-time data. |
| Prior Art 3 | Static DB (menu, hours, services) | Explicit filtering | Low (static convenience info) | Innovation: Integrated info & community. Limitation: Lacks real-time and deep personalization. |
| Traditional CARS/LARS | Ratings, history, location, time | Collaborative/content-based | Medium (context variables like location/time) | Innovation: Integrates context into recommendations. Limitation: Lacks unstructured data processing. |
| LLM-based RecSys | Ratings, history, text reviews | LLM-based semantic inference (LLM-as-ranker) | High (textual context understanding | Innovation: Deep personalization via NLP. Limitation: Lacks real-time physical environment data. |
| Proposed system | Reviews, location, history, real-time acoustics, real-time Wi-Fi signals | LLM-based inference + real-time data fusion | Very high (semantic + physical real-time context) | Innovation: Holistic experience recommendation combining semantic understanding and real-time physical sensing |
3 Proposed System Architecture and Differentiated Features
The system proposed in this study has a multi-layered architecture that organically integrates several technologies to meet the complex needs of users. The core of the system consists of a recommendation engine that deeply understands user preferences, a sensing module that detects the actual environment in real-time, and an interface that provides an immersive experience.
3.1 Multi-modal, Hyper-personalized Recommendation Engine
The heart of the system, the recommendation engine, processes a multi-modal input vector to generate hyper-personalized recommendations. This input vector includes explicitly selected filters by the user, behavioral history such as clicks and “likes” within the app, contextual data like time of day and current location, and a semantic profile extracted from unstructured data. A key differentiator of this system is its analysis of a vast amount of café reviews collected from various external platforms such as Naver, Google Maps, and Kakao Maps. For this, a fine-tuned LLM based on models like BERT or newer architectures is utilized. This LLM is responsible for extracting latent atmospheric features – such as “Instagrammable,” “cozy,” “vibrant,” or “good for focusing on work” – from unstructured text, which are difficult to formalize. These extracted high-dimensional semantic features are combined with traditional static attributes (e.g., price range, menu type) used by recommendation models, serving as input for a sophisticated model that reflects even the user’s implicit tastes. This is an attempt to understand not just “what” the user liked, but “why” they liked it, fundamentally improving the quality of recommendations.
3.2 Real-time Environmental Sensing for Atmosphere Analysis
The proposed system introduces real-time environmental sensing technology to predict and reflect the actual environment at the time of the user’s visit. This grants a dynamic context-awareness capability that existing recommendation systems lacked, measuring the two key factors of “crowd density” and “noise” in a scientific and systematic manner. This approach elevates the app’s core functions beyond simple metric provision to the application of two mature scientific fields: acoustic scene classification and passive wireless crowd sensing. This demonstrates not just “what” the system does, but “how” it does it in a scientifically valid and robust way, thereby maximizing the study’s academic contribution.
3.2.1 Crowd density estimation via passive Wi-Fi probing
Traditional methods for measuring crowd density required CCTV video analysis or the installation of dedicated sensors, leading to cost and privacy issues. To solve these problems, this system proposes a privacy-preserving passive Wi-Fi probing method. Most smartphones, when Wi-Fi is enabled, periodically broadcast probe request signals containing unique identification information to find nearby access points. The system passively collects these signals through low-cost sensors installed in the store. The MAC addresses in the collected data are immediately hashed for anonymization. The system then estimates the number of smartphone users in the store by counting the number of unique MAC addresses detected within a certain time frame.
Furthermore, by analyzing the received signal strength indicator (RSSI) values, it probabilistically distinguishes whether a user is inside the store or just passing by outside based on signal strength, thereby increasing the accuracy of the estimation. This method is a powerful and efficient way to obtain objective, real-time crowd density data without requiring any user interaction or personal information.
3.2.2 Atmosphere characterization through acoustic scene classification (ASC)
“Noise,” a critical factor in determining a café’s atmosphere, cannot be properly characterized by a simple decibel (dB) level. For example, a 60 dB noise level can provide a completely different experience to the user depending on whether it is calm background music, lively conversation, or a loud coffee machine. To distinguish these qualitative differences in noise, this system introduces acoustic scene classification (ASC) technology.
ASC is a research field that classifies a scene by recognizing the unique acoustic features of a specific environment.
The system collects short audio data clips through microphones installed in the store or, with user consent, through the smartphone’s microphone. This data is fed into a lightweight convolutional neural network (CNN) model pre-trained on an urban acoustic dataset like TAU Urban Acoustic Scenes. The model analyzes the input sound and classifies the current acoustic scene into meaningful categories such as “mostly conversation,” “background music dominant,” “quiet study atmosphere,” or “machine noise.” This classification result is then passed to the recommendation engine and serves as a crucial basis for recommending different cafés to a user looking for a “good place for conversation” versus one looking for a “quiet place to study.”
3.3 Interactive Café Map via Location-based Augmented Reality (AR)
To overcome the limitations of traditional 2D map interfaces and provide users with a more intuitive and immersive experience, this system specifically implements the abstract concept of a “metaverse map” through location-based AR technology. This functions not just as a user interface but as a two-sided market platform connecting users and café operators. When a user activates the app’s AR viewer and points their smartphone camera at the surrounding street, digital information is overlaid on the real world.
The user can see personalized recommended cafés, places they previously “liked,” and user-generated content (UGC) such as friends’ reviews or photos floating as icons or info windows around their location. This allows users to intuitively explore information and discover destinations in the scenery before them instead of trying to gauge locations on a map. Simultaneously, this AR map provides a new marketing channel for café operators. Operators can display AR-based promotional coupons at their café’s location or create an “interactive storefront” where a 3D model of a new menu item appears when the front window is scanned. For example, an experience layer created by a user titled “My Favorite Quiet Study Cafés Map” and a promotion layer created by a café offering “10% off for nearby visitors” can intersect in the AR space to create new value. As such, the AR map functions as a dynamic economic platform connecting users seeking experiences with operators providing them, going beyond a simple information visualization tool.
3.4 Gamification System for User-generated Data Contribution
The previously described acoustic scene classification and crowd density estimation models require a continuous supply of high-quality labeled data to maintain high accuracy. Collecting this data by professional personnel is a costly and time-consuming task. This system introduces gamification as a key strategy to solve this data collection bottleneck. The “point provision” or “reward” system within the app is not merely a marketing tool to encourage repeat visits. It is a strategic engine that motivates users to act as distributed sensors.
Users can participate in simple quests, such as confirming the actual crowd level (“pleasant,” “moderate,” “crowded”) after visiting a café or selecting the type of sound they currently hear (e.g., “conversation,” “music”). Users who participate in these activities receive points as a reward, which can be used for discounts at partner cafés or to participate in special events. This process creates a powerful virtuous cycle that continuously improves the system’s performance. That is, more user participation generates more accurate and richer training data, which leads to improved performance of the recommendation model. The improved recommendation quality, in turn, increases user satisfaction, encouraging more participation. Thus, gamification is a crucial mechanism that transforms users from passive consumers of the service into key participants in the ecosystem who actively contribute to data generation and model improvement.
4 Service Model and UI/UX Design
The service model of this system focuses on translating the technical architecture described earlier into a user-friendly experience. Each stage of the user journey is designed to be intuitive and efficient, reflecting the latest UI/UX design trends.
4.1 User-customized Café Recommendations
Upon launching the app, users can express their immediate needs through various filters. These filters include menu-based conditions like “dessert spot,” “great coffee,” “serves brunch,” convenience conditions like “no kids zone,” “pets allowed,” and mood conditions such as “modern,” “kitsch,” “antique,” or “minimal”.
When a user selects conditions, the recommendation engine synthesizes these explicit demands with the user’s behavioral history and latent preferences derived from external review analysis to generate a personalized recommendation ranking. The results can be provided as a list sorted by recommendation rank, as shown in Figure 4, or displayed on a map centered on the user’s current or specified location. Throughout this process, the minimalist and intuitive design principles that are a major UX trend for 2024–2025 are applied, helping users focus on core content without unnecessary information.

Figure 4 Example of user-customized café recommendation UI (a personalized list of café recommendations generated based on user-selected mood and condition filters designed by Konkuk University Student’s Works, JuyoungLee).
4.2 Location-based Augmented Reality (AR) Café Map
Beyond list-based recommendations, users can experience a more immersive exploration through a location-based AR map, as shown in Figure 5. This feature actively reflects the trend of AR integration, which has become a key element of the mobile app experience in 2025.
Users can intuitively check the location, business hours, and real-time crowd and atmosphere information of recommended cafés by viewing the actual street through their smartphone camera.
Furthermore, users can create and share their own “café maps.” For example, they can create a map titled “My Personal Dessert Hotspots” that only displays their favorite dessert cafés and share it with friends through the in-app community or external social media. This map functions as a social space where users can interact with others’ avatars, and gamification elements, such as the avatar’s appearance changing based on the user’s café consumption patterns, are incorporated to encourage continuous engagement.

Figure 5 Example of location-based AR café map (AR interface with personalized recommendations, “liked” cafés, and user-generated content overlaid on the real environment designed by Konkuk University Student’s Works, JuyoungLee).
4.3 Reliable Information Provision Based on Acoustics and Crowd Density
When a user views the detailed information of a specific café, the system provides real-time measured crowd density and acoustic scene analysis results with clear visual indicators, as shown in Figure 6. Information such as “Current crowd level: Pleasant” or “Current atmosphere: Mostly conversation” serves as an important basis for the user’s decision to visit. To increase the reliability of this information, the system encourages user participation through the gamification mechanism described earlier. Users who contribute to noise or crowd density measurements after visiting a café are rewarded. Additionally, the accuracy of the information is continuously improved through multifaceted methods, such as considering order information or table occupancy data from affiliated cafés’ point of sale (POS) systems, or having the LLM analyze sentences related to time-specific congestion in review texts (e.g., “It was too crowded right after lunch, so it was hard to order”) to calculate expected congestion.
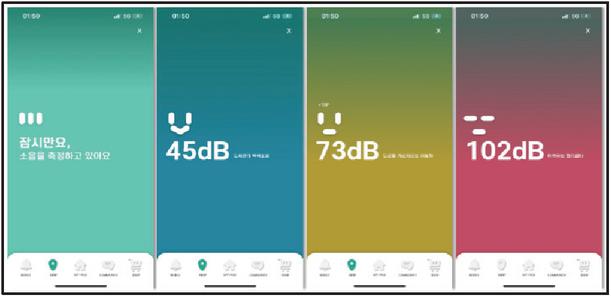
Figure 6 Example of UI for acoustic and crowd density information (visual provision of real-time crowd density and atmosphere information measured through acoustic scene classification and passive sensing designed by Konkuk University Student’s Works, JuyoungLee).
4.4 Point Provision and Reward System
Points are awarded for user contribution activities (writing reviews, measuring noise, sharing maps, etc.). This point system acts as a key driver for continuous user engagement. Accumulated points can be converted into tangible benefits such as discounts at partner cafés or opportunities to participate in special events, building a virtuous ecosystem that benefits users, the system, and partner cafés alike.
In terms of UI design, micro interactions are utilized to provide visual and auditory feedback when points are earned or rewards are used, creating a delightful experience for the user.
5 Conclusion and Future Work
5.1 Summary of Research Contributions
This study has proposed a comprehensive framework for the design and implementation of a next-generation café recommendation system that meets the technological environment and consumer demands of 2025. The key contributions of this research can be summarized as follows.
First, it designed a new integrated system for hyper-personalized café recommendations. By combining semantic analysis using LLMs, real-time environmental sensing, and user behavior data, it presented a novel approach to modeling and recommending abstract concepts like “atmosphere” and “experience,” which existing recommendation systems could not handle.
Second, it applied formal scientific methodologies – acoustic scene classification (ASC) and passive wireless sensing – to enhance the contextual accuracy of recommendations. This elevated the app’s core features of “noise” and “crowd density” from simple metrics to reliable and meaningful information, adding academic rigor to the study of physical space recommendation.
Third, it utilized location-based augmented reality (AR) as a core component of the user interface and business model. This not only provides an immersive exploration experience for users but also opens up possibilities as a two-sided market platform connecting users and local businesses, demonstrating the practical value and scalability of the technology.
5.2 Limitations
While the proposed system holds innovative potential, it has several limitations that must be considered during actual implementation and operation. First, although crowd density estimation via passive Wi-Fi probing anonymizes MAC addresses, potential privacy concerns may still exist. Therefore, efforts are needed to transparently disclose the data collection and processing procedures to users and to continuously strengthen data de-identification technologies. Second, performing acoustic scene classification directly on a device can be computationally expensive. Additional research on model quantization and efficient inference algorithms is required. Third, deploying and operating the proposed system at scale in real-world environments presents critical technical and infrastructural challenges. Implementing the necessary sensor infrastructure across numerous cafés would be resource-intensive and logistically complex, incurring significant installation and maintenance costs. Moreover, a large network of IoT sensors (for crowd and acoustic data) requires ongoing upkeep such as regular calibration and hardware replacements, which adds substantial operational overhead and may affect long-term sustainability. Additionally, scaling to many locations dramatically increases the volume of real-time data that must be processed, potentially introducing significant latency in generating recommendations. Ensuring timely responses under such load may necessitate a distributed computing architecture that balances processing tasks between edge devices and cloud servers. However, an edge-heavy approach is constrained by limited device resources and can complicate system design, whereas a cloud-centric approach risks network bottlenecks and reliance on stable connectivity. Therefore, careful architectural planning and further research are required to manage these scalability issues through strategies such as optimizing sensor deployment, leveraging efficient edge computing frameworks to reduce latency, and devising cost-effective maintenance plans. Finally, a gamification-based data collection system faces a “bootstrapping” problem, where it can be difficult to secure initial user participation and maintain data quality.
5.3 Future Research Directions
Future research could evolve this into a full-fledged generative recommendation (GenRec) model. Such a system could generate creative recommendations in natural language that include new combinations or explanations not present in the database, such as, “Since you prefer antique decor and quiet spaces, we recommend a café in the old city center with a similar atmosphere, which is not yet registered.”
Utilization of multi-modal LLMs: The development of multi-modal LLMs that can directly process not only text but also image and audio data will open new possibilities for this system. A future system could directly take as input a user-uploaded photo of a café’s interior or an audio clip collected by the ASC system to understand the space’s atmosphere more holistically and accurately.
Deepening ethical considerations: As hyper-personalization and ambient sensing technologies advance, in-depth research on ethical issues such as the fairness and transparency of recommendations, and user data control, must be conducted in parallel.
Designing mechanisms to prevent recommendation algorithms from producing biased results for certain groups and to allow users to clearly understand and control how their data is used will be an important subsequent research task.
Acknowledgment
This research was financially supported by Konkuk University in 2025, and the authors sincerely appreciate their support.
References
[1] Deshpande, Y., Murugesan, S., Ginige, A., Hansen, S., Schwabe, D., Gaedke, M., and White, B., “Web engineering,” Journal of Web Engineering, vol. 1, no. 1, pp. 003–017, 2002.
[2] Adomavicius, G., and Tuzhilin, A., “Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions,” IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 6, pp. 734–749, 2005.
[3] Shang, F., Zhao, F., Zhang, M., Sun, J., and Shi, J., “Personalized Recommendation Systems Powered By Large Language Models: Integrating Semantic Understanding and User Preferences,” International Journal of Innovative Research in Engineering and Management, vol. 11, no. 4, pp. 39–49, 2024.
[4] Adomavicius, G., and Tuzhilin, A., “Personalization and Recommender Systems,” INFORMS TutORials in Operations Research, pp. 66–81, 2008.
[5] Pani, S. K., Rao, A. K. S., and Padhi, S. K., “Hyper-Personalization Through Machine Learning,” ResearchGate, Jul. 2025.
[6] IBM, ‘What is Hyper-personalization?’, IBM Think Topics, Jan. 2025. [Online]. Available: https://www.ibm.com/think/topics/hyper-personalization.
[7] Xi, Y. et al., “End-to-End Personalization: Unifying Recommender Systems with Large Language Models,” arXiv preprint arXiv:2508.01514, 2025.
[8] Nordstone, ‘Hyper-Personalization in Mobile Apps: Trends for 2025’, Jan. 2025. [Online]. Available: https://www.researchgate.net/publication/393986665\_Hyper-Personalization\_Through\_Machine\_Learning.
[9] Wu, S. et al., “A Survey on the Integration of Large Language Models with Recommendation Systems,” MDPI, 2024.
[10] Lei, W. et al., “Enhancing LLM-Based Recommendations Through Personalized Reasoning,” arXiv preprint arXiv:2502.13845, 2025.
[11] Aparo, C., Bernardeschi, C., Lettieri, G., Lucattini, F., and Montanarella, S., “An Analysis System to Test Security of Software on Continuous Integration/Continuous Delivery Pipeline,” Journal of Web Engineering, vol. 21, no. 4, pp. 1045–1074, 2022.
[12] O’Leary, D. E., “Do Large Language Models Bias Human Evaluations?,” IEEE Intelligent Systems, vol. 39, no. 4, pp. 83–87, Jul.–Aug. 2024.
[13] Xu, Y., Liu, Y., Xu, H., and Tan, H., “AI-Driven UX/UI Design: Empirical Research and Applications in FinTech,” International Journal of Innovative Research in Computer Science & Technology, vol. 12, no. 4, pp. 99–109, Dec. 2024.
Biographies

Haekyung Chung is a professor in the Department of Visual Communication and Media Design at Konkuk University. She received her Ph.D. in Digital Media Design from Ewha Womans University. Her research focuses on combining service experience design with artificial intelligence, particularly in creating barrier-free cultural and artistic content applications. Her work aims to enhance accessibility and create more inclusive user experiences for everyone.

Janghyok Ko is an associate professor in the Division of Artificial Intelligence Convergence at Sahmyook University. He received his Ph.D. in Mechanical Engineering from Ohio State University. Prior to his current tenure at Sahmyook University, he worked as a Senior Research Engineer at Hyundai-Kia Research Center and as a Deputy Director in the Ministry of Land, Infrastructure and Transport (MOLIT), Korea. His research focuses on automotive engineering along with thermal sciences and recently his primary interest lies in AI-related smart vehicles.
Journal of Web Engineering, Vol. 24_8, 1283–1302.
doi: 10.13052/jwe1540-9589.2485
© 2025 River Publishers