Research on the Design of Mass Recommendation System Based on Lambda Architecture
Bowen Chen1, Li Zhu2,*, Da Wang1 and JunHua Cheng3
1School of Electronics and Electrical Engineering, Hubei University of Technology, Hubei, Wuhan, 430068, China
2Hubei Key Laboratory for High-efficiency Utilization of Solar Energy and Operation Control of Energy Storage System, Hubei University of technology, Wuhan, 430068, P. R. China
3Manager of No. 11 branch of China Communications Construction Third Engineering Bureau Co., Ltd, P. R. China
E-mail: cbw520go@live.com; julianabiding@126.com
*Corresponding Author
Received 05 July 2021; Accepted 06 August 2021; Publication 14 October 2021
Abstract
In the era of big data, in order to increasing the information data for conforms to the personalized needs of content, research scholars put forward based on the Lambda mass recommendation system architecture design, it can not only to the recessive and dominant behavior of users of the system data collection storage and research analysis, can also be based on the analysis of cascading hybrid algorithm to explore how to carry out real-time recommendation. Therefore, on the basis of understanding the research and development achievements of recommender systems at home and abroad in recent years, and based on the understanding and analysis of Lambda architecture and cascading hybrid algorithm, this paper aims at how to design a massive recommender system in line with users’ behavior, and makes clear the recommendation effect by combining with system testing.
Keywords: Lambda architecture, mass, recommender system, cascading, hybrid algorithm.
1 Introduction
By integrating the research results of domestic and foreign researchers on the development and design of recommender system, it can be seen that the foreign research on this topic was earlier, and the independent research field of recommender system had been established in the 1990s. Especially in Europe and the United States and other developed countries, educational institutions have been specialized in the study of recommended system courses. It can be seen that some foreign countries have already applied the mature technology system formed by research and exploration to the market and made some achievements. Late for recommendation system research and development projects in China, until into the era of reform and opening up, with the concept of a large number of network technology comprehensive promotion, all kinds of electronic commerce service system matures, recommended to clear the importance of system innovation, and start from the perspective of the global market of in-depth discussion and research. Nowadays, in the rapid development of big data technology concept, compared with the research results of China’s recommendation system and foreign research and development results, we can see that the gap between them is shrinking. In essence, part of the core algorithm of the recommendation system can be regarded as a practice of data mining technology. In the early research, similarity measurement was mainly used for recommendation. For example, researchers such as Spertus [1] used six different similarity measurement methods to carry out large-scale research in social networks. However, since the prediction accuracy of the recommendation system will not be affected by the similarity measurement method, Adomavicius [2] and other researchers proposed to use the nearest neighbor algorithm in the recommendation system, which does not require learning and maintaining the expectation setting model. At the same time, Bouza [3] and other researchers chose to build a decision tree model to make recommendations, which could be regarded as a splitting criterion on the basis of mastering the gain of all feature information, and then complete the model construction of response. With the continuous improvement of the simple model, the actual recommendation algorithm is also optimized. Nikovski [4] and other researchers proposed to build a mixed model. In other words, the model fitness method of decision number and association rules is used to find frequent item sets, and then the standardized numerical model is used to optimize the recommendation rules. In the continuous optimization and updating of recommendation algorithm, it is also widely used in artificial neural network. Berka [5] and other researchers proposed to use ANN model to design URL recommendation system for web navigation. The design and implementation of the system need to be studied in combination with access path, and it is not necessary to understand relevant content. Therefore, the back propagation algorithm can be combined to train feedback multi-layer sensors. In addition, the recommendation system is also used reasonably in strong classifiers. For example, Araki [5] and other researchers proposed to use SVM model to build a TV program recommendation system for users, and combined with TF-IDF to evaluate the overall feature structure. Nowadays, with the continuous optimization of the technology concept of big data, people have stored a lot of experience and high-quality technology when dealing with massive data information. Especially after the proposed distributed framework of Map Reduce, it can not only solve the problem of incomplete data mining in the past, but also lay the foundation for the practical system design and realization. For example, Google’s Tensor Flow, which is based on deep learning framework, uses a distributed framework. Although the framework structure developed in the early stage is too simple, the overall performance is not high, and the calculation speed is slow, these problems have been effectively solved with the improvement of the actual computer hardware level, and it is more suitable to be applied in the machine learning algorithm of multiple iterations. Therefore, during the practical exploration, based on the analysis of Hadoop distributed framework, in order to scientifically control the internal nodes based on YARN resource scheduler [6, 7], Google Enterprise proposed the Kubernetes platform to complete the automated deployment and scheduling work [8].
2 Design and Analysis of Mass Recommendation System
2.1 System Architecture
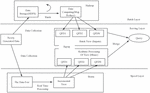
Lambda architecture, as a real-time big data processing framework, is based on the summary experience of distributed big data system operation analysis, and the ultimate goal is to design a framework that conforms to the real-time big data system operation. In practical application, this system architecture can not only carry out offline computing, but also real-time computing, and can integrate Hadoop, Kafka, and other big data components. At the same time, based on the practical computer system operation analysis, Lambda architecture has the advantages of low delay, horizontal expansion, versatility, extensibility and so on [9, 10]. The recommendation system built in the previous stand-alone environment is now unable to meet the large-scale storage and computing needs of computers for large data, while the Hadoop platform can process a large amount of data information based on the standard of big data technology and combine it with Lambda architecture. The specific structure is shown in Figure 1 below:
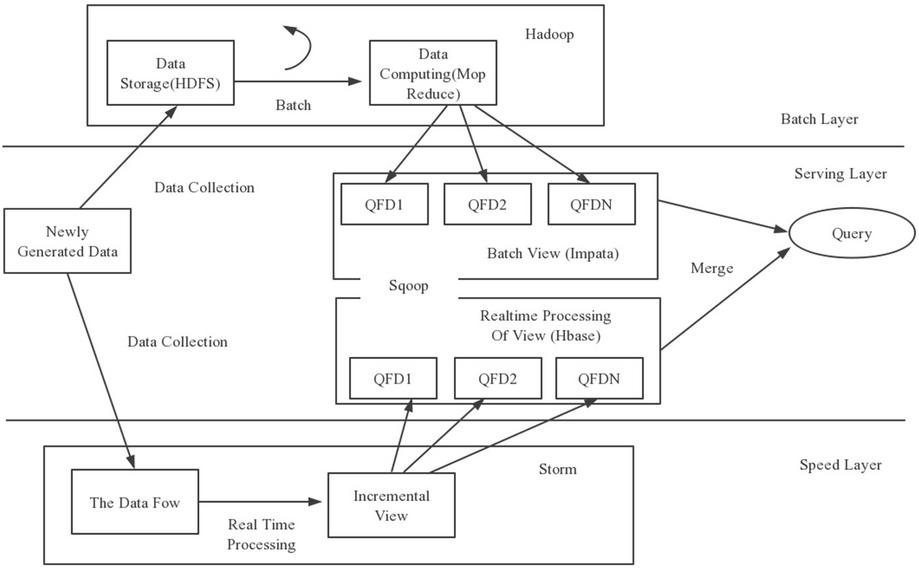
Figure 1 Architecture diagram.
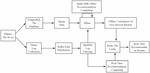
This paper makes effective use of the application advantages of Lambda architecture, and constructs specific recommendation systems according to the design requirements of different fields, as shown in Figure 2 below:
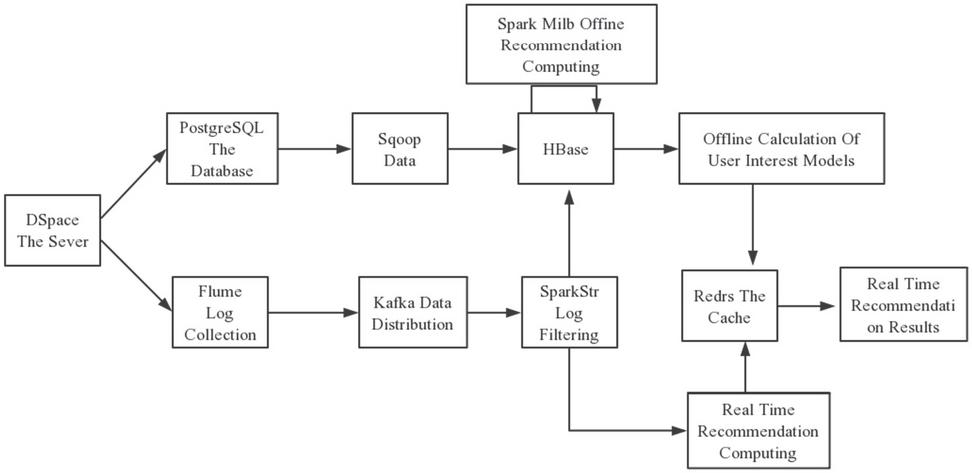
Figure 2 Recommendation system structure diagram based on Lambda architecture.
2.2 Cascading Hybrid Algorithm
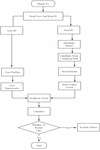
According to the analysis of the algorithm flow chart shown in Figure 3 below, the research in this paper mainly starts from the design of similarity model and user and object portrait model [11, 12]:
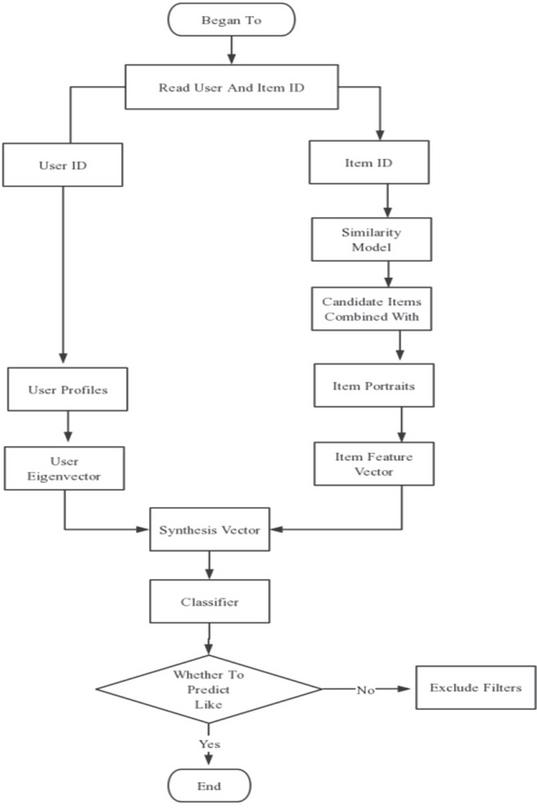
Figure 3 Flow chart based on the cascading hybrid algorithm.
On the one hand, similarity model analysis. This paper mainly discusses three algorithms: the first is the memory-centered collaborative similarity algorithm. This content is based on the study of users’ interests and hobbies, and can be completed according to relevant calculations to recommend items [13]. This kind of algorithm uses the scoring matrix to identify the set that is similar to the target object, so as to provide effective basis for subsequent recommendation. Generally speaking, the methods for calculating similarity are as follows:
Calculate with common interests as the target, and the specific formula is as follows:
In the above formula, N (m) represents the number of users who like M, N (N) represents the number of users who like N, and the intersection of the two represents the number of users who like both items. Combined with the formula analysis, it can be seen that in the case of more and more intersection between the two, it means that the number of users who like the two products is also increasing, and the similar level of the two products will be higher and higher. Also, the denominator in the above formula penalizes the weight of item n, effectively controlling the level of similarity between popular items and other items [14].
Pearson correlation coefficient is used for calculation, and the specific formula is as follows:
In the above formula, Sx and SY both represent the sample standard deviations of X and Y. This method is usually used to calculate the tightness between two well-defined distance variables, usually within the value range of [1, 1].
COSINE COSINE COSINE COSINE COSINE COSINE
The cosine value of the Angle between vectors in vector space can be calculated and analyzed to obtain, and finally can be applied to text mining.
The Tanimoto system is used for calculation. The specific formula is as follows:
Tanimoto, also known as Jaccard coefficient, is mainly used to calculate the similarity in this paper.
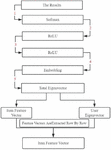
Second, the content similarity calculation with TF-IDF as the core. From the perspective of content, the proposed recommendation algorithm is a general concept, which mainly starts from the similarity analysis and calculation of users and feature attributes. According to the analysis of practical scientific computing concepts, there are many calculation methods available for content recommendation, but due to the differences in specific schemes and concerns, it gradually presents a mixed development state in the development of practice. This paper mainly studies the common dimensions of content recommendation algorithm from a coarse-grained perspective, as shown in Figure 4 below [15]:
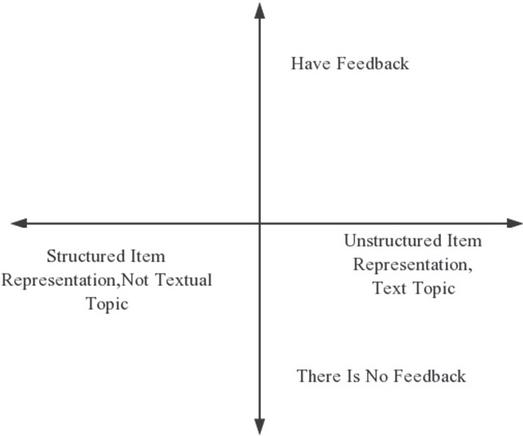
Figure 4 Classification dimension structure diagram based on content recommendation.
Combined with the above structure and the analysis of the calculation process with TF-IDF as the core, it can be seen that:
Firstly, N targets waiting for recommendation should be formed into an overall vector form, as shown below:
After the implementation of segmentation on the information contained in the sample data set, the corresponding set should be constructed, as follows:
Combined with the above two formulas, N items that need to be recommended can be identified, M different words can be used to represent, and a vector can be selected to show an item waiting for recommendation. For example, the JTH item can be represented in the form of vector:
In the above formula, wij represents the weight value of the first time and t1 in the JTH item, and the size of this value is directly proportional to the criticality of the corresponding word.
In this paper, TF-IDF is used to show the weight of the above words. For m targets waiting for recommendation, the target number of the keyword Ti contained in the set is ni, and fij can be used to show the number of the keyword Ti appearing in the target DJ waiting for recommendation. FDJ represents the total number of words contained in the target DJ waiting for recommendation. Then the calculation formula of the word frequency TFIJ in the target DJ of the keyword Ti waiting for recommendation is as follows:
IDF inverse document frequency is mainly used to measure the general importance of a word. Ni/N is used to represent the occurrence times and frequency of this word in the overall waiting recommendation target, and then logarithmic form is used to clarify the probability of obtaining the inverse document IDFI of the keyword Ti. The specific calculation formula is as follows:
At the same time, the weight value of this word can also be calculated by combining word frequency and inverse document. The specific formula is as follows:
In the above formula, ni represents the number of recommendation targets waiting for the ith word. As this value decreases, it proves that this word is more rare, and the corresponding TF value will increase accordingly. The numerical calculation formula of the weight of word I in the waiting recommendation target j is:
Third, the algorithm analysis with Spark framework as the core. This framework is designed as a new type of distributed computing architecture, which can utilize abstract distributed data sets for computing research. In line with the Hadoop framework, it has a strong function in practical applications, mainly used to support machine learning and other database analysis with multiple iterations.
On the other hand, the image model of the user and the item is designed. The hybrid algorithm contained in the cascading architecture involves a variety of algorithm models. In practical application, the most important thing is how to effectively connect the different types of algorithm models. In this paper, the portrait model is regarded as the main bridge of practical research design, and the candidate item ID set obtained by the similarity model is mapped to the item feature matrix according to the item portrait, while the user ID can map the user feature vector according to the user portrait. The two are regarded as the input content of the classification model, and after filtering layers upon layers, better information and items can be recommended for the system users. The specific operation process of the portrait based on users and objects is divided into the following points: First, data processing. By obtaining the basic information of users from the distributed file system and removing unnecessary data content, more accurate metadata can be obtained at last. Second, the modeling of user and item images. Combined with the data information contained in the metadata, modeling is carried out in the form of feature coding. Thirdly, sample training is implemented for the classification model. All metadata samples are labeled with user rating thresholds to form a dataset with three columns to fully display age, gender and other relevant information associated with different user IDs [16].
2.3 Recommendation Classifier
Combined with the structural diagram analysis shown in Figure 5 below, it can be seen that:
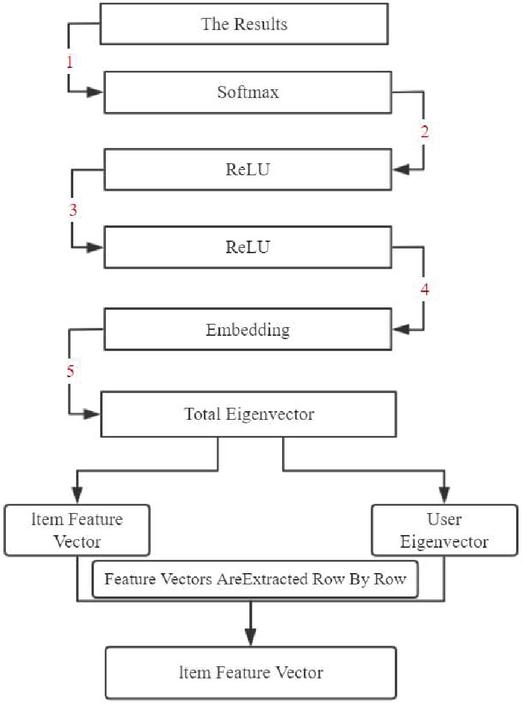
Figure 5 Structure diagram of the recommended classifier.
First, scientific processing of Embedding input features. The new feature vector is obtained, and the prediction and recommendation results of the corresponding model are obtained by combining the forward propagation form of DNN, and the specific items are recommended to the users. In this process, it is assumed that AI (k) represents the output value of unit I in layer k, and ZI (k) represents the weighted sum of input of unit I in layer k, then can be obtained, and the specific vector can be expressed as ZI (k).
Input value of layer k:
Output value of layer k:
By analogy, input a (k 1) at layer k 1 can be expressed as:
The output value of layer k 1 is:
From the perspective of back propagation, continuous optimization of parameters during DNN prediction can obtain better recommendation results, and corresponding error functions can be obtained for all training samples, as shown below:
On the basis of m sample data sets, in order to avoid excessive fitting and effectively control the weight range, L2 can be normalized. The actual error function is:
According to the pattern analysis of neural network training, the overall error J (w, b) will be greatly minimized. At this time, the gradient descent method can be used to reverse adjust the weight w and offset b in each iteration, and at this time, the learning rate is . Then, all training samples can be expressed as:
After the data set with m samples is available, L2 normality is used to prevent overfitting, then the calculation formula of weight w and bias b is as follows:
When calculating and analyzing the output function, the function mapping of the output layer can be used to obtain the prediction and recommendation results. The specific formula is as follows:
3 Result Analysis
3.1 Similarity Model
The specific analysis results are shown in Table 1 below:
Table 1 Comparative analysis results of similarity
| Operation Mode | Resource Allocation | Take/s |
| MapReduce | 3Map3Reduce | 363s |
| SparkStandalone | 2Executor | 15s |
| SparkStandalone | 3Executor | 13s |
| SparkYarn | 2Executor | 13s |
| SparkYarn | 3Executor | 11s |
Combined with the comparative analysis in Table 1, it can be seen that when the traditional distributed algorithm and the DAG structure constructed in this paper deal with massive recommendation data, the calculation speed of the latter is more than 30 times faster than that of the former, which proves that the algorithm designed in this paper has obvious advantages in the calculation application. From the perspective of resource allocation and debugging, it can not only improve the operating efficiency according to the adaptability of nodes, but also effectively deal with data sets and computing frameworks.
3.2 Classification Model
The traditional logistic regression algorithm is a high-quality algorithm with strong application performance. Assuming that the training data set is and meets the conditions of and , then the maximum likelihood estimation method is used to analyze the model parameters, and parameter B is quoted into parameter , and the following can be obtained:
The expression formula of prediction probability is as follows:
The likelihood function is:
The likelihood function of the corresponding negative logarithm is:
And because , the likelihood function of the negative logarithm can be transformed into:
Based on the calculation of the minimum value of , the estimated value of can be defined. Assuming that it is , then the corresponding logistic regression model is:
The accuracy rate (ACC) and AUC are used to calculate and analyze the application performance of the two algorithms. The specific calculation formula is as follows:
Among them, TP represents the prediction of positive categories into positive categories, FN represents the prediction of positive categories into negative categories, FP represents the prediction of negative categories into positive categories, and TN represents the prediction of negative categories into negative categories. J 1 represents the total number of positive samples, and N – represents the total number of negative samples.
The final result is shown in Table 2 below:
Table 2 Performance comparative analysis results of the classification model
| Classification Model | ACC | AUC |
| Logical regression | 0.713 | 0.757 |
| In this paper, methods | 0.837 | 0.812 |
According to the above analysis, it can be seen that all features implement vectorization processing, and the neural network model transforms the features in the same superposition mode, so that on the basis of the initial features, we can explore the hidden content of data features. The two classification logic regression is included in the recommended system engine, so we cannot implement an abstracted representation of the features because the hidden layer conversion cannot be performed. Thus, this paper shows that the construction and classification model is more effective and practical.
Based on the above analysis results, the current recommendation system provided for food shows that by organizing the 50 online food strategies on some places, collecting the relevant information on the basis of building the data set S, and implementing the multi-dimensional scoring calculation, we finally obtained the following results shown in Tables 3 and 4:
Table 3 The original food strategy
| Food Ratings | 1 | 2 | 3 | 4 | Total |
| Restaurant spacing | 9.4 | 48.4 | 9 | 18.1 | 84.9 |
| Restaurant residency time | 9 | 11 | 4 | 7 | 31 |
| Cost performance | 0.96 | 0.23 | 0.44 | 0.39 | 0.37 |
Table 4 Food guide provided by the recommendation system
| Food Ratings | 1 | 2 | 3 | 4 | Total |
| Restaurant spacing | 3 | 23.6 | 13.1 | 9.2 | 48.9 |
| Restaurant residency time | 4 | 8 | 7 | 6 | 25 |
| Cost performance | 1.33 | 0.34 | 0.53 | 0.65 | 0.51 |
Compared with the above results, not only the strategy becomes more convenient, but also reduces the distance and time between dining. Thus the analysis found that the food strategy provided based on the recommendation system is more effective than the original strategy, and can make the formation of tourists more scientific. As shown in Table 5 below, the basic information function of the actual recommended system:
Table 5 Test results of basic information function realization of the recommender system
| Test Number | Test Content | Test Input | The Output |
| 4001 | User registration | Click the register button | Jump to the registration page |
| 4002 | User logs in | Click the login button | Jump to the login page |
| 4003 | Log out | Click the Log Out button | Jump to the logout page |
| 4004 | Edit the material | Click on the user’s avatar | Jump to the user edit information page |
| 4005 | View historical orders | Click on my order cell | Jump to the history order page |
| 4006 | View the notification list | Click the Notification List button | Jump to the history notification page |
Therefore, it can be further proved that the recommendation system built based on Lambda architecture and cascading hybrid algorithm meets the practical test requirements [17].
4 Conclusion
With the continuous development of society, information technology level of continuous improvement, computer technology is also gradually deep into daily life, bringing some convenience to life. In order to provide users with more convenient information technology services to users, it is necessary to build a new recommendation system based on information technology. We introduces the design of the recommendation system and practice the application. To sum up, in the continuous innovation and exploration of information data, large-scale network information not only increases the development opportunities of the industry, but also puts forward higher requirements for the recommendation system. Based on the understanding of Lambda architecture and cascading hybrid recommendation algorithm, this paper clearly recognizes the positive effect of big data technology on the development of modern society by designing the recommendation system service platform of B/S model.
References
[1] Nielsen T A, Spertus E, Drobychev A. Methods and systems for controlling access to relationship information in a social network[J]. US, 2013.
[2] Adomavicius, Gediminas, Tuzhilin, et al. Using Data Mining Methods to Build Customer Profiles[J]. Computer, 2001.
[3] Bouza L. How could the new article 11 TEU contribute to reduce the EU’s democratic malaise?[J]. Revista Brasileira De Milho E Sorgo, 2018, 13:312–325.
[4] Nikovski D N. Method and system for recommending products to consumers by induction of decision trees[J]. US, 2007.
[5] Yuki, Urabe, Rafal, et al. Emoticon Recommendation System to Richen Your Online Communication[J]. International journal of multimedia data engineering & management, 2014, 5(1):14–33.
[6] Wang J J, Liang Y, Su J T, et al. An Analysis of the Economic Impact of US Presidential Elections Based on Principal Component and Logical Regression[J]. Complexity, 2021, 2021(8):1–12.
[7] Khalifa R M, Yacout S, Bassetto S. Developing machine-learning regression model with Logical Analysis of Data (LAD)[J]. Computers & Industrial Engineering, 2020:106947.
[8] Wang X L, Li L Q, Xie W X. A novel T-S fuzzy particle filtering algorithm based on fuzzy C-regression clustering[J]. International Journal of Approximate Reasoning, 2019, 117.
[9] Gao T, Liu J. Application of improved random forest algorithm and fuzzy mathematics in physical fitness of athletes[J]. Journal of Intelligent and Fuzzy Systems, 2020, 40(4):1–13.
[10] Liu H, Lin H, X Jiang, et al. Estimation of mass matrix in machine tool’s weak components research by using symbolic regression[J]. Computers & Industrial Engineering, 2019, 127(JAN.):998–1011.
[11] Biswas S, Nath S, Dey S, et al. Tangent-cut optimizer on gradient descent: an approach towards Hybrid Heuristics[J]. Artificial Intelligence Review, 2021:1–27.
[12] Fang Z, Guo Z C, Zhou D X. Optimal learning rates for distribution regression[J]. Journal of complexity, 2020, 56(Feb.):101426.1-101426.15.
[13] Ossai C I, Egwutuoha I P. Real-time state-of-health monitoring of lithium-ion battery with anomaly detection, Levenberg–Marquardt algorithm, and multiphase exponential regression model[J]. Neural Computing and Applications, 2020(4).
[14] Kumar P B, Parhi D R. Intelligent Hybridization of Regression Technique with Genetic Algorithm for Navigation of Humanoids in Complex Environments[J]. Robotica, 2020, 38(4):565–581.
[15] Yu X, Liu J, Keung J W, et al. Improving Ranking-Oriented Defect Prediction Using a Cost-Sensitive Ranking SVM[J]. IEEE Transactions on Reliability, 2019.
[16] Gong C, Wang P H, Su Z G. An interactive nonparametric evidential regression algorithm with instance selection[J]. Soft Computing, 2020, 24(11).
[17] Rueda R, Ruiz L, MP Cuéllar, et al. An Ant Colony Optimization approach for symbolic regression using Straight Line Programs. Application to energy consumption modelling[J]. International Journal of Approximate Reasoning, 2020, 121.
Biographies

Bowen Chen received the B.S. degree in electric engineering and automation from Hubei Polytechnic University, City, China, in 2019. He is currently working toward the M.S. degree in control engineering with the School of Hubei University of Technology, City, China. His research areas include big data, deep learning, and recommendation systems.

Li Zhu received the B.S. degree in school of information science and engineering from Wuhan University of Science and Technology, Wuhan, China, in 2004. She received the M.S. degree in Physical Electronics from Huaqiao University, Quanzhou, China, in 2007, and the Ph.D. degree in Communication and Information system from Wuhan University, Wuhan, China, in 2011. She is currently an associate professor in the School of Electrical and Electronic Engineering, Hubei University of Technology, Hubei, China. Her research areas include Artificial Intelligence and Big Data.

Da Wang received the Master degree in spatial information science and technology from Huazhong University of Science and Technology, Wuhan, China in 2008 and received the Ph.D. degree in 2012. From 2012 to now, he is a lecturer in Electrical and Electronic Engineering of HuBei University of Technology. His research interests include image reconstruction, virtual reality and data mining.

JunHua Cheng graduated from Hubei University of technology with a bachelor’s degree in management engineering. Senior engineer, national first-class constructor (communication, radio and television), long engaged in communication network construction, operation and maintenance and network optimization.
Journal of Web Engineering, Vol. 20_6, 1971–1990.
doi: 10.13052/jwe1540-9589.20614
© 2021 River Publishers