Competitive Capsule Network Based Sentiment Analysis on Twitter COVID’19 Vaccines
V. Diviya Prabha and R. Rathipriya*
Department of Computer Science, Periyar University, Periyar Palkalai Nagar, Salem – 636011, Tamil Nadu, India
E-mail: diviyaprabha7@gmail.com; rathipriyar@gmail.com
*Corresponding Author
Received 25 June 2021; Accepted 08 June 2022; Publication 08 August 2022
Abstract
COVID-19 is an extremely contagious virus that has rapidly spread around the world. This disease has infected people of all ages in India, from children to the elderly. Vaccination, on the other hand, is the only way to preserve human lives. In the midst of a pandemic, it’s critical to know what people think of COVID-19 immunizations. The primary goal of this article is to examine corona vaccination tweets from India’s Twitter social media. This study introduces CompCapNets, a unique deep learning approach for Twitter sentiment classification. The results suggest that the proposed method outperforms other strategies when compared to existing traditional methods.
Keywords: Twitter, sentiment analysis, deep learning, capsule network, COVID-19, machine language.
1 Introduction
Sentiment classification is an important problem in text analysis, which aims to identify important texts from huge amounts of text data. Social media consists of a variety of information in the form of text as a clue to understanding people’s opinions. Twitter is one of the popular social media that acts as a mediator between people and the public by sharing individuals’ opinions with the public. It is immensely difficult to understand and analyse textual information. As COVID’19 is increasing, most people get affected by this disease during this lockdown period. Hence, it is very essential to understand people’s sentiment about COVID’19 vaccine. This paper focuses on COVID’19 vaccine related tweets to perform analysis. It helps to comprehend people’s sentiments about COVAXIN, COVISHIELD dose 1 and dose 2. Sentimental analysis is used to determine the polarity rate of each text and categories them as positive or negative. However, as text data in social media is complex, consisting of disparate text that is generally very difficult to analyze, it must be cautiously classified without losing the contextual information.
In the last few decades, sentiment classification has depended on machine learning techniques. During the conversion of the Urdu language to English (Castro, 2017), hybrid machine learning techniques for text classification are utilized. In this sense, machine learning techniques are working better for text classification. (Harleen, 2021) uses hybrid machine learning to classify Twitter sentiment scores. This paper also discusses certain machine learning techniques for Twitter sentiment classification with an increasing amount of data. There is an improvement in research from machine learning to deep learning methods.
Recent work focuses on the deep learning based approaches like Convolution Neural Network (CNN) and Recurrent Neural Network (RNN). A hybrid of RNN and CNN (Cheng et al., 2016) is used in research based on word-embedding along with a max polling layer. CNN is mainly applied for image classification, and it works better for huge images. But in recent times, CNN has ascertained better text classification, showing good results with the word-vector model (Kim, 2014). Though CNN’s performance in text classification is promising, Capsule Network (CapsNets) (Hinton, 2011) has recently outperformed CNN. The main drawback of CNN is that it losses the spatial information in text while performing pooling. In fact, CapsNets work better at accomplishing this information without losing the originality of the text. It consists of capsules arranged in nested layers, which help to capture text with spatial relations for better text analysis.
This paper discusses an extension of the work in (Diviya, 2020), COVID’19 vaccine related tweets which are collected from the Twitter API. Here, Competitve CapsNets (CompCapsNets) are proposed to choose the most appropriate text to perform multi-class sentiment analysis. In some cases, identifying optimal information might not lead to successive results. So, it is crucial to understand the text and find appropriate texts among the huge text vectors. This helps to increase classification performance. The detailed explanation of the proposed work is discussed in Section 5. Also, a comparison of the existing and proposed approaches is shown in result Section 6. The results show that the proposed CompCapsNets outperforms other deep learning and machine learning techniques.
2 Literature Study
Over the years, sentiment classification is performed using machine learning algorithms (McCallum, Nigam, et al., 1998), which take input text with n-gram approaches. However, these methods require huge amounts of linguistic resources. Classification of movie reviews using Navie Bayes and Support Vector Machine (SVM) delivers moderate results (Pang et al., 2002). Other methods used for text classification are dependent on rule-based classifiers (Silva, 2011). Document classification is performed using machine learning by selecting important features (Janani, 2020). Here, documents are classified based on their content. A huge amount of analysis is required. (Hermann et al., 2013) represent text in vector format depending on certain operators which are available in the autoencoder. However, even when machine learning techniques produce better results, they fail to consider the huge number of linguistic resources and the need to understand prior knowledge about the dataset.
To overcome these limitations, deep learning methods like the CNN network for text classification (Kim, 2014) are applied. (Agarwal et al., 2020) proposed deep-learning based approach for sentimental analysis. (Samya and Rathipriya, 2016) uses deep learning models for prediction. (Cach et al., 2021) compared the hybrid models and a single model in both machine learning and deep learning techniques. The author uses Word2vec embedding to convert words to vectors using a text dataset. Moreover, the output performance is better considering the text embedding concept. (Kalchbrenner et al., 2014) uses special approaches from CNN to handle text of different lengths. (Cai et al., 2015) uses CNN to handle text and images and shows promising results. Another way of handling CNN is given by (Zhang et al., 2015) which takes input as character and performs analysis on text classification. Text data is treated as a sequence using CNN and long short term memory networks (LSTMs) are discussed in (Conneau et al., 2017). However, these models do not deal with spatial information between texts. For example, if texts are shuffled in a sentence, the classification accuracy reduces. So, they literally fail in patterns, which loses the originality of the meaning of the text. The main objective of CapsNets is to work on the concept of spatial pattern between texts. So, CapsNets is used for text classification to solve various problems (Zhao, 2018).
The main motivation for this paper is to design better CapsNets called ComCapsNets to identify the most appropriate text in tweets. Using CapNets, it will be challenging to exactly identify the spatial information in text, whereas ComCapsNets will easily identify the text by choosing the most appropriate text for the target class. CapNets have already proven to be superior for text analysis when compared to the benchmark dataset (Diviya, 2020), and this paper builds on that success by selecting the most relevant words using the CompCapsNet approach in tweets.
3 Data Collection
Data is collected from the Twitter streaming API (Trupthi and Pabboju, 2017). Tweets related to the COVID’19 vaccine are collected. For example, COVAXIN, COVISHIELD, first dose, second dose, etc., related tweets are extracted to understand people’s opinions on vaccines. COVAXIN and COVISHIELD are two types of vaccines that are developed in India and help in the fight against COVID’19. Each vaccine contains two doses with each dose a certain number of days apart. To understand people’s opinions, these vaccines related tweets are collected. Nearly 61,557 tweets about vaccination are collected through Twitter API using python. Collected unstructured data is converted into structured data in a ‘.csv’ format.
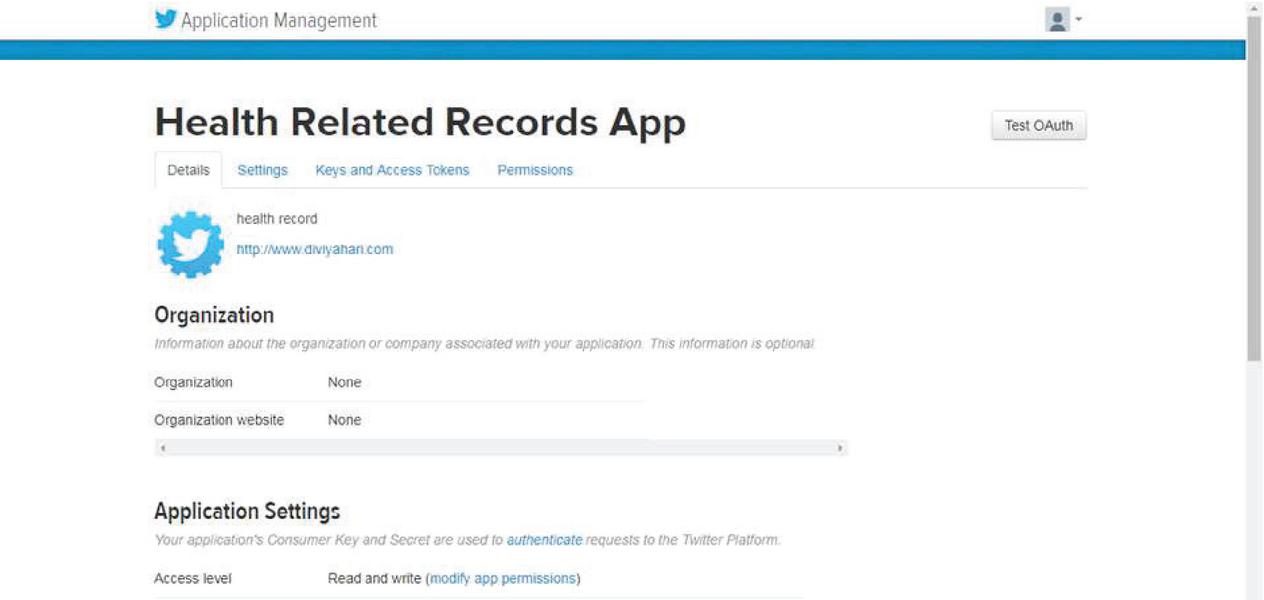
Figure 1 Twitter API to collect tweets.
Figure 1 represents the screenshot of the Twitter API created with the name “Health Related Records App”. These generated keys and access tokens help to collect vaccine tweets from Twitter using a unique id. The data is preprocessed to remove noise, unnecessary keywords, special characters, etc. The input represents the tweet text of the form T1, T2,…Tn for each Ti represents a different text in a tweet. In two-dimensional representation by vectors in the form of T*N, where N represents the number of text in tweets.
Table 1 Tweets collection
| Tweets | Size |
| COVAXIN | 16,465 |
| COVISHIELD | 14,234 |
| COVAXIN-1 Dose | 9,220 |
| COVAXIN-2 Dose | 7,010 |
| COVISHIELD-1 Dose | 9,011 |
| COVISHIELD-2 Dose | 5,617 |
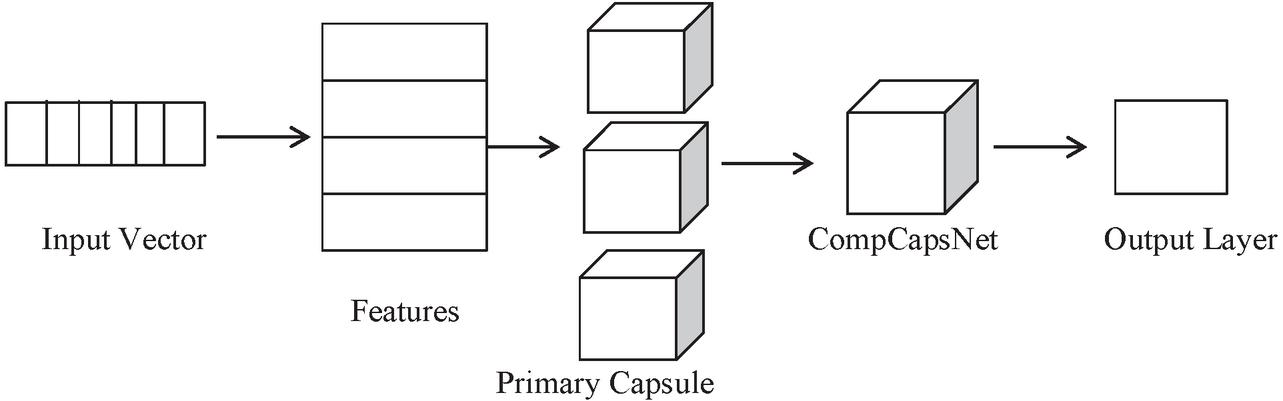
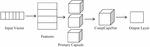
Figure 2 Architecture of CompCapsNets.
4 Proposed Approach
The proposed approach to ComCapNets is represented in Figure 2. Here, the main difference between CapsNets and ComCapsNets is that in CapsNets the capsule layer considers all rich structures of information to reach the classification task, which is quite difficult in handling huge amounts of data, whereas in ComCapsNets the information competes with one another to choose the most appropriate and useful few patterns in text to reach the target very easily.
Each individual tweet is taken into consideration. Vector representations of the input tweets are generated as input vectors. Tweets are pre-processed using a variety of methods (Diviya and Rathipriya, 2020). Every row in this work represents a single word for the purpose of extracting features. This basic capsule layer is made up of a combination of features that are represented as capsules. Multiple capsules agree to vote on a set of features in order to become a capsule. CompCapsNet aims to extract the most appropriate capsule from a range of capsules. The final capsule is identified in the output layer.
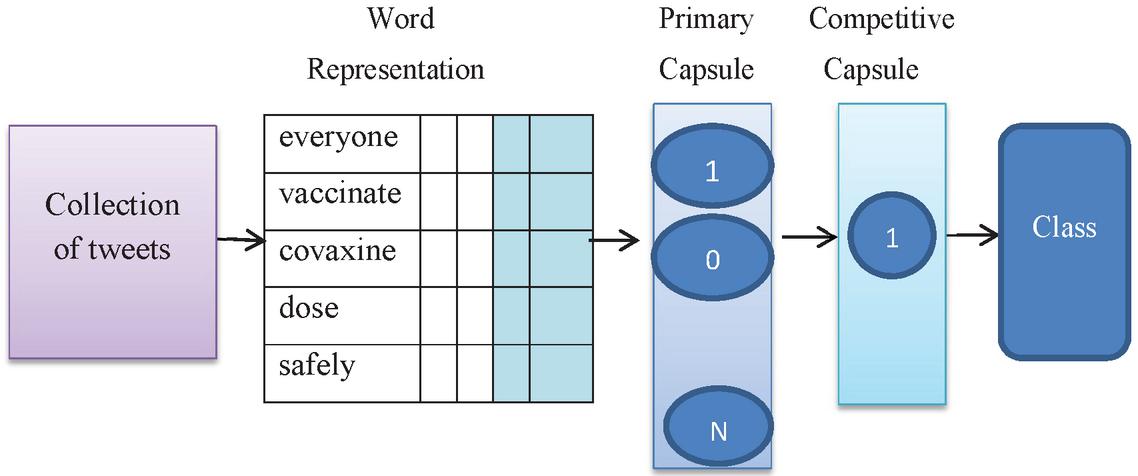
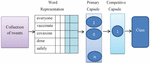
Figure 3 CompCapsNets example.
Figure 3 represents the collection of tweets related to the COVID-19 vaccine. Only one tweet is picked from all of them. These tweets, for example, are routed to the principal capsule based on the complex structural patterns that exist between low and high level text. The most relevant text for categorization is selected from among them. In this case, tweet classifications are multi-class labels (Diviya, 2020), with five labels: strong positive, positive, strong negative, negative, and neutral tweets.
The polarity score for tweets is discussed in Table 2. Text is examined using textblob, which is a basic processing method for determining the polarity rate of each tweet. Then, depending on the polarity score, each tweet is assigned a sentiment class. The tweets are given as input to proposed work to obtain the sentiment.
Table 2 Sentiment score for tweets analysis
| Polarity Score | Sentiment Class |
| Greater than 0 and less than 0.5 | Positive |
| Greater than 0.5 | Strong Positive |
| Equal to 0 | Neutral |
| Less than 0 to 0.5 | Negative |
| Less than 0.5 | Strong Negative |
Proposed Algorithm
Step 1: Consider tweets as TW,TW,…. TW, which are then preprocessed into tokens t, t…t.
Step 2: Convert each token into a capsule layer which converts to a scalar S,S,…S.
Step 3: Primary Capsule layer it collects the single capsules which are multiplied with the matrix to produce a vector c called the coupling coefficient
| (1) |
Step 4: Convert the vector to a certain interval [0,1] using the squashing function
| (2) |
This function helps to convert the values between 0 and 1 to produce the capsule.
Step 5: Using the max function, add weight to each vector to select the most appropriate words, w represents adding weight to vector; Comp variable words compete to choose the most appropriate word for classification
| (3) | ||
| (4) |
Step 6: Training and testing are validated to check the accuracy.
Equation (1) represents the vector representation of text to extract features as tokens in vector format. The output of the primary capsule layer is V. Equation (2) describes the squash function to manipulate the vectors as 0 and 1. Equation (3) describes the weight added to the output squash function. Based on weight, the most appropriate token is identified and denoted in Equation (4). Results are validated based on their accuracy.
5 Experimental Analysis
This section discusses the validation of results using machine learning and deep learning techniques. The experiments were performed using Keras with a Tensorflow backend using Python. The collected data is evaluated through the proposed algorithm for sentiment analysis.
Table 3 COVAXIN dataset sentiment classification using machine learning techniques
| Classifier | Class | Precision | Recall | F1-Score |
| RF | 0 | 0.94 | 0.99 | 0.96 |
| 1 | 0.97 | 0.84 | 0.90 | |
| 2 | 1.00 | 0.86 | 0.93 | |
| 3 | 0.00 | 0 | 0 | |
| 4 | 1.00 | 0.14 | 0.25 | |
| MA | 0.78 | 0.57 | 0.61 | |
| WA | 0.94 | 0.94 | 0.94 | |
| LR | 0 | 0.93 | 0.98 | 0.96 |
| 1 | 0.94 | 0.83 | 0.88 | |
| 2 | 1.00 | 0.79 | 0.88 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.57 | 0.52 | 0.54 | |
| WA | 0.93 | 0.93 | 0.93 | |
| KN | 0 | 0.86 | 1.00 | 0.92 |
| 1 | 0.99 | 0.58 | 0.73 | |
| 2 | 1.00 | 0.79 | 0.88 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.57 | 0.47 | 0.51 | |
| WA | 0.89 | 0.88 | 0.87 | |
| SVC | 0 | 0.94 | 0.99 | 0.96 |
| 1 | 0.95 | 0.86 | 0.91 | |
| 2 | 1.00 | 0.86 | 0.93 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.58 | 0.54 | 0.56 | |
| WA | 0.94 | 0.94 | 0.94 |
Table 3 describes the results of COVAXIN sentiment classification. The accuracy metrics, precision, recall, and F1 Score are calculated for different classifiers such as Random Forest (RF), Logistic Regression (LR), Support Vector Classifier (SVC), and K-Neighbor Classifier (KN). The values range from 0 to 4, which specifies the class label of 5 different classes. Likewise, WA represents the weighted average of each classifier, and MA denotes the macro average. In Table 3, RF achieves high WA and MA values in precision, recall and F1-score. Meanwhile, SVC also receives a high value equal to that of RF. So, it is concluded that for COVAXINE sentiment classification RF acquires high classification accuracy metrics compared to other machine learning classifiers.
Table 4 COVISHILED dataset sentiment classification using machine learning techniques
| Classifier | Class | Precision | Recall | F1-Score |
| RF | 0 | 0.93 | 1.00 | 0.96 |
| 1 | 0.99 | 0.84 | 0.91 | |
| 2 | 1.00 | 0.76 | 0.86 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.58 | 0.52 | 0.55 | |
| WA | 0.94 | 0.94 | 0.94 | |
| LR | 0 | 0.91 | 0.99 | 0.95 |
| 1 | 0.96 | 0.79 | 0.87 | |
| 2 | 1.00 | 0.72 | 0.84 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.58 | 0.50 | 0.53 | |
| WA | 0.93 | 0.93 | 0.92 | |
| KN | 0 | 0.85 | 1.00 | 0.92 |
| 1 | 1.00 | 0.59 | 0.74 | |
| 2 | 1.00 | 0.72 | 0.84 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.57 | 0.46 | 0.50 | |
| WA | 0.89 | 0.88 | 0.87 | |
| SVC | 0 | 0.94 | 0.99 | 0.97 |
| 1 | 0.96 | 0.87 | 0.91 | |
| 2 | 1.00 | 0.78 | 0.88 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.60 | 0.53 | 0.55 | |
| WA | 0.95 | 0.95 | 0.94 |
In Table 4, for the COVISHILED dataset, the SVC classifier accomplishes higher MA and WA than other classifiers. A minimum value is attained by the KN classifier with 89% for precision, 88% for recall and 87% for f1 score.
Table 5 COVAXIN Dose 1 dataset sentiment classification using machine learning techniques
| Classifier | Class | Precision | Recall | F1-Score |
| RF | 0 | 0.91 | 0.98 | 0.95 |
| 1 | 0.98 | 0.95 | 0.96 | |
| 2 | 1.00 | 0.86 | 0.92 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.58 | 0.56 | 0.57 | |
| WA | 0.95 | 0.95 | 0.95 | |
| LR | 0 | 0.93 | 0.92 | 0.92 |
| 1 | 0.93 | 0.96 | 0.95 | |
| 2 | 1.00 | 0.43 | 0.60 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.57 | 0.46 | 0.49 | |
| WA | 0.92 | 0.93 | 0.92 | |
| KN | 0 | 0.86 | 0.91 | 0.88 |
| 1 | 0.92 | 0.90 | 0.91 | |
| 2 | 1.00 | 0.43 | 0.60 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.56 | 0.45 | 0.48 | |
| WA | 0.89 | 0.89 | 0.89 | |
| SVC | 0 | 0.92 | 0.95 | 0.94 |
| 1 | 0.96 | 0.95 | 0.95 | |
| 2 | 1.00 | 0.71 | 0.83 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.57 | 0.52 | 0.54 | |
| WA | 0.94 | 0.94 | 0.94 |
In Table 5, the RF classifier acquires high accuracy metrics values in WA and MA. This classifier is best for the COVAXINE twitter dataset. It has an accuracy of 95%. A minimum value of 89% is obtained by the KN classifier.
Table 6 COVAXIN Dose 2 dataset sentiment classification using machine learning techniques
| Classifier | Class | Precision | Recall | F1-Score |
| RF | 0 | 0.92 | 0.99 | 0.96 |
| 1 | 0.98 | 0.87 | 0.92 | |
| 2 | 1.00 | 0.68 | 0.81 | |
| 3 | 1.00 | 0.94 | 0.97 | |
| 4 | 1.00 | 1.00 | 1.00 | |
| MA | 0.98 | 0.90 | 0.93 | |
| WA | 0.95 | 0.94 | 0.94 | |
| LR | 0 | 0.92 | 0.99 | 0.96 |
| 1 | 0.98 | 0.87 | 0.92 | |
| 2 | 1.00 | 0.68 | 0.81 | |
| 3 | 1.00 | 0.94 | 0.97 | |
| 4 | 1.00 | 1.00 | 1.00 | |
| MA | 0.98 | 0.90 | 0.93 | |
| WA | 0.95 | 0.94 | 0.94 | |
| KN | 0 | 0.87 | 0.95 | 0.91 |
| 1 | 0.89 | 0.76 | 0.82 | |
| 2 | 0.93 | 0.56 | 0.70 | |
| 3 | 1.00 | 0.94 | 0.97 | |
| 4 | 1.00 | 0.83 | 0.91 | |
| MA | 0.94 | 0.81 | 0.86 | |
| WA | 0.88 | 0.88 | 0.88 | |
| SVC | 0 | 0.93 | 0.98 | 0.96 |
| 1 | 0.96 | 0.90 | 0.93 | |
| 2 | 1.00 | 0.64 | 0.78 | |
| 3 | 1.00 | 0.94 | 0.97 | |
| 4 | 1.00 | 0.83 | 0.91 | |
| MA | 0.98 | 0.86 | 0.91 | |
| WA | 0.95 | 0.95 | 0.94 |
From Table 6, it is understood that the RF and SVC classifiers receive high precision metrics with a 98% percentage. However, the recall and F1-Score metrics of the SVC classifier are 95% and 94%, respectively. Minimum accuracy metrics are received by the LR classifier.
Table 7 COVISHILED Dose 1 dataset sentiment classification using machine learning techniques
| Classifier | Class | Precision | Recall | F1-Score |
| RF | 0 | 0.93 | 1.00 | 0.96 |
| 1 | 0.98 | 0.88 | 0.92 | |
| 2 | 1.00 | 0.68 | 0.81 | |
| 3 | 1.00 | 0.96 | 0.98 | |
| 4 | 1.00 | 1.00 | 1.00 | |
| MA | 0.98 | 0.90 | 0.94 | |
| WA | 0.95 | 0.95 | 0.95 | |
| LR | 0 | 0.93 | 0.98 | 0.96 |
| 1 | 0.94 | 0.89 | 0.91 | |
| 2 | 1.00 | 0.55 | 0.71 | |
| 3 | 1.00 | 0.94 | 0.97 | |
| 4 | 1.00 | 0.83 | 0.91 | |
| MA | 0.97 | 0.84 | 0.89 | |
| WA | 0.94 | 0.94 | 0.94 | |
| KN | 0 | 0.85 | 0.99 | 0.91 |
| 1 | 0.96 | 0.71 | 0.81 | |
| 2 | 1.00 | 0.55 | 0.71 | |
| 3 | 1.00 | 0.96 | 0.98 | |
| 4 | 1.00 | 0.83 | 0.91 | |
| MA | 0.96 | 0.81 | 0.86 | |
| WA | 0.90 | 0.89 | 0.88 | |
| SVC | 0 | 0.95 | 0.99 | 0.97 |
| 1 | 0.96 | 0.91 | 0.93 | |
| 2 | 1.00 | 0.59 | 0.74 | |
| 3 | 1.00 | 0.96 | 0.98 | |
| 4 | 1.00 | 0.83 | 0.91 | |
| MA | 0.95 | 0.95 | 0.95 | |
| WA | 0.95 | 0.95 | 0.95 |
In Table 7, the RF classifier acquires high MA and WA in precision, recall and F1-Score. Likewise, minimum metrics are obtained by LR. The COVISHILED dose 1 twitter dataset performs better.
Table 8 COVISHILED Dose 2 dataset sentiment classification using machine learning techniques
| Classifier | Class | Precision | Recall | F1-Score |
| RF | 0 | 0.94 | 1.00 | 0.97 |
| 1 | 0.98 | 0.84 | 0.91 | |
| 2 | 1.00 | 0.76 | 0.86 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.73 | 0.65 | 0.68 | |
| WA | 0.95 | 0.95 | 0.94 | |
| LR | 0 | 0.92 | 0.98 | 0.95 |
| 1 | 0.93 | 0.81 | 0.87 | |
| 2 | 1.00 | 0.70 | 0.83 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.71 | 0.62 | 0.66 | |
| WA | 0.92 | 0.92 | 0.92 | |
| KN | 0 | 0.88 | 0.99 | 0.93 |
| 1 | 0.97 | 0.69 | 0.80 | |
| 2 | 1.00 | 0.70 | 0.83 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.71 | 0.60 | 0.64 | |
| WA | 0.90 | 0.90 | 0.90 | |
| SVC | 0 | 0.94 | 0.99 | 0.96 |
| 1 | 0.96 | 0.86 | 0.91 | |
| 2 | 1.00 | 0.78 | 0.88 | |
| 3 | 0.00 | 0.00 | 0.00 | |
| 4 | 0.00 | 0.00 | 0.00 | |
| MA | 0.73 | 0.66 | 0.69 | |
| WA | 0.94 | 0.95 | 0.94 |
In Table 8, the RF classifier receives high accuracy metrics for the COVISHELD dose 2 dataset. A minimum number of accuracy metrics is achieved by the LR classifier.
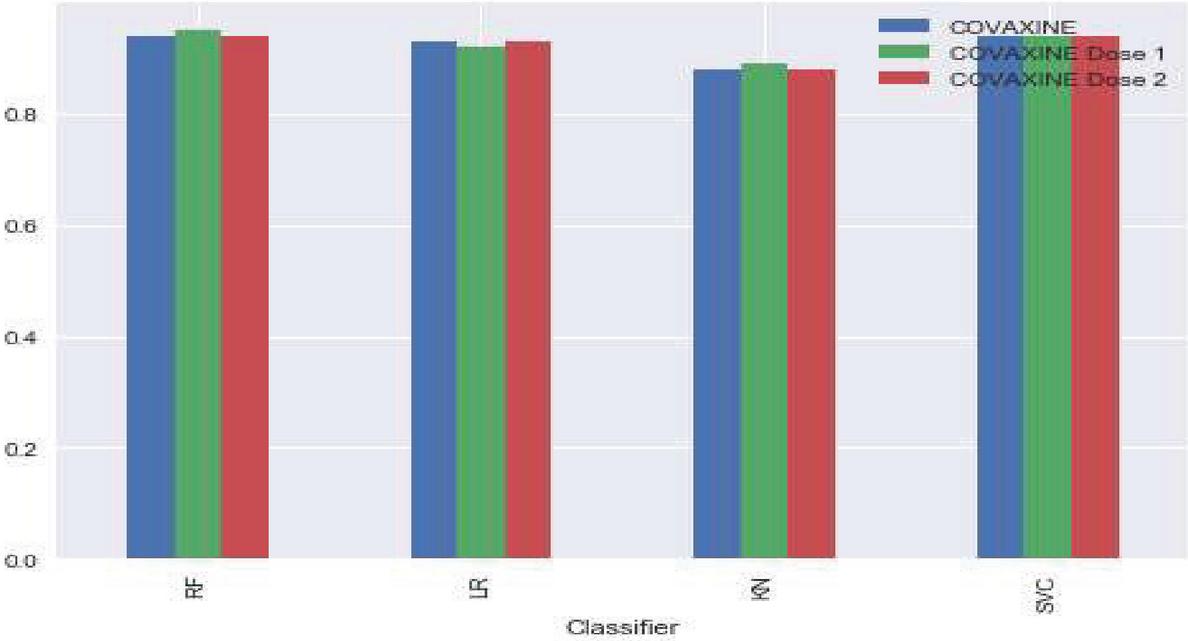
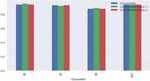
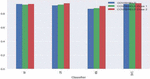
Figure 4 Accuracy percentage of COVAXINE Tweets using machine learning techniques.
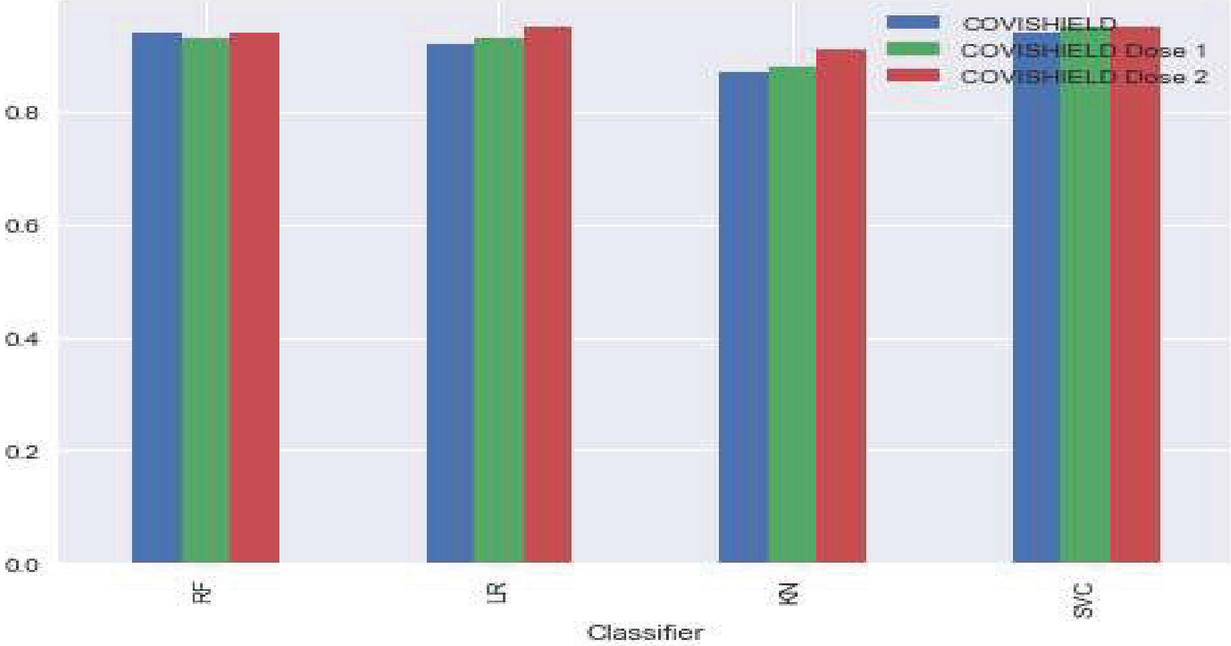
Figure 5 Accuracy percentage of COVISHIELD tweets using machine learning technique.
Figures 4 and 5 represent the accuracy percentages using different machine learning techniques. From the results, it is concluded that the KN classifier does not perform well because it receives a minimum accuracy of 6 datasets. The RF, LR, and SVC classifiers perform better for Twitter classification data. The SVC classifier performs better in all aspects as it reaches 95 percent for the COVISHELD Dose 1 dataset and the COVISHELD Dose 2 dataset.
Table 9 Different deep learning techniques accuracy
| COVAXIN | COVAXINE | COVISHIELD | COVISHIELD | |||
| Techniques | COVAXIN | Dose 1 | Dose 2 | COVISHIELD | Dose 1 | Dose 2 |
| CNN | 0.95 | 0.94 | 0.93 | 0.94 | 0.93 | 0.93 |
| LSTM | 0.94 | 0.95 | 0.94 | 0.95 | 0.94 | 0.94 |
| CNN_Static | 0.96 | 0.93 | 0.93 | 0.95 | 0.95 | 0.95 |
| Bi_LSTM | 0.95 | 0.96 | 0.95 | 0.93 | 0.94 | 0.94 |
| EmddConv | 0.95 | 0.95 | 0.95 | 0.96 | 0.95 | 0.95 |
| CapsNets | 0.96 | 0.97 | 0.96 | 0.97 | 0.96 | 0.96 |
| Proposed Approach | 0.98 | 0.99 | 0.98 | 0.99 | 0.97 | 0.98 |
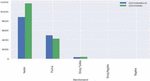
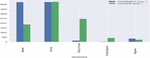
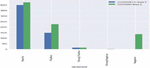
Table 9 describes different deep learning techniques for text classification. The proposed CompCapsNet performs better when compared with other state-of-the-art models. In most cases, the proposed model shows superior performance to other deep learning models. Figures 6 to 8 represent the sentiments about vaccine tweets in which COVAXIN tweets receive the highest neutral sentiment. Meanwhile, COVAXIN Dose 1 tweets receive positive sentiment, which indicates that it has a positive opinion among the people who use it. However, COVAXIN Dose 2 and COVISHIELD received the highest neutral sentiment, which means they need more awareness among the public. COVISHIELD Dose 1 tweets an equal number of neutral and positive sentiments. COVISHIELD Dose 1 tweets receive the highest neutral sentiment. Though the proposed model attains good performance, a small pitfall is choosing the most appropriate capsule. It is a tedious task, so attention must be given to choosing the capsule.
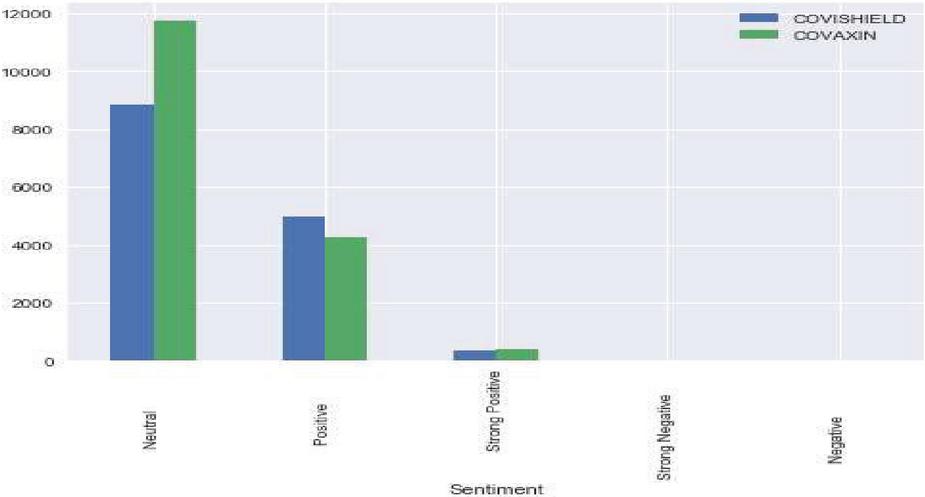
Figure 6 Sentiment analysis of COVISHIELD and COVAXIN tweets.
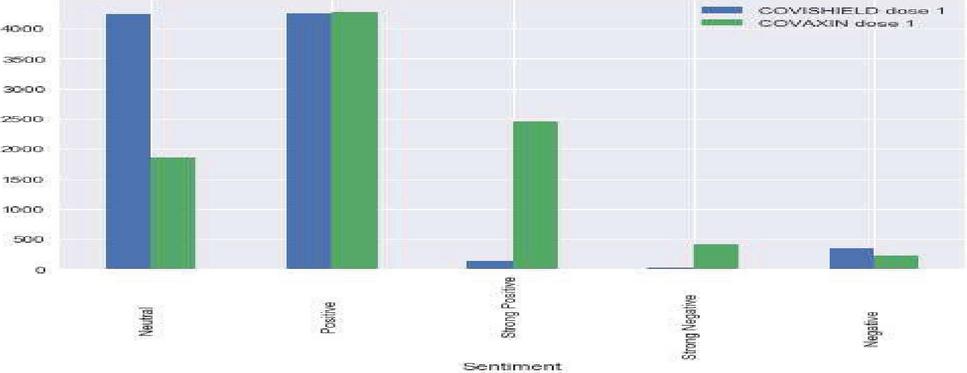
Figure 7 Sentiment analysis of COVISHELD Dose1 and COVAXIN Dose 1 tweets.
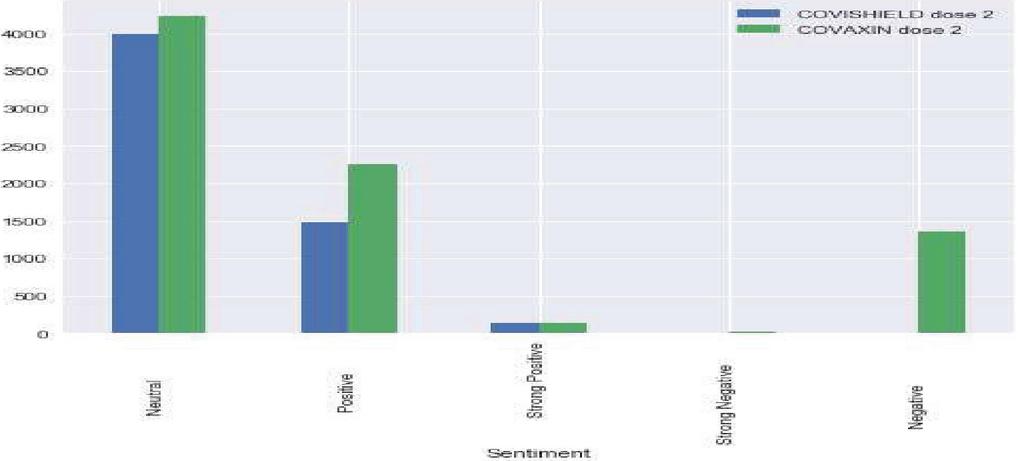
Figure 8 Sentiment analysis of COVISHELD Dose 2 and COVAXIN Dose 2 tweets.
Suggestions for Public health officials
• The public health sector should concentrate on raising awareness of the benefits of the COVID’19 vaccine and reducing the fear of vaccination among ordinary people.
• Further periodical research is needed for clinical evidence of the efficiency and safety of COVID’19 vaccines, which are important messages for improving the vaccination rate at the stipulated period to avoid further waves of COVID-19 spread.
• After the spread of the delta variant in March 2021, people were willing to take vaccines, and most of them got vaccinated. It creates a huge demand for the vaccine in India after March 2021. Therefore, the government should focus on increasing vaccine production and allow foreign vaccines into India to reduce demand.
6 Conclusion
In this work, COVID’19 vaccination opinions are collected among Indian tweets during this lockdown period. Overall, public sentiment is neutral across all the datasets. These findings encourage the government and the public to impose people more about the COVID’19 vaccination to overcome this false opinion. Experimental results suggest that a novel CamCapsNet achieves high classification accuracy for six twitter datasets. This work helps to clarify the vaccination opinion among people and necessary steps must be taken to overcome this neutral sentiment.
References
Agarwal, B.; Nayak, R.; Mittal, N.; Patnaik, S (2020) .Deep Learning-Based Approaches for Sentiment Analysis, XII, 319, Springer.
Amr Mousa and Björn Schuller. 2017. Contextual bidirectional long short-term memory recurrent neural network language models: A generative approach to sentiment analysis.In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, volume 1, pages 1023–1032.
Cach N. Dang.; María N.; Moreno-García.; and Fernando De la Prieta (2021). Hybrid Deep Learning Models for Sentiment Analysis, Hindawi
Cai, G.; Xia, B. Convolutional neural networks for multimedia sentiment analysis. In Proceedings of the 4th CCF Conference on Natural Language Processing and Chinese Computing—Volume 9362; Springer-Verlag: Berlin/Heidelberg, Germany, 2015; pp. 159–167.
Cheng, J.; Dong, L.; Lapata, M. (2016). Long short-term memory-networks for machine reading. arXiv:1601.06733.
Diviya Prabha, V.; Rathipriya, R (2013). Biclustering of web usage data using Gravitational Search Algorithm, International Conference on Pattern Recognition, Informatics and Mobile Engineering, IEEE.
Diviya Prabha, V.; Rathipriya, R (2021) Sentimental Analysis using Capsule Network with Gravitational Search Algorithm, Journal of Web Engineering.
Gaye B , Zhang D and Wulamu A., (2021) A Tweet Sentiment Classification Approach Using a Hybrid Stacked Ensemble Technique, MDPI, Information.
Haftu Wedajo Fentaw and Tae-Hyong Kim, Design and Investigation of Capsule Networks for Sentence Classification,Applied Science, 9, 2200, 2019.
Harleen Kaur, Shafqat Ul Ahsaan, Bhavya Alankar ,Victor Chang (2021). A Proposed Sentiment Analysis Deep Learning Algorithm for Analyzing COVID-19 Tweets, Information Systems Frontiers, Springer.
Hermann, K.M.; Blunsom, P. The Role of Syntax in Vector Space Models of Compositional Semantics. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013.
Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Artificial Neural Networks and Machine Learning—CANN 2011; Honkela, T., Duch, W., Girolami, M., Kaski, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011.
Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv 2014, arXiv:1404.2188.
Khattak A. M., Batool R,; Satti , F. A. et al., (2020). Tweets classification and sentiment analysis for personalized tweets recommendation,” Complexity, vol. 2020, pages 202.
Kim, J.; Jang, S.; Choi, S.; Park, E.L. Text classification using capsules. arXiv 2018, arXiv:1808.03976.
Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751.
McCallum, A., Nigam, K., et al. (1998). A comparison of event models for naive bayes text classification. In AAAI-98 workshop on learning for text categorization, Vol. 752 (pp. 41–48). Citeseer.
Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up?: Sentiment classification using machine learning techniques.In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing—Volume 10; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 79–86.
R.Janani and S. Vijayarani, Automatic text classification using machine learning and optimization algorithms,Soft Computing,Springer, Vol. 25, Pages 1129–1145, 2020.
Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: Long Beach, CA, USA, 2017.
Samya R, Rathipriya R, (2016). Predictive analysis for weather prediction using data mining with ANN: a study, International Journal of Computational Intelligence and Informatics.
Silva, J.; Coheur, L.; Mendes, A.C.; Wichert, A. From symbolic to sub-symbolic information in question classification. Artif. Intell. Rev. 2011, 35, 137–154.
Tripathy, A.; Agrawal, A; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach, Expert System Appl. 2016, 57, 117–126.
Xian Zhong, Jinhang Liu, Shuqin Chen. (2020). An emotion classification algorithm based on SPT-CapsNet, Deep Learning and Neutral Computing for Intelligent Sensing and Control, Neural Computing and Applications.
Zhang, X.; LeCun, Y. Text understanding from scratch. arXiv 2015, arXiv:1502.01710.
Zhao, W.; Ye, J.; Yang, M.; Lei, Z.; Zhang, S.; Zhao, Z. Investigating capsule networks with dynamic routing for text classification. arXiv 2018, arXiv:1804.00538.
Biographies

V. Diviya Prabha has completed a Ph.D in Data Mining at the Department of Computer Science, Periyar University, Salem in the year 2022. She did her M.Phil (Computer Science) and M.C.A at the same university in the years of 2019 and 2013. She has published several research papers in international journals.

R. Rathipriya is an Assistant Professor in the Department of Computer Science at Periyar University, Salem, Tamil Nadu. She received her M. Sc., M. Phil., and MCA degrees from the same Periyar University. She was awarded a Ph.D. at Bharathiyar University, Tamil Nadu, India. She has published several research papers in international journals. She is an expert in Web Mining and has acquired solid experience in Bioinformatics. Her research areas are bio-inspired computing techniques and bio-informatics.
Journal of Web Engineering, Vol. 21_5, 1583–1602.
doi: 10.13052/jwe1540-9589.2159
© 2022 River Publishers