Design and Analysis of Low Delay Deterministic Network Based on Data Mining Association Analysis
Jianhu Gong
School of Data and Computer Science, Guangdong Peizheng College, Guangzhou 510830, P.R. China
E-mail: 909153258@qq.com
Received 21 November 2020; Accepted 16 December 2020; Publication 09 March 2021
Abstract
The purpose of this paper is to research on the design and analysis of low delay deterministic network based on data mining association. This paper studies and implements the algorithm of mining page association rules. A session recognition algorithm based on log reference page and request time is proposed by using the time probability relationship of continuous requests. This method improves the accuracy of log data preprocessing and page association rules mining. This paper studies and tests the efficiency, prefetch timing and cache organization of the two page association rules. The results show that in this prefetch scheme, the prefetch performance of the association rules of unordered pages is better than that of the association rules of ordered pages. The prefetch performance when cache hits is better than that when cache fails and the cache fails to hit has better performance. In the case of a certain size of cache space, reasonable organization of cache space can further improve the cache hit rate and reduce the network delay.
Keywords: Cache, prefetch, unordered pages, association analysis, data mining.
1 Introduction
Network delay refers to the transmission of various kinds of data through network protocol (such as TCP/IP) in the network medium [1]. If the amount of information is too large and not limited, the excessive network traffic will lead to the slow response of equipment, resulting in network delay [2, 3].
In recent years, the field of data mining has a considerable demand for technologies for extracting knowledge from large and complex data sources. There are a large number of commercial applications and research activities in this field, aiming to develop new and improved methods for extracting information, relationships and patterns from data sets. Nowadays, the ubiquitous computer system records our behavior and lifestyle every day. While people continue to generate data records in various large databases every day, a large number of scientific applications are also continuously recording these data. For example, NASA’s Earth Orbiting Satellite System generates one byte of data every day; the Human Genome Project records and stores a large amount of genetic information in our body; molecular simulation can simulate the dynamic behavior of molecules, and generate large amounts of data stored in distribution data warehouse. The great progress of storage technology has made it possible to store all this information at a relatively low cost. However, simply providing data in the database does not make us better informed. People are facing the dilemma of “rich information” but “poor knowledge”, and the gap between recording information and understanding information is widening. Data mining can be used to bridge the gap between collecting and understanding information. It can be viewed as extracting meaningful and potentially useful patterns from a large database, or as the expression used previously as an “understanding” of the recorded “information”.
The diversity of applications and the continuous emergence of new tasks have contributed to the dynamic and rapid growth of the data mining field. A major aspect is the creation of a wide range of new data sets, from structured data such as relational databases to semi-structured data in formats such as XML and JSON. Therefore, it is unrealistic to attempt to build a mining system that meets all data types. In order to dig deeper into specific types of data, it is necessary to establish a system for specific applications. The other aspect includes Internet mining, multi-source data mining and information network mining. Compared with isolated databases/centrally discovered knowledge, the information interconnection network composed of huge, heterogeneous and widely distributed data sets contains more and richer patterns and knowledge. It is still a challenge to meet the above goals, and it is an active research field at the moment. Considering the continuous increase of data capacity, the wide distribution of data and the computational complexity of some data mining algorithms, it is necessary to ensure that the running time of the mining algorithm to process massive amounts of data is within an acceptable range, and the space complexity does not exceed the tolerance of the running machine. One solution is to develop parallel and distributed data-intensive mining algorithms. This algorithm first divides the data into several “fragments”, and then processes each fragment in parallel, and finally merges the patterns or rules explored by each part to discover knowledge. Cloud computing and cluster computing use distributed and coordinated computers to process ultra-large-scale computing tasks, which is an important direction for the study of parallel data mining. In addition, some high-overhead mining processes and incremental input have promoted the development of incremental data mining, that is, by binding with the update of new data, iteratively, they revise and strengthen the knowledge discovered in the industry incrementally.
Low delay deterministic network is the development direction of modern network. Cache technology is considered to be one of the effective ways to reduce server load, reduce network congestion and enhance network scalability [4]. Web caching technology mainly uses the time locality principle of customer access, that is, the recently accessed content is likely to be accessed again [5]. Store a copy of the user’s visited content in the cache. When the content is accessed next time, it does not need to connect to the hosted website, but is provided by the copy retained in the cache, so as to reduce the response time of the customer’s request [6, 7]. Web content can be cached on the client, proxy, and server side. The practical application shows that the cache technology can significantly improve the network performance mainly in the following aspects [8–10]:
(1) Some of the client’s requests can be obtained from the local cache without obtaining from the remote agent or server, thus reducing the network traffic and the possibility of network congestion.
(2) It can reduce the delay of customer access. The main reasons are:
– The contents of the cache can be obtained directly from the cache system rather than from the remote server, thus reducing the transmission delay;
– The content that is not cached can be acquired quickly by customers due to network congestion and server load reduction.
(3) Because of the existence of the web caching system, some requests of customers can be obtained by the caching system, which reduces the load of the remote server;
(4) If the remote server fails to respond to the customer’s request due to the failure of the remote server or network, the customer can obtain the cached document copy from the agent, which makes the network service more robust.
Therefore, in order to give full play to the advantages of prefetch technology, the research of prefetch technology in low delay deterministic networks must consider many factors such as accuracy, timeliness and cost performance. This paper focuses on the above issues.
The rest of this article is organized as follows. Section 2 discusses model analysis. Section 3 studies the data mining algorithm of page association rules. Section 4 tested the low delay deterministic network strategy. Section 5 summarizes the full text.
2 Model Analysis
2.1 Page Association Prefetch Model
The basic idea of page association prefetch model is to use the association relationship between web pages in customer access sequence to predict customer requests. The basic idea is to calculate the transfer probability between different web pages in the customer access record, and predict the next request content of the customer according to the size. Based on how many pages are requested in the customer’s current access sequence at forecast time. Page Association prefetch model can be divided into simple page association prefetch model and deep page association prefetch model.
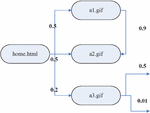
The simple page association prefetch model only considers the current request page of the customer, not the whole access sequence [11–13]. In this model, the set of web pages visited by users is regarded as the state set. According to the customer access record, the transfer probability between pages is calculated as the prefetch basis. The simple page association prefetch model is shown in Figure 1.
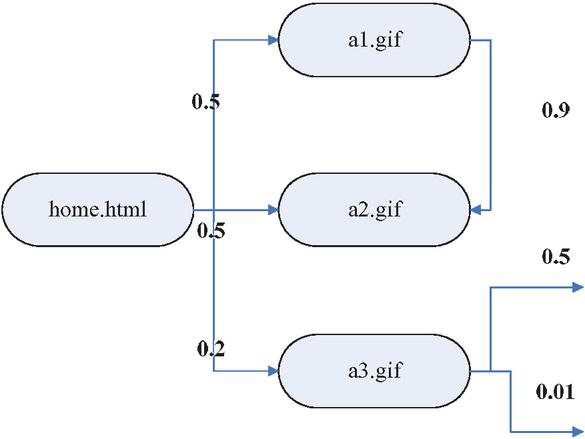
Figure 1 The simple page association prefetch model.
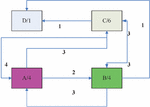
Reference [14] proposed to construct a customer access page association graph, use the customer’s historical access sequence to construct a page association graph, and determine the prefetched page based on the association relationship between other pages and the current page in the association graph [15–17]. Figure 2 is a page association diagram with forward-looking degree 2 constructed according to the access sequence ABCACBD and CCABCBCA. The direction of the arrow indicates the transfer relationship between pages, and the number on the arrow indicates the number of times the transfer occurs. If the current request page is A, it can be known from the association graph that the prefetch page may be B or C. If a probability interpretation value P is set, then whether to pre-fetch B or C is determined according to the comparison of P (B/A) and P (C/A) with the threshold P.
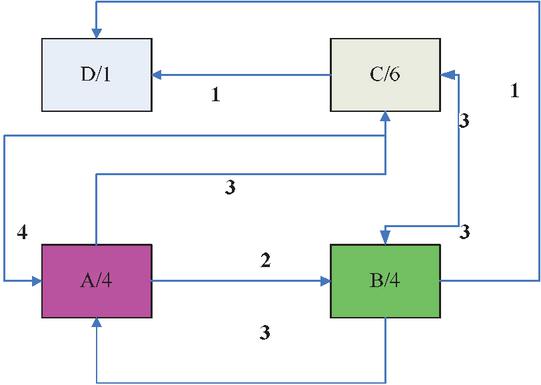
Figure 2 Page association diagram with forward-looking degree 2 constructed according to the access sequence.
The simple associative prefetch model is simple and direct, but it does not consider the customer’s current request sequence when prefetching, so the accuracy of prefetching is relatively poor. Suppose the customer visits the sequence ACD and BCE. If the customer currently visits AC, the next visit is D. If the customer currently visits BC, the next visit is E. If only the current page C is considered to predict the next request, an incorrect prediction result may be produced [18–20]. To this end, the deep correlation prediction method is introduced.
2.2 Deep Page Association Prefetch Model
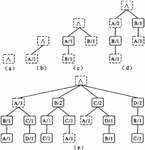
The main idea of deep page Association prefetch is to not only consider the current request of customers, but also consider the current request sequence of customers or the suffix sub-sequence of the current request sequence of customers, so as to improve the accuracy of prefetch [21–23]. The basic idea of prefetch model is to use the historical access sequence of customers to build a deep structure tree. The suffix sub-sequence of requests in the current request sequence of customers is used to predict the next request of the current request of customers [24, 25]. Figure 3 shows the construction process and results of the second-order ppm structure tree of the sequence ABACDBCA. The number next to the page indicates the number of times a page sequence occurs in the structure tree from the root node to the page node path.
This algorithm has obvious advantages:
(1) The algorithm has good scalability, which is reflected in two aspects: first, the depth of the algorithm can be determined by adjusting the size; second, when the customer generates a new access sequence, the structure tree is updated online directly on the basis of the original structure tree, with good real-time performance;
(2) The algorithm of building structure tree is efficient, which only needs to scan the access sequence of customers once;
(3) When forecasting the current requests of customers, the accuracy of prediction is relatively high because the current request sequence of customers is considered instead of the current request in isolation.
The shortcomings of depth page Association prefetch algorithm are shown in the following aspects:
(1) The spatial complexity is high. From Figure 4, it can be seen that the spatial complexity will be higher if a customer builds a PPM structure tree with a depth of more than 2 access sequences;
(2) The prediction needs to traverse the whole structure tree to match the sequence, which has low efficiency. No matter the prefetch fails or hits, the additional cost is high.
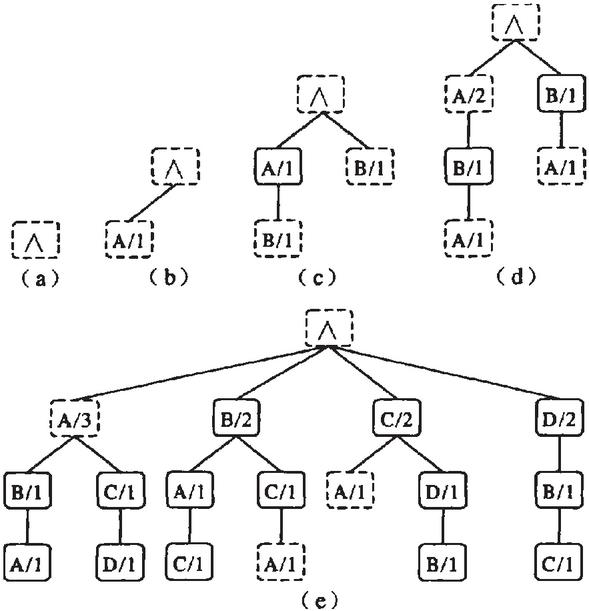
Figure 3 The construction process.
Figure 4 The spatial complexity.
2.3 Data Mining
Data mining is a hot topic in the field of artificial intelligence and database research. The so-called data mining refers to the extraordinary process of revealing the hidden, previously unknown and potentially valuable information from a large number of database data [26, 27]. Data mining is a kind of decision support process, which is mainly based on artificial intelligence, machine learning, pattern recognition, statistics, database, visualization technology, etc. it analyzes the data of enterprises highly automatically, makes inductive reasoning, excavates potential patterns from it, helps decision makers adjust market strategies, reduce risks, and make correct decisions. The process of knowledge discovery consists of three stages: (1) data preparation; (2) data mining; (3) result expression and interpretation. Data mining can interact with users or knowledge base.
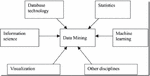
Data mining is a technology to find the rules from a large number of data by analyzing each data. It consists of three steps: data preparation, rule search and rule representation. Data preparation is to select the required data from the relevant data sources and integrate them into the data set for data mining; rule finding is to find out the rules contained in the data set in a certain way; rule representation is to express the found rules in a way that users can understand as much as possible (such as visualization). The tasks of data mining include association analysis, cluster analysis, classification analysis, anomaly analysis, specific group analysis and evolution analysis. The origins of data mining is shown in Figure 5.
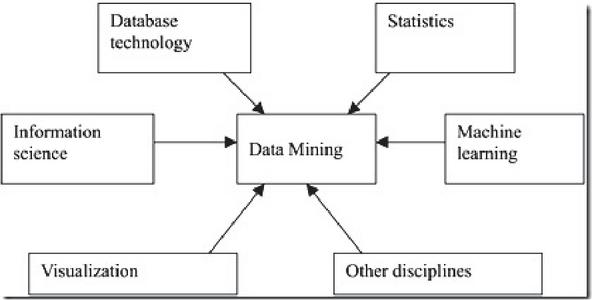
Figure 5 Spatial complexity block diagram.
In recent years, data mining has attracted great attention of the information industry. The main reason is that there are a large number of data, which can be widely used, and there is an urgent need to convert these data into useful information and knowledge. The acquired information and knowledge can be widely used in various applications, including business management, production control, market analysis, engineering design and scientific exploration. Data mining uses ideas from the following fields:
(1) sampling, estimation and hypothesis testing from statistics;
(2) search algorithm, modeling technology and learning theory of artificial intelligence, pattern recognition and machine learning.
Data mining has also rapidly embraced ideas from other areas, including optimization, evolutionary computing, information theory, signal processing, visualization and information retrieval. Some other areas also play an important supporting role. In particular, the database system is required to provide effective storage, index and query processing support. Technology derived from high-performance (parallel) computing is often important in dealing with massive data sets. Distributed technology can also help to deal with massive data, and when the data can’t be processed together, it is even more important.
3 Data Mining Algorithm of Page Association Rules
3.1 Data Sources
One of the key steps of data mining is to construct a data set suitable for the target task, which is the basis of data mining. All kinds of data collected from client, agent, server or website database are not only of different types, but also of different processing methods. The data collected from different data sources reflects different access patterns in Web usage. The data of client usually reflects the access behavior of single user and multi site. The data of agent records the usage of multi-user and multi site. The data of server describes the access behavior of multi-user and single site.
(1) Client data. The client data can be written or written remotely to help collect the data of single user and multi website access. It is much more accurate to collect users’ browsing behaviors directly on the client side than to record users’ visiting behaviors indirectly on the server side. However, the collection of user browsing data by remote in the client needs the consent of the user, otherwise the collection is difficult.
(2) Proxy data. A web proxy serves as the traffic road between the client browser and the server. The caching of the proxy helps to reduce the loading time of the web page in the client and the workload of the server. The agent can track requests from multiple clients to access multiple servers. The impact of caching on the server-side log content depends on the nature of the site content. If it is a dynamically generated web page, it will not be affected by the cache of the agent, but if it is a static web page, it may be greatly affected.
(3) Server side data. Web server log is an important data source in Web usage mining, which clearly records the browsing behavior of website users. But the server data also has its shortcomings. Because of the delay of cache and network transmission time, the information in the server log is not very reliable. Because transport protocol is a stateless protocol, it is difficult to track the whole browsing behavior of a single user. At this time, the server can be used to generate corresponding information for a single user’s access and browsing, which can help track the user’s website access trace. The server can also provide content server logs, which can provide information about the information content that users browse. In addition, the server can also provide information about the website, such as content data, structure information, local database, web metadata, such as file size and last modification time.
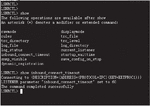
This paper mainly uses data mining technology to study the server-side prefetching technology. Under the current conditions, it is difficult to collect data from the client and the proxy server, so the data source of data mining in this topic is mainly the log files accessed by the client on the server. The extended log format is shown in Figure 6. Based on the common log format, it adds two information: reference page and client browser type manic system. These two information play an important role in user identification, session identification and transaction identification in the process of server log file preprocessing.
Figure 6 The extended log format.
3.2 Data Preprocessing
Various data sets required for Web usage mining are transformed into corresponding abstract data sets through preprocessing. For data source processing, you can use the method of record conversion data and transfer it to the traditional relational table, and use data mining algorithms to mine data in the relational table. In addition, the recorded data can be directly preprocessed and mined.
Data cleaning is to delete data items that are not related to mining tasks from the original server log files, so as to avoid misleading the analysis of users’ browsing behavior. Generally, the data to be deleted includes:
(1) Record of access request failure (based on the status code in the log record;
(2) The user request method is not a record of “get”;
(3) For the request record of embedded resources, the user usually does not actively request to display the graphics files and multimedia files in the site. Most of these files are downloaded automatically when the user requests to browse the page, which has nothing to do with the user’s browsing behavior.
You check the files with suffixes of “GIF, JPG, JPEG, JPG, JPEG, ICO, PNG” and clear the corresponding log records. But for some web pages with graphics and images as the main content, users may be really interested in these multimedia files. At this time, the log file items related to these pages can not be deleted casually, but should be handled according to the specific mining task.
User identification is to identify the corresponding users from each record in the log and identify which records belong to the same user. Due to the use of cache system, proxy server (including Internet bar, LAN and other environments) and firewall, user identification is very complex.
When using IP/agent to identify and server log files, the following typical situations are often encountered:
(1) The different users can access the same website through the same proxy server at the same time;
(2) The same user accesses the same website through multiple computers with different IP addresses (at different times), which makes it difficult to track repeated visits from the same user:
(3) The same user opens multiple browser (process) windows on the same computer at the same time and accesses different contents of the same website at the same time:
(4) Multiple users use the same computer to access content from the same web site.
Due to the above factors and the existence of the mainstream operating system, the accuracy of user identification through IP/agent is relatively low. However, because this subject adopts the prefetch scheme for group customers, it is not necessary to care whether “IP/agent” belongs to the same customer for the same multiple service sessions, as long as it can identify each service session of the customer.
3.3 Mining Page Association Rules
The algorithm proposed in this paper divides association rule mining into two steps:
(1) It iteratively identifies all frequent itemsets. The cyclic method of hierarchical sequential search is used to complete the mining of frequent item sets. This cyclic method is to use frequent K item sets to generate frequent (K 1) item sets. The specific method is: first find the frequent 1 item set, and then use the frequent 1 item set to mine the frequent 2 item set. This cycle continues until no more frequent item sets can be found, and the entire database needs to be scanned once for each layer of frequent item sets.
(2) It constructs rules from frequent items that have a credibility not lower than the minimum value set by the user.
(1) For each frequent item set F, all non-empty subsets of F are generated:
(2) For each non-empty subset s of F, if
| (1) |
Then an association rule is generated:
| (2) |
where min_conf is the minimum credibility threshold.
The rule mining algorithm for pages in this article draws on the basic ideas of the Apriori algorithm:
The first step is to find the frequent 1 item set and 2 frequent item sets in the customer conversation (transaction). The second step is to find out the association between two or two pages.
The relevant parameters are described as follows:
S: Customer conversation set;
: Total number of sessions in the client session;
TS: Customer conversation transaction set;
: Total number of session transactions in the client session transaction set;
min_supp: Minimum support value;
min_conf: Minimum credibility interpretation value;
P_count: Support frequency of page P;
PP_count: Frequency of support for the 2 item sets P, P on the page;
F1, F2: Represent frequent 1 item set and frequent 2 item set respectively.
Taking the client session as the research object, the order of page access in the session is not considered. As long as two pages appear in the same session at the same time, the two pages are considered to have potential association relationship.
The steps of mining association rules of unordered pages are as follows:
(1) From the customer conversation set, find out the page frequent 1 item set F1;
| (3) |
(2) Using the frequent 1 item set F1, find out the frequent 2 items F2 from the customer session set;
| (4) |
(3) Using formula (1) to judge whether each frequent set of 2 terms P, P can produce rules.
Taking customer session transaction as the research object, the sequence of two pages in session transaction is considered. If page A and B appear in a session transaction at the same time, and page B appears after page a, page B is considered to have a potential association with page a.
The steps of mining association rules of ordered pages are as follows:
(1) From the customer conversation set, find out the page frequent 1 item set F1;
| (5) |
(2) Using the frequent 1 item set F1, find out the frequent 2 items F2 from the customer session set;
| (6) |
(3) Using formula (1) to judge whether each frequent set of 2 terms P, P can produce rules.
4 Low Delay Deterministic Network Strategy Test
4.1 Test Plan and Evaluation Standard
The test data in this article is a log record of a website. Research on these log records has found that most customers usually click on less than one page per visit. “IP/Agent” is mostly below the same record, which means that it is very difficult to analyze the client’s access patterns on the server side due to the lack of sufficient information to analyze the client’s access pattern. On the other hand, the locality of content accessed by group customers is very obvious. Of the more than 3,000 effective access records, there are only one different page. This provides objective possibilities for analyzing the access patterns of customers in research groups. The test schemes are tested using the training data set and the test data set. The page association rule mining algorithm proposed in the previous section is used to mine the training data set to generate a rule base. On this basis, test data sets are used to test the prediction performance of these rules. The number of rules can be adjusted by adjusting the support and credibility thresholds when mining page association rules.
The support and credibility thresholds of the unordered page association rule base used here are 2% and 50%, respectively. The support and credibility thresholds of the ordered page association rule base are 2% and 30% respectively. In addition, in order to study the effect of information timeliness on prefetch performance, the log data of the above month is divided. The short term is divided into several days. The interim period is divided into weeks. The long-term division takes half a month as the time period.
The cache hit rate and server load rate are used to evaluate the prefetch strategy. Cache hit rates and services
The unit load rate is defined as follows:
Cache hit rate number of cache hit requests/total number of customer requests
Server load rate total client requests number of prefetch pages/total cache hit requests number of client requests
4.2 Test Results and Analysis
In order to better illustrate the problem, only the prefetch cache space is set in the test process, and the algorithm is used to replace the cache content, and the invalid prefetch strategy is used.
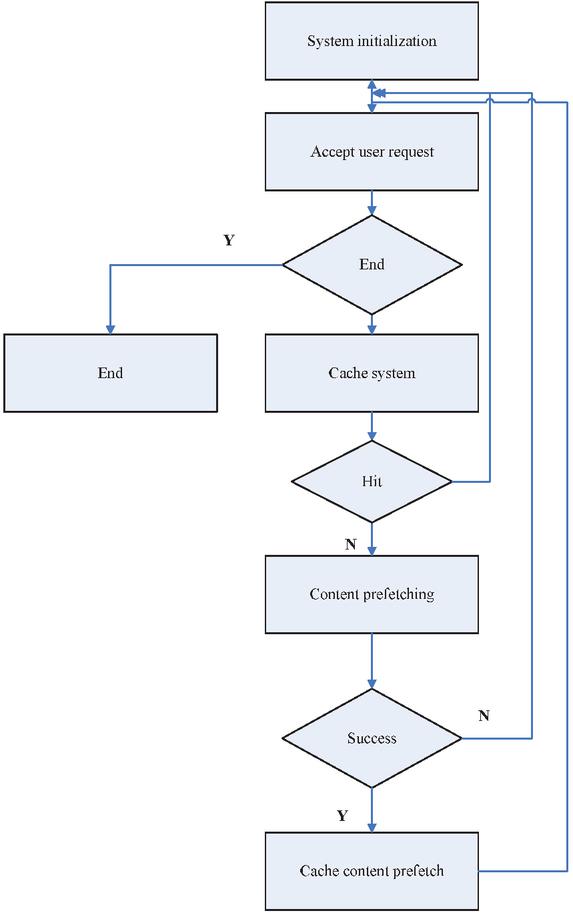
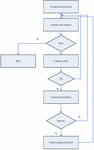
Figure 7 The test flow.
The test flow is shown in Figure 7. The specific process is described as follows:
(1) Receive customer request, the number of customer requests plus 1;
(2) Check whether there is a requested file in the cache queue. If so, move the file to the head of the queue. Add 1 to the cache hits, and go to step 1. Otherwise, go to step 3;
(3) You match the current request file with the rule left file in the rule library. If the match is successful, you add the right file of the corresponding rule to the first part of the cache file queue in turn. If the number of cache files is greater than the set value, you move the tail file of the queue out of the queue according to the LRU replacement method, and calculate the number of prefetch files. If the match is not successful, you go to step 1;
(4) Calculation results.
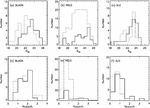
Here, short-term data, medium-term data, and long-term data were used to test the prediction performance of unordered page association rules and ordered page association rules, respectively. The test results show that the unordered page association rules are better than the ordered page association rules in overall performance. Since only the time factor is considered when dividing data, the amount of data in each data set varies greatly, which has a certain impact on the test results. To this end, the test results of the number of log records and the number of sessions of the training set and the test set are selected from short-term data, mid-term data, and long-term data for reference. The test results are shown in Figure 8.
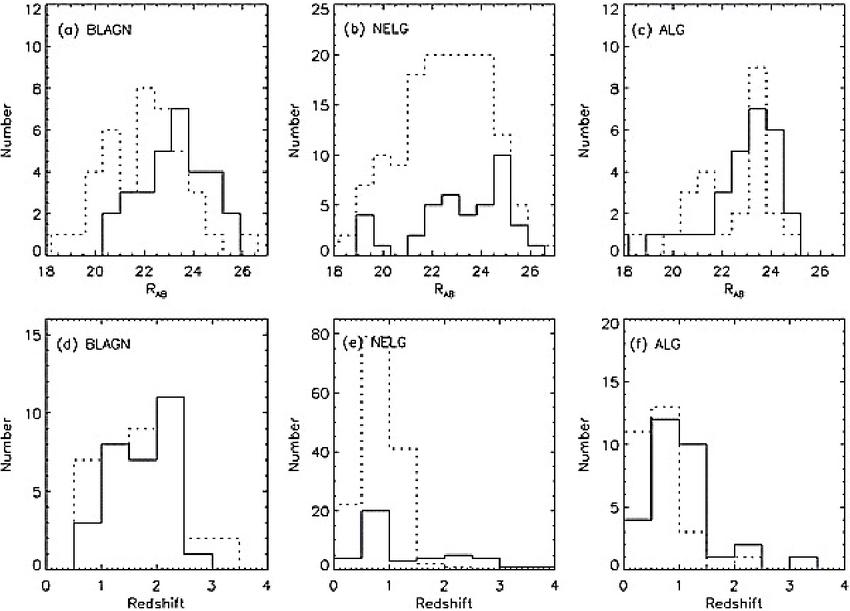
Figure 8 Low delay deterministic network strategy test result.
It can be seen from the figure: when the cache space is small, the difference between the cache hit rate of the unordered page association rules and the ordered page association rules is small. The server load of unordered page association rules is significantly higher than the server load of ordered page association rules as the cache space increases. The cache hit rate of the two gradually increases, and the server load gradually decreases. However, the cache hit rate growth rate of unordered page association rules is significantly higher than that of ordered page association rules. The server load of the unordered page association rule decreases more than the server load of the ordered page association rule; when the cache space increases to a certain extent, the cache hit rate of both will no longer increase, and the server load rate will no longer decline.
The above process can be explained as follows: when mining page association rules, the conditions for generating ordered page association rules are stricter, and they are far less in number than unordered page association rules. When the cache space is small, the unordered page association rules perform more prefetching, but due to limited cache space, only part of the prefetched content resides in the cache, so the cache hit rate is more prefetched than the ordered page association rules. It has no obvious improvement, but the server load is significantly higher than that of ordered page association rules prefetching. With the increase of cache space, the numerical advantages of unordered page association rules prefetching gradually show up, so the cache hit rate increases significantly, corresponding Ground, the server load has gradually decreased: when the cache space has grown to a certain level, after all the right pages of the rule have entered the cache, there will be no other content cache, so the cache hit rate and server load rate are stable.
It can also be seen from the figure that compared with long-term data, short-term data mining generates more association rules, the reason is that the locality of content accessed by group customers is time-phased. Website content update is a process of continuous accumulation. The content of short-term data is relatively concentrated, which can better reflect the current and current website content in a short period of time. The website content is concerned by customers, while long-term data is subject to long-term update of website content. The impact of the content is relatively scattered. When mining page association rules, it has a greater impact on support.
5 Conclusion
In today’s era of big data and artificial intelligence, data, algorithms, and computing power are particularly important. Designing algorithms to mine the knowledge and visualization value of “data association” from massive data is the core of data mining research. The test results show that: (1) Compared with cache technology alone, the combination of cache technology and prefetch technology can effectively improve cache hit rate and reduce server load rate; (2) In this prefetch scheme, the prefetch efficiency of unordered page association is better than that of ordered page Association; (3) The performance of prefetch on cache hit is better than that on cache failure and cache failure/hit; (4) In the case of a certain size of cache space, reasonable configuration of cache space can further play the effectiveness of the cache system; (5) The timeliness of data has a great influence on the results of prefetch.
References
[1] Prasan S, Sudhir P, Shih-Lin W. Design and Analysis of a Low Latency Deterministic Network MAC for Wireless Sensor Networks. Sensors, 2017, 17(10):2185–2193.
[2] Anwar M, Xia Y, Zhan Y. TDMA-Based IEEE 802.15.4 for Low-Latency Deterministic Control Applications. Industrial Informatics IEEE Transactions on, 2016, 12(1):338–347.
[3] Janssen J, Vleeschauwer DD, Petit GH, et al. Delay Bounds for Voice over IP Calls Transported over Satellite Access Networks. Mobile Networks & Applications, 2002, 7(1):79–89.
[4] Al-Nidawi Y, Yahya H, Kemp AH. Tackling Mobility in Low Latency Deterministic Multihop IEEE 802.15.4e Sensor Network. IEEE Sensors Journal, 2015, 16(5):1–10.
[5] Hu L, Cao X, Li Z. Reliability analysis of discrete time redundant system with imperfect switch and random uncertain lifetime. Journal of Intelligent and Fuzzy Systems, 2019, 37(1):1–12.
[6] Zhang P, Huang J, Zhou Z, et al. Joint category-level and discriminative feature learning networks for unsupervised domain adaptation. Journal of Intelligent and Fuzzy Systems, 2019, 37(3):1–12.
[7] Reinhold R, Underberg L, Wulf A, et al. Industrial WSN Based on IR-UWB and a Low-Latency MAC Protocol. Frequenz, 2016, 70(7–8):17–26.
[8] Whitt, Ward. Fluid Models for Multiserver Queues with Abandonments. Operations Research, 2006, 54(1):37–54.
[9] Chen M, Zhang J, Murthi MN, et al. Delay-based TCP congestion avoidance: A network calculus interpretation and performance improvements. Computer Networks, 2009, 53(9):1319–1340.
[10] Ouanteur C, Aissani D, Bouallouche-Medjkoune L, et al. Modeling and performance evaluation of the IEEE 802.15.4e LLDN mechanism designed for industrial applications in WSNs. Wireless Networks, 2017, 23(5):1343–1358.
[11] Golden BL, Magnanti TL. Deterministic Network Optimization: A Bibliography. Networks, 2006, 7(2):149–179.
[12] Tainiter M. A new deterministic network reliability measure. Networks, 1976, 6(3):191–204.
[13] Yang J, Reichert P, Abbaspour KC, et al. Hydrological modelling of the Chaohe Basin in China: Statistical model formulation and Bayesian inference. Journal of Hydrology, 2007, 340(3–4):167–182.
[14] Wang XL, Cai XD, Su ZE, et al. Quantum teleportation of multiple degrees of freedom of a single photon. Nature, 2015, 518(7540):516–519.
[15] Kellogg RA, Gómez-Sjuberg, Rafael, Leyrat AA, et al. High-throughput microfluidic single-cell analysis pipeline for studies of signaling dynamics. Nature Protocols, 2014, 9(7):1713–1726.
[16] Elsayed, K. M. F. A framework for end-to-end deterministic-delay service provisioning in multiservice packet networks. IEEE Transactions on Multimedia, 2005, 7(3):563–571.
[17] Ojo MO, Giordano S, Adami D, et al. Throughput Maximizing and Fair Scheduling Algorithms in Industrial Internet of Things Networks. IEEE Transactions on Industrial Informatics, 2018:1–12.
[18] Sensoy M, Yilmaz B, Yiltnaz E. An Intelligent Packet Loss Control Heuristic for Connectionless Real-Time Voice Communication. Mathematical Problems in Engineering, 2010, 2010(PT.1):p.48.1–48.9.
[19] Li Y. The Prediction Research of End-to-End Delay Upper Bound for Expedited Forwarding. signal processing, 2009.
[20] Andrews M, Zhang L. Creating templates to achieve low delay in multi-carrier frame-based wireless data systems. Wireless Networks, 2010, 16(6):1765–1776.
[21] Masoudi-Sobhanzadeh Y, Masoudi-Nejad A. Synthetic repurposing of drugs against hypertension: a datamining method based on association rules and a novel discrete algorithm. BMC bioinformatics, 2020, 21(1):1–21.
[22] Wang C, Zheng X. Application of improved time series Apriori algorithm by frequent itemsets in association rule data mining based on temporal constraint. Evolutionary Intelligence, 2020, 13(1):39–49.
[23] Moslehi F, Haeri A, Martínez-Álvarez F. A novel hybrid GA–PSO framework for mining quantitative association rules. Soft Computing, 2020, 24(6):4645–4666.
[24] Shao Z, Li Y, Wang X, et al. Research on a new automatic generation algorithm of concept map based on text analysis and association rules mining. Journal of Ambient Intelligence and Humanized Computing, 2020, 11(2):539–551.
[25] Zheng Q, Li Y, Cao J. Application of data mining technology in alarm analysis of communication network. Computer Communications, 2020, 163:84–90.
[26] He Z, Tao L, Xie Z, et al. Discovering spatial interaction patterns of near repeat crime by spatial association rules mining. Scientific reports, 2020, 10(1):1–11.
[27] Wang C, Bian W, Wang R, et al. Association rules mining in parallel conditional tree based on grid computing inspired partition algorithm. International Journal of Web and Grid Services, 2020, 16(3):321–339.
Biography

Jianhu Gong has been engaged in teaching in the school of data and computer science of Guangdong Peizheng College since he got his doctor’s degree from City University of Macau in 2013. He has published many papers in the fields of computer network, data science and big data technology, and participated in the research work of the Ministry of Education, Guangdong Province and other departments. He has obtained many authorized patents and software copyrights Item.
Journal of Web Engineering, Vol. 20_2, 513–532.
doi: 10.13052/jwe1540-9589.20213
© 2021 River Publishers