Differential and Access Policy Based Privacy-Preserving Model in Cloud Environment
Rishabh Gupta* and Ashutosh Kumar Singh
Department of Computer Applications, National Institute of Technology, Kurukshetra, Haryana, India
E-mail: rishabhgpt66@gmail.com; ashutosh@nitkkr.ac.in
*Corresponding Author
Received 15 February 2021; Accepted 21 November 2021; Publication 12 February 2022
Abstract
Cloud computing has multiple benefits in terms of minimum cost, maximum efficiency, and high scalability, which prompts shifting a large amount of data from the local machine to the cloud environment for storage, computation, and data sharing among various parties stakeholders. However, owners do not fully trust the cloud platform operated by a third party. Therefore, security and privacy emerge as critical issues while sharing data among different parties. In this paper, a novel privacy-preserving model is proposed by utilizing encryption, differential privacy, and machine learning approaches. It facilitates data owners to share their data securely in the cloud environment. The model defines access policy and communication protocol among the involved untrusted parties for data processing and privacy preservation. The proposed model is evaluated by executing experiments using distinct datasets. The achieved results reveal that the proposed model provides high accuracy, precision, recall, and f1-score up to 98%, 98%, 97%, and 97%, respectively, over the state of the art methods.
Keywords: Cloud computing, differential privacy, machine learning, privacy-preserving, access control.
1 Introduction
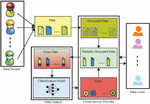
Commercial organizations and individuals have shifted their local data to the cloud platform to avail of seamless benefits such as large storage capacity, computational, and flexible accessibility [1]. These individuals and organizations are relieved from local data management and maintenance responsibility after outsourcing their data [2]. But, once data is outsourced to the cloud for storage and computation purposes, owners lose control of their data because it is managed by a third party [3, 4]. The cloud may allow access of the outsourced data to other entities for business benefits [5]. Therefore, it becomes a major challenge for the cloud service provider to establish trust among owners for data privacy. The owners encrypt their data before transferring it to the cloud platform by utilizing traditional techniques such as homomorphic cryptographic techniques. These techniques are considered inefficient because of difficulty in performing the computation over the encrypted data [6, 7]. Moreover, the stored and analyzed data must be shared with the various authorized entities for several purposes. It cannot ensure that the receiving entities will not distribute the data to other entities after they have obtained it [8]. Therefore, it is necessary to preserve the privacy of data among involved entities. To address the aforementioned challenges, a potential access control method that preserves data privacy is required. In this regard, a novel Differential and Access policy-based Privacy-preserving Model (DAPM) is proposed, which protects the data through privacy-preserving data storage, analysis, and secure sharing in the cloud environment. Figure 1 shows a bird-eye view of the proposed work and highlights our consecutive contributions in the cloud environment to protect cloud data and classify tasks. The main contributions of DAPM are described as follows:
1. An access policy is designed to improve data protection among all the engrossed entities that are deemed untrusted.
2. DAPM facilitates multiple data owners to share their data by encrypting it with a separate key to protect the data from leakage.
3. DAPM transforms encrypted data into noised data at the cloud platform to enhance the computation’s efficiency and accuracy.
4. A series of experiments are performed over the diverse datasets to evaluate the validity of the proposed model. Besides, the comparisons are made among the different a) datasets, b) classifiers, and c) preprocessed data using -differential privacy and with the state of the artworks to prove the superiority of DAPM.
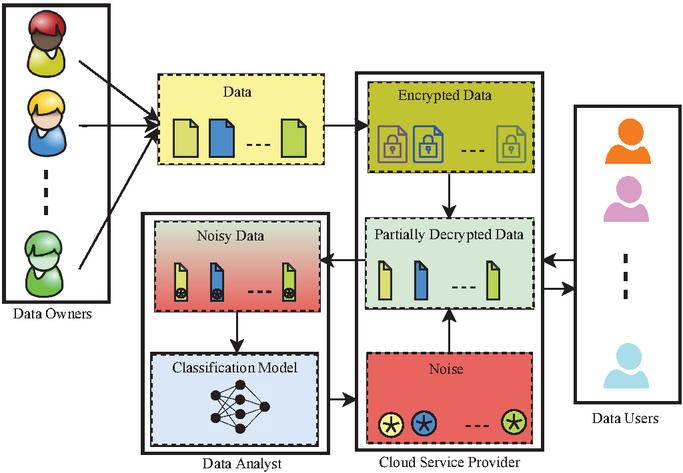
Figure 1 Bird eye view of the proposed work.
Organization: Section 2 entails related work, and an overview of the proposed model DAPM is presented in Section 3. The data preservation mechanism is described in Section 4, followed by the machine learning model in Section 5. The experimental results of DAPM are presented in Section 6, and the proposed work is summarized in Section 7. The notations list with their descriptions is shown in Table 1.
Table 1 List of symbols
| Notation | Definition |
| Data Owners | |
| Cloud Service Provider | |
| Data Users | |
| Actual data | |
| Encrypted data | |
| Noise | |
| Classification Model | |
| Data Analyst | |
| Classification Accuracy | |
| Public key | |
| Secret key | |
| Transformation key | |
| Precision | |
| Noise-added data | |
| Preprocessed data | |
| Recall | |
| Training data | |
| Testing data | |
| F1-Score | |
| Encryption time | |
| Decryption time | |
| Training objects | |
| Testing objects |
2 Related Work
2.1 Security Based on Ciphertext-Policy Attribute-Based Encryption (CP-ABE)
Wang et al. [9] proposed a File Hierarchy Ciphertext-Policy Attribute-Based Encryption (FH-CP-ABE) scheme to share the hierarchical files in cloud computing. The different access structures of files were integrated into a single access structure that can be used to encrypt the files in the same hierarchical structure. But, the computation cost of this scheme increased dramatically, even the ciphertexts were integrated, and the common attributes were computed only once. To achieve a fair key reconstruction, Liu et al. [10] proposed a data access control scheme for cloud storage in which none of the users send their shares, and no one can access shared data. This scheme minimized the computation and communication cost, but user authentication did not perform effectively. To reduce the computation cost of users and the high decryption cost increases with the complexity of access policy, a multi-authority CP-ABE scheme is presented in [11]. The updated keys of the access policy are created and sent to the cloud for updation. However, this scheme depends on untrusted cloud servers to update keys. Zhang et al. [12] proposed a Hidden access Policy CP-ABE scheme to verify the authorized users and ensure data confidentiality. The private key with constant size encrypts the data, and the decryption process requires four pairing computations. The transmission, as well as storage costs, are reduced in this scheme. It supports only the “AND” policy; therefore, it is considered a weak security scheme. Li et al. [13] proposed an efficient outsourcing policy updating the ciphertext-policy ABE (CP-ABE) scheme based on the linear secret-sharing schemes (LSSS) matrix access structure with improved the efficiency of the policy and file updating dynamically in cloud computing. The storage, communication cost of owners, and computation cost of the proxy cloud service provider were reduced. It resisted the selected plaintext attacks, but the file updating cost is high.
2.2 Privacy-Preserving Based on Machine Learning
Yuan et al. [14] proposed a secure, efficient, and accurate multiparty Back-Propagation Neural (BPN) network-based scheme which provided privacy preservation for more than two parties collaborative BPN network learning over arbitrarily partitioned data. They adopted a “doubly homomorphic” encryption algorithm to perform the operations over ciphertexts. However, they concentrated more on the improvement of data processing without considering the efficiency of the algorithm. To learn visual classifiers securely over distributed private data, Yonetani et al. [15] proposed a privacy-preserving mechanism based on double-permitted homomorphic encryption (DPHE) scheme that enabled multiparty protected scalar product. It reduced the computational cost for high-dimensional classifiers. But, DPHE supports either addition or multiplication at a particular time. Aono et al. [16] used additively homomorphic encryption to protect the gradients against the curious server. The same accuracy was achieved corresponding deep learning system, i.e., asynchronous stochastic gradient descent (ASGD) trained over the joint dataset of all participants. But, the secret-key of owners decrypts the updated parameters, and their model does not provide the privacy of parameters. To provide the privacy-preserving classification service for users and a classifier owner to delegate a remote server, a secure outsourcing scheme is presented in [17]. However, the outsourced model sharing scheme only supports a single-party setting. Li et al. [18] proposed a data protection scheme that preserves the privacy of Naive Bayes learning over data contributed by multiple providers. The -differential privacy was used for data protection. But this scheme does not satisfy the differential privacy in the local setting and preserves individual privacy with encryption techniques. Ma et al. [19] proposed a privacy-preserving deep learning model, namely PDLM, to train the model over the multi-key encrypted data. A privacy-preserving calculation toolkit based on stochastic gradient descent (SGD) was adopted to accomplish the training task in a privacy-preserving manner. The model reduced the storage overhead, but the classification accuracy is less as well as the computation cost is high. A Privacy-preserving Machine Learning with Multiple data provider (PMLM) scheme with improved computational efficiency and data analysis is proposed by Li et al. [20]. The public-key encryption with a double decryption algorithm (DD-PKE) and -differential privacy was used for data privacy. But the scheme suffers from less accuracy as well as less data sharing. A privacy-preserving outsourced classification in cloud computing (POCC) framework was introduced in [21] which protects the confidentiality of sensitive data using a fully homomorphic encryption proxy technique. However, several interactions among evaluators and storage servers increased the computational and communication cost.
3 Proposed Model
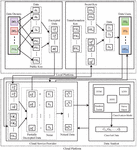
The proposed model (Figure 2) involves four entities: Data Owners (), Cloud Service Provider (), Data Users (), and Data Analyst () which are described with their intercommunication and essential information flow as follows:
(1) : An entity that produces data and uses the services of for storage and computation. encrypts data before sending it to the cloud to maintain privacy. However, is not considered a trusted entity. It does not leak its own data but may reveal the other owner’s data.
(2) : It is an entity that provides the storage, computation, and data sharing facilities to , , or after collecting the encrypted data. transforms ciphertext provided by into partially decrypted data and adds noise to it by using -differential privacy. acts as a bridge that connects , , and . strictly follows the protocols, it is not a fully trusted entity due to its curiosity to learn the information.
(3) : An entity receives data from after sending a request. performs decryption over data received from and acquires useful information. is considered an untrusted entity.
(4) : An entity that receives the noisy data from as per the request. It provides the classification service through a classification model (). It trains using machine learning algorithms over received data and gets classified data from . The achieved results are shared among or through . In the proposed model, is treated as an untrusted entity.
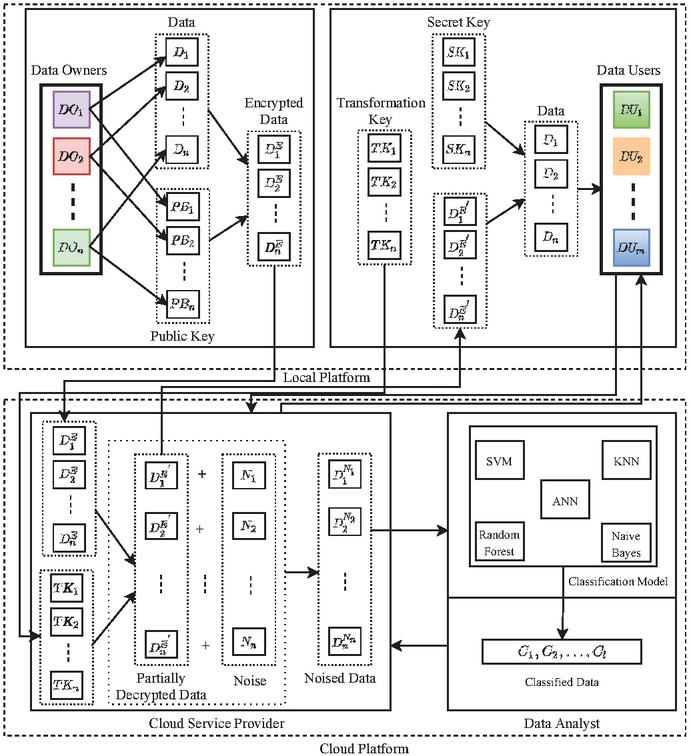
Figure 2 DAPM architecture.
Let the data owners = {, , , } own data = {, , , }, while the data object belongs to may be independent and of different sizes. It is essential that must share among the other parties such as , , and several data users = {, , , } for data usage, storage, and computation purposes. Each {, , , } has public keys = {, , , } respectively. , , , encrypt their data , , , by using the encryption technique and the public key , , , to ensure data privacy and acquire the encrypted data = {, , , }. As an encryption technique, DAPM uses the CP-ABE scheme for data , , , encryption as it is a suitable technique for data protection and fine-grained data access handling. It is also an efficient and secured encryption technique that utilizes the attributes of , , , without loss of data privacy at encryption/decryption time, and data owners themselves determine the access control policy with the data users’ attributes [22]. , , , transfers , , , to for storing, computing, and sharing data. has transformation keys = {, , , } that have been obtained from , , , . transforms the stored , , , into partially decrypted data = {, , , } using , , , . sends requested data , , , to data users , , , for utilization as per the demand. Each {, , , } has secret keys = {, , , }, which are used to decrypt , , , to obtain the plain data , , , . converts the , , , into noised data = {, , , } by adding the noise to it. The resulted data , , , is sent to for classification. , , , or , , , can make the query via that passes the query to to perform the classification tasks over it and obtain the results from through . delivers the acquired results to the corresponding entities , , , or , , , . The operational summary of the proposed model is given in Algorithm 1.
Input: Actual data , Public key , Secret key , Transformation key , Access Policy
Output: , , , and
1Initialize data := {, , , }, := {, , , }, := {, , , }, := {, , , }, := {, , , }
2for = , , , do
3 for = , , , do
4 Encrypt using keys
5 Partially decrypt data using keys
6 Add the noise into data
7 Decrypt data using keys and
8 Perform the classification over
9 end for
10end for
11 = (# / # ) * 100
12 =
13 =
=
Algorithm 1 DAPM operational summary
4 Data Preservation
Let each data owner owns data , public key , and access policy over the attributes. encrypts data with their by applying Equation (1):
| (1) | ||
Where is access policy to get the encrypted data , is bilinear map assigned by : , is the generator of and is the bilinear group of prime order . The random values , , and are used to measure the shared value for each attribute () in , whereas , are random exponents and = . A hash function is used to map the attributes. The security parameters , , , and are calculated for in . do not fully trust for data access control, and , , , has distinct decryption rights according to their attributes. , , , transfer the encrypted data , , , including the access structure to . , , , which is partially decrypted by using Equation (2), and obtained results , , , are sent to , , , . They decrypt , , , using corresponding keys , , , after matching their attributes with the access policy determined by , , , and get the actual data , , , by applying Equation (3).
| (2) | |
| (3) |
Input: , , , ,
Output: ,
1for = , , , do
2 Generate keys () from group element
3 Select random elements from
4 Calculate secret shared , in
5 Compute = , =
6 Calculate = , = ;
7 = {, , y : , }
8 Compute = , =
9 Calculate = , =
10 = {, , , }
11 = +
12 Compute = , =
13 Calculate = , =
14 = {, , , }
15end for
return ,
Algorithm 2 Data Encryption/Decryption and Noise Addition
transfers encrypted data = {, , , } into partially decrypted data = {, , , } using the transformation keys = {, , , }. To increase the accuracy and efficiency of computations while protecting data, the partially encrypted data = {, , , } is transformed into noised data = {, , , } using -differential privacy [23]. For this, produces the noise vector = {, , , } using the probability density and distribution Laplace, Gaussian, and Random function by applying Equation (4), (5), and (6), respectively.
| (4) | |
| (5) | |
| (6) |
where is a noise vector, is scale parameter, and is random noise drawn from the distribution with scale . The created noise = {, , , } is added to corresponding = {, , , } as = + where [1, ], and the resulted data = {, , , } is transferred to . Algorithm 2 defines the steps for data encryption/decryption and noise addition. In this algorithm, steps 2 to 4 find the security parameters required to encrypt the data. Steps 5 to 7 are applied for data encryption. Encrypted data is partially decrypted using steps 8 to 10. Noise is injected into partially decrypted data through step 11. By using steps 12 to 14, partially decrypted data is fully decrypted to allow access to actual data.
5 Data Classification
preprocesses the data = {, , , } by using the normalization function to achieve the preprocessed data = {, , , } by applying Eq (7), where is the training sample with attributes, , and are the mean and the standard deviation of the training sample, respectively.
| (7) |
It is well-known that = {, , , } belongs to class labels = {, , , } where and = . The data = {, , , } is divided into training data = {, , , } and testing data = {, , , }. The is trained using the training data along with machine learning algorithms while the accuracy of is evaluated by testing data , , , . The data objects , , , are provided to to assign class labels during the testing process. Thus, examines , , , and gives the output as class label vector = {, , , }. The Classification Accuracy () of is calculated using , , , by applying Equation (8), where indicates the number of correctly classified items and indicates the total number of test items.
| (8) |
The precision () and recall () are measured using Equations (9) and (10), respectively, while indicates the total number of items returned by the classifier and the total number of relevant items is indicated by .
| (9) | ||
| (10) |
The F1-Score () is calculated using Equation (11). The steps for data , , , classification is shown in Figure 3.
| (11) |
In DAPM, the feed-forward neural network classifier consists of three layers one input layer, one hidden layer, and one output layer. From the input layer with nodes, the preprocessed data ,,, is given to the hidden layer with nodes represented as {, , , + }. The results of the hidden layer are provided to the output layer with nodes shown as {, , }, where is the weight and , are the bias. The classified results , , , are obtained from the output layer. Algorithm 3 describes the steps for data classification. In this algorithm, steps 3 to 5 show the efficiency of the SVM classifier. A procedure for the K-NN classifier is given in steps 6 to 8. The Random Forest classifier classifies the data in steps 9 to 11. By using step 12, the Naive Bayes classification is carried out. Subsequently, the neural network operates from steps 13 to 16.
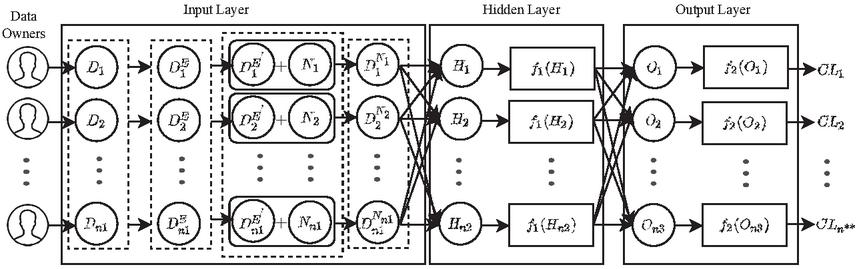
Figure 3 Feed-forward Neural Network Classifier for shared data.
Input: Input vector , weight , bias , activation function , tree numbers
Output: unknown class label
1Initialize input vector = {, , , }, = {, , , }, ,
2for = , , , do
3 = +
4 0, := 1
5 0, := 0
6 for Compute Set contains the minimum sets of do
7 distance (, )
8 end for
9 for = , , , do
10 tree_classification(, )
11 end for
12 =
13 for = , do
14 for = , , do
15 = +
16 =
17 end for
18 end for
19 return
end for
Algorithm 3 Data Classification
The computational and space complexities are , ; , ; , , where is the total number of attributes and is the input records for various phases including data encryption and decryption, differential privacy, and data classification of DAPM, respectively. DAPM complexity analysis implies that the aid of endurable time and space protects the data, which establishes its potency.
6 Performance Evaluation
6.1 Experimental Setup
A series of experiments have been performed using machine learning algorithms over four separate datasets EEG Eye State (EES), Gender Voice (GV), Seeds, and Vehicle Silhouettes (VS) with 15, 21, 7, 18 attributes and 14980, 3168, 210, 946 instances, which have been taken from the UCI Machine Learning Repository to train CM. The five separate classifiers, i.e., Support Vector Machine (SVM), K-nearest neighbor (K-NN), Random Forest, Naive Bayes, and Artificial Neural Network (ANN), have been used to train CM over training data. These experiments are carried out on a system equipped with Intel (R) Core (TM) i5-4210U CPU @ 1.70GHz clock speed along with 8 GB of main memory using Python 2.7.15.
6.2 Encryption/Decryption Time
Figures 4(a) and (b) show computation time for encryption and decryption processes over different datasets, respectively. It is found that encryption and decryption time costs increase linearly concerning the number of attributes associated with access policy. Besides, a comparison in terms of encryption time () and decryption time () has been carried out over the various datasets, which increases concerning the instance of datasets. The descending order of and for all 2 to 8 number of attributes are EES, GV, VS, Seed, respectively.
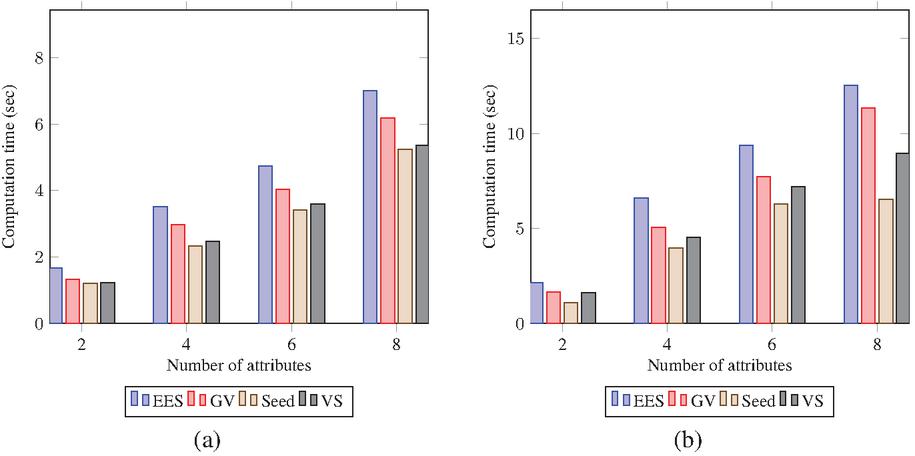
Figure 4 Computation time (sec) for various datasets: (a) and (b) .
6.3 Classification Parameters
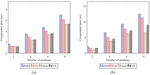
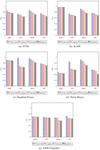
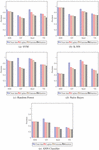
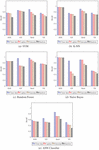
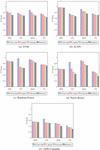
The 9/10 data of complete datasets are used for training data, while the remaining for testing data. The training is carried out on clean as well as noisy data. To produce the noised data, the Laplace, Gaussian, and Randomly noise generated mechanisms are used. The results of noised data are compared against clean data to find the differences. In addition, a distinction is made among the Laplace, Gaussian, and Random noised data to find the superior one. The outputs of CM are computed and the Classification Accuracy (CA), Precision (P), Recall (R), and F1-Score (FS) are calculated using test results. Figs. 5 to 8 show the results including CA, P, R, and FS respectively, which are achieved by CM of DAPM over Clean, Laplace noised, Gaussian noised, and Random noised data. The comparison among SVM, K-NN, Random Forest, Naive Bayes, and ANN classifiers are also shown for EES, GV, Seeds, and VS datasets, respectively. Due to noise addition, CA, P, R, and FS of noised data are less than clean data in the case of all the five classifiers as shown in Table 2. However, CA, P, R, and FS are almost equal for noised data and also have more protection compared to clean data. Also, in the case of all five classifiers, out of three noised data, Laplace noise data outperforms the Gaussian noise and the Random noise data. The datasets and classifiers’ performance descends in order: Seeds, GV, EES, VS, and Naive Bayes, Random Forest, K-NN, SVM, ANN, respectively. The Seeds dataset outperforms the remaining four data sets for all five classifiers out of four data sets. For CA, P, R, and FS, the Random Forest classifier outperforms the other three classifiers. Overall, the Random Forest classifier outperforms the other four classifiers in DAPM due to the use of kernel trick and a large optimum margin interval between separating hyperplanes during classification, which results in better performance.
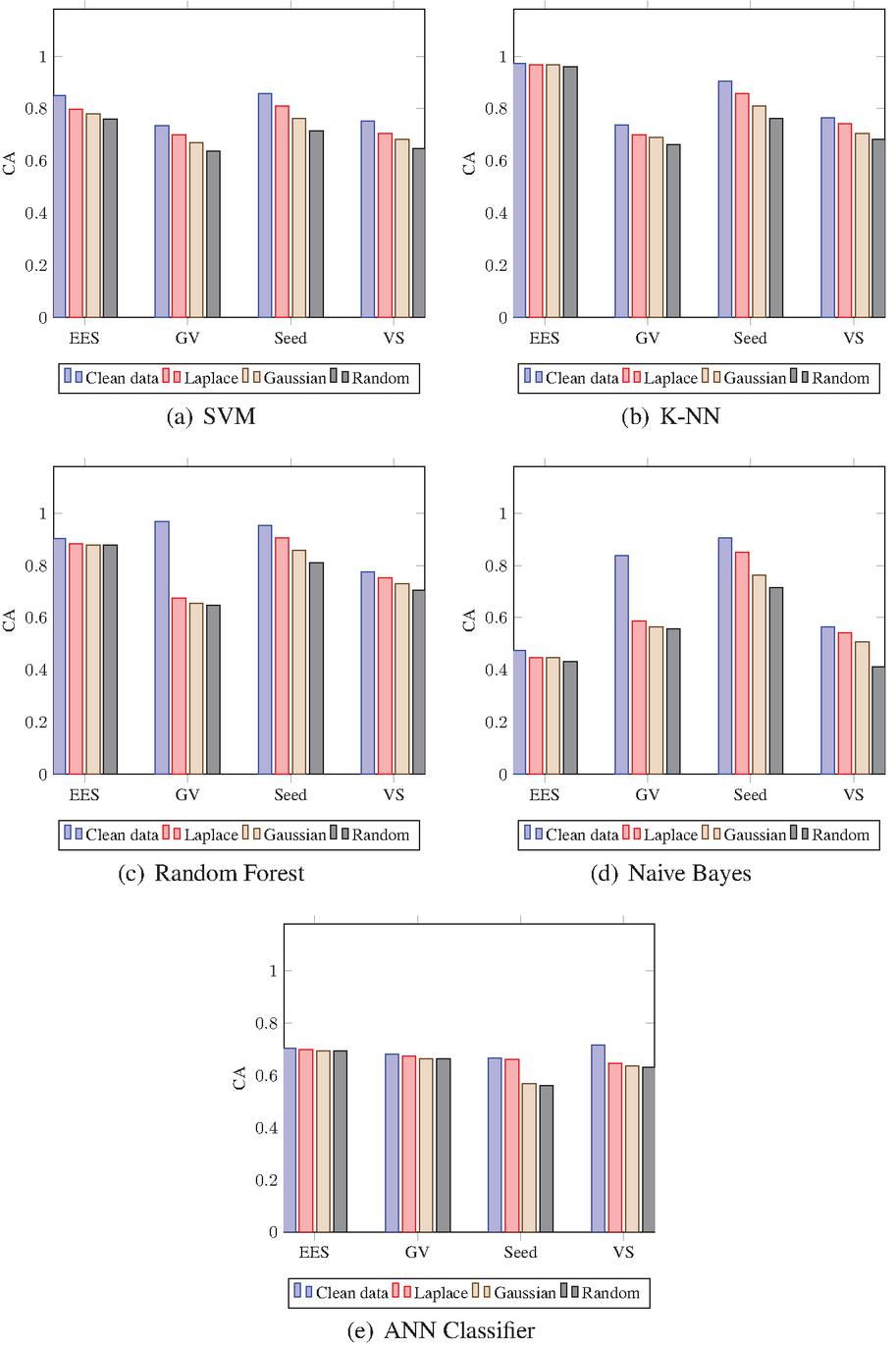
Figure 5 Accuracy of CM for DAPM.
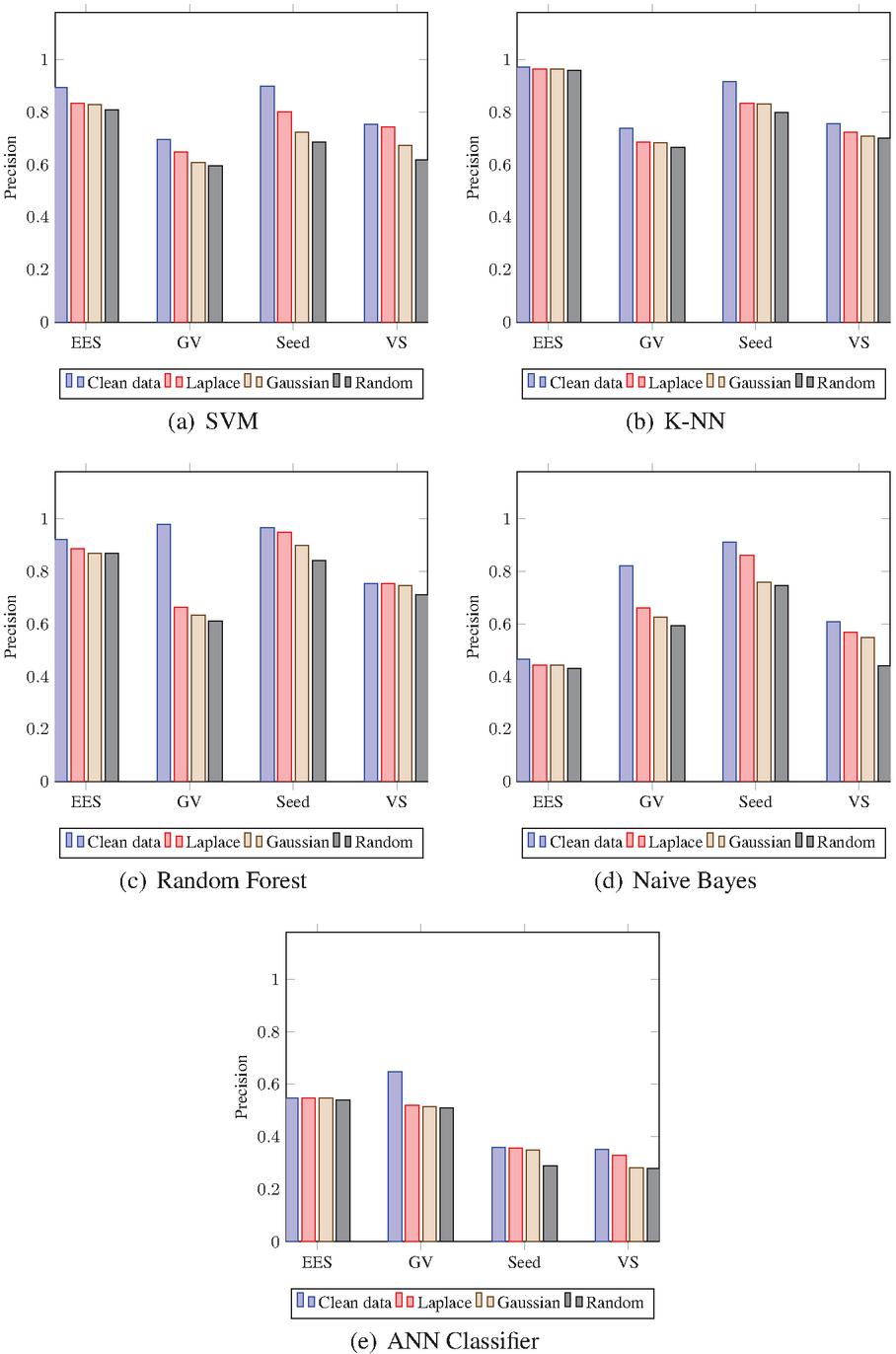
Figure 6 Precision of CM for DAPM.
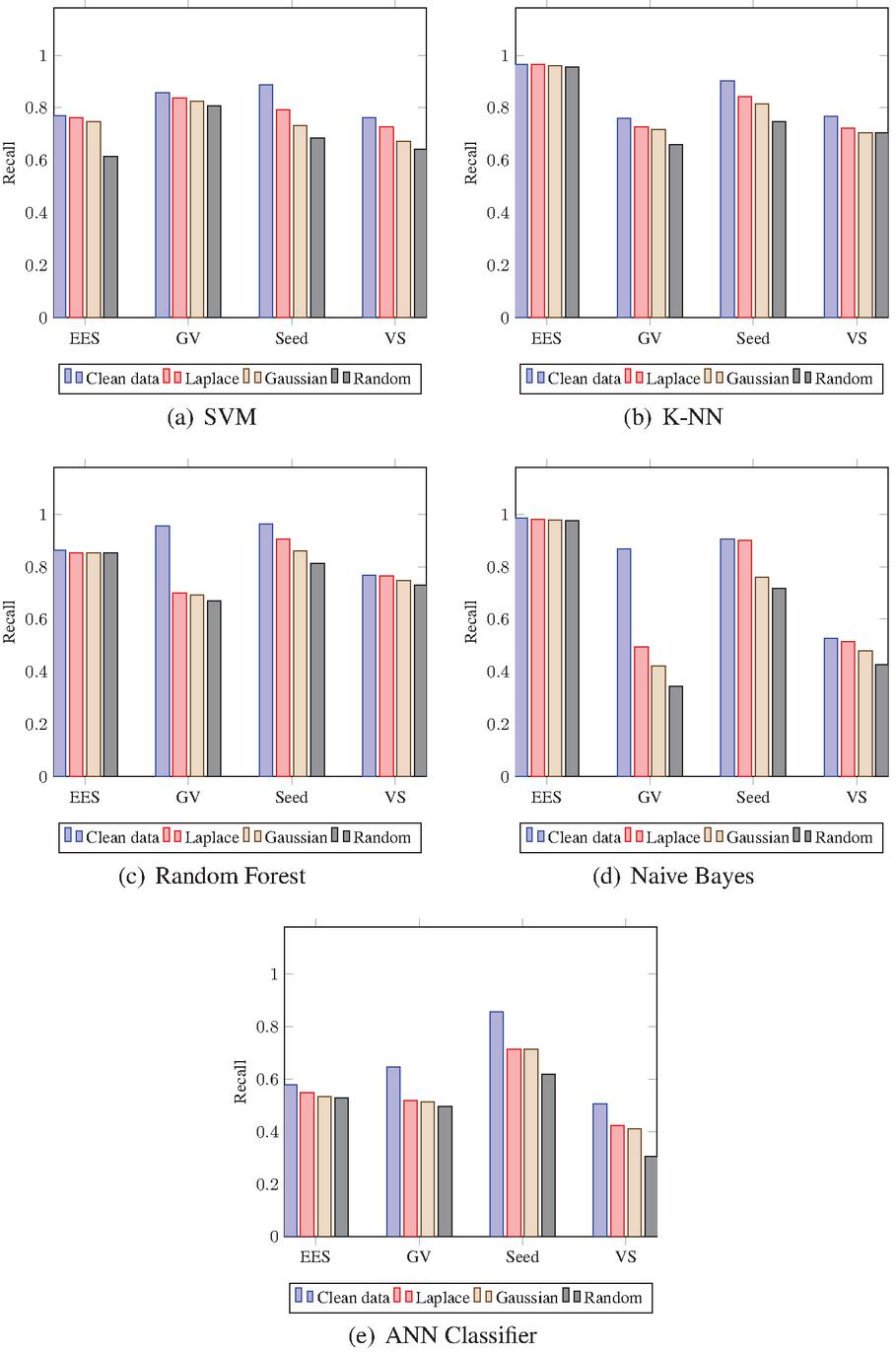
Figure 7 Recall of CM for DAPM.
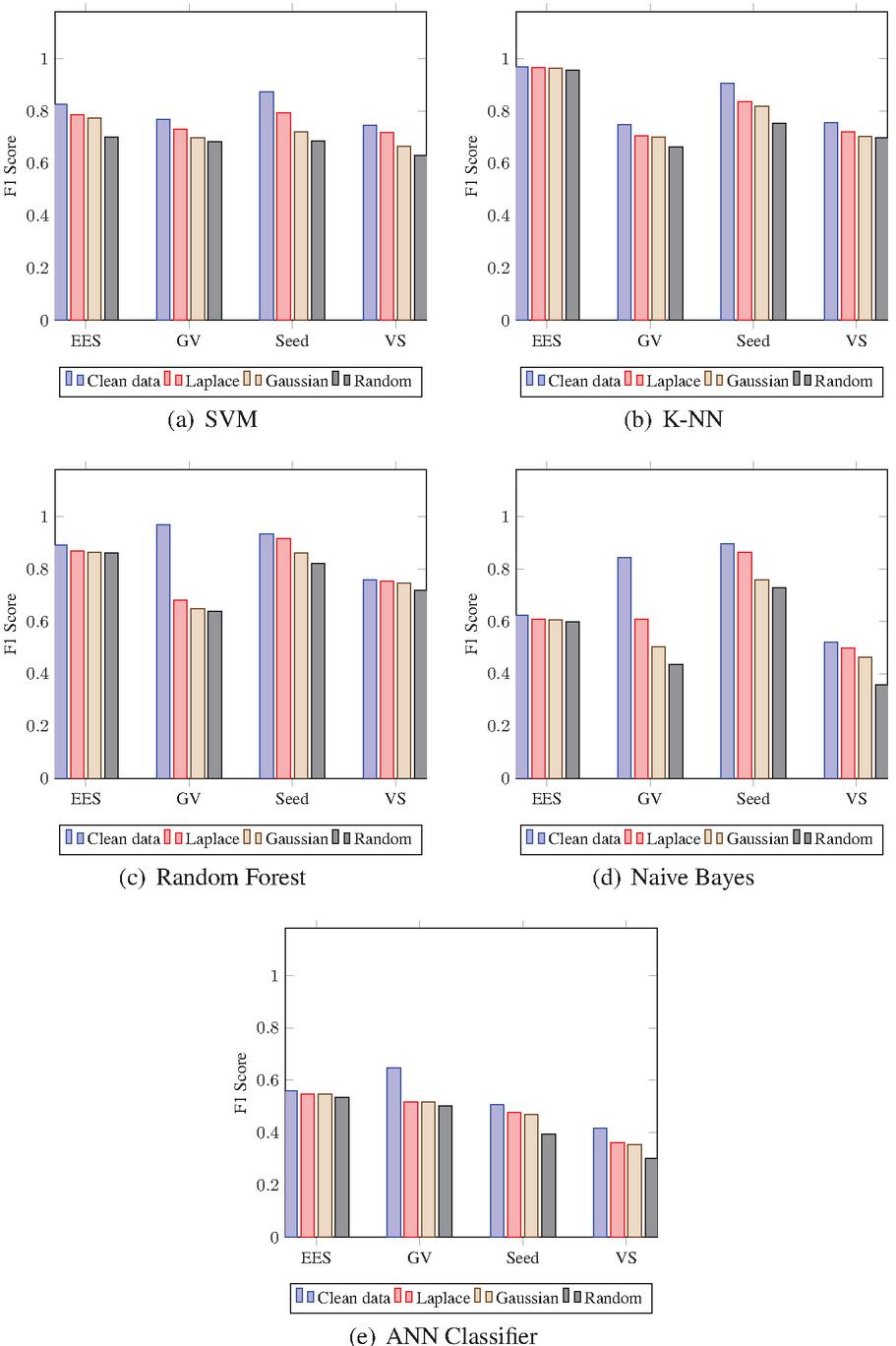
Figure 8 F1 Score of CM for DAPM.
Table 2 Reduction in the values of accuracy, precision, recall, and f1-score of Laplace (L), Gaussian (G), Random(R) noised data in comparison to the values on clean data
{adjustbox}center, width=.715DatasetClassifier% decrement in the value of parametersAccuracyPrecisionRecallF1-ScoreLGRLGRLGRLGRSVM5.487.089.155.976.408.510.772.2615.604.065.4512.60KNN0.460.531.200.780.841.380.050.561.070.410.691.22EESRF1.802.332.403.595.295.371.091.151.192.282.903.19NB2.742.874.272.132.203.360.550.670.841.571.812.60ANN0.681.071.150.140.140.903.174.575.171.361.362.68SVM3.476.639.784.688.819.892.043.375.043.716.888.48KNN3.784.817.575.135.547.353.464.3810.044.344.998.68GVRF29.3431.2332.1831.8034.7736.9525.5326.2628.7028.7032.0232.94NB25.2427.4528.0815.8619.5322.6937.2944.5452.3123.5833.9540.76ANN0.811.401.6312.7013.0813.6912.9313.2515.1412.9313.0114.42SVM4.769.5214.299.9017.6221.439.5215.5520.318.0315.4718.88KNN4.769.5214.288.338.6011.876.028.7915.676.998.7215.34SeedRF4.769.5214.281.796.6612.415.8210.3715.131.617.0311.05NB5.3614.2819.055.0015.1916.510.4714.4818.653.3313.9116.77ANN0.549.7610.640.291.127.1214.2914.2923.813.093.8311.31SVM4.717.0610.591.108.0413.503.499.0711.892.598.0011.56KNN2.365.898.243.144.805.504.606.316.413.385.285.88VSRF2.354.707.060.210.814.380.202.183.910.471.083.95NB2.365.8915.303.945.9616.751.384.729.972.215.8216.23ANN6.937.858.412.307.017.338.239.4120.005.476.1511.44
6.4 Security Analysis and Validation
DAPM protects data from all entities, including , , , and . ; [, ] use the encryption algorithm to protect their data from other entities: , , , and . encrypt data with their keys and share it in encrypted form . converts into partially decrypted data . Furthermore, is transferred into the noised form by to prevent data leakage. carries out a machine learning model on this noise-added data with -differential privacy without information loss.
The protocol’s authentication phase is explicitly verified using the ProVerif security analysis tool. Queries are used to assess the security of the protocol’s various security primitives. If the query is satisfied and returns true, then the attacker can not attack, and ensures the security primitive. Apart from this, if the query returns false, then ProVerif reconstructs the protocol’s execution path to determine the steps of attacks [24]. The statement ‘RESULT not attacker’ shown in Figure 9 implies that all variables utilized during mutual authentication, such as , , , , , , , , , , created queries, and events are secure. Consequently, the acquired results confirm that DAPM is entirely safe. DAPM provides robust security and improves the accuracy of data processing because of converting the encrypted data with distinct public keys into noise-added data. DAPM achieved a substantial CA, P, R, FS up to 98%, 98%, 97%, and 97%, respectively.

Figure 9 Security analysis and validation results.
7 Conclusion
This paper proposed a novel model named DAPM, which preserves the privacy of outsourced data in the cloud environment. All the involved entities are considered untrusted for providing more effective security. Therefore, a robust mechanism is developed in the model by exploring every possible threat during data flow among the involved parties. DAPM provides an effective sharing protocol to prevent the loss of data. In this work, multiple data owners are allowed to outsource their data to the cloud for storing and computation, and different statistical noise is injected at the cloud platform according to the queries. The experiments have been performed, and results demonstrate that DAPM ensures high accuracy, precision, recall, and f1-score and is found to be secure, efficient, and optimal.
References
[1] J. Li, X. Chen, S. S. Chow, Q. Huang, D. S. Wong, and Z. Liu, “Multi-authority fine-grained access control with accountability and its application in cloud,” Journal of Network and Computer Applications, vol. 112, pp. 89–96, 2018.
[2] Y. Miao, J. Ma, X. Liu, X. Li, Q. Jiang, and J. Zhang, “Attribute-based keyword search over hierarchical data in cloud computing,” IEEE Transactions on Services Computing, 2017.
[3] J. Hur and D. K. Noh, “Attribute-based access control with efficient revocation in data outsourcing systems,” IEEE Transactions on Parallel and Distributed Systems, vol. 22, no. 7, pp. 1214–1221, 2010.
[4] Z. Qin, H. Xiong, S. Wu, and J. Batamuliza, “A survey of proxy re-encryption for secure data sharing in cloud computing,” IEEE Transactions on Services Computing, 2016.
[5] Z. Zhu and R. Jiang, “A secure anti-collusion data sharing scheme for dynamic groups in the cloud,” IEEE Transactions on parallel and distributed systems, vol. 27, no. 1, pp. 40–50, 2015.
[6] J. Wei, W. Liu, and X. Hu, “Secure data sharing in cloud computing using revocable-storage identity-based encryption,” IEEE Transactions on Cloud Computing, vol. 6, no. 4, pp. 1136–1148, 2016.
[7] Z. Fu, L. Xia, X. Sun, A. X. Liu, and G. Xie, “Semantic-aware searching over encrypted data for cloud computing,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 9, pp. 2359–2371, 2018.
[8] B. Hauer, “Data and information leakage prevention within the scope of information security,” IEEE Access, vol. 3, pp. 2554–2565, 2015.
[9] S. Wang, J. Zhou, J. K. Liu, J. Yu, J. Chen, and W. Xie, “An efficient file hierarchy attribute-based encryption scheme in cloud computing,” IEEE Transactions on Information Forensics and Security, vol. 11, no. 6, pp. 1265–1277, 2016.
[10] H. Liu, X. Li, M. Xu, R. Mo, and J. Ma, “A fair data access control towards rational users in cloud storage,” Information Sciences, vol. 418, pp. 258–271, 2017.
[11] Z. Liu, Z. L. Jiang, X. Wang, and S.-M. Yiu, “Practical attribute-based encryption: Outsourcing decryption, attribute revocation and policy updating,” Journal of Network and Computer Applications, vol. 108, pp. 112–123, 2018.
[12] L. Zhang, Y. Cui, and Y. Mu, “Improving security and privacy attribute based data sharing in cloud computing,” IEEE Systems Journal, vol. 14, no. 1, pp. 387–397, 2019.
[13] J. Li, S. Wang, Y. Li, H. Wang, H. Wang, H. Wang, J. Chen, and Z. You, “An efficient attribute-based encryption scheme with policy update and file update in cloud computing,” IEEE Transactions on Industrial Informatics, vol. 15, no. 12, pp. 6500–6509, 2019.
[14] J. Yuan and S. Yu, “Privacy preserving back-propagation neural network learning made practical with cloud computing,” IEEE Transactions on Parallel and Distributed Systems, vol. 25, no. 1, pp. 212–221, 2013.
[15] R. Yonetani, V. Naresh Boddeti, K. M. Kitani, and Y. Sato, “Privacy-preserving visual learning using doubly permuted homomorphic encryption,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 2040–2050, 2017.
[16] Y. Aono, T. Hayashi, L. Wang, S. Moriai, et al., “Privacy-preserving deep learning via additively homomorphic encryption,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 5, pp. 1333–1345, 2017.
[17] T. Li, Z. Huang, P. Li, Z. Liu, and C. Jia, “Outsourced privacy-preserving classification service over encrypted data,” Journal of Network and Computer Applications, vol. 106, pp. 100–110, 2018.
[18] T. Li, J. Li, Z. Liu, P. Li, and C. Jia, “Differentially private naive bayes learning over multiple data sources,” Information Sciences, vol. 444, pp. 89–104, 2018.
[19] X. Ma, J. Ma, H. Li, Q. Jiang, and S. Gao, “Pdlm: Privacy-preserving deep learning model on cloud with multiple keys,” IEEE Transactions on Services Computing, 2018.
[20] P. Li, T. Li, H. Ye, J. Li, X. Chen, and Y. Xiang, “Privacy-preserving machine learning with multiple data providers,” Future Generation Computer Systems, vol. 87, pp. 341–350, 2018.
[21] P. Li, J. Li, Z. Huang, C.-Z. Gao, W.-B. Chen, and K. Chen, “Privacy-preserving outsourced classification in cloud computing,” Cluster Computing, vol. 21, no. 1, pp. 277–286, 2018.
[22] J. Bethencourt, A. Sahai, and B. Waters, “Ciphertext-policy attribute-based encryption,” in 2007 IEEE symposium on security and privacy (SP’07), pp. 321–334, IEEE, 2007.
[23] C. Dwork and A. Smith, “Differential privacy for statistics: What we know and what we want to learn,” Journal of Privacy and Confidentiality, vol. 1, no. 2, 2010.
[24] Z. Wang, “A privacy-preserving and accountable authentication protocol for iot end-devices with weaker identity,” Future Generation Computer Systems, vol. 82, pp. 342–348, 2018.
Biographies

Rishabh Gupta received the MCA degree in computer science from Guru Jambheshwar University Science and Technology, Hisar, India, in 2015. He is currently working toward the Ph.D. degree in Computer Science with the Department of Computer Applications, National Institute of Technology, Kurukshetra, Kurukshetra, India.
He is awarded the Senior Research Fellowship by the University Grants Commission, Government of India. His research interests include cloud computing, machine learning, big data, and information security and privacy.

Ashutosh Kumar Singh received the Ph.D. degree in electronics engineering from the Indian Institute of Technology BHU, Varanasi, India, in 2000.
He is working as a Professor and Head with the Department of Computer Applications, National Institute of Technology Kurukshetra, Kurukshetra, India. He has more than 20 years of research and teaching experience in various Universities in India, UK, and Malaysia. He is Postdoctoral Researcher from the Department of Computer Science, University of Bristol, Bristol, UK. He has authored/co-authored more than 250 research papers and 8 books. His research interests include verification, design, and testing of digital circuits, data science, cloud computing, machine learning, security, etc.
Journal of Web Engineering, Vol. 21_3, 609–632.
doi: 10.13052/jwe1540-9589.2132
© 2022 River Publishers